Tháng trước, tôi đã đăng một thử thách để tạo ra một trình tạo chuỗi số hiệu quả. Các phản hồi rất áp đảo. Có rất nhiều ý tưởng và đề xuất tuyệt vời, với rất nhiều ứng dụng vượt xa thách thức đặc biệt này. Điều đó khiến tôi nhận ra rằng việc trở thành một phần của cộng đồng thật tuyệt vời như thế nào và những điều tuyệt vời có thể đạt được khi một nhóm những người thông minh hợp lực. Cảm ơn Alan Burstein, Joe Obbish, Adam Machanic, Christopher Ford, Jeff Moden, Charlie, NoamGr, Kamil Kosno, Dave Mason và John Number2 đã chia sẻ ý tưởng và nhận xét của bạn.
Ban đầu tôi nghĩ chỉ viết một bài để tổng hợp những ý tưởng mà mọi người đã gửi, nhưng có quá nhiều. Vì vậy, tôi sẽ chia phạm vi phù hợp thành một số bài báo. Tháng này, tôi sẽ chủ yếu tập trung vào các cải tiến được đề xuất của Charlie và Alan Burstein đối với hai giải pháp ban đầu mà tôi đã đăng vào tháng trước dưới dạng các TVF nội tuyến có tên là dbo.GetNumsItzikBatch và dbo.GetNumsItzik. Tôi sẽ đặt tên cho các phiên bản cải tiến lần lượt là dbo.GetNumsAlanCharlieItzikBatch và dbo.GetNumsAlanCharlieItzik.
Điều này thật thú vị!
Các giải pháp ban đầu của Itzik
Xin nhắc lại, các hàm mà tôi đã đề cập vào tháng trước sử dụng CTE cơ sở xác định hàm tạo giá trị bảng có 16 hàng. Các chức năng sử dụng một loạt các CTE xếp tầng, mỗi CTE áp dụng một sản phẩm (nối chéo) của hai trường hợp CTE trước đó của nó. Bằng cách này, với năm CTE ngoài cơ sở, bạn có thể nhận được một tập hợp lên đến 4.294.967.296 hàng. CTE được gọi là Nums sử dụng hàm ROW_NUMBER để tạo ra một chuỗi các số bắt đầu bằng 1. Cuối cùng, truy vấn bên ngoài tính toán các số trong phạm vi được yêu cầu giữa các đầu vào @low và @high.
Hàm dbo.GetNumsItzikBatch sử dụng một phép nối giả vào một bảng có chỉ mục columnstore để xử lý hàng loạt. Đây là mã để tạo bảng giả:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Và đây là mã xác định hàm dbo.GetNumsItzikBatch:
CREATE OR ALTER FUNCTION dbo.GetNumsItzikBatch(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; Tôi đã sử dụng mã sau để kiểm tra chức năng với "Loại bỏ kết quả sau khi thực thi" được bật trong SSMS:
SELECT n FROM dbo.GetNumsItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Dưới đây là số liệu thống kê về hiệu suất mà tôi nhận được cho lần thực thi này:
CPU time = 16985 ms, elapsed time = 18348 ms.
Hàm dbo.GetNumsItzik cũng tương tự, chỉ khác là nó không có liên kết giả và thường được xử lý chế độ hàng trong suốt kế hoạch. Đây là định nghĩa của hàm:
CREATE OR ALTER FUNCTION dbo.GetNumsItzik(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Đây là mã tôi đã sử dụng để kiểm tra chức năng:
SELECT n FROM dbo.GetNumsItzik(1, 100000000) OPTION(MAXDOP 1);
Dưới đây là số liệu thống kê về hiệu suất mà tôi nhận được cho lần thực thi này:
CPU time = 19969 ms, elapsed time = 21229 ms.
Những cải tiến của Alan Burstein và Charlie
Alan và Charlie đã đề xuất một số cải tiến cho các chức năng của tôi, một số cải tiến với hiệu suất vừa phải và một số cải tiến ấn tượng hơn. Tôi sẽ bắt đầu với những phát hiện của Charlie về tổng chi phí biên dịch và việc gấp liên tục. Sau đó, tôi sẽ đề cập đến các đề xuất của Alan, bao gồm các chuỗi dựa trên 1 so với @ low-based (cũng được chia sẻ bởi Charlie và Jeff Moden), tránh sắp xếp không cần thiết và tính toán một phạm vi số theo thứ tự ngược lại.
Phát hiện về thời gian biên dịch
Như Charlie đã lưu ý, bộ tạo chuỗi số thường được sử dụng để tạo chuỗi với số lượng hàng rất nhỏ. Trong những trường hợp đó, thời gian biên dịch mã có thể trở thành một phần quan trọng trong tổng thời gian xử lý truy vấn. Điều đó đặc biệt quan trọng khi sử dụng iTVF, vì không giống như các thủ tục được lưu trữ, nó không phải là mã truy vấn được tham số hóa được tối ưu hóa, mà là mã truy vấn sau khi diễn ra quá trình nhúng tham số. Nói cách khác, các tham số được thay thế bằng các giá trị đầu vào trước khi tối ưu hóa và mã với các hằng số sẽ được tối ưu hóa. Quá trình này có thể có cả tác động tiêu cực và tích cực. Một trong những tác động tiêu cực là bạn nhận được nhiều biên dịch hơn khi hàm được gọi với các giá trị đầu vào khác nhau. Vì lý do này, thời gian biên dịch chắc chắn phải được tính đến — đặc biệt là khi sử dụng hàm thường xuyên với phạm vi nhỏ.
Dưới đây là thời gian biên dịch mà Charlie tìm thấy cho các thẻ bản CTE cơ bản khác nhau:
2: 22ms 4: 9ms 16: 7ms 256: 35ms
Thật tò mò khi thấy rằng trong số này, 16 là tối ưu và có một bước nhảy rất đáng kinh ngạc khi bạn lên cấp tiếp theo, là 256. Hãy nhớ lại rằng các hàm dbo.GetNumsItzikBacth và dbo.GetNumsItzik sử dụng CTE cơ bản của 16 .
Gấp liên tục
Tính năng gấp liên tục thường là một ngụ ý tích cực rằng trong điều kiện thích hợp có thể được kích hoạt nhờ vào quy trình nhúng tham số mà iTVF trải qua. Ví dụ:giả sử rằng hàm của bạn có biểu thức @x + 1, trong đó @x là tham số đầu vào của hàm. Bạn gọi hàm với @x =5 làm đầu vào. Khi đó, biểu thức nội dòng sẽ trở thành 5 + 1 và nếu đủ điều kiện để gấp liên tục (thêm về điều này trong thời gian ngắn), thì sẽ trở thành 6. Nếu biểu thức này là một phần của biểu thức phức tạp hơn liên quan đến các cột và được áp dụng cho nhiều triệu hàng, điều này có thể dẫn đến tiết kiệm không đáng kể trong các chu kỳ CPU.
Phần khó khăn là SQL Server rất kén chọn những gì cần liên tục gấp và những gì không liên tục gấp. Ví dụ:SQL Server sẽ không không đổi lần gấp col1 + 5 + 1, cũng không phải gấp 5 + col1 + 1. Nhưng nó sẽ gấp 5 + 1 + col1 thành 6 + col1. Tôi biết. Vì vậy, ví dụ:nếu hàm của bạn trả về SELECT @x + col1 + 1 AS mycol1 FROM dbo.T1, bạn có thể kích hoạt tính năng gấp liên tục với thay đổi nhỏ sau:SELECT @x + 1 + col1 AS mycol1 FROM dbo.T1. Không tin tôi? Kiểm tra các kế hoạch cho ba truy vấn sau trong cơ sở dữ liệu PerformanceV5 (hoặc các truy vấn tương tự với dữ liệu của bạn) và tự xem:
SELECT orderid + 5 + 1 AS myorderid FROM dbo.orders; SELECT 5 + orderid + 1 AS myorderid FROM dbo.orders; SELECT 5 + 1 + orderid AS myorderid FROM dbo.orders;
Tôi nhận được ba biểu thức sau trong toán tử Tính vô hướng cho ba truy vấn này, tương ứng:
[Expr1003] = Scalar Operator([PerformanceV5].[dbo].[Orders].[orderid]+(5)+(1)) [Expr1003] = Scalar Operator((5)+[PerformanceV5].[dbo].[Orders].[orderid]+(1)) [Expr1003] = Scalar Operator((6)+[PerformanceV5].[dbo].[Orders].[orderid])
Xem tôi sẽ đi đâu với cái này? Trong các hàm của mình, tôi đã sử dụng biểu thức sau để xác định cột kết quả n:
@low + rownum - 1 AS n
Charlie nhận ra rằng với một thay đổi nhỏ sau đây, anh ấy có thể cho phép gấp liên tục:
@low - 1 + rownum AS n
Ví dụ:kế hoạch cho truy vấn trước đó mà tôi đã cung cấp chống lại dbo.GetNumsItzik, với @low =1, ban đầu có biểu thức sau được xác định bởi toán tử Compute Scalar:
[Expr1154] = Scalar Operator((1)+[Expr1153]-(1))
Sau khi áp dụng thay đổi nhỏ ở trên, biểu thức trong kế hoạch trở thành:
[Expr1154] = Scalar Operator((0)+[Expr1153])
Thật tuyệt vời!
Đối với các hàm ý về hiệu suất, hãy nhớ lại rằng thống kê hiệu suất mà tôi nhận được cho truy vấn chống lại dbo.GetNumsItzikBatch trước khi thay đổi như sau:
CPU time = 16985 ms, elapsed time = 18348 ms.
Đây là những con số tôi nhận được sau khi thay đổi:
CPU time = 16375 ms, elapsed time = 17932 ms.
Đây là những con số mà tôi nhận được cho truy vấn chống lại dbo.GetNumsItzik ban đầu:
CPU time = 19969 ms, elapsed time = 21229 ms.
Và đây là những con số sau khi thay đổi:
CPU time = 19266 ms, elapsed time = 20588 ms.
Hiệu suất được cải thiện chỉ vài phần trăm một chút. Nhưng xin chờ chút nữa! Nếu bạn cần xử lý dữ liệu đã được sắp xếp theo thứ tự, thì tác động của hiệu suất có thể ấn tượng hơn nhiều, vì tôi sẽ trình bày ở phần sau về thứ tự.
dãy số dựa trên 1 so với @ low-based và số hàng đối diện
Alan, Charlie và Jeff lưu ý rằng trong phần lớn các trường hợp thực tế khi bạn cần một dải số, bạn cần nó bắt đầu bằng 1 hoặc đôi khi là 0. Việc cần một điểm xuất phát khác ít phổ biến hơn nhiều. Vì vậy, sẽ có ý nghĩa hơn khi hàm luôn trả về một phạm vi bắt đầu bằng, ví dụ, 1, và khi bạn cần một điểm bắt đầu khác, hãy áp dụng bất kỳ tính toán nào bên ngoài trong truy vấn đối với hàm.
Alan thực sự đã nảy ra một ý tưởng tuyệt vời là để TVF nội tuyến trả về cả một cột bắt đầu bằng 1 (chỉ đơn giản là kết quả trực tiếp của hàm ROW_NUMBER) được đặt bí danh là rn và một cột bắt đầu với bí danh @low là n. Vì hàm được nội tuyến, khi truy vấn bên ngoài chỉ tương tác với cột rn, cột n thậm chí không được đánh giá và bạn sẽ nhận được lợi ích về hiệu suất. Khi bạn thực sự cần trình tự bắt đầu bằng @low, bạn tương tác với cột n và trả thêm chi phí hiện hành, vì vậy không cần thêm bất kỳ phép tính bên ngoài rõ ràng nào. Alan thậm chí còn đề xuất thêm một cột có tên op tính toán các con số theo thứ tự ngược lại và chỉ tương tác với nó khi cần một chuỗi như vậy. Op của cột dựa trên phép tính:@high + 1 - rownum. Cột này có ý nghĩa khi bạn cần xử lý các hàng theo thứ tự số lượng giảm dần như tôi trình bày ở phần sau trong phần sắp xếp.
Vì vậy, hãy áp dụng các cải tiến của Charlie và Alan cho các chức năng của tôi.
Đối với phiên bản chế độ hàng loạt, trước tiên hãy đảm bảo rằng bạn tạo bảng giả với chỉ mục columnstore, nếu bảng này chưa có:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Sau đó, sử dụng định nghĩa sau cho hàm dbo.GetNumsAlanCharlieItzikBatch:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; Dưới đây là một ví dụ để sử dụng hàm:
SELECT * FROM dbo.GetNumsAlanCharlieItzikBatch(-2, 3) AS F ORDER BY rn;
Mã này tạo ra kết quả sau:
rn op n --- --- --- 1 3 -2 2 2 -1 3 1 0 4 0 1 5 -1 2 6 -2 3
Tiếp theo, kiểm tra hiệu suất của hàm với 100 triệu hàng, trước tiên trả về cột n:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Dưới đây là thống kê hiệu suất mà tôi nhận được cho lần thực thi này:
CPU time = 16375 ms, elapsed time = 17932 ms.
Như bạn có thể thấy, có một cải tiến nhỏ so với dbo.GetNumsItzikBatch về cả CPU và thời gian đã trôi qua nhờ khả năng gấp liên tục diễn ra ở đây.
Kiểm tra chức năng, chỉ lần này trả về cột rn:
SELECT rn FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Dưới đây là thống kê hiệu suất mà tôi nhận được cho lần thực thi này:
CPU time = 15890 ms, elapsed time = 18561 ms.
Thời gian CPU giảm hơn nữa, mặc dù thời gian trôi qua dường như đã tăng lên một chút trong quá trình thực thi này so với khi truy vấn cột n.
Hình 1 có các kế hoạch cho cả hai truy vấn.
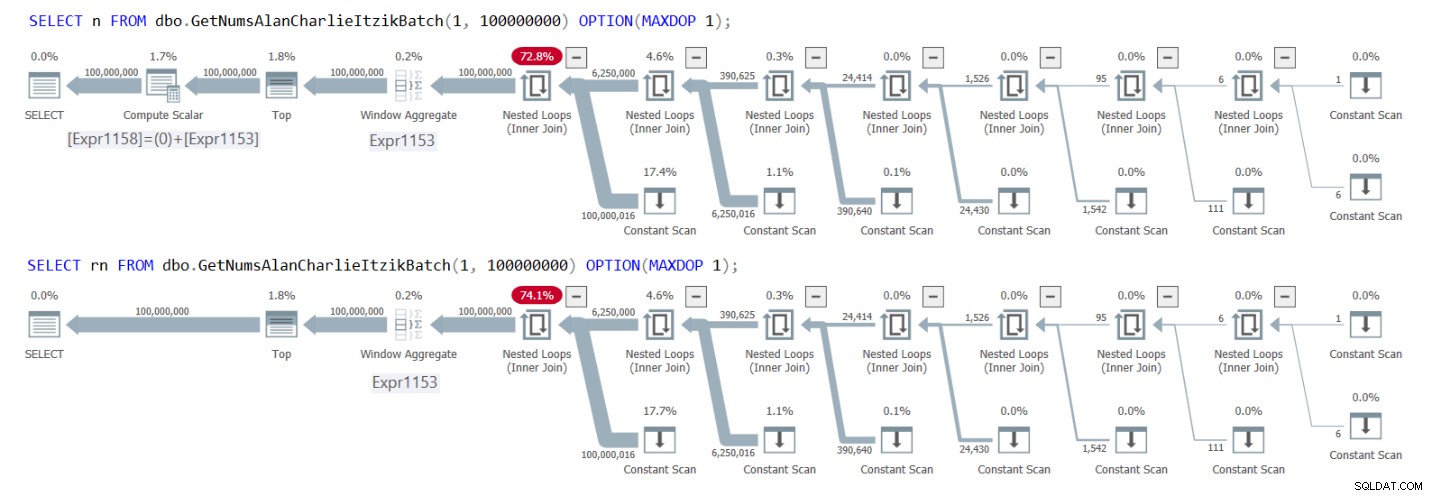 Hình 1:Các kế hoạch cho GetNumsAlanCharlieItzikBatch trả về n so với rn
Hình 1:Các kế hoạch cho GetNumsAlanCharlieItzikBatch trả về n so với rn
Bạn có thể thấy rõ trong các kế hoạch rằng khi tương tác với cột rn, không cần thêm toán tử Tính toán vô hướng. Cũng lưu ý trong kế hoạch đầu tiên về kết quả của hoạt động gấp liên tục mà tôi đã mô tả trước đó, trong đó @low - 1 + rownum được liên kết thành 1 - 1 + rownum, và sau đó được gấp lại thành 0 + rownum.
Dưới đây là định nghĩa về phiên bản chế độ hàng của hàm được gọi là dbo.GetNumsAlanCharlieItzik:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzik(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum; Sử dụng mã sau để kiểm tra chức năng, trước tiên hãy truy vấn cột n:
SELECT n FROM dbo.GetNumsAlanCharlieItzik(1, 100000000) OPTION(MAXDOP 1);
Đây là thống kê hiệu suất mà tôi nhận được:
CPU time = 19047 ms, elapsed time = 20121 ms.
Như bạn có thể thấy, nó nhanh hơn một chút so với dbo.GetNumsItzik.
Tiếp theo, truy vấn cột rn:
SELECT rn FROM dbo.GetNumsAlanCharlieItzik(1, 100000000) OPTION(MAXDOP 1);
Các con số hiệu suất được cải thiện hơn nữa trên cả CPU và mặt trận thời gian đã trôi qua:
CPU time = 17656 ms, elapsed time = 18990 ms.
Cân nhắc khi đặt hàng
Những cải tiến nói trên chắc chắn rất thú vị và tác động đến hiệu suất là không đáng kể, nhưng không đáng kể. Có thể quan sát thấy tác động mạnh mẽ và sâu sắc hơn đến hiệu suất khi bạn cần xử lý dữ liệu được sắp xếp theo cột số. Điều này có thể đơn giản như cần trả lại các hàng đã được sắp xếp, nhưng cũng phù hợp với bất kỳ nhu cầu xử lý dựa trên thứ tự nào, ví dụ:toán tử Tổng hợp luồng để nhóm và tổng hợp, thuật toán Kết hợp hợp nhất để tham gia, v.v.
Khi truy vấn dbo.GetNumsItzikBatch hoặc dbo.GetNumsItzik và sắp xếp theo n, trình tối ưu hóa không nhận ra rằng biểu thức sắp xếp cơ bản @low + rownum - 1 là bảo toàn đơn hàng đối với rownum. Hàm ý hơi giống với hàm ý của biểu thức lọc không phải SARGable, chỉ với biểu thức sắp xếp thứ tự, điều này dẫn đến toán tử Sắp xếp rõ ràng trong kế hoạch. Việc sắp xếp thêm ảnh hưởng đến thời gian phản hồi. Nó cũng ảnh hưởng đến việc chia tỷ lệ, thường trở thành n log n thay vì n.
Để chứng minh điều này, hãy truy vấn dbo.GetNumsItzikBatch, yêu cầu cột n, được sắp xếp theo n:
SELECT n FROM dbo.GetNumsItzikBatch(1,100000000) ORDER BY n OPTION(MAXDOP 1);
Tôi nhận được số liệu thống kê hiệu suất sau:
CPU time = 34125 ms, elapsed time = 39656 ms.
Thời gian chạy tăng hơn gấp đôi so với thử nghiệm không có điều khoản ORDER BY.
Kiểm tra hàm dbo.GetNumsItzik theo cách tương tự:
SELECT n FROM dbo.GetNumsItzik(1,100000000) ORDER BY n OPTION(MAXDOP 1);
Tôi nhận được những con số sau cho bài kiểm tra này:
CPU time = 52391 ms, elapsed time = 55175 ms.
Cũng ở đây thời gian chạy tăng hơn gấp đôi so với thử nghiệm không có mệnh đề ORDER BY.
Hình 2 có các kế hoạch cho cả hai truy vấn.
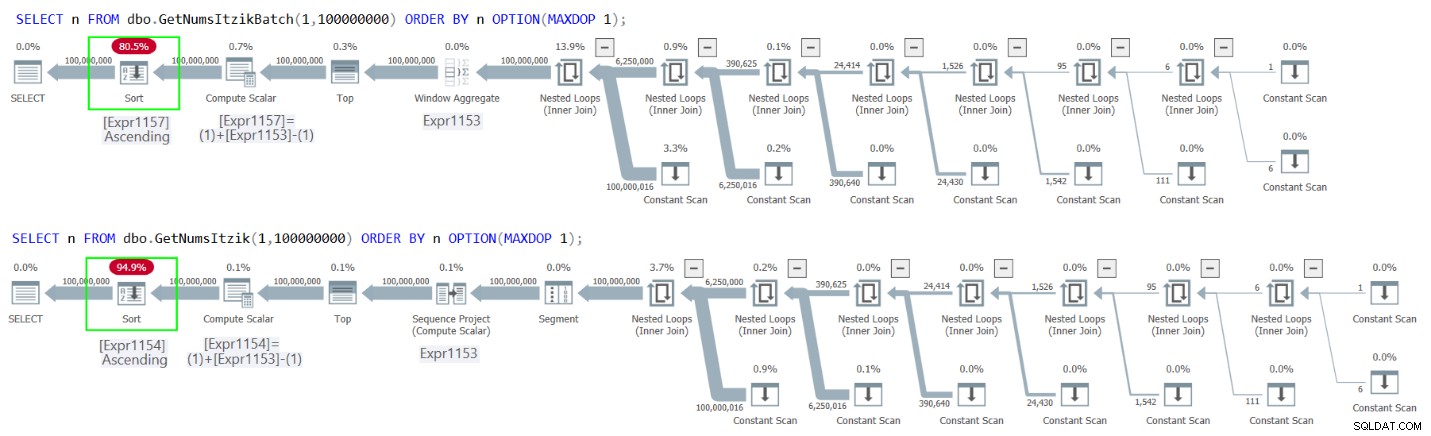 Hình 2:Kế hoạch sắp xếp GetNumsItzikBatch và GetNumsItzik theo n
Hình 2:Kế hoạch sắp xếp GetNumsItzikBatch và GetNumsItzik theo n
Trong cả hai trường hợp, bạn có thể thấy toán tử Sắp xếp rõ ràng trong các kế hoạch.
Khi truy vấn dbo.GetNumsAlanCharlieItzikBatch hoặc dbo.GetNumsAlanCharlieItzik và sắp xếp theo rn, trình tối ưu hóa không cần thêm toán tử Sắp xếp vào kế hoạch. Vì vậy, bạn có thể trả về n, nhưng sắp xếp theo rn, và theo cách này, tránh một sự sắp xếp. Tuy nhiên, điều hơi gây sốc — và tôi muốn nói theo cách tốt — là phiên bản sửa đổi của n trải nghiệm gấp liên tục, là bảo toàn trật tự! Trình tối ưu hóa có thể dễ dàng nhận ra rằng 0 + rownum là một biểu thức bảo toàn trật tự đối với rownum và do đó tránh được sự sắp xếp.
Thử nó. Truy vấn dbo.GetNumsAlanCharlieItzikBatch, trả về n và sắp xếp theo n hoặc rn, như sau:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n -- same with rn OPTION(MAXDOP 1);
Tôi nhận được các số hiệu suất sau:
CPU time = 16500 ms, elapsed time = 17684 ms.
Tất nhiên, đó là nhờ thực tế là không cần toán tử Sắp xếp trong kế hoạch.
Chạy thử nghiệm tương tự với dbo.GetNumsAlanCharlieItzik:
SELECT n FROM dbo.GetNumsAlanCharlieItzik(1,100000000) ORDER BY n -- same with rn OPTION(MAXDOP 1);
Tôi có những con số sau:
CPU time = 19546 ms, elapsed time = 20803 ms.
Hình 3 có các kế hoạch cho cả hai truy vấn:
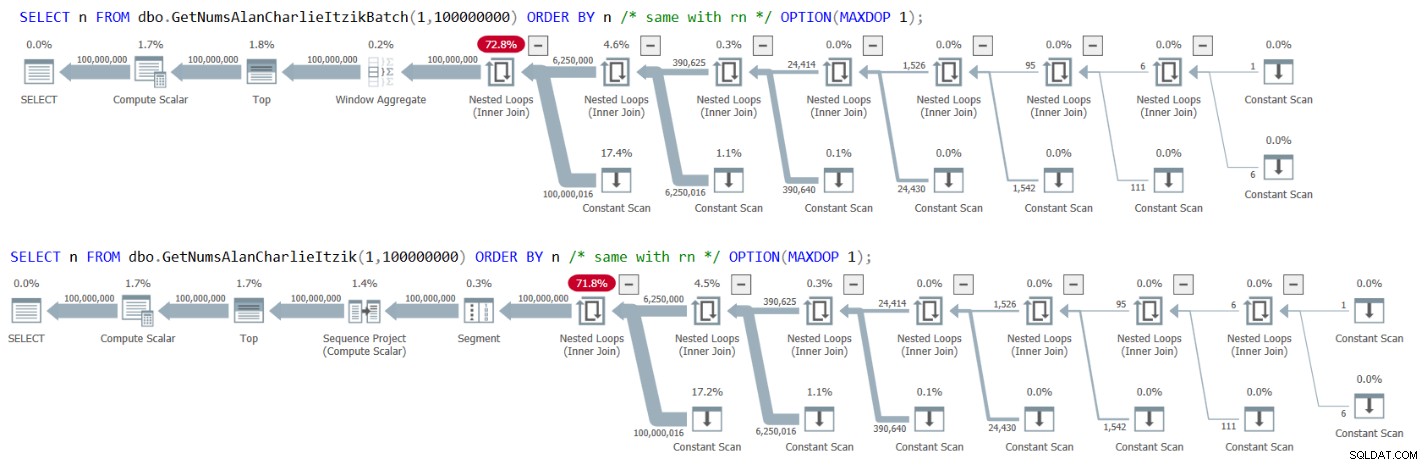
Hình 3:Các kế hoạch cho GetNumsAlanCharlieItzikBatch và GetNumsAlanCharlieItzik sắp xếp theo n hoặc rn
Quan sát rằng không có toán tử Sắp xếp trong các kế hoạch.
Khiến bạn muốn hát…
All you need is constant folding All you need is constant folding All you need is constant folding, constant folding Constant folding is all you need
Cảm ơn Charlie!
Nhưng nếu bạn cần trả lại hoặc xử lý các số theo thứ tự giảm dần thì sao? Cố gắng rõ ràng là sử dụng ORDER BY n DESC, hoặc ORDER BY rn DESC, như sau:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n DESC OPTION(MAXDOP 1); SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY rn DESC OPTION(MAXDOP 1);
Tuy nhiên, thật không may, cả hai trường hợp đều dẫn đến một sự sắp xếp rõ ràng trong các kế hoạch, như thể hiện trong Hình 4.
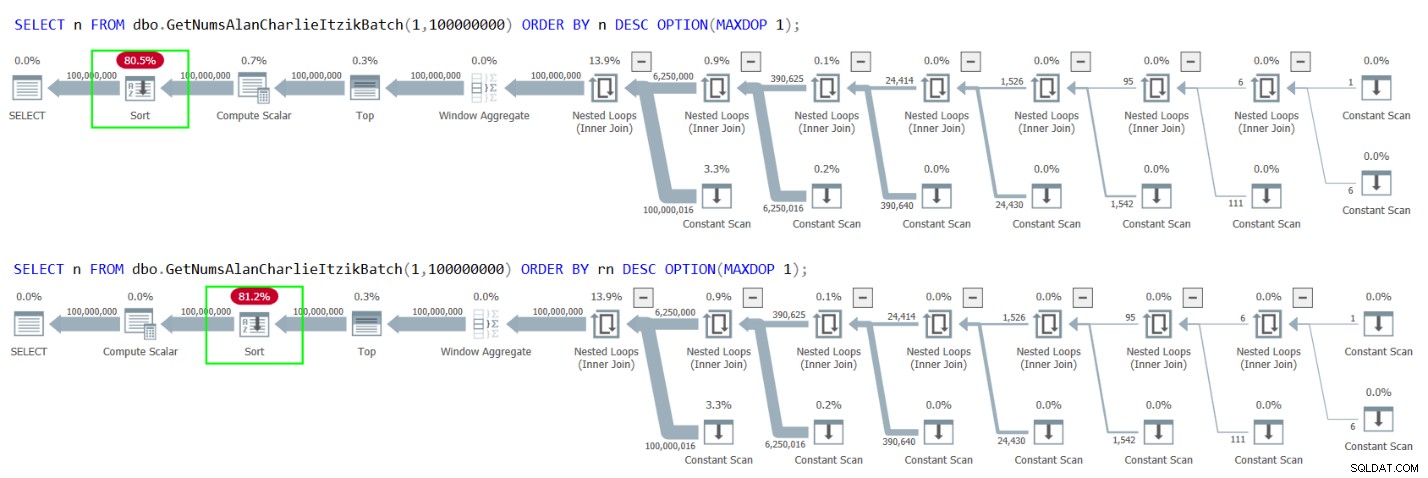 Hình 4:Kế hoạch sắp xếp GetNumsAlanCharlieItzikBatch theo n hoặc rn giảm dần
Hình 4:Kế hoạch sắp xếp GetNumsAlanCharlieItzikBatch theo n hoặc rn giảm dần
Đây là lúc mà mẹo thông minh của Alan với cột op trở thành cứu cánh. Trả về cột op trong khi sắp xếp theo n hoặc rn, như vậy:
SELECT op FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n OPTION(MAXDOP 1);
Kế hoạch cho truy vấn này được thể hiện trong Hình 5.
 Hình 5:Kế hoạch cho GetNumsAlanCharlieItzikBatch trả về op và sắp xếp theo n hoặc rn tăng dần
Hình 5:Kế hoạch cho GetNumsAlanCharlieItzikBatch trả về op và sắp xếp theo n hoặc rn tăng dần
Bạn lấy lại dữ liệu được sắp xếp theo thứ tự n giảm dần và không cần sắp xếp trong kế hoạch.
Cảm ơn Alan!
Tóm tắt hiệu suất
Vậy chúng ta đã học được gì từ tất cả những điều này?
Thời gian biên dịch có thể là một yếu tố, đặc biệt là khi sử dụng hàm thường xuyên với phạm vi nhỏ. Trên thang logarit với cơ số 2, số 16 ngọt ngào dường như là một con số kỳ diệu tuyệt vời.
Hiểu đặc thù của việc gấp liên tục và sử dụng chúng làm lợi thế của bạn. Khi iTVF có các biểu thức liên quan đến tham số, hằng số và cột, hãy đặt các tham số và hằng số vào phần đầu của biểu thức. Điều này sẽ tăng khả năng gấp, giảm chi phí CPU và tăng khả năng bảo quản đơn đặt hàng.
Bạn có thể sử dụng nhiều cột cho các mục đích khác nhau trong iTVF và truy vấn những cột có liên quan trong từng trường hợp mà không phải lo lắng về việc trả tiền cho những cột không được tham chiếu.
Khi bạn cần trả về dãy số theo thứ tự ngược lại, hãy sử dụng cột n hoặc rn ban đầu trong mệnh đề ORDER BY với thứ tự tăng dần và trả về cột op, tính toán các số theo thứ tự nghịch đảo.
Hình 6 tóm tắt các con số hiệu suất mà tôi nhận được trong các bài kiểm tra khác nhau.
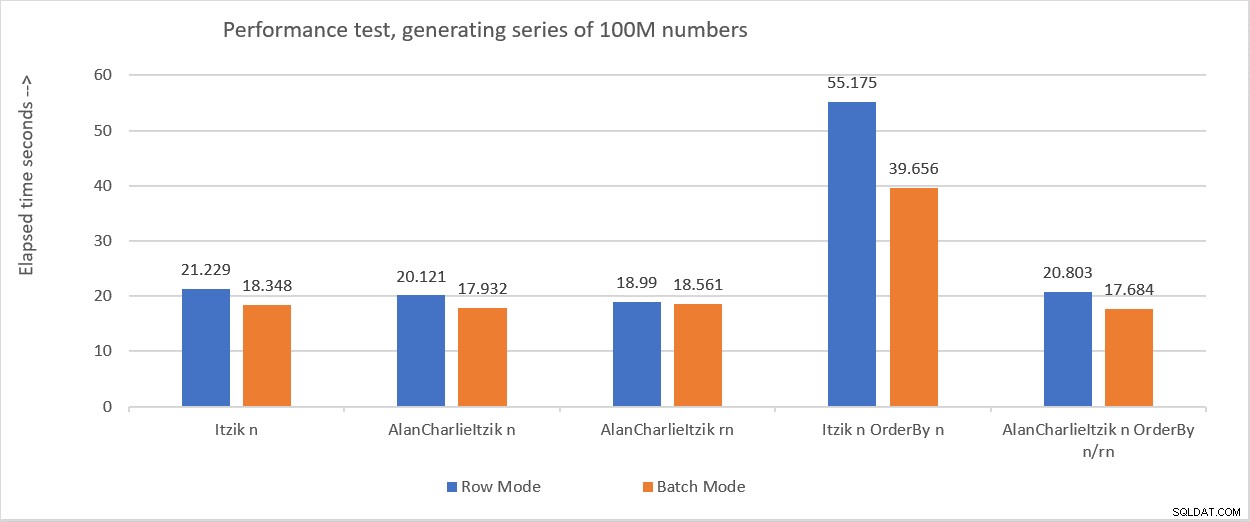 Hình 6:Tóm tắt hiệu suất
Hình 6:Tóm tắt hiệu suất
Tháng tới, tôi sẽ tiếp tục khám phá các ý tưởng, thông tin chi tiết và giải pháp bổ sung cho thách thức trình tạo chuỗi số.