TeamCity là một máy chủ phân phối liên tục và tích hợp liên tục được xây dựng bằng Java. Nó có sẵn dưới dạng dịch vụ đám mây và tại chỗ. Như bạn có thể tưởng tượng, các công cụ tích hợp và phân phối liên tục rất quan trọng đối với sự phát triển phần mềm và tính khả dụng của chúng phải không bị ảnh hưởng. May mắn thay, TeamCity có thể được triển khai ở chế độ Khả dụng cao.
Bài đăng trên blog này sẽ đề cập đến việc chuẩn bị và triển khai một môi trường có tính khả dụng cao cho TeamCity.
Môi trường
TeamCity bao gồm một số yếu tố. Có một ứng dụng Java và một cơ sở dữ liệu sao lưu nó. Nó cũng sử dụng các tác nhân đang giao tiếp với phiên bản TeamCity chính. Việc triển khai có tính khả dụng cao bao gồm một số phiên bản TeamCity, trong đó một phiên bản đóng vai trò là phiên bản chính và các phiên bản khác đóng vai trò phụ. Những trường hợp đó chia sẻ quyền truy cập vào cùng một cơ sở dữ liệu và thư mục dữ liệu. Lược đồ hữu ích có sẵn trên trang tài liệu TeamCity, như được hiển thị bên dưới:

Như chúng ta có thể thấy, có hai phần tử được chia sẻ - thư mục dữ liệu và kho dữ liệu. Chúng tôi phải đảm bảo rằng những thứ đó cũng có tính khả dụng cao. Có các tùy chọn khác nhau mà bạn có thể sử dụng để xây dựng một mount chia sẻ; tuy nhiên, chúng tôi sẽ sử dụng GlusterFS. Đối với cơ sở dữ liệu, chúng tôi sẽ sử dụng một trong những hệ quản trị cơ sở dữ liệu quan hệ được hỗ trợ - PostgreSQL và chúng tôi sẽ sử dụng ClusterControl để xây dựng một ngăn xếp tính khả dụng cao dựa trên nó.
Cách định cấu hình GlusterFS
Hãy bắt đầu với những điều cơ bản. Chúng tôi muốn định cấu hình tên máy chủ và / etc / hosts trên các nút TeamCity của chúng tôi, nơi chúng tôi cũng sẽ triển khai GlusterFS. Để làm điều đó, chúng tôi cần thiết lập kho lưu trữ cho các gói mới nhất của GlusterFS trên tất cả chúng:
sudo add-apt-repository ppa:gluster/glusterfs-7
sudo apt updateSau đó, chúng tôi có thể cài đặt GlusterFS trên tất cả các nút TeamCity của chúng tôi:
sudo apt install glusterfs-server
sudo systemctl enable glusterd.service
example@sqldat.com:~# sudo systemctl start glusterd.service
example@sqldat.com:~# sudo systemctl status glusterd.service
● glusterd.service - GlusterFS, a clustered file-system server
Loaded: loaded (/lib/systemd/system/glusterd.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2022-02-21 11:42:35 UTC; 7s ago
Docs: man:glusterd(8)
Process: 48918 ExecStart=/usr/sbin/glusterd -p /var/run/glusterd.pid --log-level $LOG_LEVEL $GLUSTERD_OPTIONS (code=exited, status=0/SUCCESS)
Main PID: 48919 (glusterd)
Tasks: 9 (limit: 4616)
Memory: 4.8M
CGroup: /system.slice/glusterd.service
└─48919 /usr/sbin/glusterd -p /var/run/glusterd.pid --log-level INFO
Feb 21 11:42:34 node1 systemd[1]: Starting GlusterFS, a clustered file-system server...
Feb 21 11:42:35 node1 systemd[1]: Started GlusterFS, a clustered file-system server.GlusterFS sử dụng cổng 24007 để kết nối giữa các nút; chúng ta phải đảm bảo rằng tất cả các nút đều mở và có thể truy cập được.
Khi đã có kết nối, chúng ta có thể tạo một cụm GlusterFS bằng cách chạy từ một nút:
example@sqldat.com:~# gluster peer probe node2
peer probe: success.
example@sqldat.com:~# gluster peer probe node3
peer probe: success.Bây giờ, chúng tôi có thể kiểm tra trạng thái trông như thế nào:
example@sqldat.com:~# gluster peer status
Number of Peers: 2
Hostname: node2
Uuid: e0f6bc53-d47d-4db6-843b-9feea111a713
State: Peer in Cluster (Connected)
Hostname: node3
Uuid: c7d285d1-bcc8-477f-a3d7-7e56ff6bfd1a
State: Peer in Cluster (Connected)Có vẻ như mọi thứ đều tốt và kết nối đã ổn định.
Tiếp theo, chúng ta nên chuẩn bị một thiết bị khối để GlusterFS sử dụng. Điều này phải được thực hiện trên tất cả các nút. Đầu tiên, tạo một phân vùng:
example@sqldat.com:~# echo 'type=83' | sudo sfdisk /dev/sdb
Checking that no-one is using this disk right now ... OK
Disk /dev/sdb: 30 GiB, 32212254720 bytes, 62914560 sectors
Disk model: VBOX HARDDISK
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
>>> Created a new DOS disklabel with disk identifier 0xbcf862ff.
/dev/sdb1: Created a new partition 1 of type 'Linux' and of size 30 GiB.
/dev/sdb2: Done.
New situation:
Disklabel type: dos
Disk identifier: 0xbcf862ff
Device Boot Start End Sectors Size Id Type
/dev/sdb1 2048 62914559 62912512 30G 83 Linux
The partition table has been altered.
Calling ioctl() to re-read partition table.
Syncing disks.Sau đó, hãy định dạng phân vùng đó:
example@sqldat.com:~# mkfs.xfs -i size=512 /dev/sdb1
meta-data=/dev/sdb1 isize=512 agcount=4, agsize=1966016 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=1, rmapbt=0
= reflink=1
data = bsize=4096 blocks=7864064, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0, ftype=1
log =internal log bsize=4096 blocks=3839, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0Cuối cùng, trên tất cả các nút, chúng ta cần tạo một thư mục sẽ được sử dụng để gắn kết phân vùng và chỉnh sửa fstab để đảm bảo nó sẽ được gắn khi khởi động:
example@sqldat.com:~# mkdir -p /data/brick1
echo '/dev/sdb1 /data/brick1 xfs defaults 1 2' >> /etc/fstabBây giờ hãy xác minh rằng điều này hoạt động:
example@sqldat.com:~# mount -a && mount | grep brick
/dev/sdb1 on /data/brick1 type xfs (rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota)Bây giờ chúng ta có thể sử dụng một trong các nút để tạo và bắt đầu tập GlusterFS:
example@sqldat.com:~# sudo gluster volume create teamcity replica 3 node1:/data/brick1 node2:/data/brick1 node3:/data/brick1 force
volume create: teamcity: success: please start the volume to access data
example@sqldat.com:~# sudo gluster volume start teamcity
volume start: teamcity: successXin lưu ý rằng chúng tôi sử dụng giá trị '3' cho số lượng bản sao. Nó có nghĩa là mỗi tập sẽ tồn tại trong ba bản sao. Trong trường hợp của chúng tôi, mọi viên gạch, mọi ổ đĩa / dev / sdb1 trên tất cả các nút sẽ chứa tất cả dữ liệu.
Khi các tập được bắt đầu, chúng tôi có thể xác minh trạng thái của chúng:
example@sqldat.com:~# sudo gluster volume status
Status of volume: teamcity
Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick node1:/data/brick1 49152 0 Y 49139
Brick node2:/data/brick1 49152 0 Y 49001
Brick node3:/data/brick1 49152 0 Y 51733
Self-heal Daemon on localhost N/A N/A Y 49160
Self-heal Daemon on node2 N/A N/A Y 49022
Self-heal Daemon on node3 N/A N/A Y 51754
Task Status of Volume teamcity
------------------------------------------------------------------------------
There are no active volume tasksNhư bạn thấy, mọi thứ đều ổn. Điều quan trọng là GlusterFS đã chọn cổng 49152 để truy cập ổ đĩa đó và chúng tôi phải đảm bảo rằng nó có thể truy cập được trên tất cả các nút nơi chúng tôi sẽ gắn nó.
Bước tiếp theo sẽ là cài đặt gói ứng dụng khách GlusterFS. Đối với ví dụ này, chúng tôi cần cài đặt nó trên cùng các nút với máy chủ GlusterFS:
example@sqldat.com:~# sudo apt install glusterfs-client
Reading package lists... Done
Building dependency tree
Reading state information... Done
glusterfs-client is already the newest version (7.9-ubuntu1~focal1).
glusterfs-client set to manually installed.
0 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.Tiếp theo, chúng ta cần tạo một thư mục trên tất cả các nút để sử dụng làm thư mục dữ liệu chia sẻ cho TeamCity. Điều này phải xảy ra trên tất cả các nút:
example@sqldat.com:~# sudo mkdir /teamcity-storageCuối cùng, gắn ổ đĩa GlusterFS trên tất cả các nút:
example@sqldat.com:~# sudo mount -t glusterfs node1:teamcity /teamcity-storage/
example@sqldat.com:~# df | grep teamcity
node1:teamcity 31440900 566768 30874132 2% /teamcity-storageViệc này hoàn tất việc chuẩn bị bộ nhớ dùng chung.
Xây dựng Cụm PostgreSQL Khả dụng Cao
Sau khi thiết lập bộ nhớ dùng chung cho TeamCity hoàn tất, bây giờ chúng tôi có thể xây dựng cơ sở hạ tầng cơ sở dữ liệu sẵn có của mình. TeamCity có thể sử dụng các cơ sở dữ liệu khác nhau; tuy nhiên, chúng tôi sẽ sử dụng PostgreSQL trong blog này. Chúng tôi sẽ tận dụng ClusterControl để triển khai và sau đó quản lý môi trường cơ sở dữ liệu.
Hướng dẫn xây dựng triển khai đa nút của TeamCity rất hữu ích, nhưng có vẻ như làm mất đi tính khả dụng cao của mọi thứ khác ngoài TeamCity. Hướng dẫn của TeamCity đề xuất một máy chủ NFS hoặc SMB để lưu trữ dữ liệu, bản thân nó, không có khả năng dự phòng và sẽ trở thành một điểm lỗi duy nhất. Chúng tôi đã giải quyết vấn đề này bằng cách sử dụng GlusterFS. Họ đề cập đến một cơ sở dữ liệu được chia sẻ, vì một nút cơ sở dữ liệu đơn lẻ rõ ràng là không cung cấp tính khả dụng cao. Chúng ta phải xây dựng một ngăn xếp phù hợp:

Trong trường hợp của chúng tôi. nó sẽ bao gồm ba nút PostgreSQL, một nút chính và hai nút sao. Chúng tôi sẽ sử dụng HAProxy làm bộ cân bằng tải và sử dụng Keepalived để quản lý IP ảo nhằm cung cấp một điểm cuối duy nhất cho ứng dụng kết nối. ClusterControl sẽ xử lý các lỗi bằng cách giám sát cấu trúc liên kết sao chép và thực hiện bất kỳ khôi phục bắt buộc nào nếu cần, chẳng hạn như khởi động lại các quy trình bị lỗi hoặc không thực hiện được một trong các bản sao nếu nút chính gặp sự cố.
Để bắt đầu, chúng ta sẽ triển khai các nút cơ sở dữ liệu. Hãy nhớ rằng ClusterControl yêu cầu kết nối SSH từ nút ClusterControl đến tất cả các nút mà nó quản lý.

Sau đó, chúng tôi chọn một người dùng mà chúng tôi sẽ sử dụng để kết nối với cơ sở dữ liệu, mật khẩu của nó và phiên bản PostgreSQL để triển khai:

Tiếp theo, chúng ta sẽ xác định các nút nào sẽ sử dụng để triển khai PostgreSQL :
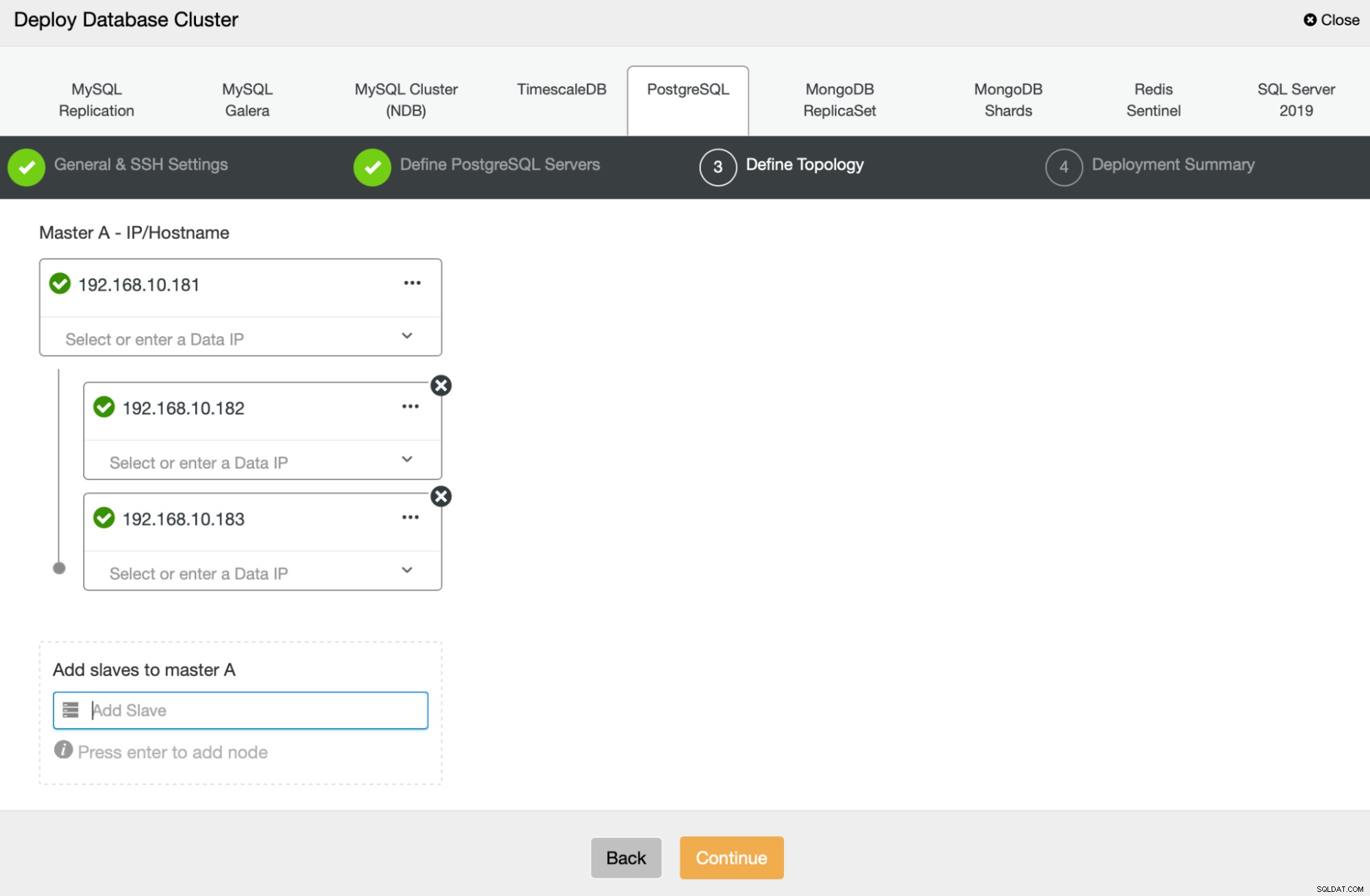
Cuối cùng, chúng ta có thể xác định xem các nút nên sử dụng sao chép không đồng bộ hay đồng bộ. Sự khác biệt chính giữa hai điều này là sao chép đồng bộ đảm bảo rằng mọi giao dịch được thực hiện trên nút chính sẽ luôn được sao chép trên các bản sao. Tuy nhiên, nhân rộng đồng bộ cũng làm chậm cam kết. Chúng tôi khuyên bạn nên bật tính năng sao chép đồng bộ để có độ bền tốt nhất, nhưng bạn nên xác minh sau nếu hiệu suất có thể chấp nhận được.

Sau khi chúng tôi nhấp vào "Triển khai", công việc triển khai sẽ bắt đầu. Chúng tôi có thể theo dõi tiến trình của nó trong tab Hoạt động trong giao diện người dùng ClusterControl. Cuối cùng chúng ta sẽ thấy rằng công việc đã hoàn thành và cụm đã được triển khai thành công.

Triển khai các phiên bản HAProxy bằng cách đi tới Quản lý -> Bộ cân bằng tải. Chọn HAProxy làm bộ cân bằng tải và điền vào biểu mẫu. Sự lựa chọn quan trọng nhất là nơi bạn muốn triển khai HAProxy. Chúng tôi đã sử dụng một nút cơ sở dữ liệu trong trường hợp này, nhưng trong môi trường sản xuất, bạn rất có thể muốn tách bộ cân bằng tải khỏi các phiên bản cơ sở dữ liệu. Tiếp theo, chọn các nút PostgreSQL để đưa vào HAProxy. Chúng tôi muốn tất cả chúng.

Bây giờ việc triển khai HAProxy sẽ bắt đầu. Chúng tôi muốn lặp lại nó ít nhất một lần nữa để tạo hai phiên bản HAProxy để dự phòng. Trong lần triển khai này, chúng tôi quyết định sử dụng ba bộ cân bằng tải HAProxy. Dưới đây là ảnh chụp màn hình cài đặt trong khi định cấu hình triển khai HAProxy thứ hai:
Khi tất cả các phiên bản HAProxy của chúng tôi đều hoạt động, chúng tôi có thể triển khai Keepalived . Ý tưởng ở đây là Keepalived sẽ được kết hợp với HAProxy và giám sát quy trình của HAProxy. Một trong những trường hợp HAProxy đang hoạt động sẽ được gán IP ảo. VIP này sẽ được ứng dụng sử dụng để kết nối với cơ sở dữ liệu. Keepalived sẽ phát hiện nếu HAProxy đó không khả dụng và chuyển sang phiên bản HAProxy khả dụng khác.
Trình hướng dẫn triển khai yêu cầu chúng tôi chuyển các phiên bản HAProxy mà chúng tôi muốn Keepalived giám sát. Chúng tôi cũng cần chuyển địa chỉ IP và giao diện mạng cho VIP.

Bước cuối cùng và cuối cùng sẽ là tạo cơ sở dữ liệu cho TeamCity:

Với điều này, chúng tôi đã kết thúc việc triển khai cụm PostgreSQL rất sẵn có.
Triển khai TeamCity dưới dạng nhiều nút
Bước tiếp theo là triển khai TeamCity trong môi trường nhiều nút. Chúng tôi sẽ sử dụng ba nút TeamCity. Đầu tiên, chúng ta phải cài đặt Java JRE và JDK phù hợp với yêu cầu của TeamCity.
apt install default-jre default-jdkBây giờ, trên tất cả các nút, chúng ta phải tải xuống TeamCity. Chúng tôi sẽ cài đặt trong một thư mục cục bộ, không dùng chung.
example@sqldat.com:~# cd /var/lib/teamcity-local/
example@sqldat.com:/var/lib/teamcity-local# wget https://download.jetbrains.com/teamcity/TeamCity-2021.2.3.tar.gzSau đó, chúng ta có thể khởi động TeamCity trên một trong các nút:
example@sqldat.com:~# /var/lib/teamcity-local/TeamCity/bin/runAll.sh start
Spawning TeamCity restarter in separate process
TeamCity restarter running with PID 83162
Starting TeamCity build agent...
Java executable is found: '/usr/lib/jvm/default-java/bin/java'
Starting TeamCity Build Agent Launcher...
Agent home directory is /var/lib/teamcity-local/TeamCity/buildAgent
Agent Launcher Java runtime version is 11
Lock file: /var/lib/teamcity-local/TeamCity/buildAgent/logs/buildAgent.properties.lock
Using no lock
Done [83731], see log at /var/lib/teamcity-local/TeamCity/buildAgent/logs/teamcity-agent.logKhi TeamCity đã khởi động, chúng tôi có thể truy cập vào giao diện người dùng và bắt đầu triển khai. Ban đầu, chúng ta phải vượt qua vị trí thư mục dữ liệu. Đây là tập chia sẻ mà chúng tôi đã tạo trên GlusterFS.

Tiếp theo, chọn cơ sở dữ liệu. Chúng tôi sẽ sử dụng một cụm PostgreSQL mà chúng tôi đã tạo.

Tải xuống và cài đặt trình điều khiển JDBC:

Tiếp theo, điền chi tiết truy cập. Chúng tôi sẽ sử dụng IP ảo do Keepalived cung cấp. Xin lưu ý rằng chúng tôi sử dụng cổng 5433. Đây là cổng được sử dụng cho phần phụ trợ đọc / ghi của HAProxy; nó sẽ luôn hướng tới nút chính đang hoạt động. Tiếp theo, chọn một người dùng và cơ sở dữ liệu để sử dụng với TeamCity.

Sau khi hoàn tất, TeamCity sẽ bắt đầu khởi tạo cấu trúc cơ sở dữ liệu.

Đồng ý với Thỏa thuận cấp phép:

Cuối cùng, tạo người dùng cho TeamCity:

Vậy là xong! Bây giờ chúng ta sẽ có thể thấy GUI của TeamCity:

Bây giờ, chúng ta phải thiết lập TeamCity ở chế độ nhiều nút. Đầu tiên, chúng ta phải chỉnh sửa các tập lệnh khởi động trên tất cả các nút:
example@sqldat.com:~# vim /var/lib/teamcity-local/TeamCity/bin/runAll.shChúng ta phải đảm bảo rằng hai biến sau được xuất. Vui lòng xác minh rằng bạn sử dụng tên máy chủ, IP thích hợp và các thư mục chính xác cho bộ nhớ cục bộ và bộ nhớ dùng chung:
export TEAMCITY_SERVER_OPTS="-Dteamcity.server.nodeId=node1 -Dteamcity.server.rootURL=https://192.168.10.221 -Dteamcity.data.path=/teamcity-storage -Dteamcity.node.data.path=/var/lib/teamcity-local"
export TEAMCITY_DATA_PATH="/teamcity-storage"Sau khi hoàn tất, bạn có thể bắt đầu các nút còn lại:
example@sqldat.com:~# /var/lib/teamcity-local/TeamCity/bin/runAll.sh startBạn sẽ thấy kết quả sau trong Quản trị -> Cấu hình nút:Một nút chính và hai nút dự phòng.

Xin lưu ý rằng chuyển đổi dự phòng trong TeamCity không được tự động hóa. Nếu nút chính ngừng hoạt động, bạn nên kết nối với một trong các nút phụ. Để thực hiện việc này, hãy chuyển đến "Cấu hình nút" và thăng cấp nó lên nút "Chính". Từ màn hình đăng nhập, bạn sẽ thấy một dấu hiệu rõ ràng rằng đây là một nút phụ:

Trong "Cấu hình nút", bạn sẽ thấy rằng một nút có rớt khỏi cụm:

Bạn sẽ nhận được một thông báo cho biết rằng bạn không thể ghi vào nút này. Đừng lo; ghi cần thiết để quảng bá nút này lên trạng thái "chính" sẽ hoạt động tốt:

Nhấp vào "Bật" và chúng tôi đã quảng bá thành công nút TimeCity phụ:

Khi nút1 khả dụng và TeamCity được khởi động lại trên nút đó, chúng tôi sẽ xem nó tham gia lại vào cụm:

Nếu bạn muốn cải thiện hiệu suất hơn nữa, bạn có thể triển khai HAProxy + Keepalived trước giao diện người dùng TeamCity để cung cấp một điểm vào duy nhất cho GUI. Bạn có thể tìm thấy chi tiết về cách định cấu hình HAProxy cho TeamCity trong tài liệu.
Kết thúc
Như bạn có thể thấy, việc triển khai TeamCity để có tính khả dụng cao không khó lắm - hầu hết nó đã được đề cập kỹ lưỡng trong tài liệu. Nếu bạn đang tìm cách tự động hóa một số việc này và thêm phần phụ trợ cơ sở dữ liệu có sẵn cao, hãy xem xét đánh giá ClusterControl miễn phí trong 30 ngày. ClusterControl có thể nhanh chóng triển khai và giám sát chương trình phụ trợ, cung cấp tính năng tự động chuyển đổi dự phòng, khôi phục, giám sát, quản lý sao lưu và hơn thế nữa.
Để biết thêm mẹo về các công cụ phát triển phần mềm và các phương pháp hay nhất, hãy xem cách hỗ trợ nhóm DevOps của bạn với nhu cầu cơ sở dữ liệu của họ.
Để nhận được tin tức mới nhất và các phương pháp hay nhất để quản lý cơ sở hạ tầng cơ sở dữ liệu dựa trên nguồn mở của bạn, đừng quên theo dõi chúng tôi trên Twitter hoặc LinkedIn và đăng ký nhận bản tin của chúng tôi. Hẹn gặp lại!



