Trong bài viết này, chúng tôi sẽ thảo luận về các lỗi điển hình mà các nhà phát triển newbie có thể gặp phải khi thiết kế mã T-SQL. Ngoài ra, chúng tôi sẽ xem xét các phương pháp hay nhất và một số mẹo hữu ích có thể giúp bạn khi làm việc với SQL Server, cũng như các giải pháp thay thế để cải thiện hiệu suất.
Nội dung:
1. Các kiểu dữ liệu
2. *
3. Bí danh
4. Thứ tự cột
5. KHÔNG VÀO và KHÔNG ĐỦ
6. Định dạng ngày tháng
7. Bộ lọc ngày
8. Tính toán
9. Chuyển đổi ẩn
10. Chỉ số LIKE &bị kìm hãm
11. Unicode và ANSI
12. THUỘC TÍNH
13. BINARY COLLATE
14. Kiểu mã
15. [var] char
16. Độ dài dữ liệu
17. ISNULL và THAN
18. Toán học
19. UNION vs UNION ALL
20. Đọc lại
21. Truy vấn con
22. TRƯỜNG HỢP KHI NÀO
23. Chức năng vô hướng
24. QUAN ĐIỂM
25. CURSORs
26. STRING_CONCAT
27. SQL Injection
Loại dữ liệu
Vấn đề chính mà chúng tôi gặp phải khi làm việc với SQL Server là lựa chọn kiểu dữ liệu không chính xác.
Giả sử chúng ta có hai bảng giống nhau:
DECLARE @ Employee1 BẢNG (KHÓA CHÍNH CỦA NHÂN VIÊN BIGINT, BIẾN SỐ IsMale (3), BIẾN Ngày Sinh (20)) CHÈN VÀO @ NHÂN VIÊN1VALUES (123, 'YES', '2012-09-01') INT PRIMARY KEY, IsMale BIT, Ngày sinh ngày sinh) CHÈN VÀO @ NV2VALUES (123, 1, '2012-09-01')
Hãy thực hiện một truy vấn để kiểm tra sự khác biệt là gì:
DECLARE @BirthDate DATE ='2012-09-01'SELECT * TỪ @ Nhân viên1 WHERE Ngày sinh =@BirthDateSELECT * FROM @ Nhân viên2 WHERE Ngày sinh =@ Ngày sinh
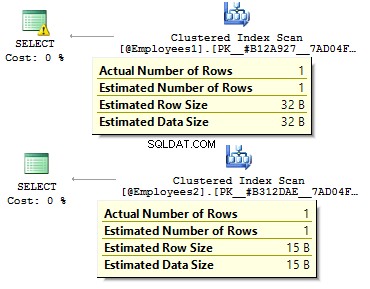
Trong trường hợp đầu tiên, các kiểu dữ liệu dư thừa hơn mức có thể. Tại sao chúng ta nên lưu trữ một giá trị bit dưới dạng CÓ / KHÔNG hàng ngang? Tại sao chúng ta nên lưu trữ một ngày dưới dạng một hàng? Tại sao chúng ta nên sử dụng BIGINT cho nhân viên trong bảng, thay vì INT ?
Nó dẫn đến những hạn chế sau:
- Các bảng có thể chiếm nhiều dung lượng trên đĩa;
- Chúng tôi cần đọc nhiều trang hơn và đưa nhiều dữ liệu hơn vào BufferPool để xử lý dữ liệu.
- Hiệu suất kém.
*
Tôi đã gặp phải tình huống khi các nhà phát triển truy xuất tất cả dữ liệu từ bảng và sau đó ở phía máy khách, hãy sử dụng DataReader để chỉ chọn các trường bắt buộc. Tôi không khuyên bạn nên sử dụng phương pháp này:
SỬ DỤNG AdventureWorks2014 THỜI GIAN THỐNG KÊ CỦA GOSET, IO ONSELECT * FROM Person.PersonSELECT BusinessEntityID, FirstName, MiddleName, LastNameFROM Person.PersonSET STATISTICS TIME, IO OFF
Sẽ có sự khác biệt đáng kể về thời gian thực hiện truy vấn. Ngoài ra, chỉ mục bao trùm có thể làm giảm số lần đọc logic.
Bảng 'Người'. Số lần quét 1, số lần đọc logic 3819, số lần đọc vật lý 3, ... Thời gian thực thi SQL Server:thời gian CPU =31 ms, thời gian trôi qua =1235 ms. Bảng 'Người'. Số lần quét 1, lần đọc logic 109, lần đọc vật lý 1, ... Thời gian thực thi máy chủ SQL:thời gian CPU =0 ms, thời gian trôi qua =227 ms.
Bí danh
Hãy tạo một bảng:
SỬ DỤNG AdventureWorks2014GOIF OBJECT_ID ('Sales.UserCurrency') KHÔNG ĐẦY ĐỦ BẢNG DROP Sales.UserCurrencyGOCREATE TABLE Sales.UserCurrency (CurrencyCode NCHAR (3) PRIMARY KEY) CHÈN VÀO Sales.UserCurrencyVALUES ('USD')
Giả sử chúng ta có một truy vấn trả về số lượng hàng giống hệt nhau trong cả hai bảng:
CHỌN COUNT_BIG (*) TỪ Sales.CurrencyWHERE CurrencyCode IN (CHỌN Mã tiền tệ TỪ Sales.UserCurrency)
Mọi thứ sẽ hoạt động như mong đợi, cho đến khi ai đó đổi tên một cột trong Sales.UserCurrency bảng:
EXEC sys.sp_rename 'Sales.UserCurrency.CurrencyCode', 'Mã', 'COLUMN'
Tiếp theo, chúng tôi sẽ thực hiện một truy vấn và thấy rằng chúng tôi nhận được tất cả các hàng trong Tiền tệ bán hàng bảng, thay vì 1 hàng. Khi xây dựng kế hoạch thực thi, ở giai đoạn liên kết, SQL Server sẽ kiểm tra các cột của Sales.UserCurrency, nó sẽ không tìm thấy CurrencyCode ở đó và quyết định rằng cột này thuộc về Đơn vị tiền tệ bán hàng bàn. Sau đó, trình tối ưu hóa sẽ loại bỏ CurrencyCode =CurrencyCode điều kiện.
Vì vậy, tôi khuyên bạn nên sử dụng bí danh:
CHỌN COUNT_BIG (*) TỪ Sales.Currency cWHERE c.CurrencyCode IN (CHỌN u.CurrencyCode FROM Sales.UserCurrency u)
Thứ tự cột
Giả sử chúng ta có một bảng:
IF OBJECT_ID ('dbo.DatePeriod') KHÔNG PHẢI LÀ BẢNG DROP NULL dbo.DatePeriodGOCREATE TABLE dbo.DatePeriod (Ngày bắt đầu, NGÀY kết thúc)
Chúng tôi luôn chèn dữ liệu vào đó dựa trên thông tin về thứ tự cột.
CHÈN VÀO dbo.DatePeriodSELECT '2015-01-01', '2015-01-31'
Giả sử ai đó thay đổi thứ tự của các cột:
TẠO BẢNG dbo.DatePeriod (Ngày kết thúc, NGÀY bắt đầu)
Dữ liệu sẽ được chèn theo một thứ tự khác. Trong trường hợp này, bạn nên chỉ định rõ ràng các cột trong câu lệnh INSERT:
CHÈN VÀO dbo.DatePeriod (Ngày bắt đầu, Ngày kết thúc) CHỌN '2015-01-01', '2015-01-31'
Đây là một ví dụ khác:
CHỌN ĐẦU (1) * TỪ dbo.DatePeriodORDER BẰNG 2 MÔ TẢ
Chúng ta sẽ sắp xếp dữ liệu trên cột nào? Nó sẽ phụ thuộc vào thứ tự cột trong bảng. Trong trường hợp một người thay đổi thứ tự, chúng tôi sẽ nhận được kết quả sai.
KHÔNG VÀO so với KHÔNG ĐỦ
Hãy nói về KHÔNG VÀO tuyên bố.
Ví dụ, bạn cần viết một số truy vấn:trả về các bản ghi từ bảng đầu tiên, không tồn tại trong bảng thứ hai và câu thị thực. Thông thường, các nhà phát triển cơ sở sử dụng IN và KHÔNG VÀO :
DECLARE @ t1 TABLE (t1 INT, UNIQUE CLUSTERED (t1)) INSERT INTO @ t1 VALUES (1), (2) DECLARE @ t2 TABLE (t2 INT, UNIQUE CLUSTERED (t2)) INSERT INTO @ t2 VALUES (1 ) CHỌN * TỪ @ t1WHERE t1 KHÔNG VÀO (CHỌN t2 TỪ @ t2) CHỌN * TỪ @ t1WHERE t1 TRONG (CHỌN t2 TỪ @ t2)
Truy vấn đầu tiên trả về 2, truy vấn thứ hai - 1. Ngoài ra, chúng tôi sẽ thêm một giá trị khác vào bảng thứ hai - NULL :
CHÈN VÀO CÁC GIÁ TRỊ @ t2 (1), (NULL)
Khi thực hiện truy vấn với NOT IN , chúng tôi sẽ không nhận được bất kỳ kết quả. Tại sao IN hoạt động và NOT In thì không? Nguyên nhân là do SQL Server sử dụng T RUE , FALSE và UNKNOWN logic khi so sánh dữ liệu.
Khi thực thi một truy vấn, SQL Server diễn giải điều kiện IN theo cách sau:
a IN (1, NULL) ==a =1 OR a =NULL
KHÔNG VÀO :
a NOT IN (1, NULL) ==a <> 1 AND a <> NULL
Khi so sánh bất kỳ giá trị nào với NULL, SQL Server trả về UNKNOWN. Hoặc 1 =NULL hoặc NULL =NULL - cả hai đều dẫn đến KHÔNG BIẾT. Theo như những gì chúng ta có AND trong biểu thức, cả hai bên đều trả về UNKNOWN.
Tôi muốn chỉ ra rằng trường hợp này không phải là hiếm. Ví dụ:bạn đánh dấu một cột là KHÔNG ĐẦY ĐỦ. Sau một thời gian, một nhà phát triển khác quyết định cấp phép NULL cho cột đó. Điều này có thể dẫn đến tình huống, khi báo cáo khách hàng ngừng hoạt động sau khi bất kỳ giá trị NULL nào được chèn vào bảng.
Trong trường hợp này, tôi khuyên bạn nên loại trừ các giá trị NULL:
CHỌN * TỪ @ t1WHERE t1 NOT IN (CHỌN t2 TỪ @ t2 TRONG ĐÓ t2 KHÔNG ĐẦY ĐỦ)
Ngoài ra, có thể sử dụng EXCEPT :
CHỌN * TỪ @ t1EXCEPTSELECT * TỪ @ t2
Ngoài ra, bạn có thể sử dụng KHÔNG TỒN TẠI :
CHỌN * TỪ @ t1 KHÔNG TỒN TẠI (CHỌN 1 TỪ @ t2 TRONG ĐÓ t1 =t2)
Lựa chọn nào thích hợp hơn? Tùy chọn thứ hai với KHÔNG TỒN TẠI dường như hiệu quả nhất vì nó tạo ra vị từ đẩy xuống tối ưu hơn toán tử để truy cập dữ liệu từ bảng thứ hai.
Trên thực tế, các giá trị NULL có thể trả về một kết quả không mong muốn.
Hãy xem xét nó trên ví dụ cụ thể sau:
SỬ DỤNG AdventureWorks2014GOSELECT COUNT_BIG (*) FROM Production.ProductSELECT COUNT_BIG (*) FROM Production.ProductWHERE Color ='Grey'SELECT COUNT_BIG (*) FROM Production.ProductWHERE Color <>' Grey '
Như bạn có thể thấy, bạn không nhận được kết quả mong đợi vì lý do giá trị NULL có các toán tử so sánh riêng biệt:
CHỌN COUNT_BIG (*) TỪ Sản xuất. Sản phẩm Ở ĐÂY Màu KHÔNG ĐỦ. COUNT_BIG (*) TỪ Sản xuất. Sản phẩm KHÔNG ĐỦ Màu
Đây là một ví dụ khác với CHECK ràng buộc:
IF OBJECT_ID ('tempdb.dbo. # temp') KHÔNG PHẢI LÀ BẢNG DROP NULL #tempGOCREATE TABLE #temp (BIẾN ĐỔI Màu (15) --NULL, CONSTRAINT CK CHECK (Màu IN ('Đen', 'Trắng')) ))
Chúng tôi tạo một bảng với quyền chỉ chèn các màu trắng và đen:
CHÈN VÀO #temp VALUES ('Đen') (1 (các) hàng bị ảnh hưởng)
Mọi thứ hoạt động như mong đợi.
INSERT INTO #temp VALUES ('Màu đỏ') Câu lệnh INSERT xung đột với ràng buộc CHECK ... Câu lệnh đã bị chấm dứt.
Bây giờ, hãy thêm NULL:
CHÈN VÀO #temp VALUES (NULL) (1 hàng bị ảnh hưởng)
Tại sao ràng buộc CHECK lại chuyển giá trị NULL? Chà, lý do là có đủ KHÔNG SAI điều kiện để lập biên bản. Cách giải quyết là xác định rõ ràng một cột là KHÔNG ĐẦY ĐỦ hoặc sử dụng NULL trong ràng buộc.
Định dạng ngày
Thông thường, bạn có thể gặp khó khăn với các loại dữ liệu.
Ví dụ, bạn cần lấy ngày hiện tại. Để làm điều này, bạn có thể sử dụng hàm GETDATE:
CHỌN GETDATE ()
Sau đó, chỉ cần sao chép kết quả trả về trong một truy vấn bắt buộc và xóa thời gian:
CHỌN * TỪ sys.objectsWHERE create_date <'2016-11-14'
Có đúng không?
Ngày được chỉ định bởi một hằng số chuỗi:
SET LANGUAGE EnglishSET DATEFORMAT DMYDECLARE @ d1 DATETIME ='05 / 12/2016 ', @ d2 DATETIME =' 2016/12/05 ', @ d3 DATETIME =' 2016-12-05 ', @ d4 DATETIME ='05 -dec-2016'SELECT @ d1, @ d2, @ d3, @ d4
Tất cả các giá trị đều có cách diễn giải một giá trị:
----------- ----------- ----------- ----------- 2016-12 -05 2016-05-12 2016-05-12 2016-12-05
Nó sẽ không gây ra bất kỳ sự cố nào cho đến khi truy vấn với logic nghiệp vụ này được thực thi trên một máy chủ khác, nơi cài đặt có thể khác:
ĐẶT DATEFORMAT MDYDECLARE @ d1 DATETIME ='05 / 12/2016 ', @ d2 DATETIME =' 2016/12/05 ', @ d3 DATETIME =' 2016-12-05 ', @ d4 DATETIME ='05 -dec -2016'SELECT @ d1, @ d2, @ d3, @ d4
Mặc dù vậy, các tùy chọn này có thể dẫn đến việc giải thích ngày tháng không chính xác:
----------- ----------- ----------- ----------- 2016-05 -12 2016-12-05 2016-12-05 2016-12-05
Hơn nữa, mã này có thể dẫn đến cả lỗi tiềm ẩn và hiển thị.
Hãy xem xét ví dụ sau. Chúng ta cần chèn dữ liệu vào một bảng thử nghiệm. Trên máy chủ thử nghiệm, mọi thứ hoạt động hoàn hảo:
DECLARE @t TABLE (a DATETIME) INSERT INTO @t VALUES ('05 / 13/2016 ')
Tuy nhiên, ở phía máy khách, truy vấn này sẽ có vấn đề do cài đặt máy chủ của chúng tôi khác nhau:
DECLARE @t TABLE (a DATETIME) ĐẶT DATEFORMAT DMYINSERT THÀNH @t VALUES ('05 / 13/2016 ') Msg 242, Mức 16, Trạng thái 3, Dòng 28 Việc chuyển đổi kiểu dữ liệu varchar thành kiểu dữ liệu datetime dẫn đến giá trị nằm ngoài phạm vi.
Vì vậy, chúng ta nên sử dụng định dạng nào để khai báo các hằng ngày? Để trả lời câu hỏi này, hãy thực hiện truy vấn sau:
SET DATEFORMAT YMDSET LANGUAGE EnglishDECLARE @ d1 DATETIME ='2016/01/12', @ d2 DATETIME ='2016-01-12', @ d3 DATETIME ='12 -jan-2016 ', @ d4 DATETIME =' 20160112 'SELECT @ d1, @ d2, @ d3, @ d4GOSET LANGUAGE DeutschDECLARE @ d1 DATETIME =' 2016/01/12 ', @ d2 DATETIME =' 2016-01-12 ', @ d3 DATETIME ='12 -jan-2016' , @ d4 DATETIME ='20160112'SELECT @ d1, @ d2, @ d3, @ d4
Việc giải thích các hằng số có thể khác nhau tùy thuộc vào ngôn ngữ được cài đặt:
----------- ----------- ----------- ----------- 2016-01 -12 2016-01-12 2016-01-12 2016-01-12 ------------- ---------------- ----------- 2016-12-01 2016-12-01 2016-01-12 2016-01-12
Vì vậy, tốt hơn là sử dụng hai tùy chọn cuối cùng. Ngoài ra, tôi muốn thêm điều đó để chỉ định rõ ràng ngày không phải là một ý kiến hay:
SET LANGUAGE FrenchDECLARE @d DATETIME ='12 -jan-2016'Msg 241, Tầng 16, Trạng thái 1, Dòng 29Échec de la convert de la date et / ou de l'heure à partir d'une chaîne de caractères.
Do đó, nếu bạn muốn các hằng số có ngày được diễn giải chính xác, thì bạn cần chỉ định chúng ở định dạng sau YYYYMMDD.
Ngoài ra, tôi muốn thu hút sự chú ý của bạn đến hành vi của một số loại dữ liệu:
SET LANGUAGE EnglishSET DATEFORMAT YMDDECLARE @ d1 DATE ='2016-01-12', @ d2 DATETIME ='2016-01-12'SELECT @ d1, @ d2GOSET LANGUAGE DeutschSET DATEFORMAT DMYDECLARE @ d1 DATE =' 2016-01- 12 ', @ d2 DATETIME =' 2016-01-12'SELECT @ d1, @ d2
Không giống như DATETIME, DATE loại được diễn giải chính xác với các cài đặt khác nhau trên máy chủ:
---------- ---------- 2016-01-12 2016-01-12 ---------------- --- 2016-01-12 2016-12-01
Bộ lọc ngày
Để tiếp tục, chúng tôi sẽ xem xét cách lọc dữ liệu hiệu quả. Hãy bắt đầu từ chúng DATETIME / DATE:
SỬ DỤNG AdventureWorks2014GOUPDATE TOP (1) dbo.DatabaseLogSET PostTime ='20140716 12:12:12'
Bây giờ, chúng ta sẽ cố gắng tìm xem có bao nhiêu hàng mà truy vấn trả về cho một ngày cụ thể:
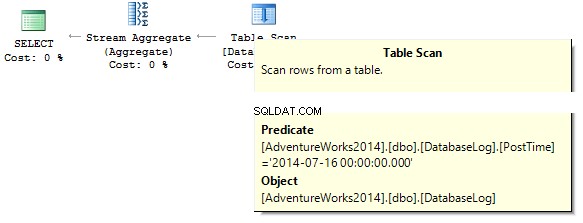
CHỌN COUNT_BIG (*) TỪ dbo.DatabaseLogWHERE PostTime ='20140716'
Truy vấn sẽ trả về 0. Khi xây dựng một kế hoạch thực thi, máy chủ SQL đang cố gắng truyền một chuỗi hằng số thành kiểu dữ liệu của cột mà chúng ta cần lọc ra:
Tạo chỉ mục:
TẠO CHỈ SỐ KHÔNG ĐƯỢC ĐIỀU CHỈNH IX_PostTime TRÊN dbo.DatabaseLog (PostTime)
Có các tùy chọn chính xác và không chính xác để xuất dữ liệu. Ví dụ:bạn cần xóa cột thời gian:
SELECT COUNT_BIG (*) FROM dbo.DatabaseLogWHERE CONVERT (CHAR (8), PostTime, 112) ='20140716'SELECT COUNT_BIG (*) FROM dbo.DatabaseLogWHERE CAST (PostTime AS DATE) =' 20140716 '
Hoặc chúng ta cần chỉ định một phạm vi:
SELECT COUNT_BIG (*) FROM dbo.DatabaseLogWHERE PostTime GIỮA '20140716' VÀ '20140716 23:59:59.997'SELECT COUNT_BIG (*) FROM dbo.DatabaseLogWHERE PostTime> =' 20140716 'VÀ PostTime <' 20140717 '
Có tính đến tối ưu hóa, tôi có thể nói rằng hai truy vấn này là những truy vấn đúng nhất. Vấn đề là tất cả các chuyển đổi và tính toán của các cột chỉ mục đang được lọc ra có thể làm giảm đáng kể hiệu suất và tăng thời gian đọc logic:
Bảng 'DatabaseLog'. Quét đếm 1, đọc logic 7, ... Bảng 'DatabaseLog'. Quét đếm 1, đọc logic 2, ...
PostTime trường không được bao gồm trong chỉ mục trước đây và chúng tôi không thể thấy bất kỳ hiệu quả nào trong việc sử dụng phương pháp lọc đúng này. Một điều nữa là khi chúng ta cần xuất dữ liệu trong một tháng:
SELECT COUNT_BIG (*) FROM dbo.DatabaseLogWHERE CONVERT (CHAR (8), PostTime, 112) LIKE '201407%' SELECT COUNT_BIG (*) FROM dbo.DatabaseLogWHERE DATEPART (YEAR, PostTime) =2014 AND DATEPART (MONTH, PostTime) =7SELECT COUNT_BIG (*) FROM dbo.DatabaseLogWHERE YEAR (PostTime) =2014 AND MONTH (PostTime) =7SELECT COUNT_BIG (*) FROM dbo.DatabaseLogWHERE EOMONTH (PostTime) ='20140731'SELECT COUNT_BIG (*) FROM dbo.DatabaseLogWHERE PostTime> ='20140701' VÀ PostTime <'20140801'
Một lần nữa, tùy chọn thứ hai thích hợp hơn:
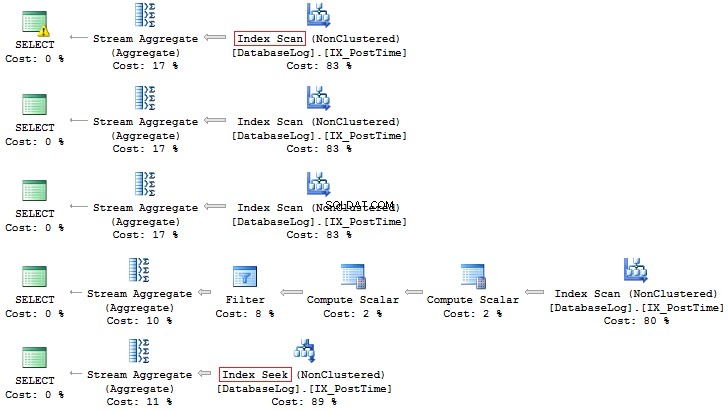
Ngoài ra, bạn luôn có thể tạo chỉ mục dựa trên trường được tính toán:
IF COL_LENGTH ('dbo.DatabaseLog', 'MonthLastDay') KHÔNG PHẢI LÀ BẢNG ALTER NULL dbo.DatabaseLog DROP COLUMN monthLastDayGOALTER TABLE dbo.DatabaseLog ADD MonthLastDay AS EOMONTH (PostTime) --PERSISTEDGOCREATE
So với truy vấn trước đó, sự khác biệt về số đọc logic có thể đáng kể (nếu các bảng lớn đang được đề cập đến):
SET STATISTICS IO ONSELECT COUNT_BIG (*) FROM dbo.DatabaseLogWHERE PostTime> ='20140701' AND PostTime <'20140801'SELECT COUNT_BIG (*) FROM dbo.DatabaseLogWHERE MonthLastDay =' 20140731'SET THỐNG KÊ IO OFFTable 'Cơ sở dữ liệu'SET' Cơ sở dữ liệu. Quét đếm 1, đọc logic 7, ... Bảng 'DatabaseLog'. Quét đếm 1, đọc logic 3, ...
Tính toán
Như đã được thảo luận, bất kỳ phép tính nào trên các cột chỉ mục làm giảm hiệu suất và tăng thời gian đọc logic:
use AdventureWorks2014GOSET STATISTICS IO ONSELECT BusinessEntityIDFROM Person.PersonWHERE BusinessEntityID * 2 =10000SELECT BusinessEntityIDFROM Person.PersonWHERE BusinessEntityID =2500 * 2SELECT BusinessEntityIDFROM Person.PersonWHERE BusinessEntityID =5000Table 'Person'. Quét đếm 1, đọc logic 67, ... Bảng 'Người'. Quét đếm 0, đọc logic 3, ...
Nếu chúng ta xem xét các kế hoạch thực thi, thì trong kế hoạch đầu tiên, SQL Server thực thi IndexScan :
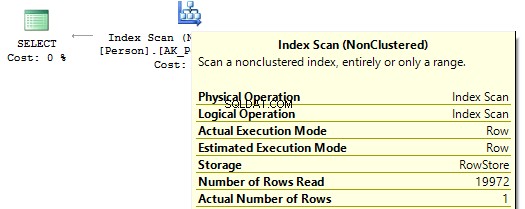
Sau đó, khi không có tính toán nào trên các cột chỉ mục, chúng ta sẽ thấy IndexSeek :

Chuyển đổi ẩn
Hãy xem xét hai truy vấn lọc theo cùng một giá trị:
SỬ DỤNG AdventureWorks2014GOSELECT BusinessEntityID, NationalIDNumberFROM HumanResources.ErantyeeWHERE NationalIDNumber =30845SELECT BusinessEntityID, NationalIDNumberFROM HumanResources.EpriseeWHERE NationalIDNumber ='30845'
Các kế hoạch thực hiện cung cấp các thông tin sau:
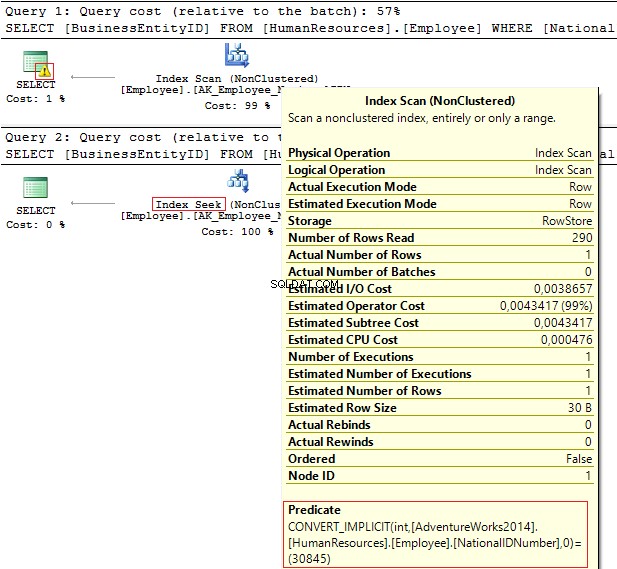
- Cảnh báo và IndexScan về kế hoạch đầu tiên
- IndexSeek - vào cái thứ hai.
Bảng 'Nhân viên'. Quét đếm 1, đọc logic 4, ... Bảng 'Nhân viên'. Quét đếm 0, đọc logic 2, ...
NationalIDNumber cột có NVARCHAR (15) loại dữ liệu. Hằng số chúng tôi sử dụng để lọc dữ liệu được đặt là INT dẫn chúng ta đến một chuyển đổi kiểu dữ liệu ngầm định. Đổi lại, nó có thể làm giảm hiệu suất. Bạn có thể giám sát nó khi ai đó sửa đổi kiểu dữ liệu trong cột, tuy nhiên, các truy vấn không bị thay đổi.
Điều quan trọng là phải hiểu rằng một chuyển đổi kiểu dữ liệu ngầm có thể dẫn đến lỗi trong thời gian chạy. Ví dụ:trước khi trường Mã bưu chính là số, hóa ra mã bưu chính có thể chứa các chữ cái. Do đó, kiểu dữ liệu đã được cập nhật. Tuy nhiên, nếu chúng tôi chèn mã bưu điện theo bảng chữ cái, thì truy vấn cũ sẽ không hoạt động nữa:
SELECT AddressIDFROM Person. [Address] WHERE PostalCode =92700SELECT AddressIDFROM Person. [Address] WHERE PostalCode ='92700'Msg 245, Level 16, State 1, Line 16Conversion không thành công khi chuyển đổi giá trị nvarchar' K4B 1S2 'thành kiểu dữ liệu int.
Một ví dụ khác là khi bạn cần sử dụng EntityFramework trên dự án, theo mặc định diễn giải tất cả các trường hàng dưới dạng Unicode:
SELECT CustomerID, AccountNumberFROM Sales.CustomerWHERE AccountNumber =N'AW00000009'SELECT CustomerID, AccountNumberFROM Sales.CustomerWHERE AccountNumber ='AW00000009'
Do đó, các truy vấn không chính xác được tạo ra:

Để giải quyết vấn đề này, hãy đảm bảo rằng các loại dữ liệu khớp nhau.
Chỉ mục LIKE &Bị chặn
Trên thực tế, có một chỉ mục bao hàm không có nghĩa là bạn sẽ sử dụng nó một cách hiệu quả.
Hãy kiểm tra nó trên ví dụ cụ thể này. Giả sử chúng ta cần xuất tất cả các hàng bắt đầu bằng…
use AdventureWorks2014GOSET STATISTICS IO ONSELECT AddressLine1FROM Person. [Address] WHERE SUBSTRING (AddressLine1, 1, 3) ='100'SELECT AddressLine1FROM Person. [Address] WHERE LEFT (AddressLine1, 3) =' 100'SELECT AddressLine1FROM Person. [ Địa chỉ] WHERE CAST (AddressLine1 AS CHAR (3)) ='100'SELECT AddressLine1FROM Person. [Address] WHERE AddressLine1 LIKE' 100% '
Chúng tôi sẽ nhận được các bài đọc logic sau và kế hoạch thực hiện:
Bảng 'Địa chỉ'. Quét đếm 1, đọc logic 216, ... Bảng 'Địa chỉ'. Quét đếm 1, đọc logic 216, ... Bảng 'Địa chỉ'. Quét đếm 1, đọc logic 216, ... Bảng 'Địa chỉ'. Quét đếm 1, đọc logic 4, ...
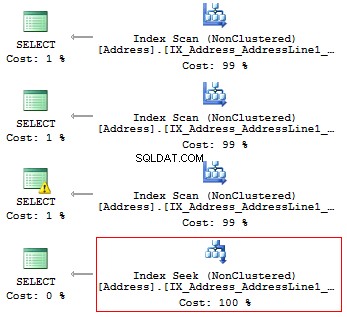
Do đó, nếu có một chỉ mục, nó không được chứa bất kỳ phép tính hoặc chuyển đổi kiểu, hàm, v.v.
Nhưng bạn phải làm gì nếu bạn cần tìm sự xuất hiện của một chuỗi con trong một chuỗi?
CHỌN Người AddressLine1FROM. [Address] WHERE AddressLine1 LIKE '% 100%' v
Chúng ta sẽ quay lại câu hỏi này sau.
Unicode so với ANSI
Điều quan trọng cần nhớ là có UNICODE và ANSI dây. Loại UNICODE bao gồm NVARCHAR / NCHAR (2 byte đến một ký hiệu). Để lưu trữ ANSI chuỗi, có thể sử dụng VARCHAR / CHAR (1 byte đến 1 ký hiệu). Ngoài ra còn có TEXT / NTEXT , nhưng tôi không khuyên bạn nên sử dụng chúng vì chúng có thể làm giảm hiệu suất.
Nếu bạn chỉ định một hằng số Unicode trong một truy vấn, thì cần phải đặt trước nó bằng ký hiệu N. Để kiểm tra nó, hãy thực hiện truy vấn sau:
CHỌN '文本 ANSI', N '文本 UNICODE' ------------ ?? ANSI 文本 UNICODE
Nếu N không đứng trước hằng số, thì SQL Server sẽ cố gắng tìm một ký hiệu phù hợp trong mã ANSI. Nếu không tìm thấy, nó sẽ hiển thị một dấu chấm hỏi.
COLLATE
Thông thường, khi được phỏng vấn vào vị trí Nhà phát triển DB Trung cấp / Cao cấp, người phỏng vấn thường hỏi câu hỏi sau:Liệu truy vấn này có trả về dữ liệu không?
DECLARE @a NCHAR (1) ='Ё', @b NCHAR (1) ='Ф'SELECT @a, @bWHERE @a =@b
Nó phụ thuộc. Thứ nhất, ký hiệu N không đứng trước hằng số chuỗi, do đó, nó sẽ được hiểu là ANSI. Thứ hai, phụ thuộc rất nhiều vào giá trị COLLATE hiện tại, là một tập hợp các quy tắc, khi chọn và so sánh dữ liệu chuỗi.
SỬ DỤNG [master] GOIF DB_ID ('test') KHÔNG BẮT ĐẦU ĐẦY ĐỦ kiểm tra CƠ SỞ DỮ LIỆU ĐẶT SINGLE_USER VỚI ROLLBACK NGAY LẬP TỨC DỮ LIỆU kiểm traENDGOCREATE DATABASE kiểm tra COLLATE Latin1_General_100_CI_ASGOUSE testGODECLARE (1) ) ='Ф'SELECT @a, @bWHERE @a =@b Câu lệnh COLLATE này sẽ trả về các dấu chấm hỏi vì các ký hiệu của chúng bằng nhau:
---- ----? ?
Nếu chúng tôi thay đổi câu lệnh COLLATE cho một câu lệnh khác:
Kiểm tra ALTER DATABASE COLLATE Cyrillic_General_100_CI_AS
Trong trường hợp này, truy vấn sẽ không trả về gì, vì các ký tự Kirin sẽ được diễn giải chính xác.
Do đó, nếu một hằng chuỗi chiếm UNICODE, thì cần phải đặt N trước một hằng chuỗi. Tuy nhiên, tôi không khuyên bạn nên đặt nó ở mọi nơi vì những lý do chúng ta đã thảo luận ở trên.
Một câu hỏi khác sẽ được hỏi trong cuộc phỏng vấn đề cập đến việc so sánh các hàng.
Hãy xem xét ví dụ sau:
DECLARE @a VARCHAR (10) ='TEXT', @b VARCHAR (10) ='text'SELECT IIF (@a =@b,' TRUE ',' FALSE ')
Các hàng này có bằng nhau không? Để kiểm tra điều này, chúng tôi cần chỉ định rõ ràng COLLATE:
DECLARE @a VARCHAR (10) ='TEXT', @b VARCHAR (10) ='text'SELECT IIF (@a COLLATE Latin1_General_CS_AS =@b COLLATE Latin1_General_CS_AS,' TRUE ',' FALSE ')
Vì có các COLLATE phân biệt chữ hoa chữ thường (CS) và không phân biệt chữ hoa chữ thường (CI) khi so sánh và chọn các hàng, chúng tôi không thể nói chắc chắn liệu chúng có bằng nhau hay không. Ngoài ra, có nhiều COLLATE khác nhau trên cả máy chủ thử nghiệm và phía máy khách.
Có một trường hợp khi COLLATE của cơ sở đích và tempdb không khớp.
Tạo cơ sở dữ liệu với COLLATE:
USE [master] GOIF DB_ID ('test') KHÔNG ĐẦY ĐỦ BÁO CÁO SAU kiểm tra CƠ SỞ DỮ LIỆU ĐẶT SINGLE_USER VỚI ROLLBACK NGAY LẬP TỨC DROP kiểm tra CƠ SỞ DỮ LIỆUENDGOCREATE DATABASE kiểm tra COLLATE Albanian_100_CS_ASGOUSE testGOCREATE TABLE INT (c) ') GOIF OBJECT_ID (' tempdb.dbo. # T1 ') KHÔNG PHẢI LÀ BẢNG DROP ĐẦY ĐỦ # t1IF OBJECT_ID (' tempdb.dbo. # T2 ') KHÔNG PHẢI LÀ BẢNG XẢ ĐẦY ĐỦ # t2IF OBJECT_ID (' tempdb.dbo. # T3 ') KHÔNG PHẢI LÀ NULL DROP TABLE # t3GOCREATE TABLE # t1 (c CHAR (1)) CHÈN VÀO GIÁ TRỊ # t1 ('a') TẠO BẢNG # t2 (c CHAR (1) COLLATE cơ sở dữ liệu_default) CHÈN VÀO GIÁ TRỊ # t2 ('a') CHỌN c =CAST ('a' AS CHAR (1)) VÀO # t3DECLARE @t BẢNG (c VARCHAR (100)) CHÈN VÀO GIÁ TRỊ @t ('a') CHỌN 'tempdb', DATABASEPROPERTYEX ('tempdb', 'collation ') UNION ALLSELECT' test ', DATABASEPROPERTYEX (DB_NAME (),' collation ') UNION ALLSELECT' t ', SQL_VARIANT_PROPERTY (c,' collation ') FROM tUNION ALLSELECT' # t1 ', SQL_VARIANT_PROPERTY (c,' collation ') FROM # t1UNION ALLSELECT '# t2', SQL_VARIANT_PROPERTY (c, 'đối chiếu') FROM # t2UNION ALLSELECT '# t3', SQL_VARIANT_PROPERTY (c, 'collation') FROM # t3UNION ALLSELECT '@t', SQL_VARIANT_PROPERTY (c, 'collation') FROM @t Khi tạo một bảng, nó kế thừa COLLATE từ cơ sở dữ liệu. Sự khác biệt duy nhất đối với bảng tạm thời đầu tiên, mà chúng tôi xác định cấu trúc một cách rõ ràng mà không có COLLATE, là nó kế thừa COLLATE từ tempdb cơ sở dữ liệu.
------ -------------------------- tempdb Cyrillic_General_CI_AStest Albanian_100_CS_ASt Albanian_100_CS_AS # t1 Cyrillic_General_CI_AS # t2 Albanian_100_CS_AS # t3 Albanian_100_CS_AS @ t Albanian_100_CS_AS
Tôi sẽ mô tả trường hợp các COLLATE không khớp trong ví dụ cụ thể với # t1.
Ví dụ:dữ liệu không được lọc ra một cách chính xác, vì COLLATE có thể không tính đến trường hợp:
CHỌN * TỪ # t1WHERE c ='A'
Ngoài ra, chúng tôi có thể có xung đột để kết nối các bảng với các COLLATE khác nhau:
CHỌN * TỪ # t1JOIN t ON [# t1] .c =t.c
Mọi thứ dường như hoạt động hoàn hảo trên máy chủ thử nghiệm, trong khi trên máy chủ khách, chúng tôi gặp lỗi:
Msg 468, Level 16, State 9, Line 93Không thể giải quyết xung đột đối chiếu giữa "Albanian_100_CS_AS" và "Cyrillic_General_CI_AS" trong phép toán ngang bằng.
Để giải quyết vấn đề này, chúng tôi phải thiết lập các bản hack ở khắp mọi nơi:
CHỌN * TỪ # t1JOIN t ON [# t1] .c =t.c COLLATE database_default
BINARY COLLATE
Bây giờ, chúng ta sẽ tìm hiểu cách sử dụng COLLATE vì lợi ích của bạn.
Hãy xem xét ví dụ về sự xuất hiện của một chuỗi con trong một chuỗi:
CHỌN AddressLine1FROM Person. [Address] WHERE AddressLine1 LIKE '% 100%'
Có thể tối ưu hóa truy vấn này và giảm thời gian thực thi.
Đầu tiên, chúng ta cần tạo một bảng lớn:
SỬ DỤNG [master] GOIF DB_ID ('test') KHÔNG BẮT ĐẦU ĐẦY ĐỦ kiểm tra CƠ SỞ DỮ LIỆU THIẾT LẬP SINGLE_USER VỚI ROLLBACK NGAY LẬP TỨC DROP kiểm tra CƠ SỞ DỮ LIỆUENDGOCREATE DATABASE kiểm tra COLLATE Latin1_General_100_CS_ASGOALTER DATABASE kiểm tra MODIFY FIestLE ') Kiểm tra CƠ SỞ DỮ LIỆU TẬP TIN SỬA ĐỔI (NAME =N'test_log ', SIZE =64MB) GOUSE testGOCREATE TABLE t (ansi VARCHAR (100) NOT NULL, unicod NVARCHAR (100) NOT NULL) GO; WITH E1 (N) AS (SELECT * FROM ( CÁC GIÁ TRỊ (1), (1), (1), (1), (1), (1), (1), (1), (1), (1)) t (N)), E2 (N ) AS (CHỌN 1 TỪ E1 a, E1 b), E4 (N) AS (CHỌN 1 TỪ E2 a, E2 b), E8 (N) AS (CHỌN 1 TỪ E4 a, E4 b) CHÈN VÀO tSELECT v, vFROM (SELECT TOP (50000) v =REPLACE (CAST (NEWID () AS VARCHAR (36)) + CAST (NEWID () AS VARCHAR (36)), '-', '') FROM E8) t Tạo các cột được tính toán với COLLATE nhị phân và chỉ mục:
ALTER TABLE t THÊM ansi_bin AS UPPER (ansi) COLLATE Latin1_General_100_Bin2ALTER TABLE t ADD unicod_bin AS UPPER (unicod) COLLATE Latin1_General_100_BIN2CREATE NONCLUSTERED INDEX ansi ON t (ansi) ansi_bin) TẠO INDEX unicod_bin KHÔNG ĐƯỢC ĐIỀU CHỈNH BẬT (unicod_bin)
Thực hiện quá trình lọc:
ĐẶT THỜI GIAN THỐNG KÊ, IO ONSELECT COUNT_BIG (*) FROM tWHERE ansi LIKE '% AB%' SELECT COUNT_BIG (*) FROM tWHERE unicod LIKE '% AB%' SELECT COUNT_BIG (*) FROM tWHERE ansi_bin LIKE '% AB%' --COLLATE Latin1_General_100_BIN2SELECT COUNT_BIG (*) TỪ tWHERE unicod_bin LIKE '% AB%' --COLLATE Latin1_General_100_BIN2SET THỐNG KÊ THỜI GIAN, IO TẮT
Như bạn có thể thấy, truy vấn này trả về kết quả sau:
Thời gian thực thi máy chủ SQL:thời gian CPU =350 mili giây, thời gian đã trôi qua =354 mili giây Thời gian thực thi máy chủQL:thời gian CPU =335 mili giây, thời gian đã trôi qua =355 mili giây Thời gian thực thi máy chủQL:thời gian CPU =16 mili giây, thời gian đã trôi qua =18 ms. Thời gian thực thi máy chủ QL:thời gian CPU =17 ms, thời gian đã trôi qua =18 ms.
Vấn đề là bộ lọc dựa trên so sánh nhị phân mất ít thời gian hơn. Do đó, nếu bạn cần lọc sự xuất hiện của các chuỗi thường xuyên và nhanh chóng, thì có thể lưu trữ dữ liệu với COLLATE kết thúc bằng BIN. Tuy nhiên, cần lưu ý rằng tất cả các COLLATE nhị phân đều phân biệt chữ hoa chữ thường.
Kiểu mã
Một phong cách mã hóa hoàn toàn mang tính cá nhân. Tuy nhiên, mã này phải được duy trì đơn giản bởi các nhà phát triển khác và phù hợp với các quy tắc nhất định.
Tạo một cơ sở dữ liệu riêng biệt và một bảng bên trong:
SỬ DỤNG [master] GOIF DB_ID ('test') KHÔNG BẮT ĐẦU ĐẦY ĐỦ kiểm tra CƠ SỞ DỮ LIỆU ĐẶT SINGLE_USER VỚI ROLLBACK NGAY LẬP TỨC DỮ LIỆU kiểm traENDGOCREATE DATABASE test COLLATE Latin1_General_CI_ASGOUSE testGOCREATE INTpreIMARY KEeeID
Sau đó, viết truy vấn:
chọn nhân viên từ nhân viên
Bây giờ, thay đổi COLLATE thành bất kỳ phân biệt chữ hoa chữ thường nào:
Kiểm tra ALTER DATABASE COLLATE Latin1_General_CS_AI
Sau đó, hãy thử thực hiện lại truy vấn:
Bản tin 208, Mức 16, Trạng thái 1, Dòng 19 Tên đối tượng không hợp lệ 'nhân viên'.
Trình tối ưu hóa sử dụng các quy tắc cho COLLATE hiện tại ở bước liên kết khi nó kiểm tra các bảng, cột và các đối tượng khác cũng như so sánh từng đối tượng của cây cú pháp với đối tượng thực của danh mục hệ thống.
Nếu bạn muốn tạo truy vấn theo cách thủ công, thì bạn cần phải luôn sử dụng đúng trường hợp trong tên đối tượng.
Đối với các biến, COLLATE được kế thừa từ cơ sở dữ liệu chính. Do đó, bạn cũng cần sử dụng đúng trường hợp để làm việc với chúng:
CHỌN DATABASEPROPERTYEX ('chính', 'đối chiếu') DECLARE @EmpID INT =1SELECT @empid
Trong trường hợp này, bạn sẽ không gặp lỗi:
----------------------- Cyrillic_General_CI_AS ----------- 1
Tuy nhiên, lỗi trường hợp có thể xuất hiện trên một máy chủ khác:
-------------------------- Latin1_General_CS_ASMsg 137, Level 15, State 2, Line 4Phải khai báo biến vô hướng "@empid".
[var] char
Như bạn đã biết, có những cố định ( CHAR , NCHAR ) và biến ( VARCHAR , NVARCHAR ) kiểu dữ liệu:
DECLARE @a CHAR (20) ='text', @b VARCHAR (20) ='text'SELECT LEN (@a), LEN (@b), DATALENGTH (@a), DATALENGTH (@b), '"' + @a + '"', '"' + @b + '" "SELECT [a =b] =IIF (@a =@b,' TRUE ',' FALSE '), [b =a] =IIF (@b =@a, 'TRUE', 'FALSE'), [a LIKE b] =IIF (@a LIKE @b, 'TRUE', 'FALSE'), [b LIKE a] =IIF (@ b THÍCH @a, 'TRUE', 'FALSE')
Nếu một hàng có độ dài cố định, giả sử 20 ký hiệu, nhưng bạn chỉ viết 4 ký hiệu, thì SQL Server sẽ thêm 16 ô trống ở bên phải theo mặc định:
--- --- ---- ---- -------------------------- ----------- 4 4 20 4 "văn bản" "văn bản"
In addition, it is important to understand that when comparing rows with =, blanks on the right are not taken into account:
a =b b =a a LIKE b b LIKE a----- ----- -------- --------TRUE TRUE TRUE FALSE
As for the LIKE operator, blanks will be always inserted.
SELECT 1WHERE 'a ' LIKE 'a'SELECT 1WHERE 'a' LIKE 'a ' -- !!!SELECT 1WHERE 'a' LIKE 'a'SELECT 1WHERE 'a' LIKE 'a%'
Data length
It is always necessary to specify type length.
Consider the following example:
DECLARE @a DECIMAL , @b VARCHAR(10) ='0.1' , @c SQL_VARIANTSELECT @a =@b , @c =@aSELECT @a , @c , SQL_VARIANT_PROPERTY(@c,'BaseType') , SQL_VARIANT_PROPERTY(@c,'Precision') , SQL_VARIANT_PROPERTY(@c,'Scale')
As you can see, the type length was not specified explicitly. Thus, the query returned an integer instead of a decimal value:
---- ---- ---------- ----- -----0 0 decimal 18 0
As for rows, if you do not specify a row length explicitly, then its length will contain only 1 symbol:
----- ------------------------------------------ ---- ---- ---- ----40 123456789_123456789_123456789_123456789_ 1 1 30 30
In addition, if you do not need to specify a length for CAST/CONVERT, then only 30 symbols will be used.
ISNULL vs COALESCE
There are two functions:ISNULL and COALESCE. On the one hand, everything seems to be simple. If the first operator is NULL, then it will return the second or the next operator, if we talk about COALESCE. On the other hand, there is a difference – what will these functions return?
DECLARE @a CHAR(1) =NULLSELECT ISNULL(@a, 'NULL'), COALESCE(@a, 'NULL')DECLARE @i INT =NULLSELECT ISNULL(@i, 7.1), COALESCE(@i, 7.1)
The answer is not obvious, as the ISNULL function converts to the smallest type of two operands, whereas COALESCE converts to the largest type.
---- ----N NULL---- ----7 7.1
As for performance, ISNULL will process a query faster, COALESCE is split into the CASE WHEN operator.
Math
Math seems to be a trivial thing in SQL Server.
SELECT 1 / 3SELECT 1.0 / 3
However, it is not. Everything depends on the fact what data is used in a query. If it is an integer, then it returns the integer result.
-----------0-----------0.333333
Also, let’s consider this particular example:
SELECT COUNT(*) , COUNT(1) , COUNT(val) , COUNT(DISTINCT val) , SUM(val) , SUM(DISTINCT val)FROM ( VALUES (1), (2), (2), (NULL), (NULL)) t (val)SELECT AVG(val) , SUM(val) / COUNT(val) , AVG(val * 1.) , AVG(CAST(val AS FLOAT))FROM ( VALUES (1), (2), (2), (NULL), (NULL)) t (val)
This query COUNT(*)/COUNT(1) will return the total amount of rows. COUNT on the column will return the amount of non-NULL rows. If we add DISTINCT, then it will return the amount of non-NULL unique values.
The AVG operation is divided into SUM and COUNT. Thus, when calculating an average value, NULL is not applicable.
UNION vs UNION ALL
When the data is not overridden, then it is better to use UNION ALL to improve performance. In order to avoid replication, you may use UNION.
Still, if there is no replication, it is preferable to use UNION ALL:
SELECT [object_id]FROM sys.system_objectsUNIONSELECT [object_id]FROM sys.objectsSELECT [object_id]FROM sys.system_objectsUNION ALLSELECT [object_id]FROM sys.objects
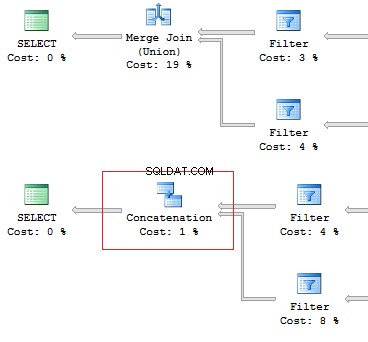
Also, I would like to point out the difference of these operators:the UNION operator is executed in a parallel way, the UNION ALL operator – in a sequential way.
Assume, we need to retrieve 1 row on the following conditions:
DECLARE @AddressLine NVARCHAR(60)SET @AddressLine ='4775 Kentucky Dr.'SELECT TOP(1) AddressIDFROM Person.[Address]WHERE AddressLine1 =@AddressLine OR AddressLine2 =@AddressLine
As we have OR in the statement, we will receive IndexScan:
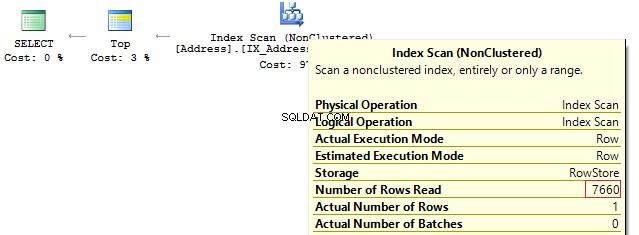
Table 'Address'. Scan count 1, logical reads 90, ...
Now, we will re-write the query using UNION ALL:
SELECT TOP(1) AddressIDFROM ( SELECT TOP(1) AddressID FROM Person.[Address] WHERE AddressLine1 =@AddressLine UNION ALL SELECT TOP(1) AddressID FROM Person.[Address] WHERE AddressLine2 =@AddressLine) t
When the first subquery had been executed, it returned 1 row. Thus, we have received the required result, and SQL Server stopped looking for, using the second subquery:
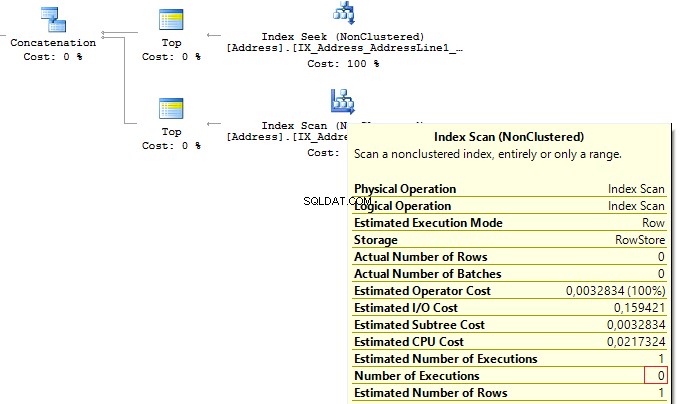
Table 'Worktable'. Scan count 0, logical reads 0, ...Table 'Address'. Scan count 1, logical reads 3, ...
Re-read
Very often, I faced the situation when the data can be retrieved with one JOIN. In addition, a lot of subqueries are created in this query:
USE AdventureWorks2014GOSET STATISTICS IO ONSELECT e.BusinessEntityID , ( SELECT p.LastName FROM Person.Person p WHERE e.BusinessEntityID =p.BusinessEntityID ) , ( SELECT p.FirstName FROM Person.Person p WHERE e.BusinessEntityID =p.BusinessEntityID )FROM HumanResources.Employee eSELECT e.BusinessEntityID , p.LastName , p.FirstNameFROM HumanResources.Employee eJOIN Person.Person p ON e.BusinessEntityID =p.BusinessEntityID
The fewer there are unnecessary table lookups, the fewer logical readings we have:
Table 'Person'. Scan count 0, logical reads 1776, ...Table 'Employee'. Scan count 1, logical reads 2, ...Table 'Person'. Scan count 0, logical reads 888, ...Table 'Employee'. Scan count 1, logical reads 2, ...
SubQuery
The previous example works only if there is a one-to-one connection between tables.
Assume tables Person.Person and Sales.SalesPersonQuotaHistory were directly connected. Thus, one employee had only one record for a share size.
USE AdventureWorks2014GOSET STATISTICS IO ONSELECT p.BusinessEntityID , ( SELECT s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID )FROM Person.Person p
However, as settings on the client server may differ, this query may lead to the following error:
Msg 512, Level 16, State 1, Line 6Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <=,>,>=or when the subquery is used as an expression.
It is possible to solve such issues by adding TOP(1) and ORDER BY. Using the TOP operation makes an optimizer force using IndexSeek. The same refers to using OUTER/CROSS APPLY with TOP:
SELECT p.BusinessEntityID , ( SELECT TOP(1) s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID ORDER BY s.QuotaDate DESC )FROM Person.Person pSELECT p.BusinessEntityID , t.SalesQuotaFROM Person.Person pOUTER APPLY ( SELECT TOP(1) s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID ORDER BY s.QuotaDate DESC) t
When executing these queries, we will get the same issue – multiple IndexSeek operators:
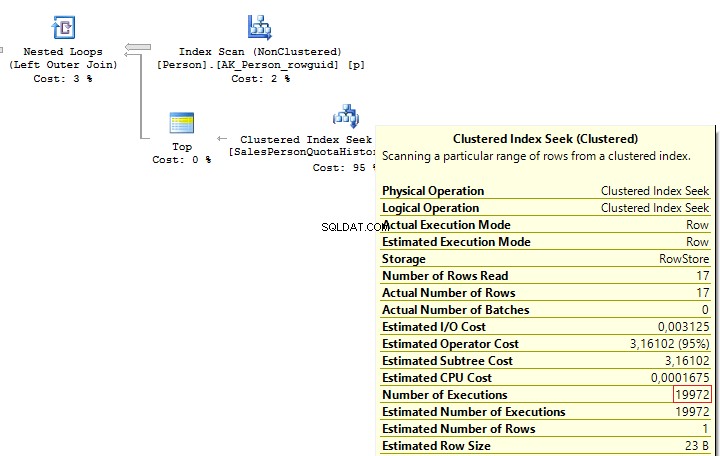
Table 'SalesPersonQuotaHistory'. Scan count 19972, logical reads 39944, ...Table 'Person'. Scan count 1, logical reads 67, ...
Re-write this query with a window function:
SELECT p.BusinessEntityID , t.SalesQuotaFROM Person.Person pLEFT JOIN ( SELECT s.BusinessEntityID , s.SalesQuota , RowNum =ROW_NUMBER() OVER (PARTITION BY s.BusinessEntityID ORDER BY s.QuotaDate DESC) FROM Sales.SalesPersonQuotaHistory s) t ON p.BusinessEntityID =t.BusinessEntityID AND t.RowNum =1
Chúng tôi nhận được kết quả sau:
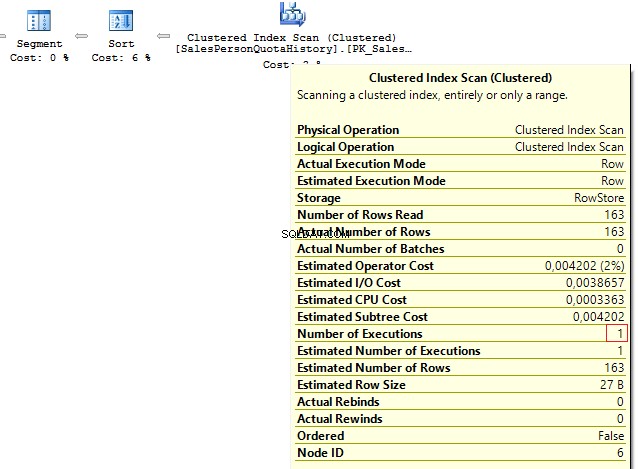
Table 'Person'. Scan count 1, logical reads 67, ...Table 'SalesPersonQuotaHistory'. Scan count 1, logical reads 4, ...
CASE WHEN
Since this operator is used very often, I would like to specify its features. Regardless, how we wrote the CASE WHEN operator:
USE AdventureWorks2014GOSELECT BusinessEntityID , Gender , Gender =CASE Gender WHEN 'M' THEN 'Male' WHEN 'F' THEN 'Female' ELSE 'Unknown' ENDFROM HumanResources.Employee
SQL Server will decompose the statement to the following:
SELECT BusinessEntityID , Gender , Gender =CASE WHEN Gender ='M' THEN 'Male' WHEN Gender ='F' THEN 'Female' ELSE 'Unknown' ENDFROM HumanResources.Employee
Thus, this will lead to the main issue:each condition will be executed in a sequential order until one of them returns TRUE or ELSE.
Consider this issue on a particular example. To do this, we will create a scalar-valued function which will return the right part of a postal code:
IF OBJECT_ID('dbo.GetMailUrl') IS NOT NULL DROP FUNCTION dbo.GetMailUrlGOCREATE FUNCTION dbo.GetMailUrl( @Email NVARCHAR(50))RETURNS NVARCHAR(50)AS BEGIN RETURN SUBSTRING(@Email, CHARINDEX('@', @Email) + 1, LEN(@Email))END
Then, configure SQL Profiler to build SQL events:StmtStarting / SP:StmtCompleted (if you want to do this with XEvents :sp_statement_starting / sp_statement_completed ).
Execute the query:
SELECT TOP(10) EmailAddressID , EmailAddress , CASE dbo.GetMailUrl(EmailAddress) --WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM Person.EmailAddress
The function will be executed for 10 times. Now, delete a comment from the condition:
SELECT TOP(10) EmailAddressID , EmailAddress , CASE dbo.GetMailUrl(EmailAddress) WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM Person.EmailAddress
In this case, the function will be executed for 20 times. The thing is that it is not necessary for a statement to be a must function in CASE. It may be a complicated calculation. As it is possible to decompose CASE, it may lead to multiple calculations of the same operators.
You may avoid it by using subqueries:
SELECT EmailAddressID , EmailAddress , CASE MailUrl WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM ( SELECT TOP(10) EmailAddressID , EmailAddress , MailUrl =dbo.GetMailUrl(EmailAddress) FROM Person.EmailAddress) t
In this case, the function will be executed 10 times.
In addition, we need to avoid replication in the CASE operator:
SELECT DISTINCT CASE WHEN Gender ='M' THEN 'Male' WHEN Gender ='M' THEN '...' WHEN Gender ='M' THEN '......' WHEN Gender ='F' THEN 'Female' WHEN Gender ='F' THEN '...' ELSE 'Unknown' ENDFROM HumanResources.Employee
Though statements in CASE are executed in a sequential order, in some cases, SQL Server may execute this operator with aggregate functions:
DECLARE @i INT =1SELECT CASE WHEN @i =1 THEN 1 ELSE 1/0 ENDGODECLARE @i INT =1SELECT CASE WHEN @i =1 THEN 1 ELSE MIN(1/0) END
Scalar func
It is not recommended to use scalar functions in T-SQL queries.
Consider the following example:
USE AdventureWorks2014GOUPDATE TOP(1) Person.[Address]SET AddressLine2 =AddressLine1GOIF OBJECT_ID('dbo.isEqual') IS NOT NULL DROP FUNCTION dbo.isEqualGOCREATE FUNCTION dbo.isEqual( @val1 NVARCHAR(100), @val2 NVARCHAR(100))RETURNS BITAS BEGIN RETURN CASE WHEN (@val1 IS NULL AND @val2 IS NULL) OR @val1 =@val2 THEN 1 ELSE 0 ENDEND
The queries return the identical data:
SET STATISTICS TIME ONSELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE dbo.IsEqual(AddressLine1, AddressLine2) =1SELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE (AddressLine1 IS NULL AND AddressLine2 IS NULL) OR AddressLine1 =AddressLine2SELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE AddressLine1 =ISNULL(AddressLine2, '')SET STATISTICS TIME OFF
However, as each call of the scalar function is a resource-intensive process, we can monitor this difference:
SQL Server Execution Times:CPU time =63 ms, elapsed time =57 ms.SQL Server Execution Times:CPU time =0 ms, elapsed time =1 ms.SQL Server Execution Times:CPU time =0 ms, elapsed time =1 ms.
In addition, when using a scalar function, it is not possible for SQL Server to build parallel execution plans, which may lead to poor performance in a huge volume of data.
Sometimes scalar functions may have a positive effect. For example, when we have SCHEMABINDING in the statement:
IF OBJECT_ID('dbo.GetPI') IS NOT NULL DROP FUNCTION dbo.GetPIGOCREATE FUNCTION dbo.GetPI ()RETURNS FLOATWITH SCHEMABINDINGAS BEGIN RETURN PI()ENDGOSELECT dbo.GetPI()FROM Sales.Currency
In this case, the function will be considered as deterministic and executed 1 time.
VIEWs
Here I would like to talk about features of views.
Create a test table and view on its base:
IF OBJECT_ID('dbo.tbl', 'U') IS NOT NULL DROP TABLE dbo.tblGOCREATE TABLE dbo.tbl (a INT, b INT)GOINSERT INTO dbo.tbl VALUES (0, 1)GOIF OBJECT_ID('dbo.vw_tbl', 'V') IS NOT NULL DROP VIEW dbo.vw_tblGOCREATE VIEW dbo.vw_tblAS SELECT * FROM dbo.tblGOSELECT * FROM dbo.vw_tbl
As you can see, we get the correct result:
a b----------- -----------0 1
Now, add a new column in the table and retrieve data from the view:
ALTER TABLE dbo.tbl ADD c INT NOT NULL DEFAULT 2GOSELECT * FROM dbo.vw_tbl
We receive the same result:
a b----------- -----------0 1
Thus, we need either to explicitly set columns or recompile a script object to get the correct result:
EXEC sys.sp_refreshview @viewname =N'dbo.vw_tbl'GOSELECT * FROM dbo.vw_tbl
Result:
a b c----------- ----------- -----------0 1 2
When you directly refer to the table, this issue will not take place.
Now, I would like to discuss a situation when all the data is combined in one query as well as wrapped in one view. I will do it on this particular example:
ALTER VIEW HumanResources.vEmployeeAS SELECT e.BusinessEntityID , p.Title , p.FirstName , p.MiddleName , p.LastName , p.Suffix , e.JobTitle , pp.PhoneNumber , pnt.[Name] AS PhoneNumberType , ea.EmailAddress , p.EmailPromotion , a.AddressLine1 , a.AddressLine2 , a.City , sp.[Name] AS StateProvinceName , a.PostalCode , cr.[Name] AS CountryRegionName , p.AdditionalContactInfo FROM HumanResources.Employee e JOIN Person.Person p ON p.BusinessEntityID =e.BusinessEntityID JOIN Person.BusinessEntityAddress bea ON bea.BusinessEntityID =e.BusinessEntityID JOIN Person.[Address] a ON a.AddressID =bea.AddressID JOIN Person.StateProvince sp ON sp.StateProvinceID =a.StateProvinceID JOIN Person.CountryRegion cr ON cr.CountryRegionCode =sp.CountryRegionCode LEFT JOIN Person.PersonPhone pp ON pp.BusinessEntityID =p.BusinessEntityID LEFT JOIN Person.PhoneNumberType pnt ON pp.PhoneNumberTypeID =pnt.PhoneNumberTypeID LEFT JOIN Person.EmailAddress ea ON p.BusinessEntityID =ea.BusinessEntityID
What should you do if you need to get only a part of information? For example, you need to get Fist Name and Last Name of employees:
SELECT BusinessEntityID , FirstName , LastNameFROM HumanResources.vEmployeeSELECT p.BusinessEntityID , p.FirstName , p.LastNameFROM Person.Person pWHERE p.BusinessEntityID IN ( SELECT e.BusinessEntityID FROM HumanResources.Employee e )
Look at the execution plan in the case of using a view:
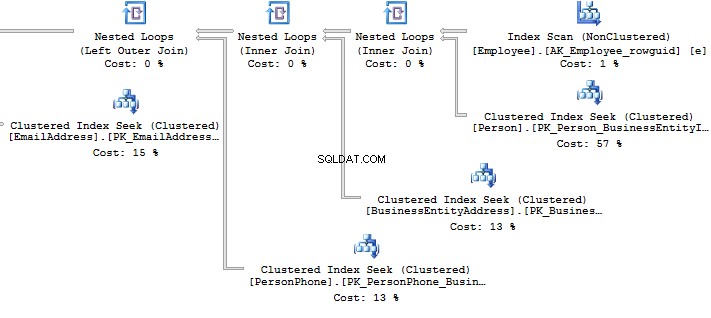
Table 'EmailAddress'. Scan count 290, logical reads 640, ...Table 'PersonPhone'. Scan count 290, logical reads 636, ...Table 'BusinessEntityAddress'. Scan count 290, logical reads 636, ...Table 'Person'. Scan count 0, logical reads 897, ...Table 'Employee'. Scan count 1, logical reads 2, ...
Now, we will compare it with the query we have written manually:
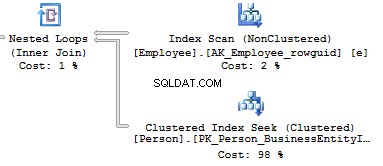
Table 'Person'. Scan count 0, logical reads 897, ...Table 'Employee'. Scan count 1, logical reads 2, ...
When creating an execution plan, an optimizer in SQL Server drops unused connections.
However, sometimes when there is no valid foreign key between tables, it is not possible to check whether a connection will impact the sample result. It may also be applied to the situation when tables are connecteCURSORs
I recommend that you do not use cursors for iteration data modification.
You can see the following code with a cursor:
DECLARE @BusinessEntityID INTDECLARE cur CURSOR FOR SELECT BusinessEntityID FROM HumanResources.EmployeeOPEN curFETCH NEXT FROM cur INTO @BusinessEntityIDWHILE @@FETCH_STATUS =0 BEGIN UPDATE HumanResources.Employee SET VacationHours =0 WHERE BusinessEntityID =@BusinessEntityID FETCH NEXT FROM cur INTO @BusinessEntityIDENDCLOSE curDEALLOCATE cur
Though, it is possible to re-write the code by dropping the cursor:
UPDATE HumanResources.EmployeeSET VacationHours =0WHERE VacationHours <> 0
In this case, it will improve performance and decrease the time to execute a query.
STRING_CONCAT
To concatenate rows, the STRING_CONCAT could be used. However, as there is no such a function in the SQL Server, we will do this by assigning a value to the variable.
To do this, create a test table:
IF OBJECT_ID('tempdb.dbo.#t') IS NOT NULL DROP TABLE #tGOCREATE TABLE #t (i CHAR(1))INSERT INTO #tVALUES ('1'), ('2'), ('3')
Then, assign values to the variable:
DECLARE @txt VARCHAR(50) =''SELECT @txt +=iFROM #tSELECT @txt--------123
Everything seems to be working fine. However, MS hints that this way is not documented and you may get this result:
DECLARE @txt VARCHAR(50) =''SELECT @txt +=iFROM #tORDER BY LEN(i)SELECT @txt--------3
Alternatively, it is a good idea to use XML as a workaround:
SELECT [text()] =iFROM #tFOR XML PATH('')--------123
It should be noted that it is necessary to concatenate rows per each data, rather than into a single set of data:
SELECT [name], STUFF(( SELECT ', ' + c.[name] FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'------------------------ ------------------------------------ScrapReason ScrapReasonID, Name, ModifiedDateShift ShiftID, Name, StartTime, EndTime
In addition, it is recommended that you should avoid using the XML method for parsing as it is a high-runner process:
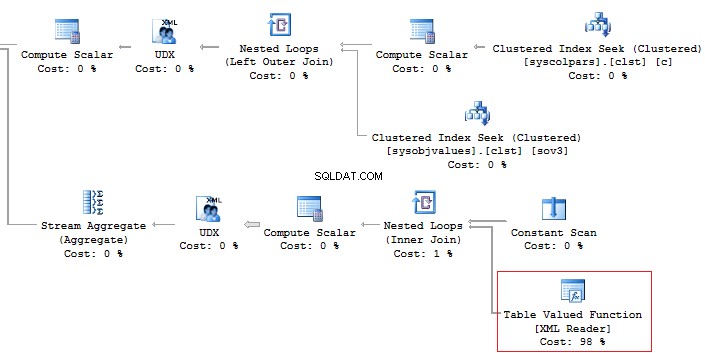
Alternatively, it is possible to do this less time-consuming:
SELECT [name], STUFF(( SELECT ', ' + c.[name] FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH(''), TYPE).value('(./text())[1]', 'NVARCHAR(MAX)'), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'
But, it does not change the main point.
Now, execute the query without using the value method:
SELECT t.name , STUFF(( SELECT ', ' + c.name FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH('')), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'
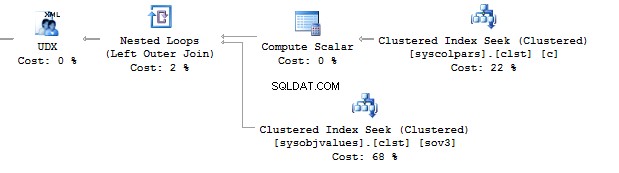
This option would work perfect. However, it may fail. If you want to check it, execute the following query:
SELECT t.name , STUFF(( SELECT ', ' + CHAR(13) + c.name FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH('')), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'
If there are special symbols in rows, such as tabulation, line break, etc., then we will get incorrect results.
Thus, if there are no special symbols, you can create a query without the value method, otherwise, use value(‘(./text())[1]’… .
SQL Injection
Assume we have a code:
DECLARE @param VARCHAR(MAX)SET @param =1DECLARE @SQL NVARCHAR(MAX)SET @SQL ='SELECT TOP(5) name FROM sys.objects WHERE schema_id =' + @paramPRINT @SQLEXEC (@SQL)
Create the query:
SELECT TOP(5) name FROM sys.objects WHERE schema_id =1
If we add any additional value to the property,
SET @param ='1; select ''hack'''
Then our query will be changed to the following construction:
SELECT TOP(5) name FROM sys.objects WHERE schema_id =1; select 'hack'
This is called SQL injection when it is possible to execute a query with any additional information.
If the query is formed with String.Format (or manually) in the code, then you may get SQL injection:
using (SqlConnection conn =new SqlConnection()){ conn.ConnectionString =@"Server=.;Database=AdventureWorks2014;Trusted_Connection=true"; conn.Open(); SqlCommand command =new SqlCommand( string.Format("SELECT TOP(5) name FROM sys.objects WHERE schema_id ={0}", value), conn); using (SqlDataReader reader =command.ExecuteReader()) { while (reader.Read()) {} }}
When you use sp_executesql and properties as shown in this code:
DECLARE @param VARCHAR(MAX)SET @param ='1; select ''hack'''DECLARE @SQL NVARCHAR(MAX)SET @SQL ='SELECT TOP(5) name FROM sys.objects WHERE schema_id =@schema_id'PRINT @SQLEXEC sys.sp_executesql @SQL , N'@schema_id INT' , @schema_id =@param
It is not possible to add some information to the property.
In the code, you may see the following interpretation of the code:
using (SqlConnection conn =new SqlConnection()){ conn.ConnectionString =@"Server=.;Database=AdventureWorks2014;Trusted_Connection=true"; conn.Open(); SqlCommand command =new SqlCommand( "SELECT TOP(5) name FROM sys.objects WHERE schema_id =@schema_id", conn); command.Parameters.Add(new SqlParameter("schema_id", value)); ...} Tóm tắt
Working with databases is not as simple as it may seem. There are a lot of points you should keep in mind when writing T-SQL queries.
Of course, it is not the whole list of pitfalls when working with SQL Server. Still, I hope that this article will be useful for newbies.