SQL Server cung cấp cho chúng ta một số hàm cửa sổ giúp chúng ta thực hiện các phép tính trên một tập hợp các hàng mà không cần lặp lại các lệnh gọi đến cơ sở dữ liệu. Không giống như các hàm tổng hợp tiêu chuẩn, các hàm cửa sổ sẽ không nhóm các hàng thành một hàng đầu ra duy nhất, chúng sẽ trả về một giá trị tổng hợp duy nhất cho mỗi hàng, giữ các danh tính riêng biệt cho các hàng đó. Thuật ngữ Window ở đây không liên quan đến hệ điều hành Microsoft Windows, nó mô tả tập hợp các hàng mà hàm sẽ xử lý.
Một trong những loại chức năng cửa sổ hữu ích nhất là Chức năng cửa sổ xếp hạng được sử dụng để xếp hạng các giá trị trường cụ thể và phân loại chúng theo thứ hạng của mỗi hàng, dẫn đến một giá trị tổng hợp duy nhất cho mỗi hàng đã tham gia. Có bốn chức năng cửa sổ xếp hạng được hỗ trợ trong SQL Server; ROW_NUMBER (), RANK (), DENSE_RANK () và NTILE (). Tất cả các hàm này được sử dụng để tính toán ROWID cho cửa sổ hàng được cung cấp theo cách riêng của chúng.
Bốn hàm cửa sổ xếp hạng sử dụng mệnh đề OVER () để xác định tập hợp hàng do người dùng chỉ định trong tập kết quả truy vấn. Bằng cách xác định mệnh đề OVER (), bạn cũng có thể bao gồm mệnh đề PARTITION BY xác định tập hợp các hàng mà hàm cửa sổ sẽ xử lý, bằng cách cung cấp các cột được phân tách bằng dấu phẩy hoặc cột để xác định phân vùng. Ngoài ra, có thể bao gồm mệnh đề ORDER BY, mệnh đề này xác định tiêu chí sắp xếp trong các phân vùng mà hàm sẽ đi qua các hàng trong khi xử lý.
Trong bài viết này, chúng ta sẽ thảo luận về cách sử dụng bốn hàm cửa sổ xếp hạng:ROW_NUMBER (), RANK (), DENSE_RANK () và NTILE () trên thực tế và sự khác biệt giữa chúng.
Để phục vụ bản trình diễn của chúng tôi, chúng tôi sẽ tạo một bảng đơn giản mới và chèn một vài bản ghi vào bảng bằng cách sử dụng tập lệnh T-SQL bên dưới:
CREATE TABLE StudentScore
(
Student_ID INT PRIMARY KEY,
Student_Name NVARCHAR (50),
Student_Score INT
)
GO
INSERT INTO StudentScore VALUES (1,'Ali', 978)
INSERT INTO StudentScore VALUES (2,'Zaid', 770)
INSERT INTO StudentScore VALUES (3,'Mohd', 1140)
INSERT INTO StudentScore VALUES (4,'Jack', 770)
INSERT INTO StudentScore VALUES (5,'John', 1240)
INSERT INTO StudentScore VALUES (6,'Mike', 1140)
INSERT INTO StudentScore VALUES (7,'Goerge', 885)
Bạn có thể kiểm tra xem dữ liệu đã được chèn thành công hay chưa bằng cách sử dụng câu lệnh SELECT sau:
SELECT * FROM StudentScore ORDER BY Student_ScoreVới kết quả đã sắp xếp được áp dụng, tập kết quả như sau:

ROW_NUMBER ()
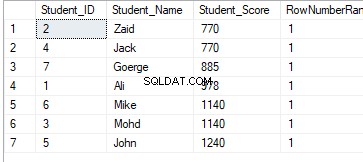
Hàm cửa sổ xếp hạng ROW_NUMBER () trả về một số tuần tự duy nhất cho mỗi hàng trong phân vùng của cửa sổ được chỉ định, bắt đầu từ 1 cho hàng đầu tiên trong mỗi phân vùng và không lặp lại hoặc bỏ qua các số trong kết quả xếp hạng của mỗi phân vùng. Nếu có các giá trị trùng lặp trong tập hàng, số ID xếp hạng sẽ được chỉ định tùy ý. Nếu mệnh đề PARTITION BY được chỉ định, số hàng xếp hạng sẽ được đặt lại cho mỗi phân vùng. Trong bảng đã tạo trước đó, truy vấn dưới đây cho biết cách sử dụng hàm cửa sổ xếp hạng ROW_NUMBER để xếp hạng các hàng trong bảng StudentScore theo điểm của từng học sinh:
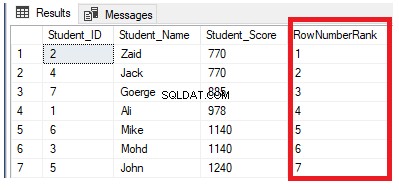
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
Rõ ràng từ bộ kết quả bên dưới rằng hàm cửa sổ ROW_NUMBER xếp hạng các hàng trong bảng theo giá trị cột Student_Score cho mỗi hàng, bằng cách tạo một số duy nhất của mỗi hàng phản ánh xếp hạng Student_Score của nó bắt đầu từ số 1 mà không có trùng lặp hoặc khoảng trống và xử lý tất cả các hàng như một phân vùng. Bạn cũng có thể thấy rằng các điểm trùng lặp được chỉ định cho các cấp bậc khác nhau một cách ngẫu nhiên:
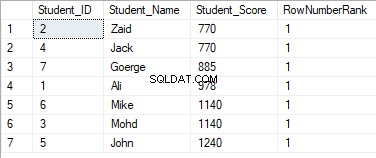
Nếu chúng tôi sửa đổi truy vấn trước đó bằng cách bao gồm mệnh đề PARTITION BY để có nhiều hơn một phân vùng, như được hiển thị trong truy vấn T-SQL bên dưới:
SELECT *, ROW_NUMBER() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
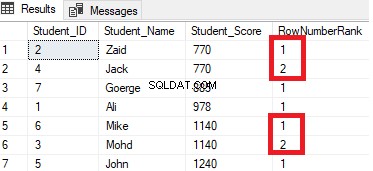
Kết quả sẽ cho thấy rằng hàm cửa sổ ROW_NUMBER sẽ xếp hạng các hàng trong bảng theo giá trị cột Student_Score cho mỗi hàng, nhưng nó sẽ xử lý các hàng có cùng giá trị Student_Score thành một phân vùng. Bạn sẽ thấy rằng một số duy nhất sẽ được tạo cho mỗi hàng phản ánh xếp hạng Student_Score của nó, bắt đầu từ số 1 mà không có trùng lặp hoặc khoảng trống trong cùng một phân vùng, đặt lại số thứ hạng khi chuyển sang một giá trị Student_Score khác.
Ví dụ, những học sinh có điểm 770 sẽ được xếp hạng trong số điểm đó bằng cách gán một số thứ hạng cho nó. Tuy nhiên, khi nó được chuyển đến học sinh có điểm 885, số thứ hạng bắt đầu sẽ được đặt lại để bắt đầu lại ở 1, như hình dưới đây:
RANK ()
Hàm cửa sổ xếp hạng RANK () trả về một số thứ hạng duy nhất cho mỗi hàng riêng biệt trong phân vùng theo một giá trị cột được chỉ định, bắt đầu từ 1 cho hàng đầu tiên trong mỗi phân vùng, với cùng một thứ hạng cho các giá trị trùng lặp và để lại khoảng cách giữa các thứ hạng; khoảng trống này xuất hiện trong chuỗi sau các giá trị trùng lặp. Nói cách khác, hàm cửa sổ xếp hạng RANK () hoạt động giống như hàm ROW_NUMBER () ngoại trừ các hàng có giá trị bằng nhau, nơi nó sẽ xếp hạng với cùng một ID xếp hạng và tạo ra khoảng cách sau nó. Nếu chúng tôi sửa đổi truy vấn xếp hạng trước đó để sử dụng hàm xếp hạng RANK ():
SELECT *, RANK () OVER( ORDER BY Student_Score) AS RankRank
FROM StudentScoreBạn sẽ thấy từ kết quả rằng hàm cửa sổ RANK sẽ xếp hạng các hàng trong bảng theo giá trị cột Student_Score cho mỗi hàng, với giá trị xếp hạng phản ánh Student_Score của nó bắt đầu từ số 1 và xếp hạng các hàng có cùng Student_Score với cùng một giá trị thứ hạng. Bạn cũng có thể thấy rằng hai hàng có Student_Score bằng 770 được xếp hạng với cùng một giá trị, để lại một khoảng trống, đó là số 2 bị bỏ lỡ, sau hàng xếp hạng thứ hai. Điều tương tự cũng xảy ra với các hàng mà Student_Score bằng 1140 được xếp hạng với cùng một giá trị, để lại một khoảng trống, là số 6 bị thiếu, sau hàng thứ hai, như được hiển thị bên dưới:
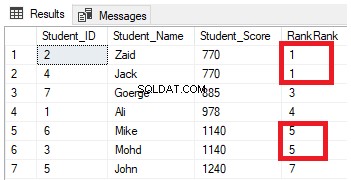
Sửa đổi truy vấn trước đó bằng cách bao gồm mệnh đề PARTITION BY để có nhiều hơn một phân vùng, như được hiển thị trong truy vấn T-SQL bên dưới:
SELECT *, RANK() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScoreKết quả xếp hạng sẽ không có ý nghĩa gì, vì thứ hạng sẽ được thực hiện theo giá trị Student_Score trên mỗi phân vùng và dữ liệu sẽ được phân vùng theo giá trị Student_Score. Và do thực tế là mỗi phân vùng sẽ có các hàng có cùng giá trị Student_Score, các hàng có cùng giá trị Student_Score trong cùng một phân vùng sẽ được xếp hạng với giá trị bằng 1. Do đó, khi chuyển sang phân vùng thứ hai, thứ hạng sẽ được đặt lại, bắt đầu lại với số 1, có tất cả các giá trị xếp hạng bằng 1 như hình dưới đây:
DENSE_RANK ()
Hàm cửa sổ xếp hạng DENSE_RANK () tương tự như hàm RANK () bằng cách tạo một số thứ hạng duy nhất cho mỗi hàng riêng biệt trong phân vùng theo một giá trị cột được chỉ định, bắt đầu từ 1 cho hàng đầu tiên trong mỗi phân vùng, xếp hạng các hàng với các giá trị bằng nhau với cùng số thứ hạng, ngoại trừ việc nó không bỏ qua bất kỳ thứ hạng nào, không để lại khoảng cách giữa các thứ hạng.
Nếu chúng tôi viết lại truy vấn xếp hạng trước đó để sử dụng hàm xếp hạng DENSE_RANK ():
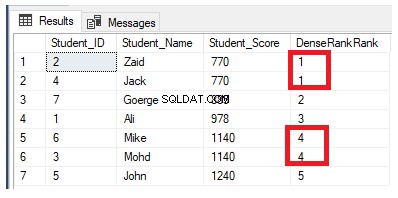
Một lần nữa, hãy sửa đổi truy vấn trước đó bằng cách bao gồm mệnh đề PARTITION BY để có nhiều hơn một phân vùng, như được hiển thị trong truy vấn T-SQL bên dưới:
SELECT *, DENSE_RANK() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
Các giá trị xếp hạng sẽ không có ý nghĩa, trong đó tất cả các hàng sẽ được xếp hạng với giá trị 1, do việc gán các giá trị trùng lặp cho cùng một giá trị xếp hạng và đặt lại id bắt đầu xếp hạng khi xử lý một phân vùng mới, như được hiển thị bên dưới:
NTILE (N)
Chức năng cửa sổ xếp hạng NTILE (N) được sử dụng để phân phối các hàng trong các hàng được đặt thành một số nhóm được chỉ định, cung cấp cho mỗi hàng trong nhóm hàng có một số nhóm duy nhất, bắt đầu bằng số 1 cho biết nhóm mà hàng này thuộc về. đến, trong đó N là một số dương, xác định số lượng nhóm bạn cần để phân phối các hàng được đặt thành.
Nói cách khác, nếu bạn cần chia các hàng dữ liệu cụ thể của bảng thành 3 nhóm, dựa trên các giá trị cột cụ thể, thì chức năng cửa sổ xếp hạng NTILE (3) sẽ giúp bạn dễ dàng đạt được điều này.
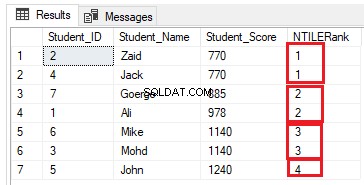
Số hàng trong mỗi nhóm có thể được tính bằng cách chia số hàng thành số nhóm cần thiết. Nếu chúng tôi sửa đổi truy vấn xếp hạng trước đó để sử dụng hàm cửa sổ xếp hạng NTILE (4) để xếp bảy hàng trong bảng thành bốn nhóm như truy vấn T-SQL bên dưới:
SELECT *, NTILE(4) OVER( ORDER BY Student_Score) AS NTILERank
FROM StudentScore
Số hàng phải là (7/4 =1,75) hàng trong mỗi nhóm. Sử dụng hàm NTILE (), SQL Server Engine sẽ chỉ định 2 hàng cho ba nhóm đầu tiên và một hàng cho nhóm cuối cùng, để có tất cả các hàng được bao gồm trong các nhóm, như được hiển thị trong tập kết quả bên dưới:
Sửa đổi truy vấn trước đó bằng cách bao gồm mệnh đề PARTITION BY để có nhiều hơn một phân vùng, như được hiển thị trong truy vấn T-SQL bên dưới:
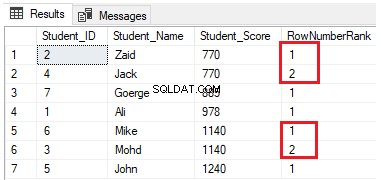
SELECT *, NTILE(4) OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScoreCác hàng sẽ được phân phối thành bốn nhóm trên mỗi phân vùng. Ví dụ:hai hàng đầu tiên có Student_Score bằng 770 sẽ nằm trong cùng một phân vùng và sẽ được phân phối trong các nhóm xếp hạng mỗi hàng với một số duy nhất, như được hiển thị trong tập kết quả bên dưới:
Hợp nhất tất cả
Để có một kịch bản so sánh rõ ràng hơn, chúng ta hãy cắt bớt bảng trước, thêm một tiêu chí phân loại khác, đó là lớp của sinh viên và cuối cùng chèn bảy hàng mới bằng cách sử dụng tập lệnh T-SQL bên dưới:
TRUNCATE TABLE StudentScore
GO
ALTER TABLE StudentScore ADD CLASS CHAR(1)
GO
INSERT INTO StudentScore VALUES (1,'Ali', 978,'A')
INSERT INTO StudentScore VALUES (2,'Zaid', 770,'B')
INSERT INTO StudentScore VALUES (3,'Mohd', 1140,'A')
INSERT INTO StudentScore VALUES (4,'Jack', 879,'B')
INSERT INTO StudentScore VALUES (5,'John', 1240,'C')
INSERT INTO StudentScore VALUES (6,'Mike', 1100,'B')
INSERT INTO StudentScore VALUES (7,'Goerge', 885,'C')Sau đó, chúng tôi sẽ xếp bảy hàng theo điểm của mỗi học sinh, phân chia các học sinh theo lớp của họ. Nói cách khác, mỗi phân vùng sẽ bao gồm một lớp và mỗi lớp sinh viên sẽ được xếp hạng theo điểm của họ trong cùng một lớp, sử dụng bốn chức năng cửa sổ xếp hạng được mô tả trước đó, như được hiển thị trong tập lệnh T-SQL bên dưới:
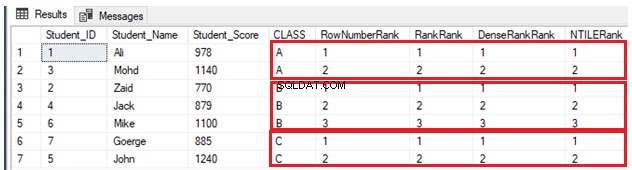
SELECT *, ROW_NUMBER() OVER(PARTITION BY CLASS ORDER BY Student_Score) AS RowNumberRank,
RANK () OVER(PARTITION BY CLASS ORDER BY Student_Score) AS RankRank,
DENSE_RANK () OVER(PARTITION BY CLASS ORDER BY Student_Score) AS DenseRankRank,
NTILE(7) OVER(PARTITION BY CLASS ORDER BY Student_Score) AS NTILERank
FROM StudentScore
GODo thực tế là không có giá trị trùng lặp, bốn hàm cửa sổ xếp hạng sẽ hoạt động theo cùng một cách, trả về cùng một kết quả, như được hiển thị trong tập kết quả bên dưới:
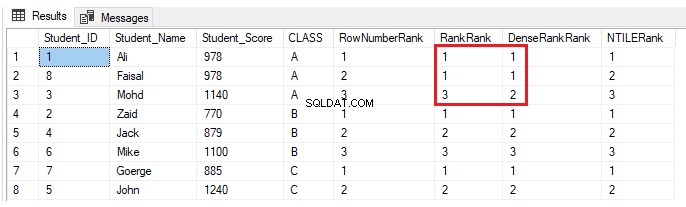
Nếu một học sinh khác được xếp vào lớp A với điểm số mà một học sinh khác trong cùng lớp đã có, sử dụng câu lệnh INSERT bên dưới:
INSERT INTO StudentScore VALUES (8,'Faisal', 978,'A')Sẽ không có gì thay đổi đối với các hàm cửa sổ xếp hạng ROW_NUMBER () và NTILE (). Các hàm RANK và DENSE_RANK () sẽ ấn định cùng một thứ hạng cho những sinh viên có cùng điểm số, với khoảng cách giữa các cấp sau các cấp trùng lặp khi sử dụng hàm RANK và không có khoảng cách trong các cấp sau các cấp trùng lặp khi sử dụng DENSE_RANK ( ), như được hiển thị trong kết quả bên dưới:
Tình huống thực tế
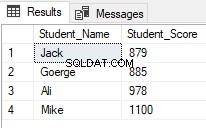
Các chức năng cửa sổ xếp hạng được sử dụng rộng rãi bởi các nhà phát triển SQL Server. Một trong những tình huống phổ biến đối với việc sử dụng hàm xếp hạng, khi bạn muốn tìm nạp các hàng cụ thể và bỏ qua các hàng khác, hãy sử dụng hàm ROW_NUMBER (,) cửa sổ xếp hạng trong CTE, như trong tập lệnh T-SQL bên dưới trả về các sinh viên có xếp hạng giữa 2 và 5 và bỏ qua những cái khác:
WITH ClassRanks AS
(
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
)
SELECT Student_Name , Student_Score
FROM ClassRanks
WHERE RowNumberRank >= 2 and RowNumberRank <=5
ORDER BY RowNumberRank
Kết quả sẽ cho thấy rằng chỉ những học sinh có xếp hạng từ 2 đến 5 mới được trả về:
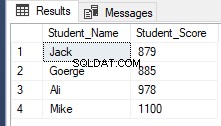
Bắt đầu từ SQL Server 2012, một lệnh hữu ích mới, OFFSET FETCH đã được giới thiệu có thể được sử dụng để thực hiện cùng một tác vụ trước đó bằng cách tìm nạp các bản ghi cụ thể và bỏ qua các bản ghi khác, sử dụng tập lệnh T-SQL bên dưới:
WITH ClassRanks AS
(
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
)
SELECT Student_Name , Student_Score
FROM ClassRanks
ORDER BY
RowNumberRank OFFSET 1 ROWS FETCH NEXT 4 ROWS ONLY;Truy xuất cùng một kết quả trước đó như được hiển thị bên dưới:
Kết luận
SQL Server cung cấp cho chúng tôi bốn chức năng cửa sổ xếp hạng giúp chúng tôi xếp hạng các hàng được cung cấp được đặt theo các giá trị cột cụ thể. Các hàm này là:ROW_NUMBER (), RANK (), DENSE_RANK () và NTILE (). Tất cả các chức năng xếp hạng này thực hiện nhiệm vụ xếp hạng theo cách riêng của nó, trả về cùng một kết quả khi không có giá trị trùng lặp trong các hàng. Nếu có một giá trị trùng lặp trong tập hợp hàng, hàm RANK sẽ chỉ định cùng một ID xếp hạng cho tất cả các hàng có cùng giá trị, để lại khoảng cách giữa các cấp sau các bản sao. Hàm DENSE_RANK cũng sẽ chỉ định cùng một ID xếp hạng cho tất cả các hàng có cùng giá trị, nhưng sẽ không để lại bất kỳ khoảng cách nào giữa các hàng sau các lần trùng lặp. Chúng tôi xem xét các tình huống khác nhau trong bài viết này để đề cập đến tất cả các trường hợp có thể xảy ra giúp bạn hiểu thực tế các chức năng của cửa sổ xếp hạng.
Tài liệu tham khảo:
- ROW_NUMBER (Giao dịch-SQL)
- RANK (Giao dịch-SQL)
- DENSE_RANK (Giao dịch-SQL)
- NTILE (Transact-SQL)
- Mệnh đề OFFSET FETCH (SQL Server Compact)