
Vào tháng 3, tôi đã bắt đầu một loạt bài về những huyền thoại về hiệu suất phổ biến trong SQL Server. Một niềm tin mà tôi thường gặp là bạn có thể vượt quá kích thước các cột varchar hoặc nvarchar mà không bị phạt.
Giả sử bạn đang lưu trữ địa chỉ e-mail. Trong kiếp trước, tôi đã xử lý vấn đề này khá nhiều - vào thời điểm đó, RFC 3696 tuyên bố rằng một địa chỉ e-mail có thể dài 320 ký tự (64chars @ 255chars). RFC mới hơn, # 5321, hiện thừa nhận rằng 254 ký tự là độ dài nhất mà một địa chỉ e-mail có thể có. Và nếu có ai trong số các bạn có địa chỉ lâu như vậy, thì có lẽ chúng ta nên trò chuyện. :-)
Bây giờ, cho dù bạn đi theo tiêu chuẩn cũ hay tiêu chuẩn mới, bạn phải ủng hộ khả năng ai đó sẽ sử dụng tất cả các ký tự được phép. Có nghĩa là bạn phải sử dụng 254 hoặc 320 ký tự. Nhưng những gì tôi đã thấy mọi người làm là không bận tâm đến việc nghiên cứu tiêu chuẩn, và chỉ cần giả định rằng họ cần hỗ trợ 1.000 ký tự, 4.000 ký tự hoặc thậm chí hơn thế nữa.
Vì vậy, hãy xem điều gì sẽ xảy ra khi chúng ta có các bảng có cột địa chỉ e-mail có kích thước khác nhau, nhưng lưu trữ cùng một dữ liệu:
CREATE TABLE dbo.Email_V320 ( id int IDENTITY PRIMARY KEY, email varchar(320) ); CREATE TABLE dbo.Email_V1000 ( id int IDENTITY PRIMARY KEY, email varchar(1000) ); CREATE TABLE dbo.Email_V4000 ( id int IDENTITY PRIMARY KEY, email varchar(4000) ); CREATE TABLE dbo.Email_Vmax ( id int IDENTITY PRIMARY KEY, email varchar(max) );
Bây giờ, hãy tạo 10.000 địa chỉ e-mail hư cấu từ siêu dữ liệu hệ thống và điền vào tất cả bốn bảng với cùng một dữ liệu:
INSERT dbo.Email_V320(email) SELECT TOP (10000) REPLACE(LEFT(LEFT(c.name, 64) + '@' + LEFT(o.name, 128) + '.com', 254), ' ', '') FROM sys.all_columns AS c INNER JOIN sys.all_objects AS o ON c.[object_id] = o.[object_id] INNER JOIN sys.all_columns AS c2 ON c.[object_id] = c2.[object_id] ORDER BY NEWID(); INSERT dbo.Email_V1000(email) SELECT email FROM dbo.Email_V320; INSERT dbo.Email_V4000(email) SELECT email FROM dbo.Email_V320; INSERT dbo.Email_Vmax (email) SELECT email FROM dbo.Email_V320; -- let's rebuild ALTER INDEX ALL ON dbo.Email_V320 REBUILD; ALTER INDEX ALL ON dbo.Email_V1000 REBUILD; ALTER INDEX ALL ON dbo.Email_V4000 REBUILD; ALTER INDEX ALL ON dbo.Email_Vmax REBUILD;
Để xác thực rằng mỗi bảng chứa chính xác cùng một dữ liệu:
SELECT AVG(LEN(email)), MAX(LEN(email)) FROM dbo.Email_<size>;
Tất cả bốn trong số đó mang lại 35 và 77 cho tôi; số dặm của bạn có thể thay đổi. Cũng hãy đảm bảo rằng tất cả bốn bảng chiếm cùng một số trang trên đĩa:
SELECT o.name, COUNT(p.[object_id])
FROM sys.objects AS o
CROSS APPLY sys.dm_db_database_page_allocations
(DB_ID(), o.object_id, 1, NULL, 'LIMITED') AS p
WHERE o.name LIKE N'Email[_]V[^2]%'
GROUP BY o.name; Tất cả bốn truy vấn đó đều mang lại 89 trang (một lần nữa, quãng đường của bạn có thể thay đổi).
Bây giờ, hãy thực hiện một truy vấn điển hình dẫn đến quét chỉ mục theo nhóm:
SELECT id, email FROM dbo.Email_<size>;
Nếu chúng ta xem xét những thứ như thời lượng, lượt đọc và chi phí ước tính, chúng đều có vẻ giống nhau:
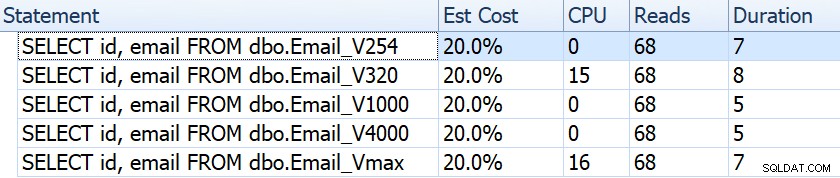
Điều này có thể ru mọi người vào một giả định sai lầm rằng không có tác động nào đến hiệu suất cả. Nhưng nếu chúng ta xem xét kỹ hơn một chút, trên chú giải công cụ để quét chỉ mục theo nhóm trong mỗi kế hoạch, chúng ta sẽ thấy sự khác biệt có thể xuất hiện trong các truy vấn khác, phức tạp hơn:

Từ đây chúng ta thấy rằng, định nghĩa cột càng lớn thì kích thước hàng và dữ liệu ước tính càng cao. Trong truy vấn đơn giản này, chi phí I / O (0,0512731) là như nhau trên tất cả các truy vấn, bất kể định nghĩa là gì, vì cách quét chỉ mục theo cụm phải đọc tất cả dữ liệu.
Nhưng có những tình huống khác trong đó hàng và tổng kích thước dữ liệu ước tính này sẽ có tác động:các hoạt động yêu cầu tài nguyên bổ sung, chẳng hạn như sắp xếp. Hãy xem truy vấn vô lý này không phục vụ bất kỳ mục đích thực sự nào, ngoài việc yêu cầu nhiều thao tác sắp xếp:
SELECT /* V<size> */ ROW_NUMBER() OVER (PARTITION BY email ORDER BY email DESC),
email, REVERSE(email), SUBSTRING(email, 1, CHARINDEX('@', email))
FROM dbo.Email_V<size>
GROUP BY REVERSE(email), email, SUBSTRING(email, 1, CHARINDEX('@', email))
ORDER BY REVERSE(email), email; Chúng tôi chạy bốn truy vấn này và chúng tôi thấy các kế hoạch đều giống như sau:

Tuy nhiên, biểu tượng cảnh báo đó trên toán tử CHỌN chỉ xuất hiện trên bảng 4000 / max. Cảnh báo là gì? Đó là cảnh báo cấp bộ nhớ quá mức, được giới thiệu trong SQL Server 2016. Đây là cảnh báo cho varchar (4000):

Và đối với varchar (max):

Hãy xem xét kỹ hơn một chút và xem điều gì đang xảy ra, ít nhất là theo sys.dm_exec_query_stats:
SELECT [table] = SUBSTRING(t.[text], 1, CHARINDEX(N'*/', t.[text])), s.last_elapsed_time, s.last_grant_kb, s.max_ideal_grant_kb FROM sys.dm_exec_query_stats AS s CROSS APPLY sys.dm_exec_sql_text(s.sql_handle) AS t WHERE t.[text] LIKE N'%/*%dbo.'+N'Email_V%' ORDER BY s.last_grant_kb;
Kết quả:

Trong trường hợp của tôi, thời lượng không bị ảnh hưởng bởi sự khác biệt về cấp bộ nhớ (ngoại trừ trường hợp tối đa), nhưng bạn có thể thấy rõ ràng tiến trình tuyến tính trùng với kích thước đã khai báo của cột. Cái mà bạn có thể sử dụng để ngoại suy những gì sẽ xảy ra trên một hệ thống không đủ bộ nhớ. Hoặc một truy vấn phức tạp hơn đối với một tập dữ liệu lớn hơn nhiều. Hoặc đồng thời đáng kể. Bất kỳ tình huống nào trong số đó đều có thể yêu cầu tràn để xử lý các hoạt động sắp xếp và kết quả là thời lượng gần như chắc chắn sẽ bị ảnh hưởng.
Nhưng những khoản tài trợ bộ nhớ lớn hơn này đến từ đâu? Hãy nhớ rằng, đó là cùng một truy vấn, dựa trên cùng một dữ liệu chính xác. Vấn đề là, đối với các hoạt động nhất định, SQL Server phải tính đến lượng dữ liệu * có thể * trong một cột. Nó không làm điều này dựa trên việc thực sự phân tích dữ liệu và nó không thể đưa ra bất kỳ giả định nào dựa trên các giá trị bước biểu đồ <=201. Thay vào đó, nó phải ước tính rằng mọi hàng chứa một nửa giá trị của kích thước cột đã khai báo . Vì vậy, đối với varchar (4000), nó giả sử mỗi địa chỉ e-mail dài 2.000 ký tự.
Khi không thể có một địa chỉ e-mail dài hơn 254 hoặc 320 ký tự, thì không có gì có được bằng cách định cỡ quá mức và có rất nhiều thứ có thể bị mất. Việc tăng kích thước của cột có chiều rộng thay đổi sau này dễ dàng hơn nhiều so với việc giải quyết tất cả các nhược điểm hiện tại.
Tất nhiên, kích thước quá lớn char hoặc nchar các cột có thể có nhiều hình phạt rõ ràng hơn.



