Là một nhà tư vấn làm việc với SQL Server, nhiều lần tôi được yêu cầu xem xét một máy chủ có vẻ như nó đang gặp vấn đề về hiệu suất. Trong khi thực hiện phân tích trên máy chủ, tôi hỏi một số câu hỏi nhất định, chẳng hạn như:mức sử dụng CPU bình thường của bạn là gì, độ trễ đĩa trung bình của bạn là gì, mức sử dụng bộ nhớ bình thường của bạn là gì, v.v. Câu trả lời thường là, "chúng tôi không biết" hoặc "chúng tôi không nắm bắt thông tin đó thường xuyên." Không có đường cơ sở gần đây khiến bạn rất khó biết hành vi bất thường trông như thế nào. Nếu bạn không biết hành vi bình thường là gì, làm sao bạn biết chắc mọi thứ tốt hơn hay tệ hơn? Tôi thường sử dụng các biểu thức, "nếu bạn không theo dõi nó, bạn không thể đo lường nó," và "nếu bạn không đo lường nó, bạn không thể quản lý nó."
Từ góc độ giám sát, tối thiểu, các tổ chức phải giám sát các công việc không thành công như sao lưu, duy trì chỉ mục, DBCC CHECKDB và bất kỳ công việc quan trọng nào khác. Thật dễ dàng để thiết lập thông báo lỗi cho những điều này; tuy nhiên bạn cũng cần có một quy trình để đảm bảo các công việc đang chạy như mong đợi. Tôi đã thấy những công việc bị treo và không bao giờ hoàn thành. Thông báo lỗi sẽ không kích hoạt cảnh báo vì công việc không bao giờ thành công hoặc không thành công.
Từ đường cơ sở về hiệu suất, có một số chỉ số chính cần được nắm bắt. Tôi đã tạo một quy trình mà tôi sử dụng với khách hàng để nắm bắt các chỉ số chính một cách thường xuyên và lưu trữ các giá trị đó trong cơ sở dữ liệu người dùng. Quy trình của tôi rất đơn giản:một cơ sở dữ liệu chuyên dụng với các thủ tục được lưu trữ đang sử dụng các tập lệnh phổ biến để chèn các tập kết quả vào bảng. Tôi có các công việc Đại lý SQL để chạy các thủ tục được lưu trữ định kỳ và một tập lệnh dọn dẹp để xóa dữ liệu cũ hơn X ngày. Các chỉ số tôi luôn nắm bắt bao gồm:
Kỳ vọng về Tuổi thọ của Trang :PLE có lẽ là một trong những cách tốt nhất để đánh giá xem hệ thống của bạn có đang bị áp lực bộ nhớ trong hay không. Hầu hết các hệ thống có giá trị PLE dao động trong khối lượng công việc bình thường. Tôi muốn tìm hiểu các giá trị này để biết giá trị tối thiểu, trung bình và tối đa là bao nhiêu. Tôi muốn cố gắng hiểu điều gì đã khiến PLE giảm trong những thời điểm nhất định trong ngày để xem liệu những quy trình đó có thể được điều chỉnh hay không. Nhiều lần, ai đó đang quét bảng và làm sạch vùng đệm. Có thể lập chỉ mục chính xác các truy vấn đó có thể giúp ích. Chỉ cần đảm bảo rằng bạn đang theo dõi đúng bộ đếm PLE - xem tại đây .
Sử dụng CPU :Có một đường cơ sở cho việc sử dụng CPU cho bạn biết liệu hệ thống của bạn có đột ngột bị áp lực CPU hay không. Thông thường, khi người dùng phàn nàn về các vấn đề hiệu suất, họ sẽ quan sát thấy CPU có vẻ cao. Ví dụ:nếu CPU dao động ở mức 80%, họ có thể nhận thấy điều đó liên quan, tuy nhiên nếu CPU cũng ở mức 80% trong cùng thời gian vào các tuần trước khi không có sự cố nào được báo cáo, thì khả năng CPU là sự cố là rất thấp. CPU xu hướng không chỉ để bắt khi CPU tăng đột biến và luôn ở giá trị cao nhất quán. Tôi có rất nhiều câu chuyện về thời điểm tôi bị đưa vào một cầu nối hội nghị nghiêm trọng vì có vấn đề với đơn đăng ký. Là DBA, tôi đã đội chiếc mũ “Người chấp nhận đổ lỗi mặc định”. Khi nhóm ứng dụng cho biết có sự cố với cơ sở dữ liệu, tôi phải chứng minh rằng không phải vậy, máy chủ cơ sở dữ liệu có tội cho đến khi được chứng minh là vô tội. Tôi nhớ lại rõ ràng một sự cố trong đó nhóm ứng dụng tin rằng máy chủ cơ sở dữ liệu đang gặp sự cố vì người dùng không thể kết nối. Họ đã đọc trên internet rằng SQL Server có thể bị chết đói nhóm luồng nếu nó từ chối kết nối. Tôi nhảy lên máy chủ và bắt đầu xem xét các tài nguyên, và những tiến trình nào hiện đang chạy. Trong vòng vài phút, tôi đã báo cáo lại rằng máy chủ được đề cập rất chán. Dựa trên các số liệu cơ bản của chúng tôi, CPU thường ở mức 60% và nó ở chế độ nhàn rỗi khoảng 20%, tuổi thọ trang cao hơn bình thường một cách đáng kể và không có hiện tượng khóa hoặc chặn xảy ra, I / O trông tuyệt vời, không có lỗi trong bất kỳ nhật ký nào và số lượng phiên là khoảng 1/3 so với số lượng bình thường của họ. Sau đó, tôi đưa ra nhận xét, "Có vẻ như người dùng thậm chí không đến được máy chủ cơ sở dữ liệu." Điều đó đã thu hút sự chú ý của những người trong mạng và họ nhận ra rằng một thay đổi mà họ thực hiện đối với bộ cân bằng tải không hoạt động bình thường và họ xác định rằng hơn 50% kết nối đang được định tuyến không chính xác và không đến được máy chủ cơ sở dữ liệu. Nếu tôi không biết đường cơ sở là gì, chúng tôi sẽ mất nhiều thời gian hơn để đạt được giải pháp.
I / O đĩa :Việc nắm bắt các số liệu đĩa là rất quan trọng. DMV sys.dm_io_virtual_file_stats được tích lũy kể từ lần khởi động lại máy chủ cuối cùng. Việc nắm bắt độ trễ I / O của bạn trong một khoảng thời gian sẽ cung cấp cho bạn thông tin cơ bản về mức độ bình thường trong thời gian đó. Việc dựa vào giá trị tích lũy có thể cung cấp cho bạn dữ liệu sai lệch từ các hoạt động sau giờ làm việc hoặc trong thời gian dài mà hệ thống không hoạt động. Paul đã thảo luận rằng tại đây .
Kích thước tệp cơ sở dữ liệu :Việc kiểm kê cơ sở dữ liệu của bạn bao gồm kích thước tệp, kích thước đã sử dụng, dung lượng trống, v.v. có thể giúp bạn dự báo sự phát triển của cơ sở dữ liệu. Thông thường, tôi được yêu cầu dự báo lượng bộ nhớ cần thiết cho một máy chủ cơ sở dữ liệu trong năm tới. Không biết xu hướng tăng trưởng hàng tuần hoặc hàng tháng, tôi không có cách nào để đưa ra một con số một cách thông minh. Khi tôi bắt đầu theo dõi các giá trị này, tôi có thể xác định đúng xu hướng này. Ngoài xu hướng, tôi cũng có thể tìm thấy khi có sự tăng trưởng cơ sở dữ liệu bất ngờ. Khi tôi thấy sự tăng trưởng bất ngờ và điều tra, tôi thường thấy rằng ai đó đã sao chép một bảng để thực hiện một số thử nghiệm (vâng, trong quá trình sản xuất!) Hoặc thực hiện một số quy trình một lần khác. Theo dõi loại dữ liệu này và có thể phản hồi khi xảy ra bất thường, giúp cho thấy rằng bạn chủ động và giám sát hệ thống của mình.
Chờ thống kê :Theo dõi số liệu thống kê về thời gian chờ có thể giúp bạn bắt đầu tìm ra nguyên nhân của một số vấn đề về hiệu suất nhất định. Nhiều DBA mới lo ngại khi họ lần đầu tiên bắt đầu nghiên cứu thống kê chờ và không nhận ra rằng các lần chờ luôn xảy ra và đó chỉ là cách mà hệ thống lập lịch của SQL Server hoạt động. Ngoài ra còn có rất nhiều sự chờ đợi có thể được coi là lành tính, hoặc hầu hết là vô hại. Paul Randal loại trừ những sự chờ đợi chủ yếu là vô hại này trong kịch bản thống kê thời gian chờ đợi phổ biến của mình. Paul cũng đã xây dựng một thư viện rộng lớn gồm nhiều kiểu chờ khác nhau và các lớp chốt với các mô tả và thông tin khác về cách khắc phục sự cố chờ và chốt.
Tôi đã ghi lại quá trình thu thập dữ liệu của mình và bạn có thể tìm thấy mã trên blog của tôi . Tùy thuộc vào tình huống và loại vấn đề mà khách hàng có thể gặp phải, tôi cũng có thể muốn nắm bắt các số liệu bổ sung. Glenn Berry đã viết blog về một quy trình mà anh ấy đã tổng hợp lại để ghi lại Số lượng tác vụ trung bình, Số lượng tác vụ có thể chạy trung bình, Số lượng I / O đang chờ xử lý, mức sử dụng CPU của quy trình SQL Server và Thời gian sử dụng trang trung bình trên tất cả NUMA nút. Tìm kiếm nhanh trên internet sẽ đưa ra một số quy trình thu thập dữ liệu khác mà mọi người đã chia sẻ, thậm chí cả SQL Server Tiger Team có một quy trình sử dụng T-SQL và PowerShell.
Sử dụng cơ sở dữ liệu tùy chỉnh và xây dựng gói thu thập dữ liệu của riêng bạn là một giải pháp hợp lệ để nắm bắt đường cơ sở, nhưng hầu hết chúng ta không có kinh nghiệm trong việc xây dựng các giải pháp giám sát SQL Server đầy đủ. Còn nhiều hơn thế nữa sẽ hữu ích để nắm bắt, những thứ như truy vấn chạy dài, truy vấn hàng đầu và thủ tục được lưu trữ dựa trên bộ nhớ, I / O và CPU, deadlock, phân mảnh chỉ mục, giao dịch mỗi giây, v.v. Vì vậy, tôi luôn khuyên khách hàng nên mua công cụ giám sát của bên thứ ba. Các nhà cung cấp này chuyên cập nhật các xu hướng và tính năng mới nhất của SQL Server để bạn có thể tập trung thời gian vào việc đảm bảo SQL Server ổn định và nhanh nhất có thể.
Các giải pháp như SQL Sentry (dành cho SQL Server) và DB Sentry (dành cho Cơ sở dữ liệu Azure SQL) nắm bắt tất cả các số liệu này cho bạn và cho phép bạn dễ dàng tạo các đường cơ sở khác nhau. Bạn có thể có một đường cơ sở bình thường, cuối tháng, cuối quý và hơn thế nữa. Sau đó, bạn có thể áp dụng đường cơ sở và xem mọi thứ khác nhau một cách trực quan. Quan trọng hơn, bạn có thể định cấu hình bất kỳ số lượng cảnh báo nào cho các điều kiện khác nhau và được thông báo khi các chỉ số vượt quá ngưỡng của bạn.
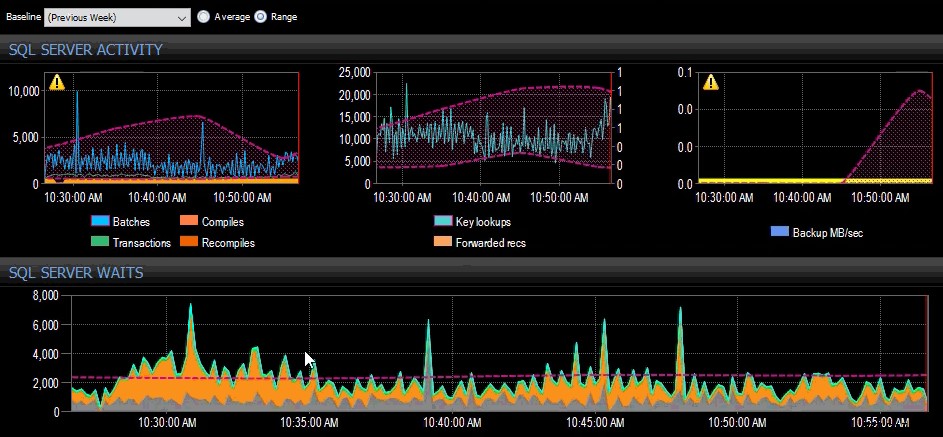 Đường cơ sở của tuần trước áp dụng cho một số chỉ số SQL Server trên bảng điều khiển SQL Sentry.
Đường cơ sở của tuần trước áp dụng cho một số chỉ số SQL Server trên bảng điều khiển SQL Sentry.
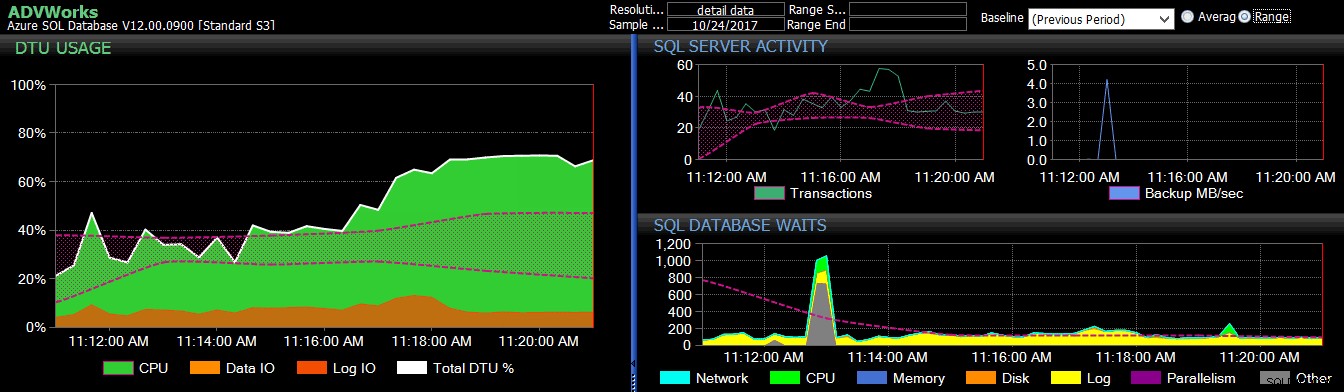 Đường cơ sở của giai đoạn trước được áp dụng cho một số chỉ số Cơ sở dữ liệu Azure SQL trên trang tổng quan DB Sentry.
Đường cơ sở của giai đoạn trước được áp dụng cho một số chỉ số Cơ sở dữ liệu Azure SQL trên trang tổng quan DB Sentry.
Để biết thêm thông tin về đường cơ sở trong SentryOne, hãy xem các bài đăng này trên blog nhóm của họ hoặc video 2 phút Thứ Ba này . Quan tâm đến việc tải xuống bản dùng thử? Họ cũng đã giúp bạn ở đó .