Bài viết này là bài thứ hai trong loạt bài về các ngưỡng tối ưu hóa liên quan đến nhóm và tổng hợp dữ liệu. Trong Phần 1, tôi đã cung cấp công thức được thiết kế ngược cho chi phí nhà điều hành Tổng hợp Luồng. Tôi đã giải thích rằng toán tử này cần sử dụng các hàng được sắp xếp theo tập hợp nhóm (bất kỳ thứ tự nào của các thành viên của nó) và khi dữ liệu được lấy được sắp xếp trước từ một chỉ mục, bạn sẽ nhận được tỷ lệ tuyến tính đối với số hàng và số lượng các nhóm. Ngoài ra, không cần cấp bộ nhớ trong trường hợp như vậy.
Trong bài viết này, tôi tập trung vào chi phí và quy mô của hoạt động dựa trên tổng hợp luồng khi dữ liệu không được sắp xếp trước từ một chỉ mục, thay vào đó, phải được sắp xếp trước.
Trong các ví dụ của tôi, tôi sẽ sử dụng cơ sở dữ liệu mẫu PerformanceV3, giống như trong Phần 1. Bạn có thể tải xuống tập lệnh tạo và điền cơ sở dữ liệu này từ đây. Trước khi bạn chạy các ví dụ từ bài viết này, hãy đảm bảo rằng bạn chạy mã sau trước tiên để giảm một vài chỉ mục không cần thiết:
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders; DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
Hai chỉ mục duy nhất nên được để lại trên bảng này là idx_cl_od (nhóm với orderdate làm khóa) và PK_Orders (không phân biệt với orderid là chìa khóa).
Sắp xếp + Tổng hợp luồng
Trọng tâm của bài viết này là thử và tìm ra quy mô hoạt động tổng hợp luồng như thế nào khi dữ liệu không được sắp xếp trước bởi tập hợp nhóm. Vì toán tử Tổng hợp Luồng phải xử lý các hàng được sắp xếp theo thứ tự, nếu chúng không được sắp xếp trước trong một chỉ mục, thì kế hoạch phải bao gồm một toán tử Sắp xếp rõ ràng. Vì vậy, chi phí của hoạt động tổng hợp mà bạn nên tính đến là tổng chi phí của các toán tử Tổng hợp Phân loại + Luồng.
Tôi sẽ sử dụng truy vấn sau (chúng tôi sẽ gọi nó là Truy vấn 1) để chứng minh một kế hoạch liên quan đến việc tối ưu hóa như vậy:
CHỌN shipperid, MAX (ngày đặt hàng) NHƯ maxod TỪ (CHỌN ĐẦU (100) * TỪ dbo.Orders) NHƯ D NHÓM THEO shipperid;
Kế hoạch cho truy vấn này được thể hiện trong Hình 1.

Hình 1:Kế hoạch cho Truy vấn 1
Lý do tôi sử dụng biểu thức bảng với bộ lọc TOP là để kiểm soát số lượng chính xác các hàng (ước tính) liên quan đến nhóm và tổng hợp. Việc áp dụng các thay đổi có kiểm soát giúp dễ dàng thử và thiết kế ngược các công thức tính giá thành.
Nếu bạn đang thắc mắc tại sao lại lọc một số lượng nhỏ hàng như vậy trong ví dụ này, thì điều đó có liên quan đến các ngưỡng tối ưu hóa khiến chiến lược này được ưu tiên hơn so với thuật toán Hash Aggregate. Trong Phần 3, tôi sẽ mô tả chi phí và quy mô của phương án băm. Trong trường hợp trình tối ưu hóa không tự chọn thao tác tổng hợp luồng, ví dụ:khi có nhiều hàng liên quan, bạn luôn có thể buộc nó bằng gợi ý TÙY CHỌN (NHÓM ĐƠN HÀNG) trong quá trình nghiên cứu. Khi tập trung vào chi phí của các kế hoạch nối tiếp, rõ ràng bạn có thể thêm gợi ý MAXDOP 1 để loại bỏ tính song song.
Như đã đề cập, để đánh giá chi phí và quy mô của thuật toán tổng hợp luồng không có thứ tự, bạn cần tính đến tổng các toán tử Sắp xếp + Tổng hợp luồng. Bạn đã biết công thức tính giá cho toán tử Tổng hợp Luồng từ Phần 1:
@numrows * 0,0000006 + @numgroups * 0,0000005Trong truy vấn của chúng tôi, chúng tôi có 100 hàng đầu vào ước tính và 5 nhóm đầu ra ước tính (5 ID người gửi hàng riêng biệt được ước tính dựa trên thông tin mật độ). Vì vậy, chi phí của nhà điều hành Tổng hợp Luồng trong kế hoạch của chúng tôi là:
100 * 0,0000006 + 5 * 0,0000005 =0,0000625Hãy thử và tìm ra công thức tính giá cho toán tử Sắp xếp. Hãy nhớ rằng, trọng tâm của chúng tôi là chi phí ước tính và tỷ lệ mở rộng bởi vì mục tiêu cuối cùng của chúng tôi là tìm ra các ngưỡng tối ưu hóa trong đó trình tối ưu hóa thay đổi lựa chọn của mình từ chiến lược này sang chiến lược khác.
Ước tính chi phí I / O dường như cố định:0,0112613. Tôi nhận được cùng một chi phí I / O bất kể các yếu tố như số hàng, số cột sắp xếp, kiểu dữ liệu, v.v. Đây có lẽ là lý do giải thích cho một số công việc I / O dự kiến.
Đối với chi phí CPU, than ôi, Microsoft không tiết lộ công khai các thuật toán chính xác mà họ sử dụng để phân loại. Tuy nhiên, trong số các thuật toán phổ biến được sử dụng để sắp xếp bởi các công cụ cơ sở dữ liệu nói chung là các cách triển khai khác nhau của sắp xếp hợp nhất và sắp xếp nhanh. Nhờ những nỗ lực của Paul White, người thích xem xét các dấu vết ngăn xếp trình gỡ lỗi Windows (không phải ai trong chúng ta cũng thích điều này), chúng tôi đã có thêm một chút thông tin chi tiết về chủ đề này, được xuất bản trong loạt bài của anh ấy “Internals of the Seven SQL Server Các loại. ” Theo phát hiện của Paul, lớp sắp xếp chung (được sử dụng trong kế hoạch ở trên) sử dụng sắp xếp hợp nhất (nội bộ đầu tiên, sau đó chuyển sang bên ngoài). Trung bình, thuật toán này yêu cầu n log n so sánh để sắp xếp n mục. Với suy nghĩ này, có lẽ khởi đầu là một đặt cược an toàn khi cho rằng phần CPU trong chi phí của nhà điều hành dựa trên một công thức như:
Chi phí CPU của người vận hành =Tất nhiên, đây có thể là đơn giản hóa của công thức tính giá thực tế mà Microsoft sử dụng, nhưng không có bất kỳ tài liệu nào về vấn đề này, đây là phỏng đoán tốt nhất ban đầu.
Tiếp theo, bạn có thể lấy chi phí CPU sắp xếp từ hai kế hoạch truy vấn được tạo ra để sắp xếp các số hàng khác nhau, chẳng hạn như 1000 và 2000, và dựa trên những thứ đó và công thức trên, thiết kế ngược lại chi phí so sánh và chi phí khởi động. Với mục đích này, bạn không cần phải sử dụng một truy vấn được nhóm lại; chỉ cần thực hiện một ORDER BY cơ bản là đủ. Tôi sẽ sử dụng hai truy vấn sau (chúng tôi sẽ gọi chúng là Truy vấn 2 và Truy vấn 3):
SELECT orderid% 1000000000 as myorderid FROM (SELECT TOP (1000) * FROM dbo.Orders) AS D ORDER BY myorderid; CHỌN orderid% 1000000000 dưới dạng myorderid TỪ (CHỌN ĐẦU (2000) * TỪ dbo.Orders) NHƯ D ĐẶT HÀNG THEO myorderid;
Điểm mấu chốt trong việc sắp xếp thứ tự theo kết quả của một phép tính là buộc sử dụng toán tử Sắp xếp trong kế hoạch.
Hình 2 cho thấy các phần liên quan của hai kế hoạch:
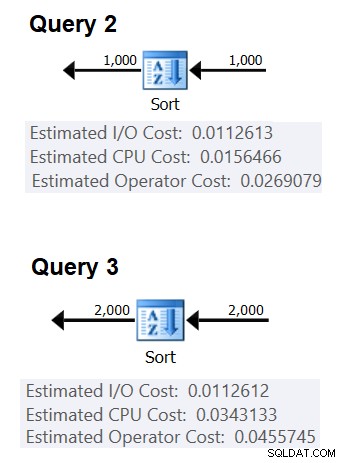
Hình 2:Kế hoạch cho Truy vấn 2 và Truy vấn 3
Để thử và suy ra chi phí của một phép so sánh, bạn sẽ sử dụng công thức sau:
chi phí so sánh =
(( ) - ( ))
/ (
(0,0343133 - 0,0156466) / (2000 * LOG (2000) - 1000 * LOG (1000)) = 2.25061348918698E-06
Đối với chi phí khởi động, bạn có thể suy ra nó dựa trên một trong hai kế hoạch, ví dụ:dựa trên kế hoạch sắp xếp 2000 hàng:
chi phí khởi động =0,0343133 - 2000 * LOG (2000) * 2.25061348918698E-06 = 9.99127891201865E-05
Và do đó công thức Phân loại chi phí CPU của chúng tôi trở thành:
Phân loại chi phí CPU của nhà điều hành =9.99127891201865E-05 + @numrows * LOG (@numrows) * 2.25061348918698E-06Sử dụng các kỹ thuật tương tự, bạn sẽ thấy rằng các yếu tố như kích thước hàng trung bình, số lượng cột sắp xếp và kiểu dữ liệu của chúng không ảnh hưởng đến chi phí CPU sắp xếp ước tính. Yếu tố duy nhất có vẻ có liên quan là số lượng hàng ước tính. Lưu ý rằng việc sắp xếp sẽ cần cấp bộ nhớ và cấp này tỷ lệ thuận với số hàng (không phải nhóm) và kích thước hàng trung bình. Nhưng trọng tâm của chúng tôi hiện tại là chi phí điều hành ước tính và có vẻ như ước tính này chỉ bị ảnh hưởng bởi số lượng hàng ước tính.
Công thức này dường như dự đoán chi phí CPU cao đến ngưỡng khoảng 5.000 hàng. Hãy thử nó với các số sau:100, 200, 300, 400, 500, 1000, 2000, 3000, 4000, 5000:
SELECT số, 9.99127891201865E-05 + số * LOG (numrows) * 2.25061348918698E-06 NHƯ chi phí dự đoán TỪ (VALUES (100), (200), (300), (400), (500), (1000) , (2000), (3000), (4000), (5000)) AS D (số);
So sánh những gì công thức dự đoán và chi phí CPU ước tính mà kế hoạch hiển thị cho các truy vấn sau:
SELECT orderid% 1000000000 as myorderid FROM (SELECT TOP (100) * FROM dbo.Orders) AS D ORDER BY myorderid; CHỌN orderid% 1000000000 dưới dạng myorderid TỪ (CHỌN ĐẦU (200) * TỪ dbo.Orders) NHƯ D ĐẶT HÀNG THEO myorderid; CHỌN orderid% 1000000000 dưới dạng myorderid TỪ (CHỌN ĐẦU (300) * TỪ dbo.Orders) NHƯ D ĐẶT HÀNG THEO myorderid; CHỌN orderid% 1000000000 dưới dạng myorderid TỪ (CHỌN ĐẦU (400) * TỪ dbo.Orders) NHƯ D ĐẶT HÀNG THEO myorderid; SELECT orderid% 1000000000 as myorderid FROM (SELECT TOP (500) * FROM dbo.Orders) NHƯ D ĐẶT HÀNG THEO myorderid; CHỌN orderid% 1000000000 dưới dạng myorderid TỪ (CHỌN ĐẦU (1000) * TỪ dbo.Orders) NHƯ D ĐẶT HÀNG THEO myorderid; SELECT orderid% 1000000000 as myorderid FROM (SELECT TOP (2000) * FROM dbo.Orders) AS D ORDER BY myorderid; CHỌN orderid% 1000000000 dưới dạng myorderid TỪ (CHỌN ĐẦU (3000) * TỪ dbo.Orders) NHƯ D ĐẶT HÀNG THEO myorderid; CHỌN orderid% 1000000000 dưới dạng myorderid TỪ (CHỌN ĐẦU (4000) * TỪ dbo.Orders) NHƯ D ĐẶT HÀNG THEO myorderid; CHỌN orderid% 1000000000 dưới dạng myorderid TỪ (CHỌN ĐẦU (5000) * TỪ dbo.Orders) NHƯ D ĐẶT HÀNG THEO myorderid;
Tôi nhận được các kết quả sau:
numrows tỷ lệ chi phí ước tính dự đoán ----------------- ---------------- ---- 100 0,0011363 0,0011365 1.00018 200 0,0024848 0,0024849 1,00004 300 0,0039510 0,0039511 1,00003 400 0,0054937 0,0054938 1,00002 500 0,0070933 0,0070933 1,00000 1000 0,0156466 0,0156466 1,00000 2000 0,0343133 0,034663133 1,00000 3000 0,0549594 0,09594 0,0954Cột dự đoán chi phí hiển thị dự đoán dựa trên công thức được thiết kế ngược của chúng tôi, cột ước tính chi phí hiển thị chi phí ước tính xuất hiện trong kế hoạch và tỷ lệ cột hiển thị tỷ lệ giữa kế hoạch sau và kế hoạch trước.
Dự đoán có vẻ khá chính xác lên đến 5.000 hàng. Tuy nhiên, với những con số lớn hơn 5.000, công thức được thiết kế ngược của chúng tôi sẽ ngừng hoạt động tốt. Truy vấn sau cung cấp cho bạn các dự đoán cho các hàng 6K, 7K, 10K, 20K, 100K và 200K:
SELECT số, 9.99127891201865E-05 + số * LOG (numrows) * 2.25061348918698E-06 NHƯ chi phí dự đoán TỪ (VALUES (6000), (7000), (10000), (20000), (100000), (200000) ) NHƯ D (số);Sử dụng các truy vấn sau để nhận chi phí CPU ước tính từ các gói (lưu ý gợi ý để bắt buộc một gói nối tiếp vì với số lượng hàng lớn hơn, nhiều khả năng bạn sẽ nhận được một kế hoạch song song trong đó các công thức chi phí được điều chỉnh cho song song):
SELECT orderid% 1000000000 as myorderid FROM (SELECT TOP (6000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION (MAXDOP 1); CHỌN orderid% 1000000000 dưới dạng myorderid TỪ (CHỌN ĐẦU (7000) * TỪ dbo.Orders) NHƯ D ĐẶT HÀNG THEO TÙY CHỌN myorderid (MAXDOP 1); CHỌN orderid% 1000000000 dưới dạng myorderid TỪ (CHỌN ĐẦU (10000) * TỪ dbo.Orders) NHƯ D ĐẶT HÀNG THEO TÙY CHỌN myorderid (MAXDOP 1); CHỌN orderid% 1000000000 dưới dạng myorderid TỪ (CHỌN ĐẦU (20000) * TỪ dbo.Orders) NHƯ D ĐẶT HÀNG THEO TÙY CHỌN myorderid (MAXDOP 1); CHỌN orderid% 1000000000 dưới dạng myorderid TỪ (CHỌN ĐẦU (100000) * TỪ dbo.Orders) NHƯ D ĐẶT HÀNG THEO TÙY CHỌN myorderid (MAXDOP 1); CHỌN orderid% 1000000000 dưới dạng myorderid TỪ (CHỌN ĐẦU (200000) * TỪ dbo.Orders) NHƯ D ĐẶT HÀNG THEO TÙY CHỌN myorderid (MAXDOP 1);Tôi nhận được các kết quả sau:
numrows tỷ lệ chi phí ước tính dự đoán ----------------- ---------------- --- 6000 0,117575 0,160970 1,3691 7000 0,139583 0,244848 1,7541 10000 0,207389 0,603420 2,9096 20000 0,445878 1,311710 2,9419 100000 2,591210 7,623920 2,9422 200000 5,494330 16.165700 2,9423Như bạn có thể thấy, vượt quá 5.000 hàng, công thức của chúng tôi ngày càng trở nên kém chính xác hơn, nhưng thật kỳ lạ, tỷ lệ chính xác ổn định trên khoảng 2,94 ở khoảng 20.000 hàng. Điều này ngụ ý rằng với số lượng lớn, công thức của chúng tôi vẫn được áp dụng, chỉ với chi phí so sánh cao hơn và khoảng từ 5.000 đến 20.000 hàng, nó chuyển dần từ chi phí so sánh thấp hơn sang chi phí so sánh cao hơn. Nhưng điều gì có thể giải thích sự khác biệt giữa quy mô nhỏ và quy mô lớn? Tin tốt là câu trả lời không phức tạp bằng việc dung hòa giữa cơ học lượng tử và thuyết tương đối rộng với lý thuyết dây. Chỉ là ở quy mô nhỏ hơn, Microsoft muốn tính đến thực tế là bộ nhớ đệm CPU có khả năng được sử dụng và vì mục đích chi phí, họ giả định kích thước bộ nhớ cache cố định.
Vì vậy, để tính toán chi phí so sánh ở quy mô lớn, bạn muốn sử dụng phân loại chi phí CPU từ hai gói cho các con số trên 20.000. Tôi sẽ sử dụng 100.000 và 200.000 hàng (hai hàng cuối cùng trong bảng trên). Dưới đây là công thức để suy ra chi phí so sánh:
chi phí so sánh =
(16.1657 - 7.62392) / (200000 * LOG (200000) - 100000 * LOG (100000)) = 6.62193536908588E-06Tiếp theo, đây là công thức để suy ra chi phí khởi động dựa trên kế hoạch cho 200.000 hàng:
chi phí khởi động =
16.1657 - 200000 * LOG (200000) * 6.62193536908588E-06 = 1.35166186417734E-04Rất có thể chi phí khởi động cho các quy mô nhỏ và lớn là như nhau, và sự khác biệt mà chúng tôi nhận được là do lỗi làm tròn. Ở bất kỳ mức độ nào, với số lượng hàng lớn, chi phí khởi động trở nên không đáng kể so với chi phí của các so sánh.
Tóm lại, đây là công thức cho chi phí CPU của toán tử Sắp xếp cho các số lớn (> =20000):
Chi phí CPU của nhà điều hành =1.35166186417734E-04 + @numrows * LOG (@numrows) * 6.62193536908588E-06Hãy kiểm tra độ chính xác của công thức với hàng 500K, 1 triệu và 10 triệu. Đoạn mã sau cung cấp cho bạn các dự đoán của công thức của chúng tôi:
SELECT số, 1.35166186417734E-04 + số * LOG (numrows) * 6.62193536908588E-06 AS dự đoán từ (VALUES (500000), (1000000), (10000000)) AS D (số);Sử dụng các truy vấn sau để nhận chi phí CPU ước tính:
SELECT orderid% 1000000000 as myorderid FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION (MAXDOP 1); CHỌN orderid% 1000000000 dưới dạng myorderid TỪ (CHỌN ĐẦU (1000000) * TỪ dbo.Orders) NHƯ D ĐẶT HÀNG THEO TÙY CHỌN myorderid (MAXDOP 1); CHỌN CHECKSUM (NEWID ()) làm myorderid TỪ (CHỌN ĐẦU (10000000) O1.orderid TỪ dbo. Đơn đặt hàng NHƯ O1 CHÉO THAM GIA dbo. Đơn hàng NHƯ O2) NHƯ D ĐƠN HÀNG THEO TÙY CHỌN myorderid (MAXDOP 1);Tôi nhận được các kết quả sau:
numrows tỷ lệ chi phí ước tính dự đoán ----------------- ---------------- --- 500000 43.4479 43.448 1.0000 1000000 91.4856 91.486 1.0000 10000000 1067.3300 1067.340 1.0000Có vẻ như công thức của chúng tôi cho các số lớn hoạt động khá tốt.
Kết hợp tất cả lại với nhau
Tổng chi phí áp dụng tổng hợp luồng có sắp xếp rõ ràng cho số lượng hàng nhỏ (<=5.000 hàng) là:
+ + =
0,0112613
+ 9.99127891201865E-05 + @numrows * LOG (@ numrows) * 2.25061348918698E-06
+ @numrows * 0.0000006 + @numgroups * 0.0000005Hình 3 có một biểu đồ khu vực cho thấy chi phí này quy mô như thế nào.
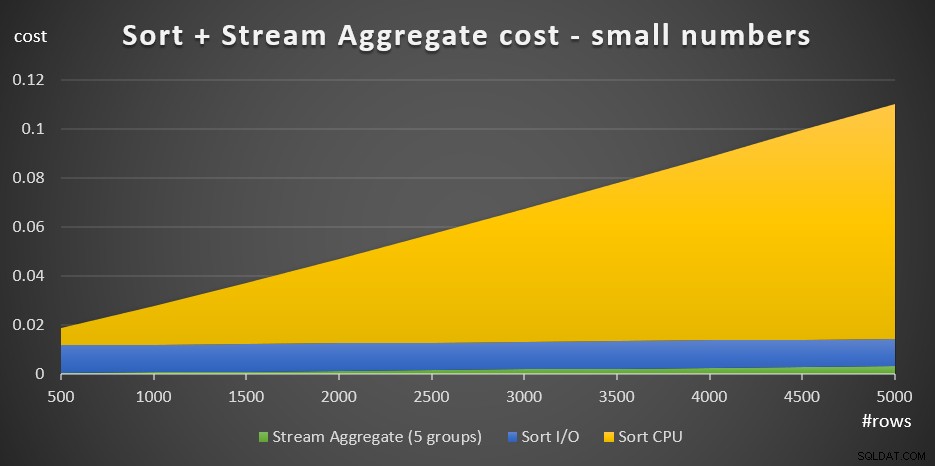
Hình 3:Chi phí Sắp xếp + Tổng hợp Luồng cho một số lượng nhỏ hàngChi phí CPU sắp xếp là phần quan trọng nhất trong tổng chi phí tổng hợp của Sắp xếp + Luồng. Tuy nhiên, với số lượng hàng nhỏ, chi phí Tổng hợp Luồng và Phần I / O Sắp xếp của chi phí không hoàn toàn không đáng kể. Về mặt hình ảnh, bạn có thể thấy rõ cả ba phần trong biểu đồ.
Đối với số lượng hàng lớn (> =20.000), công thức tính giá là:
0,0112613
+ 1,35166186417734E-04 + @numrows * LOG (@numrows) * 6,62193536908588E-06
+ @numrows * 0,0000006 + @numgroups * 0,0000005Tôi không thấy nhiều giá trị trong việc theo đuổi cách thức chính xác để so sánh chi phí chuyển đổi từ quy mô nhỏ sang quy mô lớn.
Hình 4 có một biểu đồ khu vực cho thấy quy mô chi phí đối với số lượng lớn như thế nào.
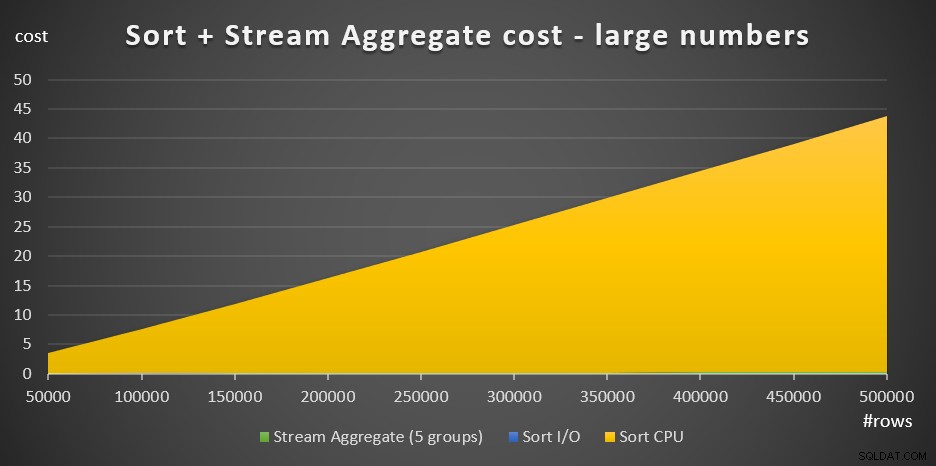
Hình 4:Chi phí Sắp xếp + Tổng hợp Luồng cho số lượng lớn hàngVới số lượng hàng lớn, chi phí Tổng hợp luồng và chi phí I / O Sắp xếp không đáng kể so với chi phí CPU Sắp xếp đến mức chúng thậm chí không thể nhìn thấy bằng mắt thường trong biểu đồ. Ngoài ra, một phần chi phí CPU Sort được quy cho công việc khởi động cũng không đáng kể. Do đó, phần duy nhất của phép tính chi phí thực sự có ý nghĩa là tổng chi phí so sánh:
@numrows * LOG (@numrows) *Điều này có nghĩa là khi bạn cần đánh giá quy mô của chiến lược Sắp xếp + Tổng hợp luồng, bạn có thể đơn giản hóa nó cho riêng phần chi phối này. Ví dụ:nếu bạn cần đánh giá chi phí sẽ thay đổi như thế nào từ 100.000 hàng đến 100.000.000 hàng, bạn có thể sử dụng công thức (lưu ý rằng chi phí so sánh không liên quan):
(100000000 * LOG (100000000)*) / (100000 * LOG (100000)*) =1600Điều này cho bạn biết rằng khi số lượng hàng tăng từ 100.000 theo hệ số 1.000 lên 100.000.000, chi phí ước tính sẽ tăng theo hệ số 1.600.
Tỷ lệ từ 1.000.000 đến 1.000.000.000 hàng được tính như sau:
(1000000000 * LOG (1000000000)) / (1000000 * LOG (1000000)) =1500Nghĩa là, khi số lượng hàng tăng từ 1.000.000 với hệ số 1.000, chi phí ước tính tăng theo hệ số 1.500.
Đây là những nhận xét thú vị về cách quy mô của chiến lược Sắp xếp + Tổng hợp luồng. Do chi phí khởi động rất thấp và mở rộng quy mô tuyến tính bổ sung, bạn sẽ mong đợi chiến lược này hoạt động tốt với số lượng hàng rất nhỏ, nhưng không tốt với số lượng lớn. Ngoài ra, thực tế là toán tử Tổng hợp luồng chỉ đại diện cho một phần nhỏ của chi phí so với khi cần sắp xếp, cho bạn biết rằng bạn có thể nhận được hiệu suất tốt hơn đáng kể nếu tình huống là bạn có thể tạo chỉ mục hỗ trợ .
Trong phần tiếp theo của loạt bài này, tôi sẽ đề cập đến quy mô của thuật toán Hash Aggregate. Nếu bạn thích bài tập này về việc cố gắng tìm ra các công thức tính chi phí, hãy xem liệu bạn có thể tìm ra nó cho thuật toán này hay không. Điều quan trọng là tìm ra các yếu tố ảnh hưởng đến nó, cách nó mở rộng quy mô và điều kiện mà nó hoạt động tốt hơn các thuật toán khác.