Bài viết này là bài thứ ba trong loạt bài về các ngưỡng tối ưu hóa để nhóm và tổng hợp dữ liệu. Trong Phần 1, tôi đã đề cập đến thuật toán Tổng hợp luồng được sắp xếp trước. Trong Phần 2, tôi đã trình bày thuật toán Sắp xếp + Tổng hợp Luồng không theo thứ tự. Trong phần này, tôi đề cập đến thuật toán Hash Match (Aggregate), mà tôi sẽ gọi đơn giản là Hash Aggregate. Tôi cũng cung cấp bản tóm tắt và so sánh giữa các thuật toán mà tôi trình bày trong Phần 1, Phần 2 và Phần 3.
Tôi sẽ sử dụng cùng một cơ sở dữ liệu mẫu có tên là PerformanceV3, mà tôi đã sử dụng trong các bài viết trước của loạt bài này. Chỉ cần đảm bảo rằng trước khi bạn chạy các ví dụ trong bài viết, trước tiên bạn chạy đoạn mã sau để giảm một vài chỉ mục không cần thiết:
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders; DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
Hai chỉ mục duy nhất nên được để lại trên bảng này là idx_cl_od (nhóm với orderdate làm khóa) và PK_Orders (không gộp với orderid làm khóa).
Tổng hợp băm
Thuật toán Hash Aggregate sắp xếp các nhóm trong một bảng băm dựa trên một số hàm băm được chọn nội bộ. Không giống như thuật toán Tổng hợp luồng, thuật toán này không cần sử dụng các hàng theo thứ tự nhóm. Hãy xem xét truy vấn sau (chúng tôi sẽ gọi nó là Truy vấn 1) làm ví dụ (bắt buộc tổng hợp băm và một kế hoạch nối tiếp):
SELECT empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (HASH GROUP, MAXDOP 1);
Hình 1 cho thấy kế hoạch cho Truy vấn 1.
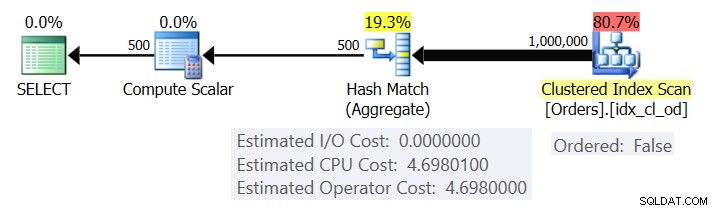
Hình 1:Kế hoạch cho Truy vấn 1
Kế hoạch quét các hàng từ chỉ mục được nhóm bằng cách sử dụng thuộc tính Có thứ tự:Sai (không bắt buộc phải quét để phân phối các hàng được sắp xếp theo khóa chỉ mục). Thông thường, trình tối ưu hóa sẽ thích quét chỉ mục bao phủ hẹp nhất, trong trường hợp của chúng tôi, đây là chỉ mục được phân nhóm. Kế hoạch xây dựng một bảng băm với các cột được nhóm và tổng hợp. Truy vấn của chúng tôi yêu cầu tổng hợp COUNT được gõ INT. Kế hoạch thực sự tính toán nó như một giá trị kiểu BIGINT, do đó, toán tử Tính vô hướng, áp dụng chuyển đổi ngầm định thành INT.
Microsoft không chia sẻ công khai các thuật toán băm mà họ sử dụng. Đây là công nghệ rất độc quyền. Tuy nhiên, để minh họa khái niệm, giả sử rằng SQL Server sử dụng hàm băm% 250 (modulo 250) cho truy vấn của chúng tôi ở trên. Trước khi xử lý bất kỳ hàng nào, bảng băm của chúng tôi có 250 nhóm đại diện cho 250 kết quả có thể có của hàm băm (0 đến 249). Khi SQL Server xử lý từng hàng, nó áp dụng hàm băm
orderid empid ------- ----- 320 3 30 5 660 253 820 3 850 1 1000 255 700 3 1240 253 350 4 400 255
Hình 2 cho thấy ba trạng thái của bảng băm:trước khi bất kỳ hàng nào được xử lý, sau khi 5 hàng đầu tiên được xử lý và sau khi 10 hàng đầu tiên được xử lý. Mỗi mục trong danh sách được liên kết chứa bộ giá trị (empid, COUNT (*)).
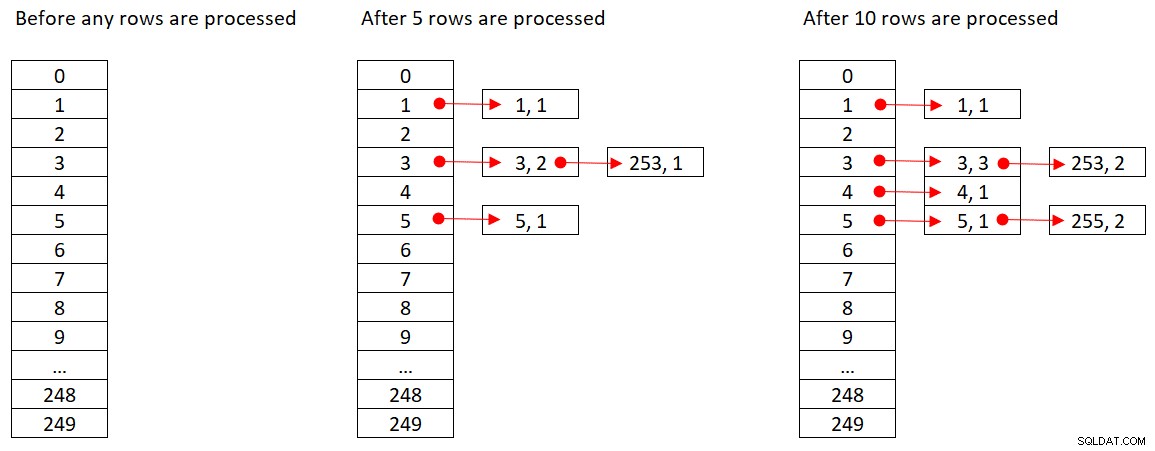
Hình 2:Trạng thái bảng băm
Khi toán tử Hash Aggregate hoàn thành việc sử dụng tất cả các hàng đầu vào, bảng băm có tất cả các nhóm có trạng thái cuối cùng của tổng hợp.
Giống như toán tử Sắp xếp, toán tử Hash Aggregate yêu cầu cấp bộ nhớ và nếu nó hết bộ nhớ, nó cần phải tràn sang tempdb; tuy nhiên, trong khi sắp xếp yêu cầu cấp bộ nhớ tỷ lệ với số hàng được sắp xếp, băm yêu cầu cấp bộ nhớ tỷ lệ với số nhóm. Vì vậy, đặc biệt khi tập hợp nhóm có mật độ cao (số lượng nhóm nhỏ), thuật toán này yêu cầu bộ nhớ ít hơn đáng kể so với khi yêu cầu sắp xếp rõ ràng.
Hãy xem xét hai truy vấn sau (gọi chúng là Truy vấn 1 và Truy vấn 2):
SELECT empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (HASH GROUP, MAXDOP 1); SELECT empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (ORDER GROUP, MAXDOP 1);
Hình 3 so sánh mức cấp bộ nhớ cho các truy vấn này.

Hình 3:Kế hoạch cho Truy vấn 1 và Truy vấn 2
Lưu ý sự khác biệt lớn giữa việc cấp bộ nhớ trong hai trường hợp.
Đối với chi phí của nhà điều hành Hash Aggregate, quay trở lại Hình 1, hãy lưu ý rằng không có chi phí I / O, thay vào đó chỉ có chi phí CPU. Tiếp theo, hãy thử thiết kế ngược lại công thức tính chi phí CPU bằng cách sử dụng các kỹ thuật tương tự như các kỹ thuật mà tôi đã trình bày trong các phần trước của loạt bài này. Các yếu tố có khả năng ảnh hưởng đến chi phí của nhà điều hành là số lượng hàng đầu vào, số lượng nhóm đầu ra, hàm tổng hợp được sử dụng và những gì bạn nhóm theo (số lượng của tập hợp nhóm, loại dữ liệu được sử dụng).
Bạn muốn toán tử này có chi phí khởi động để chuẩn bị cho việc xây dựng bảng băm. Bạn cũng sẽ mong đợi nó mở rộng quy mô tuyến tính theo số lượng hàng và nhóm. Đó thực sự là những gì tôi đã tìm thấy. Tuy nhiên, trong khi chi phí của cả toán tử Tổng hợp luồng và Sắp xếp không bị ảnh hưởng bởi những gì bạn nhóm theo, có vẻ như chi phí của toán tử Tổng hợp băm — cả về bản số của tập hợp nhóm và kiểu dữ liệu được sử dụng.
Để quan sát rằng bản chất của tập hợp nhóm ảnh hưởng đến chi phí của nhà điều hành, hãy kiểm tra chi phí CPU của các toán tử Hash Aggregate trong kế hoạch cho các truy vấn sau (gọi chúng là Truy vấn 3 và Truy vấn 4):
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 50 AS grp1, orderid % 20 AS grp2, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 50, orderid % 20 OPTION(HASH GROUP, MAXDOP 1);
Tất nhiên, bạn muốn đảm bảo rằng số lượng hàng đầu vào và nhóm đầu ra ước tính là như nhau trong cả hai trường hợp. Các kế hoạch ước tính cho các truy vấn này được thể hiện trong Hình 4.
Hình 4:Kế hoạch cho Truy vấn 3 và Truy vấn 4
Như bạn có thể thấy, chi phí CPU của toán tử Hash Aggregate là 0,16903 khi nhóm theo một cột số nguyên và 0,174016 khi nhóm theo hai cột số nguyên, với tất cả các cột khác đều bằng nhau. Điều này có nghĩa là bản số của tập hợp nhóm thực sự ảnh hưởng đến chi phí.
Về việc liệu kiểu dữ liệu của phần tử được nhóm có ảnh hưởng đến chi phí hay không, tôi đã sử dụng các truy vấn sau để kiểm tra điều này (gọi chúng là Truy vấn 5, Truy vấn 6 và Truy vấn 7):
SELECT CAST(orderid AS SMALLINT) % CAST(1000 AS SMALLINT) AS grp,
MAX(orderdate) AS maxod
FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D
GROUP BY CAST(orderid AS SMALLINT) % CAST(1000 AS SMALLINT)
OPTION(HASH GROUP, MAXDOP 1);
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod
FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D
GROUP BY orderid % 1000
OPTION(HASH GROUP, MAXDOP 1);
SELECT CAST(orderid AS BIGINT) % CAST(1000 AS BIGINT) AS grp,
MAX(orderdate) AS maxod
FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D
GROUP BY CAST(orderid AS BIGINT) % CAST(1000 AS BIGINT)
OPTION(HASH GROUP, MAXDOP 1); Các kế hoạch cho cả ba truy vấn có cùng số lượng hàng đầu vào và nhóm đầu ra ước tính, nhưng chúng đều có chi phí CPU ước tính khác nhau (0,121766, 0,16903 và 0,171716), do đó loại dữ liệu được sử dụng sẽ ảnh hưởng đến chi phí.
Loại hàm tổng hợp dường như cũng có tác động đến chi phí. Ví dụ:hãy xem xét hai truy vấn sau (gọi chúng là Truy vấn 8 và Truy vấn 9):
SELECT orderid % 1000 AS grp, COUNT(*) AS numorders FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1);
Chi phí CPU ước tính cho Tổng hợp băm trong kế hoạch cho Truy vấn 8 là 0,166344 và trong Truy vấn 9 là 0,16903.
Đó có thể là một bài tập thú vị để thử và tìm ra chính xác tính chất cơ bản của tập hợp nhóm, kiểu dữ liệu và hàm tổng hợp được sử dụng ảnh hưởng đến chi phí như thế nào; Tôi chỉ không theo đuổi khía cạnh này của chi phí. Vì vậy, sau khi thực hiện lựa chọn tập hợp nhóm và hàm tổng hợp cho truy vấn của mình, bạn có thể thiết kế ngược lại công thức tính giá thành. Ví dụ:hãy thiết kế ngược lại công thức tính giá CPU cho toán tử Hash Aggregate khi nhóm theo một cột số nguyên duy nhất và trả về tổng số MAX (orderdate). Công thức phải là:
Chi phí CPU của người vận hành =Sử dụng các kỹ thuật mà tôi đã trình bày trong các bài trước của loạt bài này, tôi nhận được công thức được thiết kế ngược sau:
Chi phí CPU của nhà điều hành =0,017749 + @numrows * 0,00000667857 + @numgroups * 0,0000177087Bạn có thể kiểm tra tính chính xác của công thức bằng các truy vấn sau:
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 2000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 2000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 3000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 3000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 6000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 6000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 5000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 5000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(HASH GROUP, MAXDOP 1);
Tôi nhận được các kết quả sau:
numrows numgroups predictedcost estimatedcost ----------- ----------- -------------- -------------- 100000 1000 0.703315 0.703316 100000 2000 0.721023 0.721024 200000 3000 1.40659 1.40659 200000 6000 1.45972 1.45972 500000 5000 3.44558 3.44558 500000 10000 3.53412 3.53412
Có vẻ như công thức đã đúng.
Tóm tắt và so sánh chi phí
Bây giờ chúng ta có các công thức chi phí cho ba chiến lược có sẵn:Tổng hợp luồng được sắp xếp trước, Tổng hợp theo thứ tự + Tổng hợp luồng và Tổng hợp băm. Bảng sau đây tóm tắt và so sánh các đặc điểm chi phí của ba thuật toán:
| Tổng hợp luồng được đặt hàng trước | Sắp xếp + Tổng hợp luồng | Tổng hợp băm | |
| Công thức | @numrows * 0,0000006 + @numgroups * 0,0000005 | 0,0112613 + Số lượng hàng nhỏ: 9.99127891201865E-05 + @numrows * LOG (@numrows) * 2.25061348918698E-06 Số lượng hàng lớn: 1.35166186417734E-04 + @numrows * LOG (@numrows) * 6.62193536908588E-06 + @numrows * 0,0000006 + @numgroups * 0,0000005 | 0,017749 + @numrows * 0,00000667857 + @numgroups * 0,0000177087
* Nhóm theo cột số nguyên duy nhất, trả về MAX ( |
| Chia tỷ lệ | tuyến tính | n log n | tuyến tính |
| Chi phí I / O khởi động | không | 0,0112613 | không |
| Chi phí CPU khởi động | không | ~ 0,0001 | 0,017749 |
Theo các công thức này, Hình 5 cho thấy cách mỗi chiến lược chia tỷ lệ cho các số lượng hàng đầu vào khác nhau, sử dụng một số lượng cố định các nhóm là 500 làm ví dụ.
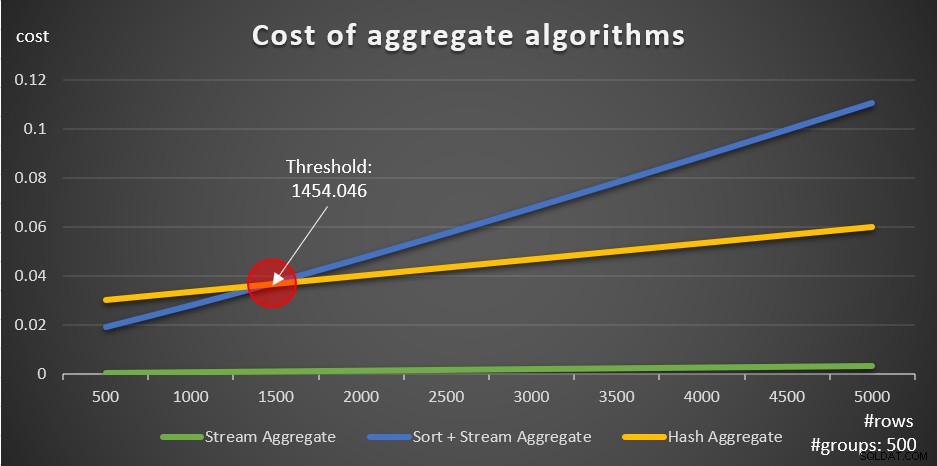
Hình 5:Chi phí của các thuật toán tổng hợp
Bạn có thể thấy rõ rằng nếu dữ liệu được sắp xếp trước, ví dụ:trong một chỉ mục bao trùm, thì chiến lược Tổng hợp luồng được sắp xếp trước là tùy chọn tốt nhất, bất kể có bao nhiêu hàng tham gia. Ví dụ:giả sử bạn cần truy vấn bảng Đơn hàng và tính ngày đặt hàng tối đa cho mỗi nhân viên. Bạn tạo chỉ mục bao trùm sau:
CREATE INDEX idx_eid_od ON dbo.Orders(empid, orderdate);
Dưới đây là năm truy vấn, mô phỏng bảng Đơn hàng với các số hàng khác nhau (10.000, 20.000, 30.000, 40.000 và 50.000):
SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (10000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (30000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (40000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (50000) * FROM dbo.Orders) AS D GROUP BY empid;
Hình 6 cho thấy các kế hoạch cho các truy vấn này.
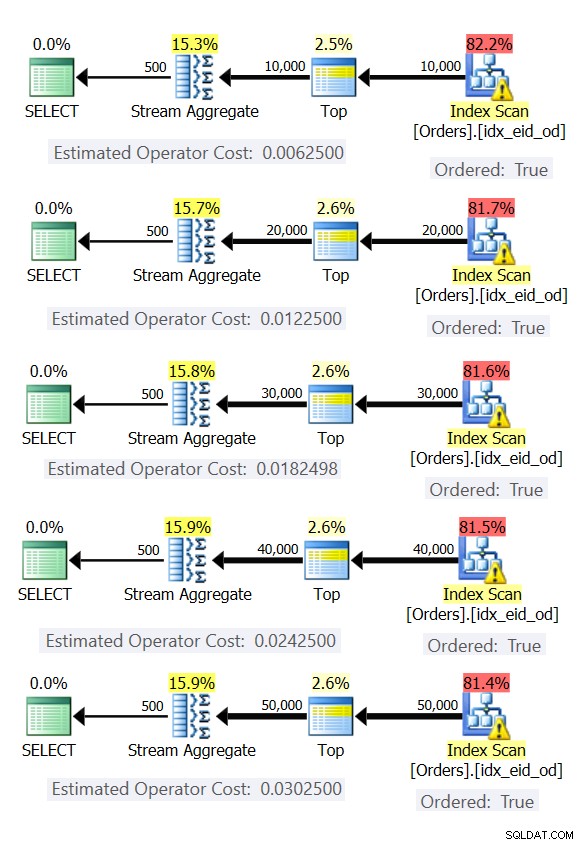
Hình 6:Các kế hoạch với chiến lược Tổng hợp luồng được sắp xếp trước
Trong mọi trường hợp, các kế hoạch thực hiện quét theo thứ tự chỉ mục bao trùm và áp dụng toán tử Tổng hợp luồng mà không cần phân loại rõ ràng.
Sử dụng mã sau để bỏ chỉ mục bạn đã tạo cho ví dụ này:
DROP INDEX idx_eid_od ON dbo.Orders;
Điều quan trọng khác cần lưu ý về các đồ thị trong Hình 5 là điều gì sẽ xảy ra khi dữ liệu không được sắp xếp trước. Điều này xảy ra khi không có chỉ mục bao gồm tại chỗ, cũng như khi bạn nhóm theo các biểu thức được thao tác trái ngược với các cột cơ sở. Có một ngưỡng tối ưu hóa — trong trường hợp của chúng tôi là 1454.046 hàng — dưới đó chiến lược Tổng hợp Sắp xếp + Luồng có chi phí thấp hơn và trên hoặc cao hơn chiến lược Tổng hợp băm có chi phí thấp hơn. Điều này liên quan đến thực tế là băm trước có chi phí khởi động thấp hơn, nhưng quy mô theo cách n log n, trong khi băm sau có chi phí khởi động cao hơn nhưng quy mô tuyến tính. Điều này làm cho trước đây được ưu tiên với số lượng nhỏ các hàng đầu vào. Nếu các công thức được thiết kế ngược của chúng tôi là chính xác, hai truy vấn sau (gọi chúng là Truy vấn 10 và Truy vấn 11) sẽ có các kế hoạch khác nhau:
SELECT orderid % 500 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (1454) * FROM dbo.Orders) AS D GROUP BY orderid % 500; SELECT orderid % 500 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (1455) * FROM dbo.Orders) AS D GROUP BY orderid % 500;
Kế hoạch cho các truy vấn này được thể hiện trong Hình 7.
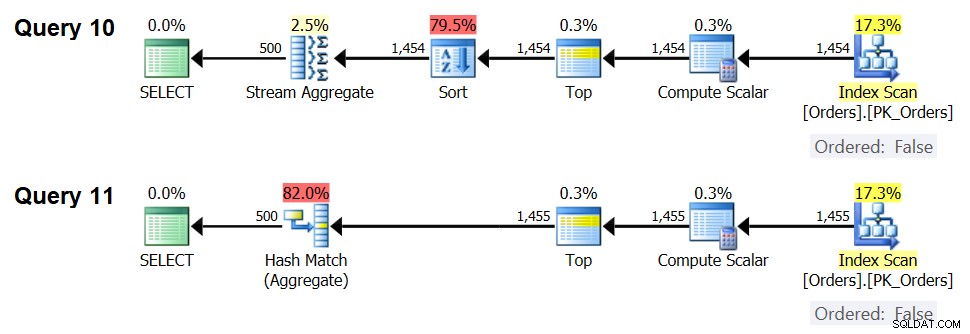
Hình 7:Kế hoạch cho Truy vấn 10 và Truy vấn 11
Thật vậy, với 1.454 hàng đầu vào (dưới ngưỡng tối ưu hóa), trình tối ưu hóa đương nhiên thích thuật toán Tổng hợp Dòng + Sắp xếp cho Truy vấn 10 và với 1.455 hàng đầu vào (trên ngưỡng tối ưu hóa), trình tối ưu hóa đương nhiên thích thuật toán Tổng hợp Hash cho Truy vấn 11 .
Tiềm năng cho toán tử Tổng hợp thích ứng
Một trong những khía cạnh khó khăn của ngưỡng tối ưu hóa là các vấn đề đánh hơi tham số khi sử dụng các truy vấn nhạy cảm với tham số trong các thủ tục được lưu trữ. Hãy xem xét quy trình được lưu trữ sau đây làm ví dụ:
CREATE OR ALTER PROC dbo.EmpOrders @initialorderid AS INT AS SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= @initialorderid GROUP BY empid; GO
Bạn tạo chỉ mục tối ưu sau để hỗ trợ truy vấn thủ tục được lưu trữ:
CREATE INDEX idx_oid_i_eid ON dbo.Orders(orderid) INCLUDE(empid);
Bạn đã tạo chỉ mục với orderid làm khóa để hỗ trợ bộ lọc phạm vi của truy vấn và bao gồm trống cho phạm vi phù hợp. Đây là tình huống mà bạn không thể thực sự tạo chỉ mục vừa hỗ trợ bộ lọc phạm vi vừa có các hàng đã lọc được sắp xếp trước theo nhóm nhóm. Điều này có nghĩa là trình tối ưu hóa sẽ phải đưa ra lựa chọn giữa Tổng hợp sắp xếp + luồng và các thuật toán Tổng hợp băm. Dựa trên các công thức tính phí của chúng tôi, ngưỡng tối ưu hóa nằm trong khoảng từ 937 đến 938 hàng đầu vào (giả sử là 937,5 hàng).
Giả sử rằng bạn thực hiện quy trình được lưu trữ lần đầu tiên với ID đơn đặt hàng ban đầu đầu vào cung cấp cho bạn một số lượng nhỏ các kết quả phù hợp (dưới ngưỡng):
EXEC dbo.EmpOrders @initialorderid = 999991;
SQL Server tạo ra một kế hoạch sử dụng thuật toán Sắp xếp + Tổng hợp Luồng và lưu trữ kế hoạch vào bộ nhớ cache. Các lần thực thi tiếp theo sử dụng lại kế hoạch đã lưu trong bộ nhớ cache, bất kể có bao nhiêu hàng tham gia. Ví dụ:thực thi sau có một số kết quả phù hợp trên ngưỡng tối ưu hóa:
EXEC dbo.EmpOrders @initialorderid = 990001;
Tuy nhiên, nó sử dụng lại kế hoạch đã lưu trong bộ nhớ cache mặc dù thực tế là nó không tối ưu cho việc thực thi này. Đó là một vấn đề đánh giá thông số cổ điển.
SQL Server 2017 giới thiệu các khả năng xử lý truy vấn thích ứng, được thiết kế để đối phó với các tình huống như vậy bằng cách xác định trong quá trình thực thi truy vấn nên sử dụng chiến lược nào. Trong số những cải tiến đó có toán tử Tham gia thích ứng mà trong quá trình thực thi sẽ xác định xem có nên kích hoạt thuật toán Vòng lặp hoặc Băm dựa trên ngưỡng tối ưu hóa được tính toán hay không. Câu chuyện tổng hợp của chúng tôi yêu cầu một toán tử Tổng hợp thích ứng tương tự, toán tử này trong quá trình thực thi sẽ đưa ra lựa chọn giữa chiến lược Tổng hợp Sắp xếp + Luồng và chiến lược Tổng hợp băm, dựa trên ngưỡng tối ưu hóa được tính toán. Hình 8 minh họa một kế hoạch giả dựa trên ý tưởng này.
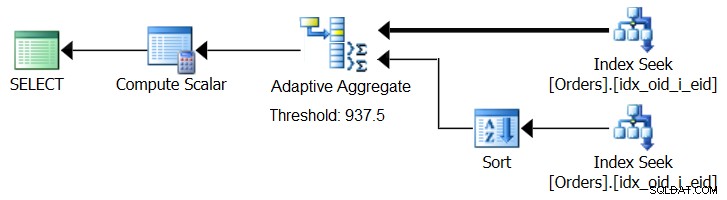
Hình 8:Kế hoạch giả với toán tử Tổng hợp thích ứng
Hiện tại, để có được kế hoạch như vậy, bạn cần sử dụng Microsoft Paint. Nhưng vì khái niệm xử lý truy vấn thích ứng rất thông minh và hoạt động rất hiệu quả, nên chỉ có điều hợp lý là chúng ta sẽ thấy những cải tiến hơn nữa trong lĩnh vực này trong tương lai.
Chạy mã sau để thả chỉ mục bạn đã tạo cho ví dụ này:
DROP INDEX idx_oid_i_eid ON dbo.Orders;
Kết luận
Trong bài viết này, tôi đã đề cập đến chi phí và quy mô của thuật toán Hash Aggregate và so sánh nó với các chiến lược Stream Aggregate và Sort + Stream Aggregate. Tôi đã mô tả ngưỡng tối ưu hóa tồn tại giữa các chiến lược Sắp xếp + Tổng hợp luồng và Tổng hợp băm. Với số lượng hàng đầu vào nhỏ, hàng đầu tiên được ưu tiên và với số lượng lớn hàng sau được ưu tiên. Tôi cũng mô tả tiềm năng thêm toán tử Tổng hợp thích ứng, tương tự như toán tử Kết hợp thích ứng đã được triển khai, để giúp giải quyết các vấn đề về dò tham số khi sử dụng các truy vấn nhạy cảm với tham số. Tháng tới, tôi sẽ tiếp tục thảo luận bằng cách đề cập đến các vấn đề cân nhắc về song song và các trường hợp cần viết lại truy vấn.