Trong khi Jeff Atwood và Joe Celko dường như nghĩ rằng chi phí của GUID không phải là vấn đề lớn (xem bài đăng trên blog của Jeff, "Khóa chính:ID so với GUID" và chủ đề nhóm tin này, có tên "Identity Vs. Uniqueidentifier"), các chuyên gia khác - cụ thể hơn là các chuyên gia kiến trúc và lập chỉ mục tập trung vào không gian SQL Server - có xu hướng không đồng ý. Ví dụ:Kimberly Tripp xem qua một số chi tiết trong bài đăng của cô ấy, "Dung lượng đĩa rẻ - ĐÓ KHÔNG PHẢI LÀ ĐIỂM!", Nơi cô ấy giải thích rằng tác động không chỉ đến dung lượng đĩa và sự phân mảnh, mà quan trọng hơn là kích thước chỉ mục và bộ nhớ dấu chân.
Những gì Kimberly nói thực sự đúng - tôi bắt gặp lời biện minh "không gian đĩa rẻ" cho GUIDs mọi lúc (ví dụ từ tuần trước). Có những lý do khác cho GUID, bao gồm nhu cầu tạo số nhận dạng duy nhất bên ngoài cơ sở dữ liệu (và đôi khi trước khi hàng thực sự được tạo) và nhu cầu về số nhận dạng duy nhất trên các hệ thống phân tán riêng biệt (và khi phạm vi nhận dạng không thực tế). Nhưng tôi thực sự muốn xóa tan lầm tưởng rằng HƯỚNG DẪN không tốn nhiều tiền như vậy, bởi vì chúng có giá và bạn cần cân nhắc những chi phí này để đưa ra quyết định của mình.
Tôi bắt đầu nhiệm vụ này để kiểm tra hiệu suất của các kích thước khóa khác nhau, được cung cấp cùng một dữ liệu trên cùng một số hàng, với cùng chỉ mục và khối lượng công việc gần giống nhau (việc phát lại * chính xác * cùng một khối lượng công việc có thể khá khó khăn). Tôi không chỉ muốn đo lường những thứ cơ bản như kích thước chỉ mục và phân mảnh chỉ mục, mà còn cả những tác động mà những thứ này gây ra đối với dòng, chẳng hạn như:
- tác động đến việc sử dụng vùng đệm
- tần suất chia tách trang "xấu"
- tác động tổng thể đến thời lượng khối lượng công việc thực tế
- tác động đến thời gian chạy trung bình của các truy vấn riêng lẻ
- tác động đến thời gian chạy của sau khi kích hoạt
- tác động đến việc sử dụng tempdb
Tôi sẽ sử dụng nhiều kỹ thuật khác nhau để điều tra dữ liệu này, bao gồm Sự kiện mở rộng, dấu vết mặc định, DMV liên quan đến tempdb và Cố vấn hiệu suất SQL Sentry.
Thiết lập
Đầu tiên, tôi đã tạo một triệu khách hàng để đưa vào bảng hạt giống bằng cách sử dụng một số siêu dữ liệu SQL Server tích hợp sẵn; điều này sẽ đảm bảo rằng các khách hàng "ngẫu nhiên" sẽ có cùng một dữ liệu tự nhiên trong mỗi lần thử nghiệm.
CREATE TABLE dbo.CustomerSeeds (rn INT PRIMARY KEY CLUSTERED, FirstName NVARCHAR (64), LastName NVARCHAR (64), EMail NVARCHAR (320) NOT NULL UNIQUE, Active BIT); CHÈN dbo.CustomerSeeds WITH (TABLOCKX) (rn, FirstName, LastName, EMail, [Active]) SELECT rn =ROW_NUMBER () OVER (ORDER BY n), fn, ln, em, aFROM (SELECT TOP (1000000) fn, ln , em, a =MAX (a), n =MAX (NEWID ()) TỪ (CHỌN fn, ln, em, a, r =ROW_NUMBER () HẾT (PHẦN CỦA em ĐẶT HÀNG THEO em) TỪ (CHỌN ĐẦU (2000000) fn =LEFT (o.name, 64), ln =LEFT (c.name, 64), em =LEFT (o.name, LEN (c.name)% 5 + 1) + '.' + LEFT (c. name, LEN (o.name)% 5 + 2) + '@' + RIGHT (c.name, LEN (o.name + c.name)% 12 + 1) + LEFT (RTRIM (CHECKSUM (NEWID ()) ), 3) + '.com', a =TRƯỜNG HỢP KHI c.name THÍCH '% y%' THÌ 0 HẾT 1 KẾT THÚC TỪ sys.all_objects AS o CROSS THAM GIA sys.all_columns NHƯ c ĐẶT HÀNG BẰNG NEWID ()) AS x) AS y WHERE r =1 GROUP BY fn, ln, em ORDER BY n) AS z ORDER BY rn; GO CHỌN ĐẦU (10) * FROM dbo.CustomerSeeds ORDER BY rn; GO
Số dặm của bạn có thể thay đổi, nhưng trên hệ thống của tôi, dân số này mất 86 giây. Mười hàng đại diện (bấm để phóng to):
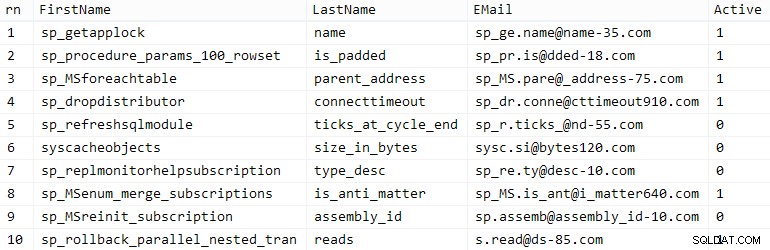 Khách hàng mẫu
Khách hàng mẫu
Tiếp theo, tôi cần các bảng để chứa dữ liệu gốc cho mỗi trường hợp sử dụng, với một vài chỉ mục bổ sung để mô phỏng một số loại thực tế và tôi đã nghĩ ra các hậu tố ngắn để giúp cho tất cả các loại chẩn đoán sau này dễ dàng hơn:
| kiểu dữ liệu | mặc định | nén | hậu tố trường hợp sử dụng |
|---|---|---|---|
| INT | IDENTITY | không có | Tôi |
| INT | IDENTITY | trang + hàng | Ic |
| BIGINT | IDENTITY | không có | B |
| BIGINT | IDENTITY | trang + hàng | Bc |
| UNIQUEIDENTIFIER | NEWID () | không có | G |
| UNIQUEIDENTIFIER | NEWID () | trang + hàng | Gc |
| UNIQUEIDENTIFIER | NEWSEQUENTIALID () | không có | S |
| UNIQUEIDENTIFIER | NEWSEQUENTIALID () | trang + hàng | Sc |
Bảng 1:Các trường hợp sử dụng, kiểu dữ liệu và hậu tố
Tất cả tám bảng đều được kể, tất cả đều sinh ra từ cùng một mẫu (Tôi chỉ thay đổi các nhận xét xung quanh để phù hợp với trường hợp sử dụng và thay thế $use_case$ với hậu tố thích hợp từ bảng trên):
TẠO BẢNG dbo.Customers_ $ use_case $ - I, Ic, B, Bc, G, Gc, S, Sc (CustomerID INT NOT NULL IDENTITY (1,1), --CustomerID BIGINT NOT NULL IDENTITY (1, 1), --CustomerID UNIQUEIDENTIFIER NOT NULL DEFAULT NEWID (), --CustomerID UNIQUEIDENTIFIER NOT NULL DEFAULT NEWSEQUENTIALID (), FirstName NVARCHAR (64) NOT NULL, LastName NVARCHAR (64) NOT NULL, EMail NVARCHAR (320) KHÔNG NULL, EMail NVARCHAR (320) BIT NOT NULL DEFAULT 1, Created DATETIME NOT NULL DEFAULT SYSDATETIME (), Cập nhật DATETIME NULL, CONSTRAINT C_PK_Customers_ $ use_case $ PRIMARY KEY (CustomerID)) --WITH (DATA_COMPRESSION_case =PAGE) GO; CREATE UNIQboUE INDEX Comers Customer_ $ use_case $ (EMail) --WITH (DATA_COMPRESSION =PAGE); GOCREATE INDEX C_Active_Customers_ $ use_case $ ON dbo.Customers_ $ use_case $ (FirstName, LastName, EMail) WHERE Active =1 --WITH (DATA_COMPRESSION =PAGE); INDEX C_Name_Customers_ $ use_case $ ON dbo.Customers_ $ use_case $ (LastName, FirstName) BAO GỒM (EMail) --WITH (DATA_COMPRESSION =PAGE); ĐISau khi các bảng được tạo, tôi tiến hành điền các bảng và đo lường nhiều số liệu mà tôi đã ám chỉ ở trên. Tôi đã khởi động lại dịch vụ SQL Server giữa mỗi lần kiểm tra để đảm bảo rằng tất cả chúng đều bắt đầu từ cùng một đường cơ sở, rằng các DMV sẽ được đặt lại, v.v.
Chèn không được kiểm tra
Mục tiêu cuối cùng của tôi là lấp đầy bảng với 1.000.000 hàng, nhưng trước tiên tôi muốn xem tác động của kiểu dữ liệu và tính năng nén đối với các phần chèn thô mà không gây tranh cãi. Tôi đã tạo truy vấn sau - truy vấn này sẽ điền vào bảng với 200.000 địa chỉ liên hệ đầu tiên, 2000 hàng cùng một lúc - và chạy nó với từng bảng:
DECLARE @i INT =1; WHILE @i <=100BEGIN CHÈN dbo.Customers_ $ use_case $ (FirstName, LastName, Email, Active) CHỌN FirstName, LastName, Email, Active FROM dbo.CustomerSeeds AS c ORDER BY rn OFFSET 2000 * (@ i-1) ROWS CHỈ TỚI 2000 ROWS TIẾP THEO; SET @i + =1; HẾTKết quả (bấm để phóng to):
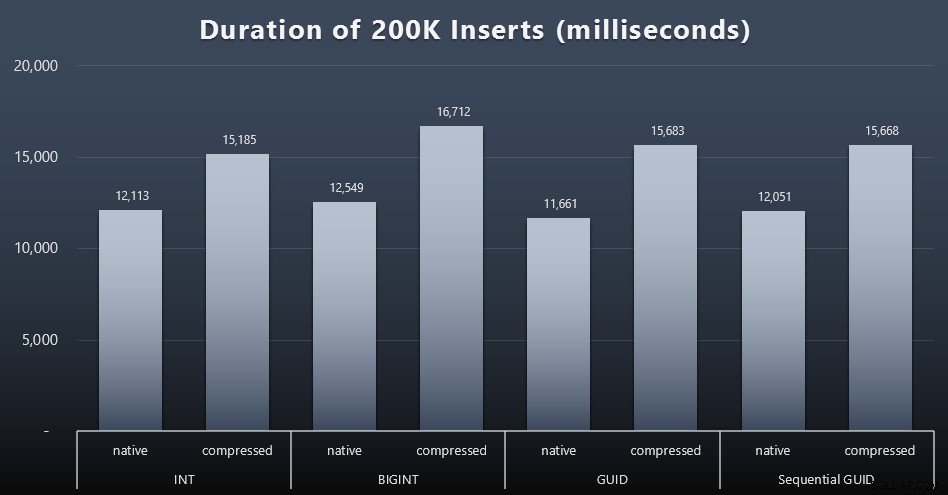
Mỗi trường hợp mất khoảng 12 giây (không nén) và 16 giây (có nén), không có người chiến thắng rõ ràng ở cả hai chế độ lưu trữ. Ảnh hưởng của việc nén (chủ yếu trên chi phí CPU) là khá nhất quán, nhưng vì tính năng này đang chạy trên SSD nhanh, tác động I / O của các loại dữ liệu khác nhau là không đáng kể. Trên thực tế, việc nén đối với BIGINT dường như có tác động lớn nhất (và điều này có ý nghĩa, vì mỗi giá trị nhỏ hơn 2 tỷ sẽ được nén).
Khối lượng công việc nhiều hơn
Tiếp theo, tôi muốn xem một khối lượng công việc hỗn hợp sẽ cạnh tranh tài nguyên như thế nào và thường hoạt động như thế nào đối với từng loại dữ liệu. Vì vậy, tôi đã tạo các thủ tục này (thay thế
$use_case$và$data_type$thích hợp cho mỗi bài kiểm tra):- cập nhật ngẫu nhiên singleton cho dữ liệu trong nhiều chỉ mục CẬP NHẬT dbo.Customers_ $ use_case $ SET LastName =COALESCE (STUFF (LastName, 4, 1, 'x'), 'x') WHERE CustomerID =@ Customer_ $ use_case $; ENDGO - lần đọc ("phân trang") - hỗ trợ nhiều sắp xếp-- sử dụng SQL động để theo dõi riêng số liệu thống kê truy vấn DECLARE @sql NVARCHAR (MAX) =N'SELECT CustomerID, FirstName, LastName, Email, Active, Created, Updates FROM dbo.Customers_ $ use_case $ ORDER BY '+ @sort + N' OFFSET ((@ pn-1) * @ ps) Chỉ ROWS FETCH TIẾP THEO @ps ROWS; '; EXEC sys.sp_executesql @sql, N '@ pn INT, @ps INT', @PageNumber, @PageSize; ENDGOSau đó, tôi tạo ra các công việc có thể gọi các thủ tục đó lặp đi lặp lại, với sự chậm trễ nhỏ, và cũng - đồng thời - hoàn thành việc điền 800.000 địa chỉ liên hệ còn lại. Tập lệnh này tạo tất cả 32 công việc và cũng in đầu ra có thể được sử dụng sau này để gọi tất cả các công việc cho một bài kiểm tra cụ thể một cách không đồng bộ:
USE msdb; GO DECLARE @typ TABLE (use_case VARCHAR (2), data_type SYSNAME); INSERT @typ (use_case, data_type) VALUES ('I', N'INT '), (' Ic ', N'INT '), (' B ', N'BIGINT'), ('Bc', N'BIGINT '), (' G ', N'UNIQUEIDENTIFIER'), ('Gc', N'UNIQUEIDENTIFIER '), (' S ', N'UNIQUEIDENTIFIER'), ('Sc', N'UNIQUEIDENTIFIER '); DECLARE @jobs TABLE (name SYSNAME, cmd NVARCHAR (MAX)); INSERT @jobs (name, cmd) VALUES (N'Random update workload ', N'DECLARE @CustomerID $ data_type $, @i INT =1; WHILE @i <=500 BEGIN CHỌN HÀNG ĐẦU (1) @CustomerID =CustomerID TỪ dbo.Customers_ $ use_case $ ORDER BY NEWID (); EXEC dbo.Customers_ $ use_case $ _RandomUpdate @ Customer_ $ use_case $ =@CustomerID; WAITFOR DELAY '' 00:00 :01 ''; SET @i + =1; END '), (Không thu hút khách hàng', N'SET QUOTED_IDENTIFIER ON; DECLARE @i INT =101; WHILE @i <=500 BẮT ĐẦU CHÈN dbo.Customers_ $ use_case $ (FirstName, LastName, Email, Active) CHỌN FirstName, LastName, Email, Active FROM dbo. 01 ''; SET @i + =1; END '), (N'Paging workload 1', N'DECLARE @i INT =1, @sql NVARCHAR (MAX); WHILE @i <=1001 BEGIN - sắp xếp theo CustomerID SET @sql =N '' EXEC dbo.Customers_ $ use_case $ _Page @PageNumber =@i, @sort =N '' '' CustomerID '' ''; ''; EXEC sys.sp_executesql @sql, N '' @ i INT '', @i; CHỜ TRÌ HOÃN '' 00:00:01 ''; ĐẶT @i + =2; END '), (N'Paging workload 2', N'DECLARE @i INT =1, @sql NVARCHAR (MAX); WHILE @i <=1001 BEGIN - sắp xếp theo LastName, FirstName SET @sql =N''EXEC dbo.Customers_ $ use_case $ _Page @PageNumber =@i, @sort =N '' '' LastName, FirstName '' ''; ''; EXEC sys.sp_executesql @sql, N '' @ i INT '', @i; CHỜ TRÌ HOÃN '' 00:00:01 ''; SET @i + =2; HẾT '); DECLARE @n SYSNAME, @c NVARCHAR (MAX); DECLARE c CURSOR LOCAL FAST_FORWARD FORSELECT name =t.use_case + N '' + j.name, cmd =REPLACE (REPLACE (j.cmd, N '$ use_case $', t.use_case), N '$ data_type $', t .data_type) FROM @typ AS t CROSS JOIN @jobs AS j; MỞ c; TÌM KIẾM c VÀO @n, @c; WHILE @@ FETCH_STATUS <> -1BEGIN NẾU TỒN TẠI (CHỌN 1 TỪ msdb.dbo.sysjobs WHERE name =@n) BẮT ĐẦU THỰC HIỆN msdb.dbo.sp_delete_job @job_name =@n; HẾT EXEC msdb.dbo.sp_add_job @job_name =@n, @enabled =0, @notify_level_eventlog =0, @category_id =0, @owner_login_name =N'sa '; EXEC msdb.dbo.sp_add_jobstep @job_name =@n, @step_name =@n, @command =@c, @database_name =N'IDs '; EXEC msdb.dbo.sp_add_jobserver @job_name =@n, @server_name =N '(cục bộ)'; IN 'EXEC msdb.dbo.sp_start_job @job_name =N' '' + @n + '' ';'; NHẬP c VÀO @n, @c; HẾTĐo lường thời gian công việc trong mỗi trường hợp là không đáng kể - tôi có thể kiểm tra ngày bắt đầu / ngày kết thúc trong
msdb.dbo.sysjobhistoryhoặc kéo chúng từ SQL Sentry Event Manager. Đây là kết quả (bấm để phóng to):
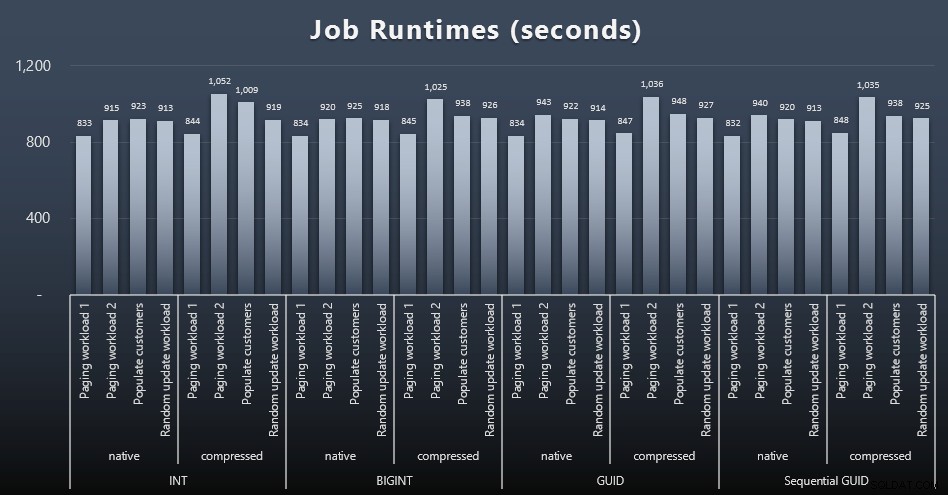
Và nếu bạn muốn có ít hơn một chút để tiêu hóa, chỉ cần xem thời gian chạy trung bình và tối đa của bốn công việc (nhấp để phóng to):
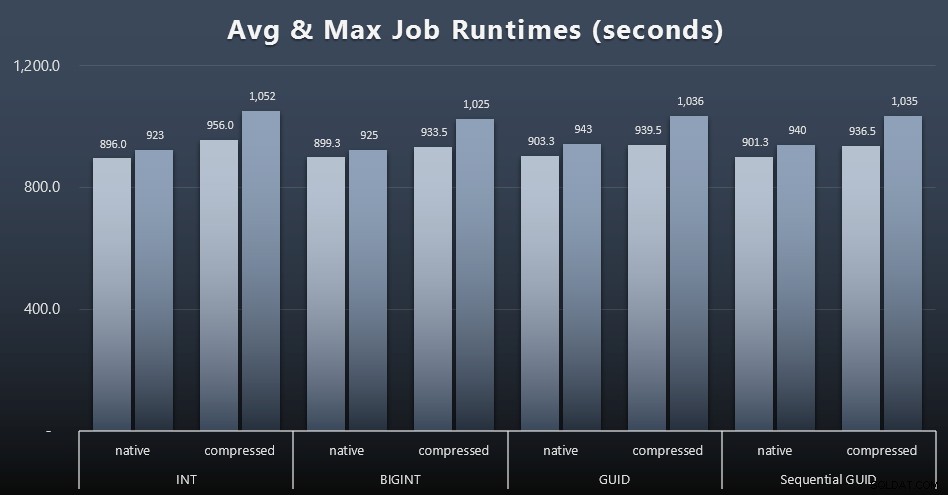
Nhưng ngay cả trong biểu đồ thứ hai này, vẫn không có đủ phương sai thực sự để tạo ra một trường hợp thuyết phục cho hoặc chống lại bất kỳ cách tiếp cận nào.
Thời gian truy vấn
Tôi đã lấy một số chỉ số từ
sys.dm_exec_query_statsvàsys.dm_exec_trigger_statsđể xác định thời gian trung bình của các truy vấn riêng lẻ.
Dân số
200.000 khách hàng đầu tiên đã được tải khá nhanh - dưới 20 giây - do không có khối lượng công việc cạnh tranh. Tuy nhiên, khi bốn công việc đang chạy đồng thời, có một tác động đáng kể đến thời lượng ghi do đồng thời. 800.000 hàng còn lại cần ít nhất một thứ tự lớn hơn thời gian để hoàn thành, trung bình. Dưới đây là kết quả tính trung bình cho mỗi 2.000 lượt chèn của khách hàng (bấm vào để phóng to):
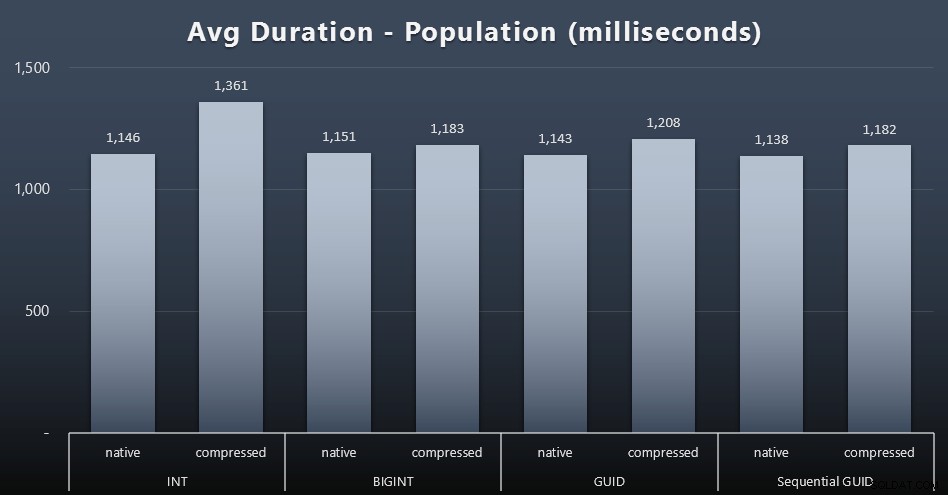
Ở đây, chúng tôi thấy rằng việc nén INT là ngoại lệ thực sự duy nhất - tôi có một số lý thuyết về điều đó, nhưng chưa có gì kết luận.
Khối lượng công việc phân trang
Thời gian chạy trung bình của các truy vấn phân trang dường như cũng bị ảnh hưởng đáng kể bởi tính đồng thời so với các lần chạy thử nghiệm của tôi một cách cô lập. Đây là kết quả (bấm để phóng to):
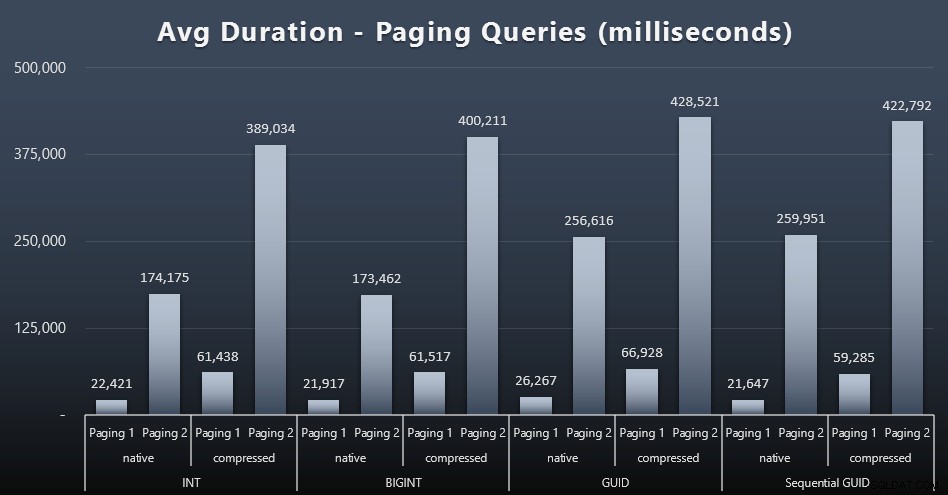
(Paging 1 =order by CustomerID, Paging 2 =order by LastName, FirstName.)
Chúng tôi thấy rằng đối với cả Phân trang 1 (theo thứ tự của CustomerID) và Phân trang 2 (thứ tự theo tên), có một tác động đáng kể đến thời gian chạy do nén (lên đến ~ 700%). Cả hai GUID dường như là những con ngựa chậm nhất trong cuộc đua này, với NEWID () có hiệu suất kém nhất.
Cập nhật khối lượng công việc
Các bản cập nhật singleton khá nhanh ngay cả trong điều kiện đồng thời nặng, nhưng vẫn có một số khác biệt đáng chú ý do nén và thậm chí một số khác biệt đáng ngạc nhiên giữa các loại dữ liệu (nhấp để phóng to):
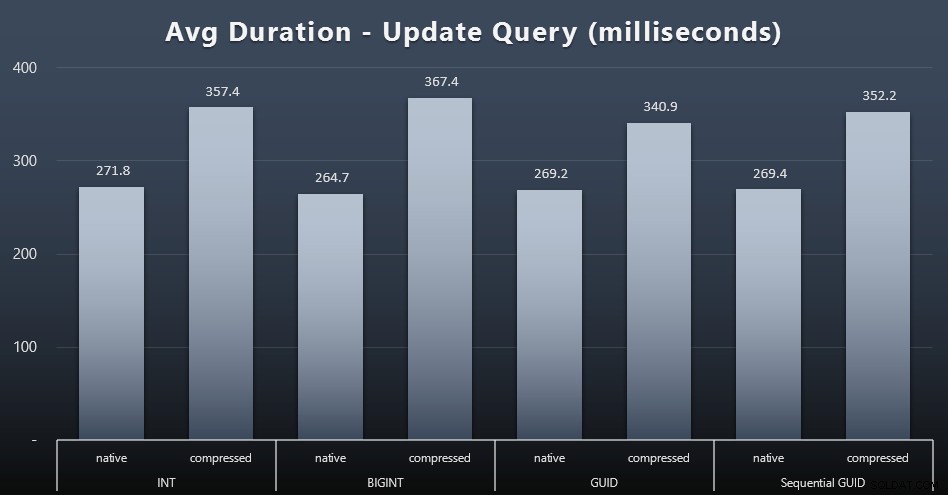
Đáng chú ý nhất, các bản cập nhật cho các hàng chứa giá trị GUID thực sự nhanh hơn so với các bản cập nhật có chứa INT / BIGINT, khi nén được sử dụng. Với lưu trữ gốc, sự khác biệt ít đáng chú ý hơn (nhưng INT vẫn là kẻ thua cuộc ở đó).
Thống kê kích hoạt
Dưới đây là thời gian chạy trung bình và tối đa cho trình kích hoạt đơn giản trong từng trường hợp (nhấp để phóng to):
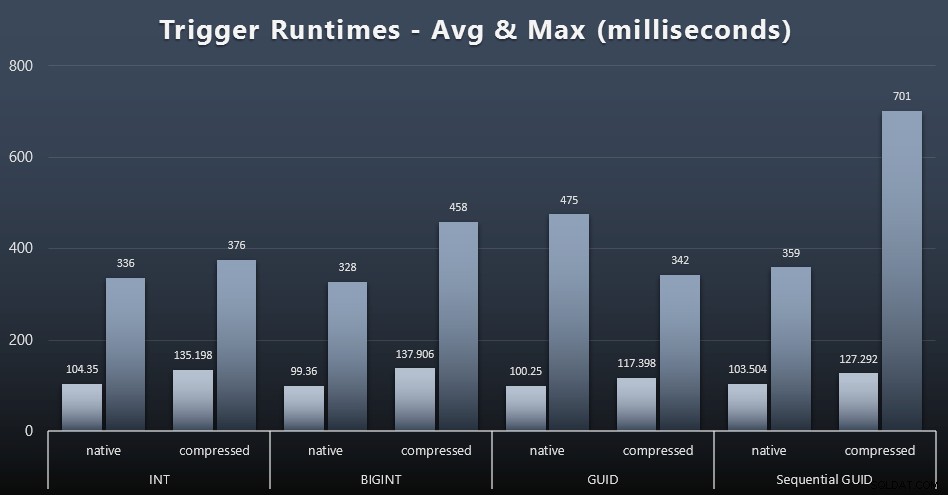
Nén dường như có tác động lớn hơn nhiều ở đây so với lựa chọn kiểu dữ liệu (mặc dù điều này có thể sẽ rõ ràng hơn nếu một số khối lượng công việc cập nhật của tôi đã cập nhật nhiều hàng thay vì chỉ bao gồm các tìm kiếm một hàng). Mức tối đa cho GUID tuần tự rõ ràng là một ngoại lệ của một số loại mà tôi không điều tra (bạn có thể nói rằng nó không đáng kể dựa trên mức trung bình vẫn ở trên bảng).
Những truy vấn này đang chờ đợi điều gì?
Sau mỗi khối lượng công việc, tôi cũng xem xét các lần chờ hàng đầu trên hệ thống, loại bỏ các lần chờ hàng đợi / hẹn giờ rõ ràng (như Paul Randal mô tả) và hoạt động không liên quan từ phần mềm giám sát (như TRACEWRITE ). Đây là 3 sự chờ đợi hàng đầu trong mỗi trường hợp (bấm để phóng to):
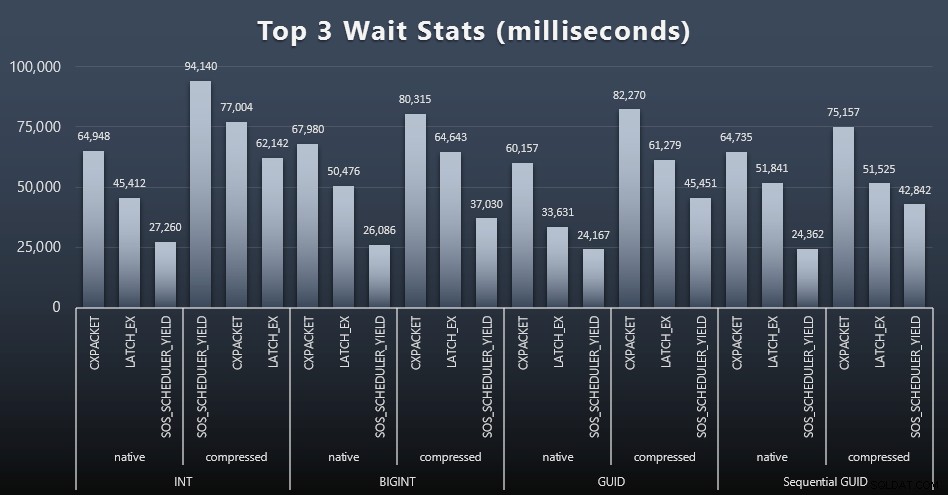
Trong hầu hết các trường hợp, lượt chờ là CXPACKET, sau đó là LATCH_EX, sau đó là SOS_SCHEDULER_YIELD. Tuy nhiên, trong trường hợp sử dụng liên quan đến số nguyên và nén, SOS_SCHEDULER_YIELD đã thay thế, điều này ngụ ý với tôi một số sự kém hiệu quả trong thuật toán nén số nguyên (có thể hoàn toàn không liên quan đến thuật toán được sử dụng để ép BIGINTs thành INT). Tôi đã không điều tra thêm về vấn đề này, cũng như không tìm thấy lý do cho việc theo dõi số lần chờ cho mỗi truy vấn riêng lẻ.
Dung lượng đĩa / Phân mảnh
Mặc dù tôi có xu hướng đồng ý rằng nó không liên quan đến dung lượng ổ đĩa, nhưng nó vẫn là một số liệu đáng để trình bày. Ngay cả trong trường hợp rất đơn giản này, khi chỉ có một bảng và khóa không có trong tất cả các bảng liên quan khác (chắc chắn sẽ tồn tại trong một ứng dụng thực), sự khác biệt là đáng kể. Đầu tiên, hãy xem reserved cột từ sp_spaceused (bấm để phóng to):
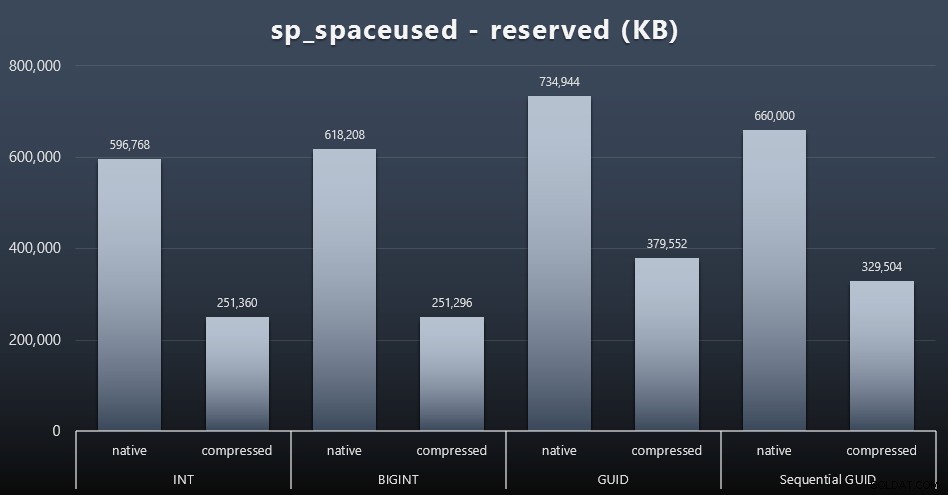
Ở đây, BIGINT chỉ chiếm nhiều dung lượng hơn INT một chút và GUID (như mong đợi) có một bước nhảy lớn hơn. GUID tuần tự có sự gia tăng ít đáng kể hơn về không gian được sử dụng và cũng được nén tốt hơn rất nhiều so với GUID truyền thống. Một lần nữa, không có gì ngạc nhiên ở đây - GUID lớn hơn một số, dừng đầy đủ. Bây giờ, những người ủng hộ GUID có thể tranh luận rằng cái giá bạn phải trả về không gian đĩa không quá nhiều (18% so với BIGINT khi không nén, khoảng 50% khi nén). Nhưng hãy nhớ rằng đây là một bảng có 1 triệu hàng. Hãy tưởng tượng điều đó sẽ ngoại suy như thế nào khi bạn có 10 triệu khách hàng và nhiều người trong số họ có 10, 30 hoặc 500 đơn đặt hàng - các phím đó có thể được lặp lại trong hàng chục bảng khác và chiếm cùng một không gian trong mỗi hàng.
Khi tôi xem xét sự phân mảnh sau mỗi khối lượng công việc (hãy nhớ rằng không có bảo trì chỉ mục nào được thực hiện) bằng cách sử dụng truy vấn sau:
SELECT index_id, FROM sys.dm_db_index_physical_stats (DB_ID (), OBJECT_ID ('dbo.Customers_ $ use_case $'), -1, 0, 'DETAILED'); Kết quả tạo ra những hình ảnh kém thú vị hơn nhiều; tất cả các chỉ mục không phân cụm bị phân mảnh hơn 99%. Tuy nhiên, các chỉ mục được nhóm lại hoặc bị phân mảnh rất cao, hoặc hoàn toàn không bị phân mảnh (bấm vào để phóng to):
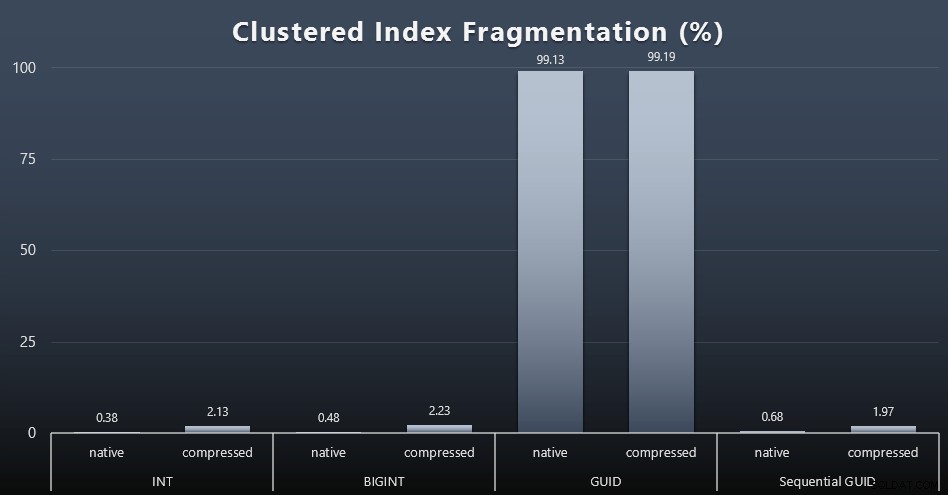
Phân mảnh là một số liệu khác thường có ý nghĩa ít hơn nhiều khi chúng ta đang nói về SSD, nhưng điều quan trọng cần lưu ý là giống nhau, vì không phải tất cả các hệ thống đều có khả năng nhận biết một cách hạnh phúc về tác động phân mảnh có thể có đối với các mẫu I / O. Tôi tin rằng việc sử dụng các GUID không tuần tự, trên một hệ thống có nhiều I / O hơn, tác động của riêng sự phân mảnh này sẽ được khuếch đại đáng kể lên hầu hết các chỉ số khác trong thử nghiệm này.
Sử dụng nhóm đệm
Đây là lúc mà việc cân nhắc về dung lượng đĩa được sử dụng bởi các bảng của bạn thực sự mang lại hiệu quả - các bảng của bạn càng lớn, chúng càng chiếm nhiều dung lượng trong vùng đệm. Việc di chuyển dữ liệu vào và ra khỏi vùng đệm rất tốn kém, và một lần nữa, đây là một trường hợp rất đơn giản khi các thử nghiệm được chạy một cách cô lập và không có ứng dụng và cơ sở dữ liệu nào khác cạnh tranh để giành bộ nhớ quý giá.
Đây là một phép đo đơn giản cho truy vấn sau ở cuối mỗi khối lượng công việc:
SELECT total_kb FROM sys.dm_os_memory_broker_clerks WHERE clerk_name =N'Buffer Pool ';
Kết quả (bấm để phóng to):
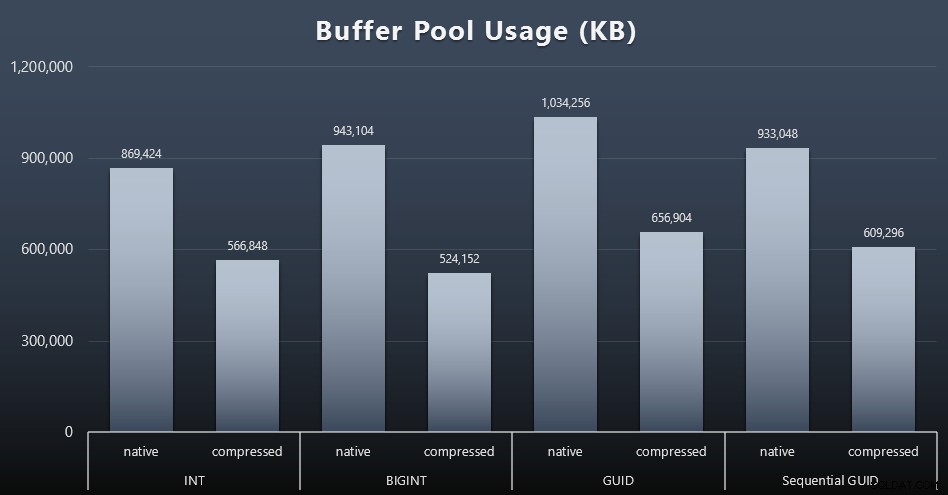
Mặc dù hầu hết biểu đồ này không có gì đáng ngạc nhiên - GUID chiếm nhiều dung lượng hơn BIGINT, BIGINT nhiều hơn INT - Tôi thực sự thấy thú vị khi một HƯỚNG DẪN Tuần tự chiếm ít dung lượng hơn BIGINT, ngay cả khi không nén. Tôi đã ghi chú để thực hiện một số pháp y cấp trang để xác định loại hiệu quả đang diễn ra ở đây.
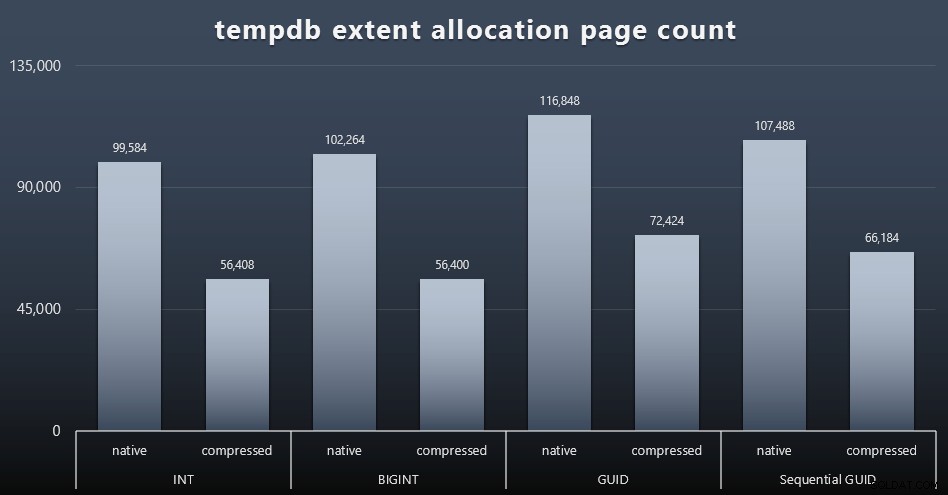
Cách sử dụng tempdb
Tôi không chắc mình đang mong đợi điều gì ở đây, nhưng sau mỗi khối lượng công việc, tôi thu thập nội dung của ba DMV sử dụng không gian liên quan đến tempdb, sys.dm_db_file|session|task_space_usage . Điều duy nhất dường như cho thấy bất kỳ sự biến động nào dựa trên loại dữ liệu là sys.dm_db_file_space_usage của extent_allocation_page_count . Điều này cho thấy rằng - ít nhất là trong cấu hình của tôi và khối lượng công việc cụ thể này - các GUID sẽ đưa tempdb qua quá trình tập luyện kỹ lưỡng hơn một chút (nhấp để phóng to):
Tách trang "Xấu"
Một trong những điều tôi muốn đo lường là tác động đến việc tách trang - không phải việc tách trang bình thường (khi bạn thêm một trang mới) mà là khi bạn thực sự phải di chuyển dữ liệu giữa các trang để nhường chỗ cho nhiều hàng hơn. Jonathan Kehayias nói sâu hơn về vấn đề này trong bài đăng trên blog của anh ấy, "Theo dõi các phần tách trang có vấn đề trong SQL Server 2012 Sự kiện mở rộng - Không thực sự xảy ra lần này!", Điều này cũng cung cấp cơ sở cho phiên Sự kiện mở rộng mà tôi đã sử dụng để thu thập dữ liệu:
TẠO PHIÊN BẢN SỰ KIỆN [BadPageSplits] TRÊN MÁY CHỦ THÊM SỰ KIỆN sqlserver.transaction_log (WHERE operation =11 AND database_id =10) THÊM MỤC TIÊU package0.histogram (SET filter_event_name ='sqlserver.transaction_log', source_type =0, source =' ); MỤC TIÊU PHIÊN BẢN SỰ KIỆN [BadPageSplits] TRÊN MÁY CHỦ STATE =BẮT ĐẦU; ĐI
Và truy vấn tôi đã sử dụng để vẽ biểu đồ:
CHỌN t.name, SUM (tab.split_count) TỪ (CHỌN n.value ('(giá trị) [1]', 'bigint') AS cert_unit_id, n.value ('(@ count) [1]' , 'bigint') AS split_count FROM (CHỌN CAST (target_data as XML) target_data FROM sys.dm_xe_sessions AS s INNER JOIN sys.dm_xe_session_targets AS t ON s.address =t.event_session_address WHERE s.name ='BadPageSplits' AND t.target_name ='histogram') AS x CROSS ÁP DỤNG target_data.nodes ('HistogramTarget / Slot') as q (n)) AS tabINNER JOIN sys.allocation_units AS au ON tab.alloc_unit_id =au.allocation_unit_idINNER JOIN sys.partitions AS p ON au. container_id =p.partition_idINNER THAM GIA sys.tables AS t ON p.object_id =t. [object_id] GROUP BY t.name; Và đây là kết quả (bấm vào để phóng to):
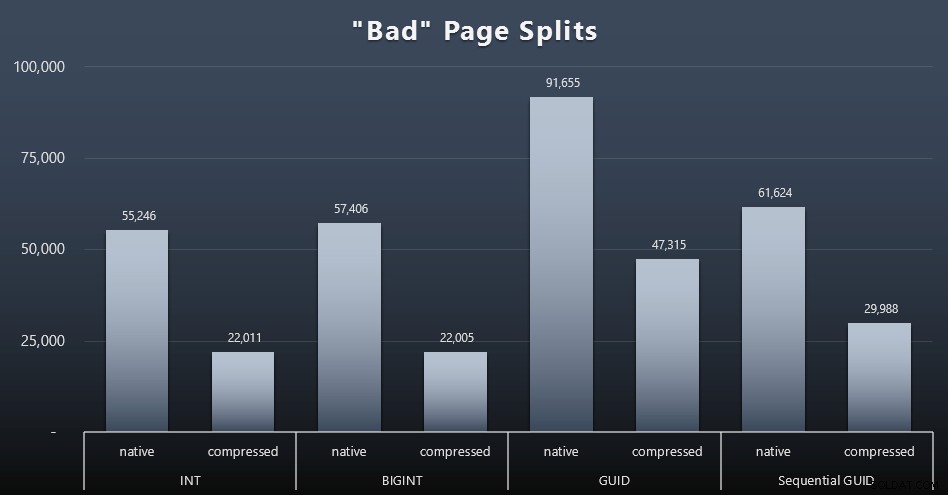
Mặc dù tôi đã lưu ý rằng trong tình huống của tôi (nơi tôi đang chạy trên SSD nhanh), sự khác biệt không thể chối cãi trong hoạt động I / O không ảnh hưởng trực tiếp đến thời gian chạy tổng thể, nhưng đây vẫn là một số liệu bạn sẽ muốn xem xét - đặc biệt nếu bạn không có SSD hoặc nếu khối lượng công việc của bạn đã bị ràng buộc I / O.
Kết luận
Mặc dù những bài kiểm tra này đã giúp tôi mở rộng tầm mắt hơn một chút về nhận thức lâu nay mà tôi đã bị thay đổi bởi phần cứng hiện đại hơn, nhưng tôi vẫn khá kiên quyết chống lại việc lãng phí dung lượng trên đĩa hoặc trong bộ nhớ. Trong khi tôi cố gắng chứng minh một số cân bằng và để GUID tỏa sáng, có rất ít ở đây từ góc độ hiệu suất để hỗ trợ chuyển từ INT / BIGINT sang một trong hai dạng UNIQUEIDENTIFIER - trừ khi bạn cần nó vì những lý do ít hữu hình khác (chẳng hạn như tạo khóa trong ứng dụng hoặc duy trì các giá trị khóa duy nhất trên các hệ thống khác nhau). Một bản tóm tắt nhanh, cho thấy rằng NEWID () là lựa chọn tồi nhất trong nhiều số liệu trong đó có sự khác biệt đáng kể (và trong hầu hết các trường hợp đó, NEWSEQUENTIALID () là một thứ hai gần nhất)):
| Số liệu | Xóa (các) Người thua cuộc? |
|---|---|
| Chèn không được kiểm tra | - vẽ - |
| Khối lượng công việc đồng thời | - vẽ - |
| Truy vấn riêng lẻ - Dân số | INT (nén) |
| Truy vấn riêng lẻ - Phân trang | NEWID () / NEWSEQUENTIALID () |
| Truy vấn riêng lẻ - Cập nhật | INT (gốc) / BIGINT (nén) |
| Các truy vấn riêng lẻ - SAU KHI kích hoạt | - vẽ - |
| Dung lượng đĩa | NEWID () |
| Phân mảnh chỉ mục theo cụm | NEWID () |
| Sử dụng nhóm đệm | NEWID () |
| Cách sử dụng tempdb | NEWID () |
| Tách trang "Xấu" | NEWID () |
Bảng 2:Những người thua nhiều nhất
Hãy tự mình kiểm tra những điều này; Tôi có thể tập hợp đầy đủ các tập lệnh của mình nếu bạn muốn chạy chúng trong môi trường của riêng mình. Mục đích ngắn gọn của toàn bộ bài đăng này khá đơn giản:có nhiều số liệu quan trọng cần xem xét ngoài tác động có thể dự đoán được đối với dung lượng đĩa, vì vậy không nên sử dụng nó một mình như một đối số theo cả hai hướng.
Bây giờ, tôi không muốn dòng suy nghĩ này bị giới hạn trong các phím. Nó thực sự nên được suy nghĩ về bất cứ khi nào có bất kỳ lựa chọn kiểu dữ liệu nào được thực hiện. Tôi thấy datetime được chọn thường xuyên, ví dụ:khi chỉ có một date hoặc smalldatetime là cần thiết. Trên các bảng giao dịch, điều này cũng có thể dẫn đến nhiều dung lượng đĩa bị lãng phí và điều này cũng giảm xuống một số tài nguyên khác.
Trong một thử nghiệm trong tương lai, tôi muốn so sánh kết quả cho một bảng lớn hơn nhiều (> 2 tỷ hàng). Tôi có thể mô phỏng điều này với INT bằng cách đặt hạt giống danh tính thành -2 tỷ, cho phép ~ 4 tỷ hàng. Và tôi muốn so sánh khối lượng công việc và dung lượng ổ đĩa / dấu chân bộ nhớ liên quan đến nhiều hơn một bảng duy nhất, vì một trong những lợi thế của khóa gầy là khi khóa đó được biểu diễn trong hàng chục bảng liên quan. Tôi đã theo dõi các sự kiện tự động duyệt, nhưng không có sự kiện nào, vì cơ sở dữ liệu đã được định kích thước trước đủ lớn để thích ứng với sự phát triển và tôi không nghĩ đến việc đo lường việc sử dụng nhật ký thực tế bên trong tệp nhật ký hiện có, vì vậy tôi muốn kiểm tra lại với các giá trị mặc định cho kích thước nhật ký và tốc độ phát triển tự động, và lần này là đo DBCC SQLPERF(LOGSPACE); . Cũng sẽ rất thú vị khi xây dựng lại thời gian và đo lường việc sử dụng nhật ký do kết quả của các hoạt động đó. Cuối cùng, tôi muốn làm cho I / O trở thành một yếu tố phù hợp hơn bằng cách tìm một máy chủ có đĩa cứng cơ học - Tôi biết có rất nhiều ở đó, nhưng ở một số cửa hàng, chúng khá khan hiếm.