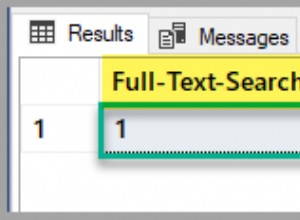
Đầu tiên, vấn đề bạn đang gặp phải ở đây là những gì bạn đang nói là "Nếu điểm nhỏ hơn 70, giá trị của biểu thức trường hợp này là đếm (xếp hạng). Nếu không, giá trị của biểu thức này là đếm (xếp hạng) . " Vì vậy, trong cả hai trường hợp, bạn luôn nhận được cùng một giá trị.
SELECT
CASE
WHEN grade < 70 THEN COUNT(rank)
ELSE COUNT(rank)
END
FROM
grades
count () chỉ đếm các giá trị không phải null, vì vậy, thông thường mẫu bạn sẽ thấy để thực hiện những gì bạn đang cố gắng là:
SELECT
count(CASE WHEN grade < 70 THEN 1 END) as grade_less_than_70,
count(CASE WHEN grade >= 70 and grade < 80 THEN 1 END) as grade_between_70_and_80
FROM
grades
Bằng cách đó, biểu thức trường hợp sẽ chỉ đánh giá bằng 1 khi biểu thức kiểm tra là đúng và sẽ là giá trị khác. Sau đó, count () sẽ chỉ đếm các trường hợp không rỗng, tức là khi biểu thức kiểm tra là đúng, điều này sẽ cung cấp cho bạn những gì bạn cần.
Chỉnh sửa:Như một lưu ý phụ, hãy lưu ý rằng điều này giống hệt như cách bạn đã viết điều này ban đầu bằng cách sử dụng count(if(test, true-value, false-value)) , chỉ được viết lại dưới dạng count(case when test then true-value end) (và null là giá trị thay thế sai vì else không được cung cấp cho trường hợp).
Chỉnh sửa:postgres 9.4 được phát hành một vài tháng sau cuộc trao đổi ban đầu này. Phiên bản đó đã giới thiệu các bộ lọc tổng hợp, có thể làm cho các tình huống như thế này trông đẹp hơn và rõ ràng hơn một chút. Câu trả lời này thỉnh thoảng vẫn nhận được một số phiếu tán thành, vì vậy nếu bạn tình cờ gặp ở đây và đang sử dụng một postgres mới hơn (tức là 9.4+), bạn có thể muốn xem xét phiên bản tương đương này:
Bộ lọcSELECT
count(*) filter (where grade < 70) as grade_less_than_70,
count(*) filter (where grade >= 70 and grade < 80) as grade_between_70_and_80
FROM
grades