Đi vào sản xuất là một công việc rất quan trọng phải được suy nghĩ và lên kế hoạch kỹ lưỡng từ trước. Một số quyết định không tốt có thể dễ dàng sửa chữa sau đó, nhưng một số khác thì không. Vì vậy, tốt hơn hết là bạn nên dành thêm thời gian đó để đọc các tài liệu, sách chính thức và nghiên cứu do người khác thực hiện sớm hơn là hối tiếc về sau. Điều này đúng với hầu hết các triển khai hệ thống máy tính và PostgreSQL không phải là ngoại lệ.
Lập kế hoạch ban đầu cho hệ thống
Một số quyết định phải được thực hiện sớm trước khi hệ thống hoạt động. PostgreSQL DBA phải trả lời một số câu hỏi:DB sẽ chạy trên kim loại trần, máy ảo hay thậm chí được chứa trong thùng chứa? Nó sẽ chạy trên cơ sở của tổ chức hay trên đám mây? Hệ điều hành nào sẽ được sử dụng? Bộ nhớ sẽ là loại đĩa quay hay SSD? Đối với mỗi kịch bản hoặc quyết định, đều có ưu và nhược điểm và cuộc gọi cuối cùng sẽ được thực hiện với sự hợp tác của các bên liên quan theo yêu cầu của tổ chức. Theo truyền thống, mọi người thường chạy PostgreSQL trên kim loại trần, nhưng điều này đã thay đổi đáng kể trong những năm gần đây với ngày càng nhiều nhà cung cấp đám mây cung cấp PostgreSQL như một tùy chọn tiêu chuẩn, đó là một dấu hiệu cho thấy sự phổ biến của PostgreSQL ngày càng tăng. Không phụ thuộc vào giải pháp cụ thể, DBA phải đảm bảo rằng dữ liệu sẽ an toàn, có nghĩa là cơ sở dữ liệu sẽ có thể sống sót sau các sự cố và đây là tiêu chí số 1 khi đưa ra quyết định về phần cứng và lưu trữ. Vì vậy, điều này đưa chúng ta đến mẹo đầu tiên!
Mẹo 1
Bất kể bộ điều khiển đĩa hoặc nhà sản xuất đĩa hoặc nhà cung cấp dịch vụ lưu trữ đám mây quảng cáo gì, bạn phải luôn đảm bảo rằng bộ nhớ không nói dối về fsync. Khi fsync trả về OK, dữ liệu sẽ được an toàn trên môi trường bất kể điều gì xảy ra sau đó (sự cố, mất điện, v.v.). Một công cụ tuyệt vời sẽ giúp bạn kiểm tra độ tin cậy của bộ nhớ cache ghi lại trên đĩa của bạn là diskchecker.pl.
Chỉ cần đọc ghi chú:https://brad.livejournal.com/2116715.html và làm bài kiểm tra.
Sử dụng một máy để nghe các sự kiện và máy thực tế để kiểm tra. Bạn sẽ thấy:
verifying: 0.00%
verifying: 10.65%
…..
verifying: 100.00%
Total errors: 0ở cuối báo cáo về máy được thử nghiệm.
Mối quan tâm thứ hai sau độ tin cậy là về hiệu suất. Các quyết định về hệ thống (CPU, bộ nhớ), từng quan trọng hơn nhiều vì sau này khá khó để thay đổi chúng. Nhưng ngày nay, trong kỷ nguyên đám mây, chúng ta có thể linh hoạt hơn về các hệ thống mà DB chạy trên đó. Điều này cũng đúng với việc lưu trữ, đặc biệt là trong thời kỳ đầu của hệ thống và trong khi kích thước vẫn còn nhỏ. Khi DB vượt qua kích thước con số TB, thì việc thay đổi các thông số lưu trữ cơ bản mà không cần phải sao chép hoàn toàn cơ sở dữ liệu - hoặc thậm chí tệ hơn, để thực hiện pg_dump, pg_restore ngày càng khó hơn. Mẹo thứ hai là về hiệu suất hệ thống.
Mẹo 2
Tương tự để luôn kiểm tra những lời hứa của nhà sản xuất về độ tin cậy, bạn cũng nên làm như vậy về hiệu suất phần cứng. Bonnie ++ là chuẩn hiệu suất lưu trữ phổ biến nhất cho các hệ thống giống Unix. Đối với kiểm tra hệ thống tổng thể (CPU, Bộ nhớ và cả bộ nhớ), không có gì đại diện hơn hiệu suất của DB. Vì vậy, bài kiểm tra hiệu suất cơ bản trên hệ thống mới của bạn sẽ chạy pgbench, bộ tiêu chuẩn PostgreSQL chính thức dựa trên TCP-B.
Bắt đầu với pgbench khá dễ dàng, tất cả những gì bạn phải làm là:
example@sqldat.com:~$ createdb pgbench
example@sqldat.com:~$ pgbench -i pgbench
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
creating tables...
100000 of 100000 tuples (100%) done (elapsed 0.12 s, remaining 0.00 s)
vacuum...
set primary keys...
done.
example@sqldat.com:~$ pgbench pgbench
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 1
query mode: simple
number of clients: 1
number of threads: 1
number of transactions per client: 10
number of transactions actually processed: 10/10
latency average = 2.038 ms
tps = 490.748098 (including connections establishing)
tps = 642.100047 (excluding connections establishing)
example@sqldat.com:~$Bạn nên luôn tham khảo pgbench sau bất kỳ thay đổi quan trọng nào mà bạn muốn đánh giá và so sánh kết quả.
Triển khai, tự động hóa và giám sát hệ thống
Khi bạn hoạt động, điều rất quan trọng là phải ghi lại và tái tạo các thành phần hệ thống chính của bạn, có các quy trình tự động để tạo dịch vụ và tác vụ lặp lại cũng như có các công cụ để thực hiện giám sát liên tục.
Mẹo 3
Một cách hữu ích để bắt đầu sử dụng PostgreSQL với tất cả các tính năng doanh nghiệp nâng cao của nó là ClusterControl của Somenines. Người ta có thể có một cụm PostgreSQL cấp doanh nghiệp, chỉ bằng cách nhấn một vài cú nhấp chuột. ClusterControl cung cấp tất cả các dịch vụ nói trên và nhiều dịch vụ khác. Thiết lập ClusterControl khá dễ dàng, chỉ cần làm theo hướng dẫn trên tài liệu chính thức. Khi bạn đã chuẩn bị hệ thống của mình (thường một hệ thống để chạy CC và một hệ thống cho PostgreSQL để thiết lập cơ bản) và thực hiện thiết lập SSH, thì bạn phải nhập các thông số cơ bản (IP, số cổng, v.v.) và nếu mọi việc suôn sẻ, bạn nên xem kết quả như sau:
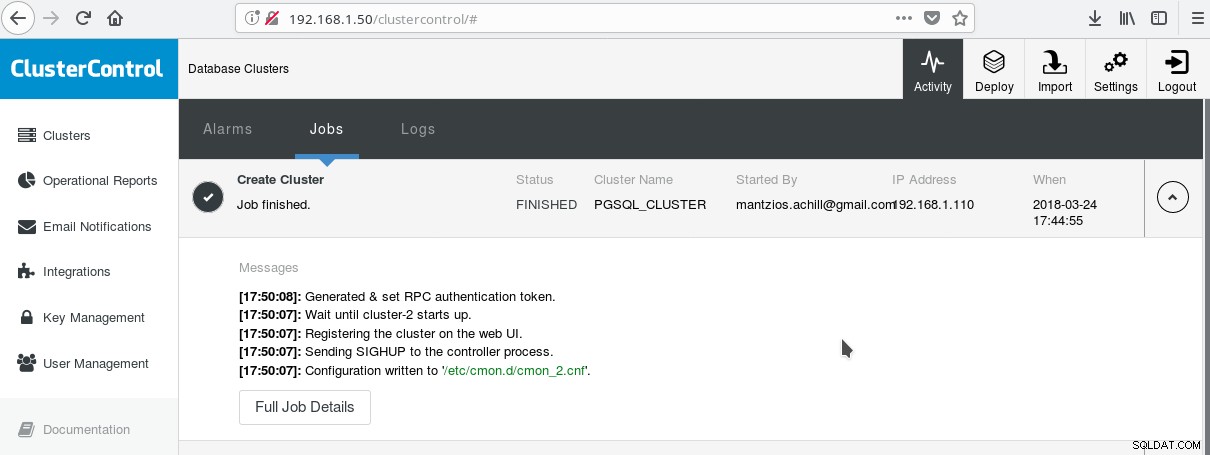
Và trong màn hình cụm chính:
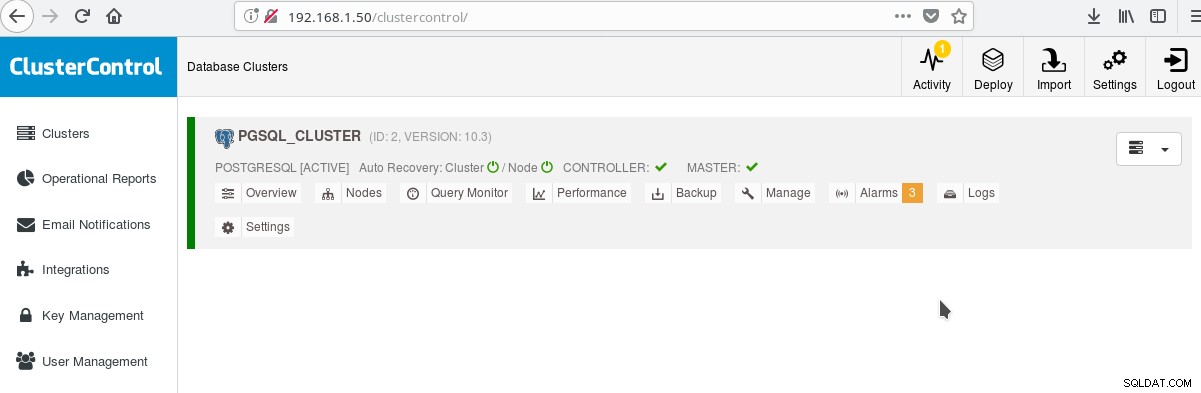
Bạn có thể đăng nhập vào máy chủ chính của mình và bắt đầu tạo lược đồ của mình! Tất nhiên, bạn có thể sử dụng làm cơ sở cụm mà bạn vừa tạo để xây dựng thêm cơ sở hạ tầng của mình (cấu trúc liên kết). Ý tưởng chung là có bố cục hệ thống tệp máy chủ ổn định và cấu hình cuối cùng trên máy chủ PostgreSQL và cơ sở dữ liệu người dùng / ứng dụng của bạn trước khi bạn bắt đầu tạo bản sao và standbys (nô lệ) dựa trên máy chủ hoàn toàn mới vừa được tạo của bạn.
Bố cục, Tham số và Cài đặt PostgreSQL
Ở giai đoạn khởi tạo cụm, quyết định quan trọng nhất là có sử dụng tổng kiểm tra dữ liệu trên các trang dữ liệu hay không. Nếu bạn muốn an toàn dữ liệu tối đa cho dữ liệu có giá trị (trong tương lai) của mình, thì đây là lúc để làm điều đó. Nếu có khả năng bạn muốn tính năng này trong tương lai và bạn không thực hiện nó ở giai đoạn này, bạn sẽ không thể thay đổi nó sau này (nếu không có pg_dump / pg_restore thì có). Đây là mẹo tiếp theo:
Mẹo 4
Để bật tổng kiểm tra dữ liệu, hãy chạy initdb như sau:
$ /usr/lib/postgresql/10/bin/initdb --data-checksums <DATADIR>Lưu ý rằng điều này nên được thực hiện tại thời điểm của mẹo 3 mà chúng tôi đã mô tả ở trên. Nếu bạn đã tạo cụm với ClusterControl, bạn sẽ phải chạy lại pg_createcluster bằng tay, vì tại thời điểm viết bài này, không có cách nào để yêu cầu hệ thống hoặc CC bao gồm tùy chọn này.
Một bước rất quan trọng khác trước khi bạn đi vào sản xuất là lập kế hoạch bố trí hệ thống tệp máy chủ. Hầu hết các bản phân phối Linux hiện đại (ít nhất là các bản dựa trên debian) gắn kết mọi thứ trên / nhưng với PostgreSQL, thông thường bạn không muốn điều đó. Sẽ có lợi nếu bạn có (các) vùng bảng của bạn trên (các) ổ đĩa riêng biệt, có một ổ đĩa dành riêng cho các tệp WAL và một ổ đĩa khác cho nhật ký pg. Nhưng quan trọng nhất là di chuyển WAL sang đĩa riêng của nó. Điều này đưa chúng ta đến mẹo tiếp theo.
Mẹo 5
Với PostgreSQL 10 trên Debian Stretch, bạn có thể di chuyển WAL của mình sang đĩa mới bằng các lệnh sau (giả sử đĩa mới có tên / dev / sdb):
# mkfs.ext4 /dev/sdb
# mount /dev/sdb /pgsql_wal
# mkdir /pgsql_wal/pgsql
# chown postgres:postgres /pgsql_wal/pgsql
# systemctl stop postgresql
# su postgres
$ cd /var/lib/postgresql/10/main/
$ mv pg_wal /pgsql_wal/pgsql/.
$ ln -s /pgsql_wal/pgsql/pg_wal
$ exit
# systemctl start postgresqlĐiều cực kỳ quan trọng là phải thiết lập chính xác ngôn ngữ và mã hóa cơ sở dữ liệu của bạn. Bỏ qua điều này ở giai đoạn được tạo và bạn sẽ rất hối tiếc về điều này, khi ứng dụng / DB của bạn chuyển sang lãnh thổ i18n, l10n. Mẹo tiếp theo chỉ cách thực hiện điều đó.
Mẹo 6
Bạn nên đọc các tài liệu chính thức và quyết định cài đặt COLLATE và CTYPE (createb --locale =) của mình (chịu trách nhiệm về thứ tự sắp xếp và phân loại ký tự) cũng như cài đặt bộ ký tự (createb --encoding =). Việc chỉ định UTF8 làm mã hóa sẽ cho phép cơ sở dữ liệu của bạn lưu trữ văn bản đa ngôn ngữ.
Tải xuống Báo cáo chính thức hôm nay Quản lý &Tự động hóa PostgreSQL với ClusterControlTìm hiểu về những điều bạn cần biết để triển khai, giám sát, quản lý và mở rộng PostgreSQLTải xuống Báo cáo chính thứcTính khả dụng cao của PostgreSQL
Kể từ PostgreSQL 9.0, khi tính năng sao chép trực tuyến trở thành một tính năng tiêu chuẩn, có thể có một hoặc nhiều standbys nóng chỉ đọc, do đó cho phép khả năng hướng lưu lượng chỉ đọc đến bất kỳ nô lệ nào có sẵn. Đã có kế hoạch mới để nhân rộng multimaster nhưng tại thời điểm của bài viết này (10.3), chỉ có thể có một master read-write, ít nhất là trong sản phẩm mã nguồn mở chính thức. Để biết mẹo tiếp theo giải quyết chính xác vấn đề này.
Mẹo 7
Chúng tôi sẽ sử dụng ClusterControl PGSQL_CLUSTER được tạo trong Mẹo 3. Đầu tiên, chúng tôi tạo một máy thứ hai sẽ hoạt động như máy nô lệ chỉ đọc của chúng tôi (chế độ chờ nóng trong thuật ngữ PostgreSQL). Sau đó, chúng tôi nhấp vào Add Replication slave, và chọn master của chúng tôi và nô lệ mới. Sau khi công việc kết thúc, bạn sẽ thấy kết quả này:
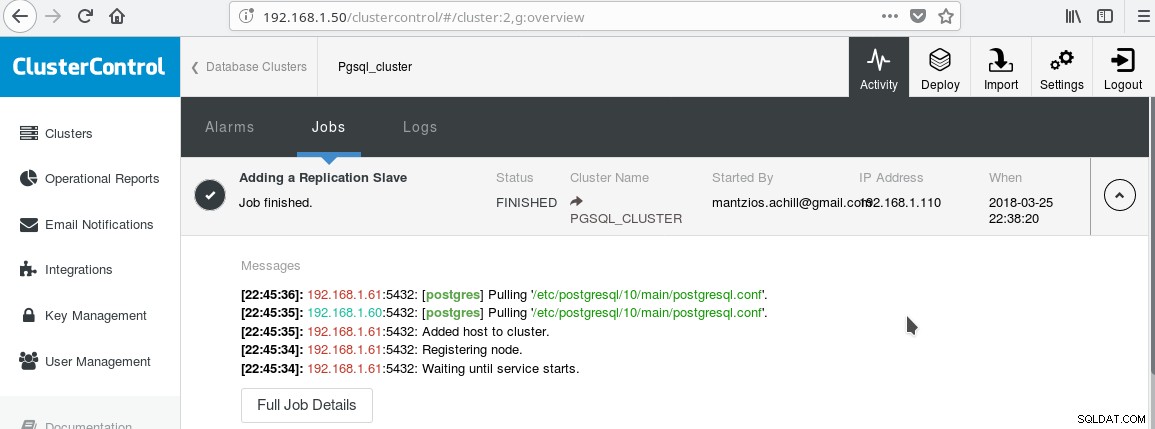
Và cụm bây giờ sẽ giống như sau:
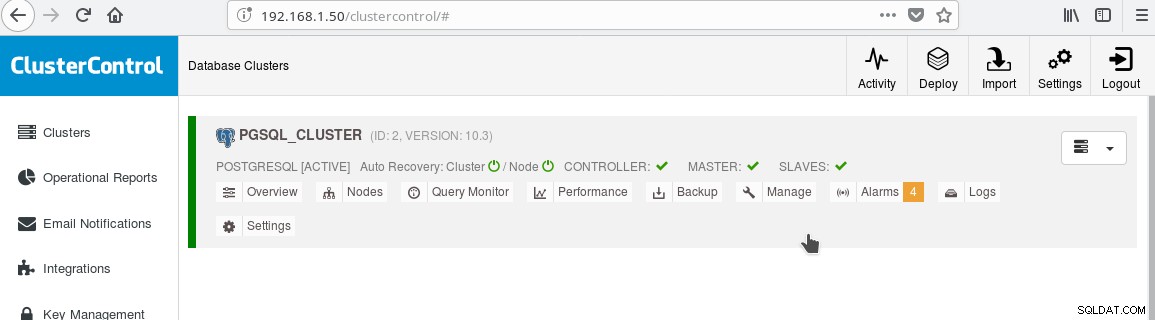
Lưu ý biểu tượng “được đánh dấu” màu xanh lục trên nhãn “SLAVES” bên cạnh “MASTER”. Bạn có thể xác minh rằng tính năng sao chép trực tuyến hoạt động bằng cách tạo một đối tượng cơ sở dữ liệu (cơ sở dữ liệu, bảng, v.v.) hoặc chèn một số hàng trong bảng trên trang cái và xem thay đổi ở chế độ chờ.
Sự hiện diện của chế độ chờ chỉ đọc cho phép chúng tôi thực hiện cân bằng tải cho các máy khách thực hiện các truy vấn chỉ được chọn giữa hai máy chủ có sẵn, máy chủ và máy chủ. Điều này đưa chúng ta đến mẹo 8.
Mẹo 8
Bạn có thể bật cân bằng tải giữa hai máy chủ bằng HAProxy. Với ClusterControl, điều này khá dễ thực hiện. Bạn bấm vào Manage-> Load Balancer. Sau khi chọn máy chủ HAProxy của bạn, ClusterControl sẽ cài đặt mọi thứ cho bạn:xinetd trên tất cả các trường hợp bạn đã chỉ định và HAProxy trên máy chủ được chỉ định HAProxy của bạn. Sau khi công việc hoàn thành thành công, bạn sẽ thấy:
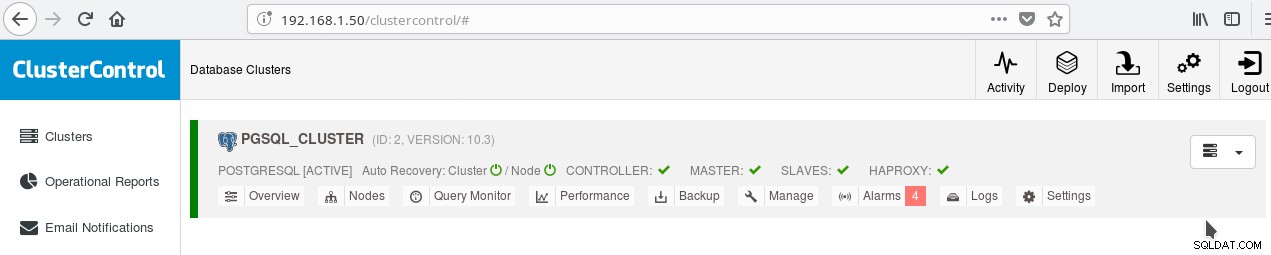
Lưu ý đánh dấu màu xanh lá cây HAPROXY bên cạnh SLAVES. Bây giờ bạn có thể kiểm tra xem HAProxy có hoạt động không:
example@sqldat.com:~$ psql -h localhost -p 5434
psql (10.3 (Debian 10.3-1.pgdg90+1))
SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
Type "help" for help.
postgres=# select inet_server_addr();
inet_server_addr
------------------
192.168.1.61
(1 row)
--
-- HERE STOP PGSQL SERVER AT 192.168.1.61
--
postgres=# select inet_server_addr();
FATAL: terminating connection due to administrator command
SSL connection has been closed unexpectedly
The connection to the server was lost. Attempting reset: Succeeded.
postgres=# select inet_server_addr();
inet_server_addr
------------------
192.168.1.60
(1 row)
postgres=#Mẹo 9
Bên cạnh việc định cấu hình cho HA và cân bằng tải, luôn có lợi khi có một số loại nhóm kết nối phía trước máy chủ PostgreSQL. Pgpool và Pgbouncer là hai dự án đến từ cộng đồng PostgreSQL. Nhiều máy chủ ứng dụng doanh nghiệp cũng cung cấp các nhóm riêng của họ. Pgbouncer đã rất phổ biến do tính đơn giản, tốc độ và tính năng “tổng hợp giao dịch”, theo đó, kết nối với máy chủ được giải phóng sau khi giao dịch kết thúc, khiến nó có thể được sử dụng lại cho các giao dịch tiếp theo có thể đến từ cùng một phiên hoặc một phiên khác . Cài đặt tổng hợp giao dịch phá vỡ một số tính năng tổng hợp phiên, nhưng nhìn chung, việc chuyển đổi sang thiết lập "tổng hợp giao dịch" đã được thiết lập rất dễ dàng và nhược điểm không quá quan trọng trong trường hợp chung. Một thiết lập phổ biến là định cấu hình nhóm máy chủ ứng dụng với các kết nối bán liên tục:Nhóm kết nối khá lớn trên mỗi người dùng hoặc mỗi ứng dụng (kết nối với pgbouncer) với thời gian chờ lâu. Bằng cách này, thời gian kết nối từ ứng dụng là tối thiểu trong khi pgbouncer sẽ giúp giữ ít kết nối đến máy chủ nhất có thể.
Một điều có lẽ bạn sẽ quan tâm nhất khi bạn sử dụng PostgreSQL là hiểu và sửa các truy vấn chậm. Các công cụ giám sát mà chúng tôi đã đề cập trong blog trước như pg_stat_statements và cả màn hình của các công cụ như ClusterControl sẽ giúp bạn xác định và có thể đề xuất ý tưởng để khắc phục các truy vấn chậm. Tuy nhiên, khi bạn xác định được truy vấn chậm, bạn sẽ cần chạy GIẢI THÍCH hoặc PHÂN TÍCH GIẢI THÍCH để xem chính xác chi phí và thời gian liên quan đến kế hoạch truy vấn. Mẹo tiếp theo là về một công cụ rất hữu ích để làm điều đó.
Mẹo 10
Bạn phải chạy PHÂN TÍCH GIẢI THÍCH trên cơ sở dữ liệu của mình, sau đó sao chép đầu ra và dán vào công cụ trực tuyến giải thích phân tích của depesz và nhấp vào gửi. Sau đó, bạn sẽ thấy ba tab:HTML, TEXT và STATS. HTML chứa chi phí, thời gian và số vòng lặp cho mọi nút trong kế hoạch. Tab STATS hiển thị thống kê cho mỗi loại nút. Bạn nên quan sát cột "% truy vấn" để biết chính xác truy vấn của mình bị ảnh hưởng ở đâu.
Khi bạn quen hơn với PostgreSQL, bạn sẽ tìm thấy nhiều mẹo khác cho riêng mình!