Quản lý cài đặt PostgreSQL liên quan đến việc kiểm tra và kiểm soát nhiều khía cạnh trong ngăn xếp phần mềm / cơ sở hạ tầng mà PostgreSQL chạy trên đó. Điều này phải bao gồm:
- Điều chỉnh ứng dụng liên quan đến việc sử dụng cơ sở dữ liệu / giao dịch / kết nối
- Mã cơ sở dữ liệu (truy vấn, hàm)
- Hệ thống cơ sở dữ liệu (hiệu suất, HA, các bản sao lưu)
- Phần cứng / Cơ sở hạ tầng (đĩa, CPU / Bộ nhớ)
Cốt lõi của PostgreSQL cung cấp lớp cơ sở dữ liệu mà trên đó chúng tôi tin tưởng dữ liệu của mình sẽ được lưu trữ, xử lý và phục vụ. Nó cũng cung cấp tất cả các công nghệ để có một hệ thống thực sự hiện đại, hiệu quả, đáng tin cậy và an toàn. Nhưng thường thì công nghệ này không có sẵn dưới dạng sản phẩm cấp doanh nghiệp / doanh nghiệp đã được tinh chỉnh, sẵn sàng sử dụng trong bản phân phối PostgreSQL cốt lõi. Thay vào đó, có rất nhiều sản phẩm / giải pháp của cộng đồng PostgreSQL hoặc các dịch vụ thương mại đáp ứng những nhu cầu đó. Các giải pháp đó có thể là các cải tiến thân thiện với người dùng đối với các công nghệ cốt lõi, hoặc các phần mở rộng của các công nghệ cốt lõi hoặc thậm chí là sự tích hợp giữa các thành phần PostgreSQL và các thành phần khác của hệ thống. Trong blog trước của chúng tôi có tiêu đề Mười Mẹo để Đi vào Sản xuất với PostgreSQL, chúng tôi đã xem xét một số công cụ có thể giúp quản lý cài đặt PostgreSQL trong quá trình sản xuất. Trong blog này, chúng ta sẽ khám phá chi tiết hơn các khía cạnh phải được đề cập khi quản lý cài đặt PostgreSQL trong sản xuất và các công cụ được sử dụng phổ biến nhất cho mục đích đó. Chúng tôi sẽ đề cập đến các chủ đề sau:
- Triển khai
- Quản lý
- Chia tỷ lệ
- Giám sát
Triển khai
Ngày xưa, mọi người thường tải và biên dịch PostgreSQL bằng tay, sau đó cấu hình các thông số thời gian chạy và kiểm soát truy cập của người dùng. Vẫn có một số trường hợp có thể cần đến điều này nhưng khi các hệ thống trưởng thành và bắt đầu phát triển, nhu cầu về các cách tiêu chuẩn hóa hơn để triển khai và quản lý Postgresql đã nảy sinh. Hầu hết các hệ điều hành đều cung cấp các gói để cài đặt, triển khai và quản lý các cụm PostgreSQL. Debian đã chuẩn hóa bố cục hệ thống của riêng họ hỗ trợ nhiều phiên bản Postgresql, và nhiều cụm trên mỗi phiên bản cùng một lúc. gói postgresql-common debian cung cấp các công cụ cần thiết. Ví dụ:để tạo một cụm mới (gọi là i18n_cluster) cho PostgreSQL phiên bản 10 trong Debian, chúng tôi có thể thực hiện việc đó bằng cách đưa ra các lệnh sau:
$ pg_createcluster 10 i18n_cluster -- --encoding=UTF-8 --data-checksumsSau đó làm mới systemd:
$ sudo systemctl daemon-reloadvà cuối cùng bắt đầu và sử dụng cụm mới:
$ sudo systemctl start example@sqldat.com_cluster.service
$ createdb -p 5434 somei18ndb(lưu ý rằng Debian xử lý các cụm khác nhau bằng cách sử dụng các cổng khác nhau 5432, 5433, v.v.)
Khi nhu cầu triển khai tự động nhiều hơn và quy mô lớn hơn, ngày càng có nhiều cài đặt sử dụng các công cụ tự động hóa như Ansible, Chef và Puppet. Bên cạnh tự động hóa và khả năng tái tạo của các triển khai, các công cụ tự động hóa rất tuyệt vời vì chúng là một cách hay để ghi lại việc triển khai và cấu hình của một cụm. Mặt khác, tự động hóa đã phát triển để trở thành một lĩnh vực rộng lớn, đòi hỏi những người có kỹ năng viết, quản lý và chạy các tập lệnh tự động. Có thể tìm thấy thêm thông tin về cấp phép PostgreSQL trong blog này:Trở thành DBA PostgreSQL:Cấp phép và Triển khai.
Quản lý
Quản lý một hệ thống trực tiếp bao gồm các nhiệm vụ như:lên lịch sao lưu và theo dõi trạng thái của chúng, khôi phục sau thảm họa, quản lý cấu hình, quản lý tính sẵn sàng cao và xử lý chuyển đổi dự phòng tự động. Việc sao lưu một cụm Postgresql có thể được thực hiện theo nhiều cách khác nhau. Các công cụ cấp thấp:
- pg_dump truyền thống (sao lưu lôgic)
- bản sao lưu cấp hệ thống tệp (sao lưu vật lý)
- pg_basebackup (sao lưu vật lý)
Hoặc cấp cao hơn:
- Barman
- PgBackRest
Mỗi cách trong số đó bao gồm các trường hợp sử dụng và tình huống khôi phục khác nhau, đồng thời có sự phức tạp khác nhau. Sao lưu PostgreSQL có liên quan chặt chẽ đến các khái niệm về lưu trữ và nhân rộng PITR, WAL. Qua nhiều năm, quy trình lấy, kiểm tra và cuối cùng là sử dụng các bản sao lưu với PostgreSQL đã phát triển thành một nhiệm vụ phức tạp. Người ta có thể tìm thấy tổng quan tốt đẹp về các giải pháp sao lưu cho PostgreSQL trong blog này:Các công cụ sao lưu hàng đầu cho PostgreSQL.
Về tính khả dụng cao và tự động chuyển đổi dự phòng, mức tối thiểu tối thiểu mà một cài đặt phải có để thực hiện điều này là:
- Một cơ sở chính đang hoạt động
- Chế độ chờ nóng chấp nhận WAL được phát trực tiếp từ mạng chính
- Trong trường hợp chính không thành công, một phương pháp để thông báo cho phương thức chính rằng nó không còn là phương thức chính (đôi khi được gọi là STONITH)
- Cơ chế nhịp tim để kiểm tra kết nối giữa hai máy chủ và tình trạng của máy chủ chính
- Một phương pháp để thực hiện chuyển đổi dự phòng (ví dụ:thông qua quảng cáo pg_ctl hoặc tệp kích hoạt)
- Quy trình tự động để tạo lại thiết bị chính cũ dưới dạng chế độ chờ mới:Sau khi phát hiện thấy sự cố hoặc lỗi trên thiết bị chính thì chế độ chờ phải được nâng cấp làm chế độ chờ chính mới. Chính cũ không còn hợp lệ hoặc không thể sử dụng được nữa. Vì vậy hệ thống phải có cách xử lý trạng thái này giữa chuyển đổi dự phòng và tạo lại máy chủ chính cũ làm chế độ chờ mới. Trạng thái này được gọi là trạng thái suy giảm và PostgreSQL cung cấp một công cụ gọi là pg_rewind để tăng tốc quá trình đưa trang chính cũ trở lại trạng thái có thể đồng bộ hóa từ trang chính mới.
- Một phương pháp để thực hiện chuyển đổi theo yêu cầu / theo kế hoạch
Một công cụ được sử dụng rộng rãi để xử lý tất cả những điều trên là Repmgr. Chúng tôi sẽ mô tả thiết lập tối thiểu sẽ cho phép chuyển đổi thành công. Chúng tôi bắt đầu bằng một PostgreSQL 10.4 chính đang hoạt động chạy trên FreeBSD 11.1, được xây dựng và cài đặt theo cách thủ công, và repmgr 4.0 cũng được xây dựng và cài đặt theo cách thủ công cho phiên bản này (10.4). Chúng tôi sẽ sử dụng hai máy chủ có tên fbsd (192.168.1.80) và fbsdclone (192.168.1.81) với các phiên bản giống hệt nhau của PostgreSQL và repmgr. Trên chính (ban đầu là fbsd, 192.168.1.80), chúng tôi đảm bảo các tham số PostgreSQL sau được đặt:
max_wal_senders = 10
wal_level = 'logical'
hot_standby = on
archive_mode = 'on'
archive_command = '/usr/bin/true'
wal_keep_segments = '1000' Sau đó, chúng tôi tạo người dùng repmgr (dưới dạng superuser) và cơ sở dữ liệu:
example@sqldat.com:~ % createuser -s repmgr
example@sqldat.com:~ % createdb repmgr -O repmgrvà thiết lập kiểm soát truy cập dựa trên máy chủ lưu trữ trong pg_hba.conf bằng cách đặt các dòng sau lên đầu:
local replication repmgr trust
host replication repmgr 127.0.0.1/32 trust
host replication repmgr 192.168.1.0/24 trust
local repmgr repmgr trust
host repmgr repmgr 127.0.0.1/32 trust
host repmgr repmgr 192.168.1.0/24 trustChúng tôi đảm bảo rằng chúng tôi thiết lập đăng nhập không cần mật khẩu cho người dùng repmgr trong tất cả các nút của cụm, trong trường hợp của chúng tôi là fbsd và fbsdclone bằng cách đặt ủy quyền trong .ssh và sau đó chia sẻ .ssh. Sau đó, chúng tôi tạo repmrg.conf trên chính là:
example@sqldat.com:~ % cat /etc/repmgr.conf
node_id=1
node_name=fbsd
conninfo='host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/usr/local/var/lib/pgsql/data'Sau đó, chúng tôi đăng ký chính:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf primary register
NOTICE: attempting to install extension "repmgr"
NOTICE: "repmgr" extension successfully installed
NOTICE: primary node record (id: 1) registeredVà kiểm tra trạng thái của cụm:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+------+---------+-----------+----------+----------+---------------------------------------------------------------
1 | fbsd | primary | * running | | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2Bây giờ chúng tôi làm việc ở chế độ chờ bằng cách thiết lập repmgr.conf như sau:
example@sqldat.com:~ % cat /etc/repmgr.conf
node_id=2
node_name=fbsdclone
conninfo='host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2'
data_directory='/usr/local/var/lib/pgsql/data'Ngoài ra, chúng tôi đảm bảo rằng thư mục dữ liệu được chỉ định ngay trong dòng trên tồn tại, trống và có quyền chính xác:
example@sqldat.com:~ % rm -fr data && mkdir data
example@sqldat.com:~ % chmod 700 dataBây giờ chúng tôi phải sao chép sang chế độ chờ mới của mình:
example@sqldat.com:~ % repmgr -h 192.168.1.80 -U repmgr -f /etc/repmgr.conf --force standby clone
NOTICE: destination directory "/usr/local/var/lib/pgsql/data" provided
NOTICE: starting backup (using pg_basebackup)...
HINT: this may take some time; consider using the -c/--fast-checkpoint option
NOTICE: standby clone (using pg_basebackup) complete
NOTICE: you can now start your PostgreSQL server
HINT: for example: pg_ctl -D /usr/local/var/lib/pgsql/data start
HINT: after starting the server, you need to register this standby with "repmgr standby register"Và bắt đầu ở chế độ chờ:
example@sqldat.com:~ % pg_ctl -D data startTại thời điểm này, bản sao sẽ hoạt động như mong đợi, hãy xác minh điều này bằng cách truy vấn pg_stat_replication (fbsd) và pg_stat_wal_receiver (fbsdclone). Bước tiếp theo là đăng ký chế độ chờ:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf standby registerBây giờ chúng ta có thể nhận được trạng thái của cụm ở chế độ chờ hoặc chính và xác minh rằng chế độ chờ đã được đăng ký:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+-----------+---------+-----------+----------+----------+---------------------------------------------------------------
1 | fbsd | primary | * running | | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2
2 | fbsdclone | standby | running | fbsd | default | host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2Bây giờ, giả sử rằng chúng ta muốn thực hiện chuyển đổi thủ công theo lịch trình theo thứ tự, ví dụ:để thực hiện một số công việc quản trị trên nút fbsd. Trên nút chờ, chúng tôi chạy lệnh sau:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf standby switchover
…
NOTICE: STANDBY SWITCHOVER has completed successfullyChuyển đổi đã được thực hiện thành công! Hãy xem chương trình cụm mang lại gì:
example@sqldat.com:~ % repmgr -f /etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Connection string
----+-----------+---------+-----------+-----------+----------+---------------------------------------------------------------
1 | fbsd | standby | running | fbsdclone | default | host=192.168.1.80 user=repmgr dbname=repmgr connect_timeout=2
2 | fbsdclone | primary | * running | | default | host=192.168.1.81 user=repmgr dbname=repmgr connect_timeout=2Hai máy chủ đã hoán đổi vai trò! Repmgr cung cấp daemon repmgrd cung cấp khả năng giám sát, chuyển đổi dự phòng tự động, cũng như các thông báo / cảnh báo. Kết hợp repmgrd với pgbouncer, có thể triển khai cập nhật tự động thông tin kết nối của cơ sở dữ liệu, do đó cung cấp hàng rào cho nút chính bị lỗi (ngăn không cho ứng dụng sử dụng nút bị lỗi) cũng như cung cấp thời gian ngừng hoạt động tối thiểu cho ứng dụng. Trong các chương trình phức tạp hơn, một ý tưởng khác là kết hợp Keepalived với HAProxy trên pgbouncer và repmgr, để đạt được:
- cân bằng tải (mở rộng quy mô)
- tính khả dụng cao
Lưu ý rằng ClusterControl cũng quản lý chuyển đổi dự phòng các thiết lập sao chép PostgreSQL và tích hợp HAProxy và VirtualIP để tự động định tuyến lại các kết nối máy khách đến máy chủ đang làm việc. Có thể tìm thấy thêm thông tin trong sách trắng này về Tự động hóa PostgreSQL.
Tải xuống Báo cáo chính thức hôm nay Quản lý &Tự động hóa PostgreSQL với ClusterControlTìm hiểu về những điều bạn cần biết để triển khai, giám sát, quản lý và mở rộng PostgreSQLTải xuống Báo cáo chính thứcChia tỷ lệ
Kể từ PostgreSQL 10 (và 11), vẫn không có cách nào để có bản sao đa chủ, ít nhất là không phải từ PostgreSQL cốt lõi. Điều này có nghĩa là chỉ hoạt động được chọn (chỉ đọc) mới có thể được mở rộng. Việc mở rộng quy mô trong PostgreSQL đạt được bằng cách thêm nhiều standby nóng hơn, do đó cung cấp nhiều tài nguyên hơn cho hoạt động chỉ đọc. Với repmgr, dễ dàng thêm chế độ chờ mới như chúng ta đã thấy trước đó thông qua bản sao chế độ chờ và đăng ký chờ các lệnh. Cấu hình của bộ cân bằng tải được thêm vào (hoặc loại bỏ) các điểm chờ. HAProxy, như đã đề cập ở trên trong chủ đề quản lý, là một trình cân bằng tải phổ biến cho PostgreSQL. Thông thường, nó được kết hợp với Keepalived cung cấp IP ảo thông qua VRRP. Bạn có thể tìm thấy tổng quan tốt đẹp về việc sử dụng HAProxy và Keepalived cùng với PostgreSQL trong bài viết này:Cân bằng tải PostgreSQL bằng HAProxy &Keepalived.
Giám sát
Tổng quan về những gì cần giám sát trong PostgreSQL có thể được tìm thấy trong bài viết này:Những điều quan trọng cần theo dõi trong PostgreSQL - Phân tích khối lượng công việc của bạn. Có nhiều công cụ có thể cung cấp giám sát hệ thống và postgresql thông qua các plugin. Một số công cụ bao gồm lĩnh vực trình bày biểu đồ đồ họa của các giá trị lịch sử (munin), các công cụ khác bao gồm lĩnh vực theo dõi dữ liệu trực tiếp và cung cấp cảnh báo trực tiếp (nagios), trong khi một số công cụ bao gồm cả hai lĩnh vực (zabbix). Bạn có thể tìm thấy danh sách các công cụ như vậy cho PostgreSQL tại đây:https://wiki.postgresql.org/wiki/Moosystem. Một công cụ phổ biến để giám sát ngoại tuyến (dựa trên tệp nhật ký) là pgBadger. pgBadger là một tập lệnh Perl hoạt động bằng cách phân tích cú pháp nhật ký PostgreSQL (thường bao gồm hoạt động của một ngày), trích xuất thông tin, thống kê tính toán và cuối cùng tạo ra một trang html ưa thích trình bày kết quả. pgBadger không hạn chế cài đặt log_line_prefix, nó có thể thích ứng với định dạng hiện có của bạn. Ví dụ:nếu bạn đã đặt trong postgresql.conf của mình một cái gì đó như:
log_line_prefix = '%r [%p] %c %m %a %example@sqldat.com%d line:%l 'thì lệnh pgbadger để phân tích cú pháp tệp nhật ký và tạo ra kết quả có thể giống như sau:
./pgbadger --prefix='%r [%p] %c %m %a %example@sqldat.com%d line:%l ' -Z +2 -o pgBadger_$today.html $yesterdayfile.log && rm -f $yesterdayfile.logpgBadger cung cấp báo cáo cho:
- Thống kê tổng quan (chủ yếu là lưu lượng truy cập SQL)
- Kết nối (mỗi giây, mỗi cơ sở dữ liệu / người dùng / máy chủ)
- Phiên (số lượng, thời gian phiên, trên mỗi cơ sở dữ liệu / người dùng / máy chủ / ứng dụng)
- Điểm kiểm tra (bộ đệm, tệp wal, hoạt động)
- Sử dụng tệp tạm thời
- Hút chân không / Phân tích hoạt động (trên mỗi bảng, bộ dữ liệu / trang đã bị xóa)
- Khóa
- Truy vấn (theo loại / cơ sở dữ liệu / người dùng / máy chủ / ứng dụng, thời lượng theo người dùng)
- Hàng đầu (Truy vấn:chậm nhất, tốn thời gian, thường xuyên hơn, chuẩn hóa chậm nhất)
- Sự kiện (Lỗi, Cảnh báo, Tử vong, v.v.)
Màn hình hiển thị các phiên có dạng như sau:
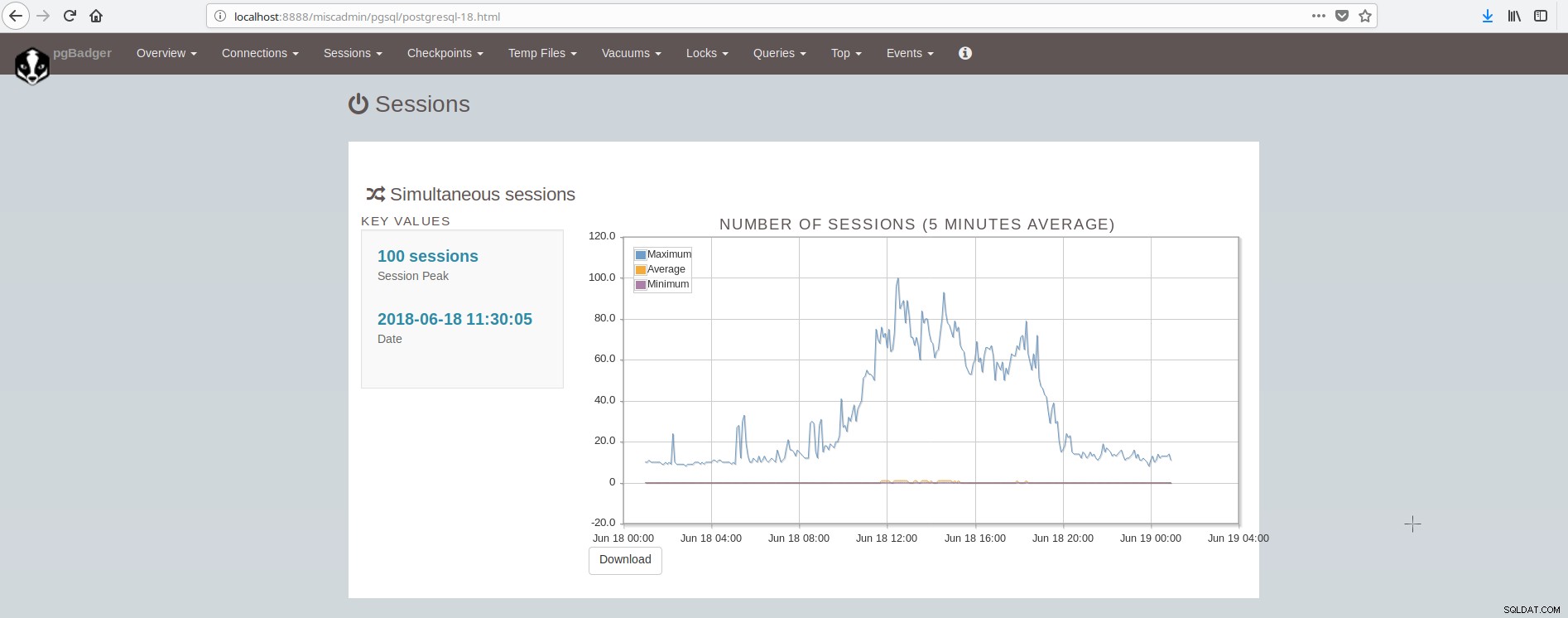
Như chúng ta có thể kết luận, cài đặt PostgreSQL trung bình phải tích hợp và chăm sóc nhiều công cụ để có cơ sở hạ tầng nhanh và đáng tin cậy hiện đại và điều này khá phức tạp để đạt được, trừ khi có các nhóm lớn tham gia vào quản trị hệ thống và postgresql. Một bộ phần mềm tốt thực hiện tất cả những điều trên và hơn thế nữa là ClusterControl.