Giám sát là một trong những nhiệm vụ cơ bản trong bất kỳ hệ thống nào. Nó có thể giúp chúng tôi phát hiện các vấn đề và thực hiện hành động, hoặc đơn giản là để biết trạng thái hiện tại của hệ thống của chúng tôi. Sử dụng màn hình trực quan có thể giúp chúng tôi hiệu quả hơn vì chúng tôi có thể dễ dàng phát hiện các vấn đề về hiệu suất hơn.
Trong blog này, chúng ta sẽ xem cách sử dụng SCUMM để theo dõi cơ sở dữ liệu PostgreSQL của chúng ta và những số liệu nào chúng ta có thể sử dụng cho nhiệm vụ này. Chúng tôi cũng sẽ xem qua các trang tổng quan có sẵn, vì vậy bạn có thể dễ dàng tìm ra điều gì đang thực sự xảy ra với các phiên bản PostgreSQL của bạn.
SCUMM là gì?
Trước hết, hãy xem SCUMM (Giám sát và Quản lý Hợp nhất của Somenines ClusterControl).
Đó là một giải pháp dựa trên tác nhân mới với các tác nhân được cài đặt trên các nút cơ sở dữ liệu.
Đại lý SCUMM là các nhà xuất khẩu Prometheus, xuất các chỉ số từ các dịch vụ như PostgreSQL dưới dạng chỉ số Prometheus.
Máy chủ Prometheus được sử dụng để thu thập và lưu trữ dữ liệu chuỗi thời gian từ SCUMM Agent.
Prometheus là một bộ công cụ cảnh báo và giám sát hệ thống mã nguồn mở được xây dựng ban đầu tại SoundCloud. Bây giờ nó là một dự án mã nguồn mở độc lập và được duy trì một cách độc lập.
Prometheus được thiết kế để đảm bảo độ tin cậy, là hệ thống bạn sử dụng trong thời gian ngừng hoạt động để cho phép bạn nhanh chóng chẩn đoán sự cố.
Cách sử dụng SCUMM?
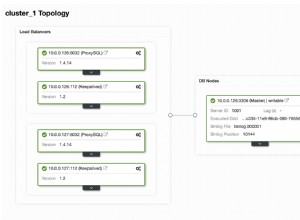
Khi sử dụng ClusterControl, khi chúng ta chọn một cụm, chúng ta có thể thấy tổng quan về cơ sở dữ liệu của mình, cũng như một số số liệu cơ bản có thể được sử dụng để xác định một vấn đề. Trong trang tổng quan bên dưới, chúng ta có thể thấy thiết lập chủ-tớ với một chủ và 2 nô lệ, với HAProxy và Keepalived.
 Tổng quan về ClusterControl
Tổng quan về ClusterControl Nếu chúng ta đi tới tùy chọn “Trang tổng quan”, chúng ta có thể thấy một thông báo như sau.
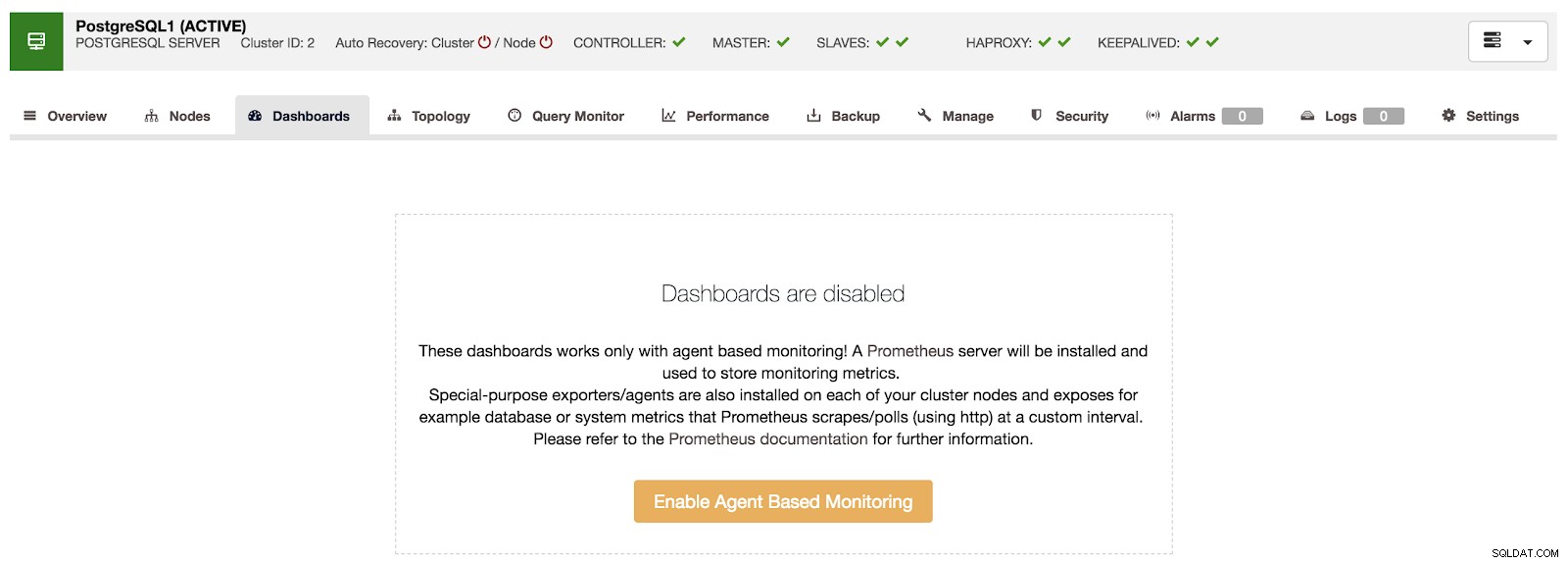 Đã tắt ClusterControl Dashboards
Đã tắt ClusterControl Dashboards Để sử dụng tính năng này, chúng ta phải kích hoạt tác nhân được đề cập ở trên. Đối với điều này, chúng tôi chỉ phải nhấn vào nút "Bật theo dõi dựa trên tác nhân" trong phần này.
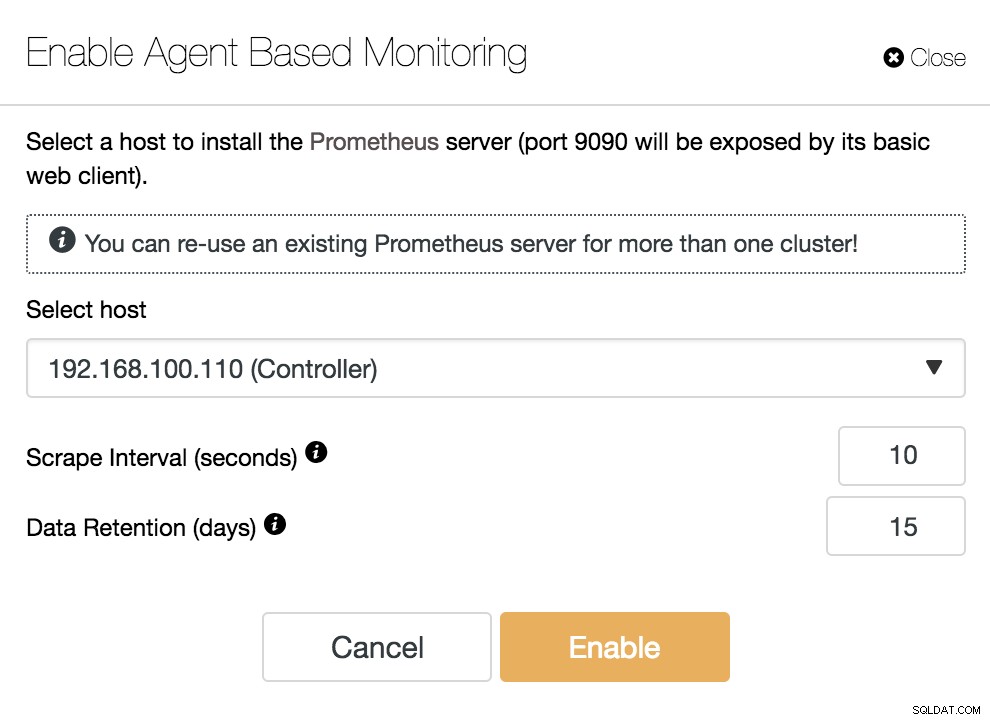 ClusterControl Bật theo dõi dựa trên tác nhân
ClusterControl Bật theo dõi dựa trên tác nhân Để kích hoạt tác nhân của chúng tôi, chúng tôi phải chỉ định máy chủ lưu trữ nơi chúng tôi sẽ cài đặt máy chủ Prometheus, như chúng ta có thể thấy trong ví dụ, có thể là máy chủ ClusterControl của chúng tôi.
Chúng tôi cũng phải chỉ rõ:
- Khoảng thời gian cạo (giây):Đặt tần suất các nút được quét cho các chỉ số. Mặc định là 10 giây.
- Lưu giữ dữ liệu (ngày):Đặt khoảng thời gian các chỉ số được lưu giữ trước khi bị xóa. Mặc định là 15 ngày.
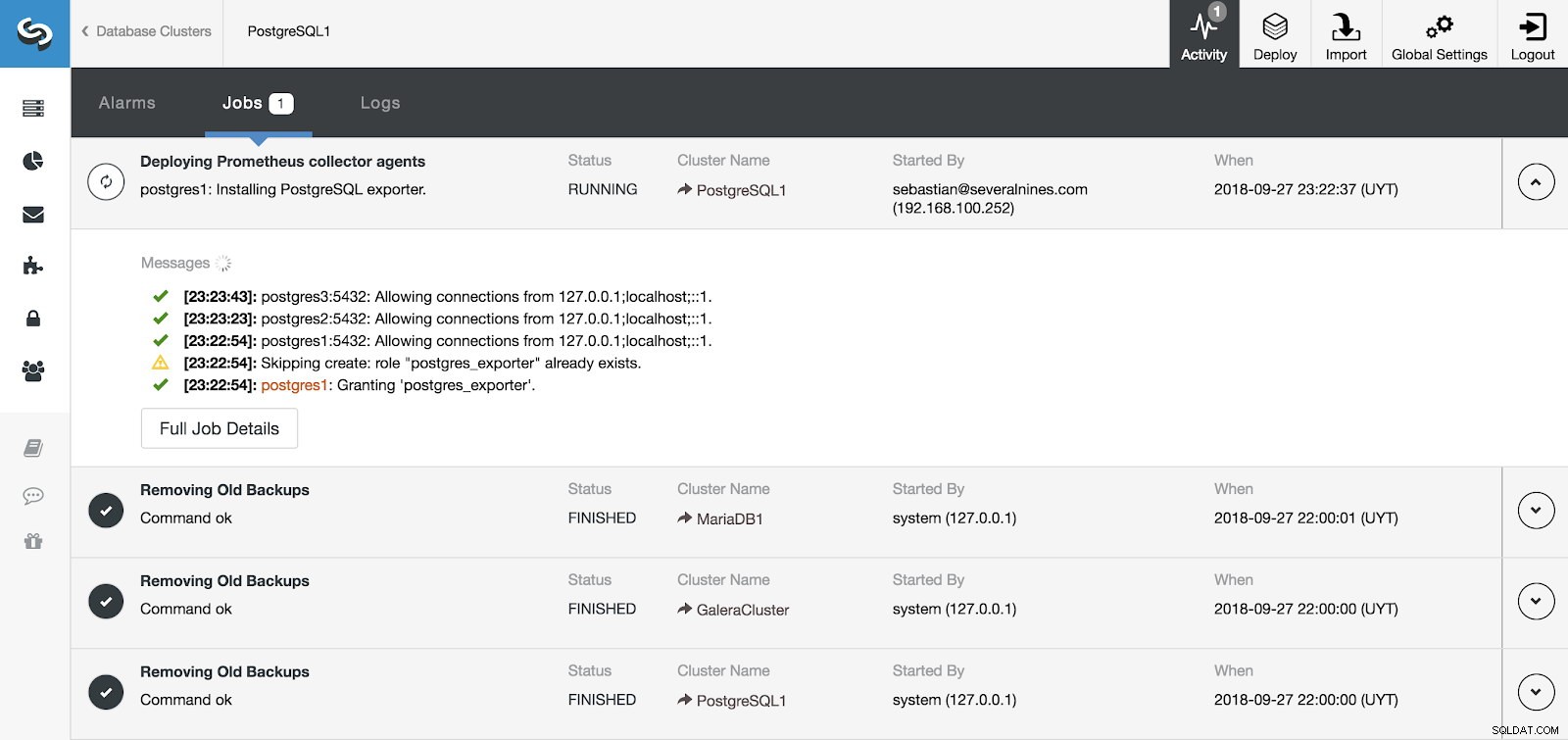 Phần hoạt động ClusterControl
Phần hoạt động ClusterControl Chúng tôi có thể theo dõi quá trình cài đặt máy chủ và tác nhân của mình từ phần Hoạt động trong ClusterControl và sau khi hoàn tất, chúng tôi có thể thấy cụm của mình với các tác nhân được bật từ màn hình ClusterControl chính.
 Đã bật tác nhân ClusterControl
Đã bật tác nhân ClusterControl Trang tổng quan
Khi các tác nhân của chúng tôi được bật, nếu chúng tôi đi đến phần Trang tổng quan, chúng tôi sẽ thấy một cái gì đó như sau:
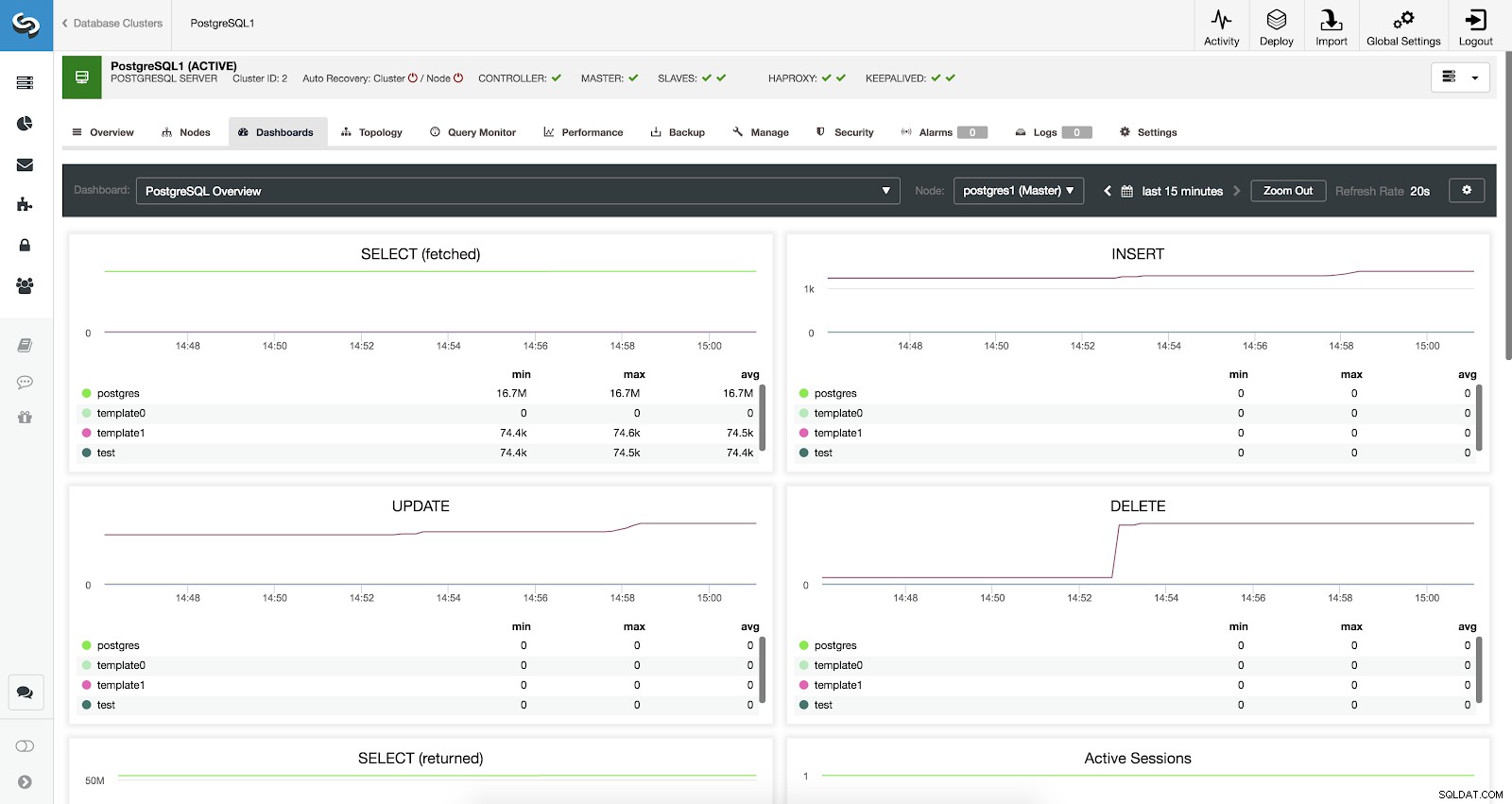 Đã bật Bảng điều khiển ClusterControl
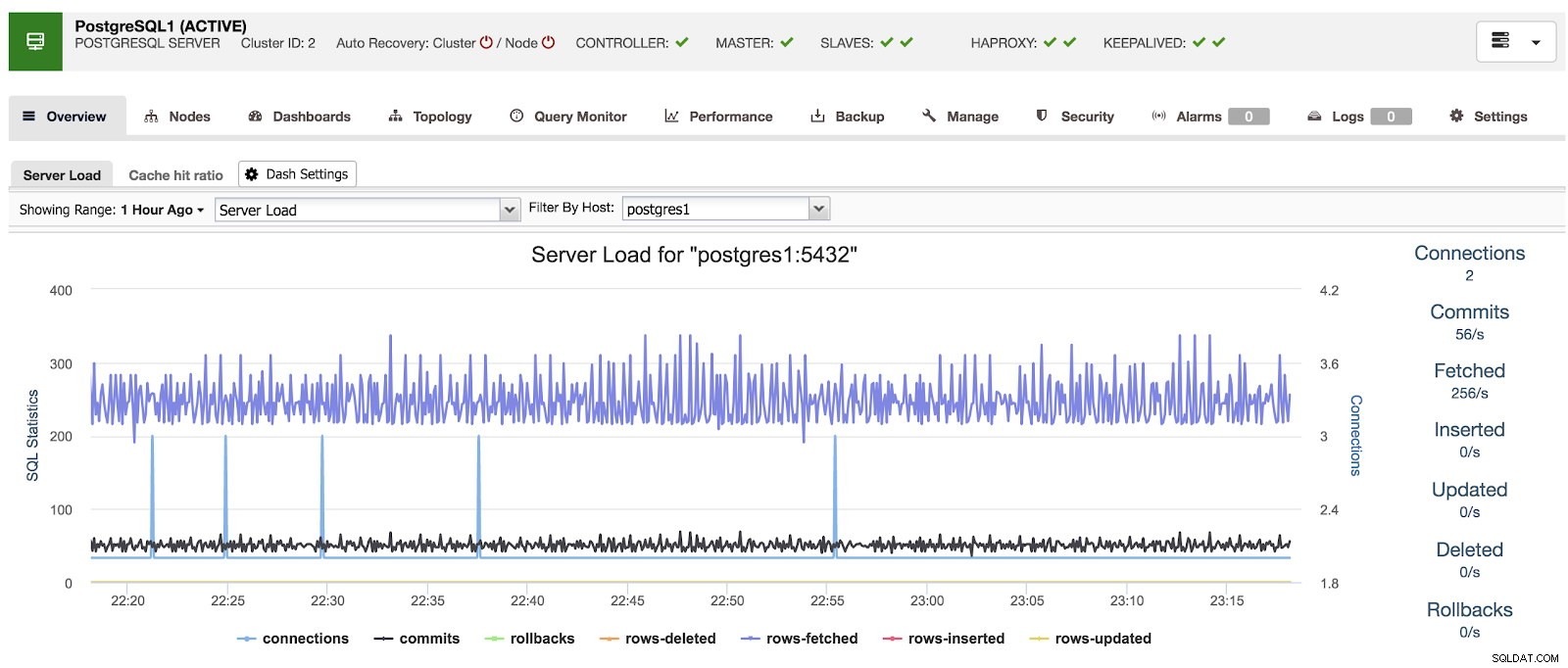
Đã bật Bảng điều khiển ClusterControl Chúng tôi có sẵn ba loại trang tổng quan khác nhau, Tổng quan về hệ thống, Đồ thị máy chủ chéo và Tổng quan về PostgreSQL. Cái cuối cùng là những gì chúng ta thấy theo mặc định khi vào phần này.
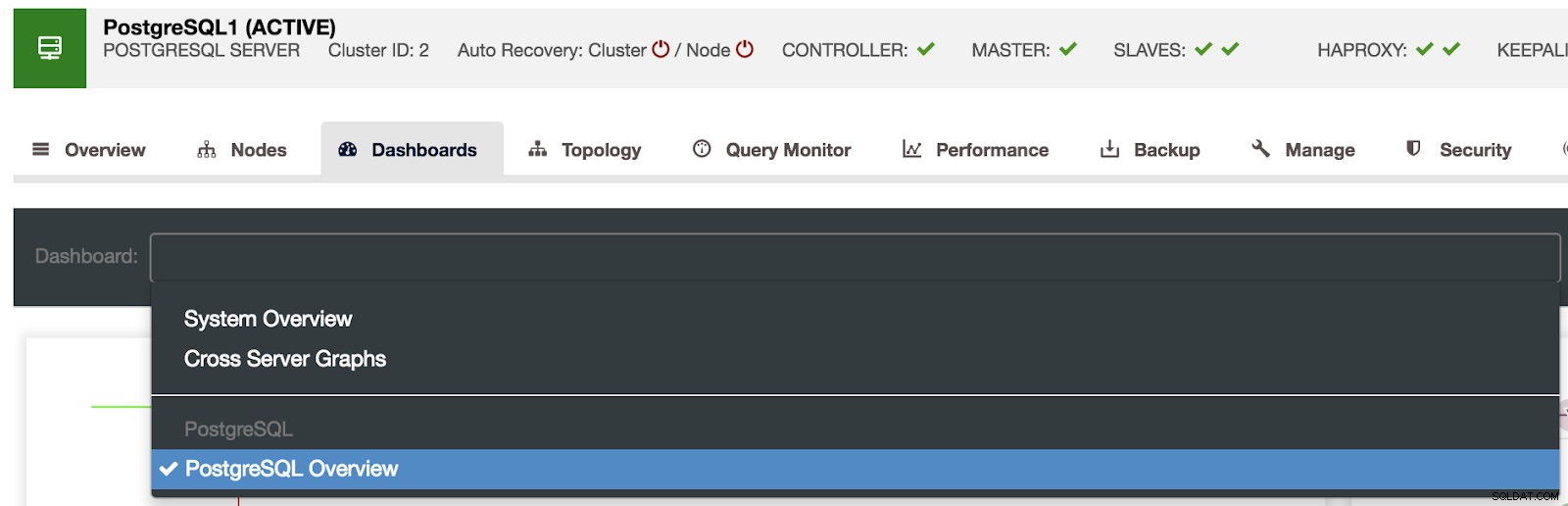 Lựa chọn bảng điều khiển ClusterControl
Lựa chọn bảng điều khiển ClusterControl Tại đây, chúng tôi cũng có thể chỉ định nút nào cần giám sát, phạm vi thời gian và tốc độ làm mới.
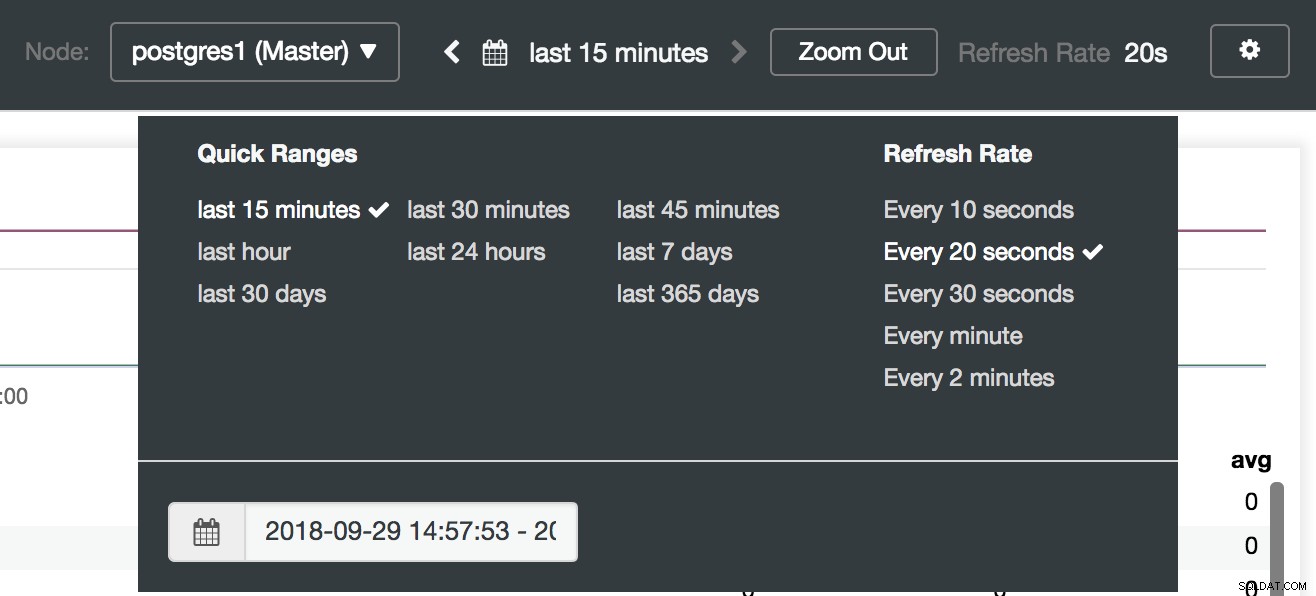 Tùy chọn Bảng điều khiển ClusterControl
Tùy chọn Bảng điều khiển ClusterControl Trong phần cấu hình, chúng tôi có thể bật hoặc tắt tác nhân của mình (Nhà xuất khẩu), kiểm tra trạng thái tác nhân và xác minh phiên bản máy chủ Prometheus của chúng tôi.
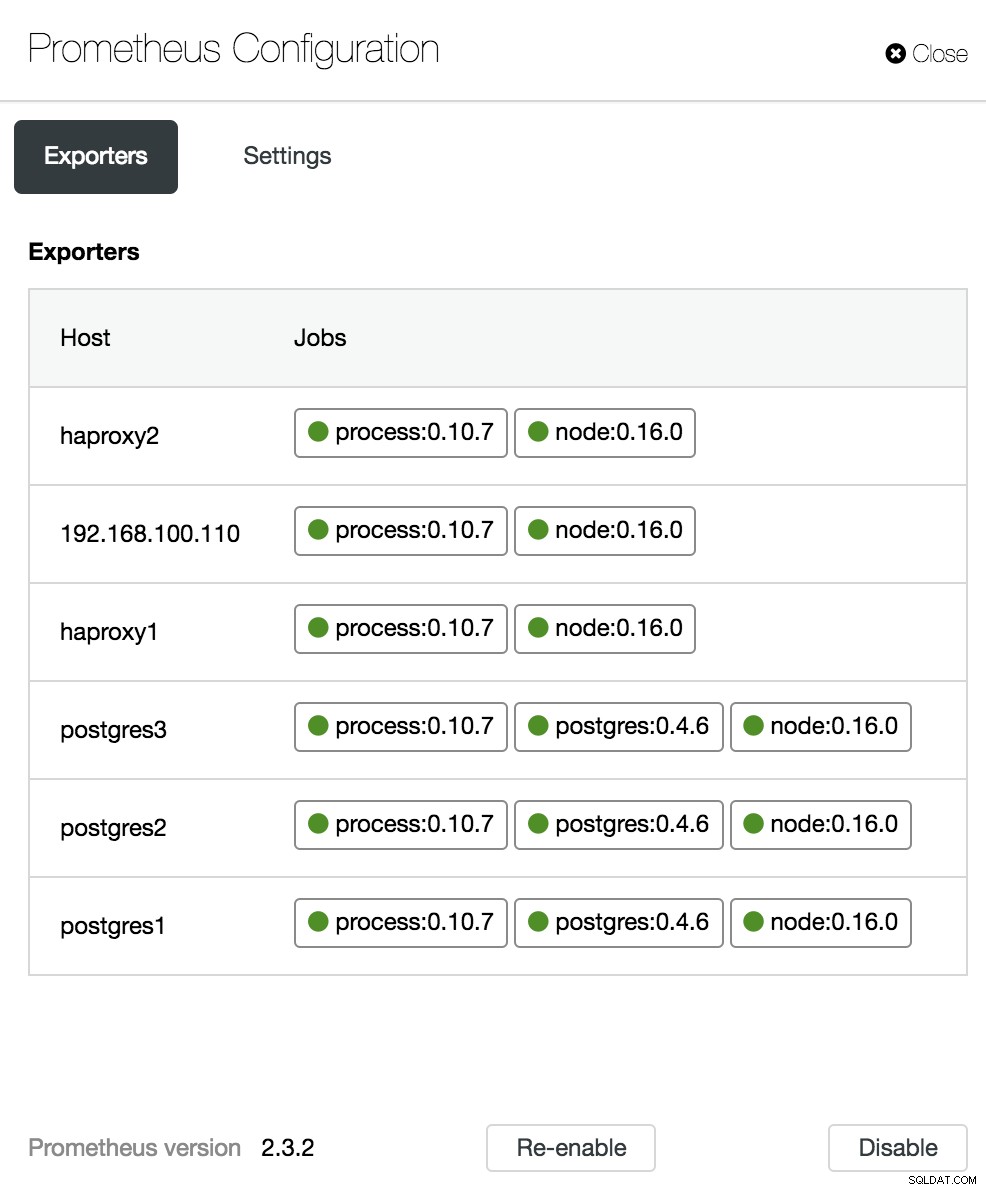 Cấu hình bảng điều khiển ClusterControl
Cấu hình bảng điều khiển ClusterControl Số liệu tổng quan về PostgreSQL
Bây giờ chúng ta hãy xem những chỉ số nào chúng tôi có sẵn cho mỗi cơ sở dữ liệu PostgreSQL của chúng tôi (tất cả chúng cho nút đã chọn).
- CHỌN (tìm nạp):Số lượng hàng được chọn (tìm nạp) cho mỗi cơ sở dữ liệu. Các hàng đã tìm nạp đề cập đến các hàng trực tiếp được tìm nạp từ bảng.
- SELECT (trả về):Số lượng hàng được chọn (trả về) cho mỗi cơ sở dữ liệu. Các hàng được trả về đề cập đến tất cả các hàng được đọc từ bảng, bao gồm các hàng đã chết và các hàng chưa được cam kết (trái ngược với các hàng đã tìm nạp chỉ tính các bộ giá trị đang hoạt động).
- CHÈN:Số lượng hàng được chèn cho mỗi cơ sở dữ liệu.
- CẬP NHẬT:Số lượng hàng được cập nhật cho mỗi cơ sở dữ liệu.
- XÓA:Số lượng hàng đã bị xóa cho mỗi cơ sở dữ liệu.
- Phiên hoạt động:Số lượng phiên hoạt động (tối thiểu, tối đa và trung bình) cho mỗi cơ sở dữ liệu.
- Phiên không hoạt động:Số lượng phiên không hoạt động (tối thiểu, tối đa và trung bình) cho mỗi cơ sở dữ liệu.
- Bảng khóa:Số lượng khóa (tối thiểu, tối đa và trung bình) được phân tách theo loại cho mỗi cơ sở dữ liệu.
- Sử dụng IO trên đĩa:Sử dụng IO trên đĩa máy chủ.
- Sử dụng đĩa:Tỷ lệ sử dụng đĩa của máy chủ (tối thiểu, tối đa và trung bình).
- Độ trễ của đĩa:Độ trễ của đĩa máy chủ.
Số liệu tổng quan về ClusterControl PostgreSQL Số liệu tổng quan về hệ thống
Để giám sát hệ thống của chúng tôi, chúng tôi cung cấp sẵn cho mỗi máy chủ các chỉ số sau (tất cả chúng cho nút đã chọn):
- Thời gian hoạt động của hệ thống:Thời gian kể từ khi máy chủ hoạt động.
- CPU:Số lượng CPU.
- RAM:Dung lượng bộ nhớ RAM.
- Bộ nhớ còn trống:Phần trăm bộ nhớ RAM khả dụng.
- Tải trung bình:Tải máy chủ tối thiểu, tối đa và trung bình.
- Bộ nhớ:Bộ nhớ máy chủ khả dụng, tổng số và bộ nhớ đã sử dụng.
- Sử dụng CPU:Thông tin sử dụng CPU máy chủ tối thiểu, tối đa và trung bình.
- Phân phối bộ nhớ:Phân phối bộ nhớ (bộ đệm, bộ nhớ đệm, trống và đã sử dụng) trên nút đã chọn.
- Chỉ số bão hòa:Tối thiểu, tối đa và trung bình của tải IO và tải CPU trên nút đã chọn.
- Chi tiết Nâng cao về Bộ nhớ:Chi tiết sử dụng bộ nhớ như trang, bộ đệm và hơn thế nữa, trên nút đã chọn.
- Forks:Số lượng quy trình fork. Fork là một hoạt động theo đó một quy trình tạo ra một bản sao của chính nó. Nó thường là một lệnh gọi hệ thống, được triển khai trong hạt nhân.
- Quy trình:Số lượng quy trình đang chạy hoặc chờ trên Hệ điều hành.
- Công tắc ngữ cảnh:Chuyển đổi ngữ cảnh là hành động lưu trữ trạng thái của một quá trình hoặc của một chuỗi.
- Ngắt:Số lượng ngắt. Ngắt là một sự kiện làm thay đổi quy trình thực thi bình thường của một chương trình và có thể được tạo ra bởi các thiết bị phần cứng hoặc thậm chí bởi chính CPU.
- Lưu lượng mạng:Lưu lượng mạng đến và đi tính bằng KByte mỗi giây trên nút đã chọn.
- Sử dụng mạng hàng giờ:Lưu lượng truy cập được gửi và nhận trong ngày qua.
- Hoán đổi:Hoán đổi mức sử dụng (miễn phí và đã sử dụng) trên nút đã chọn.
- Hoạt động Hoán đổi:Đọc và ghi dữ liệu trên Hoán đổi.
- Hoạt động I / O:Trang vào và trang ra trên IO.
- Bộ mô tả tệp:Bộ mô tả tệp được phân bổ và giới hạn.
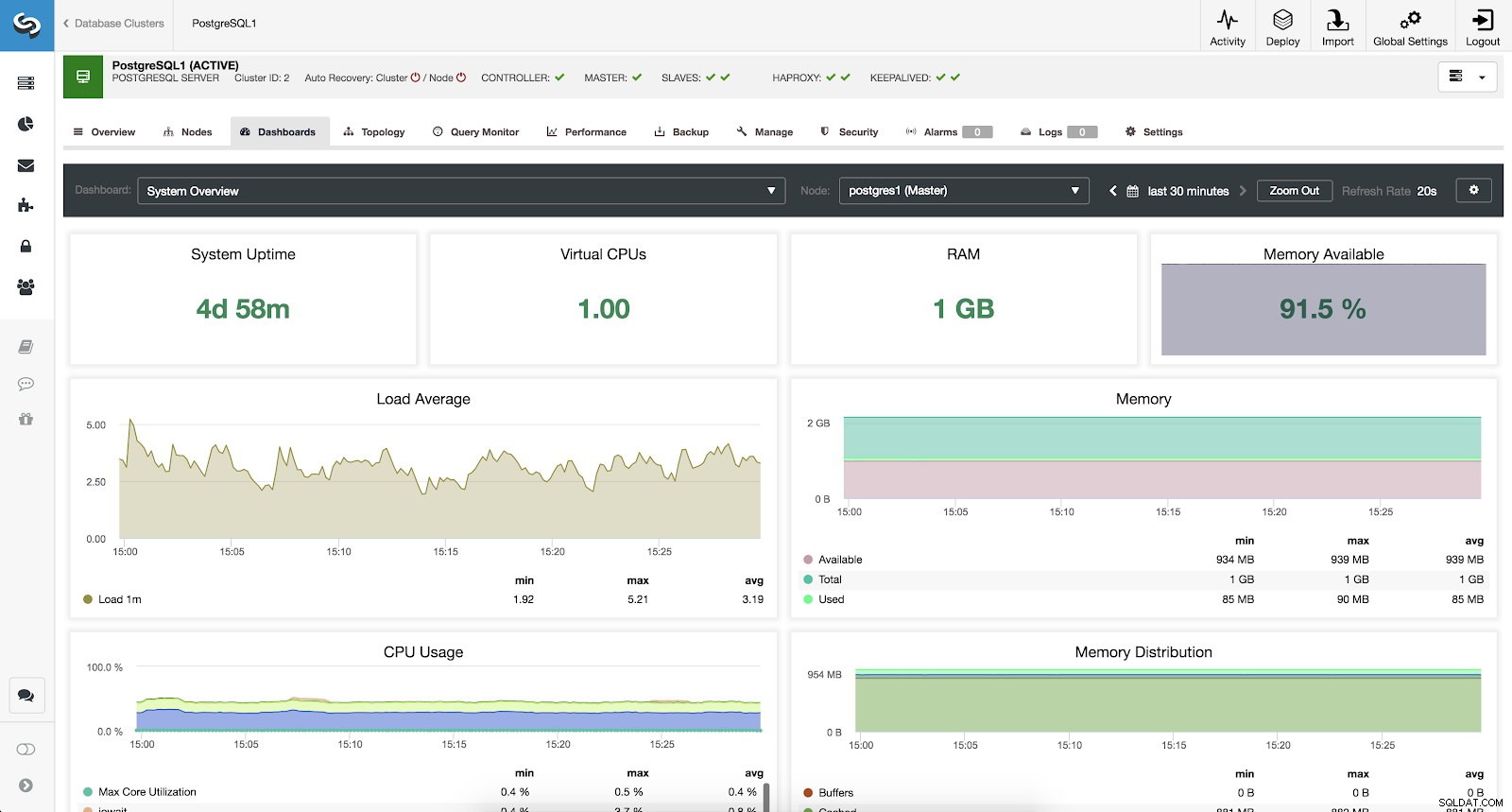 Số liệu tổng quan về hệ thống ClusterControl
Số liệu tổng quan về hệ thống ClusterControl Chỉ số Đồ thị Máy chủ Chéo
Nếu chúng tôi muốn xem trạng thái chung của tất cả các máy chủ của mình, chúng tôi có thể sử dụng trang tổng quan này với các số liệu sau:
- Trung bình tải:Máy chủ tải trung bình cho mỗi máy chủ.
- Sử dụng bộ nhớ:Phần trăm sử dụng bộ nhớ cho mỗi máy chủ.
- Lưu lượng mạng:KByte lưu lượng mạng tối thiểu, tối đa và trung bình mỗi giây.
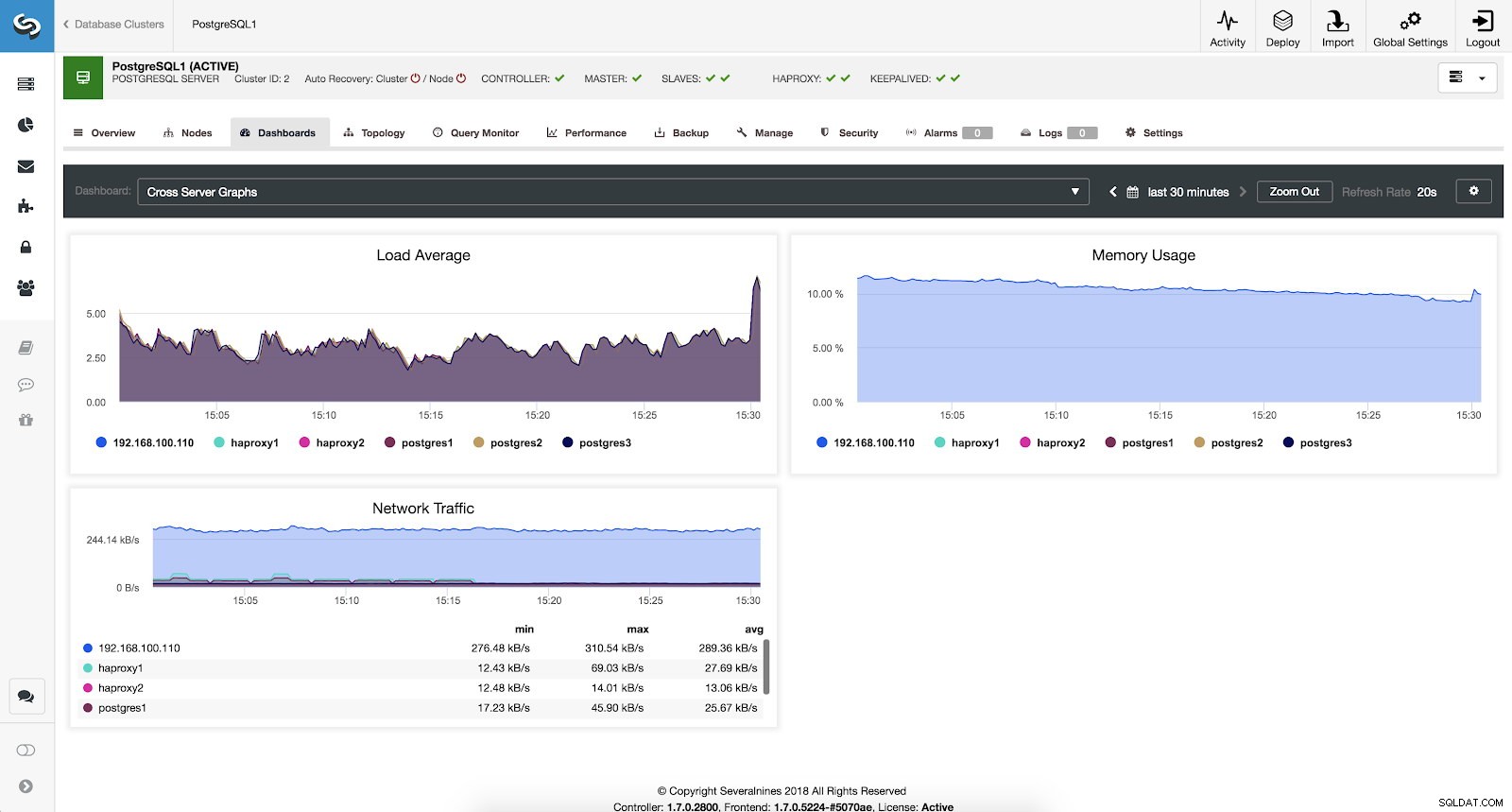 Số liệu đồ thị máy chủ chéo ClusterControl
Số liệu đồ thị máy chủ chéo ClusterControl Kết luận
Có nhiều cách để theo dõi PostgreSQL. ClusterControl cung cấp cả giám sát không tác nhân và hiện dựa trên tác nhân thông qua Prometheus. Nó cung cấp dữ liệu giám sát độ phân giải cao hơn, cũng như các bảng điều khiển khác nhau để hiểu hiệu suất cơ sở dữ liệu. ClusterControl cũng có thể tích hợp với các công cụ bên ngoài như Slack hoặc PagerDuty để cảnh báo.