Tính sẵn sàng cao là điều bắt buộc trong những ngày này vì hầu hết các tổ chức không thể để mất dữ liệu của mình. Tuy nhiên, tính sẵn có cao luôn đi kèm với một thẻ giá (có thể thay đổi rất nhiều). Tuy nhiên, có những lựa chọn khác có thể ít tốn kém hơn. Những điều này có thể không cho phép chuyển ngay lập tức sang một cụm khôi phục sau thảm họa, nhưng chúng sẽ vẫn cho phép hoạt động kinh doanh liên tục (và sẽ không tiêu hao ngân sách.)
Ví dụ về kiểu thiết lập này là môi trường DR "ở chế độ chờ lạnh". Nó cho phép bạn giảm chi phí của mình trong khi vẫn có thể tạo ra một môi trường mới ở một địa điểm bên ngoài nếu thảm họa xảy ra. Trong bài đăng trên blog này, chúng tôi sẽ trình bày cách tạo một thiết lập như vậy.
Thiết lập Ban đầu
Giả sử chúng ta có một thiết lập Bản sao MySQL Master / Slave khá chuẩn trong trung tâm dữ liệu của riêng chúng ta. Nó được thiết lập rất sẵn sàng với ProxySQL và Keepalived để xử lý IP ảo. Rủi ro chính là trung tâm dữ liệu sẽ không khả dụng. Đây là một DC nhỏ, có thể đó là một ISP duy nhất không có BGP tại chỗ. Và trong tình huống này, chúng tôi sẽ giả định rằng nếu mất hàng giờ để khôi phục lại cơ sở dữ liệu thì vẫn được, miễn là có thể đưa nó trở lại.
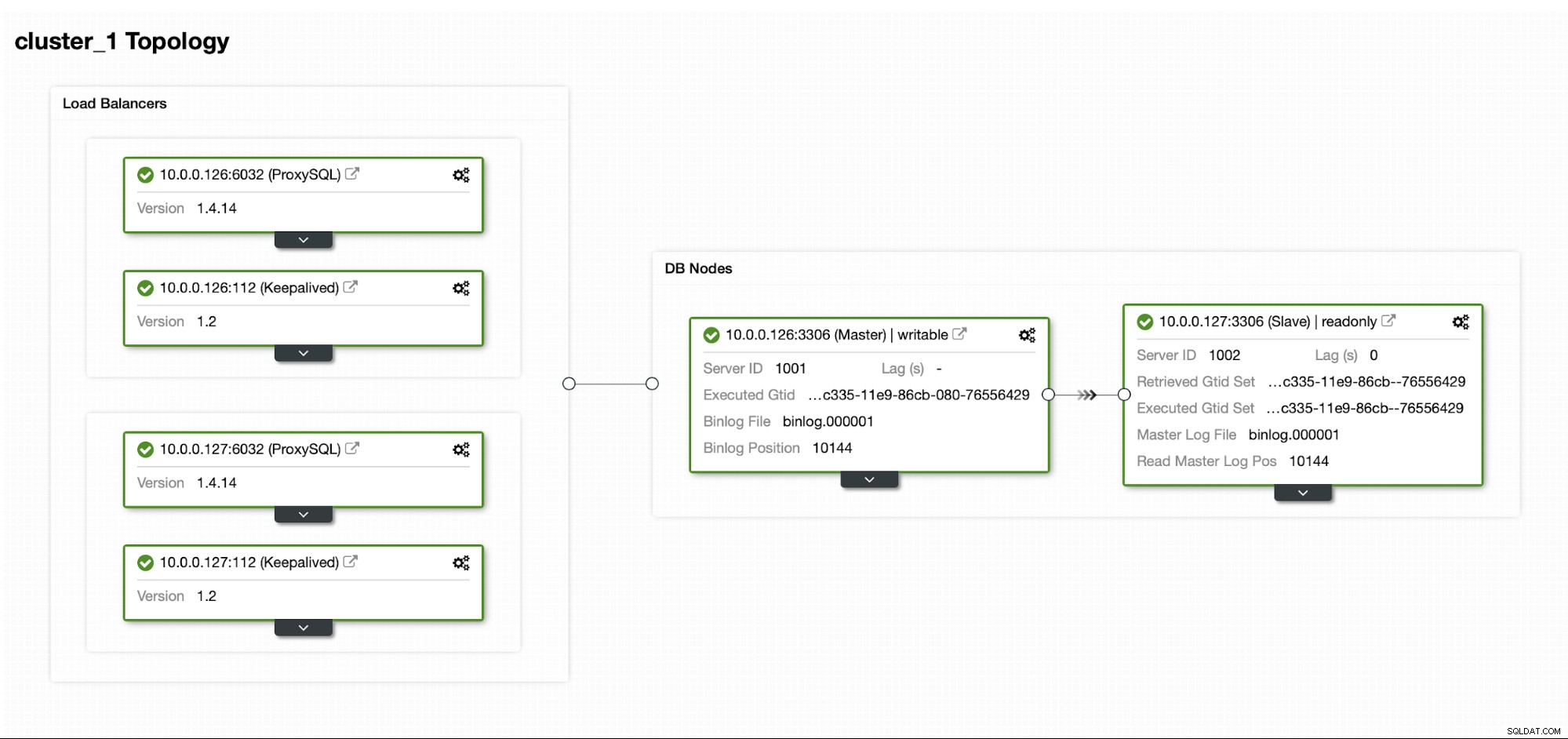
Để triển khai cụm này, chúng tôi đã sử dụng ClusterControl, bạn có thể tải xuống miễn phí. Đối với môi trường DR của chúng tôi, chúng tôi sẽ sử dụng EC2 (nhưng nó cũng có thể là bất kỳ nhà cung cấp đám mây nào khác.)
Thử thách
Vấn đề chính mà chúng ta phải giải quyết là làm cách nào để đảm bảo rằng chúng ta có một dữ liệu mới để khôi phục cơ sở dữ liệu của mình trong môi trường khôi phục sau thảm họa? Tất nhiên, lý tưởng nhất là chúng tôi sẽ có một nô lệ sao chép và chạy trong EC2 ... nhưng sau đó chúng tôi phải trả tiền cho nó. Nếu chúng tôi eo hẹp về ngân sách, chúng tôi có thể cố gắng giải quyết vấn đề đó bằng các bản sao lưu. Đây không phải là giải pháp hoàn hảo vì trong trường hợp xấu nhất, chúng tôi sẽ không bao giờ có thể khôi phục tất cả dữ liệu.
Theo "trường hợp xấu nhất", chúng tôi muốn nói đến tình huống mà chúng tôi sẽ không có quyền truy cập vào các máy chủ cơ sở dữ liệu ban đầu. Nếu chúng tôi có thể tiếp cận họ, dữ liệu sẽ không bị mất.
Giải pháp
Chúng tôi sẽ sử dụng ClusterControl để thiết lập lịch sao lưu nhằm giảm nguy cơ mất dữ liệu. Chúng tôi cũng sẽ sử dụng tính năng ClusterControl để tải các bản sao lưu lên đám mây. Nếu trung tâm dữ liệu không khả dụng, chúng tôi có thể hy vọng rằng nhà cung cấp đám mây mà chúng tôi đã chọn sẽ có thể truy cập được.
Thiết lập Lịch trình Sao lưu trong ClusterControl
Đầu tiên, chúng tôi sẽ phải định cấu hình ClusterControl bằng thông tin đăng nhập đám mây của mình.
Chúng tôi có thể thực hiện việc này bằng cách sử dụng "Tích hợp" từ menu bên trái.
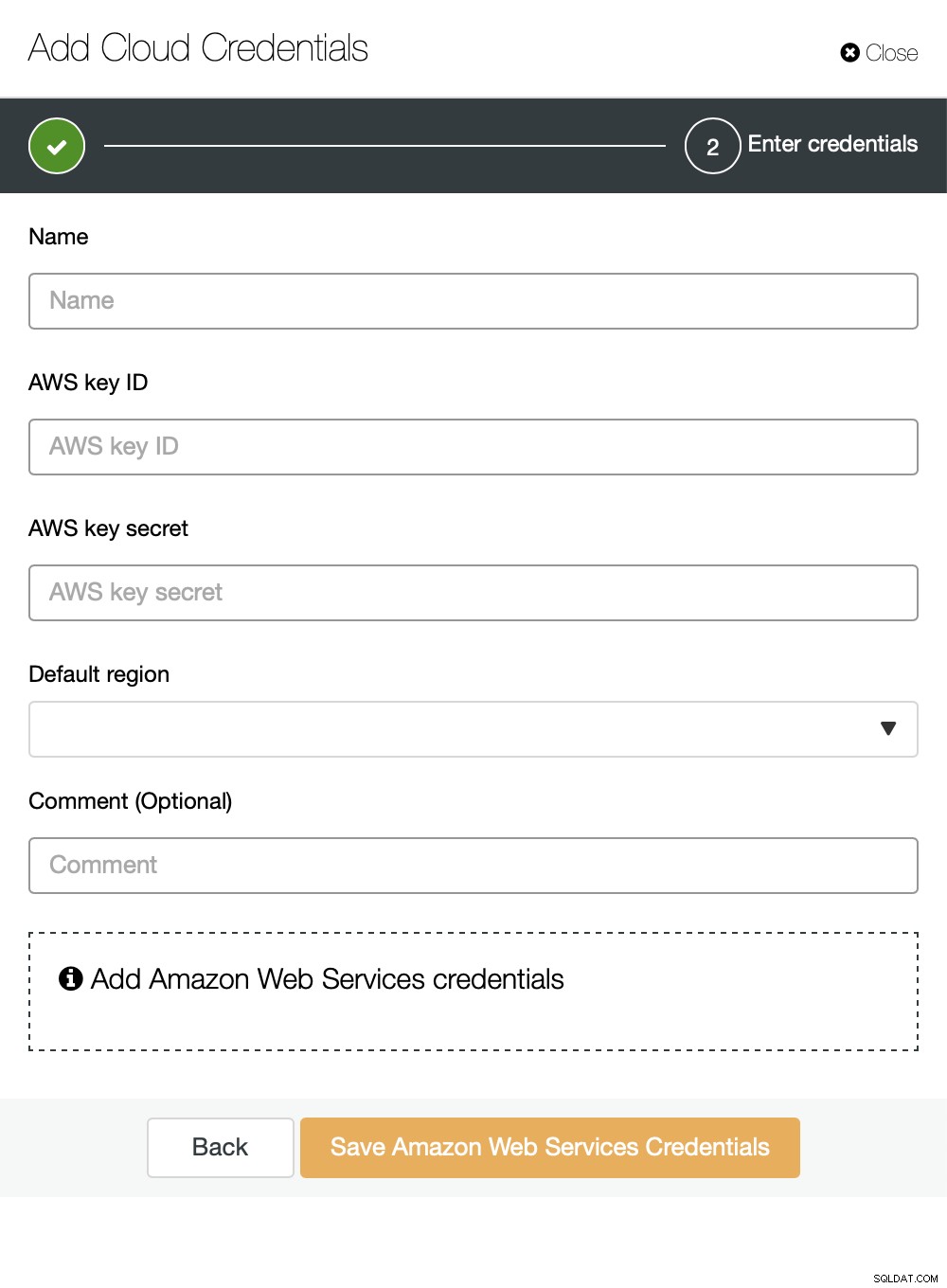
Bạn có thể chọn Amazon Web Services, Google Cloud hoặc Microsoft Azure làm đám mây bạn muốn ClusterControl tải các bản sao lưu lên. Chúng tôi sẽ tiếp tục với AWS trong đó ClusterControl sẽ sử dụng S3 để lưu trữ các bản sao lưu.
Sau đó, chúng ta cần chuyển ID khóa và khóa bí mật, chọn vùng mặc định và chọn tên cho bộ thông tin xác thực này.
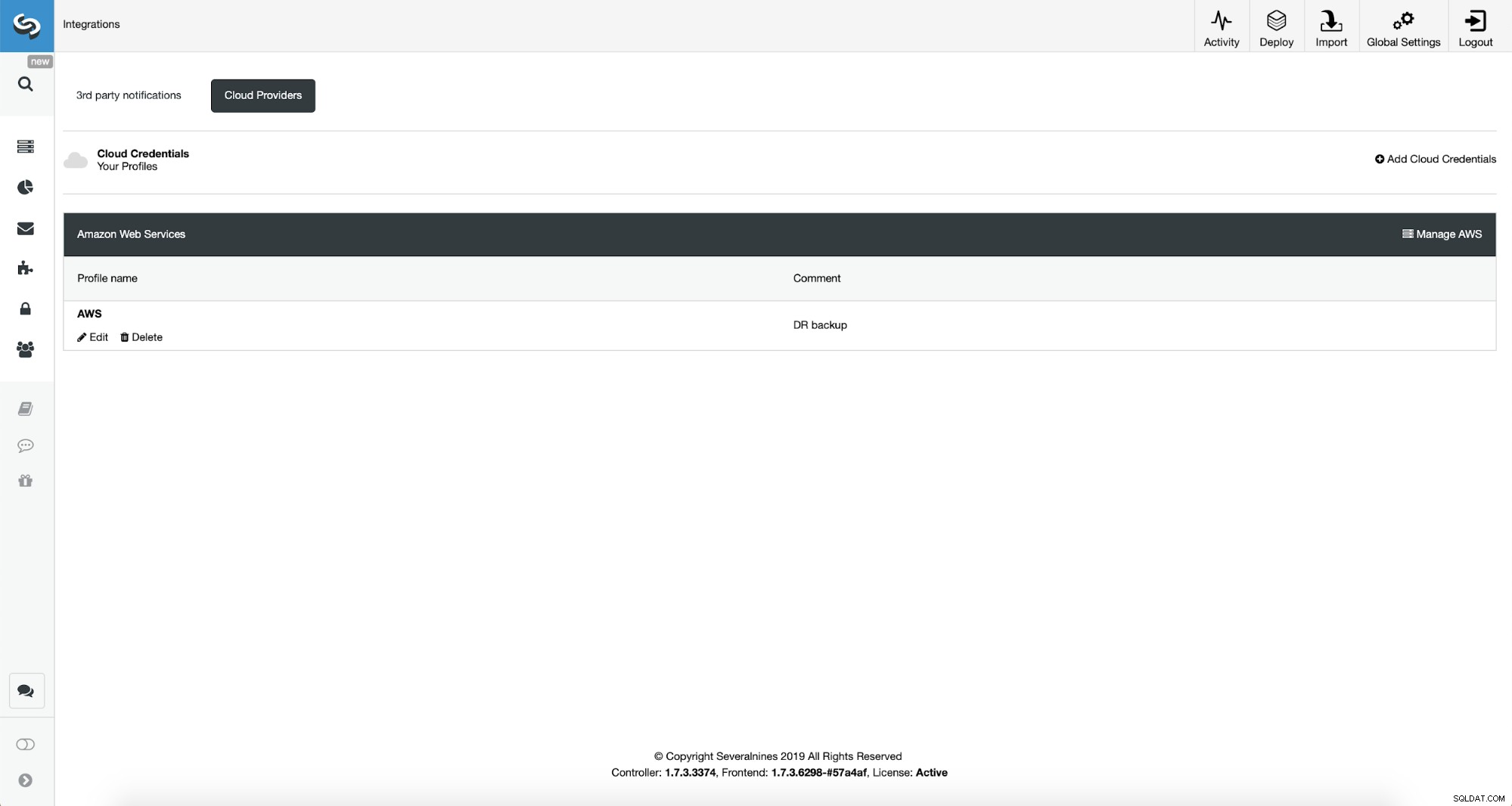
Sau khi hoàn tất, chúng ta có thể thấy thông tin đăng nhập chúng ta vừa thêm được liệt kê trong ClusterControl.
Bây giờ, chúng ta sẽ tiến hành thiết lập lịch sao lưu.
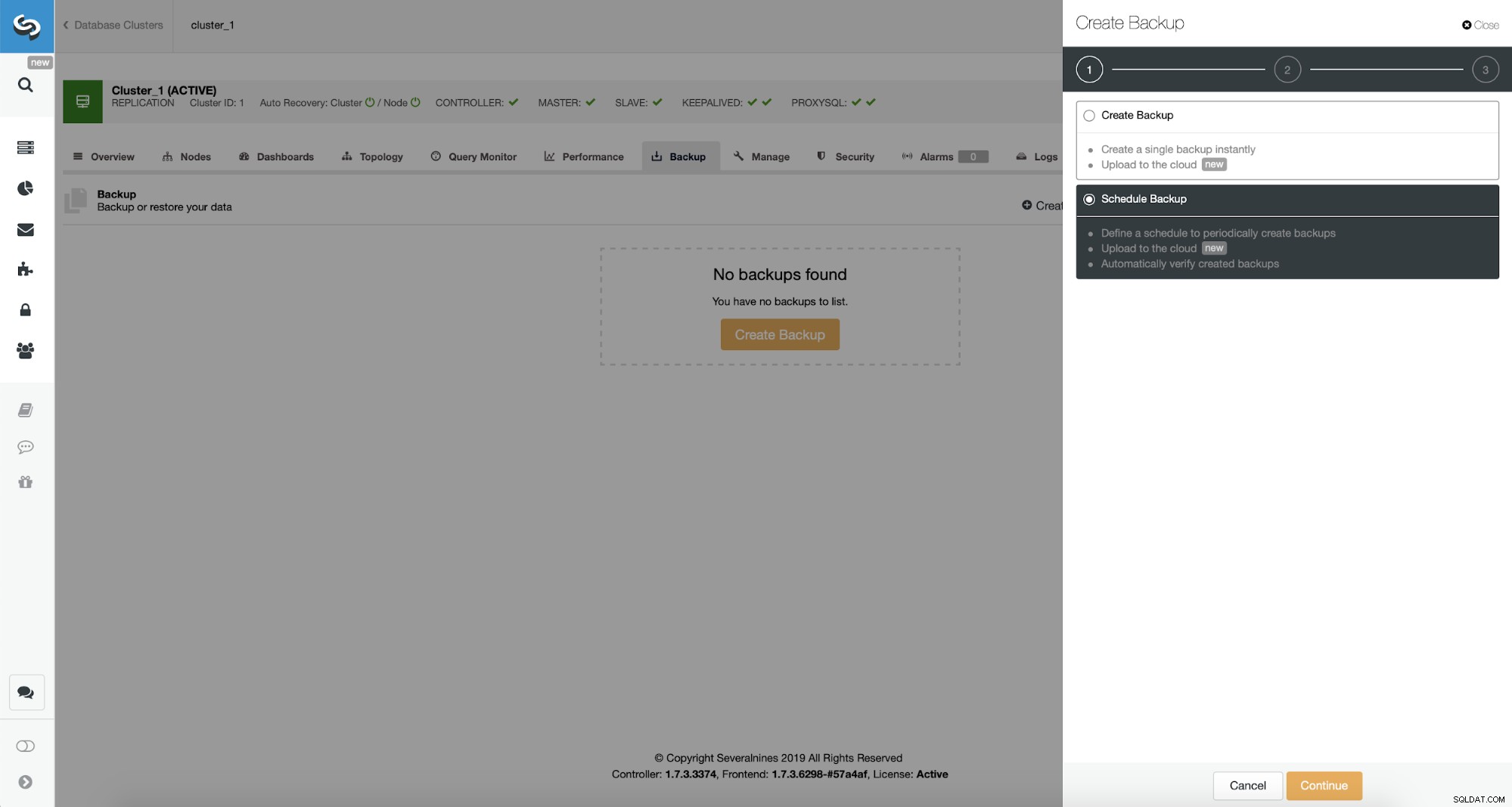
ClusterControl cho phép bạn tạo bản sao lưu ngay lập tức hoặc lên lịch. Chúng tôi sẽ đi với tùy chọn thứ hai. Những gì chúng tôi muốn là tạo một lịch trình sau:
- Bản sao lưu đầy đủ được tạo một lần mỗi ngày
- Các bản sao lưu tăng dần được tạo sau mỗi 10 phút.
Ý tưởng ở đây như sau. Trường hợp xấu nhất chúng tôi sẽ chỉ mất 10 phút lưu lượng truy cập. Nếu trung tâm dữ liệu không khả dụng từ bên ngoài nhưng nó sẽ hoạt động bên trong, chúng tôi có thể cố gắng tránh mọi mất mát dữ liệu bằng cách đợi 10 phút, sao chép bản sao lưu gia tăng mới nhất trên một số máy tính xách tay và sau đó chúng tôi có thể gửi thủ công đến cơ sở dữ liệu DR của mình bằng cách sử dụng ngay cả chia sẻ kết nối qua điện thoại và kết nối di động để tránh ISP bị lỗi. Nếu chúng tôi không thể lấy dữ liệu ra khỏi trung tâm dữ liệu cũ trong một thời gian, điều này nhằm mục đích giảm thiểu số lượng giao dịch mà chúng tôi sẽ phải hợp nhất theo cách thủ công vào cơ sở dữ liệu DR.
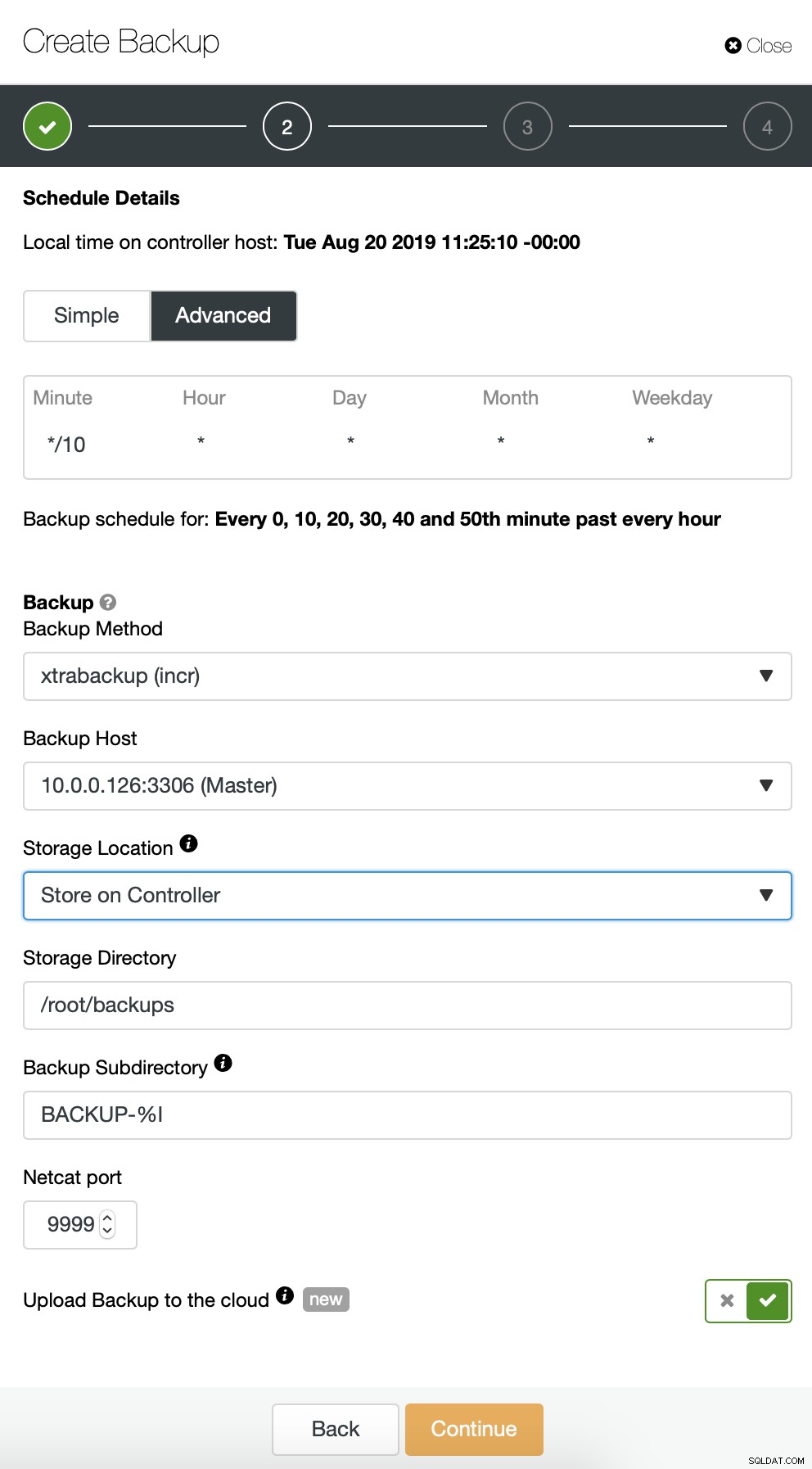
Chúng tôi bắt đầu sao lưu đầy đủ sẽ diễn ra hàng ngày lúc 2:00 sáng. Chúng tôi sẽ sử dụng cái chính để lấy bản sao lưu từ đó, chúng tôi sẽ lưu trữ nó trên bộ điều khiển trong thư mục / root / backups /. Chúng tôi cũng sẽ bật tùy chọn “Tải bản sao lưu lên đám mây”.
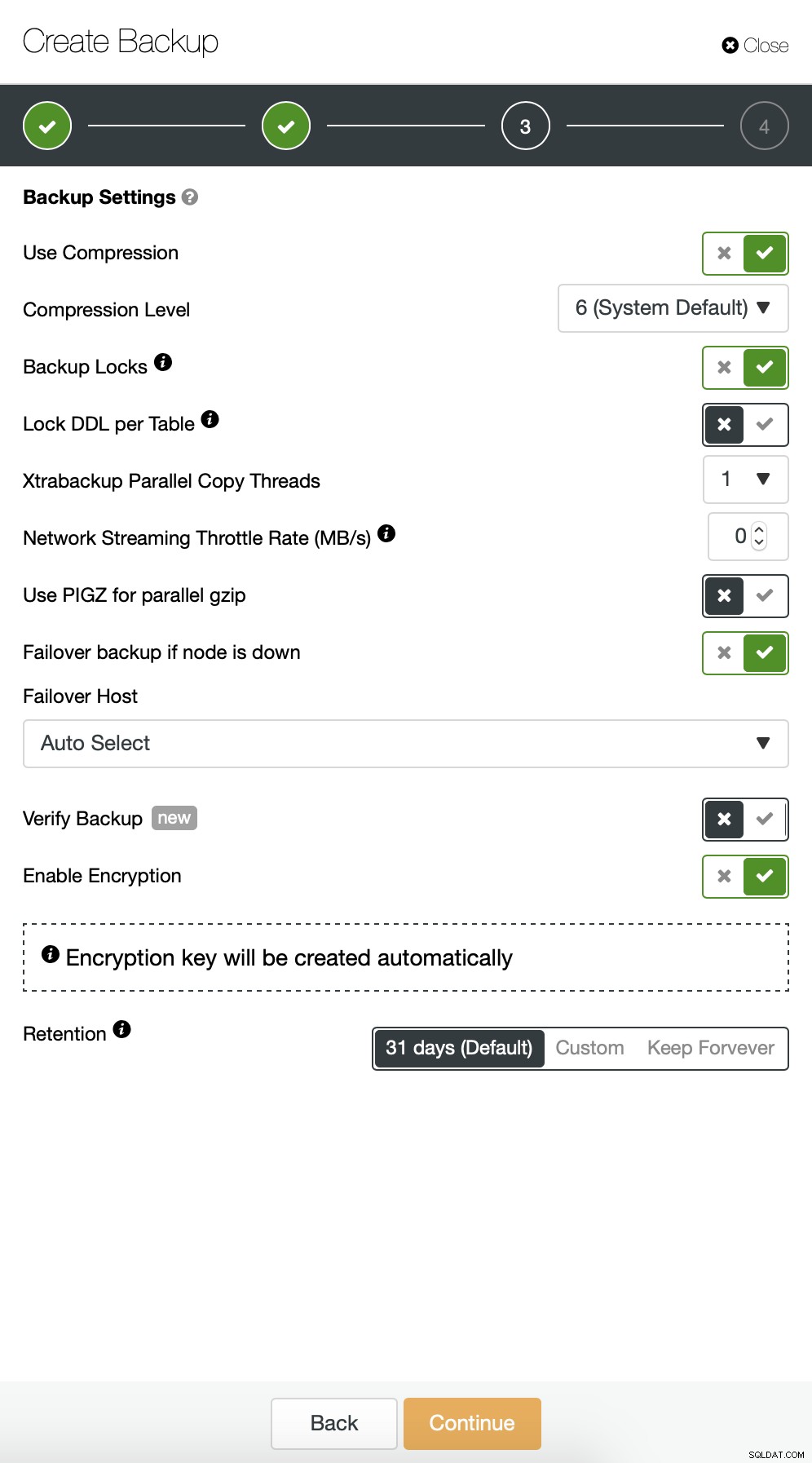
Tiếp theo, chúng tôi muốn thực hiện một số thay đổi trong cấu hình mặc định. Chúng tôi quyết định sử dụng máy chủ chuyển đổi dự phòng được chọn tự động (trong trường hợp máy chủ của chúng tôi không khả dụng, ClusterControl sẽ sử dụng bất kỳ nút nào khác có sẵn). Chúng tôi cũng muốn bật mã hóa vì chúng tôi sẽ gửi các bản sao lưu của mình qua mạng.
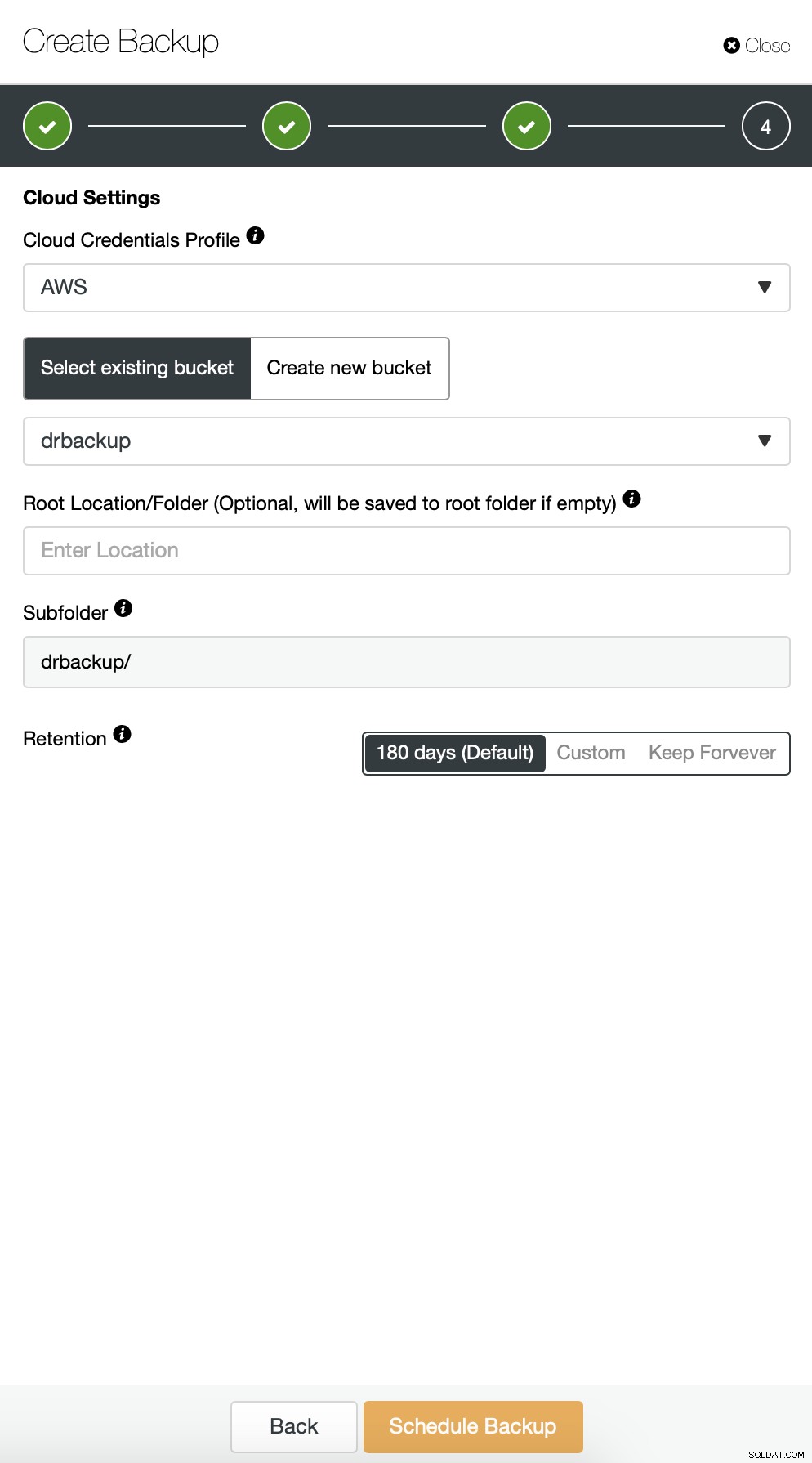
Sau đó, chúng tôi phải chọn thông tin đăng nhập, chọn nhóm S3 hiện có hoặc tạo cái mới nếu cần.
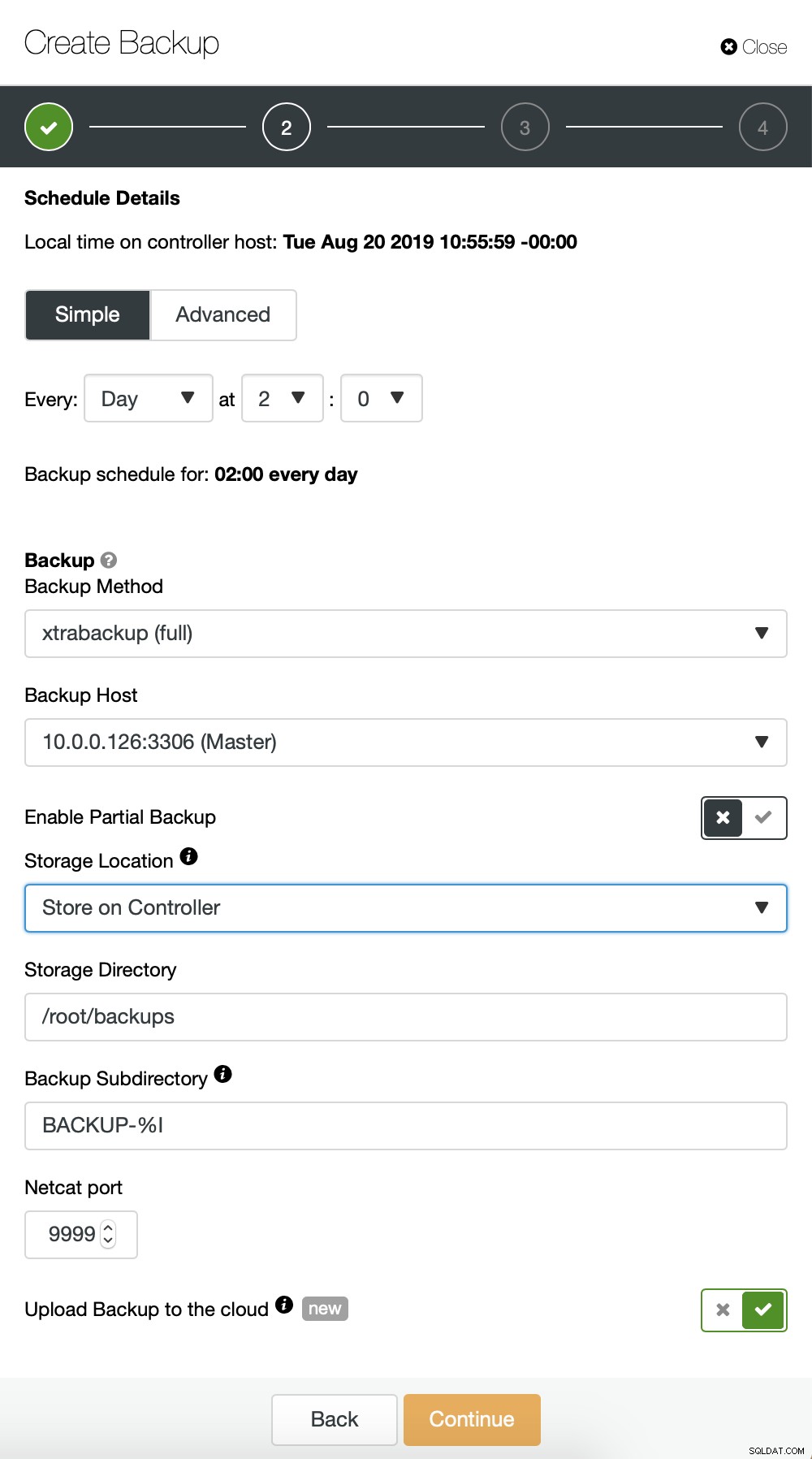
Về cơ bản, chúng tôi đang lặp lại quá trình sao lưu gia tăng, lần này chúng tôi đã sử dụng hộp thoại “Nâng cao” để chạy các bản sao lưu cứ 10 phút một lần.
Phần còn lại của các cài đặt tương tự, chúng tôi cũng có thể sử dụng lại nhóm S3.
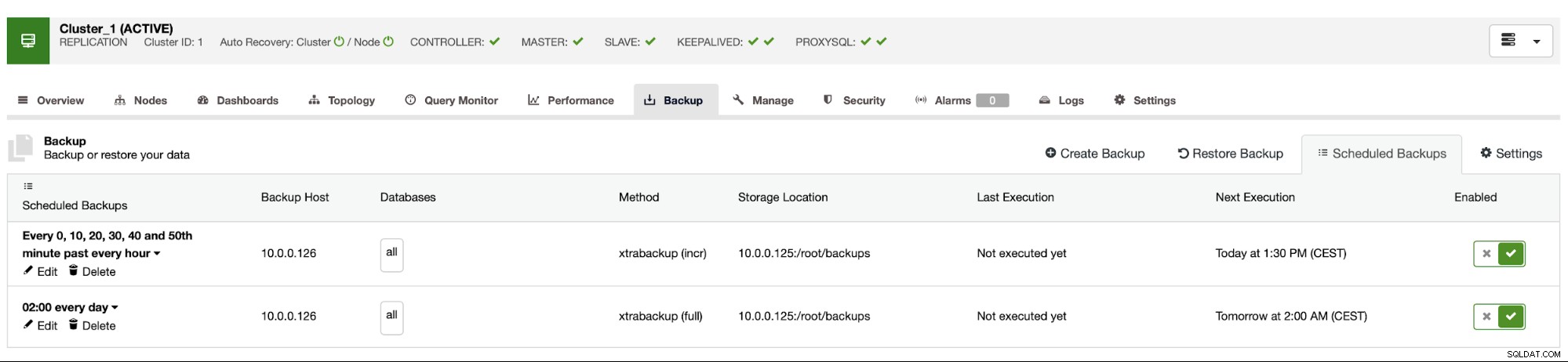
Lịch trình sao lưu trông như trên. Chúng tôi không phải bắt đầu sao lưu đầy đủ theo cách thủ công, ClusterControl sẽ chạy sao lưu gia tăng như đã lên lịch và nếu phát hiện không có sẵn bản sao lưu đầy đủ, nó sẽ chạy một bản sao lưu đầy đủ thay vì tăng dần.
Với thiết lập như vậy, chúng tôi có thể an tâm khi nói rằng chúng tôi có thể khôi phục dữ liệu trên bất kỳ hệ thống bên ngoài nào với mức độ chi tiết trong 10 phút.
Khôi phục Sao lưu Thủ công
Nếu xảy ra trường hợp bạn cần khôi phục bản sao lưu trên phiên bản khôi phục sau thảm họa, bạn phải thực hiện một số bước. Chúng tôi đặc biệt khuyên bạn nên kiểm tra quy trình này theo thời gian, đảm bảo quy trình hoạt động chính xác và bạn thực hiện thành thạo.
Trước tiên, chúng tôi phải cài đặt công cụ dòng lệnh AWS trên máy chủ mục tiêu của chúng tôi:
example@sqldat.com:~# apt install python3-pip
example@sqldat.com:~# pip3 install awscli --upgrade --userSau đó, chúng ta phải định cấu hình nó bằng thông tin đăng nhập thích hợp:
example@sqldat.com:~# ~/.local/bin/aws configure
AWS Access Key ID [None]: yourkeyID
AWS Secret Access Key [None]: yourkeySecret
Default region name [None]: us-west-1
Default output format [None]: jsonBây giờ chúng tôi có thể kiểm tra xem chúng tôi có quyền truy cập vào dữ liệu trong nhóm S3 của mình hay không:
example@sqldat.com:~# ~/.local/bin/aws s3 ls s3://drbackup/
PRE BACKUP-1/
PRE BACKUP-2/
PRE BACKUP-3/
PRE BACKUP-4/
PRE BACKUP-5/
PRE BACKUP-6/
PRE BACKUP-7/Bây giờ, chúng ta phải tải xuống dữ liệu. Chúng tôi sẽ tạo thư mục cho các bản sao lưu - hãy nhớ rằng, chúng tôi phải tải xuống toàn bộ tập hợp sao lưu - bắt đầu từ bản sao lưu đầy đủ đến phần tăng dần cuối cùng mà chúng tôi muốn áp dụng.
example@sqldat.com:~# mkdir backups
example@sqldat.com:~# cd backups/Bây giờ có hai tùy chọn. Chúng tôi có thể tải xuống từng bản sao lưu:
example@sqldat.com:~# ~/.local/bin/aws s3 cp s3://drbackup/BACKUP-1/ BACKUP-1 --recursive
download: s3://drbackup/BACKUP-1/cmon_backup.metadata to BACKUP-1/cmon_backup.metadata
Completed 30.4 MiB/36.2 MiB (4.9 MiB/s) with 1 file(s) remaining
download: s3://drbackup/BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256 to BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256
example@sqldat.com:~# ~/.local/bin/aws s3 cp s3://drbackup/BACKUP-2/ BACKUP-2 --recursive
download: s3://drbackup/BACKUP-2/cmon_backup.metadata to BACKUP-2/cmon_backup.metadata
download: s3://drbackup/BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256 to BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256Chúng tôi cũng có thể, đặc biệt nếu bạn có lịch trình xoay vòng chặt chẽ, đồng bộ hóa tất cả nội dung của nhóm với những gì chúng tôi có cục bộ trên máy chủ:
example@sqldat.com:~/backups# ~/.local/bin/aws s3 sync s3://drbackup/ .
download: s3://drbackup/BACKUP-2/cmon_backup.metadata to BACKUP-2/cmon_backup.metadata
download: s3://drbackup/BACKUP-4/cmon_backup.metadata to BACKUP-4/cmon_backup.metadata
download: s3://drbackup/BACKUP-3/cmon_backup.metadata to BACKUP-3/cmon_backup.metadata
download: s3://drbackup/BACKUP-6/cmon_backup.metadata to BACKUP-6/cmon_backup.metadata
download: s3://drbackup/BACKUP-5/cmon_backup.metadata to BACKUP-5/cmon_backup.metadata
download: s3://drbackup/BACKUP-7/cmon_backup.metadata to BACKUP-7/cmon_backup.metadata
download: s3://drbackup/BACKUP-3/backup-incr-2019-08-20_115005.xbstream.gz.aes256 to BACKUP-3/backup-incr-2019-08-20_115005.xbstream.gz.aes256
download: s3://drbackup/BACKUP-1/cmon_backup.metadata to BACKUP-1/cmon_backup.metadata
download: s3://drbackup/BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256 to BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256
download: s3://drbackup/BACKUP-7/backup-incr-2019-08-20_123008.xbstream.gz.aes256 to BACKUP-7/backup-incr-2019-08-20_123008.xbstream.gz.aes256
download: s3://drbackup/BACKUP-6/backup-incr-2019-08-20_122008.xbstream.gz.aes256 to BACKUP-6/backup-incr-2019-08-20_122008.xbstream.gz.aes256
download: s3://drbackup/BACKUP-5/backup-incr-2019-08-20_121007.xbstream.gz.aes256 to BACKUP-5/backup-incr-2019-08-20_121007.xbstream.gz.aes256
download: s3://drbackup/BACKUP-4/backup-incr-2019-08-20_120007.xbstream.gz.aes256 to BACKUP-4/backup-incr-2019-08-20_120007.xbstream.gz.aes256
download: s3://drbackup/BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256 to BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256Như bạn nhớ, các bản sao lưu được mã hóa. Chúng ta phải có khóa mã hóa được lưu trữ trong ClusterControl. Đảm bảo rằng bạn đã lưu trữ bản sao của nó ở một nơi an toàn, bên ngoài trung tâm dữ liệu chính. Nếu bạn không thể tiếp cận nó, bạn sẽ không thể giải mã các bản sao lưu. Bạn có thể tìm thấy khóa trong cấu hình ClusterControl:
example@sqldat.com:~# grep backup_encryption_key /etc/cmon.d/cmon_1.cnf
backup_encryption_key='aoxhIelVZr1dKv5zMbVPLxlLucuYpcVmSynaeIEeBnM='Nó được mã hóa bằng base64, do đó chúng tôi phải giải mã nó trước và lưu trữ nó trong tệp trước khi chúng tôi có thể bắt đầu giải mã bản sao lưu:
echo "aoxhIelVZr1dKv5zMbVPLxlLucuYpcVmSynaeIEeBnM =" | openssl enc -base64 -d> pass
Bây giờ chúng ta có thể sử dụng lại tệp này để giải mã các bản sao lưu. Hiện tại, giả sử chúng tôi sẽ thực hiện một bản sao lưu đầy đủ và hai bản sao lưu tăng dần.
mkdir 1
mkdir 2
mkdir 3
cat BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256 | openssl enc -d -aes-256-cbc -pass file:/root/backups/pass | zcat | xbstream -x -C /root/backups/1/
cat BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256 | openssl enc -d -aes-256-cbc -pass file:/root/backups/pass | zcat | xbstream -x -C /root/backups/2/
cat BACKUP-3/backup-incr-2019-08-20_115005.xbstream.gz.aes256 | openssl enc -d -aes-256-cbc -pass file:/root/backups/pass | zcat | xbstream -x -C /root/backups/3/Chúng tôi đã giải mã dữ liệu, bây giờ chúng tôi phải tiến hành thiết lập máy chủ MySQL của mình. Tốt nhất, đây phải là phiên bản chính xác giống như trên hệ thống sản xuất. Chúng tôi sẽ sử dụng Máy chủ Percona cho MySQL:
cd ~
wget https://repo.percona.com/apt/percona-release_latest.generic_all.deb
sudo dpkg -i percona-release_latest.generic_all.deb
apt-get update
apt-get install percona-server-5.7Không có gì phức tạp, chỉ cần cài đặt thông thường. Sau khi nó hoạt động và sẵn sàng, chúng tôi phải dừng nó lại và xóa nội dung trong thư mục dữ liệu của nó.
service mysql stop
rm -rf /var/lib/mysql/*Để khôi phục bản sao lưu, chúng ta sẽ cần Xtrabackup - một công cụ mà CC sử dụng để tạo nó (ít nhất là đối với Perona và Oracle MySQL, MariaDB sử dụng MariaBackup). Điều quan trọng là công cụ này phải được cài đặt cùng một phiên bản như trên máy chủ sản xuất:
apt install percona-xtrabackup-24Đó là tất cả những gì chúng tôi phải chuẩn bị. Bây giờ chúng ta có thể bắt đầu khôi phục bản sao lưu. Với các bản sao lưu gia tăng, điều quan trọng cần ghi nhớ là bạn phải chuẩn bị và áp dụng chúng trên bản sao lưu cơ sở. Dự phòng cơ sở cũng phải được chuẩn bị. Điều quan trọng là chạy chuẩn bị với tùy chọn ‘--apply-log-only’ để ngăn xtrabackup chạy giai đoạn khôi phục. Nếu không, bạn sẽ không thể áp dụng bản sao lưu gia tăng tiếp theo.
xtrabackup --prepare --apply-log-only --target-dir=/root/backups/1/
xtrabackup --prepare --apply-log-only --target-dir=/root/backups/1/ --incremental-dir=/root/backups/2/
xtrabackup --prepare --target-dir=/root/backups/1/ --incremental-dir=/root/backups/3/Trong lệnh cuối cùng, chúng tôi đã cho phép xtrabackup chạy khôi phục các giao dịch chưa hoàn thành - sau đó chúng tôi sẽ không áp dụng bất kỳ bản sao lưu gia tăng nào nữa. Bây giờ đã đến lúc điền vào thư mục dữ liệu với bản sao lưu, khởi động MySQL và xem mọi thứ có hoạt động như mong đợi hay không:
example@sqldat.com:~/backups# mv /root/backups/1/* /var/lib/mysql/
example@sqldat.com:~/backups# chown -R mysql.mysql /var/lib/mysql
example@sqldat.com:~/backups# service mysql start
example@sqldat.com:~/backups# mysql -ppass
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 6
Server version: 5.7.26-29 Percona Server (GPL), Release '29', Revision '11ad961'
Copyright (c) 2009-2019 Percona LLC and/or its affiliates
Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show schemas;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| proxydemo |
| sbtest |
| sys |
+--------------------+
6 rows in set (0.00 sec)
mysql> select count(*) from sbtest.sbtest1;
+----------+
| count(*) |
+----------+
| 10506 |
+----------+
1 row in set (0.01 sec)Như bạn thấy, tất cả đều tốt. MySQL đã khởi động đúng cách và chúng tôi có thể truy cập vào nó (và dữ liệu ở đó!) Chúng tôi đã quản lý thành công để khôi phục và chạy cơ sở dữ liệu của mình ở một vị trí riêng biệt. Tổng thời gian cần thiết phụ thuộc hoàn toàn vào kích thước của dữ liệu - chúng tôi phải tải dữ liệu xuống từ S3, giải mã và giải nén nó và cuối cùng là chuẩn bị sao lưu. Tuy nhiên, đây là một tùy chọn rất rẻ (bạn chỉ phải trả tiền cho dữ liệu S3), cung cấp cho bạn một tùy chọn để hoạt động kinh doanh liên tục nếu xảy ra thảm họa.