Ai đó đã vô tình xóa một phần của cơ sở dữ liệu. Ai đó quên đưa mệnh đề WHERE vào truy vấn DELETE hoặc họ đã bỏ nhầm bảng. Những sự việc như thế có thể và sẽ xảy ra, đó là điều tất yếu và con người. Nhưng tác động có thể rất tai hại. Bạn có thể làm gì để bảo vệ mình trước những tình huống như vậy và làm thế nào bạn có thể khôi phục dữ liệu của mình? Trong bài đăng blog này, chúng tôi sẽ đề cập đến một số trường hợp mất dữ liệu điển hình nhất và cách bạn có thể chuẩn bị cho mình để có thể khôi phục chúng.
Chuẩn bị
Có những điều bạn nên làm để đảm bảo phục hồi suôn sẻ. Hãy xem qua chúng. Xin lưu ý rằng đó không phải là tình huống "chọn một trong hai" - lý tưởng là bạn sẽ thực hiện tất cả các biện pháp mà chúng ta sẽ thảo luận bên dưới.
Sao lưu
Bạn phải có một bản sao lưu, không có cách nào thoát khỏi nó. Bạn nên kiểm tra các tệp sao lưu của mình - trừ khi bạn kiểm tra các bản sao lưu của mình, bạn không thể chắc chắn liệu chúng có tốt hay không và liệu bạn có thể khôi phục chúng hay không. Để phục hồi sau thảm họa, bạn nên giữ một bản sao lưu của mình ở đâu đó bên ngoài trung tâm dữ liệu - đề phòng trường hợp toàn bộ trung tâm dữ liệu không khả dụng. Để tăng tốc quá trình khôi phục, sẽ rất hữu ích nếu bạn giữ một bản sao lưu trên các nút cơ sở dữ liệu. Nếu tập dữ liệu của bạn lớn, việc sao chép tập dữ liệu qua mạng từ máy chủ sao lưu vào nút cơ sở dữ liệu mà bạn muốn khôi phục có thể mất nhiều thời gian. Giữ cục bộ bản sao lưu mới nhất có thể cải thiện đáng kể thời gian khôi phục.
Sao lưu lôgic
Bản sao lưu đầu tiên của bạn, rất có thể, sẽ là bản sao lưu vật lý. Đối với MySQL hoặc MariaDB, nó sẽ là một thứ gì đó giống như xtrabackup hoặc một số loại ảnh chụp nhanh hệ thống tệp. Các bản sao lưu như vậy là rất tốt để khôi phục toàn bộ tập dữ liệu hoặc để cung cấp các nút mới. Tuy nhiên, trong trường hợp xóa một tập hợp con dữ liệu, chúng phải chịu chi phí đáng kể. Trước hết, bạn không thể khôi phục tất cả dữ liệu, nếu không, bạn sẽ ghi đè lên tất cả các thay đổi đã xảy ra sau khi tạo bản sao lưu. Những gì bạn đang tìm kiếm là khả năng khôi phục chỉ một tập hợp con dữ liệu, chỉ những hàng đã vô tình bị xóa. Để làm điều đó với một bản sao lưu vật lý, bạn sẽ phải khôi phục nó trên một máy chủ riêng biệt, xác định vị trí các hàng đã xóa, kết xuất chúng và sau đó khôi phục chúng trên cụm sản xuất. Sao chép và khôi phục hàng trăm gigabyte dữ liệu chỉ để khôi phục một số ít hàng là điều mà chúng tôi chắc chắn sẽ gọi là chi phí đáng kể. Để tránh nó, bạn có thể sử dụng các bản sao lưu hợp lý - thay vì lưu trữ dữ liệu vật lý, các bản sao lưu đó lưu trữ dữ liệu ở định dạng văn bản. Điều này giúp dễ dàng xác định vị trí dữ liệu chính xác đã bị xóa, dữ liệu này sau đó có thể được khôi phục trực tiếp trên cụm sản xuất. Để dễ dàng hơn, bạn cũng có thể chia bản sao lưu hợp lý như vậy thành các phần và sao lưu từng bảng vào một tệp riêng biệt. Nếu tập dữ liệu của bạn lớn, bạn nên chia nhỏ một tệp văn bản lớn nhất có thể. Điều này sẽ làm cho bản sao lưu không nhất quán nhưng trong phần lớn các trường hợp, điều này không có vấn đề gì - nếu bạn cần khôi phục toàn bộ tập dữ liệu về trạng thái nhất quán, bạn sẽ sử dụng sao lưu vật lý, nhanh hơn nhiều về mặt này. Nếu bạn chỉ cần khôi phục một tập hợp con dữ liệu, các yêu cầu về tính nhất quán sẽ ít nghiêm ngặt hơn.
Khôi phục điểm trong thời gian
Sao lưu chỉ là bước khởi đầu - bạn sẽ có thể khôi phục dữ liệu của mình tại thời điểm sao lưu được thực hiện nhưng rất có thể, dữ liệu đã bị xóa sau thời gian đó. Chỉ bằng cách khôi phục dữ liệu bị thiếu từ bản sao lưu mới nhất, bạn có thể mất bất kỳ dữ liệu nào đã bị thay đổi sau khi sao lưu. Để tránh điều đó, bạn nên thực hiện Khôi phục điểm trong thời gian. Đối với MySQL, về cơ bản có nghĩa là bạn sẽ phải sử dụng nhật ký nhị phân để phát lại tất cả các thay đổi đã xảy ra giữa thời điểm sao lưu và sự kiện mất dữ liệu. Ảnh chụp màn hình dưới đây cho thấy ClusterControl có thể giúp như thế nào.
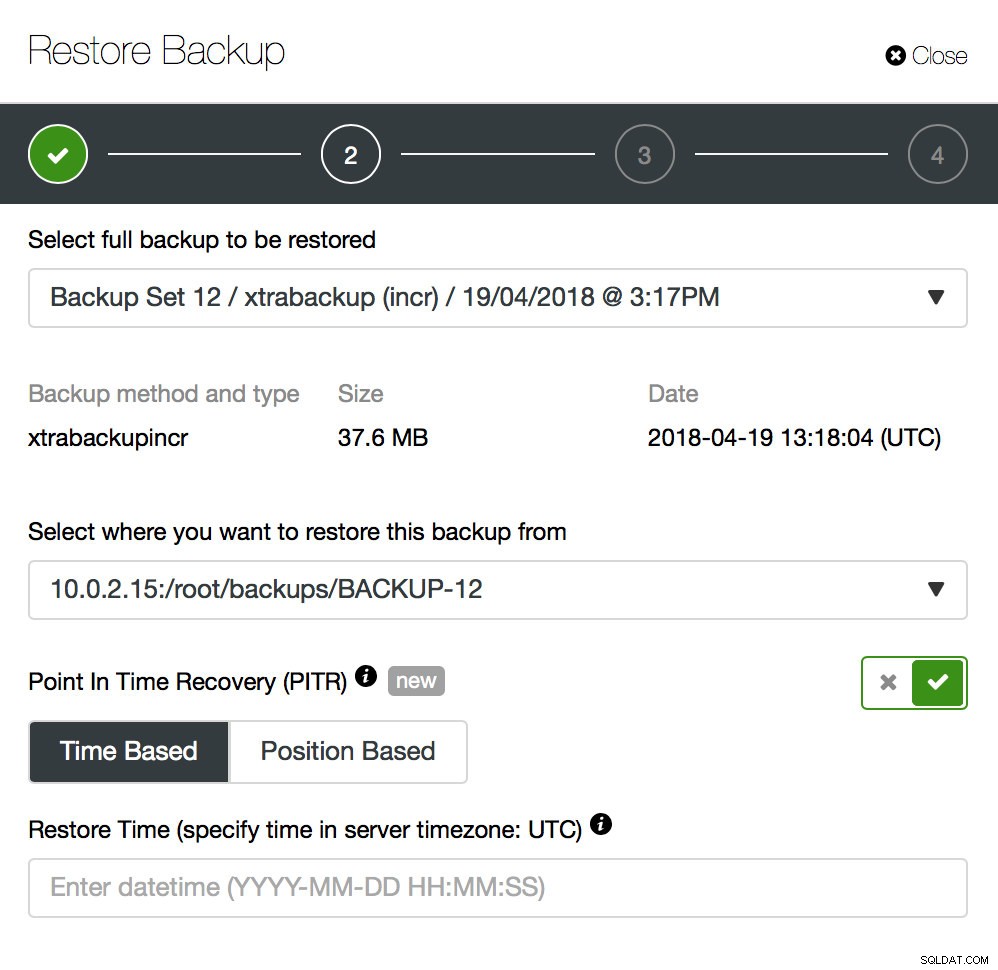
Những gì bạn sẽ phải làm là khôi phục bản sao lưu này đến thời điểm ngay trước khi mất dữ liệu. Bạn sẽ phải khôi phục nó trên một máy chủ riêng biệt để không thực hiện các thay đổi trên cụm sản xuất. Sau khi khôi phục bản sao lưu, bạn có thể đăng nhập vào máy chủ đó, tìm dữ liệu bị thiếu, kết xuất dữ liệu và khôi phục trên cụm sản xuất.
Nô lệ bị trì hoãn
Tất cả các phương pháp chúng ta đã thảo luận ở trên đều có một điểm chung khó khăn - cần có thời gian để khôi phục dữ liệu. Có thể mất nhiều thời gian hơn, khi bạn khôi phục tất cả dữ liệu và sau đó chỉ cố gắng loại bỏ phần thú vị. Có thể mất ít thời gian hơn nếu bạn có bản sao lưu hợp lý và bạn có thể nhanh chóng đi sâu vào dữ liệu bạn muốn khôi phục, nhưng nó không có nghĩa là một nhiệm vụ nhanh chóng. Bạn vẫn phải tìm một vài hàng trong một tệp văn bản lớn. Nó càng lớn, nhiệm vụ càng phức tạp - đôi khi kích thước tuyệt đối của tệp làm chậm tất cả các hành động. Một phương pháp để tránh những vấn đề đó là có một nô lệ bị trì hoãn. Các nô lệ thường cố gắng cập nhật với chủ nhưng cũng có thể cấu hình chúng để chúng giữ khoảng cách với chủ. Trong ảnh chụp màn hình bên dưới, bạn có thể thấy cách sử dụng ClusterControl để triển khai một nô lệ như vậy:
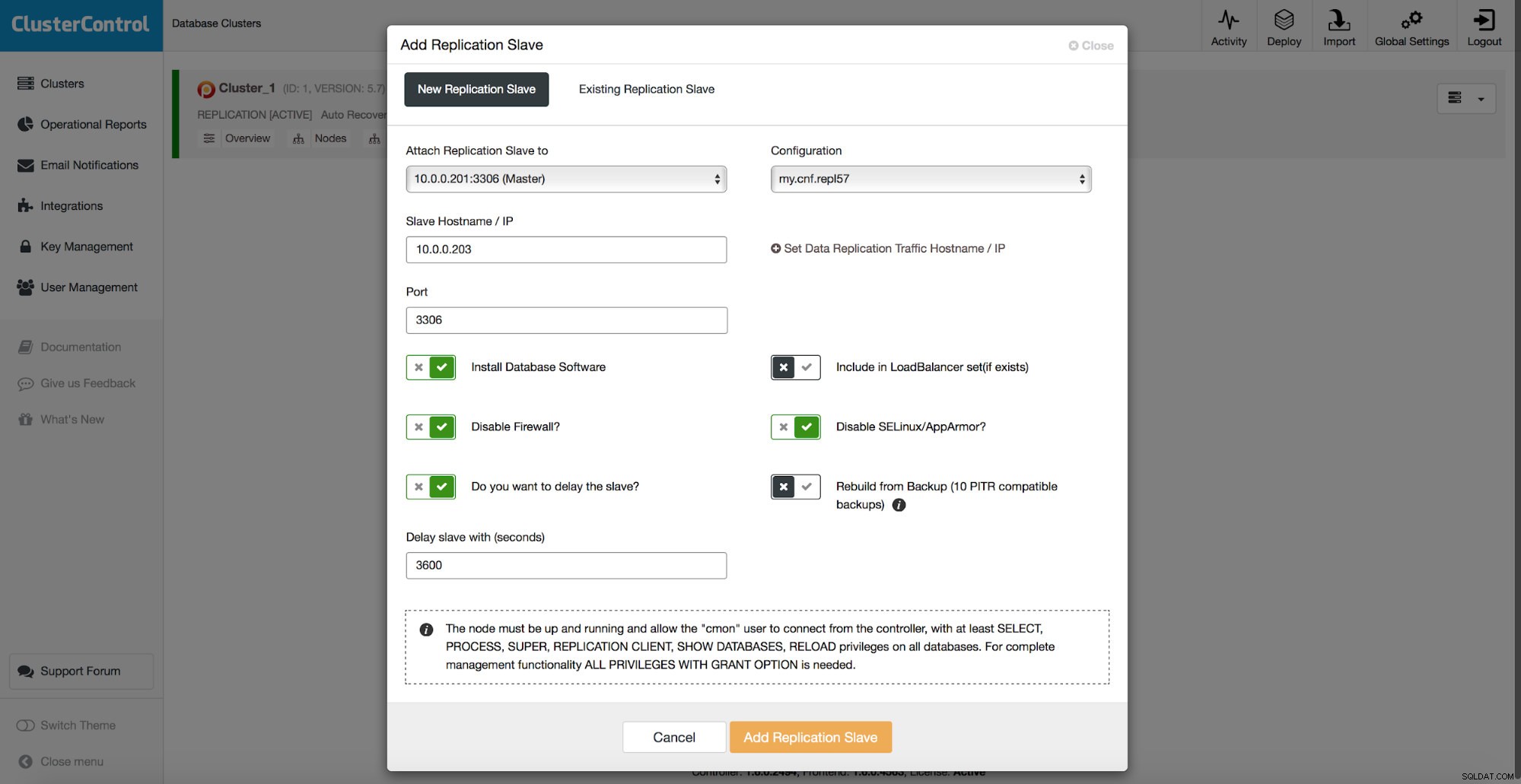
Nói tóm lại, ở đây chúng tôi có một tùy chọn để thêm một nô lệ sao chép vào thiết lập cơ sở dữ liệu và định cấu hình nó bị trì hoãn. Trong ảnh chụp màn hình ở trên, nô lệ sẽ bị trễ 3600 giây, tức là một giờ. Điều này cho phép bạn sử dụng nô lệ đó để khôi phục dữ liệu đã xóa trong tối đa một giờ kể từ khi xóa dữ liệu. Bạn sẽ không phải khôi phục bản sao lưu, nó sẽ đủ để chạy mysqldump hoặc SELECT ... INTO OUTFILE đối với dữ liệu bị thiếu và bạn sẽ nhận được dữ liệu để khôi phục trên cụm sản xuất của mình.
Khôi phục dữ liệu
Trong phần này, chúng ta sẽ xem xét một số ví dụ về việc vô tình xóa dữ liệu và cách bạn có thể khôi phục chúng. Chúng tôi sẽ hướng dẫn cách khôi phục sau khi mất toàn bộ dữ liệu, chúng tôi cũng sẽ hướng dẫn cách khôi phục sau khi mất một phần dữ liệu khi sử dụng các bản sao lưu vật lý và logic. Cuối cùng, chúng tôi sẽ chỉ cho bạn cách khôi phục các hàng vô tình bị xóa nếu bạn có một nô lệ bị trì hoãn trong quá trình thiết lập của mình.
Mất toàn bộ dữ liệu
Tình cờ “rm -rf” hoặc “DROP SCHEMA myonlyschema;” đã được thực thi và bạn không có dữ liệu nào cả. Nếu bạn tình cờ xóa các tệp khác ngoài thư mục dữ liệu MySQL, bạn có thể cần phải kiểm tra lại máy chủ. Để giữ cho mọi thứ đơn giản hơn, chúng tôi sẽ giả định rằng chỉ có MySQL bị ảnh hưởng. Hãy xem xét hai trường hợp, với một nô lệ bị trì hoãn và không có một nô lệ.
Không có nô lệ bị trì hoãn
Trong trường hợp này, điều duy nhất chúng ta có thể làm là khôi phục bản sao lưu vật lý cuối cùng. Vì tất cả dữ liệu của chúng tôi đã bị xóa, chúng tôi không cần phải lo lắng về hoạt động xảy ra sau khi mất dữ liệu vì không có dữ liệu, sẽ không có hoạt động nào. Chúng ta nên lo lắng về hoạt động xảy ra sau khi sao lưu diễn ra. Điều này có nghĩa là chúng tôi phải thực hiện khôi phục Điểm trong Thời gian. Tất nhiên, sẽ mất nhiều thời gian hơn là chỉ khôi phục dữ liệu từ bản sao lưu. Nếu việc đưa cơ sở dữ liệu của bạn lên nhanh chóng là điều quan trọng hơn cả việc khôi phục tất cả dữ liệu, thì bạn cũng có thể khôi phục một bản sao lưu và ổn với nó.
Trước hết, nếu bạn vẫn có quyền truy cập vào nhật ký nhị phân trên máy chủ mà bạn muốn khôi phục, bạn có thể sử dụng chúng cho PITR. Đầu tiên, chúng tôi muốn chuyển đổi phần có liên quan của nhật ký nhị phân thành tệp văn bản để điều tra thêm. Chúng tôi biết rằng việc mất dữ liệu đã xảy ra sau 13:00:00. Trước tiên, hãy kiểm tra tệp binlog nào chúng ta nên điều tra:
example@sqldat.com:~# ls -alh /var/lib/mysql/binlog.*
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:32 /var/lib/mysql/binlog.000001
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:33 /var/lib/mysql/binlog.000002
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:35 /var/lib/mysql/binlog.000003
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:38 /var/lib/mysql/binlog.000004
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:39 /var/lib/mysql/binlog.000005
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:41 /var/lib/mysql/binlog.000006
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:43 /var/lib/mysql/binlog.000007
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:45 /var/lib/mysql/binlog.000008
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:47 /var/lib/mysql/binlog.000009
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:49 /var/lib/mysql/binlog.000010
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:51 /var/lib/mysql/binlog.000011
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:53 /var/lib/mysql/binlog.000012
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:55 /var/lib/mysql/binlog.000013
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:57 /var/lib/mysql/binlog.000014
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:59 /var/lib/mysql/binlog.000015
-rw-r----- 1 mysql mysql 306M Apr 23 13:18 /var/lib/mysql/binlog.000016Có thể thấy, chúng tôi quan tâm đến tệp binlog cuối cùng.
example@sqldat.com:~# mysqlbinlog --start-datetime='2018-04-23 13:00:00' --verbose /var/lib/mysql/binlog.000016 > sql.outSau khi hoàn tất, hãy xem nội dung của tệp này. Chúng tôi sẽ tìm kiếm ‘drop schema’ trong vim. Đây là phần có liên quan của tệp:
# at 320358785
#180423 13:18:58 server id 1 end_log_pos 320358850 CRC32 0x0893ac86 GTID last_committed=307804 sequence_number=307805 rbr_only=no
SET @@SESSION.GTID_NEXT= '52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415'/*!*/;
# at 320358850
#180423 13:18:58 server id 1 end_log_pos 320358946 CRC32 0x487ab38e Query thread_id=55 exec_time=1 error_code=0
SET TIMESTAMP=1524489538/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
drop schema sbtest
/*!*/;Như chúng ta thấy, chúng tôi muốn khôi phục đến vị trí 320358785. Chúng tôi có thể chuyển dữ liệu này đến giao diện người dùng ClusterControl:
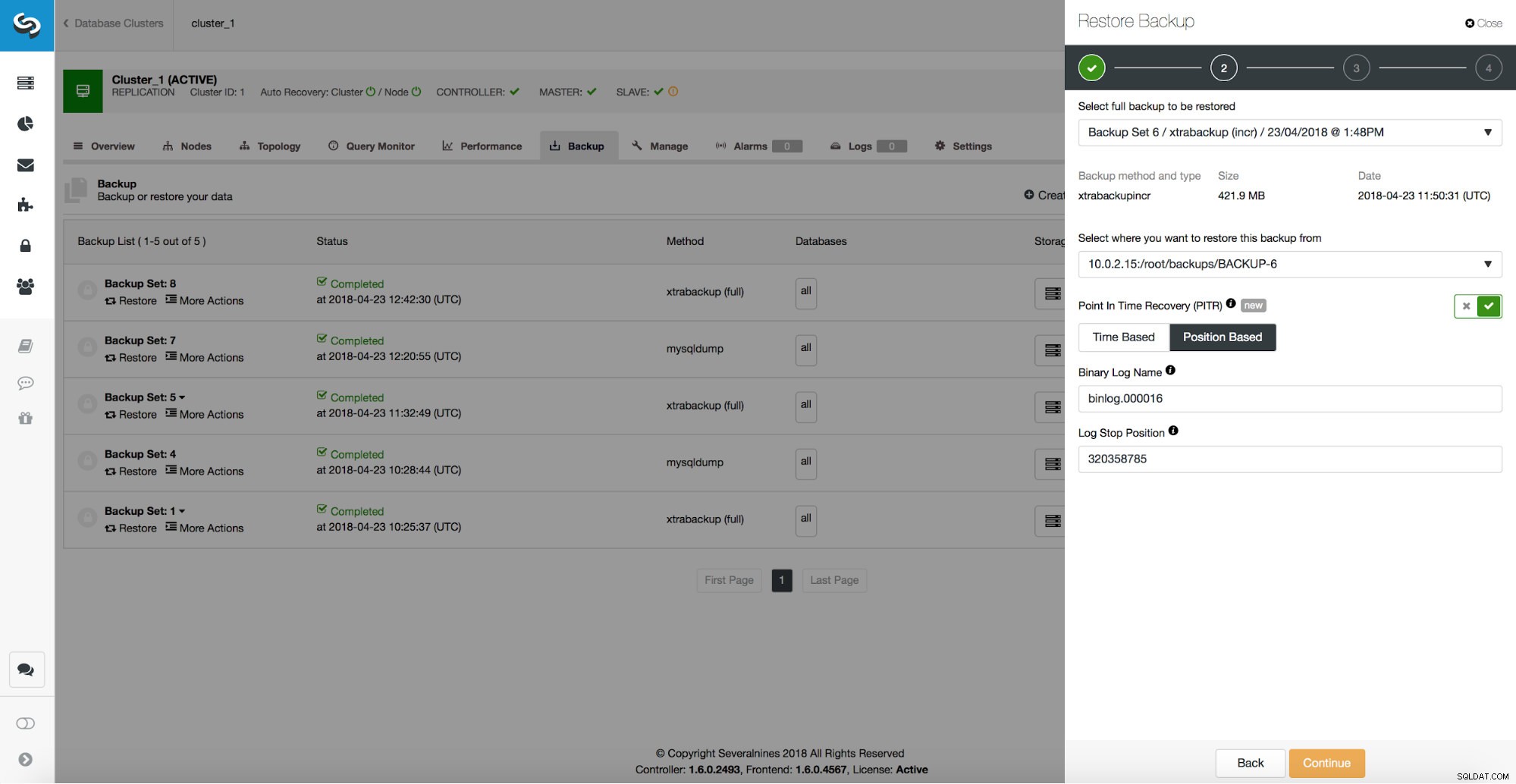
Nô lệ bị trì hoãn
Nếu chúng ta có một nô lệ bị trì hoãn và máy chủ đó đủ để xử lý tất cả lưu lượng truy cập, chúng ta có thể sử dụng nó và thăng cấp nó lên thành master. Tuy nhiên, trước tiên, chúng ta phải đảm bảo rằng nó bắt kịp với bản gốc cũ cho đến thời điểm mất dữ liệu. Chúng tôi sẽ sử dụng một số CLI ở đây để biến nó thành hiện thực. Đầu tiên, chúng ta cần tìm ra vị trí mà việc mất dữ liệu đã xảy ra. Sau đó, chúng tôi sẽ dừng nô lệ và để nó chạy đến sự kiện mất dữ liệu. Chúng tôi đã chỉ ra cách để có được vị trí chính xác trong phần trước - bằng cách kiểm tra các bản ghi nhị phân. Chúng tôi có thể sử dụng vị trí đó (binlog.000016, vị trí 320358785) hoặc, nếu chúng tôi sử dụng nô lệ đa luồng, chúng tôi nên sử dụng GTID của sự kiện mất dữ liệu (52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415) và phát lại các truy vấn lên đến GTID đó.
Trước tiên, chúng ta hãy dừng nô lệ và vô hiệu hóa độ trễ:
mysql> STOP SLAVE;
Query OK, 0 rows affected (0.01 sec)
mysql> CHANGE MASTER TO MASTER_DELAY = 0;
Query OK, 0 rows affected (0.02 sec)Sau đó, chúng tôi có thể bắt đầu nó đến một vị trí nhật ký nhị phân nhất định.
mysql> START SLAVE UNTIL MASTER_LOG_FILE='binlog.000016', MASTER_LOG_POS=320358785;
Query OK, 0 rows affected (0.01 sec)Nếu chúng tôi muốn sử dụng GTID, lệnh sẽ trông khác:
mysql> START SLAVE UNTIL SQL_BEFORE_GTIDS = ‘52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415’;
Query OK, 0 rows affected (0.01 sec)Khi quá trình sao chép dừng lại (có nghĩa là tất cả các sự kiện chúng tôi yêu cầu đã được thực thi), chúng tôi nên xác minh rằng máy chủ chứa dữ liệu bị thiếu. Nếu vậy, bạn có thể thăng cấp nó lên máy chủ và sau đó xây dựng lại các máy chủ khác bằng cách sử dụng máy chủ mới làm nguồn dữ liệu.
Đây không phải lúc nào cũng là lựa chọn tốt nhất. Tất cả phụ thuộc vào mức độ trì hoãn của nô lệ của bạn - nếu nó bị trì hoãn vài giờ, có thể không có ý nghĩa gì khi đợi nó bắt kịp, đặc biệt nếu lưu lượng truy cập quá lớn trong môi trường của bạn. Trong trường hợp như vậy, việc xây dựng lại máy chủ lưu trữ bằng cách sử dụng sao lưu vật lý có khả năng nhanh hơn. Mặt khác, nếu bạn có một lượng lưu lượng truy cập khá nhỏ, đây có thể là một cách tốt để thực sự nhanh chóng khắc phục sự cố, quảng cáo tổng thể mới và tiếp tục phân phối lưu lượng truy cập, trong khi phần còn lại của các nút đang được xây dựng lại trong nền .
Mất một phần dữ liệu - Sao lưu vật lý
Trong trường hợp mất một phần dữ liệu, các bản sao lưu vật lý có thể không hiệu quả nhưng vì đây là loại bản sao lưu phổ biến nhất nên điều rất quan trọng là phải biết cách sử dụng chúng để khôi phục một phần. Bước đầu tiên sẽ luôn là khôi phục bản sao lưu cho đến thời điểm trước khi xảy ra sự kiện mất dữ liệu. Việc khôi phục nó trên một máy chủ riêng cũng rất quan trọng. ClusterControl sử dụng xtrabackup để sao lưu vật lý, vì vậy chúng tôi sẽ hướng dẫn cách sử dụng nó. Giả sử chúng tôi đã chạy truy vấn không chính xác sau:
DELETE FROM sbtest1 WHERE id < 23146;
Chúng tôi chỉ muốn xóa một hàng duy nhất (‘=’ trong mệnh đề WHERE), thay vào đó chúng tôi xóa một loạt chúng (
Bây giờ, hãy xem tệp đầu ra và xem những gì chúng ta có thể tìm thấy ở đó. Chúng tôi đang sử dụng sao chép dựa trên hàng do đó chúng tôi sẽ không thấy SQL chính xác đã được thực thi. Thay vào đó (miễn là chúng tôi sẽ sử dụng cờ --verbose cho mysqlbinlog), chúng tôi sẽ thấy các sự kiện như dưới đây:
Có thể thấy, MySQL xác định các hàng cần xóa bằng cách sử dụng điều kiện WHERE rất chính xác. Các dấu hiệu bí ẩn trong nhận xét mà con người có thể đọc được, “@ 1”, “@ 2”, có nghĩa là “cột đầu tiên”, “cột thứ hai”. Chúng tôi biết rằng cột đầu tiên là "id", đây là điều chúng tôi quan tâm. Chúng tôi cần tìm một sự kiện DELETE lớn trên bảng "sbtest1". Các nhận xét theo sau phải đề cập đến id là 1, sau đó đến id là ‘2’, sau đó là ‘3’, v.v. - tất cả cho đến id là ‘23145’. Tất cả phải được thực hiện trong một giao dịch duy nhất (sự kiện duy nhất trong nhật ký nhị phân). Sau khi phân tích đầu ra bằng cách sử dụng "less", chúng tôi nhận thấy:
Sự kiện mà những nhận xét đó được đính kèm bắt đầu tại:
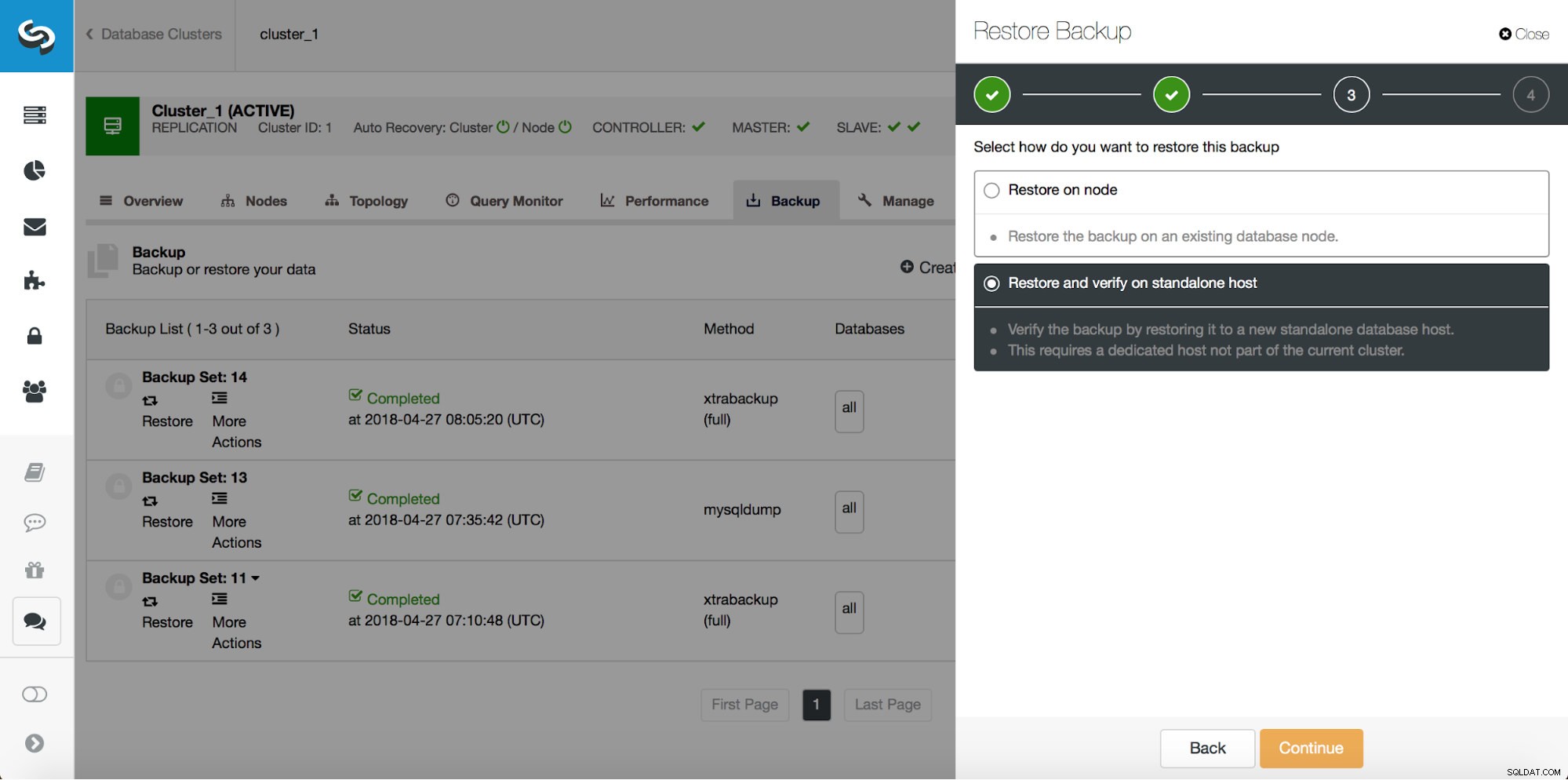
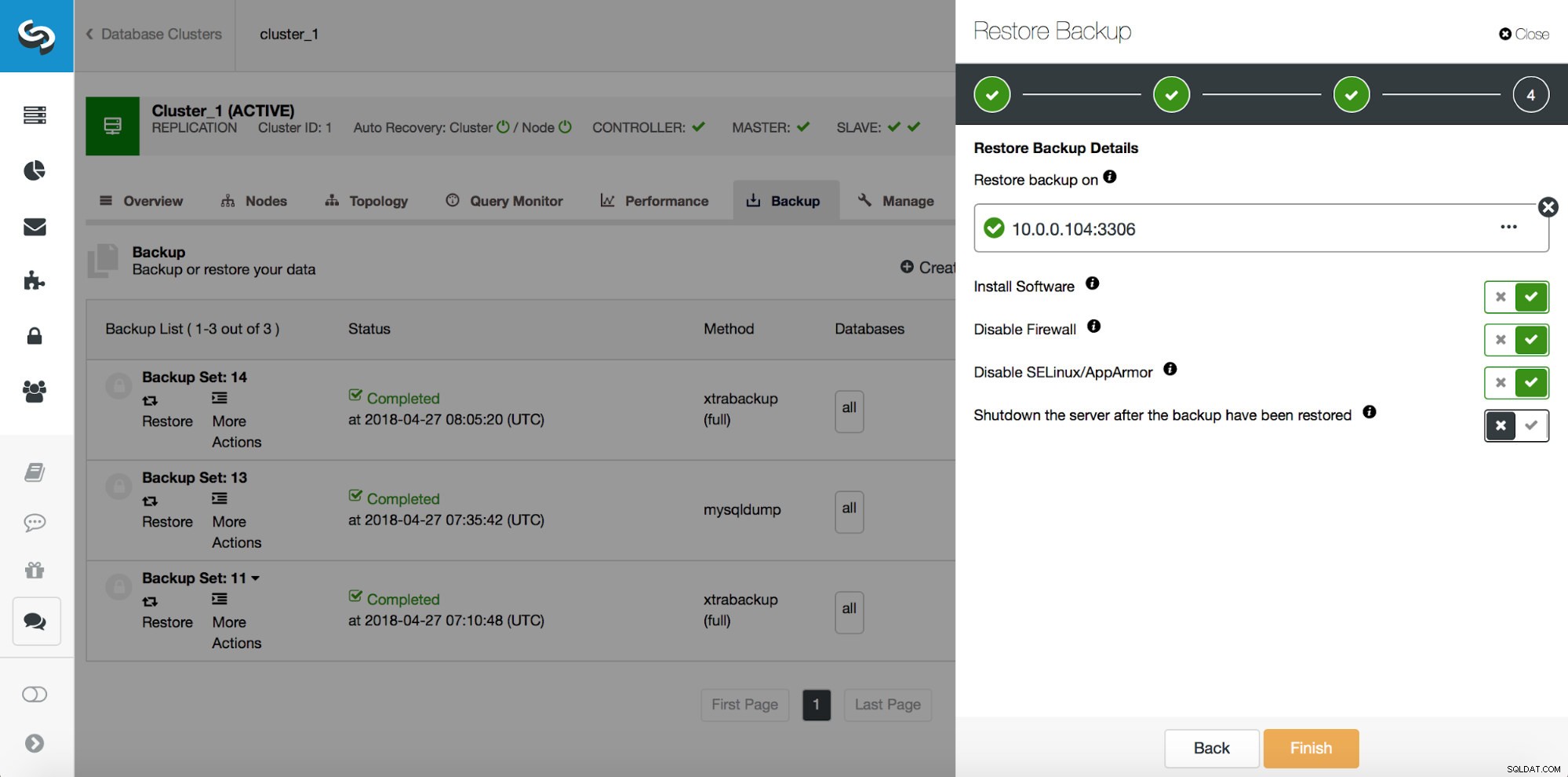
Vì vậy, chúng tôi muốn khôi phục bản sao lưu về cam kết trước đó ở vị trí 29600687. Hãy làm điều đó ngay bây giờ. Chúng tôi sẽ sử dụng máy chủ bên ngoài cho việc đó. Chúng tôi sẽ khôi phục bản sao lưu đến vị trí đó và chúng tôi sẽ duy trì hoạt động của máy chủ khôi phục để sau đó chúng tôi có thể trích xuất dữ liệu bị thiếu.
Sau khi quá trình khôi phục hoàn tất, hãy đảm bảo rằng dữ liệu của chúng tôi đã được khôi phục:
Có vẻ tốt. Bây giờ chúng tôi có thể trích xuất dữ liệu này thành một tệp mà chúng tôi sẽ tải lại trên tệp chính.
Có điều gì đó không ổn - điều này là do máy chủ được định cấu hình để chỉ có thể ghi tệp ở một vị trí cụ thể - tất cả là về bảo mật, chúng tôi không muốn để người dùng lưu nội dung ở bất kỳ đâu họ thích. Hãy kiểm tra nơi chúng tôi có thể lưu tệp của mình:
Được rồi, chúng ta hãy thử một lần nữa:
Bây giờ nó trông tốt hơn nhiều. Hãy sao chép dữ liệu vào cái chính:
Bây giờ đã đến lúc tải các hàng còn thiếu trên trang cái và kiểm tra xem nó có thành công không:
Đó là tất cả, chúng tôi đã khôi phục dữ liệu bị thiếu của mình.
Trong phần trước, chúng tôi đã khôi phục dữ liệu bị mất bằng cách sử dụng sao lưu vật lý và máy chủ bên ngoài. Điều gì sẽ xảy ra nếu chúng ta đã tạo bản sao lưu hợp lý? Chúng ta hãy xem xét. Trước tiên, hãy xác minh rằng chúng tôi có một bản sao lưu hợp lý:
Vâng, nó ở đó. Bây giờ, đã đến lúc giải nén nó.
Khi bạn nhìn vào nó, bạn sẽ thấy rằng dữ liệu được lưu trữ ở định dạng INSERT đa giá trị. Ví dụ:
Tất cả những gì chúng ta cần làm bây giờ là xác định vị trí của bảng và sau đó là nơi lưu trữ các hàng mà chúng ta quan tâm. Đầu tiên, khi biết các mẫu mysqldump (thả bảng, tạo mới, tắt chỉ mục, chèn dữ liệu), hãy tìm ra dòng nào chứa câu lệnh CREATE TABLE cho bảng ‘sbtest1’:
Bây giờ, bằng cách sử dụng phương pháp thử và sai, chúng ta cần tìm ra vị trí cần tìm các hàng của chúng ta. Chúng tôi sẽ chỉ cho bạn lệnh cuối cùng mà chúng tôi đã nghĩ ra. Toàn bộ thủ thuật là thử và in các phạm vi dòng khác nhau bằng cách sử dụng sed và sau đó kiểm tra xem dòng mới nhất có chứa các hàng gần với nhưng muộn hơn những gì chúng ta đang tìm kiếm hay không. Trong lệnh bên dưới, chúng tôi tìm kiếm các dòng từ 971 (CREATE TABLE) đến 993. Chúng tôi cũng yêu cầu sed thoát khi nó đạt đến dòng 994 vì chúng tôi không quan tâm đến phần còn lại của tệp:
Đầu ra giống như bên dưới:
Điều này có nghĩa là phạm vi hàng của chúng tôi (tối đa hàng có id là 23145) là gần. Tiếp theo, đó là tất cả về việc xóa tệp thủ công. Chúng tôi muốn nó bắt đầu với hàng đầu tiên chúng tôi cần khôi phục:
Và kết thúc với hàng cuối cùng để khôi phục:
Chúng tôi đã phải cắt bớt một số dữ liệu không cần thiết (đó là chèn nhiều dòng) nhưng sau tất cả những điều này, chúng tôi có một tệp mà chúng tôi có thể tải lại trên tệp chính.
Cuối cùng, hãy kiểm tra lần cuối:
Tất cả đều tốt, dữ liệu đã được khôi phục.
Trong trường hợp này, chúng tôi sẽ không xem xét toàn bộ quá trình. Chúng tôi đã mô tả cách xác định vị trí của sự kiện mất dữ liệu trong nhật ký nhị phân. Chúng tôi cũng mô tả cách dừng nô lệ bị trì hoãn và bắt đầu sao chép lại, cho đến thời điểm trước khi xảy ra sự kiện mất dữ liệu. Chúng tôi cũng giải thích cách sử dụng SELECT INTO OUTFILE và LOAD DATA INFILE để xuất dữ liệu từ máy chủ bên ngoài và tải nó trên máy chủ. Đó là tất cả những gì bạn cần. Miễn là dữ liệu vẫn còn trên nô lệ bị trì hoãn, bạn phải dừng nó lại. Sau đó, bạn cần xác định vị trí trước khi xảy ra sự kiện mất dữ liệu, khởi động nô lệ cho đến thời điểm đó và sau khi hoàn thành việc này, sử dụng nô lệ bị trì hoãn để trích xuất dữ liệu đã bị xóa, sao chép tệp vào master và tải nó để khôi phục dữ liệu .
Việc khôi phục dữ liệu bị mất không phải là điều thú vị, nhưng nếu bạn làm theo các bước mà chúng tôi đã trải qua trong blog này, bạn sẽ có cơ hội tốt để khôi phục những gì bạn đã mất. mysqlbinlog --verbose /var/lib/mysql/binlog.000003 > bin.out### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=999296
### @2=1009782
### @3='96260841950-70557543083-97211136584-70982238821-52320653831-03705501677-77169427072-31113899105-45148058587-70555151875'
### @4='84527471555-75554439500-82168020167-12926542460-82869925404'### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=1
### @2=1006036
### @3='123'
### @4='43683718329-48150560094-43449649167-51455516141-06448225399'
### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=2
### @2=1008980
### @3='123'
### @4='05603373460-16140454933-50476449060-04937808333-32421752305'#180427 8:09:21 server id 1 end_log_pos 29600687 CRC32 0x8cfdd6ae Xid = 307686
COMMIT/*!*/;
# at 29600687
#180427 8:09:21 server id 1 end_log_pos 29600752 CRC32 0xb5aa18ba GTID last_committed=42844 sequence_number=42845 rbr_only=yes
/*!50718 SET TRANSACTION ISOLATION LEVEL READ COMMITTED*//*!*/;
SET @@SESSION.GTID_NEXT= '0c695e13-4931-11e8-9f2f-080027e8bf1b:55893'/*!*/;
# at 29600752
#180427 8:09:21 server id 1 end_log_pos 29600826 CRC32 0xc7b71da5 Query thread_id=44 exec_time=0 error_code=0
SET TIMESTAMP=1524816561/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
BEGIN
/*!*/;
# at 29600826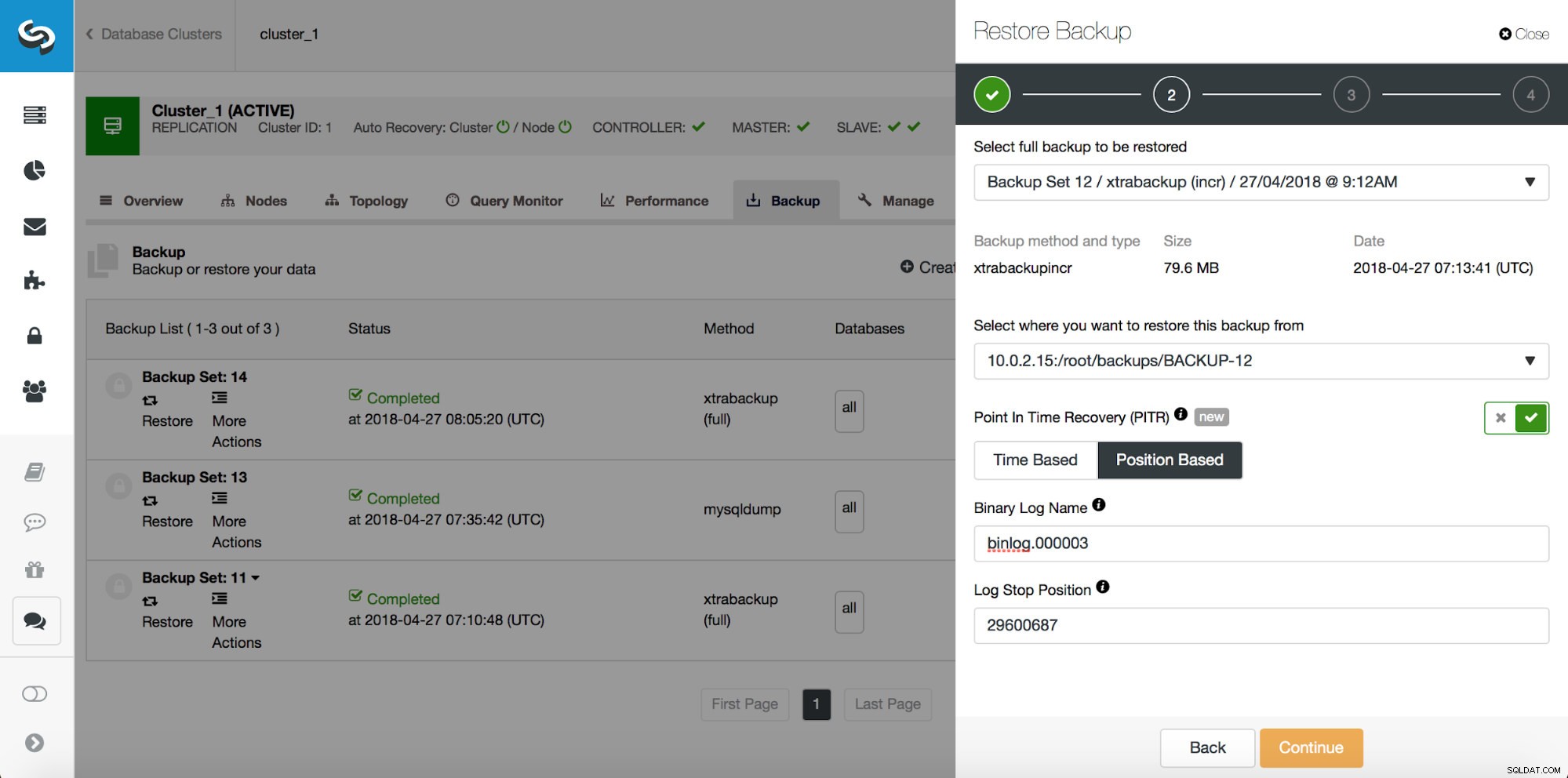
mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.03 sec)mysql> SELECT * FROM sbtest.sbtest1 WHERE id < 23146 INTO OUTFILE 'missing.sql';
ERROR 1290 (HY000): The MySQL server is running with the --secure-file-priv option so it cannot execute this statementmysql> SHOW VARIABLES LIKE "secure_file_priv";
+------------------+-----------------------+
| Variable_name | Value |
+------------------+-----------------------+
| secure_file_priv | /var/lib/mysql-files/ |
+------------------+-----------------------+
1 row in set (0.13 sec)mysql> SELECT * FROM sbtest.sbtest1 WHERE id < 23146 INTO OUTFILE '/var/lib/mysql-files/missing.sql';
Query OK, 23145 rows affected (0.05 sec)example@sqldat.com:~# scp /var/lib/mysql-files/missing.sql 10.0.0.101:/var/lib/mysql-files/
missing.sql 100% 1744KB 1.7MB/s 00:00mysql> LOAD DATA INFILE '/var/lib/mysql-files/missing.sql' INTO TABLE sbtest.sbtest1;
Query OK, 23145 rows affected (2.22 sec)
Records: 23145 Deleted: 0 Skipped: 0 Warnings: 0
mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.00 sec) Mất một phần dữ liệu - Sao lưu lôgic
example@sqldat.com:~# ls -alh /root/backups/BACKUP-13/
total 5.8G
drwx------ 2 root root 4.0K Apr 27 07:35 .
drwxr-x--- 5 root root 4.0K Apr 27 07:14 ..
-rw-r--r-- 1 root root 2.4K Apr 27 07:35 cmon_backup.metadata
-rw------- 1 root root 5.8G Apr 27 07:35 mysqldump_2018-04-27_071434_complete.sql.gzexample@sqldat.com:~# mkdir /root/restore
example@sqldat.com:~# zcat /root/backups/BACKUP-13/mysqldump_2018-04-27_071434_complete.sql.gz > /root/restore/backup.sqlINSERT INTO `sbtest1` VALUES (1,1006036,'18034632456-32298647298-82351096178-60420120042-90070228681-93395382793-96740777141-18710455882-88896678134-41810932745','43683718329-48150560094-43449649167-51455516141-06448225399'),(2,1008980,'69708345057-48265944193-91002879830-11554672482-35576538285-03657113365-90301319612-18462263634-56608104414-27254248188','05603373460-16140454933-50476449060-04937808333-32421752305')example@sqldat.com:~/restore# grep -n "CREATE TABLE \`sbtest1\`" backup.sql > out
example@sqldat.com:~/restore# cat out
971:CREATE TABLE `sbtest1` (example@sqldat.com:~/restore# sed -n '971,993p; 994q' backup.sql > 1.sql
example@sqldat.com:~/restore# tail -n 1 1.sql | lessINSERT INTO `sbtest1` VALUES (31351,1007187,'23938390896-69688180281-37975364313-05234865797-89299459691-74476188805-03642252162-40036598389-45190639324-97494758464','60596247401-06173974673-08009930825-94560626453-54686757363'),INSERT INTO `sbtest1` VALUES (1,1006036,'18034632456-32298647298-82351096178-60420120042-90070228681-93395382793-96740777141-18710455882-88896678134-41810932745','43683718329-48150560094-43449649167-51455516141-06448225399')(23145,1001595,'37250617862-83193638873-99290491872-89366212365-12327992016-32030298805-08821519929-92162259650-88126148247-75122945670','60801103752-29862888956-47063830789-71811451101-27773551230');example@sqldat.com:~/restore# cat 1.sql | mysql -usbtest -psbtest -h10.0.0.101 sbtest
mysql: [Warning] Using a password on the command line interface can be insecure.mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.00 sec) Mất một phần dữ liệu, Nô lệ bị trì hoãn
Kết luận