Những thay đổi trong biểu diễn nội bộ của bảng được phân vùng giữa SQL Server 2005 và SQL Server 2008 dẫn đến việc cải thiện hiệu suất và kế hoạch truy vấn trong phần lớn các trường hợp (đặc biệt là khi thực hiện song song có liên quan). Thật không may, những thay đổi tương tự đã khiến một số tính năng hoạt động tốt trong SQL Server 2005 đột nhiên không hoạt động tốt trong SQL Server 2008 trở lên. Bài đăng này xem xét một ví dụ trong đó trình tối ưu hóa truy vấn SQL Server 2005 tạo ra một kế hoạch thực thi vượt trội so với các phiên bản sau.
Bảng và Dữ liệu Mẫu
Các ví dụ trong bài đăng này sử dụng bảng và dữ liệu được phân vùng sau:
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES
(
10000, 20000, 30000, 40000, 50000,
60000, 70000, 80000, 90000, 100000,
110000, 120000, 130000, 140000, 150000
);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
CREATE TABLE dbo.T4
(
RowID integer IDENTITY NOT NULL,
SomeData integer NOT NULL,
CONSTRAINT PK_T4
PRIMARY KEY CLUSTERED (RowID)
ON PS (RowID)
);
INSERT dbo.T4 WITH (TABLOCKX)
(SomeData)
SELECT
ABS(CHECKSUM(NEWID()))
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
CREATE NONCLUSTERED INDEX nc1
ON dbo.T4 (SomeData)
ON PS (RowID); Bố cục dữ liệu được phân vùng
Bảng của chúng tôi có một chỉ mục được phân nhóm được phân vùng. Trong trường hợp này, khóa phân cụm cũng đóng vai trò là khóa phân vùng (mặc dù nói chung đây không phải là một yêu cầu). Việc phân vùng dẫn đến các đơn vị lưu trữ vật lý riêng biệt (bộ hàng) mà bộ xử lý truy vấn hiển thị cho người dùng như một thực thể duy nhất.
Sơ đồ dưới đây cho thấy ba phân vùng đầu tiên của bảng của chúng tôi (nhấp để phóng to):
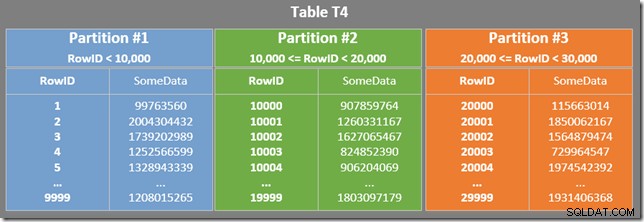
Chỉ mục không phân tán được phân vùng theo cùng một cách (nó được “căn chỉnh”):

Mỗi phân vùng của chỉ mục không phân bổ bao gồm một loạt các giá trị RowID. Trong mỗi phân vùng, dữ liệu được sắp xếp theo SomeData (nhưng các giá trị RowID nói chung sẽ không được sắp xếp theo thứ tự).
Sự cố MIN / MAX
Nó được biết đến một cách hợp lý rằng MIN và MAX tổng hợp không tối ưu hóa tốt trên các bảng được phân vùng (trừ khi cột được tổng hợp cũng giống như cột phân vùng). Hạn chế này (vẫn tồn tại trong SQL Server 2014 CTP 1) đã được viết nhiều lần trong nhiều năm; phạm vi yêu thích của tôi là trong bài viết này của Itzik Ben-Gan. Để minh họa ngắn gọn vấn đề, hãy xem xét truy vấn sau:
SELECT MIN(SomeData) FROM dbo.T4;
Kế hoạch thực thi trên SQL Server 2008 trở lên như sau:

Kế hoạch này đọc tất cả 150.000 hàng từ chỉ mục và một Tổng hợp Luồng tính toán giá trị tối thiểu (kế hoạch thực thi về cơ bản giống nhau nếu chúng tôi yêu cầu giá trị lớn nhất thay thế). Kế hoạch thực thi SQL Server 2005 hơi khác (mặc dù không tốt hơn):
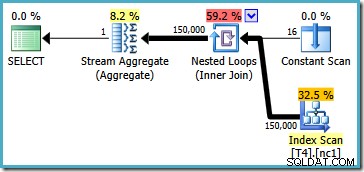
Kế hoạch này lặp qua số phân vùng (được liệt kê trong Quét liên tục) quét toàn bộ phân vùng tại một thời điểm. Tất cả 150.000 hàng cuối cùng vẫn được đọc và xử lý bởi Stream Aggregate.
Nhìn lại bảng được phân vùng và sơ đồ chỉ mục và nghĩ về cách truy vấn có thể được xử lý hiệu quả hơn trên tập dữ liệu của chúng tôi. Chỉ mục không phân tán có vẻ là một lựa chọn tốt để giải quyết truy vấn vì nó chứa các giá trị SomeData theo thứ tự có thể được khai thác khi tính toán tổng hợp.
Bây giờ, thực tế là chỉ mục được phân vùng làm phức tạp một chút vấn đề:mỗi phân vùng của chỉ mục được sắp xếp theo cột SomeData, nhưng chúng tôi không thể chỉ đọc giá trị thấp nhất từ bất kỳ cụ thể nào phân vùng để có câu trả lời phù hợp cho toàn bộ truy vấn.
Khi bản chất cơ bản của vấn đề được hiểu, con người có thể thấy rằng chiến lược hiệu quả sẽ là tìm giá trị thấp nhất của SomeData trong mỗi phân vùng của chỉ mục, rồi lấy giá trị thấp nhất từ kết quả trên mỗi phân vùng.
Đây thực chất là cách giải quyết mà Itzik trình bày trong bài viết của mình; viết lại truy vấn để tính tổng hợp cho mỗi phân vùng (sử dụng APPLY cú pháp) và sau đó tổng hợp lại trên các kết quả trên mỗi phân vùng đó. Sử dụng cách tiếp cận đó, MIN được viết lại truy vấn tạo ra kế hoạch thực thi này (xem bài viết của Itzik để biết cú pháp chính xác):
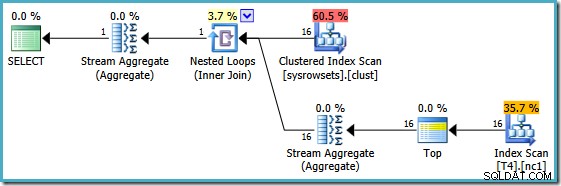
Kế hoạch này đọc số phân vùng từ bảng hệ thống và truy xuất giá trị thấp nhất của SomeData trong mỗi phân vùng. Tổng hợp Luồng cuối cùng chỉ tính toán mức tối thiểu qua kết quả trên mỗi phân vùng.
Tính năng quan trọng trong kế hoạch này là nó đọc một hàng đơn từ mỗi phân vùng (khai thác thứ tự sắp xếp của chỉ mục trong mỗi phân vùng). Nó hiệu quả hơn nhiều so với kế hoạch của trình tối ưu hóa đã xử lý tất cả 150.000 hàng trong bảng.
MIN và MAX trong một phân vùng duy nhất
Bây giờ, hãy xem xét truy vấn sau để tìm giá trị nhỏ nhất trong cột SomeData, cho một phạm vi giá trị RowID được chứa trong một phân vùng duy nhất :
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 18000;
Chúng tôi nhận thấy rằng trình tối ưu hóa gặp sự cố với MIN và MAX qua nhiều phân vùng, nhưng chúng tôi hy vọng những hạn chế đó không áp dụng cho một truy vấn phân vùng.
Phân vùng đơn là phân vùng được giới hạn bởi các giá trị RowID 10.000 và 20.000 (xem lại định nghĩa hàm phân vùng). Hàm phân vùng được định nghĩa là RANGE RIGHT , vì vậy giá trị ranh giới 10.000 thuộc phân vùng # 2 và ranh giới 20.000 thuộc phân vùng # 3. Do đó, phạm vi giá trị RowID được chỉ định bởi truy vấn mới của chúng tôi chỉ được chứa trong phân vùng 2.
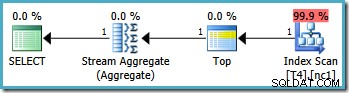
Các kế hoạch thực thi đồ họa cho truy vấn này trông giống nhau trên tất cả các phiên bản SQL Server từ năm 2005 trở đi:
Phân tích kế hoạch
Trình tối ưu hóa đã lấy phạm vi RowID được chỉ định trong WHERE và so sánh nó với định nghĩa hàm phân vùng để xác định rằng chỉ phân vùng 2 của chỉ mục không phân tán cần được truy cập. Thuộc tính kế hoạch SQL Server 2005 cho Quét chỉ mục hiển thị rõ ràng quyền truy cập phân vùng đơn:
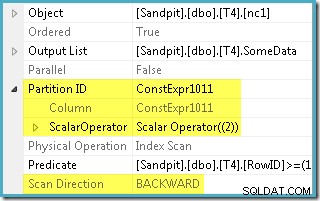
Thuộc tính được đánh dấu khác là Hướng quét. Thứ tự của quá trình quét khác nhau tùy thuộc vào việc truy vấn đang tìm kiếm giá trị SomeData tối thiểu hay tối đa. Chỉ mục không phân bổ được sắp xếp theo thứ tự (trên mỗi phân vùng, hãy nhớ) trên các giá trị SomeData tăng dần, vì vậy hướng Quét chỉ mục là FORWARD nếu truy vấn yêu cầu giá trị nhỏ nhất và BACKWARD nếu giá trị lớn nhất là cần thiết (ảnh chụp màn hình ở trên được lấy từ MAX kế hoạch truy vấn).
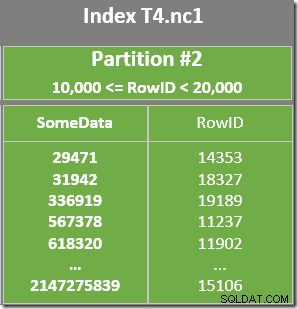
Ngoài ra còn có một Dự đoán còn lại trên Quét chỉ mục để kiểm tra xem các giá trị RowID được quét từ phân vùng 2 có khớp với WHERE không vị ngữ mệnh đề. Trình tối ưu hóa giả định rằng các giá trị RowID được phân phối khá ngẫu nhiên thông qua chỉ mục không phân biệt, vì vậy nó hy vọng sẽ tìm thấy hàng đầu tiên phù hợp với WHERE vị ngữ mệnh đề khá nhanh chóng. Sơ đồ bố trí dữ liệu được phân vùng cho thấy rằng các giá trị RowID thực sự được phân phối khá ngẫu nhiên trong chỉ mục (được sắp xếp theo thứ tự của cột SomeData):
Toán tử trên cùng trong kế hoạch truy vấn giới hạn Quét chỉ mục trong một hàng (từ đầu thấp hoặc cao của chỉ mục tùy thuộc vào Hướng quét). Quét chỉ mục có thể có vấn đề trong các kế hoạch truy vấn, nhưng toán tử Top làm cho nó trở thành một tùy chọn hiệu quả ở đây:quá trình quét chỉ có thể tạo ra một hàng, sau đó nó dừng lại. Kết hợp Quét chỉ mục trên cùng và có thứ tự thực hiện một cách hiệu quả việc tìm kiếm giá trị cao nhất hoặc thấp nhất trong chỉ mục cũng khớp với WHERE các vị ngữ mệnh đề. Tổng hợp Luồng cũng xuất hiện trong kế hoạch để đảm bảo rằng NULL được tạo ra trong trường hợp không có hàng nào được trả về bởi Quét chỉ mục. Vô hướng MIN và MAX tổng hợp được xác định để trả về NULL khi đầu vào là một tập hợp trống.
Nhìn chung, đây là một chiến lược rất hiệu quả và các kế hoạch có chi phí ước tính chỉ là 0,0032921 kết quả là đơn vị. Cho đến nay rất tốt.
Vấn đề giá trị ranh giới
Ví dụ tiếp theo này sửa đổi phần cuối cùng của dải RowID:
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 20000;
Lưu ý rằng truy vấn loại trừ giá trị 20.000 bằng cách sử dụng toán tử “nhỏ hơn”. Nhớ lại rằng giá trị 20.000 thuộc về phân vùng 3 (không phải phân vùng 2) vì hàm phân vùng được định nghĩa là RANGE RIGHT . Máy chủ SQL 2005 trình tối ưu hóa xử lý tình huống này một cách chính xác, tạo ra kế hoạch truy vấn phân vùng đơn tối ưu, với chi phí ước tính là 0,0032878 :
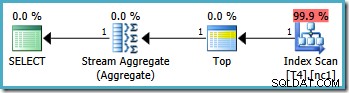
Tuy nhiên, cùng một truy vấn tạo ra một kế hoạch khác trên SQL Server 2008 trở lên (bao gồm SQL Server 2014 CTP 1):
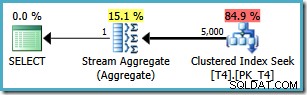
Bây giờ chúng ta có Tìm kiếm chỉ mục theo cụm (thay vì kết hợp quét chỉ mục và toán tử hàng đầu mong muốn). Tất cả 5.000 hàng khớp với WHERE mệnh đề được xử lý thông qua Tổng hợp luồng trong kế hoạch thực thi mới này. Chi phí ước tính của gói này là 0,0199319 đơn vị - hơn sáu lần chi phí của gói SQL Server 2005.
Nguyên nhân
Trình tối ưu hóa SQL Server 2008 (và mới hơn) không hoàn toàn hiểu đúng logic nội bộ khi tham chiếu khoảng thời gian, nhưng loại trừ , một giá trị ranh giới thuộc một phân vùng khác. Trình tối ưu hóa cho rằng không chính xác sẽ có nhiều phân vùng được truy cập và kết luận rằng nó không thể sử dụng tối ưu hóa một phân vùng cho MIN và MAX tổng hợp.
Giải pháp thay thế
Một tùy chọn là viết lại truy vấn bằng cách sử dụng toán tử> =và <=để chúng tôi không tham chiếu giá trị ranh giới từ một phân vùng khác (thậm chí loại trừ nó!):
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID <= 19999;
Điều này dẫn đến kế hoạch tối ưu, chạm vào một phân vùng duy nhất:
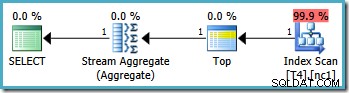
Thật không may, không phải lúc nào cũng có thể chỉ định các giá trị ranh giới chính xác theo cách này (tùy thuộc vào loại cột phân vùng). Một ví dụ về điều đó là với các loại ngày và giờ, nơi tốt nhất là sử dụng các khoảng thời gian nửa kín. Một ý kiến phản đối khác đối với cách giải quyết này mang tính chủ quan hơn:hàm phân vùng loại trừ một ranh giới khỏi phạm vi, do đó, việc viết truy vấn cũng sử dụng cú pháp khoảng thời gian nửa mở dường như tự nhiên nhất.
Cách giải quyết thứ hai là chỉ định số phân vùng một cách rõ ràng (và giữ lại khoảng thời gian nửa mở):
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 20000 AND $PARTITION.PF(RowID) = 2;
Điều này tạo ra kế hoạch tối ưu, với chi phí đắt đỏ là yêu cầu thêm một vị từ và dựa vào người dùng để tìm ra số phân vùng nên là bao nhiêu.
Tất nhiên sẽ tốt hơn nếu các trình tối ưu hóa năm 2008 trở về sau tạo ra cùng một kế hoạch tối ưu mà SQL Server 2005 đã làm. Trong một thế giới hoàn hảo, một giải pháp toàn diện hơn cũng sẽ giải quyết trường hợp đa phân vùng, khiến cho giải pháp mà Itzik mô tả là không cần thiết.