Sao lưu là rất quan trọng khi nói đến sự an toàn của dữ liệu. Chúng là giải pháp khôi phục sau thảm họa tối ưu - bạn không có nút cơ sở dữ liệu nào có thể truy cập được và trung tâm dữ liệu của bạn có thể đã tan thành mây khói, nhưng miễn là bạn có bản sao lưu dữ liệu của mình, bạn vẫn có thể khôi phục sau tình huống như vậy.
Thông thường, bạn sẽ sử dụng các bản sao lưu để khôi phục từ các loại trường hợp khác nhau:
- ngẫu nhiên DROP TABLE hoặc DELETE mà không có mệnh đề WHERE hoặc có mệnh đề WHERE không đủ cụ thể.
- nâng cấp cơ sở dữ liệu không thành công và làm hỏng dữ liệu
- lỗi / hỏng phương tiện lưu trữ
Khôi phục từ bản sao lưu là không đủ? Nó có gì để được điểm trong thời gian? Chúng ta phải ghi nhớ rằng bản sao lưu là một bản chụp nhanh dữ liệu được thực hiện tại một thời điểm nhất định. Nếu bạn sao lưu vào lúc 1 giờ sáng và một bảng vô tình bị xóa lúc 11 giờ sáng, bạn có thể khôi phục dữ liệu của mình đến 1 giờ sáng nhưng những thay đổi xảy ra trong khoảng thời gian từ 1 giờ sáng đến 11 giờ sáng thì sao? Những thay đổi đó sẽ bị mất trừ khi bạn có thể phát lại các sửa đổi đã xảy ra ở giữa. May mắn thay, MySQL có một cơ chế như vậy để lưu trữ các thay đổi - nhật ký nhị phân. Bạn có thể biết những bản ghi đó được sử dụng để sao chép - MySQL sử dụng chúng để lưu trữ tất cả các thay đổi đã xảy ra trên bản chính và một nô lệ sử dụng chúng để phát lại những thay đổi đó và áp dụng chúng vào tập dữ liệu của nó. Vì binlog lưu trữ tất cả các thay đổi, bạn cũng có thể sử dụng chúng để phát lại lưu lượng truy cập. Trong bài đăng trên blog này, chúng ta sẽ xem xét cách ClusterControl có thể giúp bạn thực hiện Khôi phục điểm trong thời gian (PITR).
Tạo bản sao lưu tương thích với khôi phục tại chỗ
Trước hết, hãy nói về điều kiện tiên quyết. Máy chủ lưu trữ nơi bạn thực hiện các bản sao lưu phải được bật nhật ký nhị phân. Không có chúng, PITR là không thể. Yêu cầu thứ hai - một máy chủ lưu trữ nơi bạn thực hiện các bản sao lưu phải có tất cả các bản ghi nhị phân cần thiết để khôi phục về một thời điểm nhất định. Nếu bạn sử dụng xoay vòng nhật ký nhị phân quá mạnh, điều này có thể trở thành vấn đề.
Vì vậy, chúng ta hãy xem cách sử dụng tính năng này trong ClusterControl. Trước hết, bạn phải tạo một bản sao lưu tương thích với PITR. Bản sao lưu đó phải đầy đủ, hoàn chỉnh và nhất quán. Đối với xtrabackup, miễn là nó chứa tập dữ liệu đầy đủ (bạn không chỉ bao gồm một tập hợp con các lược đồ), nó sẽ tương thích với PITR.
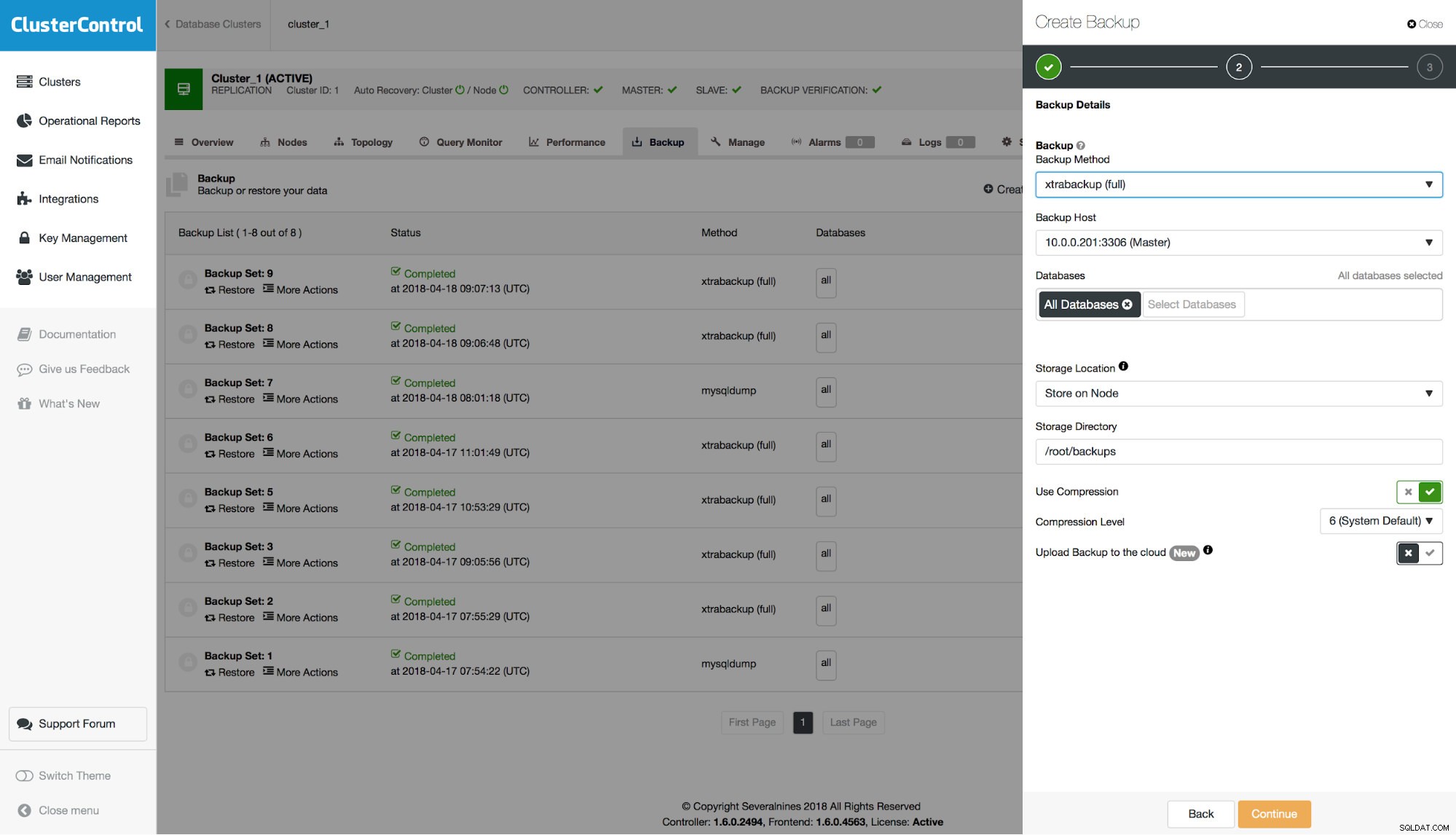
Đối với mysqldump, có một tùy chọn để làm cho nó tương thích với PITR. Khi bạn bật tùy chọn này, tất cả các tùy chọn cần thiết sẽ được định cấu hình (ví dụ:bạn sẽ không thể chọn các lược đồ riêng biệt để đưa vào kết xuất) và bản sao lưu sẽ được đánh dấu là khả dụng để khôi phục tại thời điểm.
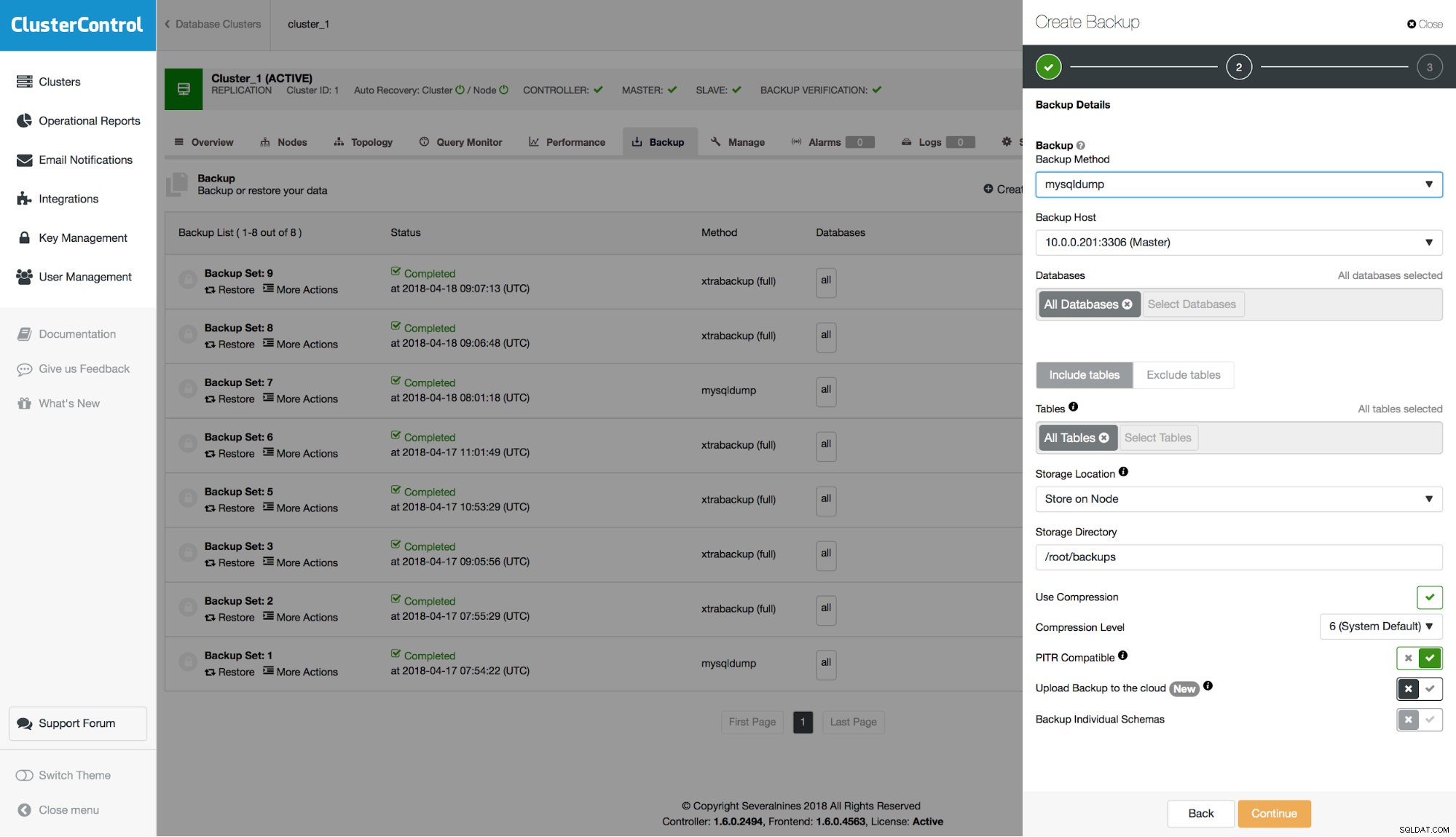
Khôi phục điểm trong thời gian từ bản sao lưu
Đầu tiên, bạn phải chọn một bản sao lưu để khôi phục.
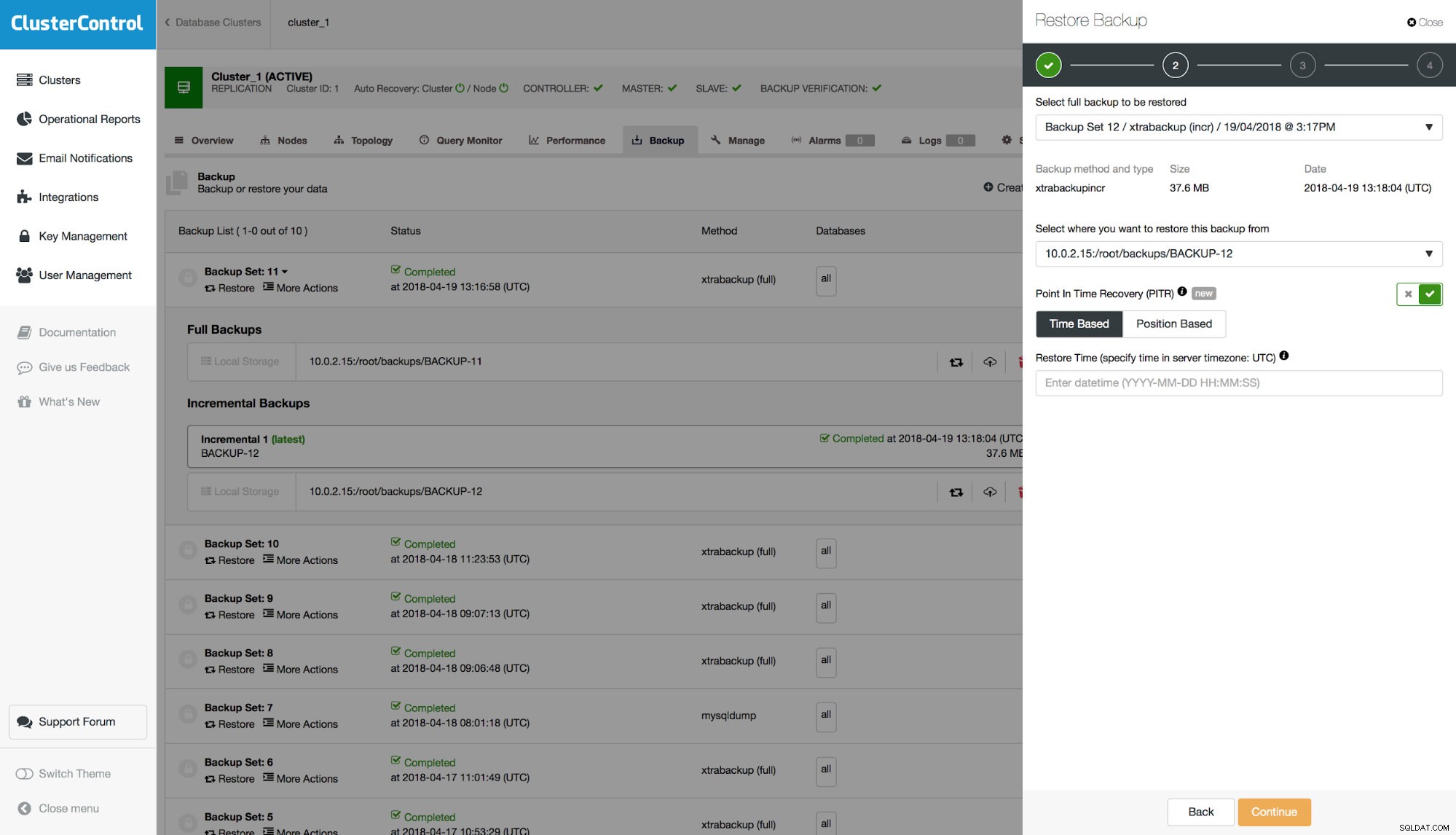
Nếu bản sao lưu tương thích với PITR, một tùy chọn sẽ được hiển thị để thực hiện Khôi phục điểm trong thời gian. Bạn sẽ có hai tùy chọn cho điều đó - "Dựa trên thời gian" và "Dựa trên vị trí". Hãy thảo luận về sự khác biệt giữa hai lựa chọn đó.
PITR “Dựa trên thời gian”
Với tùy chọn này, bạn có thể chuyển ngày và giờ, đến ngày mà bản sao lưu sẽ được khôi phục. Nó có thể được xác định trong vòng một giây phân giải. Nó không đảm bảo rằng tất cả dữ liệu sẽ được khôi phục bởi vì, ngay cả khi bạn xác định rất chính xác thời gian, trong một giây, nhiều sự kiện có thể được ghi lại trong nhật ký nhị phân. Giả sử bạn biết rằng việc mất dữ liệu đã xảy ra vào lúc 10:00:01 ngày 18 tháng 4. Bạn chuyển ngày và giờ sau vào biểu mẫu:‘2018-04-18 10:00:00’. Xin lưu ý rằng bạn nên sử dụng thời gian dựa trên cài đặt múi giờ trên máy chủ cơ sở dữ liệu mà bản sao lưu được tạo.
Vẫn có thể xảy ra trường hợp mất dữ liệu thậm chí không phải là lần đầu tiên xảy ra lúc 10:00:01 nên một số sự kiện sẽ bị mất trong quá trình này. Hãy xem điều đó có nghĩa là gì.
Trong một giây, nhiều sự kiện có thể được ghi vào binlog. Hãy xem xét trường hợp như vậy:
10:00:00 - sự kiện A, B, C, D, E, F
10:00:01 - sự kiện V, W, X, Y, Z
> trong đó X là sự kiện mất dữ liệu. Với mức độ chi tiết của một giây, bạn có thể khôi phục tối đa mọi thứ đã xảy ra lúc 10:00:00 (tối đa F) hoặc đến 10:00:01 (tối đa Z). Trường hợp sau này không được sử dụng vì X sẽ được thực thi lại. Trong trường hợp trước đây, chúng tôi bỏ lỡ V và W.
Đó là lý do tại sao khôi phục dựa trên vị trí chính xác hơn. Bạn có thể nói "Tôi muốn khôi phục tối đa W".
Khôi phục dựa trên thời gian là chính xác nhất mà bạn có thể nhận được mà không cần phải truy cập nhật ký nhị phân và xác định vị trí chính xác mà bạn muốn khôi phục. Điều này dẫn chúng ta đến phương pháp thứ hai để thực hiện PITR.
PITR “Dựa trên vị trí”
Đây là một số kinh nghiệm với các công cụ dòng lệnh cho MySQL, cụ thể là tiện ích mysqlbinlog, là bắt buộc. Mặt khác, bạn sẽ có quyền kiểm soát tốt nhất đối với cách thực hiện khôi phục.
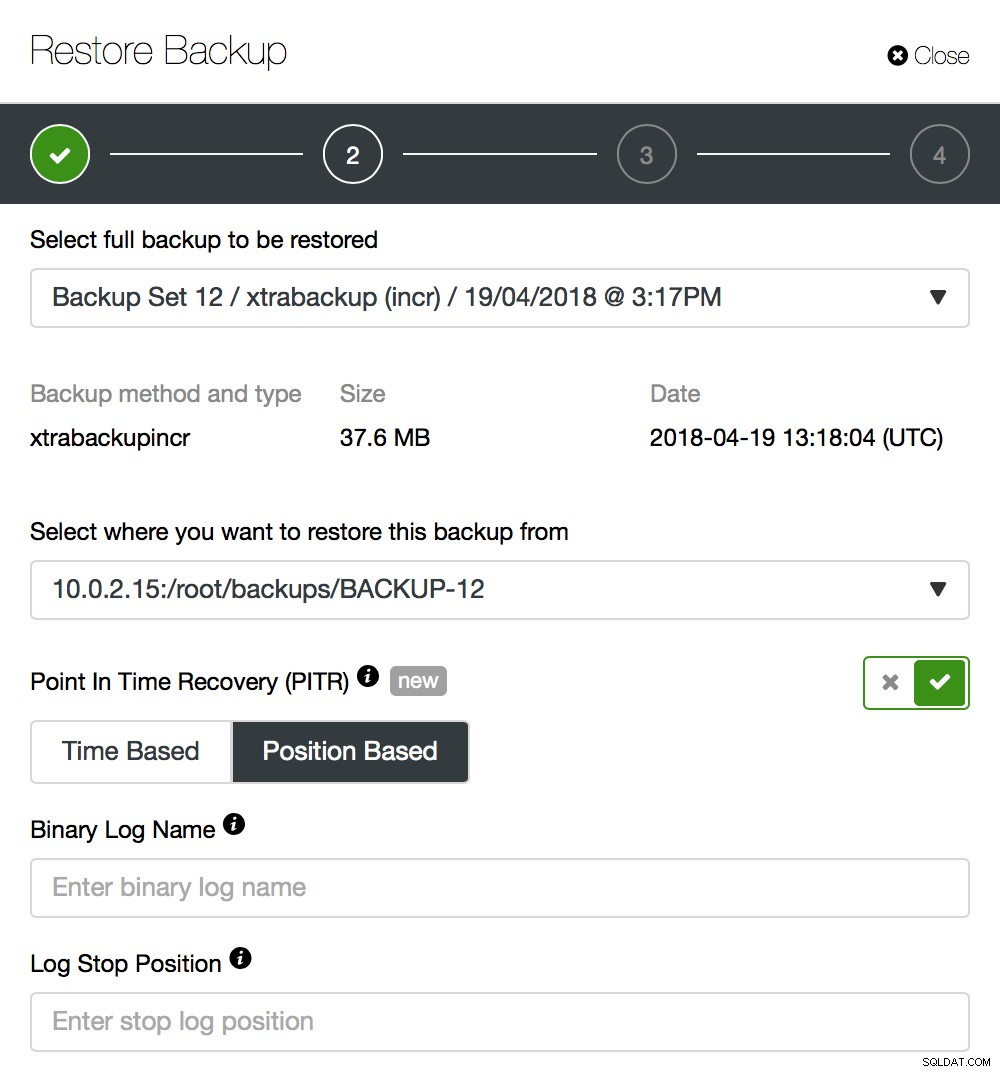
Hãy xem qua một ví dụ đơn giản. Như bạn có thể thấy trong ảnh chụp màn hình ở trên, bạn sẽ phải chuyển tên nhật ký nhị phân và vị trí nhật ký nhị phân cho đến thời điểm đó bản sao lưu sẽ được khôi phục. Hầu hết thời gian, đây phải là vị trí cuối cùng trước sự kiện mất dữ liệu.
Ai đó đã thực thi một lệnh SQL dẫn đến mất dữ liệu nghiêm trọng:
mysql> DROP TABLE sbtest1;
Query OK, 0 rows affected (0.02 sec)Đơn của chúng tôi ngay lập tức bắt đầu phàn nàn:
sysbench 1.1.0-ecf1191 (using bundled LuaJIT 2.1.0-beta3)
Running the test with following options:
Number of threads: 2
Report intermediate results every 1 second(s)
Initializing random number generator from current time
Initializing worker threads...
Threads started!
FATAL: mysql_drv_query() returned error 1146 (Table 'sbtest.sbtest1' doesn't exist) for query 'DELETE FROM sbtest1 WHERE id=5038'
FATAL: `thread_run' function failed: /usr/local/share/sysbench/oltp_common.lua:490: SQL error, errno = 1146, state = '42S02': Table 'sbtest.sbtest1' doesn't existChúng tôi có một bản sao lưu nhưng chúng tôi muốn khôi phục tất cả dữ liệu cho đến thời điểm quan trọng đó. Trước hết, chúng tôi giả định rằng ứng dụng không hoạt động vì vậy chúng tôi có thể loại bỏ tất cả các lần ghi đã xảy ra sau BẢNG DỪA là không quan trọng. Nếu ứng dụng của bạn hoạt động ở một mức độ nào đó, bạn sẽ phải hợp nhất các thay đổi còn lại sau này. Được rồi, chúng ta hãy kiểm tra nhật ký nhị phân để tìm vị trí của câu lệnh DROP TABLE. Vì chúng ta muốn tránh phân tích cú pháp tất cả các nhật ký nhị phân, hãy tìm vị trí của bản sao lưu mới nhất của chúng ta. Bạn có thể kiểm tra điều đó bằng cách kiểm tra nhật ký để tìm bộ sao lưu mới nhất và tìm dòng tương tự như dòng này:
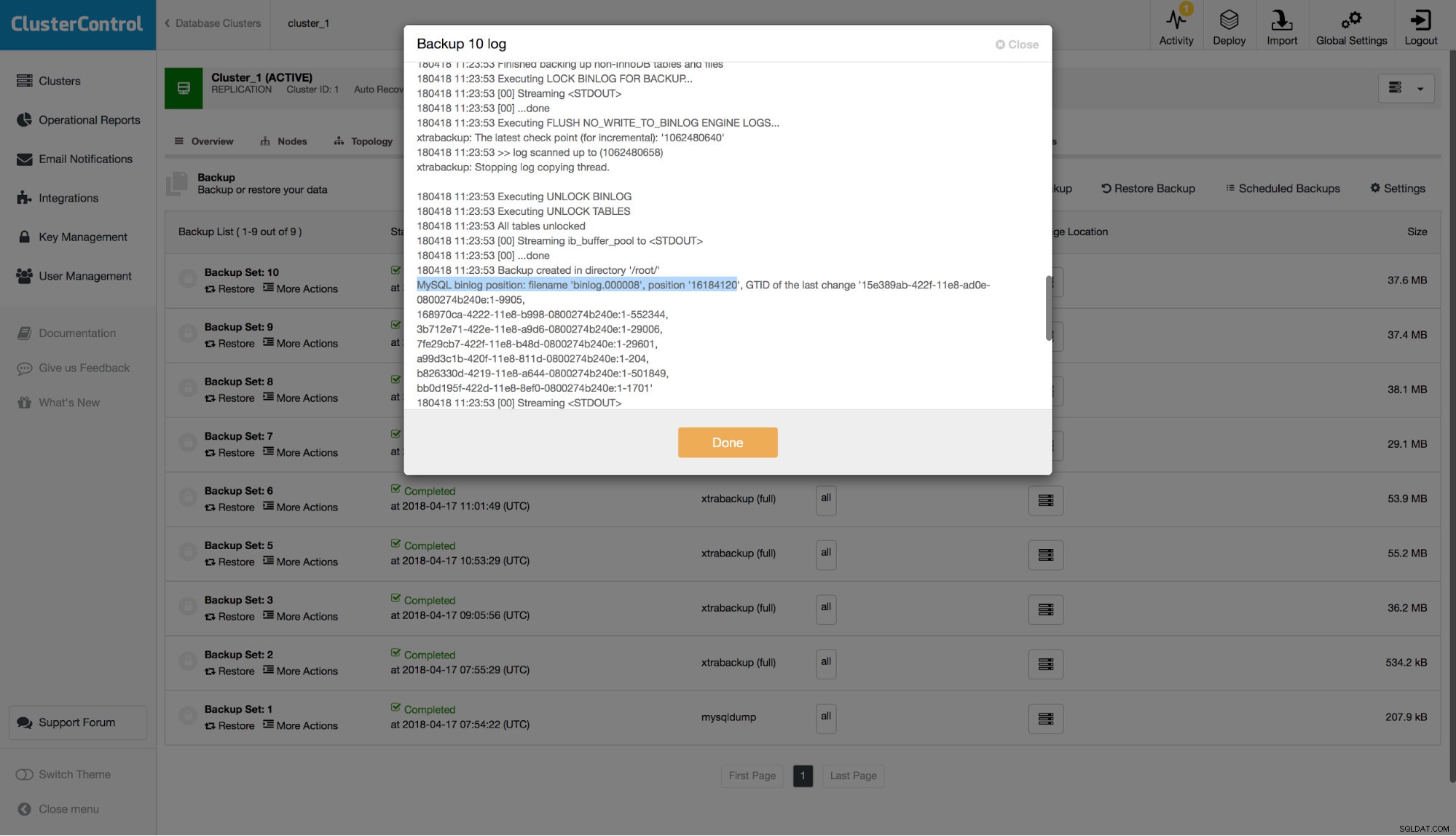
Vì vậy, chúng ta đang nói về tên tệp 'binlog.000008' và vị trí '16184120'. Hãy sử dụng điều này làm điểm khởi đầu của chúng ta. Hãy kiểm tra xem chúng tôi có tệp nhật ký nhị phân nào:
example@sqldat.com:~# ls -alh /var/lib/mysql/binlog.*
-rw-r----- 1 mysql mysql 58M Apr 17 08:31 /var/lib/mysql/binlog.000001
-rw-r----- 1 mysql mysql 116M Apr 17 08:59 /var/lib/mysql/binlog.000002
-rw-r----- 1 mysql mysql 379M Apr 17 09:30 /var/lib/mysql/binlog.000003
-rw-r----- 1 mysql mysql 344M Apr 17 10:54 /var/lib/mysql/binlog.000004
-rw-r----- 1 mysql mysql 892K Apr 17 10:56 /var/lib/mysql/binlog.000005
-rw-r----- 1 mysql mysql 74M Apr 17 11:03 /var/lib/mysql/binlog.000006
-rw-r----- 1 mysql mysql 5.2M Apr 17 11:06 /var/lib/mysql/binlog.000007
-rw-r----- 1 mysql mysql 21M Apr 18 11:35 /var/lib/mysql/binlog.000008
-rw-r----- 1 mysql mysql 59K Apr 18 11:35 /var/lib/mysql/binlog.000009
-rw-r----- 1 mysql mysql 144 Apr 18 11:35 /var/lib/mysql/binlog.indexVì vậy, ngoài 'binlog.000008', chúng tôi cũng có 'binlog.000009' để kiểm tra. Hãy chạy lệnh sẽ chuyển đổi nhật ký nhị phân sang định dạng SQL bắt đầu từ vị trí mà chúng tôi tìm thấy trong nhật ký sao lưu:
example@sqldat.com:~# mysqlbinlog --start-position='16184120' --verbose /var/lib/mysql/binlog.000008 /var/lib/mysql/binlog.000009 > binlog.outVui lòng nút ‘--verbose’ là bắt buộc để giải mã các sự kiện dựa trên hàng. Điều này không nhất thiết phải bắt buộc đối với BẢNG DROP mà chúng tôi đang tìm kiếm, nhưng đối với các loại sự kiện khác, nó có thể cần thiết.
Hãy tìm kiếm đầu ra của chúng tôi cho truy vấn DROP TABLE:
example@sqldat.com:~# grep -B 7 -A 1 "DROP TABLE" binlog.out
# at 20885489
#180418 11:24:32 server id 1 end_log_pos 20885554 CRC32 0xb89f2e66 GTID last_committed=38168 sequence_number=38170 rbr_only=no
SET @@SESSION.GTID_NEXT= '7fe29cb7-422f-11e8-b48d-0800274b240e:38170'/*!*/;
# at 20885554
#180418 11:24:32 server id 1 end_log_pos 20885678 CRC32 0xb38a427b Query thread_id=54 exec_time=0 error_code=0
use `sbtest`/*!*/;
SET TIMESTAMP=1524050672/*!*/;
DROP TABLE `sbtest1` /* generated by server */
/*!*/;Trong mẫu này, chúng ta có thể thấy hai sự kiện. Đầu tiên, ở vị trí 20885489, đặt biến GTID_NEXT.
# at 20885489
#180418 11:24:32 server id 1 end_log_pos 20885554 CRC32 0xb89f2e66 GTID last_committed=38168 sequence_number=38170 rbr_only=no
SET @@SESSION.GTID_NEXT= '7fe29cb7-422f-11e8-b48d-0800274b240e:38170'/*!*/;Thứ hai, ở vị trí 20885554 là sự kiện DROP TABLE của chúng tôi. Điều này dẫn đến kết luận rằng chúng ta nên thực hiện PITR lên đến vị trí 20885489. Câu hỏi duy nhất cần trả lời là chúng ta đang nói về nhật ký nhị phân nào. Chúng tôi có thể kiểm tra điều đó bằng cách tìm kiếm các mục xoay vòng binlog:
example@sqldat.com:~# grep "Rotate to binlog" binlog.out
#180418 11:35:46 server id 1 end_log_pos 21013114 CRC32 0x2772cc18 Rotate to binlog.000009 pos: 4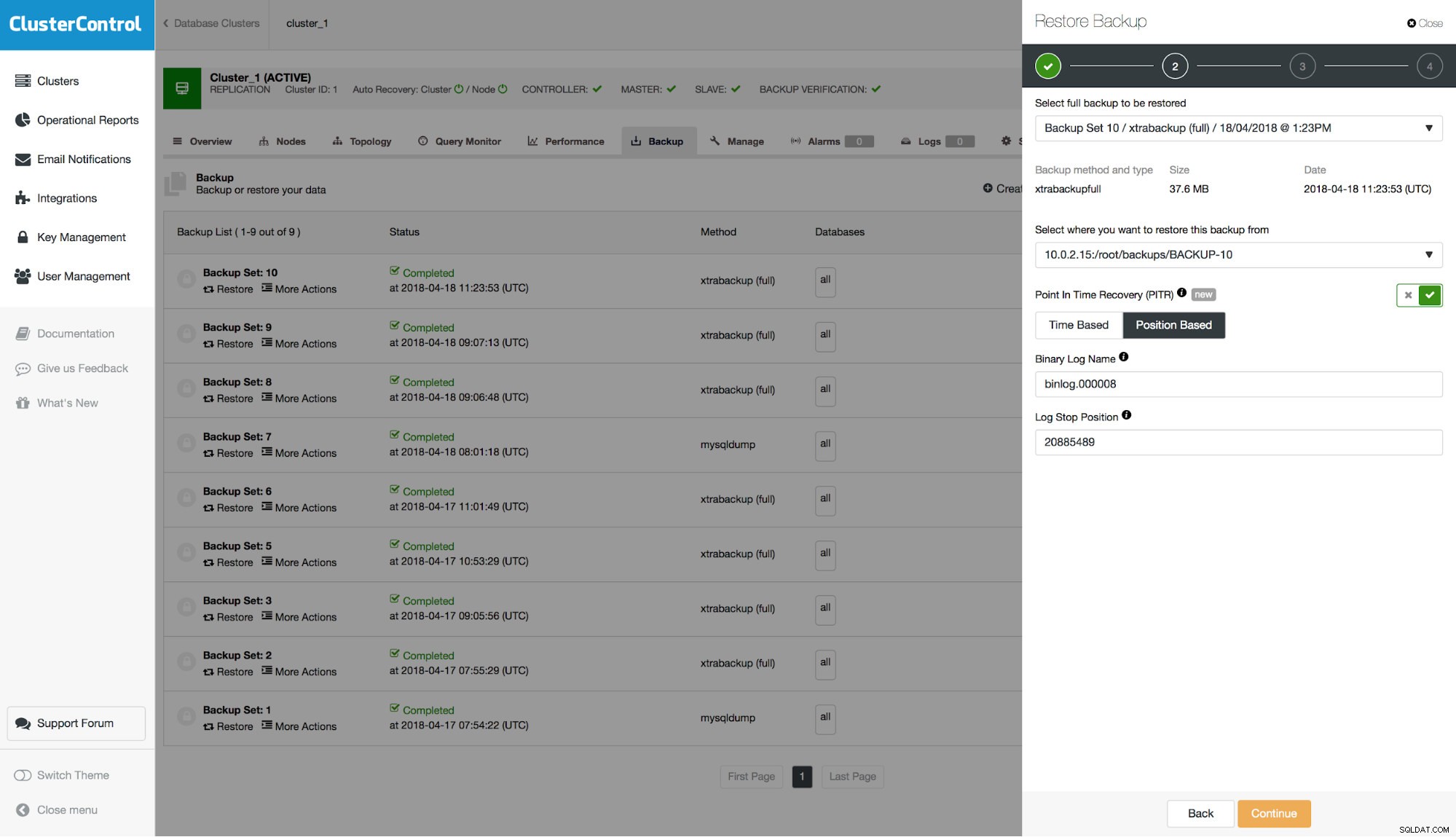
Như có thể thấy rõ ràng bằng cách so sánh ngày tháng, việc xoay vòng sang binlog.000009 đã xảy ra sau đó, do đó chúng tôi muốn chuyển binlog.000008 làm tệp binlog trong biểu mẫu.
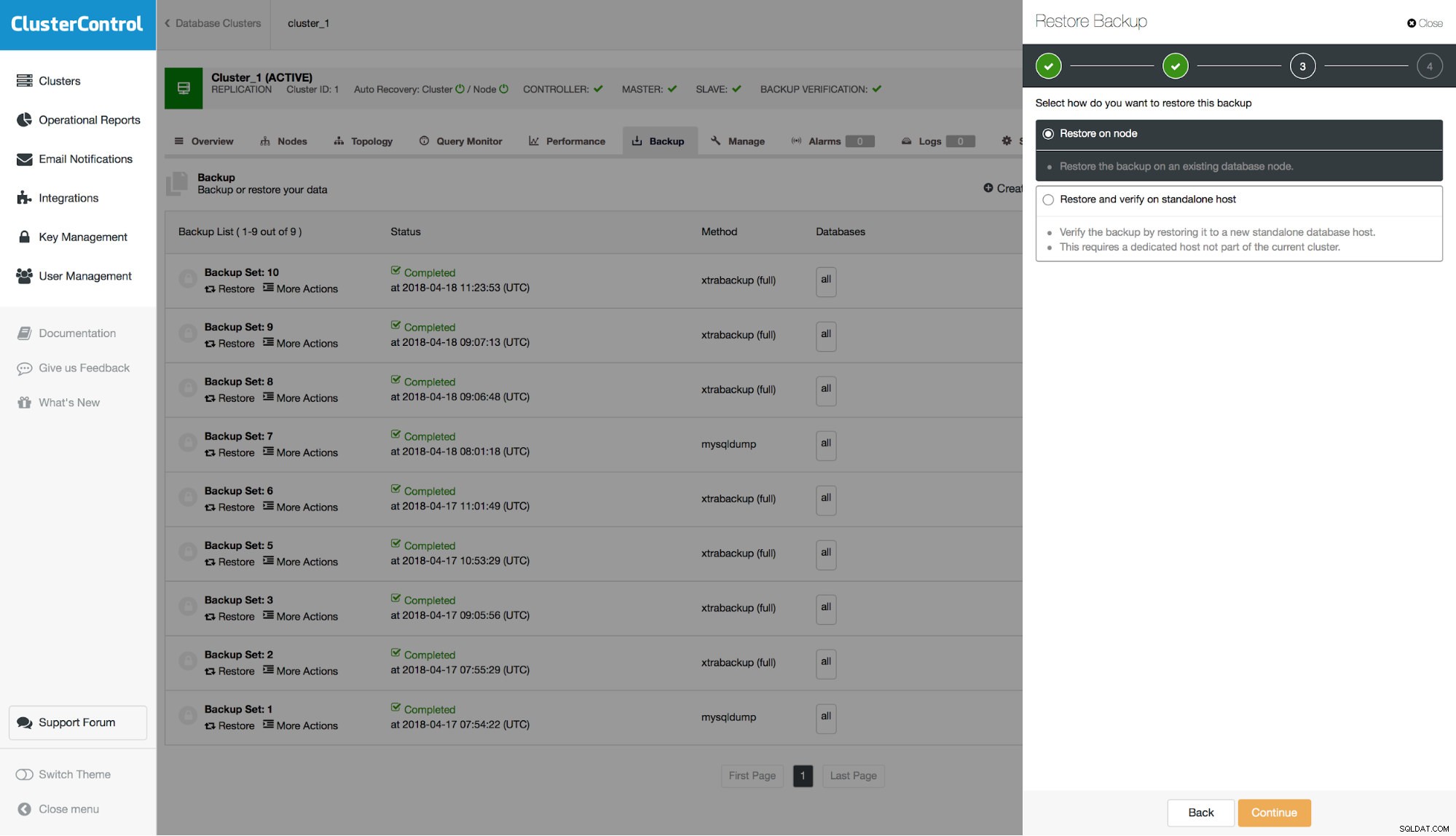
Tiếp theo, chúng ta phải quyết định xem chúng ta sẽ khôi phục bản sao lưu trên cụm hay chúng ta muốn sử dụng máy chủ bên ngoài để khôi phục nó. Tùy chọn thứ hai này có thể hữu ích nếu bạn chỉ muốn khôi phục một tập hợp con dữ liệu. Bạn có thể khôi phục bản sao lưu vật lý đầy đủ trên một máy chủ riêng biệt và sau đó sử dụng mysqldump để kết xuất dữ liệu bị thiếu và tải nó lên máy chủ sản xuất.
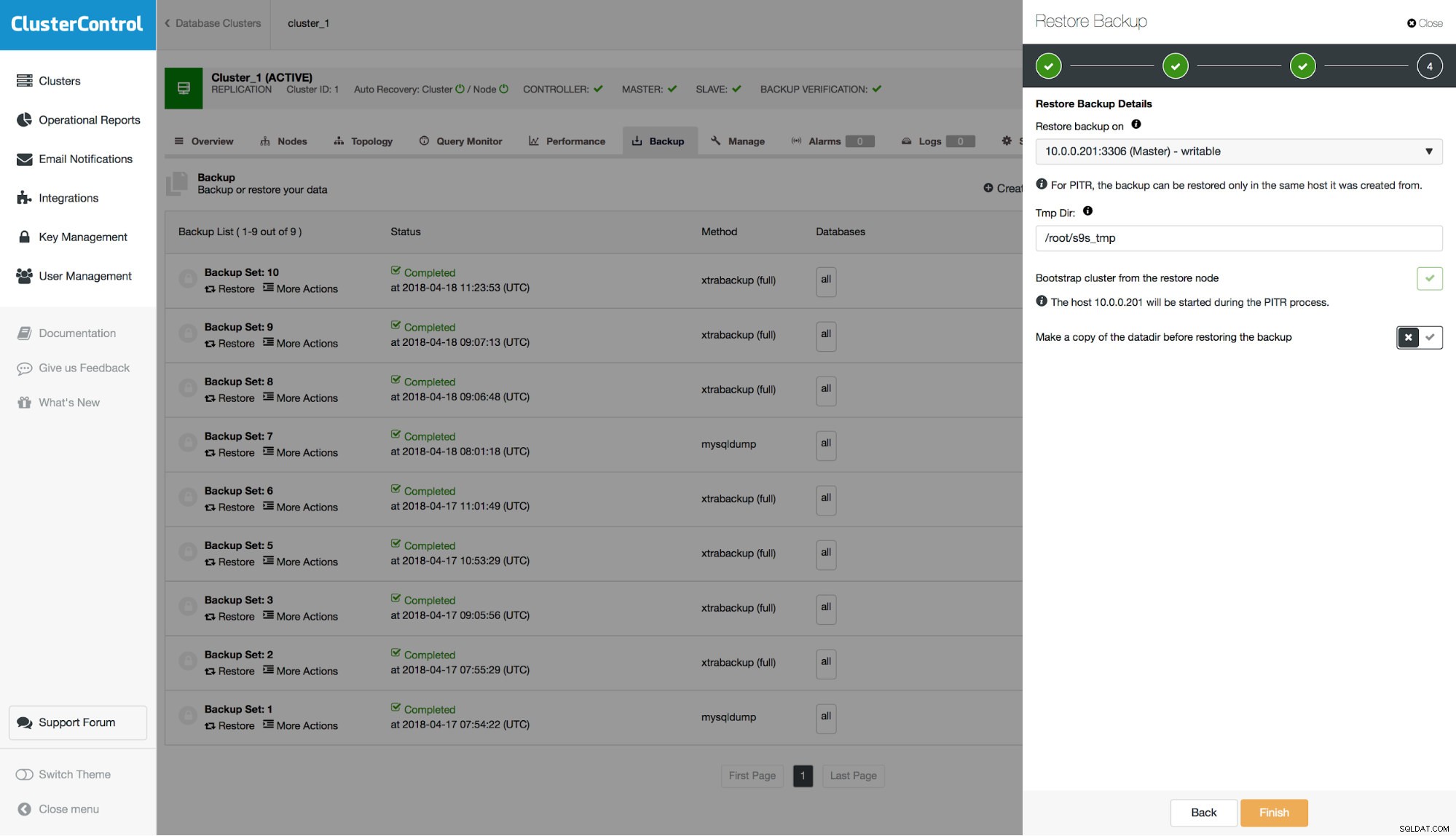
Hãy nhớ rằng khi bạn khôi phục bản sao lưu trên cụm của mình, bạn sẽ phải xây dựng lại các nút khác với nút bạn đã khôi phục. Trong kịch bản chủ - tớ, thông thường bạn sẽ muốn khôi phục bản sao lưu trên bản chính và sau đó xây dựng lại các nô lệ từ nó.
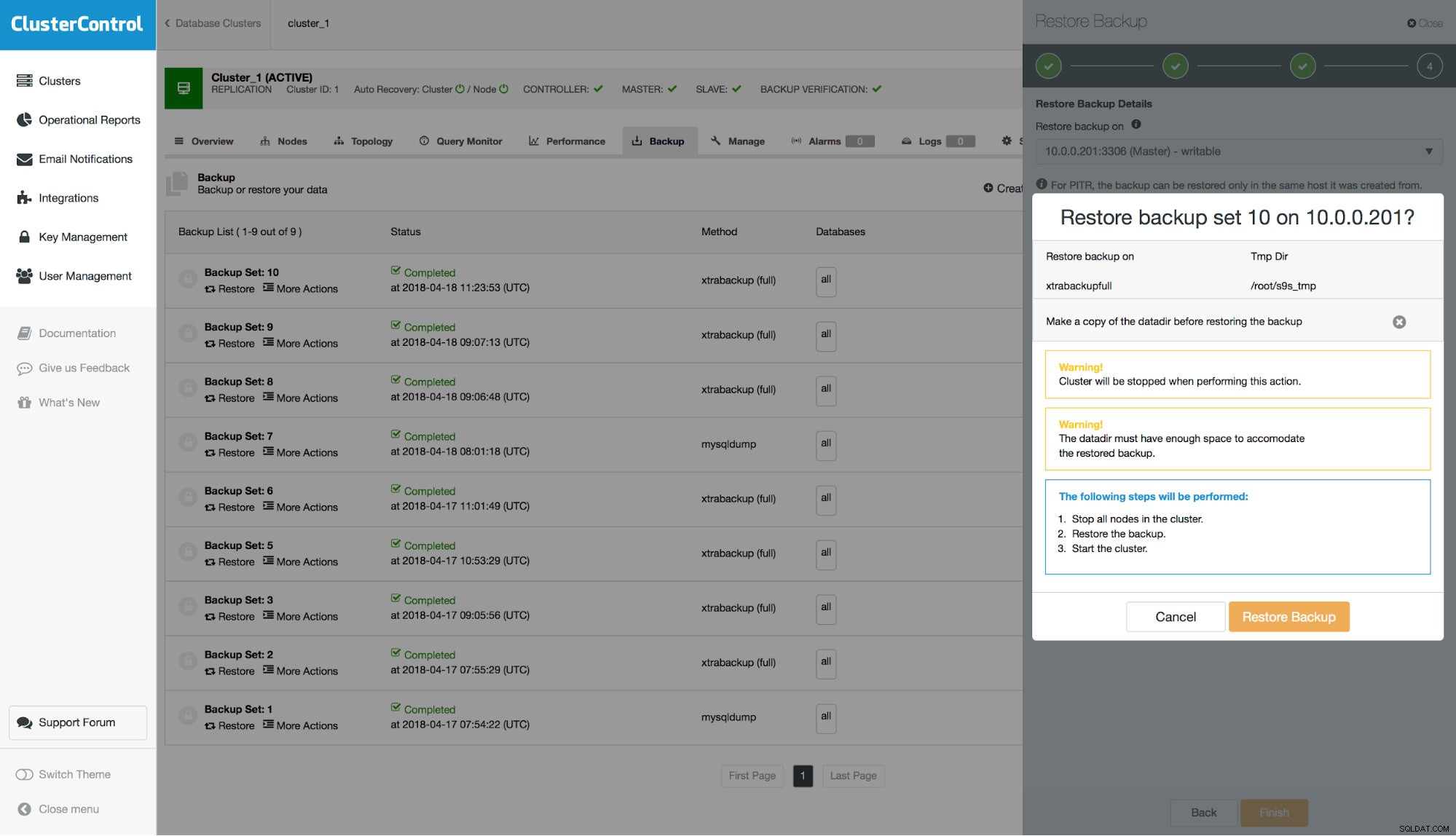
Bước cuối cùng, bạn sẽ thấy bản tóm tắt các hành động mà ClusterControl sẽ thực hiện.
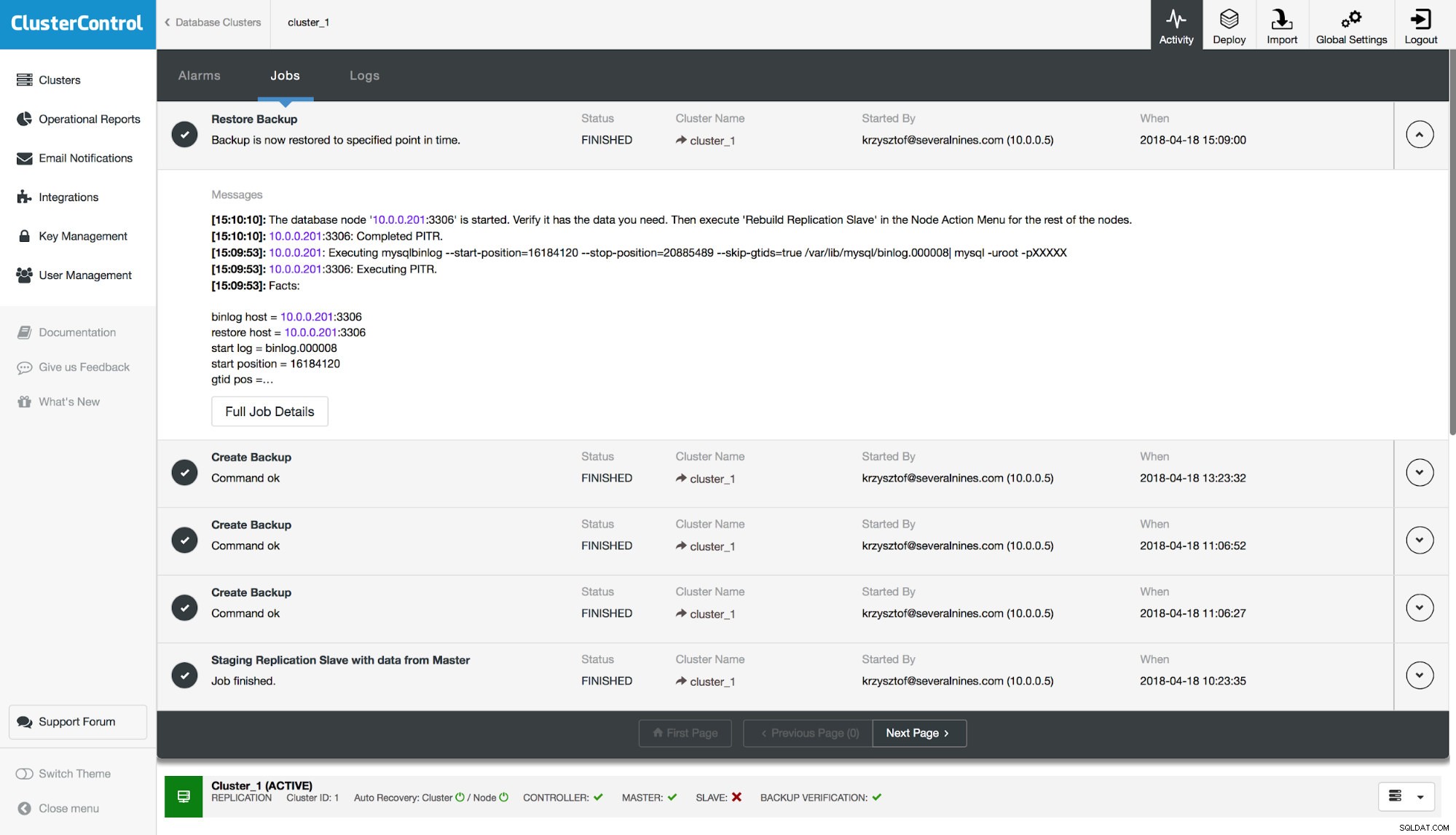
Cuối cùng, sau khi sao lưu được khôi phục, chúng tôi sẽ kiểm tra xem bảng bị thiếu đã được khôi phục hay chưa:
mysql> show tables from sbtest like 'sbtest1'\G
*************************** 1. row ***************************
Tables_in_sbtest (sbtest1): sbtest1
1 row in set (0.00 sec)Mọi thứ có vẻ ổn, chúng tôi đã quản lý để khôi phục dữ liệu bị thiếu.
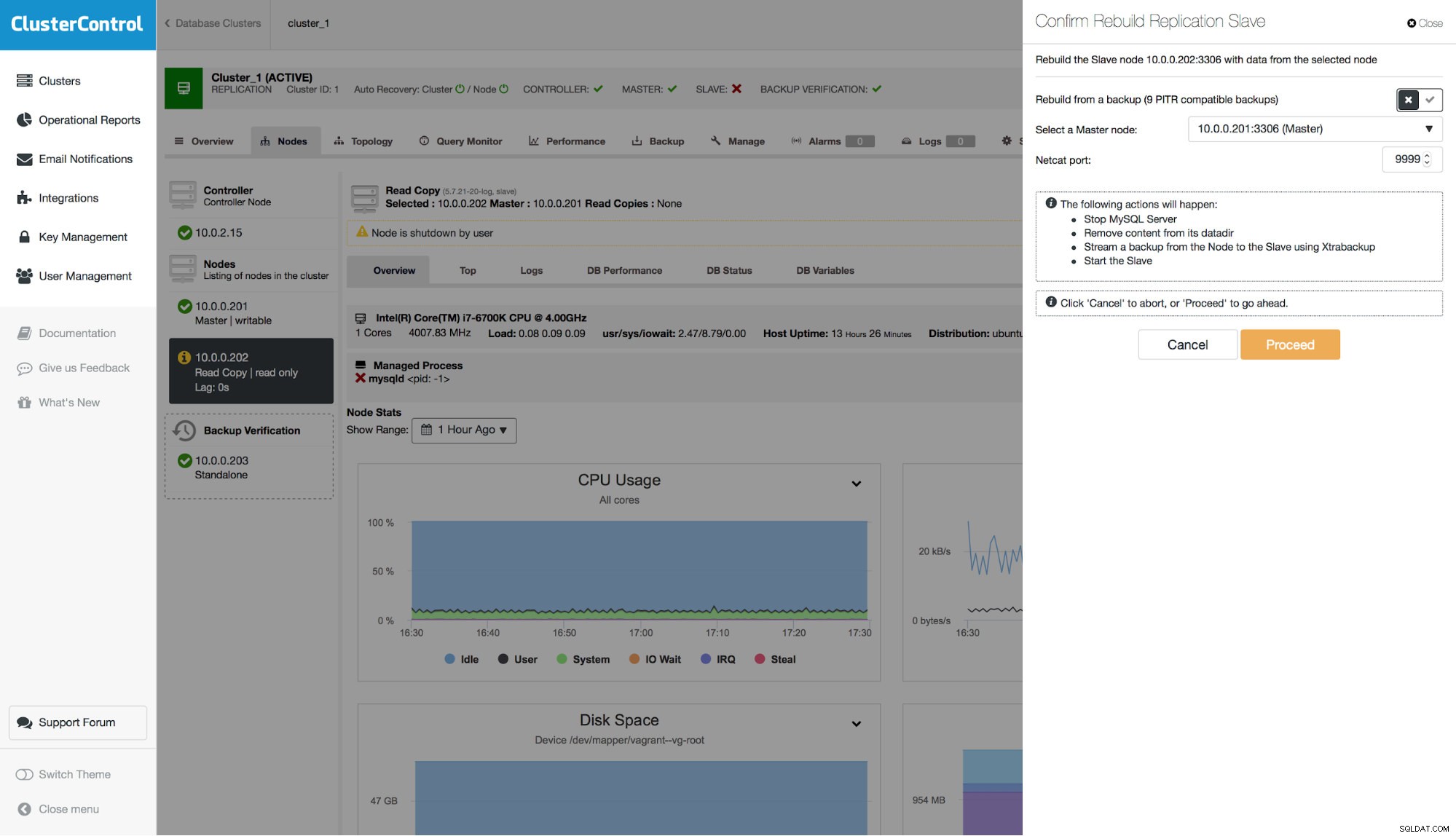
Bước cuối cùng chúng ta phải làm là xây dựng lại nô lệ của chúng ta. Xin lưu ý rằng có một tùy chọn để sử dụng bản sao lưu PITR. Trong ví dụ ở đây, điều này là không thể xảy ra vì máy chủ sẽ sao chép sự kiện DROP TABLE và nó sẽ không nhất quán với cái chính.