Tôi đã dành một tuần ở thành phố Lisbon tráng lệ để tham dự Hội nghị PostgeSQL hàng năm của Châu Âu. Điều này đánh dấu kỷ niệm 10 năm kể từ hội nghị PostgreSQL Châu Âu đầu tiên và lần thứ sáu tôi tham dự.
Ấn tượng đầu tiên
Thành phố thật tuyệt, bầu không khí tuyệt vời và có vẻ như đây sẽ là một tuần rất hiệu quả và nhiều thông tin với những cuộc trò chuyện thú vị với những người thông minh và thân thiện. Vì vậy, về cơ bản, điều thú vị đầu tiên tôi học được ở Lisbon là Lisbon và Bồ Đào Nha tuyệt vời như thế nào, nhưng tôi đoán bạn đã đến đây để xem phần còn lại của câu chuyện!


Bộ đệm được chia sẻ
Chúng tôi đã tham dự buổi đào tạo “Bộ công cụ PostgreSQL DBA cho hoạt động hàng ngày”
bởi Kaarel Moppel (Cybertec) . Một điều tôi lưu ý là cài đặt shared_buffers. Vì shared_buffers thực sự cạnh tranh hoặc bổ sung cho bộ nhớ cache của hệ thống, nó không nên được đặt thành bất kỳ giá trị nào trong khoảng từ 25% đến 75% tổng bộ nhớ RAM khả dụng. Vì vậy, mặc dù nói chung, cài đặt được khuyến nghị cho khối lượng công việc điển hình là 25% RAM, nó có thể được đặt thành> =75% cho các trường hợp đặc biệt, nhưng không phải ở giữa.
Những điều khác chúng tôi đã học được trong phiên này:
- rất tiếc, việc kích hoạt / kích hoạt tổng kiểm tra dữ liệu trực tuyến (hoặc ngoại tuyến) dễ dàng vẫn chưa có trong 11 (initdb / sao chép logic vẫn là lựa chọn duy nhất)
- hãy cẩn thận với vm.overcommit_memory, tốt hơn bạn nên tắt nó bằng cách đặt nó thành 2. Đặt vm.overcommit_ratio thành khoảng 80.
Tái tạo lôgic nâng cao

Trong bài nói chuyện của Petr Jelinek (Góc phần tư thứ 2) , các tác giả ban đầu của việc sao chép hợp lý, chúng tôi đã tìm hiểu về những cách sử dụng tiên tiến hơn của công nghệ thú vị mới này:
- Thu thập dữ liệu tập trung:chúng tôi có thể có nhiều nhà xuất bản và sau đó là một hệ thống trung tâm với người đăng ký cho mỗi nhà xuất bản đó, làm cho dữ liệu từ nhiều nguồn khác nhau có sẵn trong một hệ thống trung tâm. (cách sử dụng điển hình:OLAP)
- Dữ liệu toàn cầu được chia sẻ hay nói cách khác là hệ thống trung tâm để duy trì dữ liệu và thông số toàn cầu (chẳng hạn như tiền tệ, cổ phiếu, giá trị thị trường / hàng hóa, thời tiết, v.v.) xuất bản cho một hoặc nhiều người đăng ký. Sau đó, những dữ liệu này chỉ được duy trì trong một hệ thống nhưng có sẵn cho tất cả người đăng ký.
- Sao chép lôgic có thể không đồng bộ nhưng cũng đồng bộ (được đảm bảo khi cam kết)
- Khả năng mới với giải mã logic:
- tích hợp với Debezium / Kafka thông qua các plugin giải mã logic
- plugin wal2json
- Sao chép hai hướng
- Nâng cấp thời gian chết gần như bằng không:
- thiết lập bản sao lôgic trên máy chủ mới (có thể là initdb với việc bật tổng kiểm tra dữ liệu)
- đợi cho đến khi độ trễ tương đối nhỏ
- từ pgbouncer, hãy tạm dừng (các) cơ sở dữ liệu
- đợi cho đến khi độ trễ bằng 0
- thay đổi cấu hình pgbouncer để trỏ đến máy chủ mới, tải lại cấu hình của pgbouncer
- từ pgbouncer tiếp tục (các) cơ sở dữ liệu
Có gì mới trong PostgreSQL 11

Trong phần trình bày thú vị này, Magnus Hagander (Redpill Linpro AB) đã giới thiệu cho chúng tôi những điều kỳ diệu của PostgreSQL 11:
- pg_stat_statements hỗ trợ queryid 64-bit.
- pg_prewarm (một phương pháp để làm ấm bộ đệm của hệ thống hoặc bộ đệm được chia sẻ):bổ sung các thông số cấu hình mới
- Các vai trò mặc định mới giúp dễ dàng di chuyển khỏi các postgres (ý tôi là người dùng :))
- Các thủ tục được lưu trữ với kiểm soát giao dịch
- Tìm kiếm toàn văn bản nâng cao
- Sao chép lôgic hỗ trợ TRUNCATE
- Bản sao lưu cơ sở (pg_basebackup) xác thực tổng kiểm tra
- Một số cải tiến trong việc song song hóa các truy vấn
- Phân vùng thậm chí còn tinh vi hơn trong 10
- phân vùng mặc định
- cập nhật trên các phân vùng (di chuyển hàng từ phân vùng này sang phân vùng khác)
- chỉ mục phân vùng cục bộ
- khóa duy nhất trên tất cả các phân vùng (vẫn chưa thể tham chiếu được)
- phân vùng băm
- tham gia phân vùng khôn ngoan
- tổng hợp phân vùng khôn ngoan phân vùng
- có thể là các bảng ngoại trong các máy chủ nước ngoài khác nhau. Điều này mở ra khả năng tuyệt vời để phân loại hạt mịn hơn.
- Tổng hợp JIT
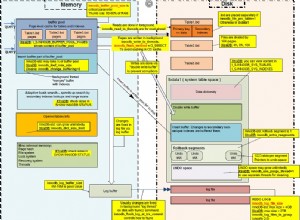
zheap:Một câu trả lời cho những tai họa Bloat của PostgreSQL
Điều này vẫn chưa có trong 11, nhưng nghe có vẻ hứa hẹn đến mức tôi phải đưa nó vào danh sách những thứ hay ho. Bài thuyết trình được đưa ra bởi Amit Kapila (EnterpriseDB) một trong những tác giả chính của công nghệ mới này nhằm mục đích cuối cùng được tích hợp vào lõi PostgreSQL như một loại heap thay thế. Điều này sẽ được tích hợp với API lưu trữ có thể cắm được mới trong PostgreSQL, sẽ hỗ trợ nhiều Phương thức truy cập bảng (theo cùng kiểu với các Phương thức truy cập [Chỉ mục] khác nhau được đề cập trong blog đầu tiên của tôi).
Điều này sẽ cố gắng giải quyết những thiếu sót kinh niên mà PostgreSQL mắc phải với:
- bàn bị phình ra
- cần (tự động) hút bụi
- có khả năng là một sự bao bọc id giao dịch
Tất cả những điều đó không phải là vấn đề đối với doanh nghiệp trung bình từ trung bình đến lớn (mặc dù điều này rất tương đối), chúng tôi biết các ngân hàng và tổ chức tài chính khác chạy PostgreSQL hàng chục TB dữ liệu và vài 1000 giao dịch / giây mà không có vấn đề gì. Bảng phình to được xử lý bằng autovacuum và đóng băng hàng giải quyết vấn đề bao quanh id giao dịch, nhưng điều này vẫn không phải là miễn phí bảo trì. Cộng đồng PostgreSQL hướng tới một cơ sở dữ liệu thực sự không cần bảo trì, do đó kiến trúc zheap được đề xuất. Điều này sẽ mang lại:
- nhật ký UNDO mới
- Nhật ký UNDO sẽ hiển thị dữ liệu đối với các giao dịch cũ bằng các phiên bản cũ
- UNDO sẽ được sử dụng để đảo ngược ảnh hưởng của các giao dịch bị hủy bỏ
- thay đổi xảy ra tại chỗ. Các phiên bản cũ không còn được lưu trong tệp dữ liệu.
Mục tiêu cấp cao:
- kiểm soát phồng rộp tốt hơn
- viết ít hơn
- tiêu đề bộ tuple nhỏ hơn
Điều này sẽ đưa PostgreSQL ngang bằng với MySql và Oracle về mặt này.
Truy vấn song song trong PostgreSQL:Làm thế nào để không (sai) Sử dụng nó?
Trong phần trình bày này của Amit Kapila và Rafia Sabih (EnterpriseDB), chúng ta đã học được các điểm bên trong của song song hóa và cả các mẹo để tránh các lỗi thường gặp cũng như một số cài đặt GUC được khuyến nghị:
- tính song song chỉ hỗ trợ các chỉ mục cây B
- max_parallel_workers_per_gather được đặt thành 1 → 4 (tùy thuộc vào lõi có sẵn)
- chú ý đến các cài đặt sau:
- song song_tuple_cost:chi phí chuyển một tuple từ một quy trình công nhân song song sang một quy trình khác
- llel_setup_cost:chi phí khởi chạy các nhân viên song song và khởi chạy bộ nhớ động được chia sẻ
- min_parallel_table_scan_size:kích thước tối thiểu của các quan hệ được xem xét để quét theo trình tự song song
- min_parallel_index_scan_size:kích thước chỉ mục tối thiểu được xem xét để quét song song
- random_page_cost:chi phí ước tính để truy cập một trang ngẫu nhiên trong đĩa