Blog này bắt đầu một loạt bài gồm nhiều tài liệu về hành trình của tôi trong việc đo điểm chuẩn cho PostgreSQL trên đám mây.
Phần đầu tiên bao gồm tổng quan về các công cụ đo điểm chuẩn và bắt đầu niềm vui với Amazon Aurora PostgreSQL.
Chọn nhà cung cấp dịch vụ đám mây PostgreSQL
Một lúc trước, tôi đã xem qua quy trình điểm chuẩn AWS cho Aurora và nghĩ rằng sẽ thực sự tuyệt vời nếu tôi có thể thực hiện bài kiểm tra đó và chạy nó trên các nhà cung cấp dịch vụ lưu trữ đám mây khác. Theo tín dụng của Amazon, trong số ba nhà cung cấp dịch vụ điện toán tiện ích nổi tiếng nhất - AWS, Google và Microsoft - AWS là người đóng góp chính duy nhất cho sự phát triển PostgreSQL và là người đầu tiên cung cấp dịch vụ PostgreSQL được quản lý (ra đời vào tháng 11 năm 2013).
Trong khi các dịch vụ PostgreSQL được quản lý cũng có sẵn từ rất nhiều Nhà cung cấp dịch vụ lưu trữ PostgreSQL, tôi muốn tập trung vào ba nhà cung cấp dịch vụ điện toán đám mây nói trên vì môi trường của họ là nơi mà nhiều tổ chức đang tìm kiếm lợi thế của điện toán đám mây chọn chạy các ứng dụng của họ, miễn là họ có bí quyết bắt buộc về quản lý PostgreSQL. Tôi tin chắc rằng trong bối cảnh CNTT ngày nay, các tổ chức làm việc với khối lượng công việc quan trọng trên đám mây sẽ được hưởng lợi rất nhiều từ các dịch vụ của một nhà cung cấp dịch vụ PostgreSQL chuyên biệt, có thể giúp họ điều hướng thế giới phức tạp của GUCS và vô số bản trình bày SlideShare.
Chọn Công cụ Điểm chuẩn Phù hợp
Đánh giá điểm chuẩn PostgreSQL xuất hiện khá thường xuyên trong danh sách gửi thư hiệu suất, và như được nhấn mạnh vô số lần, các bài kiểm tra không nhằm xác nhận cấu hình cho một ứng dụng đời thực. Tuy nhiên, việc lựa chọn công cụ và thông số điểm chuẩn phù hợp là rất quan trọng để thu thập các kết quả có ý nghĩa. Tôi mong đợi mọi nhà cung cấp dịch vụ đám mây cung cấp các quy trình để đánh giá điểm chuẩn dịch vụ của họ, đặc biệt là khi trải nghiệm đám mây đầu tiên có thể không bắt đầu tốt. Tin tốt là hai trong số ba người chơi trong bài kiểm tra này, đã bao gồm các điểm chuẩn trong tài liệu của họ. Hướng dẫn về Quy trình Điểm chuẩn AWS cho Aurora rất dễ tìm, có sẵn ngay trên trang Amazon Aurora Resources. Google không cung cấp hướng dẫn cụ thể cho PostgreSQL, tuy nhiên, tài liệu Compute Engine chứa hướng dẫn kiểm tra tải cho SQL Server dựa trên HammerDB.
Sau đây là tóm tắt về các công cụ điểm chuẩn dựa trên tài liệu tham khảo của chúng đáng được xem xét:
- Điểm chuẩn AWS được đề cập ở trên dựa trên pgbench và sysbench.
- HammerDB, cũng đã được đề cập trước đó, được thảo luận trong một bài đăng gần đây về danh sách tin tặc pgsql.
- Các bài kiểm tra TPC-C dựa trên oltpbench như được đề cập trong cuộc thảo luận pgsql-hacker khác này.
- benchmarkql là một thử nghiệm TPC-C khác đã được sử dụng để xác thực các thay đổi đối với việc phân chia trang B-Tree.
- pg_ycsb là một đứa trẻ mới trong thị trấn, đang cải tiến trên pgbench và đã được một số tin tặc PostgreSQL sử dụng.
- pgbench-tools như tên cho thấy, dựa trên pgbench và mặc dù không nhận được bất kỳ bản cập nhật nào kể từ năm 2016, nhưng nó là sản phẩm của Greg Smith, tác giả của sách Hiệu suất cao PostgreSQL.
- điểm chuẩn của đơn đặt hàng tham gia là điểm chuẩn sẽ kiểm tra trình tối ưu hóa truy vấn.
- pgreplay mà tôi đã xem khi đọc blog Command Prompt gần giống như nó có thể lấy điểm chuẩn cho một tình huống thực tế.
Một điểm khác cần lưu ý là PostgreSQL vẫn chưa phù hợp với tiêu chuẩn điểm chuẩn TPC-H và như đã lưu ý ở trên, tất cả các công cụ (ngoại trừ pgreplay) phải chạy ở chế độ TPC-C (pgbench được đặt mặc định).
Đối với mục đích của blog này, tôi nghĩ rằng Quy trình điểm chuẩn AWS cho Aurora là một khởi đầu tốt đơn giản vì nó đặt ra tiêu chuẩn cho các nhà cung cấp đám mây và dựa trên các công cụ được sử dụng rộng rãi.
Ngoài ra, tôi đã sử dụng phiên bản PostgreSQL mới nhất có sẵn vào thời điểm đó. Khi lựa chọn nhà cung cấp dịch vụ đám mây, điều quan trọng là phải xem xét tần suất nâng cấp, đặc biệt khi các tính năng quan trọng được giới thiệu bởi phiên bản mới có thể ảnh hưởng đến hiệu suất (trường hợp của phiên bản 10 và 11 so với 9). Khi viết bài này, chúng tôi có:
- Amazon Aurora PostgreSQL 10.6
- Amazon RDS cho PostgreSQL 10.6
- Google Cloud SQL dành cho PostgreSQL 9.6
- Microsoft Azure PostgreSQL 10.5
... và người chiến thắng ở đây là AWS bằng cách cung cấp phiên bản mới nhất (mặc dù nó không phải là phiên bản mới nhất, tính đến thời điểm này là 11.2).
Thiết lập Môi trường đo điểm chuẩn
Tôi quyết định giới hạn các thử nghiệm của mình ở mức khối lượng công việc trung bình vì một số lý do:Thứ nhất, các tài nguyên đám mây có sẵn không giống nhau giữa các nhà cung cấp. Trong hướng dẫn, các thông số kỹ thuật AWS cho phiên bản cơ sở dữ liệu là 64 vCPU / 488 GiB RAM / 25 Gigabit Network, trong khi RAM tối đa của Google cho bất kỳ kích thước phiên bản nào (lựa chọn phải được đặt thành "tùy chỉnh" trong Google Máy tính) là 208 GiB, và Business Critical Gen5 của Microsoft với 32 vCPU chỉ có 163 GiB). Thứ hai, việc khởi tạo pgbench đưa kích thước cơ sở dữ liệu lên 160GiB, trong trường hợp một phiên bản có RAM 488 GiB có khả năng sẽ được lưu trong bộ nhớ.
Ngoài ra, tôi vẫn để nguyên cấu hình PostgreSQL. Lý do cho việc tuân theo các giá trị mặc định của nhà cung cấp dịch vụ đám mây là vì ngoài khả năng, khi bị điểm chuẩn tiêu chuẩn nhấn mạnh, một dịch vụ được quản lý được kỳ vọng sẽ hoạt động tốt một cách hợp lý. Hãy nhớ rằng cộng đồng PostgreSQL chạy các bài kiểm tra pgbench như một phần của quá trình quản lý phát hành. Ngoài ra, hướng dẫn AWS không đề cập đến bất kỳ thay đổi nào đối với cấu hình PostgreSQL mặc định.
Như đã giải thích trong hướng dẫn, AWS đã áp dụng hai bản vá cho pgbench. Vì bản vá cho số lượng khách hàng không được áp dụng rõ ràng trên phiên bản 10.6 của PostgreSQL và tôi không muốn đầu tư thời gian để sửa nó, nên số lượng khách hàng được giới hạn ở mức tối đa 1.000.
Hướng dẫn chỉ định yêu cầu đối với phiên bản máy khách để kích hoạt mạng nâng cao - đối với phiên bản này, loại phiên bản này là mặc định:
[example@sqldat.com ~]$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc mq state UP group default qlen 1000
link/ether 0a:cd:ee:40:2b:e6 brd ff:ff:ff:ff:ff:ff
inet 172.31.19.190/20 brd 172.31.31.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::8cd:eeff:fe40:2be6/64 scope link
valid_lft forever preferred_lft forever
[example@sqldat.com ~]$ ethtool -i eth0
driver: ena
version: 2.0.2g
firmware-version:
bus-info: 0000:00:03.0
supports-statistics: yes
supports-test: no
supports-eeprom-access: no
supports-register-dump: no
supports-priv-flags: no
>>> aws (master *%) ~ $ aws ec2 describe-instances --instance-ids i-0ee51642334c1ec57 --query "Reservations[].Instances[].EnaSupport"
[
true
]Chạy Điểm chuẩn trên Amazon Aurora PostgreSQL
Trong quá trình chạy thực tế, tôi quyết định thực hiện một sai lệch nữa so với hướng dẫn:thay vì chạy thử nghiệm trong 1 giờ, hãy đặt giới hạn thời gian thành 10 phút, thông thường được chấp nhận là một giá trị tốt.
Chạy # 1
Chi tiết cụ thể
- Thử nghiệm này sử dụng các thông số kỹ thuật AWS cho cả kích thước phiên bản máy khách và cơ sở dữ liệu.
- Máy khách:Phiên bản EC2 được tối ưu hóa bộ nhớ theo yêu cầu:
- vCPU:32 (16 Cores x 2 Threads / Core)
- RAM:244 GiB
- Bộ nhớ:Tối ưu hóa EBS
- Mạng:10 Gigabit
- Cụm DB:db.r4.16xlarge
- vCPU:64
- ECU (dung lượng CPU):195 x [1,0-1,2 GHz] 2007 Opteron / Xeon
- RAM:488 GiB
- Bộ nhớ:Tối ưu hóa EBS (Dung lượng dành riêng cho I / O)
- Mạng:Băng thông tối đa 14.000 Mbps trên mạng 25 Gps
- Máy khách:Phiên bản EC2 được tối ưu hóa bộ nhớ theo yêu cầu:
- Thiết lập cơ sở dữ liệu bao gồm một bản sao.
- Bộ nhớ cơ sở dữ liệu không được mã hóa.
Thực hiện các thử nghiệm và kết quả
- Làm theo hướng dẫn trong hướng dẫn để cài đặt pgbench và sysbench.
- Chỉnh sửa ~ / .bashrc để đặt các biến môi trường cho kết nối cơ sở dữ liệu và các đường dẫn bắt buộc đến các thư viện PostgreSQL:
export PGHOST=aurora.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com export PGUSER=postgres export PGPASSWORD=postgres export PGDATABASE=postgres export PATH=$PATH:/usr/local/pgsql/bin export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/lib - Khởi tạo cơ sở dữ liệu:
[example@sqldat.com ~]# pgbench -i --fillfactor=90 --scale=10000 NOTICE: table "pgbench_history" does not exist, skipping NOTICE: table "pgbench_tellers" does not exist, skipping NOTICE: table "pgbench_accounts" does not exist, skipping NOTICE: table "pgbench_branches" does not exist, skipping creating tables... 100000 of 1000000000 tuples (0%) done (elapsed 0.05 s, remaining 457.23 s) 200000 of 1000000000 tuples (0%) done (elapsed 0.13 s, remaining 631.70 s) 300000 of 1000000000 tuples (0%) done (elapsed 0.21 s, remaining 688.29 s) ... 999500000 of 1000000000 tuples (99%) done (elapsed 811.41 s, remaining 0.41 s) 999600000 of 1000000000 tuples (99%) done (elapsed 811.50 s, remaining 0.32 s) 999700000 of 1000000000 tuples (99%) done (elapsed 811.58 s, remaining 0.24 s) 999800000 of 1000000000 tuples (99%) done (elapsed 811.65 s, remaining 0.16 s) 999900000 of 1000000000 tuples (99%) done (elapsed 811.73 s, remaining 0.08 s) 1000000000 of 1000000000 tuples (100%) done (elapsed 811.80 s, remaining 0.00 s) vacuum... set primary keys... done. - Xác minh kích thước cơ sở dữ liệu:
postgres=> \l+ postgres List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description ----------+----------+----------+-------------+-------------+-------------------+--------+------------+-------------------------------------------- postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 160 GB | pg_default | default administrative connection database (1 row) - Sử dụng truy vấn sau để xác minh rằng khoảng thời gian giữa các điểm kiểm tra được đặt để các điểm kiểm tra sẽ bị bắt buộc trong 10 phút chạy:
Kết quả:SELECT total_checkpoints, seconds_since_start / total_checkpoints / 60 AS minutes_between_checkpoints FROM ( SELECT EXTRACT( EPOCH FROM ( now() - pg_postmaster_start_time() ) ) AS seconds_since_start, (checkpoints_timed+checkpoints_req) AS total_checkpoints FROM pg_stat_bgwriter) AS sub;postgres=> \e total_checkpoints | minutes_between_checkpoints -------------------+----------------------------- 50 | 0.977392292333333 (1 row) - Chạy khối lượng công việc Đọc / Ghi:
Đầu ra[example@sqldat.com ~]# pgbench --protocol=prepared -P 60 --time=600 --client=1000 --jobs=2048starting vacuum...end. progress: 60.0 s, 35670.3 tps, lat 27.243 ms stddev 10.915 progress: 120.0 s, 36569.5 tps, lat 27.352 ms stddev 11.859 progress: 180.0 s, 35845.2 tps, lat 27.896 ms stddev 12.785 progress: 240.0 s, 36613.7 tps, lat 27.310 ms stddev 11.804 progress: 300.0 s, 37323.4 tps, lat 26.793 ms stddev 11.376 progress: 360.0 s, 36828.8 tps, lat 27.155 ms stddev 11.318 progress: 420.0 s, 36670.7 tps, lat 27.268 ms stddev 12.083 progress: 480.0 s, 37176.1 tps, lat 26.899 ms stddev 10.981 progress: 540.0 s, 37210.8 tps, lat 26.875 ms stddev 11.341 progress: 600.0 s, 37415.4 tps, lat 26.727 ms stddev 11.521 transaction type: <builtin: TPC-B (sort of)> scaling factor: 10000 query mode: prepared number of clients: 1000 number of threads: 1000 duration: 600 s number of transactions actually processed: 22040445 latency average = 27.149 ms latency stddev = 11.617 ms tps = 36710.828624 (including connections establishing) tps = 36811.054851 (excluding connections establishing) - Chuẩn bị kiểm tra sysbench:
Đầu ra:sysbench --test=/usr/local/share/sysbench/oltp.lua \ --pgsql-host=aurora.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com \ --pgsql-db=postgres \ --pgsql-user=postgres \ --pgsql-password=postgres \ --pgsql-port=5432 \ --oltp-tables-count=250\ --oltp-table-size=450000 \ preparesysbench 0.5: multi-threaded system evaluation benchmark Creating table 'sbtest1'... Inserting 450000 records into 'sbtest1' Creating secondary indexes on 'sbtest1'... Creating table 'sbtest2'... ... Creating table 'sbtest250'... Inserting 450000 records into 'sbtest250' Creating secondary indexes on 'sbtest250'... - Chạy kiểm tra sysbench:
Đầu ra:sysbench --test=/usr/local/share/sysbench/oltp.lua \ --pgsql-host=aurora.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com \ --pgsql-db=postgres \ --pgsql-user=postgres \ --pgsql-password=postgres \ --pgsql-port=5432 \ --oltp-tables-count=250 \ --oltp-table-size=450000 \ --max-requests=0 \ --forced-shutdown \ --report-interval=60 \ --oltp_simple_ranges=0 \ --oltp-distinct-ranges=0 \ --oltp-sum-ranges=0 \ --oltp-order-ranges=0 \ --oltp-point-selects=0 \ --rand-type=uniform \ --max-time=600 \ --num-threads=1000 \ runsysbench 0.5: multi-threaded system evaluation benchmark Running the test with following options: Number of threads: 1000 Report intermediate results every 60 second(s) Random number generator seed is 0 and will be ignored Forcing shutdown in 630 seconds Initializing worker threads... Threads started! [ 60s] threads: 1000, tps: 20443.09, reads: 0.00, writes: 81834.16, response time: 68.24ms (95%), errors: 0.62, reconnects: 0.00 [ 120s] threads: 1000, tps: 20580.68, reads: 0.00, writes: 82324.33, response time: 70.75ms (95%), errors: 0.73, reconnects: 0.00 [ 180s] threads: 1000, tps: 20531.85, reads: 0.00, writes: 82127.21, response time: 70.63ms (95%), errors: 0.73, reconnects: 0.00 [ 240s] threads: 1000, tps: 20212.67, reads: 0.00, writes: 80861.67, response time: 71.99ms (95%), errors: 0.43, reconnects: 0.00 [ 300s] threads: 1000, tps: 19383.90, reads: 0.00, writes: 77537.87, response time: 75.64ms (95%), errors: 0.75, reconnects: 0.00 [ 360s] threads: 1000, tps: 19797.20, reads: 0.00, writes: 79190.78, response time: 75.27ms (95%), errors: 0.68, reconnects: 0.00 [ 420s] threads: 1000, tps: 20304.43, reads: 0.00, writes: 81212.87, response time: 73.82ms (95%), errors: 0.70, reconnects: 0.00 [ 480s] threads: 1000, tps: 20933.80, reads: 0.00, writes: 83737.16, response time: 74.71ms (95%), errors: 0.68, reconnects: 0.00 [ 540s] threads: 1000, tps: 20663.05, reads: 0.00, writes: 82626.42, response time: 73.56ms (95%), errors: 0.75, reconnects: 0.00 [ 600s] threads: 1000, tps: 20746.02, reads: 0.00, writes: 83015.81, response time: 73.58ms (95%), errors: 0.78, reconnects: 0.00 OLTP test statistics: queries performed: read: 0 write: 48868458 other: 24434022 total: 73302480 transactions: 12216804 (20359.59 per sec.) read/write requests: 48868458 (81440.43 per sec.) other operations: 24434022 (40719.87 per sec.) ignored errors: 414 (0.69 per sec.) reconnects: 0 (0.00 per sec.) General statistics: total time: 600.0516s total number of events: 12216804 total time taken by event execution: 599964.4735s response time: min: 6.27ms avg: 49.11ms max: 350.24ms approx. 95 percentile: 72.90ms Threads fairness: events (avg/stddev): 12216.8040/31.27 execution time (avg/stddev): 599.9645/0.01
Số liệu được Thu thập
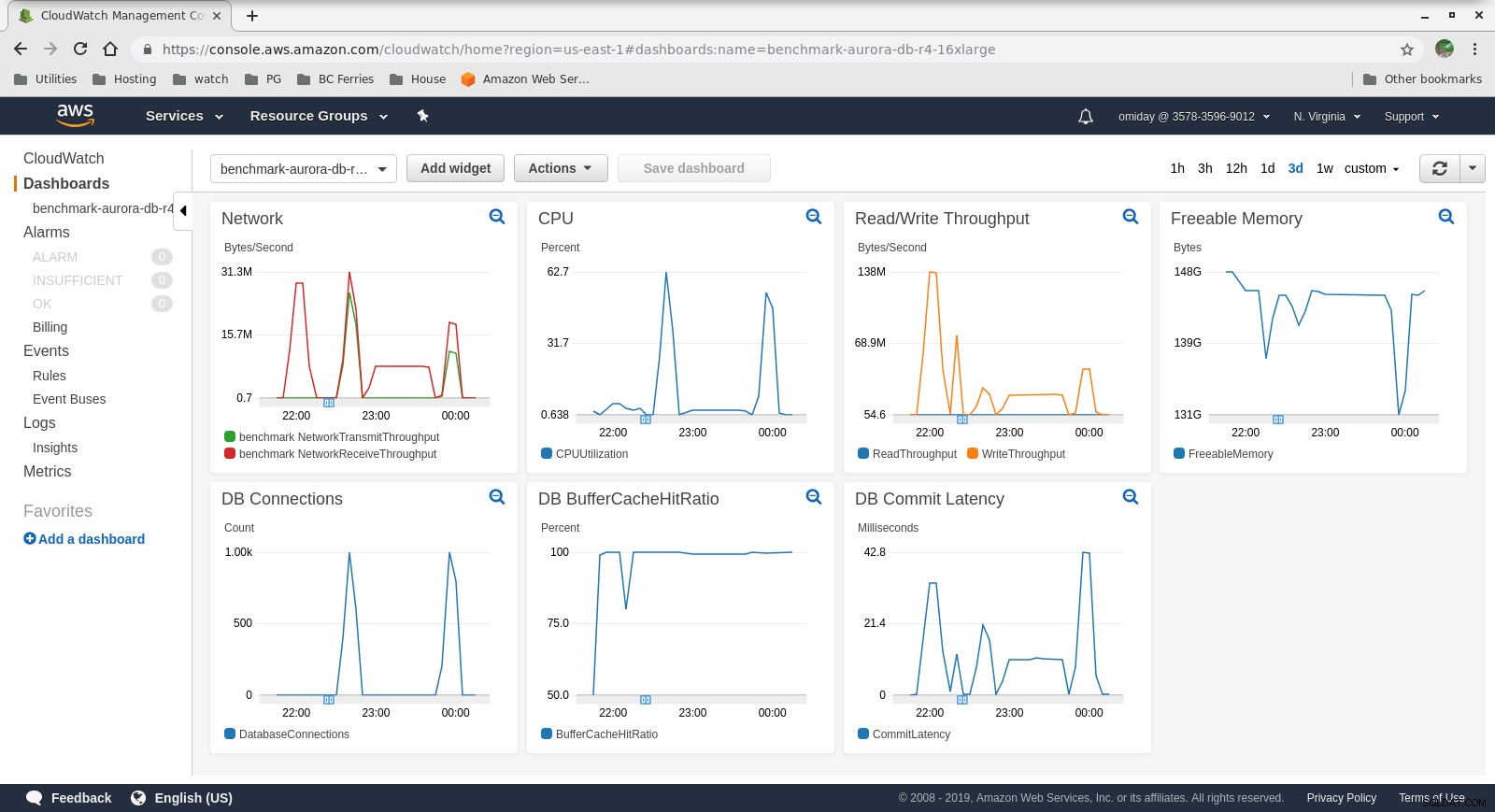 Số liệu Cloudwatch
Số liệu Cloudwatch 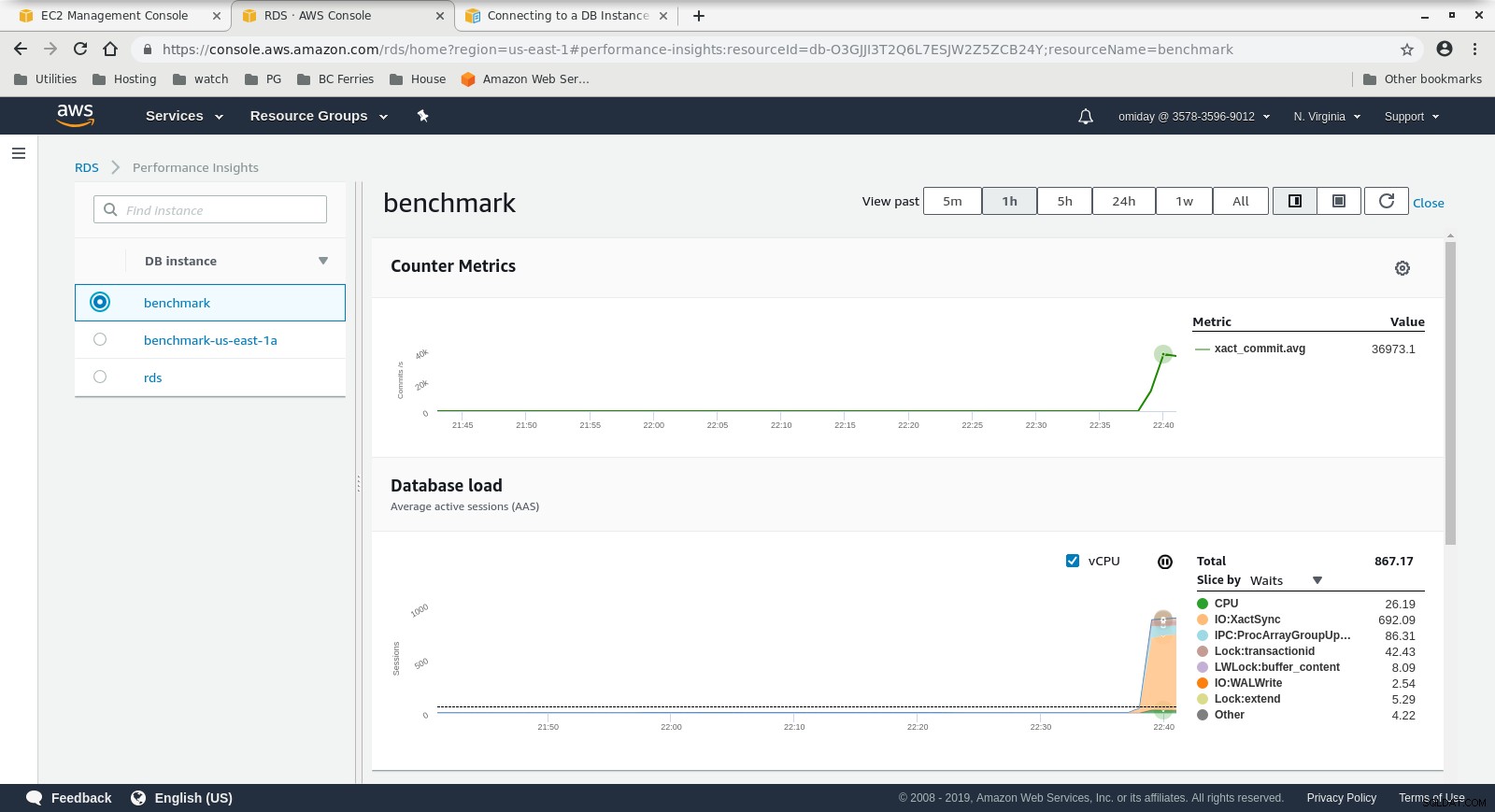 Chỉ số thông tin chi tiết về hiệu suấtTải xuống báo cáo chính thức về Quản lý &tự động hóa PostgreSQL hôm nay với ClusterControlTìm hiểu về những điều bạn cần biết để triển khai, giám sát, quản lý và mở rộng quy mô PostgreSQLTải xuống báo cáo chính thức
Chỉ số thông tin chi tiết về hiệu suấtTải xuống báo cáo chính thức về Quản lý &tự động hóa PostgreSQL hôm nay với ClusterControlTìm hiểu về những điều bạn cần biết để triển khai, giám sát, quản lý và mở rộng quy mô PostgreSQLTải xuống báo cáo chính thức Chạy # 2
Chi tiết cụ thể
- Thử nghiệm này sử dụng các thông số kỹ thuật AWS cho máy khách và kích thước phiên bản nhỏ hơn cho cơ sở dữ liệu:
- Máy khách:Phiên bản EC2 được tối ưu hóa bộ nhớ theo yêu cầu:
- vCPU:32 (16 Cores x 2 Threads / Core)
- RAM:244 GiB
- Bộ nhớ:Tối ưu hóa EBS
- Mạng:10 Gigabit
- Cụm DB:db.r4.2xlarge:
- vCPU:8
- RAM:61GiB
- Bộ nhớ:Tối ưu hóa EBS
- Mạng:Băng thông tối đa 1.750 Mbps trên kết nối tối đa 10 Gbps
- Máy khách:Phiên bản EC2 được tối ưu hóa bộ nhớ theo yêu cầu:
- Cơ sở dữ liệu không bao gồm một bản sao.
- Bộ nhớ cơ sở dữ liệu không được mã hóa.
Thực hiện các thử nghiệm và kết quả
Các bước này giống với Run # 1 nên tôi chỉ hiển thị đầu ra:
-
pgbench Khối lượng công việc Đọc / Ghi:
... 745700000 of 1000000000 tuples (74%) done (elapsed 794.93 s, remaining 271.09 s) 745800000 of 1000000000 tuples (74%) done (elapsed 795.00 s, remaining 270.97 s) 745900000 of 1000000000 tuples (74%) done (elapsed 795.09 s, remaining 270.86 s) 746000000 of 1000000000 tuples (74%) done (elapsed 795.17 s, remaining 270.74 s) 746100000 of 1000000000 tuples (74%) done (elapsed 795.24 s, remaining 270.62 s) 746200000 of 1000000000 tuples (74%) done (elapsed 795.33 s, remaining 270.51 s) ... 999800000 of 1000000000 tuples (99%) done (elapsed 1067.11 s, remaining 0.21 s) 999900000 of 1000000000 tuples (99%) done (elapsed 1067.19 s, remaining 0.11 s) 1000000000 of 1000000000 tuples (100%) done (elapsed 1067.28 s, remaining 0.00 s) vacuum... set primary keys... total time: 4386.44 s (insert 1067.33 s, commit 0.46 s, vacuum 2088.25 s, index 1230.41 s) done.starting vacuum...end. progress: 60.0 s, 3361.3 tps, lat 286.143 ms stddev 80.417 progress: 120.0 s, 3466.8 tps, lat 288.386 ms stddev 76.373 progress: 180.0 s, 3683.1 tps, lat 271.840 ms stddev 75.712 progress: 240.0 s, 3444.3 tps, lat 289.909 ms stddev 69.564 progress: 300.0 s, 3475.8 tps, lat 287.736 ms stddev 73.712 progress: 360.0 s, 3449.5 tps, lat 289.832 ms stddev 71.878 progress: 420.0 s, 3518.1 tps, lat 284.432 ms stddev 74.276 progress: 480.0 s, 3430.7 tps, lat 291.359 ms stddev 73.264 progress: 540.0 s, 3515.7 tps, lat 284.522 ms stddev 73.206 progress: 600.0 s, 3482.9 tps, lat 287.037 ms stddev 71.649 transaction type: <builtin: TPC-B (sort of)> scaling factor: 10000 query mode: prepared number of clients: 1000 number of threads: 1000 duration: 600 s number of transactions actually processed: 2090702 latency average = 286.030 ms latency stddev = 74.245 ms tps = 3481.731730 (including connections establishing) tps = 3494.157830 (excluding connections establishing) -
kiểm tra sysbench:
sysbench 0.5: multi-threaded system evaluation benchmark Running the test with following options: Number of threads: 1000 Report intermediate results every 60 second(s) Random number generator seed is 0 and will be ignored Forcing shutdown in 630 seconds Initializing worker threads... Threads started! [ 60s] threads: 1000, tps: 4809.05, reads: 0.00, writes: 19301.02, response time: 288.03ms (95%), errors: 0.05, reconnects: 0.00 [ 120s] threads: 1000, tps: 5264.15, reads: 0.00, writes: 21005.40, response time: 255.23ms (95%), errors: 0.08, reconnects: 0.00 [ 180s] threads: 1000, tps: 5178.27, reads: 0.00, writes: 20713.07, response time: 260.40ms (95%), errors: 0.03, reconnects: 0.00 [ 240s] threads: 1000, tps: 5145.95, reads: 0.00, writes: 20610.08, response time: 255.76ms (95%), errors: 0.05, reconnects: 0.00 [ 300s] threads: 1000, tps: 5127.92, reads: 0.00, writes: 20507.98, response time: 264.24ms (95%), errors: 0.05, reconnects: 0.00 [ 360s] threads: 1000, tps: 5063.83, reads: 0.00, writes: 20278.10, response time: 268.55ms (95%), errors: 0.05, reconnects: 0.00 [ 420s] threads: 1000, tps: 5057.51, reads: 0.00, writes: 20237.28, response time: 269.19ms (95%), errors: 0.10, reconnects: 0.00 [ 480s] threads: 1000, tps: 5036.32, reads: 0.00, writes: 20139.29, response time: 279.62ms (95%), errors: 0.10, reconnects: 0.00 [ 540s] threads: 1000, tps: 5115.25, reads: 0.00, writes: 20459.05, response time: 264.64ms (95%), errors: 0.08, reconnects: 0.00 [ 600s] threads: 1000, tps: 5124.89, reads: 0.00, writes: 20510.07, response time: 265.43ms (95%), errors: 0.10, reconnects: 0.00 OLTP test statistics: queries performed: read: 0 write: 12225686 other: 6112822 total: 18338508 transactions: 3056390 (5093.75 per sec.) read/write requests: 12225686 (20375.20 per sec.) other operations: 6112822 (10187.57 per sec.) ignored errors: 42 (0.07 per sec.) reconnects: 0 (0.00 per sec.) General statistics: total time: 600.0277s total number of events: 3056390 total time taken by event execution: 600005.2104s response time: min: 9.57ms avg: 196.31ms max: 608.70ms approx. 95 percentile: 268.71ms Threads fairness: events (avg/stddev): 3056.3900/67.44 execution time (avg/stddev): 600.0052/0.01
Số liệu được Thu thập
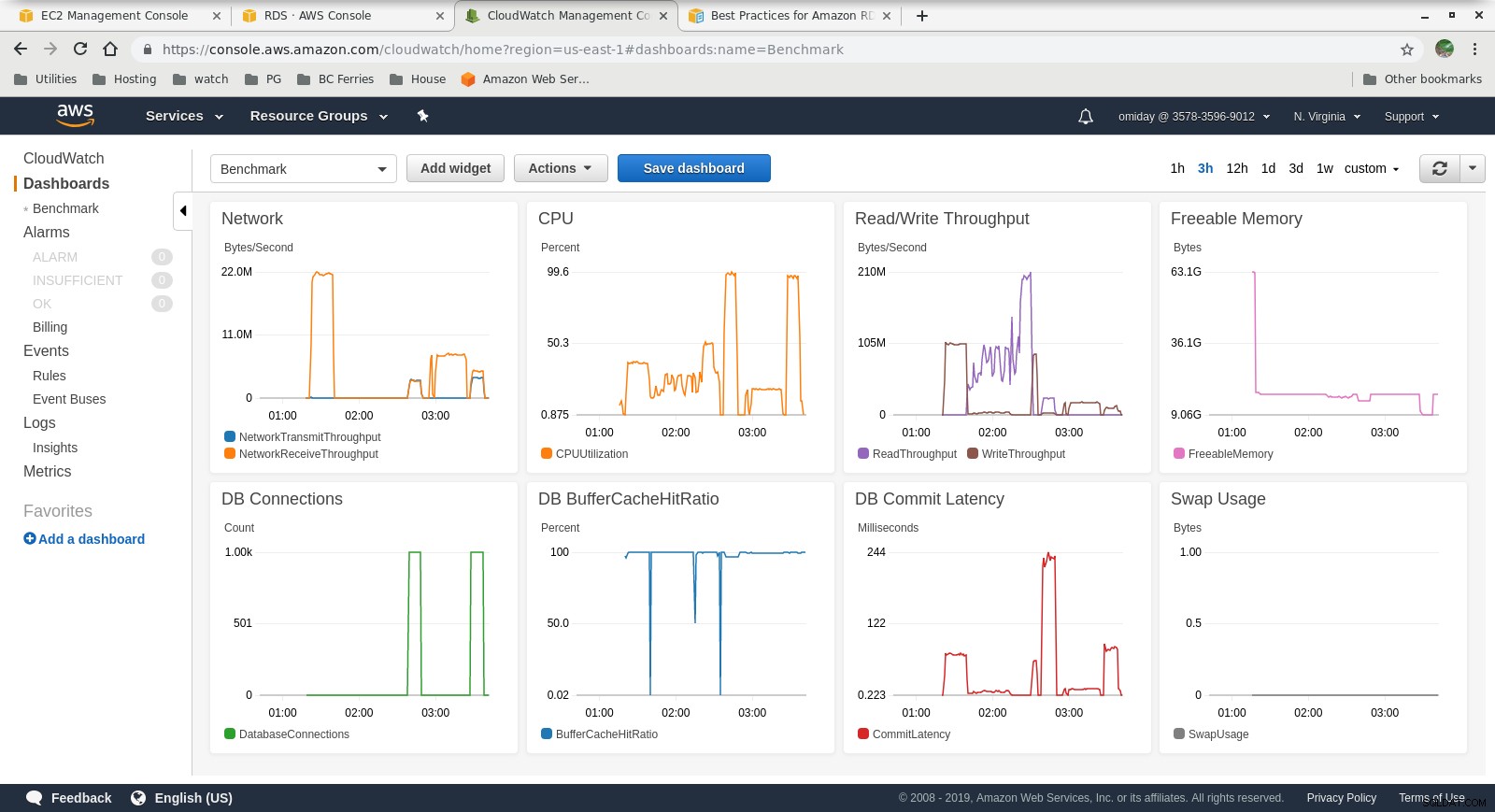 Số liệu Cloudwatch
Số liệu Cloudwatch 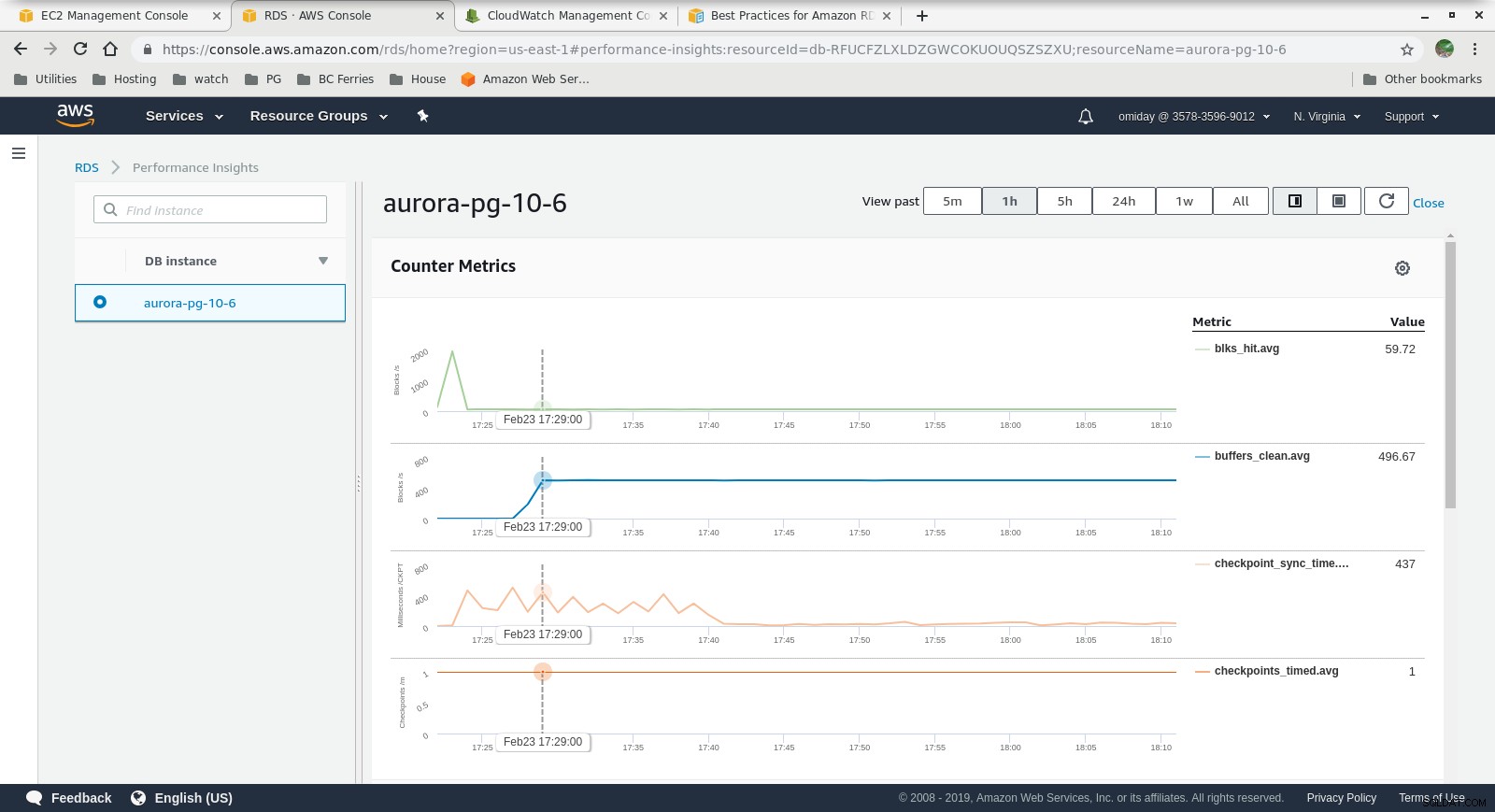 Thông tin chi tiết về hiệu suất - Chỉ số bộ đếm
Thông tin chi tiết về hiệu suất - Chỉ số bộ đếm 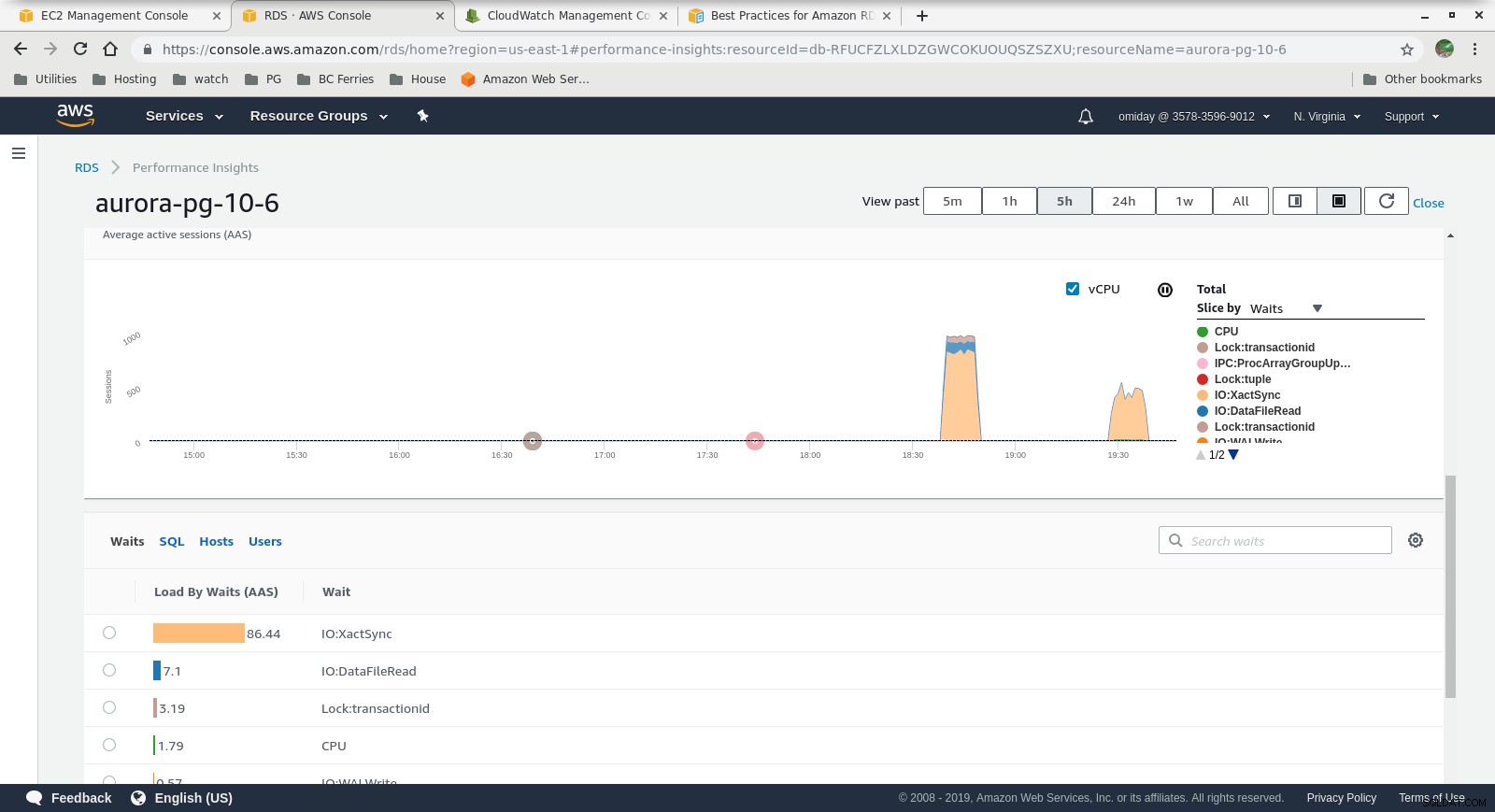 Thông tin chi tiết về hiệu suất - Tải cơ sở dữ liệu theo thời gian chờ
Thông tin chi tiết về hiệu suất - Tải cơ sở dữ liệu theo thời gian chờ Lời kết
- Người dùng bị giới hạn trong việc sử dụng các kích thước phiên bản được xác định trước. Mặt khác, nếu điểm chuẩn cho thấy phiên bản có thể được hưởng lợi từ bộ nhớ bổ sung thì không thể “chỉ thêm RAM”. Thêm nhiều bộ nhớ hơn đồng nghĩa với việc tăng kích thước phiên bản, đi kèm với chi phí cao hơn (chi phí tăng gấp đôi cho mọi kích thước phiên bản).
- Công cụ lưu trữ Amazon Aurora khác nhiều so với RDS và được xây dựng dựa trên phần cứng SAN. Các chỉ số thông lượng I / O cho mỗi trường hợp cho thấy rằng bài kiểm tra thậm chí không đạt gần đến mức tối đa đối với khối lượng IOPS SSD EBS được cung cấp là 1.750 MiB / s.
- Bạn có thể điều chỉnh thêm bằng cách xem lại Sự kiện AWS PostgreSQL có trong biểu đồ Thông tin chi tiết về hiệu suất.
Tiếp theo trong Sê-ri
Hãy theo dõi phần tiếp theo:Amazon RDS cho PostgreSQL 10.6.