Gần một năm trước cho đến ngày hôm nay, tôi đã đăng giải pháp của mình để phân trang trong SQL Server, liên quan đến việc sử dụng CTE để chỉ định vị các giá trị khóa cho tập hợp các hàng được đề cập và sau đó kết hợp trở lại từ CTE với bảng nguồn để truy xuất các cột khác chỉ cho "trang" của các hàng. Điều này tỏ ra có lợi nhất khi có chỉ mục hẹp hỗ trợ thứ tự do người dùng yêu cầu hoặc khi thứ tự dựa trên khóa phân cụm, nhưng thậm chí hoạt động tốt hơn một chút mà không có chỉ mục hỗ trợ sắp xếp được yêu cầu.
Kể từ đó, tôi tự hỏi liệu các chỉ mục ColumnStore (cả nhóm và không nhóm) có thể giúp ích cho bất kỳ trường hợp nào trong số này hay không. TL; DR :Dựa trên thử nghiệm này một cách riêng lẻ, câu trả lời cho tiêu đề của bài đăng này là một KHÔNG vang dội . Nếu bạn không muốn xem thiết lập thử nghiệm, mã, kế hoạch thực thi hoặc đồ thị, vui lòng bỏ qua phần tóm tắt của tôi, lưu ý rằng phân tích của tôi dựa trên một trường hợp sử dụng rất cụ thể.
Thiết lập
Trên một máy ảo mới được cài đặt SQL Server 2016 CTP 3.2 (13.0.900.73), tôi đã chạy qua thiết lập gần giống như trước đây, chỉ lần này với ba bảng. Đầu tiên, một bảng truyền thống có khóa phân cụm hẹp và nhiều chỉ mục hỗ trợ:
CREATE TABLE [dbo].[Customers] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL UNIQUE, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED ([CustomerID]) ); CREATE NONCLUSTERED INDEX [Active_Customers] ON [dbo].[Customers]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); -- to support "PhoneBook" sorting (order by Last,First) CREATE NONCLUSTERED INDEX [PhoneBook_Customers] ON [dbo].[Customers]([LastName],[FirstName]) INCLUDE ([EMail]);
Tiếp theo, một bảng có chỉ mục ColumnStore được phân nhóm:
CREATE TABLE [dbo].[Customers_CCI] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL UNIQUE, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_CustomersCCI] PRIMARY KEY NONCLUSTERED ([CustomerID]) ); CREATE CLUSTERED COLUMNSTORE INDEX [Customers_CCI] ON [dbo].[Customers_CCI];
Và cuối cùng, một bảng có chỉ mục ColumnStore không phân cụm bao gồm tất cả các cột:
CREATE TABLE [dbo].[Customers_NCCI]
(
[CustomerID] [int] NOT NULL,
[FirstName] [nvarchar](64) NOT NULL,
[LastName] [nvarchar](64) NOT NULL,
[EMail] [nvarchar](320) NOT NULL UNIQUE,
[Active] [bit] NOT NULL DEFAULT 1,
[Created] [datetime] NOT NULL DEFAULT SYSDATETIME(),
[Updated] [datetime] NULL,
CONSTRAINT [PK_CustomersNCCI] PRIMARY KEY CLUSTERED
([CustomerID])
);
CREATE NONCLUSTERED COLUMNSTORE INDEX [Customers_NCCI]
ON [dbo].[Customers_NCCI]
(
[CustomerID],
[FirstName],
[LastName],
[EMail],
[Active],
[Created],
[Updated]
); Lưu ý rằng đối với cả hai bảng có chỉ mục ColumnStore, tôi đã loại bỏ chỉ mục sẽ hỗ trợ tìm kiếm nhanh hơn trên phân loại "PhoneBook" (họ, tên).
Dữ liệu thử nghiệm
Sau đó, tôi điền bảng đầu tiên với 1.000.000 hàng ngẫu nhiên, dựa trên một tập lệnh mà tôi đã sử dụng lại từ các bài viết trước:
INSERT dbo.Customers WITH (TABLOCKX)
(CustomerID, FirstName, LastName, EMail, [Active])
SELECT rn = ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, a
FROM
(
SELECT TOP (1000000) fn, ln, em, a = MAX(a), n = MAX(NEWID())
FROM
(
SELECT fn, ln, em, a, r = ROW_NUMBER() OVER (PARTITION BY em ORDER BY em)
FROM
(
SELECT TOP (2000000)
fn = LEFT(o.name, 64),
ln = LEFT(c.name, 64),
em = LEFT(o.name, LEN(c.name)%5+1) + '.'
+ LEFT(c.name, LEN(o.name)%5+2) + '@'
+ RIGHT(c.name, LEN(o.name+c.name)%12 + 1)
+ LEFT(RTRIM(CHECKSUM(NEWID())),3) + '.com',
a = CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END
FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c
ORDER BY NEWID()
) AS x
) AS y WHERE r = 1
GROUP BY fn, ln, em
ORDER BY n
) AS z
ORDER BY rn; Sau đó, tôi sử dụng bảng đó để điền vào hai bảng kia với cùng một dữ liệu và xây dựng lại tất cả các chỉ mục:
INSERT dbo.Customers_CCI WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; INSERT dbo.Customers_NCCI WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; ALTER INDEX ALL ON dbo.Customers REBUILD; ALTER INDEX ALL ON dbo.Customers_CCI REBUILD; ALTER INDEX ALL ON dbo.Customers_NCCI REBUILD;
Tổng kích thước của mỗi bảng:
| Bảng | Được bảo lưu | Dữ liệu | Chỉ mục |
|---|---|---|---|
| Khách hàng | 463.200 KB | 154.344 KB | 308,576 KB |
| Khách hàng_CCI | 117.280 KB | 30.288 KB | 86.536 KB |
| Khách hàng_NCCI | 349.480 KB | 154.344 KB | 194,976 KB |
Và số hàng / số trang của các chỉ mục có liên quan (chỉ mục duy nhất trên e-mail có nhiều thứ để tôi trông nom tập lệnh tạo dữ liệu của riêng mình hơn bất kỳ thứ gì khác):
| Bảng | Chỉ mục | Hàng | Trang |
|---|---|---|---|
| Khách hàng | PK_Customers | 1.000.000 | 19.377 |
| Khách hàng | PhoneBook_Customers | 1.000.000 | 17.209 |
| Khách hàng | Active_Customers | 808.012 | 13,977 |
| Khách hàng_CCI | PK_CustomersCCI | 1.000.000 | 2.737 |
| Khách hàng_CCI | Khách hàng_CCI | 1.000.000 | 3.826 |
| Khách hàng_NCCI | PK_CustomersNCCI | 1.000.000 | 19.377 |
| Khách hàng_NCCI | Khách hàng_NCCI | 1.000.000 | 16,971 |
Thủ tục
Sau đó, để xem liệu các chỉ mục ColumnStore có xâm nhập và làm cho bất kỳ tình huống nào tốt hơn hay không, tôi đã chạy cùng một bộ truy vấn như trước đây, nhưng bây giờ dựa trên cả ba bảng. Tôi đã thông minh hơn một chút và thực hiện hai thủ tục được lưu trữ với SQL động để chấp nhận nguồn bảng và thứ tự sắp xếp. (Tôi biết rõ về việc đưa vào SQL; đây không phải là điều tôi sẽ làm trong quá trình sản xuất nếu các chuỗi này đến từ người dùng cuối, vì vậy vui lòng không coi đó là một khuyến nghị làm như vậy. Tôi tin tưởng bản thân vừa đủ vào môi trường khép kín mà nó không phải là mối quan tâm đối với các thử nghiệm này.)
CREATE PROCEDURE dbo.P_Old
@PageNumber INT = 1,
@PageSize INT = 100,
@Table SYSNAME,
@Sort VARCHAR(32)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX) = N'
SELECT CustomerID, FirstName, LastName,
EMail, Active, Created, Updated
FROM dbo.' + QUOTENAME(@Table) + N'
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N'
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY OPTION (RECOMPILE);';
EXEC sys.sp_executesql @sql, N'@PageSize INT, @PageNumber INT', @PageSize, @PageNumber;
END
GO
CREATE PROCEDURE dbo.P_CTE
@PageNumber INT = 1,
@PageSize INT = 100,
@Table SYSNAME,
@Sort VARCHAR(32)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX) = N'
;WITH pg AS
(
SELECT CustomerID
FROM dbo.' + QUOTENAME(@Table) + N'
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N' OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
SELECT c.CustomerID, c.FirstName, c.LastName,
c.EMail, c.Active, c.Created, c.Updated
FROM dbo.' + QUOTENAME(@Table) + N' AS c
WHERE EXISTS (SELECT 1 FROM pg WHERE pg.CustomerID = c.CustomerID)
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N' OPTION (RECOMPILE);';
EXEC sys.sp_executesql @sql, N'@PageSize INT, @PageNumber INT', @PageSize, @PageNumber;
END
GO
Sau đó, tôi bổ sung thêm một số SQL động để tạo tất cả các kết hợp lệnh gọi mà tôi cần thực hiện để gọi cả thủ tục lưu trữ cũ và mới, theo cả ba thứ tự sắp xếp mong muốn và ở các số trang khác nhau (để mô phỏng nhu cầu một trang gần đầu, giữa và cuối của thứ tự sắp xếp). Để tôi có thể sao chép PRINT xuất và dán nó vào SQL Sentry Plan Explorer để nhận số liệu thời gian chạy, tôi đã chạy lô này hai lần, một lần với procedures CTE sử dụng P_Old , và sau đó sử dụng lại P_CTE .
DECLARE @sql NVARCHAR(MAX) = N''; ;WITH [tables](name) AS ( SELECT N'Customers' UNION ALL SELECT N'Customers_CCI' UNION ALL SELECT N'Customers_NCCI' ), sorts(sort) AS ( SELECT 'Key' UNION ALL SELECT 'PhoneBook' UNION ALL SELECT 'Unsupported' ), pages(pagenumber) AS ( SELECT 1 UNION ALL SELECT 500 UNION ALL SELECT 5000 UNION ALL SELECT 9999 ), procedures(name) AS ( SELECT N'P_CTE' -- N'P_Old' ) SELECT @sql += N' EXEC dbo.' + p.name + N' @Table = N' + CHAR(39) + t.name + CHAR(39) + N', @Sort = N' + CHAR(39) + s.sort + CHAR(39) + N', @PageNumber = ' + CONVERT(NVARCHAR(11), pg.pagenumber) + N';' FROM tables AS t CROSS JOIN sorts AS s CROSS JOIN pages AS pg CROSS JOIN procedures AS p ORDER BY t.name, s.sort, pg.pagenumber; PRINT @sql;
Đầu ra được tạo ra như thế này (36 lệnh gọi hoàn toàn cho phương thức cũ (P_Old ) và 36 lệnh gọi cho phương thức mới (P_CTE )):
EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 1; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 500; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 5000; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'PhoneBook', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'PhoneBook', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Unsupported', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Unsupported', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers_CCI', @Sort = N'Key', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers_CCI', @Sort = N'Unsupported', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers_NCCI', @Sort = N'Key', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers_NCCI', @Sort = N'Unsupported', @PageNumber = 9999;
Tôi biết, tất cả điều này đều rất rườm rà; Tôi hứa chúng ta sẽ sớm đạt đến đỉnh cao.
Kết quả
Tôi đã lấy hai bộ 36 câu lệnh đó và bắt đầu hai phiên mới trong Plan Explorer, chạy mỗi nhóm nhiều lần để đảm bảo chúng tôi đang nhận dữ liệu từ bộ nhớ cache ấm và lấy giá trị trung bình (tôi cũng có thể so sánh bộ nhớ cache lạnh và ấm, nhưng tôi nghĩ có đủ biến ở đây).
Tôi có thể cho bạn biết ngay lập tức một vài sự kiện đơn giản mà không cần hiển thị cho bạn các biểu đồ hoặc kế hoạch hỗ trợ:
- Không có trường hợp nào phương pháp "cũ" đánh bại phương pháp CTE mới Tôi đã thăng hạng trong bài viết trước của mình, bất kể loại chỉ mục nào hiện diện. Vì vậy, điều đó khiến bạn hầu như dễ dàng bỏ qua một nửa kết quả, ít nhất là về thời lượng (là chỉ số mà người dùng cuối quan tâm nhất).
- Không có chỉ mục ColumnStore được xếp hạng tốt khi phân trang về cuối kết quả - họ chỉ cung cấp các lợi ích ngay từ đầu, và chỉ trong một vài trường hợp.
- Khi sắp xếp theo khoá chính (nhóm hoặc không), sự hiện diện của các chỉ mục ColumnStore không giúp ích được gì - một lần nữa, về thời lượng.
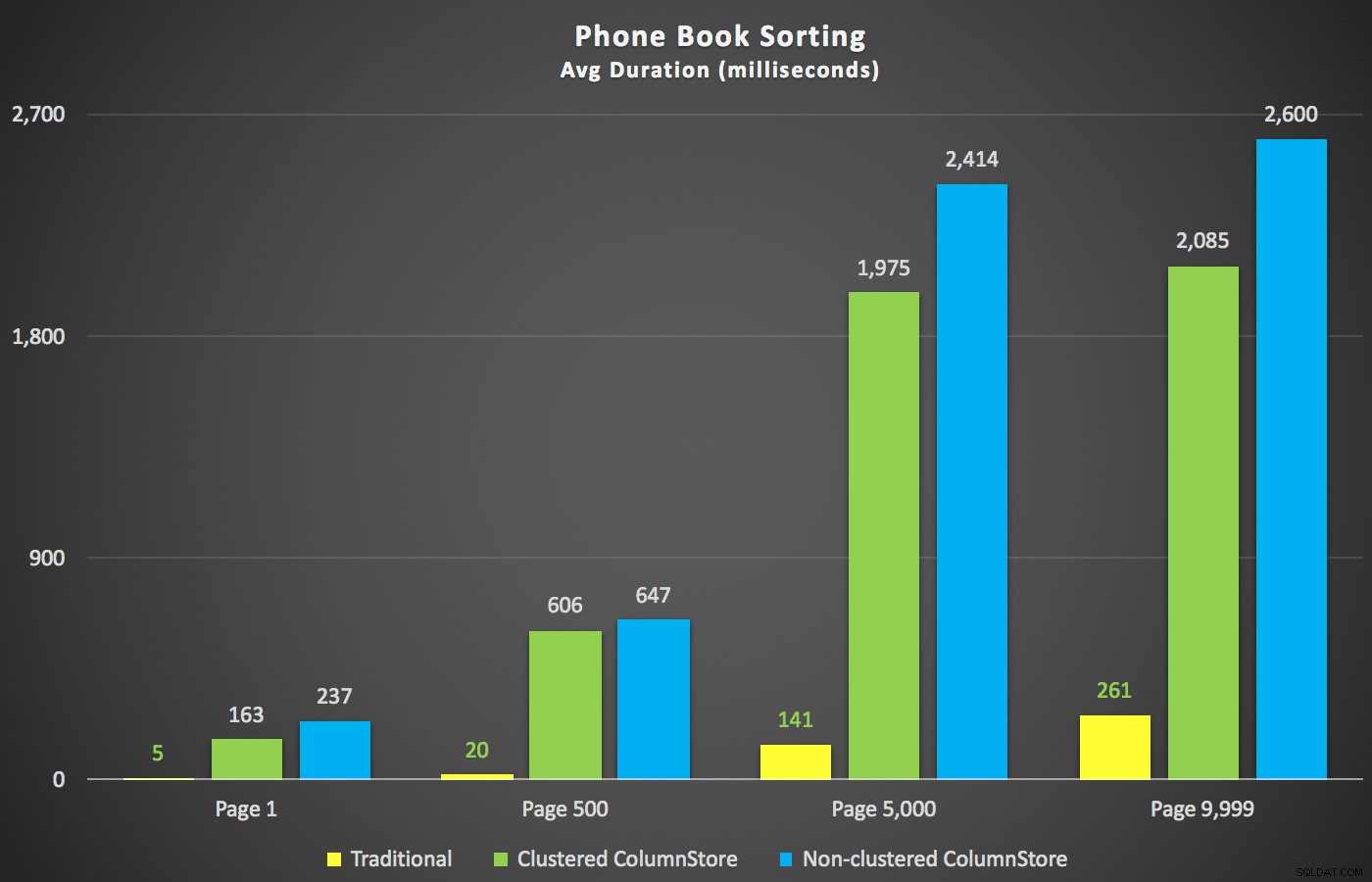
Với những bản tóm tắt đó, chúng ta hãy xem xét một vài phần của dữ liệu thời lượng. Đầu tiên, kết quả của truy vấn được sắp xếp theo tên giảm dần, sau đó đến e-mail, không có hy vọng sử dụng chỉ mục hiện có để sắp xếp. Như bạn có thể thấy trong biểu đồ, hiệu suất không nhất quán - ở số trang thấp hơn, ColumnStore không phân cụm đã làm tốt nhất; ở số trang cao hơn, chỉ mục truyền thống luôn thắng:
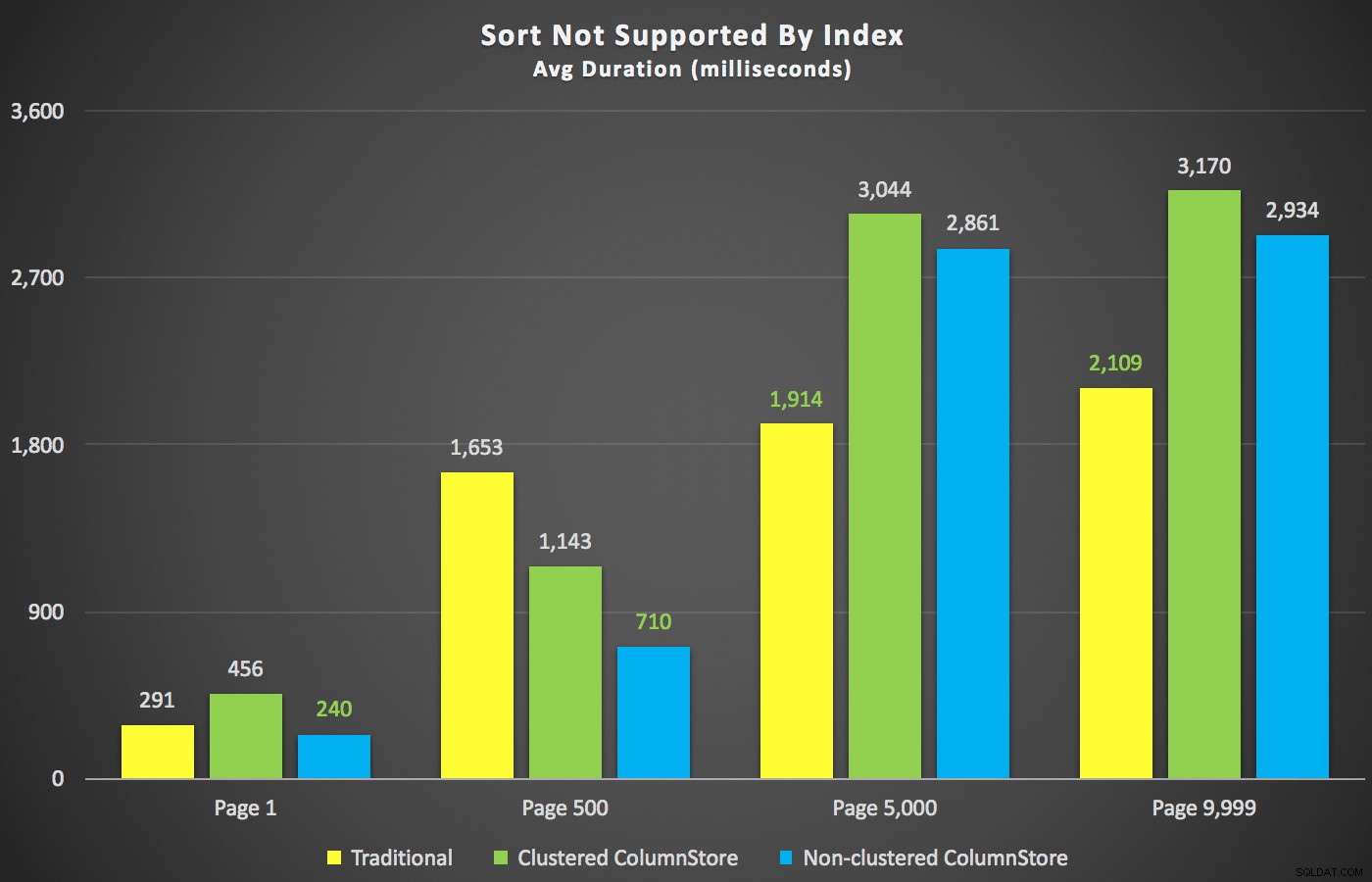 Thời lượng (mili giây) cho các số trang khác nhau và các loại chỉ mục khác nhau
Thời lượng (mili giây) cho các số trang khác nhau và các loại chỉ mục khác nhau
Và sau đó là ba kế hoạch đại diện cho ba loại chỉ mục khác nhau (với thang độ xám được Photoshop thêm vào để làm nổi bật sự khác biệt chính giữa các kế hoạch):
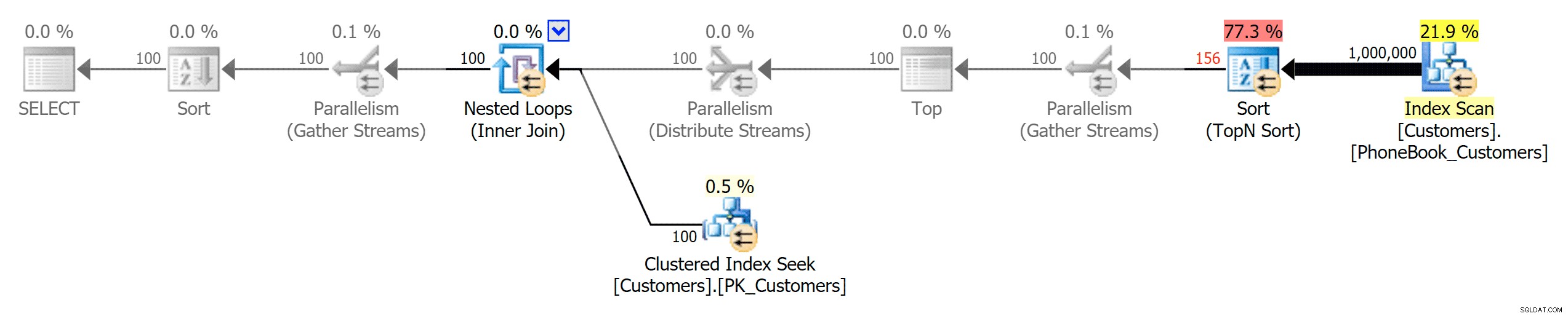 Kế hoạch cho chỉ mục truyền thống
Kế hoạch cho chỉ mục truyền thống
 Kế hoạch cho chỉ mục ColumnStore theo nhóm
Kế hoạch cho chỉ mục ColumnStore theo nhóm
 Kế hoạch cho chỉ mục ColumnStore không phân cụm
Kế hoạch cho chỉ mục ColumnStore không phân cụm
Một kịch bản mà tôi quan tâm hơn, ngay cả trước khi tôi bắt đầu thử nghiệm, là phương pháp sắp xếp danh bạ điện thoại (họ, tên). Trong trường hợp này, các chỉ mục ColumnStore thực sự khá bất lợi cho hiệu suất của kết quả:
Các kế hoạch ColumnStore ở đây là hình ảnh phản chiếu gần với hai kế hoạch ColumnStore được hiển thị ở trên cho loại không được hỗ trợ. Lý do là giống nhau trong cả hai trường hợp:quét hoặc sắp xếp đắt tiền do thiếu chỉ mục hỗ trợ sắp xếp.
Vì vậy, tiếp theo, tôi tạo các chỉ mục "PhoneBook" hỗ trợ trên các bảng cũng có chỉ mục ColumnStore, để xem liệu tôi có thể áp dụng một kế hoạch khác và / hoặc thời gian thực hiện nhanh hơn trong bất kỳ trường hợp nào trong số đó không. Tôi đã tạo hai chỉ mục này, sau đó xây dựng lại một lần nữa:
CREATE NONCLUSTERED INDEX [PhoneBook_CustomersCCI] ON [dbo].[Customers_CCI]([LastName],[FirstName]) INCLUDE ([EMail]); ALTER INDEX ALL ON dbo.Customers_CCI REBUILD; CREATE NONCLUSTERED INDEX [PhoneBook_CustomersNCCI] ON [dbo].[Customers_NCCI]([LastName],[FirstName]) INCLUDE ([EMail]); ALTER INDEX ALL ON dbo.Customers_NCCI REBUILD;
Dưới đây là các khoảng thời gian mới:
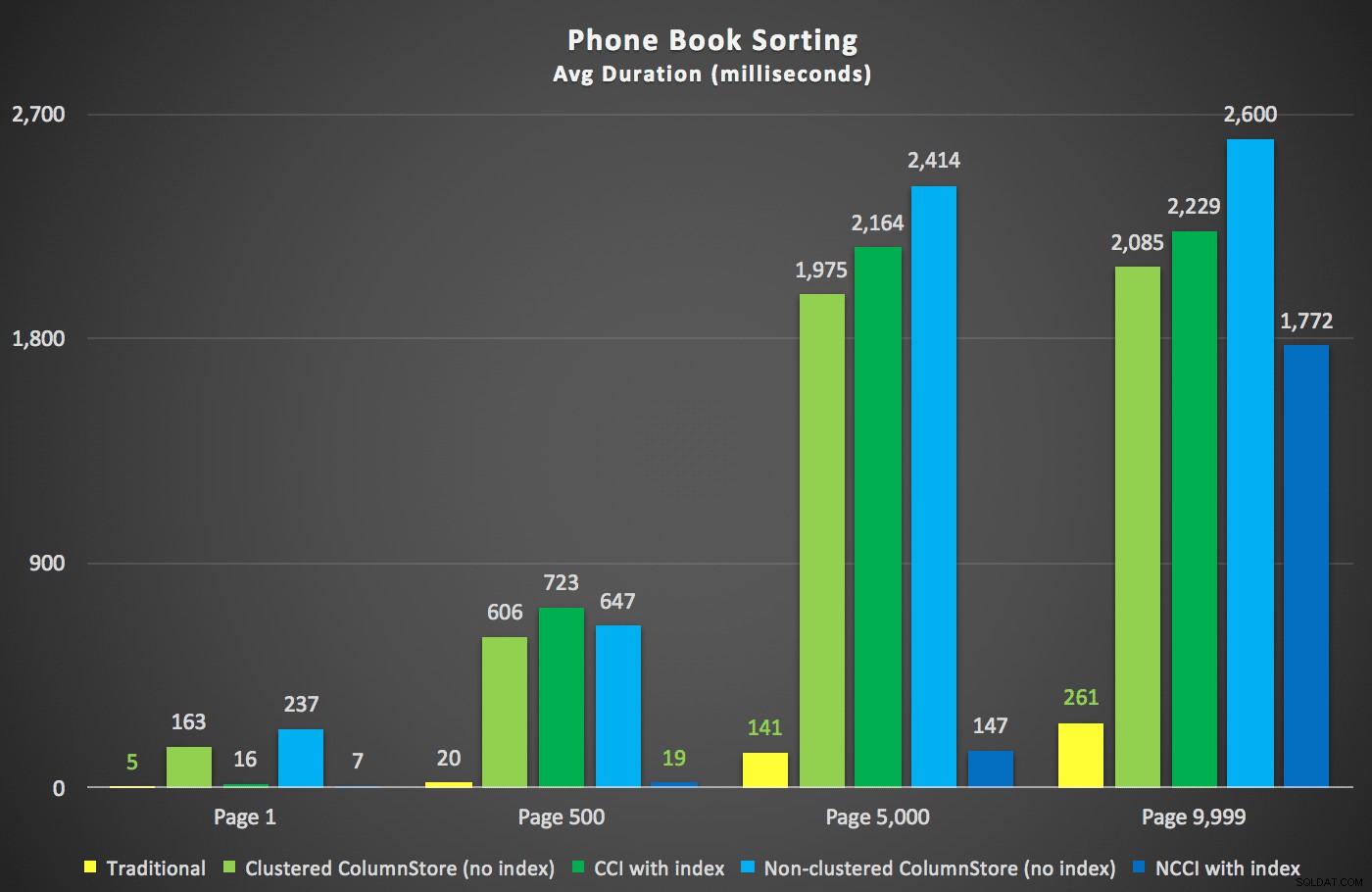
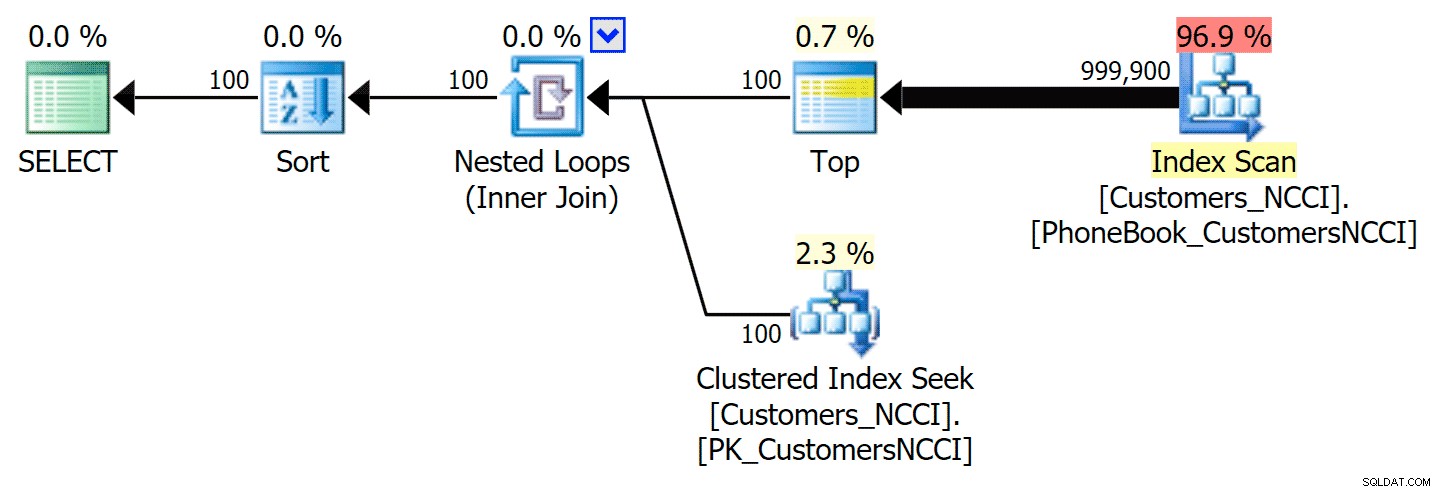
Điều thú vị nhất ở đây là bây giờ truy vấn phân trang chống lại bảng với chỉ mục ColumnStore không phân cụm dường như đang theo kịp với chỉ mục truyền thống, cho đến khi chúng ta vượt ra khỏi giữa bảng. Nhìn vào các kế hoạch, chúng ta có thể thấy rằng ở trang 5.000, cách quét chỉ mục truyền thống được sử dụng và chỉ mục ColumnStore hoàn toàn bị bỏ qua:
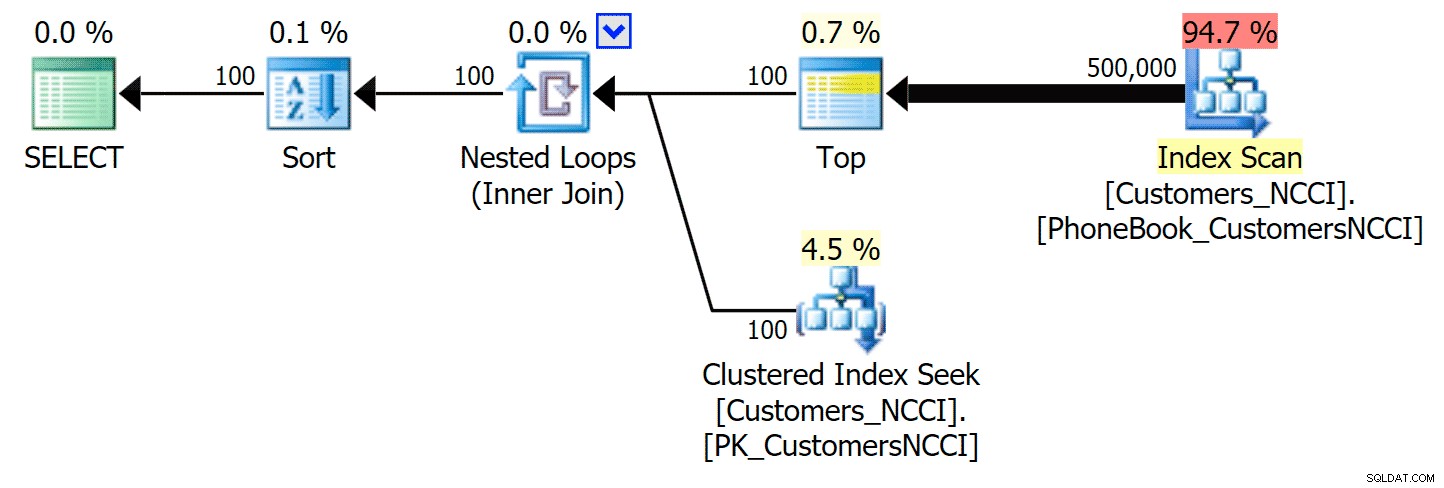 Gói Danh bạ điện thoại bỏ qua chỉ mục ColumnStore không phân cụm
Gói Danh bạ điện thoại bỏ qua chỉ mục ColumnStore không phân cụm
Nhưng ở đâu đó giữa điểm giữa của 5.000 trang và "cuối" của bảng là 9.999 trang, trình tối ưu hóa đã đạt đến một loại điểm giới hạn và - đối với cùng một truy vấn - hiện đang chọn quét chỉ mục ColumnStore không phân cụm. :
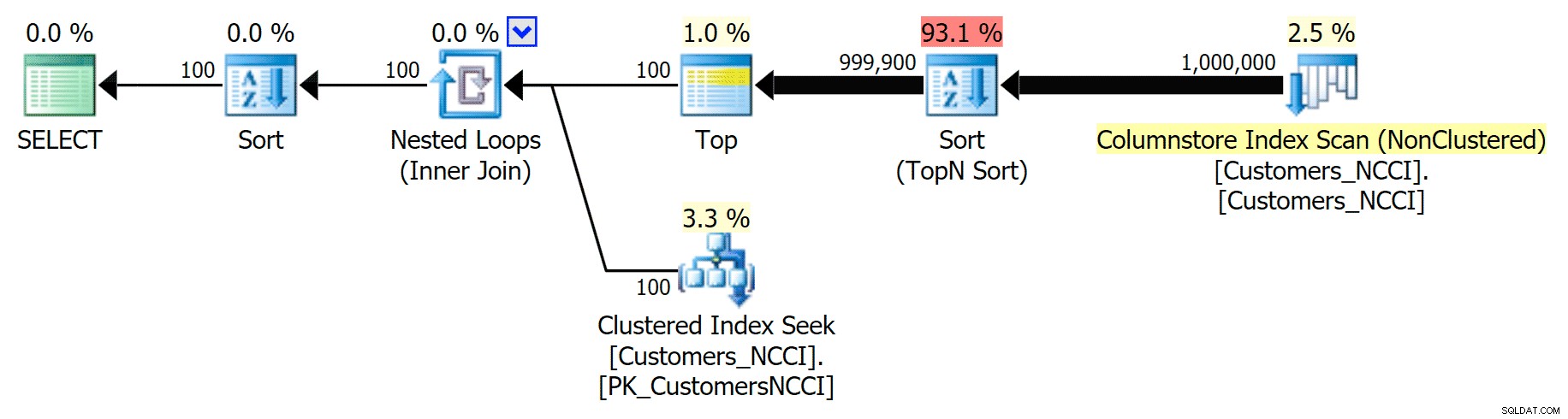 'Mẹo' kế hoạch Danh bạ điện thoại và sử dụng chỉ mục ColumnStore
'Mẹo' kế hoạch Danh bạ điện thoại và sử dụng chỉ mục ColumnStore
Điều này hóa ra là một quyết định không quá lớn của trình tối ưu hóa, chủ yếu là do chi phí của hoạt động sắp xếp. Bạn có thể thấy thời lượng sẽ tốt hơn bao nhiêu nếu bạn gợi ý chỉ mục thông thường:
-- ...
;WITH pg AS
(
SELECT CustomerID
FROM dbo.[Customers_NCCI] WITH (INDEX(PhoneBook_CustomersNCCI)) -- hint here
ORDER BY LastName, FirstName OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
-- ... Điều này mang lại kế hoạch sau, gần giống với kế hoạch đầu tiên ở trên (tuy nhiên, chi phí quét cao hơn một chút, đơn giản vì có nhiều đầu ra hơn):
 Gói Danh bạ điện thoại có chỉ mục gợi ý
Gói Danh bạ điện thoại có chỉ mục gợi ý
Bạn có thể đạt được điều tương tự bằng cách sử dụng OPTION (IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX) thay vì gợi ý chỉ mục rõ ràng. Chỉ cần lưu ý rằng điều này cũng giống như việc không có chỉ mục ColumnStore ở đó ngay từ đầu.
Kết luận
Mặc dù có một số trường hợp vượt trội ở trên mà chỉ mục ColumnStore có thể (hầu như không) mang lại hiệu quả, đối với tôi, có vẻ như chúng không phù hợp với kịch bản phân trang cụ thể này. Tôi nghĩ, quan trọng nhất, trong khi ColumnStore tiết kiệm không gian đáng kể do nén, hiệu suất thời gian chạy không tuyệt vời do các yêu cầu sắp xếp (mặc dù các loại này được ước tính chạy ở chế độ hàng loạt, một tối ưu hóa mới cho SQL Server 2016).
Nói chung, điều này có thể làm được với rất nhiều thời gian dành cho nghiên cứu và thử nghiệm; trong sự hỗ trợ của các bài viết trước, tôi muốn thay đổi càng ít càng tốt. Ví dụ, tôi muốn tìm ra điểm tới hạn đó và tôi cũng muốn thừa nhận rằng đây không phải là những thử nghiệm quy mô lớn (do kích thước VM và giới hạn bộ nhớ) và tôi đã để bạn đoán về rất nhiều chỉ số thời gian chạy (chủ yếu là ngắn gọn, nhưng tôi không biết rằng một biểu đồ số lần đọc không phải lúc nào cũng tỷ lệ thuận với thời lượng sẽ thực sự cho bạn biết). Các bài kiểm tra này cũng giả định sự xa xỉ của SSD, bộ nhớ đủ, bộ nhớ đệm luôn ấm và môi trường một người dùng. Tôi thực sự muốn thực hiện một lượng lớn các bài kiểm tra đối với nhiều dữ liệu hơn, trên các máy chủ lớn hơn với các đĩa và phiên bản chậm hơn với ít bộ nhớ hơn, đồng thời với đồng thời được mô phỏng.
Điều đó nói rằng, đây cũng có thể chỉ là một kịch bản mà ColumnStore không được thiết kế để giúp giải quyết ngay từ đầu, vì giải pháp cơ bản với các chỉ mục truyền thống đã khá hiệu quả trong việc kéo ra một tập hợp các hàng hẹp - không chính xác là kho của ColumnStore. Có lẽ một biến khác để thêm vào ma trận là kích thước trang - tất cả các thử nghiệm ở trên đều kéo 100 hàng cùng một lúc, nhưng điều gì sẽ xảy ra nếu chúng ta sau 10.000 hoặc 100.000 hàng cùng một lúc, bất kể bảng bên dưới lớn như thế nào?
Bạn có gặp trường hợp khối lượng công việc OLTP của mình được cải thiện đơn giản bằng cách bổ sung các chỉ mục ColumnStore không? Tôi biết rằng chúng được thiết kế cho khối lượng công việc theo kiểu kho dữ liệu, nhưng nếu bạn đã thấy lợi ích ở những nơi khác, tôi muốn nghe về kịch bản của bạn và xem liệu tôi có thể kết hợp bất kỳ yếu tố khác biệt nào vào hệ thống thử nghiệm của mình hay không.