Đầu tháng này, tôi đã xuất bản một mẹo về điều mà có lẽ tất cả chúng ta đều ước không phải làm:sắp xếp hoặc loại bỏ các bản sao khỏi các chuỗi được phân tách, thường liên quan đến các chức năng do người dùng xác định (UDF). Đôi khi bạn cần tập hợp lại danh sách (không có các bản sao) theo thứ tự bảng chữ cái và đôi khi bạn có thể cần duy trì thứ tự ban đầu (ví dụ:đó có thể là danh sách các cột quan trọng trong một chỉ mục không hợp lệ).
Đối với giải pháp của tôi, giải quyết cả hai trường hợp, tôi đã sử dụng một bảng số, cùng với một cặp hàm do người dùng xác định (UDF) - một hàm để tách chuỗi, hàm kia để tập hợp lại. Bạn có thể xem mẹo đó tại đây:
- Xóa các bản sao khỏi các chuỗi trong SQL Server
Tất nhiên, có nhiều cách để giải quyết vấn đề này; Tôi chỉ cung cấp một phương pháp để thử nếu bạn bị mắc kẹt với dữ liệu cấu trúc đó. @Phil_Factor của Red-Gate tiếp tục với một bài đăng nhanh cho thấy cách tiếp cận của anh ấy, tránh các hàm và bảng số, thay vào đó chọn thao tác XML nội tuyến. Anh ấy nói rằng anh ấy thích có các truy vấn câu lệnh đơn và tránh cả hai hàm và xử lý từng hàng:
- Khử trùng lặp các danh sách phân cách trong SQL Server
Sau đó, một độc giả, Steve Mangiameli, đã đăng một giải pháp lặp lại như một bình luận về mẹo này. Lý do của anh ấy là việc sử dụng một bảng số dường như đã quá kỹ thuật đối với anh ấy.
Cả ba chúng tôi đều không giải quyết được một khía cạnh của vấn đề này thường sẽ khá quan trọng nếu bạn đang thực hiện nhiệm vụ đủ thường xuyên hoặc ở bất kỳ cấp độ quy mô nào: hiệu suất .
Thử nghiệm
Tò mò muốn xem các phương pháp tiếp cận vòng lặp và XML nội tuyến sẽ hoạt động tốt như thế nào so với giải pháp dựa trên bảng số của tôi, tôi đã xây dựng một bảng giả tưởng để thực hiện một số thử nghiệm; mục tiêu của tôi là 5.000 hàng, với độ dài chuỗi trung bình lớn hơn 250 ký tự và ít nhất 10 phần tử trong mỗi chuỗi. Với một chu kỳ thử nghiệm rất ngắn, tôi đã có thể đạt được điều gì đó rất gần với điều này bằng đoạn mã sau:
CREATE TABLE dbo.SourceTable
(
[RowID] int IDENTITY(1,1) PRIMARY KEY CLUSTERED,
DelimitedString varchar(8000)
);
GO
;WITH s(s) AS
(
SELECT TOP (250) o.name + REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(
(
SELECT N'/column_' + c.name
FROM sys.all_columns AS c
WHERE c.[object_id] = o.[object_id]
ORDER BY NEWID()
FOR XML PATH(N''), TYPE).value(N'.[1]', N'nvarchar(max)'
),
-- make fake duplicates using 5 most common column names:
N'/column_name/', N'/name/name/foo/name/name/id/name/'),
N'/column_status/', N'/id/status/blat/status/foo/status/name/'),
N'/column_type/', N'/type/id/name/type/id/name/status/id/type/'),
N'/column_object_id/', N'/object_id/blat/object_id/status/type/name/'),
N'/column_pdw_node_id/', N'/pdw_node_id/name/pdw_node_id/name/type/name/')
FROM sys.all_objects AS o
WHERE EXISTS
(
SELECT 1 FROM sys.all_columns AS c
WHERE c.[object_id] = o.[object_id]
)
ORDER BY NEWID()
)
INSERT dbo.SourceTable(DelimitedString)
SELECT s FROM s;
GO 20 Điều này tạo ra một bảng với các hàng mẫu trông như thế này (các giá trị bị cắt bớt):
RowID DelimitedString ----- --------------- 1 master_files/column_redo_target_fork_guid/.../column_differential_base_lsn/... 2 allocation_units/column_used_pages/.../column_data_space_id/type/id/name/type/... 3 foreign_key_columns/column_parent_object_id/column_constraint_object_id/...
Dữ liệu nói chung có cấu hình sau đây, đủ tốt để phát hiện ra bất kỳ vấn đề tiềm năng nào về hiệu suất:
;WITH cte([Length], ElementCount) AS
(
SELECT 1.0*LEN(DelimitedString),
1.0*LEN(REPLACE(DelimitedString,'/',''))
FROM dbo.SourceTable
)
SELECT row_count = COUNT(*),
avg_size = AVG([Length]),
max_size = MAX([Length]),
avg_elements = AVG(1 + [Length]-[ElementCount]),
sum_elements = SUM(1 + [Length]-[ElementCount])
FROM cte;
EXEC sys.sp_spaceused N'dbo.SourceTable';
/* results (numbers may vary slightly, depending on SQL Server version the user objects in your database):
row_count avg_size max_size avg_elements sum_elements
--------- ---------- -------- ------------ ------------
5000 299.559000 2905.0 17.650000 88250.0
reserved data index_size unused
-------- ------- ---------- ------
1672 KB 1648 KB 16 KB 8 KB
*/
Lưu ý rằng tôi đã chuyển sang varchar tại đây từ nvarchar trong bài viết gốc, vì các mẫu mà Phil và Steve cung cấp giả định là varchar , chuỗi giới hạn ở 255 hoặc 8000 ký tự, dấu phân cách một ký tự, v.v. Tôi đã học được bài học của mình một cách khó khăn, rằng nếu bạn định lấy chức năng của ai đó và đưa nó vào so sánh hiệu suất, bạn chỉ thay đổi có thể - lý tưởng là không có gì. Trong thực tế, tôi luôn sử dụng nvarchar và không giả định bất cứ điều gì về chuỗi dài nhất có thể. Trong trường hợp này, tôi biết mình không bị mất bất kỳ dữ liệu nào vì chuỗi dài nhất chỉ có 2.905 ký tự và trong cơ sở dữ liệu này, tôi không có bất kỳ bảng hoặc cột nào sử dụng ký tự Unicode.
Tiếp theo, tôi tạo các hàm của mình (yêu cầu một bảng số). Một độc giả đã phát hiện ra một vấn đề trong hàm trong mẹo của tôi, trong đó tôi cho rằng dấu phân cách sẽ luôn là một ký tự duy nhất và đã sửa lỗi đó tại đây. Tôi cũng đã chuyển đổi mọi thứ thành varchar(8000) để cân bằng sân chơi về loại chuỗi và độ dài.
DECLARE @UpperLimit INT = 1000000;
;WITH n(rn) AS
(
SELECT ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_columns AS s1
CROSS JOIN sys.all_columns AS s2
)
SELECT [Number] = rn
INTO dbo.Numbers FROM n
WHERE rn <= @UpperLimit;
CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers([Number]);
GO
CREATE FUNCTION [dbo].[SplitString] -- inline TVF
(
@List varchar(8000),
@Delim varchar(32)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT
rn,
vn = ROW_NUMBER() OVER (PARTITION BY [Value] ORDER BY rn),
[Value]
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY CHARINDEX(@Delim, @List + @Delim)),
[Value] = LTRIM(RTRIM(SUBSTRING(@List, [Number],
CHARINDEX(@Delim, @List + @Delim, [Number]) - [Number])))
FROM dbo.Numbers
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delim + @List, [Number], LEN(@Delim)) = @Delim
) AS x
);
GO
CREATE FUNCTION [dbo].[ReassembleString] -- scalar UDF
(
@List varchar(8000),
@Delim varchar(32),
@Sort varchar(32)
)
RETURNS varchar(8000)
WITH SCHEMABINDING
AS
BEGIN
RETURN
(
SELECT newval = STUFF((
SELECT @Delim + x.[Value]
FROM dbo.SplitString(@List, @Delim) AS x
WHERE (x.vn = 1) -- filter out duplicates
ORDER BY CASE @Sort
WHEN 'OriginalOrder' THEN CONVERT(int, x.rn)
WHEN 'Alphabetical' THEN CONVERT(varchar(8000), x.[Value])
ELSE CONVERT(SQL_VARIANT, NULL) END
FOR XML PATH(''), TYPE).value(N'(./text())[1]',N'varchar(8000)'),1,LEN(@Delim),'')
);
END
GO Tiếp theo, tôi tạo một hàm có giá trị bảng nội tuyến duy nhất kết hợp hai hàm trên, điều mà bây giờ tôi ước tôi đã làm trong bài viết gốc, để tránh hoàn toàn hàm vô hướng. (Mặc dù đúng là không tất cả các hàm vô hướng có quy mô khủng khiếp, có rất ít ngoại lệ.)
CREATE FUNCTION [dbo].[RebuildString]
(
@List varchar(8000),
@Delim varchar(32),
@Sort varchar(32)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT [Output] = STUFF((
SELECT @Delim + x.[Value]
FROM
(
SELECT rn, [Value], vn = ROW_NUMBER() OVER (PARTITION BY [Value] ORDER BY rn)
FROM
(
SELECT rn = ROW_NUMBER() OVER (ORDER BY CHARINDEX(@Delim, @List + @Delim)),
[Value] = LTRIM(RTRIM(SUBSTRING(@List, [Number],
CHARINDEX(@Delim, @List + @Delim, [Number]) - [Number])))
FROM dbo.Numbers
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delim + @List, [Number], LEN(@Delim)) = @Delim
) AS y
) AS x
WHERE (x.vn = 1)
ORDER BY CASE @Sort
WHEN 'OriginalOrder' THEN CONVERT(int, x.rn)
WHEN 'Alphabetical' THEN CONVERT(varchar(8000), x.[Value])
ELSE CONVERT(sql_variant, NULL) END
FOR XML PATH(''), TYPE).value(N'(./text())[1]',N'varchar(8000)'),1,LEN(@Delim),'')
);
GO
Tôi cũng đã tạo các phiên bản riêng biệt của TVF nội tuyến dành riêng cho từng lựa chọn trong số hai lựa chọn sắp xếp, để tránh sự biến động của CASE nhưng hóa ra nó không có tác động đáng kể nào cả.
Sau đó, tôi tạo hai hàm của Steve:
CREATE FUNCTION [dbo].[gfn_ParseList] -- multi-statement TVF
(@strToPars VARCHAR(8000), @parseChar CHAR(1))
RETURNS @parsedIDs TABLE
(ParsedValue VARCHAR(255), PositionID INT IDENTITY)
AS
BEGIN
DECLARE
@startPos INT = 0
, @strLen INT = 0
WHILE LEN(@strToPars) >= @startPos
BEGIN
IF (SELECT CHARINDEX(@parseChar,@strToPars,(@startPos+1))) > @startPos
SELECT @strLen = CHARINDEX(@parseChar,@strToPars,(@startPos+1)) - @startPos
ELSE
BEGIN
SET @strLen = LEN(@strToPars) - (@startPos -1)
INSERT @parsedIDs
SELECT RTRIM(LTRIM(SUBSTRING(@strToPars,@startPos, @strLen)))
BREAK
END
SELECT @strLen = CHARINDEX(@parseChar,@strToPars,(@startPos+1)) - @startPos
INSERT @parsedIDs
SELECT RTRIM(LTRIM(SUBSTRING(@strToPars,@startPos, @strLen)))
SET @startPos = @startPos+@strLen+1
END
RETURN
END
GO
CREATE FUNCTION [dbo].[ufn_DedupeString] -- scalar UDF
(
@dupeStr VARCHAR(MAX), @strDelimiter CHAR(1), @maintainOrder BIT
)
-- can't possibly return nvarchar, but I'm not touching it
RETURNS NVARCHAR(MAX)
AS
BEGIN
DECLARE @tblStr2Tbl TABLE (ParsedValue VARCHAR(255), PositionID INT);
DECLARE @tblDeDupeMe TABLE (ParsedValue VARCHAR(255), PositionID INT);
INSERT @tblStr2Tbl
SELECT DISTINCT ParsedValue, PositionID FROM dbo.gfn_ParseList(@dupeStr,@strDelimiter);
WITH cteUniqueValues
AS
(
SELECT DISTINCT ParsedValue
FROM @tblStr2Tbl
)
INSERT @tblDeDupeMe
SELECT d.ParsedValue
, CASE @maintainOrder
WHEN 1 THEN MIN(d.PositionID)
ELSE ROW_NUMBER() OVER (ORDER BY d.ParsedValue)
END AS PositionID
FROM cteUniqueValues u
JOIN @tblStr2Tbl d ON d.ParsedValue=u.ParsedValue
GROUP BY d.ParsedValue
ORDER BY d.ParsedValue
DECLARE
@valCount INT
, @curValue VARCHAR(255) =''
, @posValue INT=0
, @dedupedStr VARCHAR(4000)='';
SELECT @valCount = COUNT(1) FROM @tblDeDupeMe;
WHILE @valCount > 0
BEGIN
SELECT @posValue=a.minPos, @curValue=d.ParsedValue
FROM (SELECT MIN(PositionID) minPos FROM @tblDeDupeMe WHERE PositionID > @posValue) a
JOIN @tblDeDupeMe d ON d.PositionID=a.minPos;
SET @dedupedStr+=@curValue;
SET @valCount-=1;
IF @valCount > 0
SET @dedupedStr+='/';
END
RETURN @dedupedStr;
END
GO
Sau đó, tôi đặt các truy vấn trực tiếp của Phil vào hệ thống thử nghiệm của mình (lưu ý rằng các truy vấn của anh ấy mã hóa < dưới dạng < để bảo vệ chúng khỏi lỗi phân tích cú pháp XML, nhưng chúng không mã hóa > hoặc & - Tôi đã thêm trình giữ chỗ trong trường hợp bạn cần đề phòng các chuỗi có khả năng chứa các ký tự có vấn đề đó):
-- Phil's query for maintaining original order
SELECT /*the re-assembled list*/
stuff(
(SELECT '/'+TheValue FROM
(SELECT x.y.value('.','varchar(20)') AS Thevalue,
row_number() OVER (ORDER BY (SELECT 1)) AS TheOrder
FROM XMLList.nodes('/list/i/text()') AS x ( y )
)Nodes(Thevalue,TheOrder)
GROUP BY TheValue
ORDER BY min(TheOrder)
FOR XML PATH('')
),1,1,'')
as Deduplicated
FROM (/*XML version of the original list*/
SELECT convert(XML,'<list><i>'
--+replace(replace(
+replace(replace(ASCIIList,'<','<') --,'>','>'),'&','&')
,'/','</i><i>')+'</i></list>')
FROM (SELECT DelimitedString FROM dbo.SourceTable
)XMLlist(AsciiList)
)lists(XMLlist);
-- Phil's query for alpha
SELECT
stuff( (SELECT DISTINCT '/'+x.y.value('.','varchar(20)')
FROM XMLList.nodes('/list/i/text()') AS x ( y )
FOR XML PATH('')),1,1,'') as Deduplicated
FROM (
SELECT convert(XML,'<list><i>'
--+replace(replace(
+replace(replace(ASCIIList,'<','<') --,'>','>'),'&','&')
,'/','</i><i>')+'</i></list>')
FROM (SELECT AsciiList FROM
(SELECT DelimitedString FROM dbo.SourceTable)ListsWithDuplicates(AsciiList)
)XMLlist(AsciiList)
)lists(XMLlist);
Hệ thống kiểm tra về cơ bản là hai truy vấn đó và cũng có các lệnh gọi hàm sau đây. Sau khi tôi xác thực rằng tất cả chúng đều trả về cùng một dữ liệu, tôi đã xen kẽ tập lệnh với DATEDIFF xuất và ghi nó vào bảng:
-- Maintain original order
-- My UDF/TVF pair from the original article
SELECT UDF_Original = dbo.ReassembleString(DelimitedString, '/', 'OriginalOrder')
FROM dbo.SourceTable ORDER BY RowID;
-- My inline TVF based on the original article
SELECT TVF_Original = f.[Output] FROM dbo.SourceTable AS t
CROSS APPLY dbo.RebuildString(t.DelimitedString, '/', 'OriginalOrder') AS f
ORDER BY t.RowID;
-- Steve's UDF/TVF pair:
SELECT Steve_Original = dbo.ufn_DedupeString(DelimitedString, '/', 1)
FROM dbo.SourceTable;
-- Phil's first query from above
-- Reassemble in alphabetical order
-- My UDF/TVF pair from the original article
SELECT UDF_Alpha = dbo.ReassembleString(DelimitedString, '/', 'Alphabetical')
FROM dbo.SourceTable ORDER BY RowID;
-- My inline TVF based on the original article
SELECT TVF_Alpha = f.[Output] FROM dbo.SourceTable AS t
CROSS APPLY dbo.RebuildString(t.DelimitedString, '/', 'Alphabetical') AS f
ORDER BY t.RowID;
-- Steve's UDF/TVF pair:
SELECT Steve_Alpha = dbo.ufn_DedupeString(DelimitedString, '/', 0)
FROM dbo.SourceTable;
-- Phil's second query from above Và sau đó, tôi đã chạy các bài kiểm tra hiệu suất trên hai hệ thống khác nhau (một lõi tứ với 8GB và một máy ảo 8 lõi với 32GB) và trong mỗi trường hợp, trên cả SQL Server 2012 và SQL Server 2016 CTP 3.2 (13.0.900.73).
Kết quả
Các kết quả mà tôi quan sát được được tóm tắt trong biểu đồ sau, biểu đồ này hiển thị thời lượng tính bằng mili giây của mỗi loại truy vấn, tính trung bình theo thứ tự bảng chữ cái và thứ tự ban đầu, kết hợp bốn máy chủ / phiên bản và chuỗi 15 lần thực thi cho mỗi hoán vị. Bấm để phóng to:
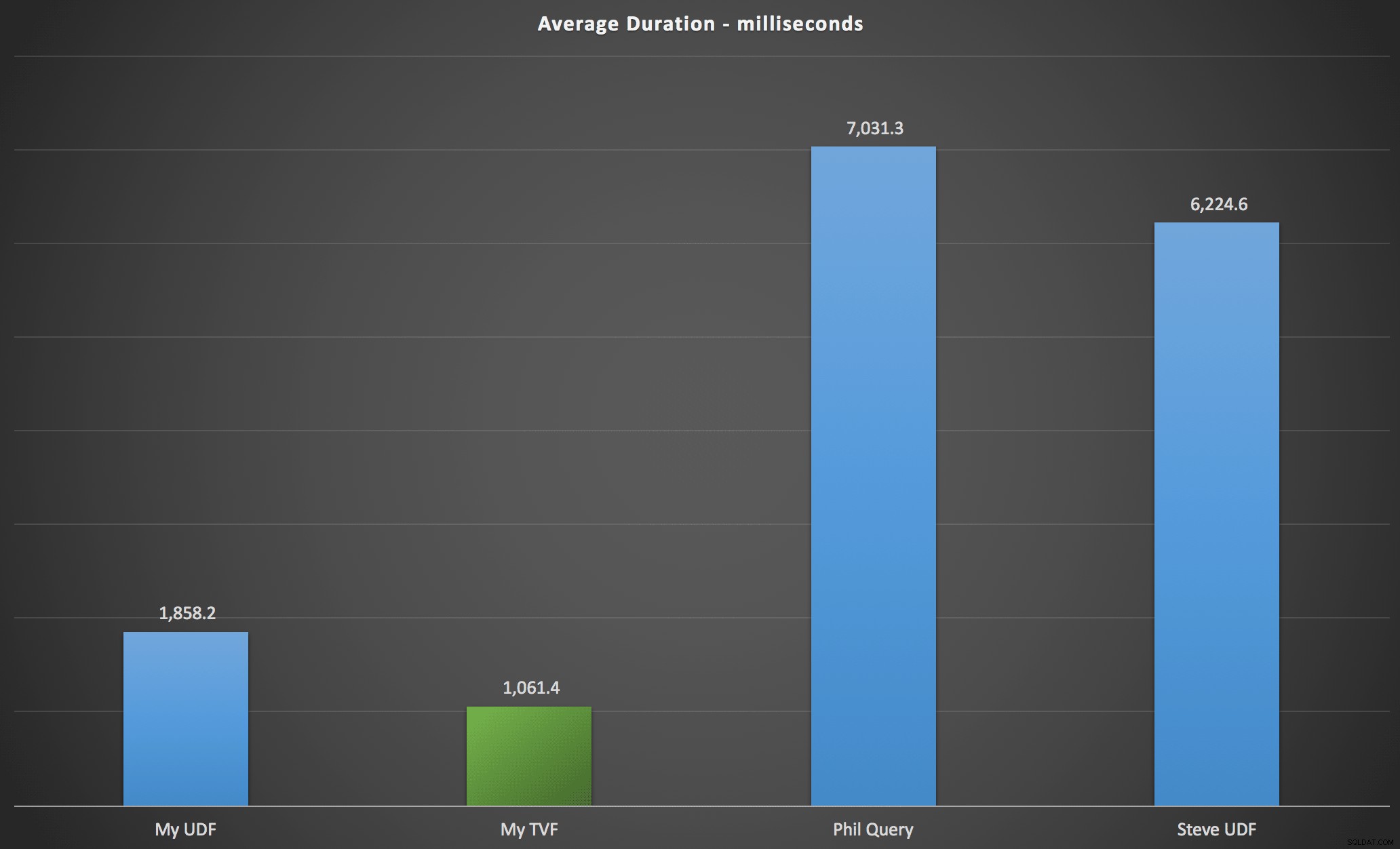
Điều này cho thấy rằng bảng con số, mặc dù được coi là được thiết kế quá mức, nhưng thực sự đã mang lại giải pháp hiệu quả nhất (ít nhất là về thời lượng). Tất nhiên, điều này tốt hơn với TVF đơn lẻ mà tôi đã triển khai gần đây hơn là với các hàm lồng nhau từ bài viết gốc, nhưng cả hai giải pháp đều chạy vòng quanh hai giải pháp thay thế.
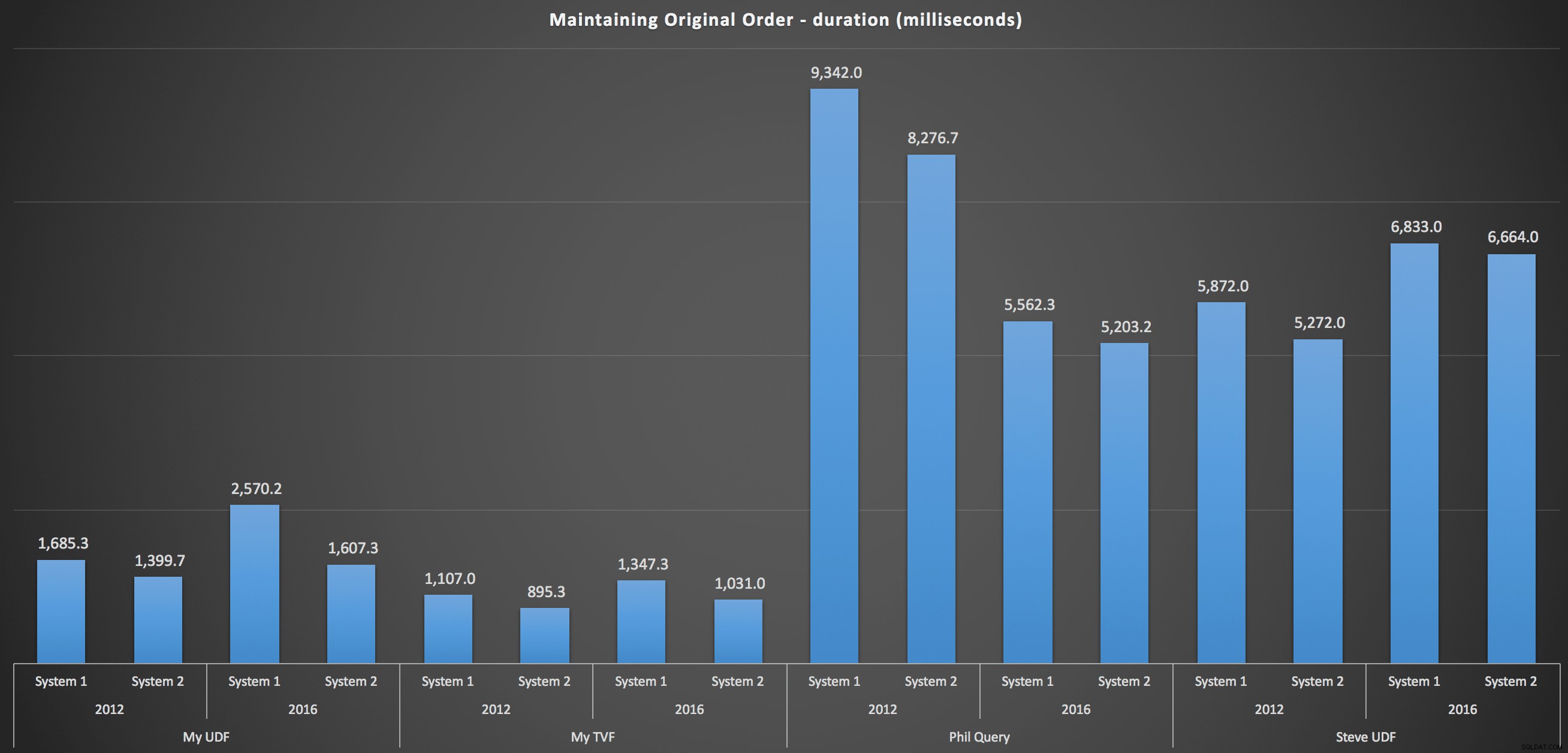
Để tìm hiểu chi tiết hơn, đây là bảng phân tích cho từng máy, phiên bản và loại truy vấn để duy trì trật tự ban đầu:
… Và để tập hợp lại danh sách theo thứ tự bảng chữ cái:
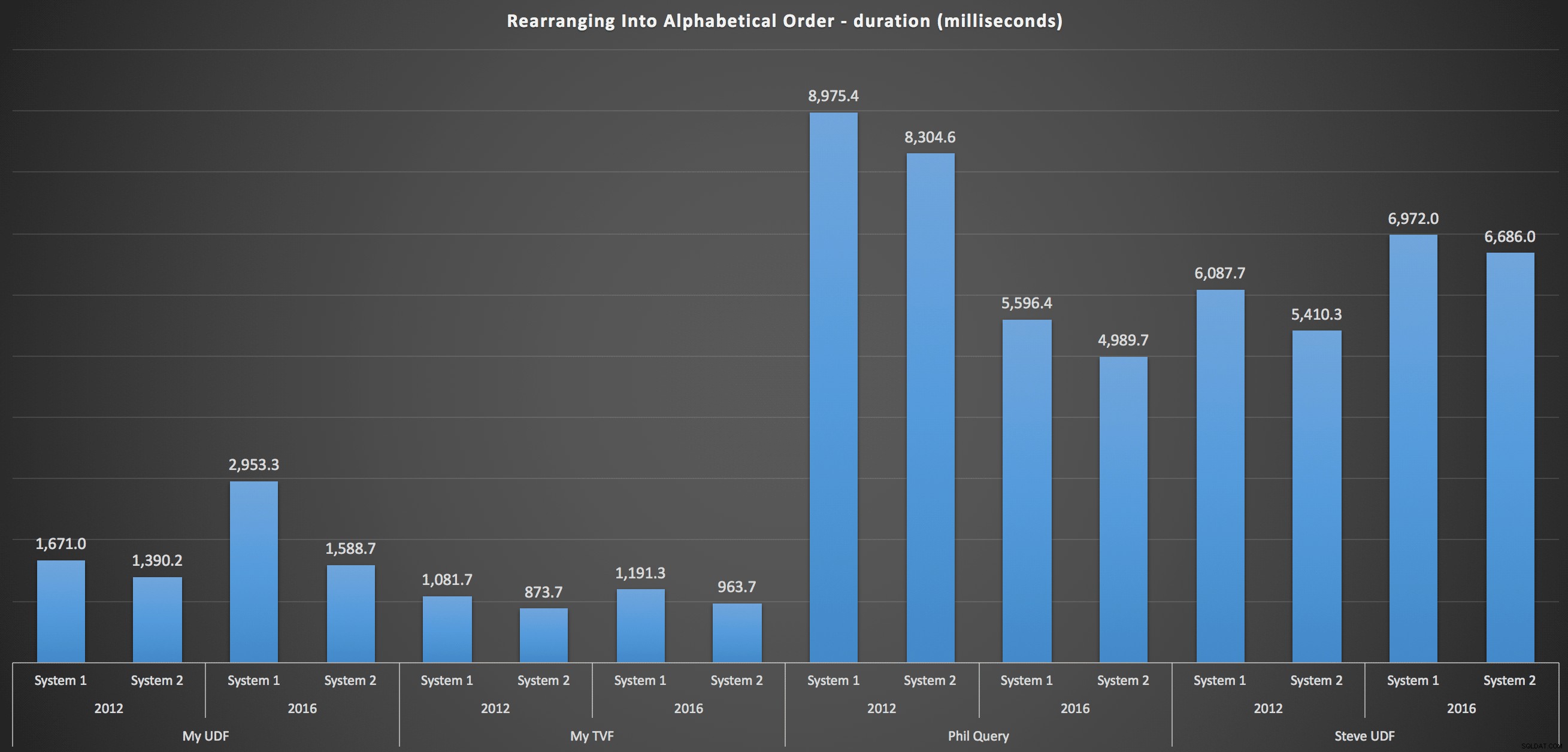
Những điều này cho thấy lựa chọn sắp xếp có ít ảnh hưởng đến kết quả - cả hai biểu đồ hầu như giống hệt nhau. Và điều đó có ý nghĩa bởi vì, với dạng dữ liệu đầu vào, không có chỉ mục nào mà tôi có thể hình dung sẽ làm cho việc sắp xếp hiệu quả hơn - đó là một cách tiếp cận lặp đi lặp lại bất kể bạn cắt nó như thế nào hoặc bạn trả lại dữ liệu như thế nào. Nhưng rõ ràng là một số phương pháp tiếp cận lặp đi lặp lại có thể kém hơn các phương pháp khác và không nhất thiết việc sử dụng UDF (hoặc một bảng số) khiến chúng theo cách đó.
Kết luận
Cho đến khi chúng ta có chức năng tách và nối nguyên bản trong SQL Server, chúng ta sẽ sử dụng tất cả các loại phương pháp không trực quan để hoàn thành công việc, bao gồm cả các hàm do người dùng xác định. Nếu bạn đang xử lý một chuỗi duy nhất tại một thời điểm, bạn sẽ không thấy nhiều sự khác biệt. Nhưng khi dữ liệu của bạn mở rộng, sẽ rất đáng để bạn thử nghiệm nhiều cách tiếp cận khác nhau (và tôi không có ý đề xuất rằng các phương pháp ở trên là tốt nhất mà bạn sẽ tìm thấy - ví dụ:tôi thậm chí còn không xem xét CLR, hoặc các cách tiếp cận T-SQL khác từ loạt bài này).



