Ngày nay, sao chép được đưa ra trong môi trường có tính khả dụng cao và khả năng chịu lỗi cho khá nhiều công nghệ cơ sở dữ liệu mà bạn đang sử dụng. Đó là một chủ đề mà chúng tôi đã xem đi xem lại, nhưng điều đó không bao giờ cũ.
Nếu bạn đang sử dụng TimescaleDB, loại sao chép phổ biến nhất là sao chép trực tuyến, nhưng nó hoạt động như thế nào?
Trong blog này, chúng tôi sẽ xem xét một số khái niệm liên quan đến sao chép và chúng tôi sẽ tập trung vào việc sao chép trực tuyến cho TimescaleDB, đây là một chức năng được kế thừa từ công cụ PostgreSQL cơ bản. Sau đó, chúng ta sẽ xem cách ClusterControl có thể giúp chúng ta định cấu hình nó.
Vì vậy, sao chép luồng dựa trên việc vận chuyển các bản ghi WAL và áp dụng chúng cho máy chủ dự phòng. Vì vậy, trước tiên, hãy xem WAL là gì.
WAL
Write Ahead Log (WAL) là một phương pháp tiêu chuẩn để đảm bảo tính toàn vẹn của dữ liệu, nó được tự động bật theo mặc định.
WAL là nhật ký REDO trong TimescaleDB. Nhưng, nhật ký REDO là gì?
Nhật ký REDO chứa tất cả các thay đổi đã được thực hiện trong cơ sở dữ liệu và chúng được sử dụng bằng cách tái tạo, phục hồi, sao lưu trực tuyến và khôi phục tại chỗ (PITR). Bất kỳ thay đổi nào chưa được áp dụng cho các trang dữ liệu có thể được thực hiện lại từ nhật ký REDO.
Sử dụng WAL dẫn đến giảm đáng kể số lần ghi vào đĩa, vì chỉ tệp nhật ký cần được lưu vào đĩa để đảm bảo rằng giao dịch được cam kết, thay vì mọi tệp dữ liệu được thay đổi bởi giao dịch.
Một bản ghi WAL sẽ chỉ định từng chút một, những thay đổi được thực hiện đối với dữ liệu. Mỗi bản ghi WAL sẽ được nối vào một tệp WAL. Vị trí chèn là Số thứ tự nhật ký (LSN) là một byte bù đắp vào nhật ký, tăng dần theo mỗi bản ghi mới.
Các WAL được lưu trữ trong thư mục pg_wal, trong thư mục dữ liệu. Các tệp này có kích thước mặc định là 16MB (có thể thay đổi kích thước bằng cách thay đổi tùy chọn cấu hình --with-wal-segsize khi xây dựng máy chủ). Chúng có một tên tăng dần duy nhất, ở định dạng sau:"00000001 00000000 00000000".
Số lượng tệp WAL có trong pg_wal sẽ phụ thuộc vào giá trị được gán cho thông số min_wal_size và max_wal_size trong tệp cấu hình postgresql.conf.
Một tham số mà chúng ta cần thiết lập khi định cấu hình tất cả các cài đặt TimescaleDB của chúng ta là wal_level. Nó xác định lượng thông tin được ghi vào WAL. Giá trị mặc định là tối thiểu, chỉ ghi thông tin cần thiết để khôi phục sau sự cố hoặc tắt máy ngay lập tức. Lưu trữ thêm ghi nhật ký cần thiết để lưu trữ WAL; hot_standby bổ sung thêm thông tin cần thiết để chạy các truy vấn chỉ đọc trên máy chủ dự phòng; và, cuối cùng lôgic bổ sung thông tin cần thiết để hỗ trợ giải mã lôgic. Thông số này yêu cầu khởi động lại, do đó, có thể khó thay đổi khi chạy cơ sở dữ liệu sản xuất nếu chúng tôi quên điều đó.
Sao chép truyền trực tuyến
Việc nhân rộng luồng dựa trên phương thức vận chuyển nhật ký. Các bản ghi WAL được chuyển trực tiếp từ máy chủ cơ sở dữ liệu này sang máy chủ cơ sở dữ liệu khác để được áp dụng. Có thể nói đó là PITR liên tục.
Việc chuyển này được thực hiện theo hai cách khác nhau, bằng cách chuyển các bản ghi WAL một tệp (phân đoạn WAL) tại một thời điểm (vận chuyển nhật ký dựa trên tệp) và bằng cách chuyển các bản ghi WAL (một tệp WAL bao gồm các bản ghi WAL) một cách nhanh chóng (dựa trên bản ghi ghi nhật ký vận chuyển), giữa một máy chủ chính và một hoặc một số máy chủ phụ, mà không cần đợi tệp WAL được điền.
Trong thực tế, một quá trình được gọi là bộ thu WAL, chạy trên máy chủ phụ, sẽ kết nối với máy chủ chính bằng kết nối TCP / IP. Trong máy chủ chính, tồn tại một quá trình khác, có tên là người gửi WAL và chịu trách nhiệm gửi các đăng ký WAL đến máy chủ phụ khi chúng xảy ra.
Sao chép luồng có thể được biểu diễn như sau:
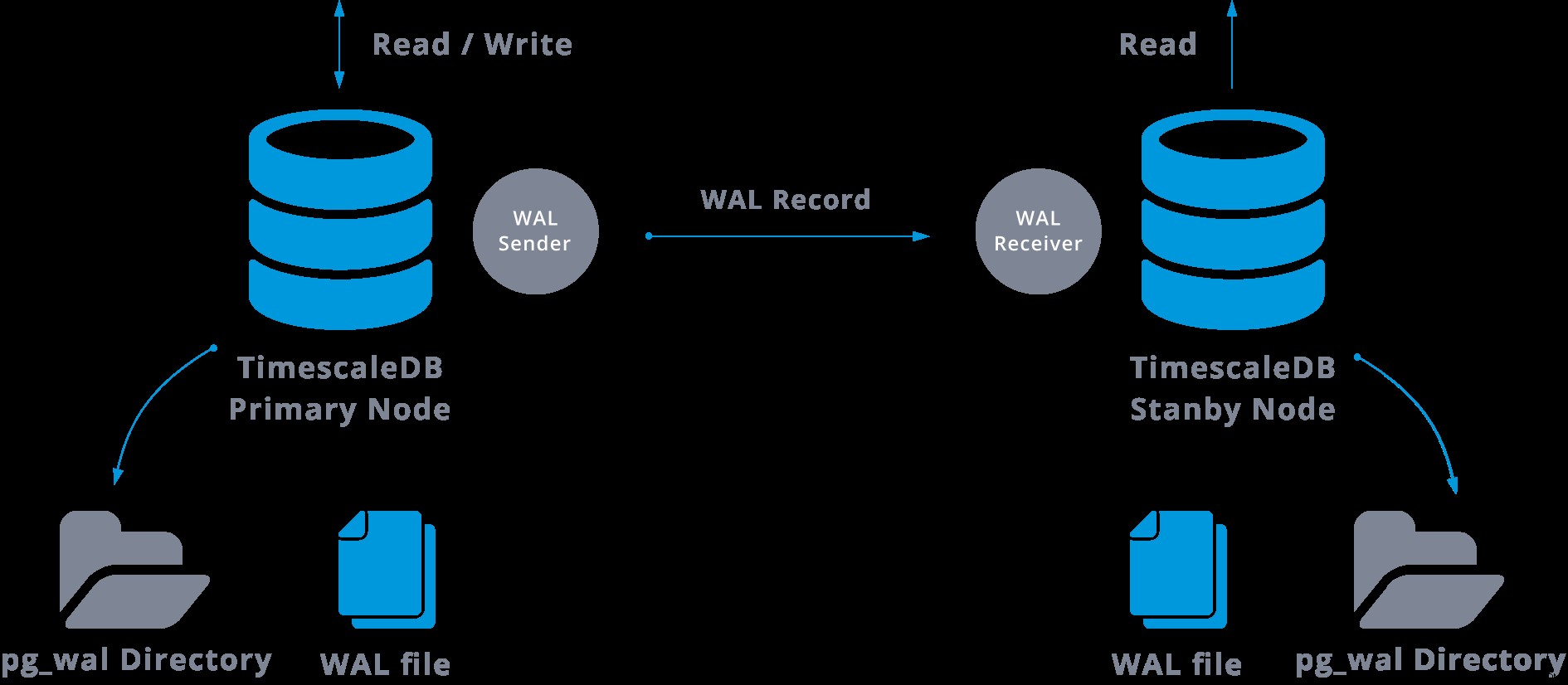
Bằng cách nhìn vào sơ đồ trên, chúng ta có thể nghĩ, điều gì sẽ xảy ra khi giao tiếp giữa người gửi WAL và người nhận WAL không thành công?
Khi định cấu hình sao chép trực tuyến, chúng tôi có tùy chọn để bật lưu trữ WAL.
Bước này thực ra không bắt buộc, nhưng cực kỳ quan trọng để thiết lập sao chép mạnh mẽ, vì cần tránh máy chủ chính tái chế các tệp WAL cũ chưa được áp dụng cho máy chủ. Nếu điều này xảy ra, chúng tôi sẽ cần tạo lại bản sao từ đầu.
Khi định cấu hình sao chép với lưu trữ liên tục, chúng tôi đang bắt đầu từ một bản sao lưu và để đạt được trạng thái đồng bộ hóa với bản chính, chúng tôi cần áp dụng tất cả các thay đổi được lưu trữ trong WAL đã xảy ra sau khi sao lưu. Trong quá trình này, chế độ chờ trước tiên sẽ khôi phục tất cả WAL có sẵn trong vị trí lưu trữ (được thực hiện bằng cách gọi lệnh restore_command). Lệnh khôi phục sẽ không thành công khi chúng ta đến bản ghi WAL được lưu trữ cuối cùng, vì vậy sau đó, chế độ chờ sẽ xem xét thư mục pg_wal để xem liệu thay đổi có tồn tại ở đó hay không (điều này thực sự được thực hiện để tránh mất dữ liệu khi máy chủ chính gặp sự cố và một số những thay đổi đã được chuyển vào bản sao và được áp dụng vẫn chưa được lưu trữ).
Nếu không thành công và bản ghi được yêu cầu không tồn tại ở đó, thì nó sẽ bắt đầu giao tiếp với bản gốc thông qua sao chép trực tuyến.
Bất cứ khi nào sao chép luồng không thành công, nó sẽ quay lại bước 1 và khôi phục lại các bản ghi từ kho lưu trữ. Vòng lặp truy xuất này từ kho lưu trữ, pg_wal và thông qua sao chép trực tuyến tiếp tục cho đến khi máy chủ bị dừng hoặc chuyển đổi dự phòng được kích hoạt bởi một tệp trình kích hoạt.
Đây sẽ là một sơ đồ của cấu hình như vậy:
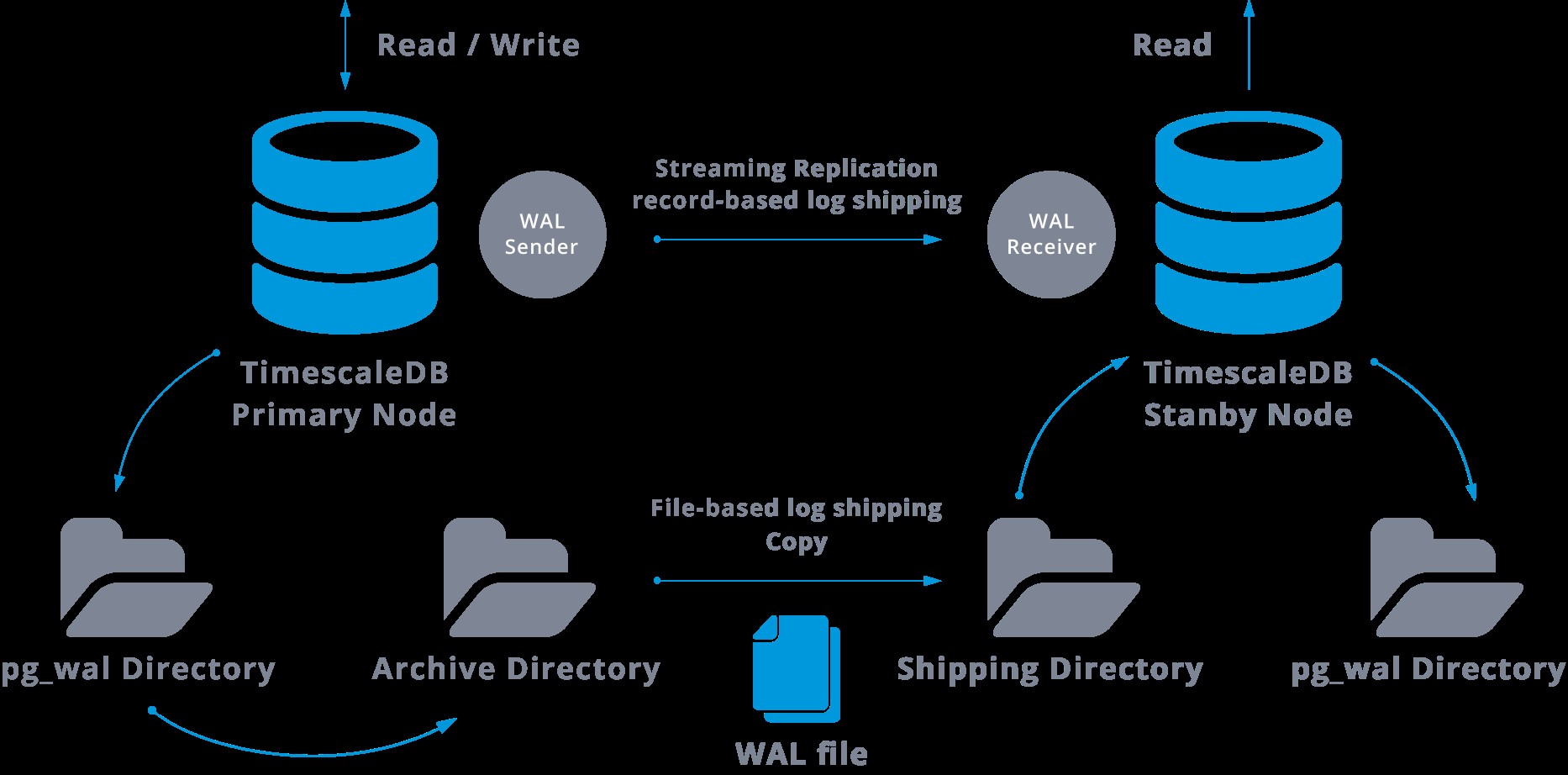
Theo mặc định, sao chép luồng là không đồng bộ, vì vậy tại một số thời điểm nhất định, chúng tôi có thể có một số giao dịch có thể được cam kết trong bản chính và chưa được sao chép vào máy chủ dự phòng. Điều này ngụ ý một số khả năng mất dữ liệu.
Tuy nhiên, độ trễ giữa cam kết và tác động của những thay đổi trong bản sao được cho là thực sự nhỏ (vài mili giây), tất nhiên giả sử rằng máy chủ bản sao đủ mạnh để theo kịp tải.
Đối với những trường hợp ngay cả rủi ro mất mát dữ liệu nhỏ cũng không thể chấp nhận được, chúng tôi có thể sử dụng tính năng sao chép đồng bộ.
Trong sao chép đồng bộ, mỗi cam kết của một giao dịch ghi sẽ đợi cho đến khi nhận được xác nhận rằng cam kết đã được ghi vào nhật ký ghi trước trên đĩa của cả máy chủ chính và máy chủ dự phòng.
Phương pháp này giảm thiểu khả năng mất dữ liệu, vì để điều đó xảy ra, chúng tôi sẽ cần cả bản chính và chế độ chờ cùng một lúc không hoạt động.
Nhược điểm rõ ràng của cấu hình này là thời gian phản hồi cho mỗi giao dịch ghi tăng lên, vì chúng ta cần đợi cho đến khi tất cả các bên đã phản hồi. Vì vậy, thời gian cho một lần cam kết, tối thiểu là chuyến đi khứ hồi giữa bản chính và bản sao. Giao dịch chỉ đọc sẽ không bị ảnh hưởng bởi điều đó.
Để thiết lập sao chép đồng bộ, chúng ta cần cho mỗi máy chủ dự phòng chỉ định tên_dung_dục trong primary_conninfo của tệp recovery.conf:primary_conninfo ='... aplication_name =slaveX'.
Chúng tôi cũng cần chỉ định danh sách các máy chủ dự phòng sẽ tham gia vào quá trình sao chép đồng bộ:sync_standby_name ='slaveX, slaveY'.
Chúng tôi có thể thiết lập một hoặc một số máy chủ đồng bộ và thông số này cũng chỉ định phương pháp (ĐẦU TIÊN và BẤT KỲ) để chọn các dự phòng đồng bộ từ các dự phòng được liệt kê.
Để triển khai TimescaleDB với các thiết lập sao chép trực tuyến (đồng bộ hoặc không đồng bộ), chúng ta có thể sử dụng ClusterControl, như chúng ta có thể thấy ở đây.
Sau khi chúng tôi đã định cấu hình bản sao của mình và nó bắt đầu hoạt động, chúng tôi sẽ cần có một số tính năng bổ sung để theo dõi và quản lý sao lưu. ClusterControl cho phép chúng tôi theo dõi và quản lý các bản sao lưu / lưu giữ cụm TimescaleDB của chúng tôi từ cùng một nơi mà không cần bất kỳ công cụ bên ngoài nào.
Cách định cấu hình sao chép phát trực tuyến trên TimescaleDB
Thiết lập tính năng sao chép trực tuyến là một công việc đòi hỏi một số bước phải được tuân thủ kỹ lưỡng. Nếu bạn muốn định cấu hình nó theo cách thủ công, bạn có thể theo dõi blog của chúng tôi về chủ đề này.
Tuy nhiên, bạn có thể triển khai hoặc nhập TimescaleDB hiện tại của mình trên ClusterControl và sau đó, bạn có thể định cấu hình sao chép phát trực tuyến bằng một vài cú nhấp chuột. Hãy xem chúng ta có thể làm điều đó như thế nào.
Đối với nhiệm vụ này, chúng tôi sẽ giả sử bạn có cụm TimescaleDB của mình được quản lý bởi ClusterControl. Đi tới ClusterControl -> Chọn Cluster -> Cluster Actions -> Thêm Replication Slave.
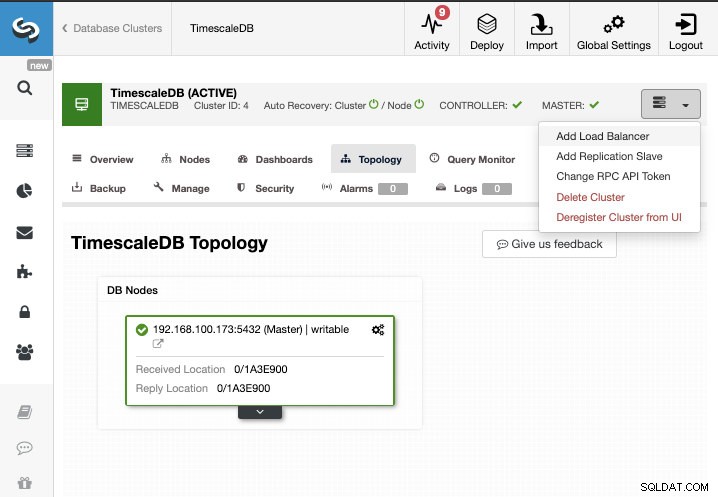
Chúng tôi có thể tạo một nô lệ sao chép mới (chế độ chờ) hoặc chúng tôi có thể nhập một nô lệ hiện có. Trong trường hợp này, chúng tôi sẽ tạo một cái mới.
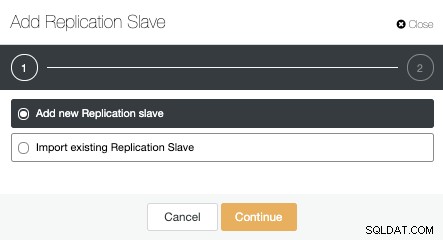
Bây giờ, chúng ta phải chọn nút Chính, thêm Địa chỉ IP hoặc tên máy chủ cho máy chủ dự phòng mới và cổng cơ sở dữ liệu. Chúng tôi cũng có thể chỉ định nếu chúng tôi muốn ClusterControl cài đặt phần mềm và nếu chúng tôi muốn định cấu hình sao chép luồng đồng bộ hoặc không đồng bộ.
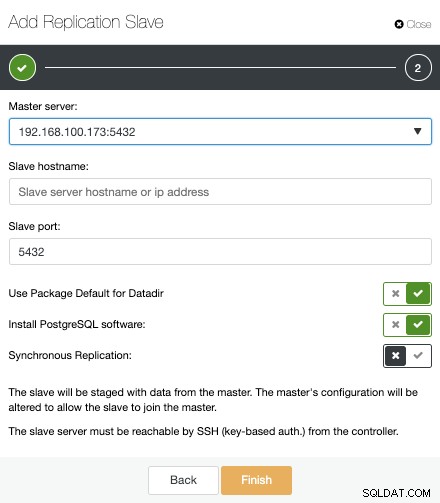
Đó là tất cả. Chúng ta chỉ cần đợi cho đến khi ClusterControl hoàn thành công việc. Chúng tôi có thể theo dõi trạng thái từ phần Hoạt động.
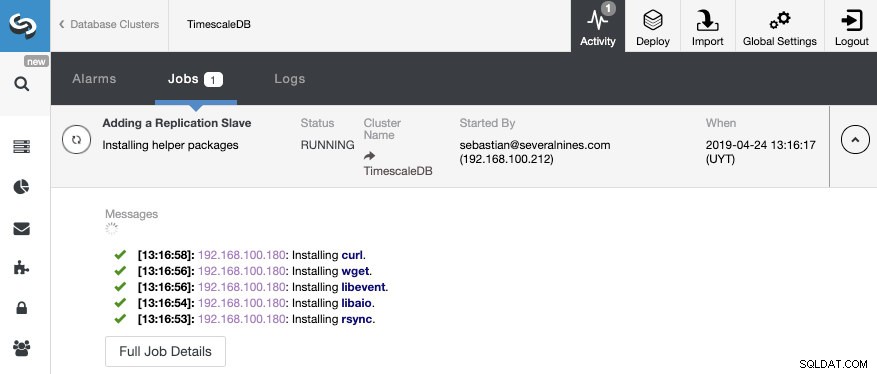
Sau khi công việc kết thúc, chúng ta nên định cấu hình bản sao truyền trực tuyến và chúng ta có thể kiểm tra cấu trúc liên kết mới trong phần Chế độ xem cấu trúc liên kết ClusterControl.
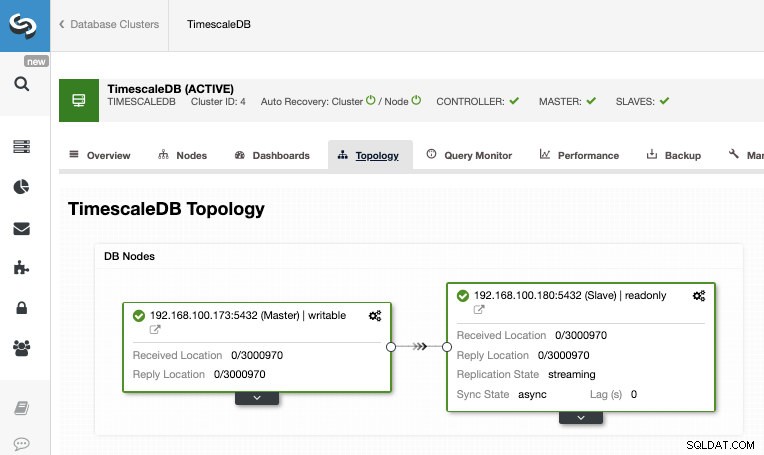
Bằng cách sử dụng ClusterControl, bạn cũng có thể thực hiện một số tác vụ quản lý trên TimescaleDB của mình như sao lưu, giám sát và cảnh báo, tự động chuyển đổi dự phòng, thêm nút, thêm bộ cân bằng tải, v.v.
Chuyển đổi dự phòng
Như chúng ta có thể thấy, TimescaleDB sử dụng một luồng bản ghi ghi nhật ký ghi trước (WAL) để giữ cho cơ sở dữ liệu dự phòng được đồng bộ hóa. Nếu máy chủ chính bị lỗi, máy chủ dự phòng chứa gần như toàn bộ dữ liệu của máy chủ chính và có thể nhanh chóng làm máy chủ cơ sở dữ liệu chủ mới. Điều này có thể đồng bộ hoặc không đồng bộ và chỉ có thể được thực hiện cho toàn bộ máy chủ cơ sở dữ liệu.
Để đảm bảo tính khả dụng cao một cách hiệu quả, chỉ cần có kiến trúc dự phòng chính là chưa đủ. Chúng tôi cũng cần bật một số hình thức chuyển đổi dự phòng tự động, vì vậy nếu có sự cố nào đó, chúng tôi có thể có độ trễ nhỏ nhất có thể để khôi phục lại chức năng bình thường.
TimescaleDB không bao gồm cơ chế chuyển đổi dự phòng tự động để xác định các lỗi trên cơ sở dữ liệu chính và thông báo cho máy chủ sở hữu quyền sở hữu, do đó, điều này sẽ yêu cầu một chút công việc từ phía DBA. Bạn cũng sẽ chỉ có một máy chủ hoạt động, vì vậy cần phải tạo lại kiến trúc chế độ chờ chính, để chúng tôi quay lại tình trạng bình thường như trước khi sự cố xảy ra.
ClusterControl bao gồm một tính năng tự động chuyển đổi dự phòng cho TimescaleDB để cải thiện thời gian sửa chữa trung bình (MTTR) trong môi trường sẵn sàng cao của bạn. Trong trường hợp không thành công, ClusterControl sẽ thăng cấp nô lệ cao cấp nhất thành chủ và nó sẽ định cấu hình lại (các) nô lệ còn lại để kết nối với chủ mới. HAProxy cũng có thể được triển khai tự động để cung cấp một điểm cuối cơ sở dữ liệu duy nhất cho các ứng dụng, do đó chúng không bị ảnh hưởng bởi sự thay đổi của máy chủ chính.
Hạn chế
Các tài nguyên liên quan ClusterControl for TimescaleDB Cách dễ dàng triển khai TimescaleDB PostgreSQL Streaming Replication - một Deep DiveChúng tôi có một số hạn chế nổi tiếng khi sử dụng tính năng Sao chép trực tuyến:
- Chúng tôi không thể sao chép thành một phiên bản hoặc kiến trúc khác
- Chúng tôi không thể thay đổi bất kỳ điều gì trên máy chủ dự phòng
- Chúng tôi không có nhiều thông tin chi tiết về những gì chúng tôi có thể tái tạo
Vì vậy, để khắc phục những hạn chế này, chúng ta có tính năng sao chép hợp lý. Để biết thêm về kiểu sao chép này, bạn có thể xem blog sau.
Kết luận
Cấu trúc liên kết tổng thể ở chế độ chờ có nhiều cách sử dụng khác nhau như phân tích, sao lưu, tính sẵn sàng cao, chuyển đổi dự phòng. Trong mọi trường hợp, cần phải hiểu cách hoạt động của tính năng sao chép phát trực tuyến trên TimescaleDB. Nó cũng hữu ích nếu có một hệ thống để quản lý tất cả các cụm và cung cấp cho bạn khả năng tạo cấu trúc liên kết này một cách dễ dàng. Trong blog này, chúng tôi đã biết cách đạt được điều đó bằng cách sử dụng ClusterControl và chúng tôi đã xem xét một số khái niệm cơ bản về sao chép trực tuyến.