Bối cảnh
Một trong những điều đầu tiên tôi xem xét khi khắc phục sự cố về hiệu suất là thống kê thời gian chờ qua DMV sys.dm_os_wait_stats. Để xem SQL Server đang chờ gì, tôi sử dụng truy vấn từ bộ Truy vấn chẩn đoán SQL Server hiện tại của Glenn Berry. Tùy thuộc vào kết quả đầu ra, tôi bắt đầu đào sâu vào các khu vực cụ thể trong SQL Server.
Ví dụ:nếu tôi thấy CXPACKET chờ đợi cao, tôi sẽ kiểm tra số lõi trên máy chủ, số nút NUMA và các giá trị cho mức độ song song tối đa và ngưỡng chi phí cho tính song song. Đây là thông tin cơ bản mà tôi sử dụng để hiểu cấu hình. Trước khi cân nhắc thực hiện bất kỳ thay đổi nào, tôi thu thập thêm dữ liệu định lượng, vì một hệ thống có CXPACKET chờ không nhất thiết có cài đặt sai cho mức độ song song tối đa.
Tương tự, một hệ thống có thời gian chờ cao đối với các kiểu chờ liên quan đến I / O như PAGEIOLATCH_XX, WRITELOG và IO_COMPLETION không nhất thiết phải có hệ thống con lưu trữ kém hơn. Khi tôi thấy các kiểu chờ liên quan đến I / O là hàng đợi trên cùng, tôi ngay lập tức muốn hiểu thêm về bộ nhớ cơ bản. Đó là bộ nhớ gắn trực tiếp hay SAN? Mức RAID là gì, có bao nhiêu đĩa tồn tại trong mảng và tốc độ của các đĩa là gì? Tôi cũng muốn biết liệu các tệp hoặc cơ sở dữ liệu khác có chia sẻ bộ nhớ hay không. Và mặc dù điều quan trọng là phải hiểu cấu hình, nhưng bước tiếp theo hợp lý là xem số liệu thống kê tệp ảo thông qua sys.dm_io_virtual_file_stats DMV.
Được giới thiệu trong SQL Server 2005, DMV này là sự thay thế cho hàm fn_virtualfilestats mà những bạn đã chạy trên SQL Server 2000 trở về trước có thể biết và yêu thích. DMV chứa thông tin I / O tích lũy cho mỗi tệp cơ sở dữ liệu, nhưng dữ liệu sẽ đặt lại khi khởi động lại phiên bản, khi cơ sở dữ liệu bị đóng, được thực hiện ngoại tuyến, tách ra và gắn lại, v.v. Điều quan trọng là phải hiểu rằng dữ liệu thống kê tệp ảo không đại diện cho hiện tại hiệu suất - đó là ảnh chụp nhanh là tổng hợp dữ liệu I / O kể từ lần xóa cuối cùng bởi một trong các sự kiện nói trên. Mặc dù dữ liệu không mang tính thời điểm nhưng nó vẫn có thể hữu ích. Nếu thời gian chờ cao nhất cho một phiên bản liên quan đến I / O, nhưng thời gian chờ trung bình dưới 10 mili giây, thì bộ nhớ có thể không phải là vấn đề - nhưng tương quan đầu ra với những gì bạn thấy trong sys.dm_io_virtual_stats vẫn đáng để xác nhận. độ trễ. Hơn nữa, ngay cả khi bạn thấy độ trễ cao trong sys.dm_io_virtual_stats, bạn vẫn chưa chứng minh được rằng bộ nhớ là một vấn đề.
Thiết lập
Để xem số liệu thống kê về tệp ảo, tôi đã thiết lập hai bản sao của cơ sở dữ liệu AdventureWorks2012, bạn có thể tải xuống từ Codeplex. Đối với bản sao đầu tiên, sau đây được gọi là EX_AdventureWorks2012, tôi đã chạy tập lệnh của Jonathan Kehayias để mở rộng bảng Sales.SalesOrderHeader và Sales.SalesOrderDetail thành 1,2 triệu và 4,9 triệu hàng, tương ứng. Đối với cơ sở dữ liệu thứ hai, BIG_AdventureWorks2012, tôi đã sử dụng tập lệnh từ bài đăng phân vùng trước đó của mình để tạo bản sao của bảng Sales.SalesOrderHeader với 123 triệu hàng. Cả hai cơ sở dữ liệu đều được lưu trữ trên ổ USB bên ngoài (Seagate Slim 500GB), với tempdb trên đĩa cục bộ (SSD) của tôi.
Trước khi thử nghiệm, tôi đã tạo bốn thủ tục được lưu trữ tùy chỉnh trong mỗi cơ sở dữ liệu (Create_Custom_SPs.zip), sẽ đóng vai trò là khối lượng công việc "bình thường" của tôi. Quy trình thử nghiệm của tôi như sau cho từng cơ sở dữ liệu:
- Khởi động lại phiên bản.
- Ghi lại số liệu thống kê về tệp ảo.
- Chạy khối lượng công việc "bình thường" trong hai phút (các thủ tục được gọi nhiều lần qua tập lệnh PowerShell).
- Ghi lại số liệu thống kê về tệp ảo.
- Tạo lại tất cả các chỉ mục cho (các) bảng SalesOrder thích hợp.
- Ghi lại số liệu thống kê về tệp ảo.
Dữ liệu
Để nắm bắt số liệu thống kê tệp ảo, tôi đã tạo một bảng để chứa thông tin lịch sử, sau đó sử dụng một biến thể của truy vấn của Jimmy May từ tập lệnh DMV All-Stars của anh ấy cho ảnh chụp nhanh:
USE [msdb];
GO
CREATE TABLE [dbo].[SQLskills_FileLatency]
(
[RowID] [INT] IDENTITY(1,1) NOT NULL,
[CaptureID] [INT] NOT NULL,
[CaptureDate] [DATETIME2](7) NULL,
[ReadLatency] [BIGINT] NULL,
[WriteLatency] [BIGINT] NULL,
[Latency] [BIGINT] NULL,
[AvgBPerRead] [BIGINT] NULL,
[AvgBPerWrite] [BIGINT] NULL,
[AvgBPerTransfer] [BIGINT] NULL,
[Drive] [NVARCHAR](2) NULL,
[DB] [NVARCHAR](128) NULL,
[database_id] [SMALLINT] NOT NULL,
[file_id] [SMALLINT] NOT NULL,
[sample_ms] [INT] NOT NULL,
[num_of_reads] [BIGINT] NOT NULL,
[num_of_bytes_read] [BIGINT] NOT NULL,
[io_stall_read_ms] [BIGINT] NOT NULL,
[num_of_writes] [BIGINT] NOT NULL,
[num_of_bytes_written] [BIGINT] NOT NULL,
[io_stall_write_ms] [BIGINT] NOT NULL,
[io_stall] [BIGINT] NOT NULL,
[size_on_disk_MB] [NUMERIC](25, 6) NULL,
[file_handle] [VARBINARY](8) NOT NULL,
[physical_name] [NVARCHAR](260) NOT NULL
) ON [PRIMARY];
GO
CREATE CLUSTERED INDEX CI_SQLskills_FileLatency ON [dbo].[SQLskills_FileLatency] ([CaptureDate], [RowID]);
CREATE NONCLUSTERED INDEX NCI_SQLskills_FileLatency ON [dbo].[SQLskills_FileLatency] ([CaptureID]);
DECLARE @CaptureID INT;
SELECT @CaptureID = MAX(CaptureID) FROM [msdb].[dbo].[SQLskills_FileLatency];
PRINT (@CaptureID);
IF @CaptureID IS NULL
BEGIN
SET @CaptureID = 1;
END
ELSE
BEGIN
SET @CaptureID = @CaptureID + 1;
END
INSERT INTO [msdb].[dbo].[SQLskills_FileLatency]
(
[CaptureID],
[CaptureDate],
[ReadLatency],
[WriteLatency],
[Latency],
[AvgBPerRead],
[AvgBPerWrite],
[AvgBPerTransfer],
[Drive],
[DB],
[database_id],
[file_id],
[sample_ms],
[num_of_reads],
[num_of_bytes_read],
[io_stall_read_ms],
[num_of_writes],
[num_of_bytes_written],
[io_stall_write_ms],
[io_stall],
[size_on_disk_MB],
[file_handle],
[physical_name]
)
SELECT
--virtual file latency
@CaptureID,
GETDATE(),
CASE
WHEN [num_of_reads] = 0
THEN 0
ELSE ([io_stall_read_ms]/[num_of_reads])
END [ReadLatency],
CASE
WHEN [io_stall_write_ms] = 0
THEN 0
ELSE ([io_stall_write_ms]/[num_of_writes])
END [WriteLatency],
CASE
WHEN ([num_of_reads] = 0 AND [num_of_writes] = 0)
THEN 0
ELSE ([io_stall]/([num_of_reads] + [num_of_writes]))
END [Latency],
--avg bytes per IOP
CASE
WHEN [num_of_reads] = 0
THEN 0
ELSE ([num_of_bytes_read]/[num_of_reads])
END [AvgBPerRead],
CASE
WHEN [io_stall_write_ms] = 0
THEN 0
ELSE ([num_of_bytes_written]/[num_of_writes])
END [AvgBPerWrite],
CASE
WHEN ([num_of_reads] = 0 AND [num_of_writes] = 0)
THEN 0
ELSE (([num_of_bytes_read] + [num_of_bytes_written])/([num_of_reads] + [num_of_writes]))
END [AvgBPerTransfer],
LEFT([mf].[physical_name],2) [Drive],
DB_NAME([vfs].[database_id]) [DB],
[vfs].[database_id],
[vfs].[file_id],
[vfs].[sample_ms],
[vfs].[num_of_reads],
[vfs].[num_of_bytes_read],
[vfs].[io_stall_read_ms],
[vfs].[num_of_writes],
[vfs].[num_of_bytes_written],
[vfs].[io_stall_write_ms],
[vfs].[io_stall],
[vfs].[size_on_disk_bytes]/1024/1024. [size_on_disk_MB],
[vfs].[file_handle],
[mf].[physical_name]
FROM [sys].[dm_io_virtual_file_stats](NULL,NULL) AS vfs
JOIN [sys].[master_files] [mf]
ON [vfs].[database_id] = [mf].[database_id]
AND [vfs].[file_id] = [mf].[file_id]
ORDER BY [Latency] DESC; Tôi khởi động lại phiên bản và sau đó thu thập số liệu thống kê tệp ngay lập tức. Khi tôi lọc đầu ra để chỉ xem các tệp cơ sở dữ liệu EX_AdventureWorks2012 và tempdb, chỉ dữ liệu tempdb được ghi lại vì không có dữ liệu nào được yêu cầu từ cơ sở dữ liệu EX_AdventureWorks2012:

Đầu ra từ quá trình chụp ban đầu của sys.dm_os_virtual_file_stats
Sau đó, tôi đã chạy khối lượng công việc "bình thường" trong hai phút (số lần thực thi của mỗi thủ tục được lưu trữ hơi khác nhau) và sau khi nó hoàn thành thống kê tệp đã chụp một lần nữa:

Đầu ra từ sys.dm_os_virtual_file_stats sau khối lượng công việc bình thường
Chúng tôi thấy độ trễ là 57ms cho tệp dữ liệu EX_AdventureWorks2012. Không phải là lý tưởng, nhưng theo thời gian với khối lượng công việc bình thường của tôi, điều này có thể sẽ xảy ra. Có độ trễ tối thiểu cho tempdb, điều này được mong đợi vì khối lượng công việc tôi đã chạy không tạo ra nhiều hoạt động tempdb. Tiếp theo, tôi xây dựng lại tất cả các chỉ mục cho các bảng Sales.SalesOrderHeaderEnlarged và Sales.SalesOrderDetailEnlarged:
USE [EX_AdventureWorks2012]; GO ALTER INDEX ALL ON Sales.SalesOrderHeaderEnlarged REBUILD; ALTER INDEX ALL ON Sales.SalesOrderDetailEnlarged REBUILD;
Quá trình xây dựng lại mất chưa đầy một phút và nhận thấy độ trễ đọc tăng đột biến đối với tệp dữ liệu EX_AdventureWorks2012 và độ trễ ghi tăng đột biến đối với dữ liệu EX_AdventureWorks2012 và tệp nhật ký:

Đầu ra từ sys.dm_os_virtual_file_stats sau khi xây dựng lại chỉ mục
Theo ảnh chụp nhanh về số liệu thống kê tệp, độ trễ là khủng khiếp; hơn 600ms để ghi! Nếu tôi nhìn thấy giá trị này đối với một hệ thống sản xuất, sẽ dễ dàng ngay lập tức nghi ngờ các vấn đề về lưu trữ. Tuy nhiên, cũng cần lưu ý rằng AvgBPerWrite cũng tăng lên và việc ghi khối lớn hơn sẽ mất nhiều thời gian hơn để hoàn thành. Mức tăng AvgBPerWrite được mong đợi cho tác vụ xây dựng lại chỉ mục.
Hãy hiểu rằng khi bạn nhìn vào dữ liệu này, bạn sẽ không có được một bức tranh hoàn chỉnh. Cách tốt hơn để xem độ trễ bằng cách sử dụng số liệu thống kê tệp ảo là chụp ảnh nhanh và sau đó tính toán độ trễ trong khoảng thời gian đã trôi qua. Ví dụ:tập lệnh bên dưới sử dụng hai ảnh chụp nhanh (Hiện tại và Trước đó) rồi tính số lần đọc và ghi trong khoảng thời gian đó, sự khác biệt về giá trị io_stall_read_ms và io_stall_write_ms, sau đó chia io_stall_read_ms delta cho số lần đọc và io_stall_write_ms delta cho số lần viết. Với phương pháp này, chúng tôi tính toán lượng thời gian SQL Server chờ đợi trên I / O để đọc hoặc ghi, sau đó chia nó cho số lần đọc hoặc ghi để xác định độ trễ.
DECLARE @CurrentID INT, @PreviousID INT; SET @CurrentID = 3; SET @PreviousID = @CurrentID - 1; WITH [p] AS ( SELECT [CaptureDate], [database_id], [file_id], [ReadLatency], [WriteLatency], [num_of_reads], [io_stall_read_ms], [num_of_writes], [io_stall_write_ms] FROM [msdb].[dbo].[SQLskills_FileLatency] WHERE [CaptureID] = @PreviousID ) SELECT [c].[CaptureDate] [CurrentCaptureDate], [p].[CaptureDate] [PreviousCaptureDate], DATEDIFF(MINUTE, [p].[CaptureDate], [c].[CaptureDate]) [MinBetweenCaptures], [c].[DB], [c].[physical_name], [c].[ReadLatency] [CurrentReadLatency], [p].[ReadLatency] [PreviousReadLatency], [c].[WriteLatency] [CurrentWriteLatency], [p].[WriteLatency] [PreviousWriteLatency], [c].[io_stall_read_ms]- [p].[io_stall_read_ms] [delta_io_stall_read], [c].[num_of_reads] - [p].[num_of_reads] [delta_num_of_reads], [c].[io_stall_write_ms] - [p].[io_stall_write_ms] [delta_io_stall_write], [c].[num_of_writes] - [p].[num_of_writes] [delta_num_of_writes], CASE WHEN ([c].[num_of_reads] - [p].[num_of_reads]) = 0 THEN NULL ELSE ([c].[io_stall_read_ms] - [p].[io_stall_read_ms])/([c].[num_of_reads] - [p].[num_of_reads]) END [IntervalReadLatency], CASE WHEN ([c].[num_of_writes] - [p].[num_of_writes]) = 0 THEN NULL ELSE ([c].[io_stall_write_ms] - [p].[io_stall_write_ms])/([c].[num_of_writes] - [p].[num_of_writes]) END [IntervalWriteLatency] FROM [msdb].[dbo].[SQLskills_FileLatency] [c] JOIN [p] ON [c].[database_id] = [p].[database_id] AND [c].[file_id] = [p].[file_id] WHERE [c].[CaptureID] = @CurrentID AND [c].[database_id] IN (2, 11);
Khi chúng tôi thực hiện điều này để tính toán độ trễ trong quá trình xây dựng lại chỉ mục, chúng tôi nhận được như sau:

Độ trễ được tính từ sys.dm_io_virtual_file_stats trong quá trình xây dựng lại chỉ mục cho EX_AdventureWorks2012
Bây giờ chúng ta có thể thấy rằng độ trễ thực tế trong thời gian đó là cao - điều mà chúng ta mong đợi. Và nếu sau đó chúng tôi quay trở lại khối lượng công việc bình thường của mình và chạy nó trong vài giờ, các giá trị trung bình được tính toán từ thống kê tệp ảo sẽ giảm theo thời gian. Trên thực tế, nếu chúng ta nhìn vào dữ liệu PerfMon được thu thập trong quá trình thử nghiệm (và sau đó được xử lý thông qua PAL), chúng ta thấy mức tăng đột biến đáng kể trong Vị trí trung bình. Đĩa giây / Đọc và Tr.bình Disk sec / Write tương quan với thời gian mà bản xây dựng lại chỉ mục đang chạy. Nhưng vào những thời điểm khác, giá trị độ trễ thấp hơn nhiều so với giá trị có thể chấp nhận được:
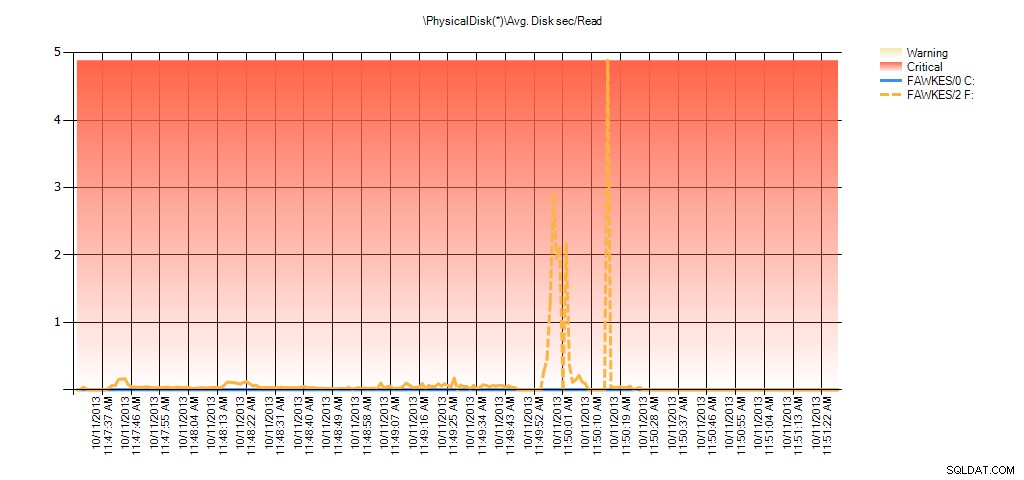
Tóm tắt về số giây / đọc trên đĩa trung bình từ PAL cho EX_AdventureWorks2012 trong quá trình thử nghiệm
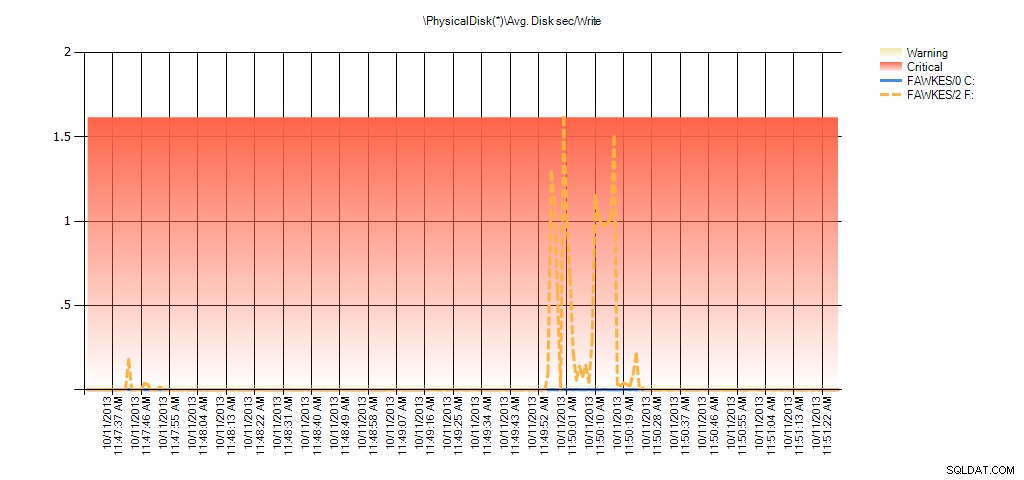
Tóm tắt về tính năng ghi / ghi trên đĩa trung bình từ PAL cho EX_AdventureWorks2012 trong quá trình thử nghiệm
Bạn có thể thấy hành vi tương tự đối với cơ sở dữ liệu BIG_AdventureWorks 2012. Đây là thông tin về độ trễ dựa trên ảnh chụp nhanh thống kê tệp ảo trước khi xây dựng lại chỉ mục và sau khi xây dựng lại chỉ mục:

Độ trễ được tính từ sys.dm_io_virtual_file_stats trong quá trình xây dựng lại chỉ mục cho BIG_AdventureWorks2012
Và dữ liệu Giám sát hiệu suất hiển thị cùng một mức tăng đột biến trong quá trình xây dựng lại:
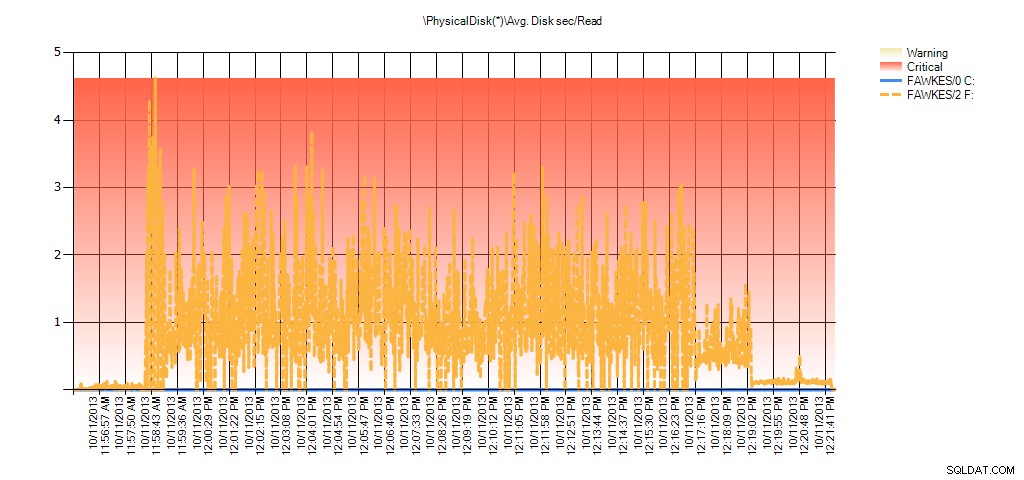
Tóm tắt về số giây / đọc trên đĩa trung bình từ PAL cho BIG_AdventureWorks2012 trong quá trình thử nghiệm
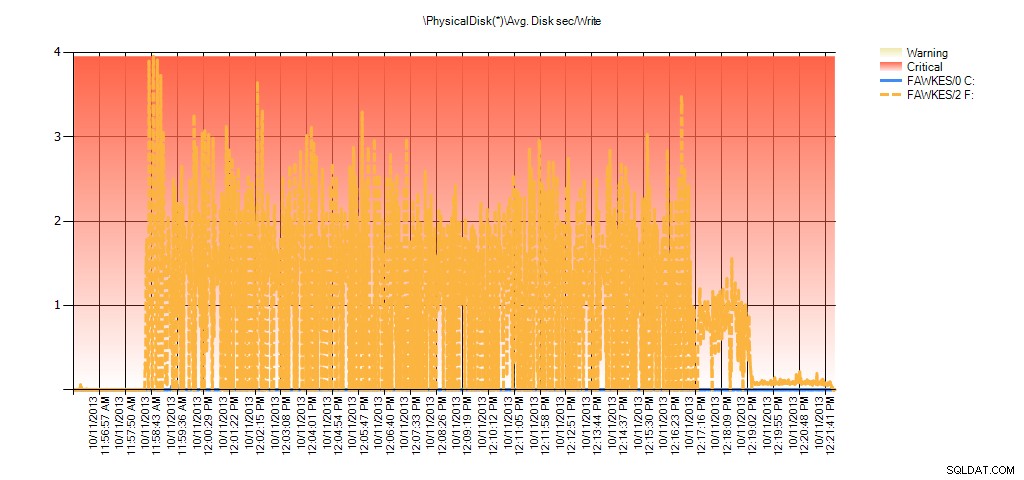
Tóm tắt về tính năng ghi / ghi trên đĩa trung bình từ PAL cho BIG_AdventureWorks2012 trong quá trình thử nghiệm
Kết luận
Số liệu thống kê tệp ảo là một điểm khởi đầu tuyệt vời khi bạn muốn hiểu hiệu suất I / O cho một phiên bản SQL Server. Nếu bạn thấy số lần chờ liên quan đến I / O khi xem thống kê thời gian chờ, thì xem sys.dm_io_virtual_file_stats là bước tiếp theo hợp lý. Tuy nhiên, hãy hiểu rằng dữ liệu bạn đang xem là dữ liệu tổng hợp kể từ khi thống kê bị xóa lần cuối bởi một trong các sự kiện liên quan (khởi động lại phiên bản, ngoại tuyến của cơ sở dữ liệu, v.v.). Nếu bạn thấy độ trễ thấp, thì hệ thống con I / O đang theo kịp với tải hiệu suất. Tuy nhiên, nếu bạn thấy độ trễ cao, thì không phải kết luận trước rằng bộ nhớ là một vấn đề. Để thực sự biết điều gì đang xảy ra, bạn có thể bắt đầu xem nhanh số liệu thống kê của tệp, như được hiển thị ở đây hoặc bạn có thể chỉ cần sử dụng Trình theo dõi hiệu suất để xem độ trễ trong thời gian thực. Rất dễ dàng để tạo Bộ thu thập dữ liệu trong PerfMon để ghi lại vị trí trung bình của bộ đếm đĩa vật lý. Disk Sec / Read và Avg. Disk Sec / Read cho tất cả các đĩa lưu trữ các tệp cơ sở dữ liệu. Lên lịch để Trình thu thập dữ liệu bắt đầu và dừng thường xuyên và lấy mẫu mỗi n giây (ví dụ:15) và khi bạn đã nắm bắt được dữ liệu PerfMon trong một thời điểm thích hợp, hãy chạy nó qua PAL để kiểm tra độ trễ theo thời gian.
Nếu bạn nhận thấy rằng độ trễ I / O xảy ra trong khối lượng công việc bình thường của bạn và không chỉ trong các tác vụ bảo trì thúc đẩy I / O, bạn vẫn vẫn không thể chỉ ra bộ nhớ là vấn đề cơ bản. Độ trễ lưu trữ có thể tồn tại vì nhiều lý do, chẳng hạn như:
- Máy chủ SQL phải đọc quá nhiều dữ liệu do kế hoạch truy vấn không hiệu quả hoặc thiếu chỉ mục
- Quá ít bộ nhớ được cấp cho phiên bản và cùng một dữ liệu được đọc đi đọc lại từ đĩa vì nó không thể ở trong bộ nhớ
- Chuyển đổi ngầm định gây ra chỉ mục hoặc quét bảng
- Các truy vấn thực hiện SELECT * khi không phải tất cả các cột đều được yêu cầu
- Sự cố bản ghi được chuyển tiếp trong đống gây ra thêm I / O
- Mật độ trang thấp do phân mảnh chỉ mục, tách trang hoặc cài đặt hệ số lấp đầy không chính xác gây ra thêm I / O
Cho dù nguyên nhân gốc rễ là gì, điều cần thiết để hiểu về hiệu suất - đặc biệt vì nó liên quan đến I / O - là hiếm khi có một điểm dữ liệu mà bạn có thể sử dụng để xác định vấn đề. Việc tìm ra vấn đề thực sự cần nhiều dữ kiện mà khi ghép lại với nhau sẽ giúp bạn khám phá ra vấn đề.
Cuối cùng, lưu ý rằng trong một số trường hợp, độ trễ lưu trữ có thể hoàn toàn chấp nhận được. Trước khi bạn yêu cầu lưu trữ nhanh hơn hoặc thay đổi mã, hãy xem lại các mẫu khối lượng công việc và Thỏa thuận mức dịch vụ (SLA) cho cơ sở dữ liệu. Trong trường hợp Kho dữ liệu mà các dịch vụ báo cáo cho người dùng, SLA cho các truy vấn có thể không phải là các giá trị phụ thứ hai mà bạn mong đợi đối với hệ thống OLTP khối lượng lớn. Trong giải pháp DW, độ trễ I / O lớn hơn một giây có thể hoàn toàn chấp nhận được và được mong đợi. Hiểu mong đợi của doanh nghiệp và người dùng, sau đó xác định hành động cần thực hiện, nếu có. Và nếu thay đổi là bắt buộc, hãy thu thập dữ liệu định lượng bạn cần để hỗ trợ lập luận của mình, cụ thể là thống kê chờ, thống kê tệp ảo và độ trễ từ Trình theo dõi hiệu suất.