Cơ sở dữ liệu chuỗi thời gian, như tên cho thấy, được thiết kế để lưu trữ dữ liệu thay đổi theo thời gian. Đây có thể là bất kỳ loại dữ liệu nào được thu thập theo thời gian. Nó có thể là số liệu được thu thập từ một số hệ thống và trên thực tế, tất cả các hệ thống thịnh hành đều là ví dụ về dữ liệu chuỗi thời gian.
Chúng tôi có các loại cơ sở dữ liệu chuỗi thời gian khác nhau, chúng tôi nên sử dụng loại nào?
Trong blog này, chúng ta sẽ thấy sự khác biệt chính giữa hai trong số các tùy chọn chính, TimescaleDB và InfluxDB.
InfluxDB
InfluxDB đã được tạo bởi InfluxData. Nó là một cơ sở dữ liệu chuỗi thời gian NoSQL tùy chỉnh, mã nguồn mở, được viết bằng Go. Kho dữ liệu cung cấp một ngôn ngữ giống SQL để truy vấn dữ liệu, được gọi là InfluxQL, giúp các nhà phát triển dễ dàng tích hợp vào các ứng dụng của họ. Nó cũng có một ngôn ngữ truy vấn tùy chỉnh mới được gọi là Flux, ngôn ngữ này có thể làm cho một số tác vụ dễ dàng hơn, nhưng luôn có một đường cong học tập khi áp dụng ngôn ngữ truy vấn tùy chỉnh.
Đây là một ví dụ về truy vấn Flux:
from(db:"testing")
|> range(start:-1h)
|> filter(fn: (r) => r._measurement == "cpu")
|> exponentialMovingAverage()Trong cơ sở dữ liệu này, mỗi phép đo có một dấu thời gian và một tập hợp các thẻ và tập hợp các trường được liên kết. Trường đại diện cho các giá trị đọc phép đo thực tế, trong khi thẻ đại diện cho siêu dữ liệu để mô tả các phép đo. Các kiểu dữ liệu trường được giới hạn ở float, ints, string và boolean, và không thể thay đổi nếu không viết lại dữ liệu. Các giá trị thẻ được lập chỉ mục. Chúng được biểu diễn dưới dạng chuỗi và không thể cập nhật.
InfluxDB khá dễ bắt đầu vì bạn không phải lo lắng về việc tạo lược đồ hoặc chỉ mục. Tuy nhiên, nó khá cứng nhắc và hạn chế, không có khả năng tạo chỉ mục bổ sung, chỉ mục trên các trường liên tục, cập nhật siêu dữ liệu sau khi thực tế, thực thi xác thực dữ liệu, v.v.
Nó không phải là không có cặn. Có một lược đồ cơ bản được tạo tự động từ dữ liệu đầu vào.
InfluxDB phải triển khai từ đầu một số công cụ để chịu lỗi, như sao chép, tính sẵn sàng cao và sao lưu / khôi phục và nó chịu trách nhiệm về độ tin cậy trên đĩa của nó. Chúng tôi bị giới hạn sử dụng các công cụ này và nhiều tính năng trong số này, chẳng hạn như HA, chỉ khả dụng trong phiên bản doanh nghiệp.
Công cụ sao lưu InfluxDB có thể thực hiện sao lưu toàn bộ hoặc tăng dần và nó có thể được sử dụng để khôi phục từng thời điểm.
InfluxDB cũng cung cấp khả năng nén trên đĩa tốt hơn đáng kể so với PostgreSQL và TimescaleDB.
TimescaleDB
TimescaleDB là cơ sở dữ liệu chuỗi thời gian mã nguồn mở được tối ưu hóa để nhập nhanh và các truy vấn phức tạp hỗ trợ SQL đầy đủ. Nó dựa trên PostgreSQL và nó cung cấp những gì tốt nhất của NoSQL và thế giới Quan hệ cho dữ liệu Chuỗi thời gian.
Đây là ví dụ về truy vấn TimescaleDB:
SELECT time,
exponential_moving_average(value, 0.5) OVER (ORDER BY time)
FROM testing
WHERE measurement = cpu and time > now() - '1 hour';TimescaleDB, như một phần mở rộng PostgreSQL, là một cơ sở dữ liệu quan hệ. Điều này cho phép có một đường cong học tập ngắn cho người dùng mới và kế thừa các công cụ như pg_dump hoặc pg_backup để sao lưu và các công cụ có tính khả dụng cao, đây là một lợi thế trước các cơ sở dữ liệu chuỗi thời gian khác. Nó cũng hỗ trợ sao chép trực tuyến như là phương pháp sao chép chính, có thể được sử dụng trong thiết lập tính khả dụng cao. Về chuyển đổi dự phòng và sao lưu, bạn có thể tự động hóa quá trình này bằng cách sử dụng hệ thống bên ngoài như ClusterControl.
Trong TimescaleDB, mỗi phép đo chuỗi thời gian được ghi lại trong hàng riêng của nó, với trường thời gian được theo sau bởi bất kỳ số trường nào khác, có thể là float, ints, string, boolean, array, JSON blobs, geospatial, date / time / dấu thời gian, tiền tệ, dữ liệu nhị phân, v.v.
Bạn có thể tạo chỉ mục trên bất kỳ trường nào (chỉ mục tiêu chuẩn) hoặc nhiều trường (chỉ mục tổng hợp), hoặc trên các biểu thức như hàm, hoặc thậm chí giới hạn một chỉ mục trong một tập hợp con các hàng (chỉ mục một phần). Bất kỳ trường nào trong số này đều có thể được sử dụng làm khóa ngoại cho các bảng phụ, sau đó có thể lưu trữ siêu dữ liệu bổ sung.
Theo cách này, bạn cần chọn một giản đồ và quyết định chỉ mục nào bạn sẽ cần cho hệ thống của mình.
Hiệu suất
Nếu chúng ta nói về hiệu suất, chúng ta có thể kiểm tra blog so sánh TimescaleDB tuyệt vời. Ở đó, bạn có một so sánh chi tiết về hiệu suất giữa cả hai cơ sở dữ liệu với biểu đồ và số liệu. Hãy xem một số thông tin quan trọng nhất từ blog này.
Phụ trang
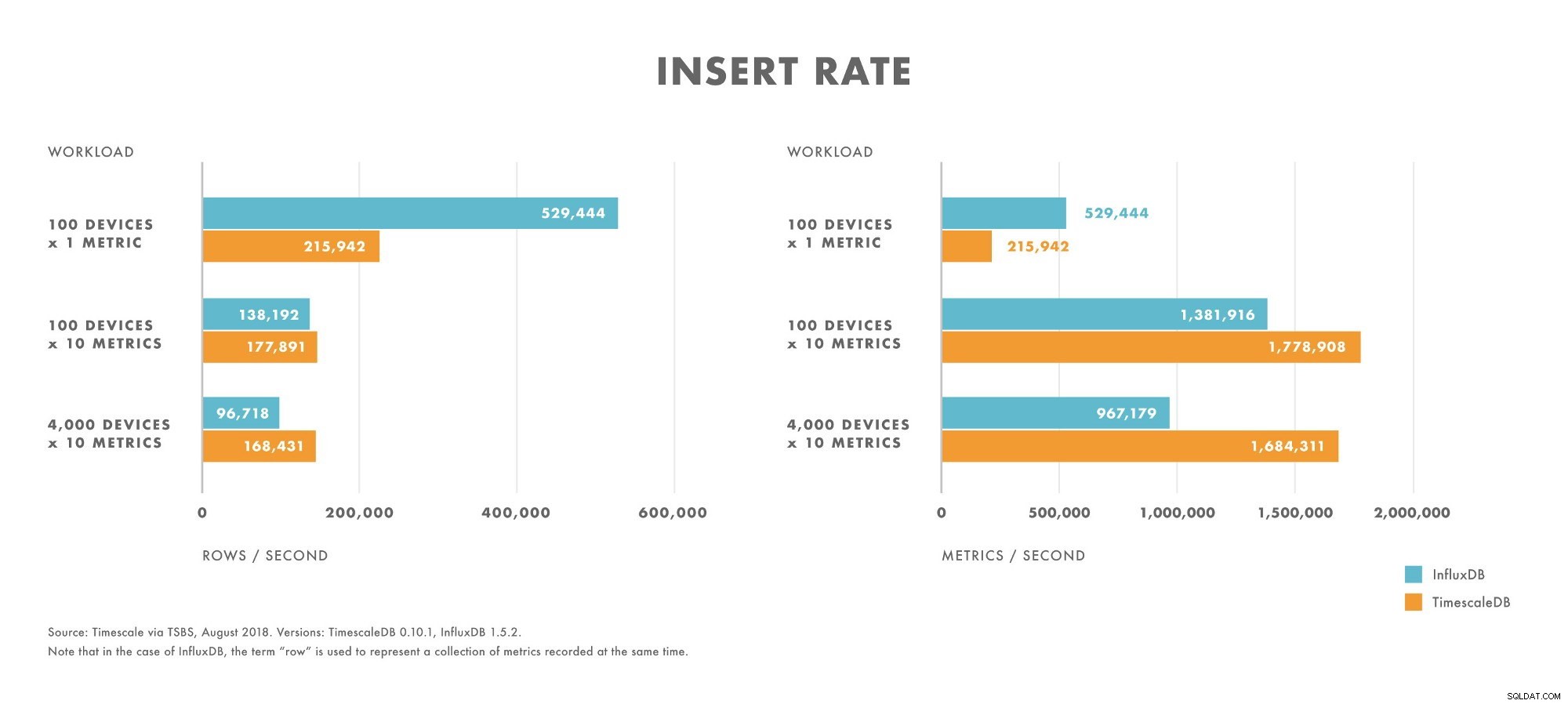
- Đối với khối lượng công việc có dung lượng rất thấp (ví dụ:100 thiết bị), InfluxDB hoạt động tốt hơn TimescaleDB.
- Khi số lượng bản lề tăng lên, hiệu suất chèn InfluxDB giảm nhanh hơn so với TimescaleDB.
- Đối với khối lượng công việc có số lượng trung bình đến cao (ví dụ:100 thiết bị gửi 10 chỉ số), TimescaleDB hoạt động tốt hơn InfluxDB.

Độ trễ khi đọc
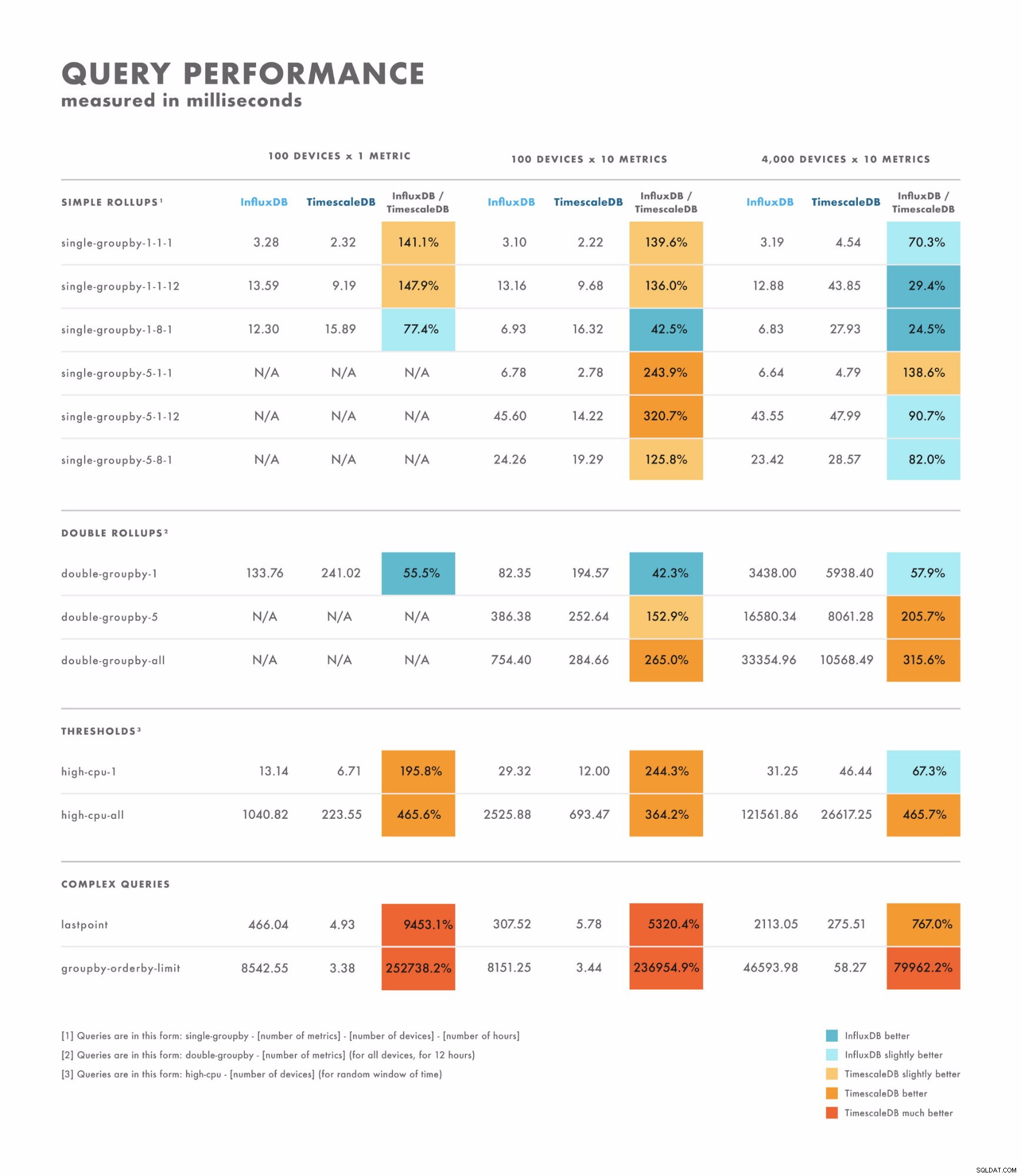
- Đối với các truy vấn đơn giản, kết quả khác nhau khá nhiều:có một số trong đó một cơ sở dữ liệu rõ ràng là tốt hơn cơ sở dữ liệu kia, trong khi các kết quả khác phụ thuộc vào bản số của tập dữ liệu của bạn. Sự khác biệt ở đây thường nằm trong khoảng mili giây từ một chữ số đến hai chữ số.
- Đối với các truy vấn phức tạp, TimescaleDB vượt trội hơn hẳn InfluxDB và hỗ trợ nhiều loại truy vấn hơn. Sự khác biệt ở đây thường trong khoảng vài giây đến hàng chục giây.
- Với ý nghĩ đó, cách tốt nhất để kiểm tra chính xác là đánh giá điểm chuẩn bằng cách sử dụng các truy vấn bạn định thực hiện.
Các vấn đề về tính ổn định
- InfluxDB có vấn đề về độ ổn định và hiệu suất ở các bản số cao (100K +).
Kết luận
Nếu dữ liệu của bạn phù hợp với mô hình dữ liệu InfluxDB và bạn không mong đợi thay đổi trong tương lai, thì bạn nên cân nhắc sử dụng InfluxDB vì mô hình này dễ bắt đầu hơn và giống như hầu hết các cơ sở dữ liệu sử dụng cách tiếp cận theo hướng cột, cung cấp khả năng nén trên đĩa tốt hơn PostgreSQL và TimescaleDB.
Tuy nhiên, mô hình quan hệ linh hoạt hơn và cung cấp nhiều chức năng, tính linh hoạt và khả năng kiểm soát hơn mô hình InfluxDB. Điều này đặc biệt quan trọng khi ứng dụng của bạn phát triển. Và khi lập kế hoạch cho hệ thống của mình, bạn nên xem xét cả nhu cầu hiện tại và tương lai của nó.
Trong blog này, chúng ta có thể thấy một so sánh ngắn giữa TimescaleDB và InfluxDB, và có thể nói TimescaleDB là một tiện ích mở rộng PostgreSQL, trông khá trưởng thành và giàu tính năng vì nó thừa hưởng rất nhiều từ PostgreSQL. Nhưng bạn có thể đưa ra quyết định của riêng mình dựa trên những ưu và nhược điểm được đề cập trước đó trong blog này và đảm bảo bạn đánh giá khối lượng công việc của chính mình. Chúc bạn may mắn trong thế giới cơ sở dữ liệu chuỗi thời gian mới này!