Trở lại tháng 1 năm 2015, người bạn tốt của tôi và người bạn SQL Server MVP Rob Farley đã viết về một giải pháp mới cho vấn đề tìm giá trị trung bình trong các phiên bản SQL Server trước năm 2012. Cũng như là một cuốn sách thú vị, nó hóa ra là một ví dụ tuyệt vời để sử dụng để chứng minh một số phân tích kế hoạch thực thi nâng cao và để làm nổi bật một số hành vi tinh vi của trình tối ưu hóa truy vấn và công cụ thực thi.
Trung vị đơn
Mặc dù bài viết của Rob nhắm mục tiêu cụ thể đến một phép tính trung vị được nhóm lại, nhưng tôi sẽ bắt đầu bằng cách áp dụng phương pháp của anh ấy cho một bài toán tính toán trung vị đơn lẻ lớn, bởi vì nó nêu bật các vấn đề quan trọng một cách rõ ràng nhất. Dữ liệu mẫu một lần nữa sẽ đến từ bài báo gốc của Aaron Bertrand:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id); Áp dụng kỹ thuật của Rob Farley cho vấn đề này sẽ đưa ra đoạn mã sau:
-- 5800ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f;
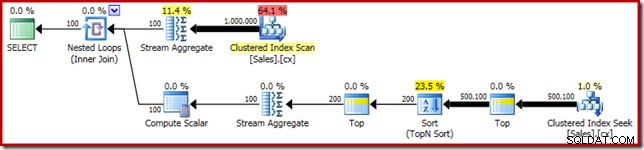
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Như thường lệ, tôi đã nhận xét về việc đếm số hàng trong bảng và thay thế nó bằng một hằng số để tránh nguồn của phương sai hiệu suất. Kế hoạch thực thi cho truy vấn quan trọng như sau:

Truy vấn này chạy trong 5800ms trên máy thử nghiệm của tôi.
Sắp xếp tràn
Nguyên nhân chính của hiệu suất kém này nên rõ ràng khi xem xét kế hoạch thực thi ở trên:Cảnh báo trên toán tử Sắp xếp cho thấy rằng cấp bộ nhớ không gian làm việc không đủ gây ra sự cố tràn cấp 2 (nhiều lần) sang vật lý tempdb đĩa:
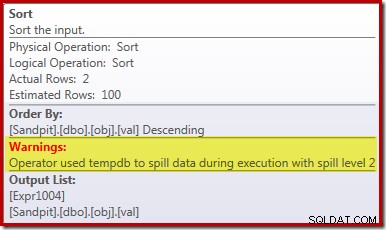
Trong các phiên bản của SQL Server trước năm 2012, bạn sẽ cần phải theo dõi riêng các sự kiện tràn sắp xếp để xem điều này. Dù sao, việc đặt trước bộ nhớ sắp xếp không đủ là do lỗi ước lượng bản số, như kế hoạch trước khi thực thi (ước tính) cho thấy:

Ước tính số lượng 100 hàng ở đầu vào Sắp xếp là một phỏng đoán (cực kỳ không chính xác) của trình tối ưu hóa, do biểu thức biến cục bộ trong toán tử Hàng đầu trước đó:

Lưu ý rằng lỗi ước tính bản số này không phải là vấn đề về mục tiêu hàng. Việc áp dụng cờ theo dõi 4138 sẽ loại bỏ hiệu ứng mục tiêu hàng bên dưới Top đầu tiên, nhưng ước tính sau Top vẫn sẽ là dự đoán 100 hàng (do đó, bộ nhớ dành cho Sắp xếp vẫn còn quá nhỏ):

Gợi ý giá trị của biến cục bộ
Có một số cách chúng tôi có thể giải quyết vấn đề ước tính bản số này. Một tùy chọn là sử dụng gợi ý để cung cấp cho trình tối ưu hóa thông tin về giá trị được giữ trong biến:
-- 3250ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1, OPTIMIZE FOR (@Count = 11000000)); -- NEW!
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Sử dụng gợi ý sẽ cải thiện hiệu suất lên 3250ms từ 5800ms . Kế hoạch sau khi thực hiện cho thấy rằng loại không còn tràn:

Tuy nhiên, có một số nhược điểm của điều này. Đầu tiên, kế hoạch thực thi mới này yêu cầu 388MB cấp bộ nhớ - bộ nhớ có thể được máy chủ sử dụng để lưu các kế hoạch, chỉ mục và dữ liệu trong bộ nhớ cache:
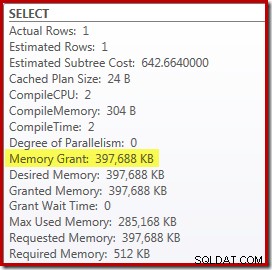
Thứ hai, có thể khó chọn một số tốt cho gợi ý sẽ hoạt động tốt cho tất cả các lần thực thi trong tương lai mà không cần dự trữ bộ nhớ một cách không cần thiết.
Cũng lưu ý rằng chúng ta phải gợi ý một giá trị cho biến cao hơn 10% so với giá trị thực của biến để loại bỏ hoàn toàn sự cố tràn. Điều này không có gì lạ, bởi vì thuật toán sắp xếp chung khá phức tạp hơn là sắp xếp tại chỗ đơn giản. Bộ nhớ dành riêng bằng với kích thước của tập hợp được sắp xếp sẽ không phải lúc nào (hoặc thậm chí nói chung) cũng đủ để tránh tràn trong thời gian chạy.
Nhúng và biên dịch lại
Một tùy chọn khác là tận dụng tính năng Tối ưu hóa Nhúng Tham số được bật bằng cách thêm gợi ý biên dịch lại cấp truy vấn trên SQL Server 2008 SP1 CU5 trở lên. Hành động này sẽ cho phép trình tối ưu hóa xem giá trị thời gian chạy của biến và tối ưu hóa cho phù hợp:
-- 3150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1, RECOMPILE);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
Điều này cải thiện thời gian thực thi lên 3150 mili giây - Tốt hơn 100ms so với sử dụng OPTIMIZE FOR gợi ý. Có thể thấy lý do cho sự cải tiến nhỏ hơn nữa này từ kế hoạch sau khi thực hiện mới:

Biểu thức (2 – @Count % 2) - như đã thấy trước đây trong toán tử Top thứ hai - bây giờ có thể được gấp lại thành một giá trị đã biết duy nhất. Sau đó, việc viết lại sau tối ưu hóa có thể kết hợp Top với Sắp xếp, dẫn đến một Sắp xếp N. Việc viết lại này trước đây không thể thực hiện được vì việc thu gọn Top + Sort thành Top N Sắp xếp chỉ hoạt động với giá trị Top theo nghĩa đen không đổi (không phải biến hoặc tham số).
Thay thế Top và Sort bằng Top N Sort có ảnh hưởng nhỏ đến hiệu suất (ở đây là 100ms), nhưng nó cũng gần như loại bỏ hoàn toàn yêu cầu về bộ nhớ, bởi vì Top N Sort chỉ phải theo dõi N cao nhất (hoặc thấp nhất) hàng, thay vì toàn bộ tập hợp. Do sự thay đổi trong thuật toán này, kế hoạch sau khi thực thi cho truy vấn này cho thấy rằng 1MB tối thiểu bộ nhớ đã được dành riêng cho Xếp hạng N hàng đầu trong gói này và chỉ 16KB đã được sử dụng trong thời gian chạy (hãy nhớ, kế hoạch sắp xếp đầy đủ yêu cầu 388MB):
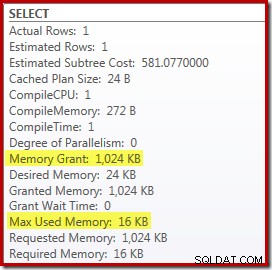
Tránh biên dịch
Hạn chế (rõ ràng) của việc sử dụng gợi ý truy vấn biên dịch là nó yêu cầu biên dịch đầy đủ trên mỗi lần thực thi. Trong trường hợp này, chi phí khá nhỏ - khoảng 1ms thời gian CPU và 272KB bộ nhớ. Mặc dù vậy, vẫn có một cách để điều chỉnh truy vấn sao cho chúng ta nhận được những lợi ích của Sắp xếp N Top mà không cần sử dụng bất kỳ gợi ý nào và không cần biên dịch lại.
Ý tưởng đến từ việc nhận ra rằng một tối đa của hai hàng sẽ được yêu cầu cho phép tính trung vị cuối cùng. Nó có thể là một hàng hoặc có thể là hai hàng trong thời gian chạy, nhưng không bao giờ có thể nhiều hơn. Thông tin chi tiết này có nghĩa là chúng ta có thể thêm bước trung gian Trên cùng (2) dư thừa về mặt logic vào truy vấn như sau:
-- 3150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (2) -- NEW!
z.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS z
ORDER BY z.val DESC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Top mới (với chữ hằng số quan trọng) có nghĩa là kế hoạch thực thi cuối cùng có toán tử Sắp xếp Top N mong muốn mà không cần biên dịch lại:

Hiệu suất của kế hoạch thực thi này không thay đổi so với phiên bản được gợi ý biên dịch lại ở 3150ms và yêu cầu bộ nhớ là như nhau. Mặc dù vậy, lưu ý rằng việc thiếu nhúng tham số có nghĩa là các ước tính về số lượng bên dưới loại sắp xếp là các phỏng đoán 100 hàng (mặc dù điều đó không ảnh hưởng đến hiệu suất ở đây).
Bài học kinh nghiệm chính ở giai đoạn này là nếu bạn muốn Sắp xếp Top N có bộ nhớ thấp, bạn phải sử dụng một ký tự không đổi hoặc cho phép trình tối ưu hóa xem một ký tự thông qua tối ưu hóa nhúng tham số.
Phạm vi tính toán
Loại bỏ 388MB việc cấp bộ nhớ (đồng thời cải thiện hiệu suất 100ms) chắc chắn là đáng giá, nhưng có một phần thắng về hiệu suất lớn hơn nhiều. Mục tiêu khó có thể xảy ra của cải tiến cuối cùng này là Tính vô hướng ngay trên Quét chỉ mục theo cụm.
Vô hướng tính toán này liên quan đến biểu thức (0E + f.val) có trong AVG tổng hợp trong truy vấn. Trong trường hợp có vẻ kỳ lạ với bạn, đây là một thủ thuật viết truy vấn khá phổ biến (như nhân với 1,0) để tránh tính số nguyên trong phép tính trung bình, nhưng nó có một số tác dụng phụ rất quan trọng.
Ở đây có một chuỗi sự kiện cụ thể mà chúng ta cần làm theo từng bước.
Đầu tiên, hãy lưu ý rằng 0E là một số 0 theo nghĩa đen không đổi, với một float loại dữ liệu. Để thêm giá trị này vào cột số nguyên val, bộ xử lý truy vấn phải chuyển đổi cột từ số nguyên sang số thực (phù hợp với quy tắc ưu tiên kiểu dữ liệu). Một loại chuyển đổi tương tự sẽ là cần thiết nếu chúng tôi chọn nhân cột với 1,0 (một chữ với kiểu dữ liệu số ngầm định). Điểm quan trọng là thủ thuật thường xuyên này giới thiệu một biểu thức .
Bây giờ, SQL Server thường cố gắng đẩy biểu thức xuống cây kế hoạch càng xa càng tốt trong quá trình biên dịch và tối ưu hóa. Điều này được thực hiện vì một số lý do, bao gồm để làm cho các biểu thức so khớp với các cột được tính toán dễ dàng hơn và để tạo điều kiện đơn giản hóa bằng cách sử dụng thông tin ràng buộc. Chính sách đẩy xuống này giải thích tại sao Vô hướng tính toán xuất hiện gần với cấp độ lá của kế hoạch hơn nhiều so với vị trí văn bản ban đầu của biểu thức trong truy vấn sẽ đề xuất.
Rủi ro khi thực hiện thao tác đẩy xuống này là biểu thức có thể bị tính nhiều lần hơn mức cần thiết. Hầu hết các kế hoạch có tính năng giảm số lượng hàng khi chúng tôi di chuyển lên cây kế hoạch, do tác động của phép nối, tổng hợp và bộ lọc. Do đó, việc đẩy các biểu thức xuống cây sẽ có nguy cơ đánh giá các biểu thức đó nhiều lần hơn (tức là trên nhiều hàng hơn) so với mức cần thiết.
Để giảm thiểu điều này, SQL Server 2005 đã giới thiệu một tính năng tối ưu hóa, theo đó các Phạm vi tính toán có thể chỉ cần xác định một biểu thức, với công việc thực sự là đánh giá biểu thức hoãn lại cho đến khi một nhà điều hành sau đó trong kế hoạch yêu cầu kết quả. Khi tối ưu hóa này hoạt động như dự định, tác dụng là đạt được tất cả lợi ích của việc đẩy biểu thức xuống dưới dạng cây, trong khi vẫn chỉ thực sự đánh giá biểu thức nhiều lần nếu thực sự cần thiết.
Tất cả công cụ Compute Scalar này có nghĩa là gì
Trong ví dụ đang chạy của chúng tôi, 0E + val ban đầu biểu thức được liên kết với AVG tổng hợp, vì vậy chúng tôi có thể mong đợi sẽ thấy nó tại (hoặc một chút sau) Tổng hợp luồng. Tuy nhiên, biểu thức này đã bị đẩy xuống cây sẽ trở thành Vô hướng tính toán mới ngay sau khi quét, với biểu thức được gắn nhãn là [Expr1004].
Nhìn vào kế hoạch thực thi, chúng ta có thể thấy rằng [Expr1004] được tham chiếu bởi Tổng hợp luồng (trích xuất Tab Biểu thức của Plan Explorer được hiển thị bên dưới):

Tất cả mọi thứ đều bình đẳng, đánh giá biểu thức [Expr1004] sẽ được hoãn lại cho đến khi tổng hợp cần những giá trị đó cho phần tổng của phép tính trung bình. Vì tổng hợp chỉ có thể gặp một hoặc hai hàng, điều này sẽ dẫn đến việc [Expr1004] chỉ được đánh giá một hoặc hai lần:
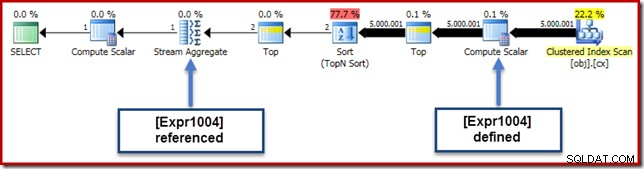
Thật không may, đây không phải là hoàn toàn như thế nào nó hoạt động ở đây. Vấn đề là toán tử Sắp xếp chặn:
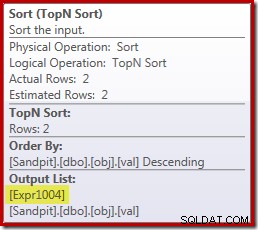
Điều này buộc đánh giá [Expr1004], vì vậy thay vì nó chỉ được đánh giá một hoặc hai lần tại Tổng hợp luồng, Sắp xếp có nghĩa là chúng tôi kết thúc chuyển đổi val cột vào số nổi và thêm số 0 vào cột đó 5.000.001 lần!
Một giải pháp thay thế
Lý tưởng nhất là SQL Server sẽ thông minh hơn một chút về tất cả những điều này, nhưng đó không phải là cách nó hoạt động ngày nay. Không có gợi ý truy vấn nào để ngăn các biểu thức bị đẩy xuống cây kế hoạch và chúng tôi cũng không thể buộc Tính toán vô hướng bằng Hướng dẫn kế hoạch. Tất nhiên, có một lá cờ theo dõi không có tài liệu, nhưng nó không phải là lá cờ mà tôi có thể nói một cách có trách nhiệm trong bối cảnh hiện tại.
Vì vậy, dù tốt hơn hay tệ hơn, điều này khiến chúng ta phải cố gắng tìm cách viết lại truy vấn xảy ra để ngăn SQL Server tách biểu thức khỏi tổng thể và đẩy nó xuống dưới Sắp xếp mà không làm thay đổi kết quả của truy vấn. Điều này không dễ dàng như bạn nghĩ, nhưng sửa đổi (phải thừa nhận là hơi kỳ quặc) dưới đây đạt được điều này bằng cách sử dụng CASE biểu hiện trên một hàm nội tại không xác định:
-- 2150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
-- NEW!
Median = AVG(CASE WHEN GETDATE() >= {D '1753-01-01'} THEN 0E + f.val END)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (2)
z.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS z
ORDER BY z.val DESC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Kế hoạch thực thi cho dạng truy vấn cuối cùng này được hiển thị bên dưới:

Lưu ý rằng Vô hướng tính toán không còn xuất hiện giữa Quét chỉ mục theo cụm và trên cùng. 0E + val biểu thức hiện được tính toán tại Tổng hợp luồng trên tối đa hai hàng (thay vì năm triệu!) và hiệu suất tăng thêm 32% từ 3150 mili giây đến 2150 mili giây kết quả là.
Điều này vẫn không so sánh tốt với hiệu suất dưới giây của OFFSET và các giải pháp tính toán trung vị bằng con trỏ động, nhưng nó vẫn thể hiện một cải tiến rất đáng kể so với 5800ms ban đầu cho phương pháp này trên một tập hợp bài toán trung bình đơn lớn.
Tất nhiên, thủ thuật CASE không được đảm bảo sẽ hoạt động trong tương lai. Bài học rút ra không phải là quá nhiều về việc sử dụng các thủ thuật biểu thức chữ hoa chữ thường kỳ lạ, mà nó là về các tác động tiềm năng về hiệu suất của Compute Scalars. Một khi bạn biết về loại điều này, bạn có thể suy nghĩ kỹ trước khi nhân với 1,0 hoặc thêm số float vào trong một phép tính trung bình.
Cập nhật: vui lòng xem bình luận đầu tiên để biết một giải pháp tốt của Robert Heinig mà không yêu cầu bất kỳ thủ thuật không có tài liệu nào. Một điều cần lưu ý khi bạn tiếp theo muốn nhân một số nguyên với số thập phân (hoặc số thực) trong một tổng trung bình.
Trung vị được nhóm
Để có sự hoàn chỉnh và để kết nối phân tích này chặt chẽ hơn với bài viết ban đầu của Rob, chúng tôi sẽ kết thúc bằng cách áp dụng các cải tiến tương tự cho phép tính trung bình được nhóm theo nhóm. Kích thước tập hợp nhỏ hơn (mỗi nhóm) có nghĩa là các hiệu ứng sẽ nhỏ hơn, tất nhiên.
Dữ liệu mẫu trung bình được nhóm lại (một lần nữa như ban đầu được tạo bởi Aaron Bertrand) bao gồm mười nghìn hàng cho mỗi một trăm người bán hàng tưởng tượng:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount); Việc áp dụng trực tiếp giải pháp của Rob Farley sẽ đưa ra mã sau, mã này thực thi trong 560ms trên máy của tôi.
-- 560ms Original
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + f.Amount)
FROM
(
SELECT TOP (2 - d.y % 2)
t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Kế hoạch thực hiện có những điểm tương đồng rõ ràng với trung vị duy nhất:
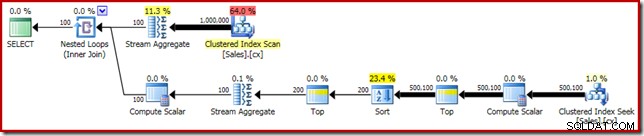
Cải tiến đầu tiên của chúng tôi là thay thế Sắp xếp bằng Sắp xếp N hàng đầu, bằng cách thêm một Đầu rõ ràng (2). Điều này cải thiện một chút thời gian thực hiện từ 560 mili giây lên 550 mili giây .
-- 550ms
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + f.Amount)
FROM
(
SELECT TOP (2 - d.y % 2)
q.Amount
FROM
(
-- NEW!
SELECT TOP (2) t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS q
ORDER BY q.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Kế hoạch thực hiện hiển thị Xếp hạng N hàng đầu như mong đợi:
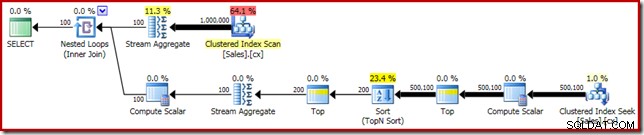
Cuối cùng, chúng tôi triển khai biểu thức CASE trông kỳ quặc để loại bỏ biểu thức Tính vô hướng được đẩy. Điều này cải thiện hơn nữa hiệu suất lên 450ms (cải thiện 20% so với bản gốc):
-- 450ms
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
-- NEW!
SELECT AVG(CASE WHEN GETDATE() >= {D '1753-01-01'} THEN 0E + Amount END)
FROM
(
SELECT TOP (2 - d.y % 2)
q.Amount
FROM
(
SELECT TOP (2) t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS q
ORDER BY q.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Kế hoạch thực hiện hoàn thành như sau: