Khi bạn cần triển khai hệ thống phân tích cho một công ty, bạn thường có câu hỏi về nơi dữ liệu nên được lưu trữ. Không phải lúc nào cũng có một lựa chọn hoàn hảo cho tất cả các yêu cầu và nó phụ thuộc vào ngân sách, lượng dữ liệu và nhu cầu của công ty.
PostgreSQL, với tư cách là cơ sở dữ liệu mã nguồn mở tiên tiến nhất, rất linh hoạt, có thể phục vụ như một cơ sở dữ liệu quan hệ đơn giản, cơ sở dữ liệu chuỗi thời gian và thậm chí là một giải pháp lưu trữ dữ liệu hiệu quả, chi phí thấp. Bạn cũng có thể tích hợp nó với một số công cụ phân tích.
Nếu bạn đang tìm kiếm một kho dữ liệu tương thích rộng rãi, chi phí thấp và hoạt động hiệu quả, thì tùy chọn cơ sở dữ liệu tốt nhất có thể là PostgreSQL, nhưng tại sao? Trong blog này, chúng ta sẽ xem kho dữ liệu là gì, tại sao lại cần nó và tại sao PostgreSQL có thể là lựa chọn tốt nhất ở đây.
Kho dữ liệu là gì
Kho dữ liệu là một hệ thống được tiêu chuẩn hóa, nhất quán và tích hợp, chứa dữ liệu hiện tại hoặc lịch sử từ một hoặc nhiều nguồn được sử dụng để báo cáo và phân tích dữ liệu. Đây được coi là thành phần cốt lõi của trí tuệ kinh doanh, là chiến lược và công nghệ được một công ty sử dụng để hiểu rõ hơn về bối cảnh thương mại của mình.
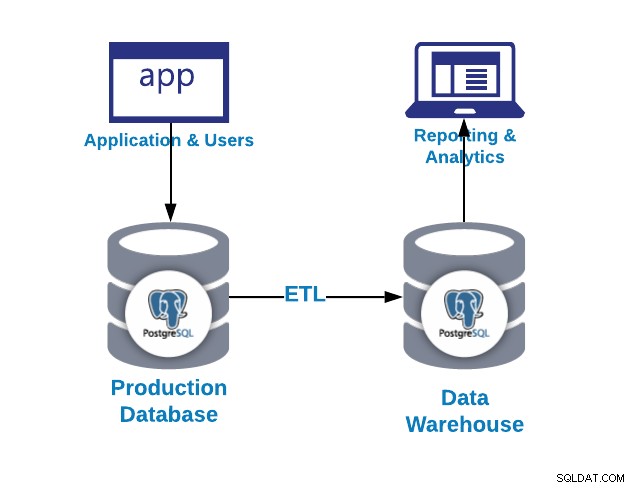
Câu hỏi đầu tiên bạn có thể hỏi là tại sao tôi cần một kho dữ liệu?
- Tích hợp:Tích hợp / tập trung dữ liệu từ nhiều hệ thống / cơ sở dữ liệu
- Chuẩn hoá:Chuẩn hoá tất cả dữ liệu ở cùng một định dạng
- Phân tích:Phân tích dữ liệu trong bối cảnh lịch sử
Một số lợi ích của kho dữ liệu có thể là ...
- Tích hợp dữ liệu từ nhiều nguồn vào một cơ sở dữ liệu duy nhất
- Tránh bị khóa hoặc tải sản xuất do các truy vấn chạy dài
- Lưu trữ thông tin lịch sử
- Cấu trúc lại dữ liệu để phù hợp với các yêu cầu phân tích
Như chúng ta có thể thấy trong hình trước, chúng ta có thể sử dụng PostgreSQL cho cả đề xuất OLAP và OLTP. Hãy xem sự khác biệt.
- OLTP:Xử lý giao dịch trực tuyến. Nói chung, nó có một số lượng lớn các giao dịch trực tuyến ngắn (CHÈN, CẬP NHẬT, XÓA) được tạo ra bởi hoạt động của người dùng. Các hệ thống này nhấn mạnh việc xử lý truy vấn rất nhanh và duy trì tính toàn vẹn của dữ liệu trong môi trường đa truy cập. Ở đây, hiệu quả được đo lường bằng số lượng giao dịch mỗi giây. Cơ sở dữ liệu OLTP chứa dữ liệu chi tiết và hiện tại.
- OLAP:Xử lý phân tích trực tuyến. Nói chung, nó có khối lượng giao dịch phức tạp thấp do các báo cáo lớn tạo ra. Thời gian phản hồi là một thước đo hiệu quả. Các cơ sở dữ liệu này lưu trữ dữ liệu lịch sử, tổng hợp trong các lược đồ đa chiều. Cơ sở dữ liệu OLAP được sử dụng để phân tích dữ liệu đa chiều từ nhiều nguồn và quan điểm.
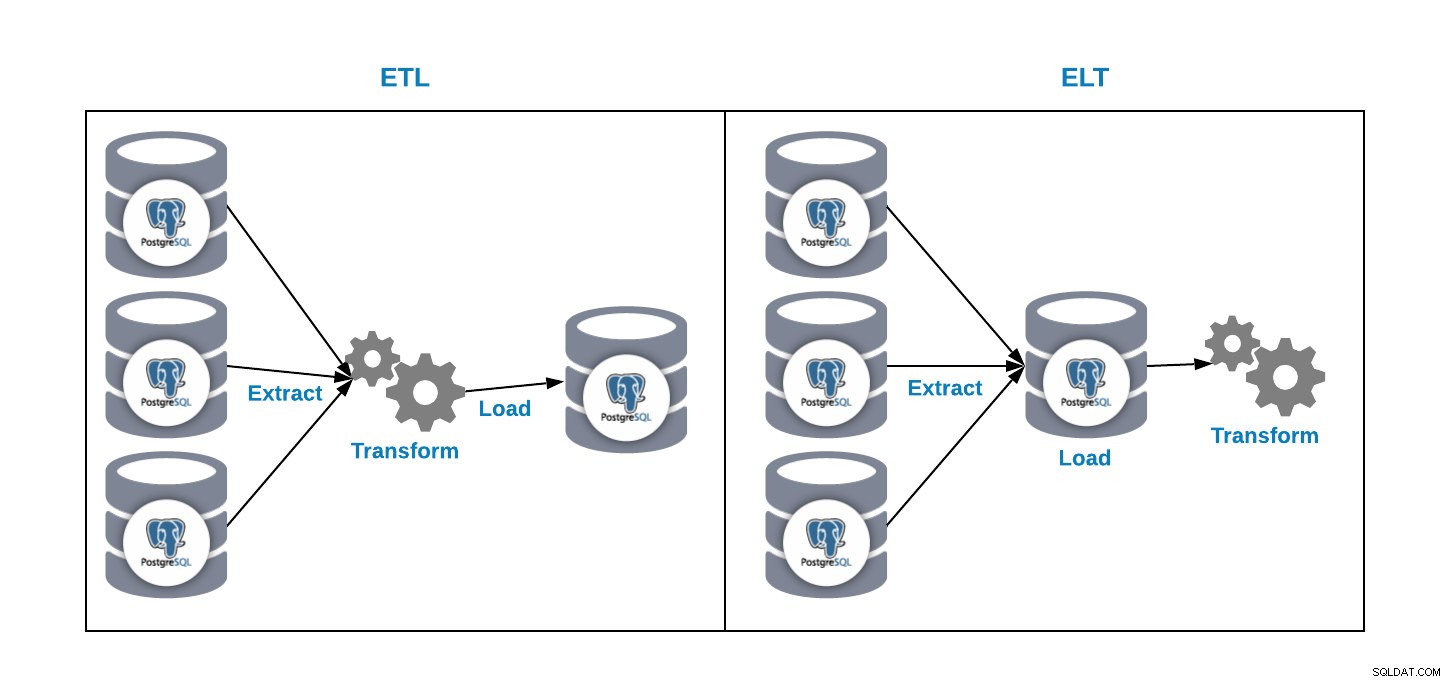
Chúng tôi có hai cách để tải dữ liệu vào cơ sở dữ liệu phân tích của mình:
- ETL:Trích xuất, biến đổi và tải. Đây là cách để tạo kho dữ liệu của chúng tôi. Đầu tiên, trích xuất dữ liệu từ cơ sở dữ liệu sản xuất, chuyển đổi dữ liệu theo yêu cầu của chúng tôi, sau đó tải dữ liệu vào kho dữ liệu của chúng tôi.
- ELT:Giải nén, tải và biến đổi. Đầu tiên, trích xuất dữ liệu từ cơ sở dữ liệu sản xuất, tải nó vào cơ sở dữ liệu và sau đó chuyển đổi dữ liệu. Cách này được gọi là Data Lake và đó là một khái niệm mới để quản lý dữ liệu lớn của chúng tôi.
Và bây giờ, câu hỏi thứ hai, tại sao tôi nên sử dụng PostgreSQL cho kho dữ liệu của mình?
Lợi ích của PostgreSQL như một Kho dữ liệu
Hãy xem xét một số lợi ích của việc sử dụng PostgreSQL làm kho dữ liệu ...
- Chi phí:Nếu bạn đang sử dụng môi trường tại chỗ, chi phí cho chính sản phẩm sẽ là 0 đô la, ngay cả khi bạn đang sử dụng một số sản phẩm trên đám mây, có lẽ chi phí của một sản phẩm dựa trên PostgreSQL sẽ thấp hơn phần còn lại của các sản phẩm.
- Quy mô:Bạn có thể mở rộng quy mô đọc nó theo cách đơn giản bằng cách thêm nhiều nút bản sao tùy thích.
- Hiệu suất:Với cấu hình đúng, PostgreSQL có hiệu suất thực sự tốt trên các ngôn ngữ khác nhau.
- Khả năng tương thích:Bạn có thể tích hợp PostgreSQL với các công cụ hoặc ứng dụng bên ngoài để khai thác dữ liệu, OLAP và báo cáo.
- Khả năng mở rộng:PostgreSQL có các loại dữ liệu và chức năng do người dùng xác định.
Ngoài ra còn có một số tính năng của PostgreSQL có thể giúp chúng tôi quản lý thông tin kho dữ liệu của mình ...
- Bảng tạm thời:Đó là một bảng tồn tại trong thời gian của phiên cơ sở dữ liệu. PostgreSQL tự động loại bỏ các bảng tạm thời khi kết thúc phiên hoặc giao dịch.
- Các thủ tục đã lưu trữ:Bạn có thể sử dụng nó để tạo các thủ tục hoặc hàm trên nhiều ngôn ngữ (PL / pgSQL, PL / Perl, PL / Python, v.v.).
- Phân vùng:Điều này thực sự hữu ích cho việc bảo trì cơ sở dữ liệu, các truy vấn sử dụng khoá phân vùng và INSERT hiệu suất.
- Chế độ xem cụ thể hóa:Kết quả truy vấn được hiển thị dưới dạng bảng.
- Không gian bảng:Bạn có thể thay đổi vị trí dữ liệu sang một đĩa khác. Bằng cách này, bạn sẽ có quyền truy cập đĩa song song.
- Tương thích với PITR:Bạn có thể tạo các bản sao lưu tương thích với từng thời điểm khôi phục, vì vậy trong trường hợp không thành công, bạn có thể khôi phục trạng thái cơ sở dữ liệu trong một khoảng thời gian cụ thể.
- Cộng đồng lớn:Và cuối cùng nhưng không kém phần quan trọng, PostgreSQL có một cộng đồng khổng lồ, nơi bạn có thể tìm thấy sự hỗ trợ về nhiều vấn đề khác nhau.
Định cấu hình PostgreSQL để sử dụng kho dữ liệu
Không có cấu hình tốt nhất để sử dụng trong mọi trường hợp và trong mọi công nghệ cơ sở dữ liệu. Nó phụ thuộc vào nhiều yếu tố như phần cứng, cách sử dụng và yêu cầu hệ thống. Dưới đây là một số mẹo để định cấu hình cơ sở dữ liệu PostgreSQL của bạn để hoạt động như một kho dữ liệu theo đúng cách.
Dựa trên bộ nhớ
- max_connections:Là cơ sở dữ liệu kho dữ liệu, bạn không cần số lượng kết nối cao vì điều này sẽ được sử dụng cho công việc báo cáo và phân tích, vì vậy bạn có thể giới hạn số lượng kết nối tối đa bằng cách sử dụng thông số này.
- shared_buffers:Đặt dung lượng bộ nhớ mà máy chủ cơ sở dữ liệu sử dụng cho các bộ đệm bộ nhớ được chia sẻ. Giá trị hợp lý có thể là từ 15% đến 25% bộ nhớ RAM.
- effect_cache_size:Giá trị này được sử dụng bởi trình lập kế hoạch truy vấn để tính đến các kế hoạch có thể có hoặc có thể không vừa trong bộ nhớ. Điều này được tính đến trong ước tính chi phí của việc sử dụng một chỉ số; giá trị cao làm cho khả năng quét chỉ mục được sử dụng nhiều hơn và giá trị thấp làm cho khả năng quét tuần tự sẽ được sử dụng nhiều hơn. Giá trị hợp lý sẽ là khoảng 75% bộ nhớ RAM.
- work mem:Chỉ định lượng bộ nhớ sẽ được sử dụng bởi các hoạt động bên trong của ORDER BY, DISTINCT, JOIN và bảng băm trước khi ghi vào các tệp tạm thời trên đĩa. Khi định cấu hình giá trị này, chúng ta phải lưu ý rằng một số phiên đang thực hiện các hoạt động này cùng một lúc và mỗi hoạt động sẽ được phép sử dụng nhiều bộ nhớ như được chỉ định bởi giá trị này trước khi nó bắt đầu ghi dữ liệu vào các tệp tạm thời. Giá trị hợp lý có thể là khoảng 2% Bộ nhớ RAM.
- security_work_mem:Chỉ định dung lượng bộ nhớ tối đa mà các hoạt động bảo trì sẽ sử dụng, chẳng hạn như VACUUM, CREATE INDEX và ALTER TABLE ADD FOREIGN KEY. Giá trị hợp lý có thể là khoảng 15% bộ nhớ RAM.
Dựa trên CPU
- Max_worker_processes:Đặt số lượng quy trình nền tối đa mà hệ thống có thể hỗ trợ. Giá trị hợp lý có thể là số lượng CPU.
- Max_parallel_workers_per_gather:Đặt số lượng công nhân tối đa có thể được bắt đầu bởi một nút Tập hợp hoặc Kết hợp tập hợp. Giá trị hợp lý có thể là 50% số lượng CPU.
- Max_parallel_workers:Đặt số lượng công nhân tối đa mà hệ thống có thể hỗ trợ cho các truy vấn song song. Giá trị hợp lý có thể là số lượng CPU.
Vì dữ liệu được tải vào kho dữ liệu của chúng tôi không được thay đổi, nên chúng tôi cũng có thể tắt tính năng Autovacuum để tránh tải thêm cơ sở dữ liệu PostgreSQL của bạn. Quy trình Hút chân không và Phân tích có thể là một phần của quy trình tải hàng loạt.
Kết luận
Nếu bạn đang tìm kiếm kho dữ liệu tương thích rộng rãi, chi phí thấp và hiệu suất cao, bạn chắc chắn nên xem xét PostgreSQL như một tùy chọn cho cơ sở dữ liệu kho dữ liệu của mình. PostgreSQL có nhiều lợi ích và tính năng hữu ích để quản lý kho dữ liệu của chúng tôi như phân vùng hoặc các thủ tục được lưu trữ, v.v.