Sysbench là một công cụ tuyệt vời để tạo dữ liệu thử nghiệm và thực hiện các điểm chuẩn OLTP của MySQL. Thông thường, người ta sẽ thực hiện chu trình chuẩn bị-chạy-dọn dẹp khi thực hiện điểm chuẩn bằng Sysbench. Theo mặc định, bảng do Sysbench tạo ra là một bảng cơ sở không phân vùng tiêu chuẩn. Tất nhiên, hành vi này có thể được mở rộng, nhưng bạn phải biết cách viết nó trong tập lệnh LUA.
Trong bài đăng trên blog này, chúng tôi sẽ giới thiệu cách tạo dữ liệu thử nghiệm cho một bảng được phân vùng trong MySQL bằng Sysbench. Đây có thể được sử dụng như một sân chơi để chúng tôi đi sâu hơn vào nguyên nhân-kết quả của phân vùng bảng, phân phối dữ liệu và định tuyến truy vấn.
Phân vùng bảng một máy chủ
Phân vùng một máy chủ đơn giản có nghĩa là tất cả các phân vùng của bảng nằm trên cùng một máy chủ / phiên bản MySQL. Khi tạo cấu trúc bảng, chúng ta sẽ xác định tất cả các phân vùng cùng một lúc. Loại phân vùng này tốt nếu bạn có dữ liệu mất tính hữu dụng theo thời gian và có thể dễ dàng bị xóa khỏi bảng đã phân vùng bằng cách bỏ phân vùng (hoặc các phân vùng) chỉ chứa dữ liệu đó.
Tạo lược đồ Sysbench:
mysql> CREATE SCHEMA sbtest;Tạo người dùng cơ sở dữ liệu sysbench:
mysql> CREATE USER 'sbtest'@'%' IDENTIFIED BY 'passw0rd';
mysql> GRANT ALL PRIVILEGES ON sbtest.* TO 'sbtest'@'%';Trong Sysbench, người ta sẽ sử dụng lệnh --prepare để chuẩn bị máy chủ MySQL với cấu trúc lược đồ và tạo các hàng dữ liệu. Chúng ta phải bỏ qua phần này và xác định cấu trúc bảng theo cách thủ công.
Tạo một bảng được phân vùng. Trong ví dụ này, chúng ta sẽ chỉ tạo một bảng có tên sbtest1 và nó sẽ được phân vùng bởi một cột có tên "k", về cơ bản là một số nguyên nằm trong khoảng từ 0 đến 1.000.000 (dựa trên tùy chọn --table-size mà chúng ta đang sẽ sử dụng trong thao tác insert-only sau này):
mysql> CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`,`k`)
)
PARTITION BY RANGE (k) (
PARTITION p1 VALUES LESS THAN (499999),
PARTITION p2 VALUES LESS THAN MAXVALUE
);Chúng ta sẽ có 2 phân vùng - Phân vùng đầu tiên được gọi là p1 và sẽ lưu trữ dữ liệu trong đó giá trị trong cột "k" thấp hơn 499.999 và phân vùng thứ hai, p2, sẽ lưu trữ các giá trị còn lại . Chúng tôi cũng tạo một khóa chính chứa cả hai cột quan trọng - "id" là mã định danh hàng và "k" là khóa phân vùng. Trong phân vùng, khóa chính phải bao gồm tất cả các cột trong hàm phân vùng của bảng (trong đó chúng tôi sử dụng "k" trong hàm phân vùng phạm vi).
Xác minh các phân vùng ở đó:
mysql> SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA='sbtest2'
AND TABLE_NAME='sbtest1';
+--------------+------------+----------------+------------+
| TABLE_SCHEMA | TABLE_NAME | PARTITION_NAME | TABLE_ROWS |
+--------------+------------+----------------+------------+
| sbtest | sbtest1 | p1 | 0 |
| sbtest | sbtest1 | p2 | 0 |
+--------------+------------+----------------+------------+Sau đó, chúng tôi có thể bắt đầu hoạt động chỉ chèn Sysbench như sau:
$ sysbench \
/usr/share/sysbench/oltp_insert.lua \
--report-interval=2 \
--threads=4 \
--rate=20 \
--time=9999 \
--db-driver=mysql \
--mysql-host=192.168.11.131 \
--mysql-port=3306 \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=passw0rd \
--tables=1 \
--table-size=1000000 \
runXem các phân vùng bảng phát triển khi Sysbench chạy:
mysql> SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA='sbtest2'
AND TABLE_NAME='sbtest1';
+--------------+------------+----------------+------------+
| TABLE_SCHEMA | TABLE_NAME | PARTITION_NAME | TABLE_ROWS |
+--------------+------------+----------------+------------+
| sbtest | sbtest1 | p1 | 1021 |
| sbtest | sbtest1 | p2 | 1644 |
+--------------+------------+----------------+------------+Nếu chúng ta đếm tổng số hàng bằng cách sử dụng hàm COUNT, nó sẽ tương ứng với tổng số hàng được báo cáo bởi các phân vùng:
mysql> SELECT COUNT(id) FROM sbtest1;
+-----------+
| count(id) |
+-----------+
| 2665 |
+-----------+Vậy là xong. Chúng tôi đã sẵn sàng phân vùng bảng một máy chủ mà chúng tôi có thể sử dụng.
Phân vùng bảng nhiều máy chủ
Trong phân vùng nhiều máy chủ, chúng tôi sẽ sử dụng nhiều máy chủ MySQL để lưu trữ vật lý một tập hợp con dữ liệu của một bảng cụ thể (sbtest1), như thể hiện trong sơ đồ sau:
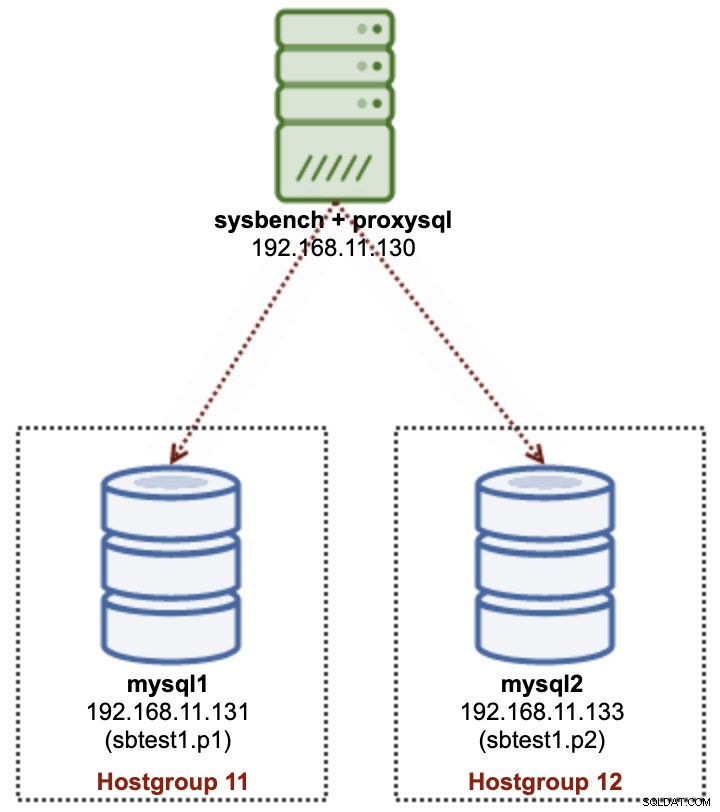
Chúng tôi sẽ triển khai 2 nút MySQL độc lập - mysql1 và mysql2. Bảng sbtest1 sẽ được phân vùng trên hai nút này và chúng ta sẽ gọi kết hợp phân vùng + máy chủ này là một phân đoạn. Sysbench đang chạy từ xa trên máy chủ thứ ba, bắt chước tầng ứng dụng. Vì Sysbench không nhận biết được phân vùng, chúng ta cần có trình điều khiển cơ sở dữ liệu hoặc bộ định tuyến để định tuyến các truy vấn cơ sở dữ liệu đến đúng phân đoạn. Chúng tôi sẽ sử dụng ProxySQL để đạt được mục đích này.
Hãy tạo một cơ sở dữ liệu mới khác có tên sbtest3 cho mục đích này:
mysql> CREATE SCHEMA sbtest3;
mysql> USE sbtest3;Cấp các đặc quyền phù hợp cho người dùng cơ sở dữ liệu sbtest:
mysql> CREATE USER 'sbtest'@'%' IDENTIFIED BY 'passw0rd';
mysql> GRANT ALL PRIVILEGES ON sbtest3.* TO 'sbtest'@'%';Trên mysql1, tạo phân vùng đầu tiên của bảng:
mysql> CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`,`k`)
)
PARTITION BY RANGE (k) (
PARTITION p1 VALUES LESS THAN (499999)
);Không giống như phân vùng độc lập, chúng tôi chỉ xác định điều kiện cho phân vùng p1 trong bảng để lưu trữ tất cả các hàng có giá trị cột "k" nằm trong khoảng từ 0 đến 499.999.
Trên mysql2, tạo một bảng được phân vùng khác:
mysql> CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`,`k`)
)
PARTITION BY RANGE (k) (
PARTITION p2 VALUES LESS THAN MAXVALUE
);Trên máy chủ thứ hai, nó phải giữ dữ liệu của phân vùng thứ hai bằng cách lưu trữ phần còn lại của các giá trị dự đoán của cột "k".
Cấu trúc bảng của chúng tôi hiện đã sẵn sàng để đưa vào dữ liệu thử nghiệm.
Trước khi có thể chạy thao tác chỉ chèn Sysbench, chúng ta cần cài đặt máy chủ ProxySQL làm bộ định tuyến truy vấn và hoạt động như cổng cho các mảnh MySQL của chúng ta. Sharding đa máy chủ yêu cầu các kết nối cơ sở dữ liệu đến từ các ứng dụng phải được định tuyến đến đúng phân đoạn. Nếu không, bạn sẽ thấy lỗi sau:
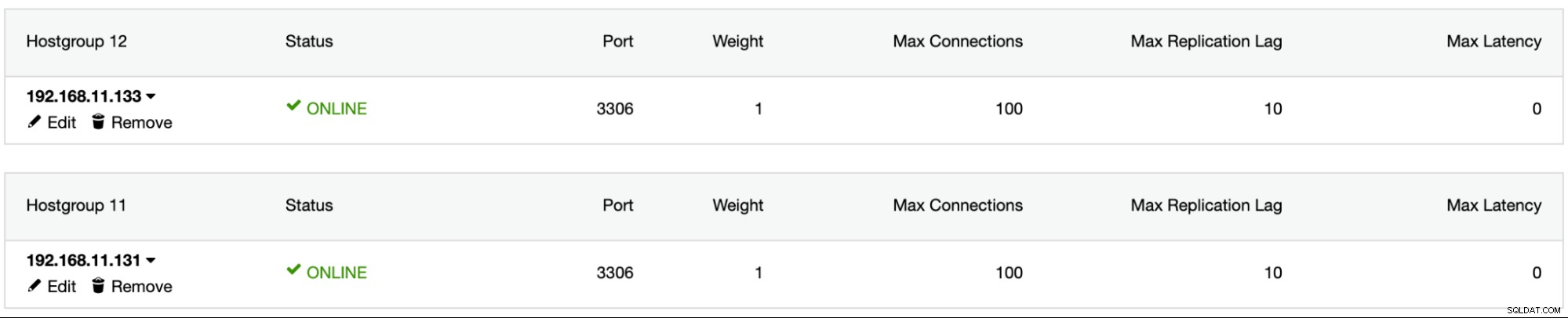
1526 (Table has no partition for value 503599)Cài đặt ProxySQL bằng ClusterControl, thêm người dùng cơ sở dữ liệu sbtest vào ProxySQL, thêm cả hai máy chủ MySQL vào ProxySQL và định cấu hình mysql1 làm nhóm máy chủ 11 và mysql2 làm nhóm máy chủ 12:
Tiếp theo, chúng ta cần tìm cách định tuyến truy vấn. Một mẫu truy vấn CHÈN sẽ được thực hiện bởi Sysbench sẽ trông giống như sau:
INSERT INTO sbtest1 (id, k, c, pad)
VALUES (0, 503502, '88816935247-23939908973-66486617366-05744537902-39238746973-63226063145-55370375476-52424898049-93208870738-99260097520', '36669559817-75903498871-26800752374-15613997245-76119597989')Vì vậy, chúng tôi sẽ sử dụng biểu thức chính quy sau để lọc truy vấn INSERT cho "k" => 500000, để đáp ứng điều kiện phân vùng:
^INSERT INTO sbtest1 \(id, k, c, pad\) VALUES \([0-9]\d*, ([5-9]{1,}[0-9]{5}|[1-9]{1,}[0-9]{6,}).*Biểu thức trên chỉ cố gắng lọc những điều sau:
-
[0-9] \ d * - Chúng tôi đang mong đợi một số nguyên tăng tự động ở đây, do đó, chúng tôi khớp với bất kỳ số nguyên nào.
-
[5-9] {1,} [0-9] {5} - Giá trị khớp với bất kỳ số nguyên nào từ 5 làm chữ số đầu tiên và 0-9 ở 5 chữ số cuối, để khớp với giá trị phạm vi từ 500.000 đến 999.999.
-
[1-9] {1,} [0-9] {6,} - Giá trị khớp với bất kỳ số nguyên nào từ 1-9 làm chữ số đầu tiên và 0-9 trên 6 chữ số cuối cùng hoặc lớn hơn, để khớp với giá trị từ 1.000.000 trở lên.
Chúng ta sẽ tạo hai quy tắc truy vấn tương tự. Quy tắc truy vấn đầu tiên là phủ định của biểu thức chính quy ở trên. Chúng tôi cung cấp quy tắc này ID 51 và nhóm máy chủ đích phải là nhóm máy chủ 11 để khớp với cột "k" <500.000 và chuyển tiếp các truy vấn đến phân vùng đầu tiên. Nó sẽ trông như thế này:
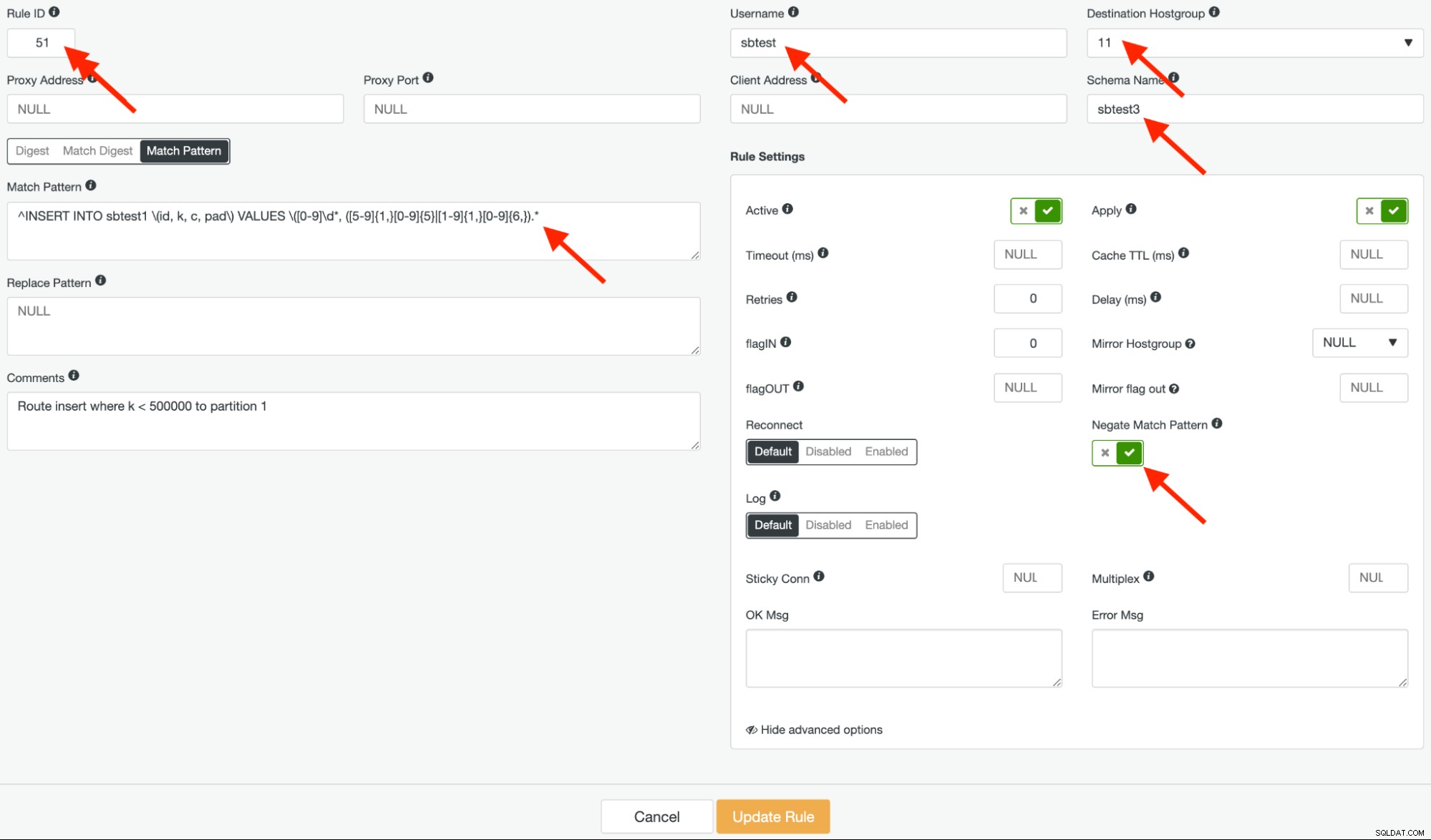
Hãy chú ý đến "Negate Match Pattern" trong ảnh chụp màn hình ở trên. Tùy chọn đó rất quan trọng đối với việc định tuyến đúng quy tắc truy vấn này.
Tiếp theo, tạo một quy tắc truy vấn khác với quy tắc ID 52, sử dụng cùng một biểu thức chính quy và nhóm máy chủ đích phải là 12, nhưng lần này, hãy để "Mẫu Đối sánh Phủ định" là sai, như được hiển thị bên dưới:
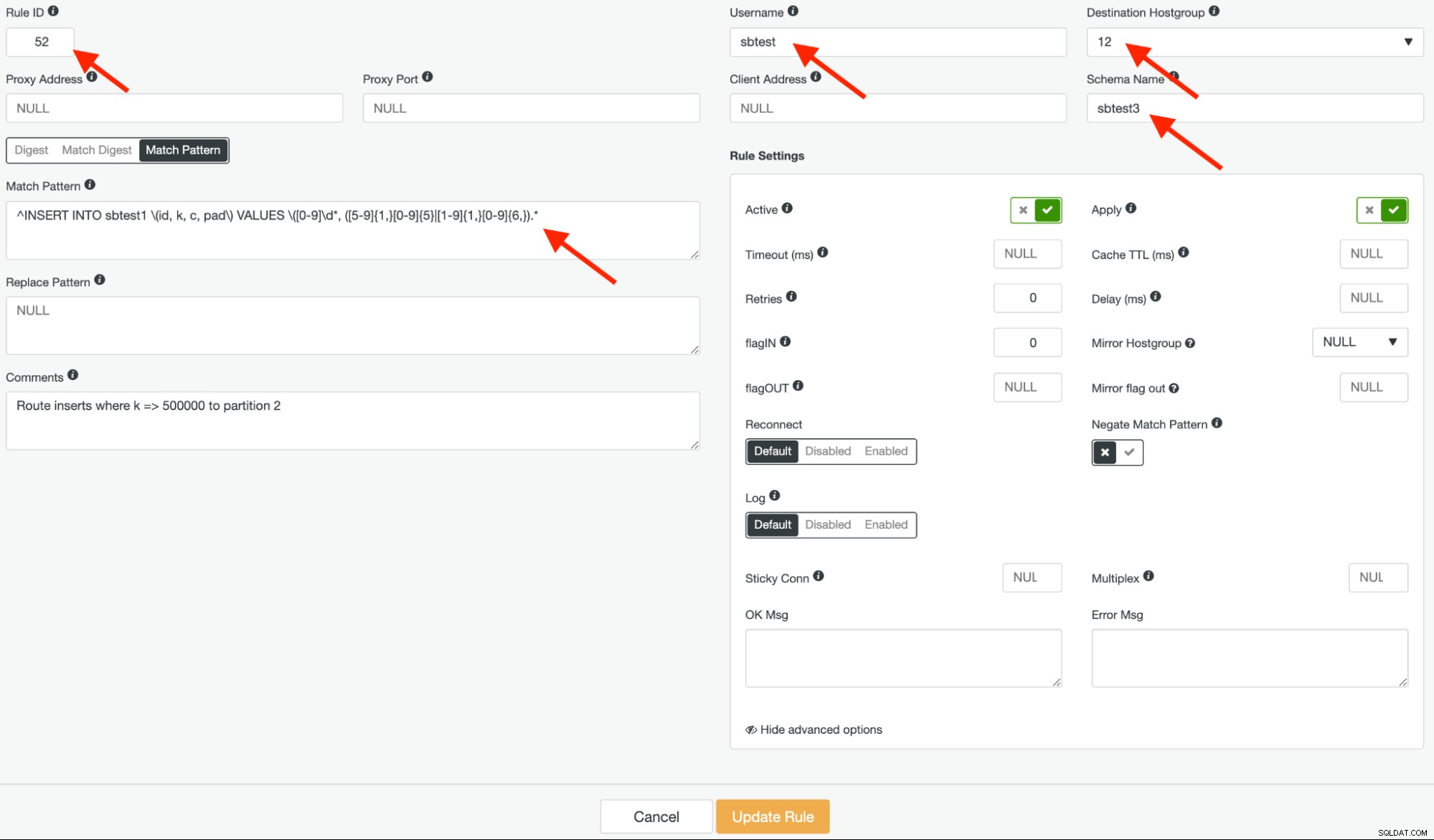
Sau đó, chúng tôi có thể bắt đầu hoạt động chỉ chèn bằng cách sử dụng Sysbench để tạo dữ liệu thử nghiệm . Thông tin liên quan đến quyền truy cập MySQL phải là máy chủ ProxySQL (192.168.11.130 trên cổng 6033):
$ sysbench \
/usr/share/sysbench/oltp_insert.lua \
--report-interval=2 \
--threads=4 \
--rate=20 \
--time=9999 \
--db-driver=mysql \
--mysql-host=192.168.11.130 \
--mysql-port=6033 \
--mysql-user=sbtest \
--mysql-db=sbtest3 \
--mysql-password=passw0rd \
--tables=1 \
--table-size=1000000 \
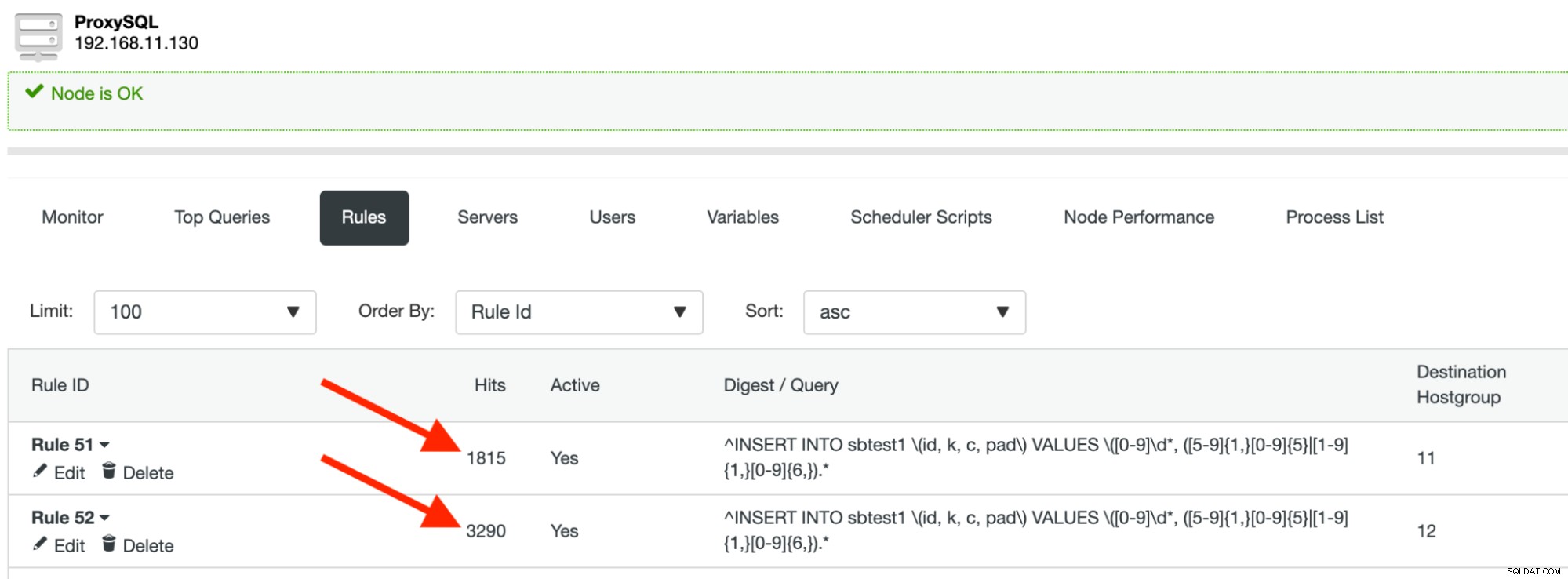
runNếu bạn không thấy bất kỳ lỗi nào, điều đó có nghĩa là ProxySQL đã định tuyến các truy vấn của chúng tôi đến đúng phân đoạn / phân vùng. Bạn sẽ thấy số lần truy cập quy tắc truy vấn đang tăng lên trong khi quá trình Sysbench đang chạy:
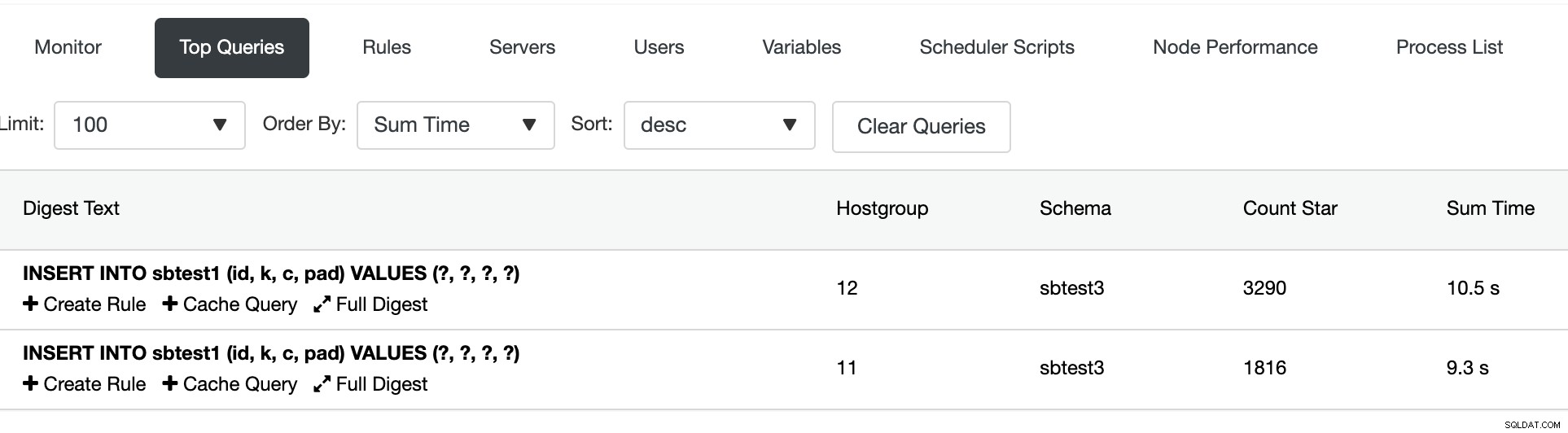
Trong phần Truy vấn hàng đầu, chúng ta có thể xem tóm tắt định tuyến truy vấn:
Để kiểm tra kỹ, hãy đăng nhập vào mysql1 để tìm phân vùng đầu tiên và kiểm tra giá trị tối thiểu và lớn nhất của cột 'k' trên bảng sbtest1:
mysql> USE sbtest3;
mysql> SELECT min(k), max(k) FROM sbtest1;
+--------+--------+
| min(k) | max(k) |
+--------+--------+
| 232185 | 499998 |
+--------+--------+Trông tuyệt. Giá trị lớn nhất của cột "k" không vượt quá giới hạn 499.999. Hãy kiểm tra số hàng mà nó lưu trữ cho phân vùng này:
mysql> SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA='sbtest3'
AND TABLE_NAME='sbtest1';
+--------------+------------+----------------+------------+
| TABLE_SCHEMA | TABLE_NAME | PARTITION_NAME | TABLE_ROWS |
+--------------+------------+----------------+------------+
| sbtest3 | sbtest1 | p1 | 1815 |
+--------------+------------+----------------+------------+Bây giờ hãy kiểm tra máy chủ MySQL khác (mysql2):
mysql> USE sbtest3;
mysql> SELECT min(k), max(k) FROM sbtest1;
+--------+--------+
| min(k) | max(k) |
+--------+--------+
| 500003 | 794952 |
+--------+--------+Hãy kiểm tra số hàng mà nó lưu trữ cho phân vùng này:
mysql> SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA='sbtest3'
AND TABLE_NAME='sbtest1';
+--------------+------------+----------------+------------+
| TABLE_SCHEMA | TABLE_NAME | PARTITION_NAME | TABLE_ROWS |
+--------------+------------+----------------+------------+
| sbtest3 | sbtest1 | p2 | 3247 |
+--------------+------------+----------------+------------+Tuyệt vời! Chúng tôi có một thiết lập thử nghiệm MySQL được phân đoạn với phân vùng dữ liệu thích hợp bằng cách sử dụng Sysbench để chúng tôi thử nghiệm. Chúc bạn đạt điểm chuẩn vui vẻ!