Dữ liệu có lẽ là một trong những tài sản quý giá nhất trong một công ty. Do đó, chúng ta phải luôn có Kế hoạch khôi phục sau thảm họa (DRP) để ngăn ngừa mất dữ liệu trong trường hợp xảy ra sự cố hoặc lỗi phần cứng.
Bản sao lưu là dạng DR đơn giản nhất, tuy nhiên, nó có thể không phải lúc nào cũng đủ để đảm bảo Mục tiêu Điểm khôi phục (RPO) được chấp nhận. Bạn nên lưu trữ ít nhất ba bản sao lưu ở những nơi thực tế khác nhau.
Phương pháp hay nhất yêu cầu các tệp sao lưu phải có một tệp được lưu trữ cục bộ trên máy chủ cơ sở dữ liệu (để khôi phục nhanh hơn), một tệp khác trong máy chủ sao lưu tập trung và tệp cuối cùng là đám mây.
Đối với blog này, chúng tôi sẽ xem xét các tùy chọn mà Amazon AWS cung cấp để lưu trữ các bản sao lưu PostgreSQL trên đám mây và chúng tôi sẽ hiển thị một số ví dụ về cách thực hiện.
Giới thiệu về Amazon AWS
Amazon AWS là một trong những nhà cung cấp dịch vụ đám mây tiên tiến nhất thế giới về tính năng và dịch vụ, với hàng triệu khách hàng. Nếu chúng tôi muốn chạy cơ sở dữ liệu PostgreSQL của mình trên Amazon AWS, chúng tôi có một số tùy chọn ...
-
Amazon RDS:Nó cho phép chúng tôi tạo, quản lý và mở rộng cơ sở dữ liệu PostgreSQL (hoặc các công nghệ cơ sở dữ liệu khác nhau) trên đám mây một cách dễ dàng và nhanh chóng.
-
Amazon Aurora:Đó là cơ sở dữ liệu tương thích với PostgreSQL được xây dựng cho đám mây. Theo trang web AWS, tốc độ này nhanh hơn ba lần so với cơ sở dữ liệu PostgreSQL tiêu chuẩn.
-
Amazon EC2:Đây là một dịch vụ web cung cấp khả năng tính toán có thể thay đổi kích thước trên đám mây. Nó cung cấp cho bạn quyền kiểm soát hoàn toàn các tài nguyên máy tính của bạn và cho phép bạn thiết lập và định cấu hình mọi thứ về các phiên bản của bạn từ hệ điều hành cho đến các ứng dụng của bạn.
Nhưng trên thực tế, chúng tôi không cần phải có cơ sở dữ liệu của mình chạy trên Amazon để lưu trữ các bản sao lưu của chúng tôi tại đây.
Lưu trữ Bản sao lưu trên Amazon AWS
Có các tùy chọn khác nhau để lưu trữ bản sao lưu PostgreSQL của chúng tôi trên AWS. Nếu chúng tôi đang chạy cơ sở dữ liệu PostgreSQL của mình trên AWS, chúng tôi có nhiều tùy chọn hơn và (vì chúng tôi đang ở trong cùng một mạng) nó cũng có thể nhanh hơn. Hãy xem cách AWS có thể giúp chúng tôi lưu trữ các bản sao lưu của mình.
AWS CLI
Trước tiên, hãy chuẩn bị môi trường của chúng tôi để thử nghiệm các tùy chọn AWS khác nhau. Đối với các ví dụ của chúng tôi, chúng tôi sẽ sử dụng máy chủ PostgreSQL 11 tại chỗ, chạy trên CentOS 7. Tại đây, chúng tôi cần cài đặt AWS CLI theo hướng dẫn từ trang web này.
Khi chúng tôi đã cài đặt AWS CLI, chúng tôi có thể kiểm tra nó từ dòng lệnh:
[example@sqldat.com ~]# aws --version
aws-cli/1.16.225 Python/2.7.5 Linux/4.15.18-14-pve botocore/1.12.215Bây giờ, bước tiếp theo là định cấu hình ứng dụng khách mới của chúng tôi đang chạy lệnh aws với tùy chọn cấu hình.
[example@sqldat.com ~]# aws configure
AWS Access Key ID [None]: AKIA7TMEO21BEBR1A7HR
AWS Secret Access Key [None]: SxrCECrW/RGaKh2FTYTyca7SsQGNUW4uQ1JB8hRp
Default region name [None]: us-east-1
Default output format [None]:Để nhận thông tin này, bạn có thể đi tới Phần IAM AWS và kiểm tra người dùng hiện tại hoặc nếu muốn, bạn có thể tạo một người mới cho tác vụ này.
Sau đó, chúng tôi đã sẵn sàng sử dụng AWS CLI để truy cập các dịch vụ Amazon AWS của chúng tôi.
Amazon S3
Đây có lẽ là tùy chọn được sử dụng phổ biến nhất để lưu trữ các bản sao lưu trên đám mây. Amazon S3 có thể lưu trữ và truy xuất bất kỳ lượng dữ liệu nào từ bất kỳ đâu trên Internet. Đây là một dịch vụ lưu trữ đơn giản cung cấp cơ sở hạ tầng lưu trữ dữ liệu cực kỳ bền, có tính khả dụng cao và khả năng mở rộng vô hạn với chi phí thấp.
Amazon S3 cung cấp giao diện dịch vụ web đơn giản mà bạn có thể sử dụng để lưu trữ và truy xuất bất kỳ lượng dữ liệu nào, bất kỳ lúc nào, từ bất kỳ đâu trên web và (với AWS CLI hoặc AWS SDK) bạn có thể tích hợp nó với các hệ thống và ngôn ngữ lập trình khác nhau.
Cách sử dụng
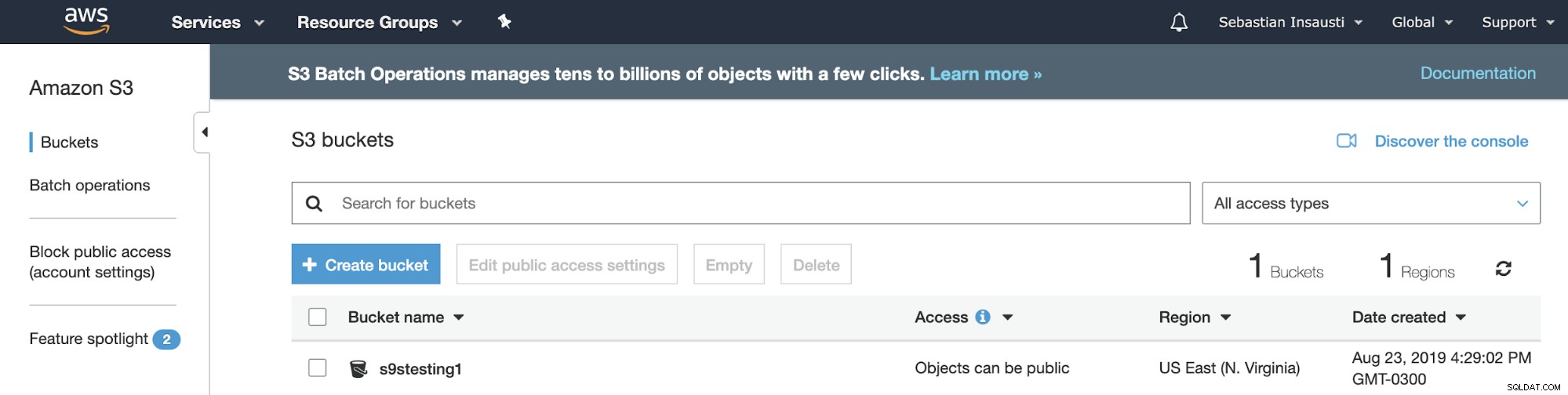
Amazon S3 sử dụng Nhóm. Chúng là những vùng chứa duy nhất cho mọi thứ mà bạn lưu trữ trong Amazon S3. Vì vậy, bước đầu tiên là truy cập Bảng điều khiển quản lý Amazon S3 và tạo Nhóm mới.
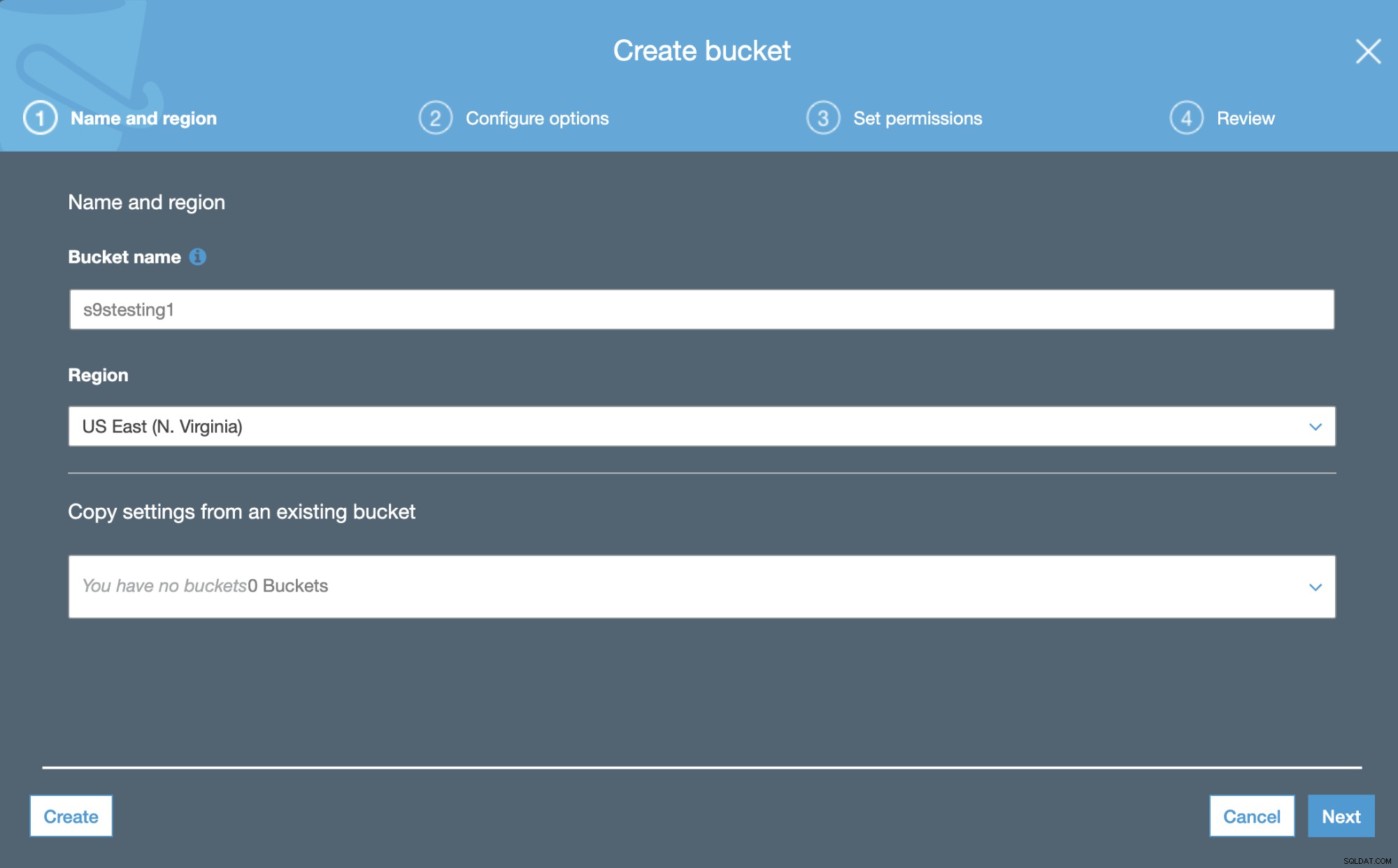
Ở bước đầu tiên, chúng ta chỉ cần thêm tên Nhóm và Khu vực AWS.
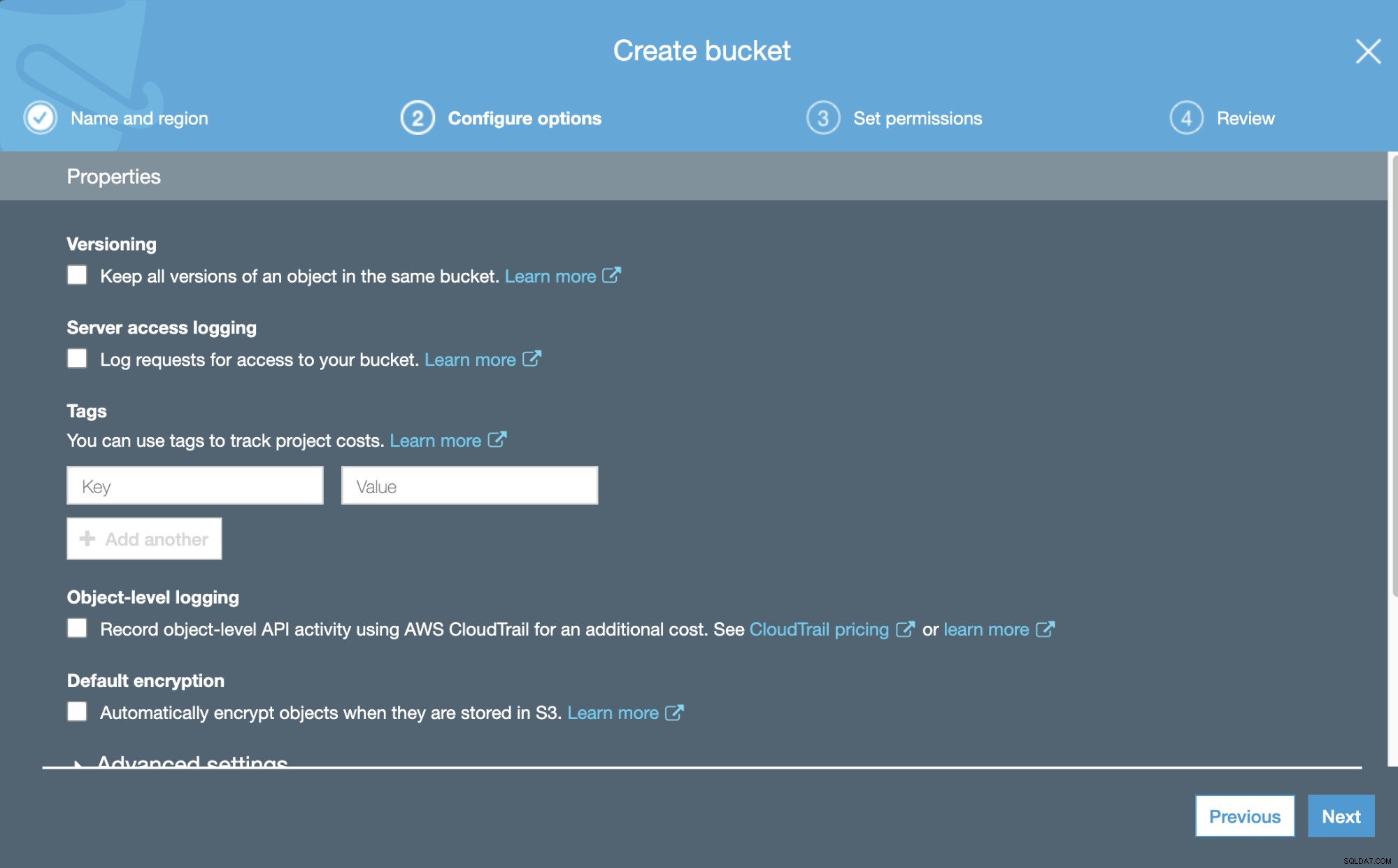
Bây giờ, chúng ta có thể định cấu hình một số chi tiết về Nhóm mới của mình, như lập phiên bản và ghi nhật ký.

Và sau đó, chúng tôi có thể chỉ định các quyền cho Nhóm mới này.
Bây giờ chúng ta đã tạo Nhóm của mình, hãy xem cách chúng ta có thể sử dụng nó để lưu trữ các bản sao lưu PostgreSQL của chúng tôi.
Trước tiên, hãy kiểm tra ứng dụng khách của chúng tôi kết nối nó với S3.
[example@sqldat.com ~]# aws s3 ls
2019-08-23 19:29:02 s9stesting1Nó hoạt động! Với lệnh trước, chúng tôi liệt kê các Nhóm hiện tại đã được tạo.
Vì vậy, bây giờ, chúng ta có thể tải bản sao lưu lên dịch vụ S3. Đối với điều này, chúng ta có thể sử dụng lệnh aws sync hoặc aws cp.
[example@sqldat.com ~]# aws s3 sync /root/backups/BACKUP-5/ s3://s9stesting1/backups/
upload: backups/BACKUP-5/cmon_backup.metadata to s3://s9stesting1/backups/cmon_backup.metadata
upload: backups/BACKUP-5/cmon_backup.log to s3://s9stesting1/backups/cmon_backup.log
upload: backups/BACKUP-5/base.tar.gz to s3://s9stesting1/backups/base.tar.gz
[example@sqldat.com ~]#
[example@sqldat.com ~]# aws s3 cp /root/backups/BACKUP-6/pg_dump_2019-08-23_205919.sql.gz s3://s9stesting1/backups/
upload: backups/BACKUP-6/pg_dump_2019-08-23_205919.sql.gz to s3://s9stesting1/backups/pg_dump_2019-08-23_205919.sql.gz
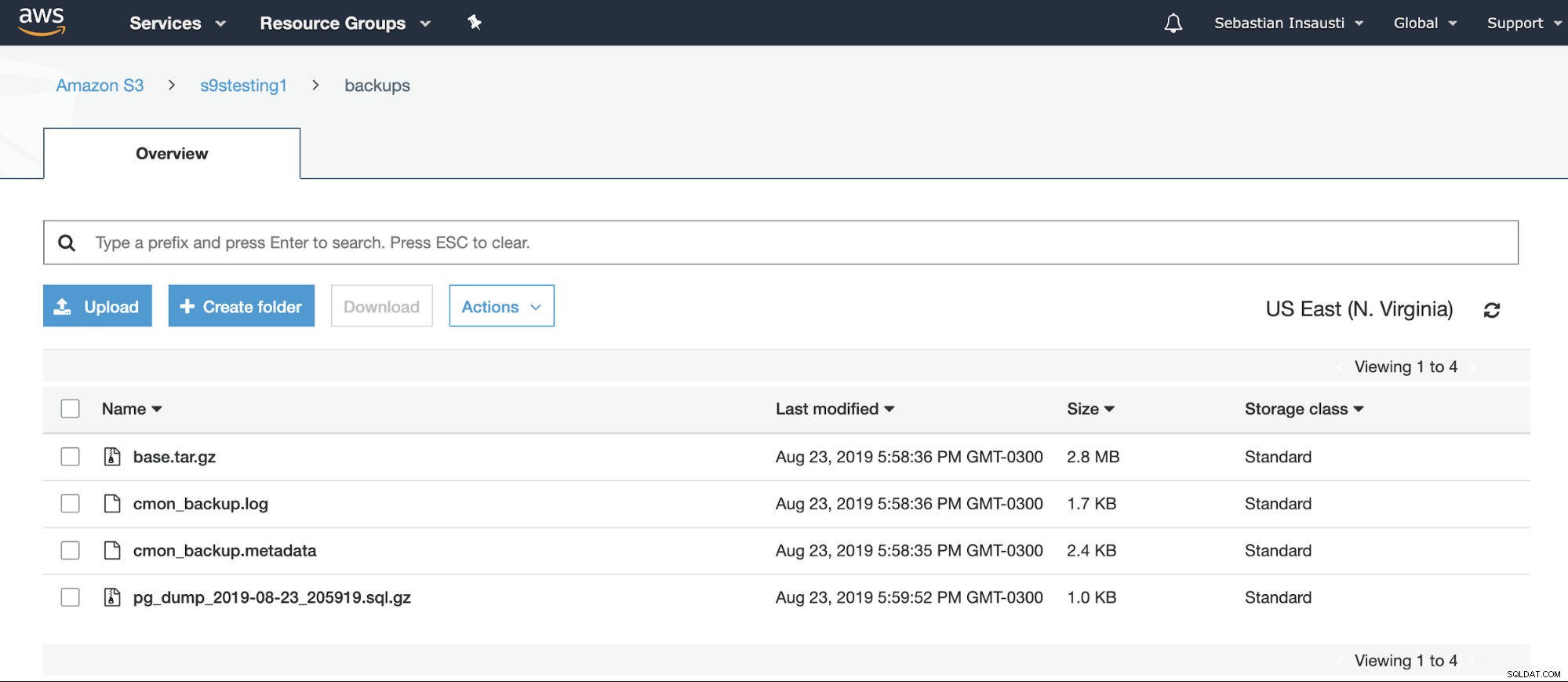
[example@sqldat.com ~]# Chúng tôi có thể kiểm tra nội dung Nhóm từ trang web AWS.
Hoặc thậm chí bằng cách sử dụng AWS CLI.
[example@sqldat.com ~]# aws s3 ls s3://s9stesting1/backups/
2019-08-23 19:29:31 0
2019-08-23 20:58:36 2974633 base.tar.gz
2019-08-23 20:58:36 1742 cmon_backup.log
2019-08-23 20:58:35 2419 cmon_backup.metadata
2019-08-23 20:59:52 1028 pg_dump_2019-08-23_205919.sql.gzĐể biết thêm thông tin về AWS S3 CLI, bạn có thể xem tài liệu AWS chính thức.
Amazon S3 Glacier
Đây là phiên bản Amazon S3 chi phí thấp hơn. Sự khác biệt chính giữa chúng là vận tốc và khả năng tiếp cận. Bạn có thể sử dụng Amazon S3 Glacier nếu chi phí lưu trữ cần duy trì ở mức thấp và bạn không yêu cầu quyền truy cập phần nghìn giây vào dữ liệu của mình. Cách sử dụng là một khác biệt quan trọng giữa chúng.
Cách sử dụng
Thay vì Thùng, Amazon S3 Glacier sử dụng Vaults. Nó là một thùng chứa để lưu trữ bất kỳ đồ vật nào. Vì vậy, bước đầu tiên là truy cập Bảng điều khiển quản lý Amazon S3 Glacier và tạo Vault mới.
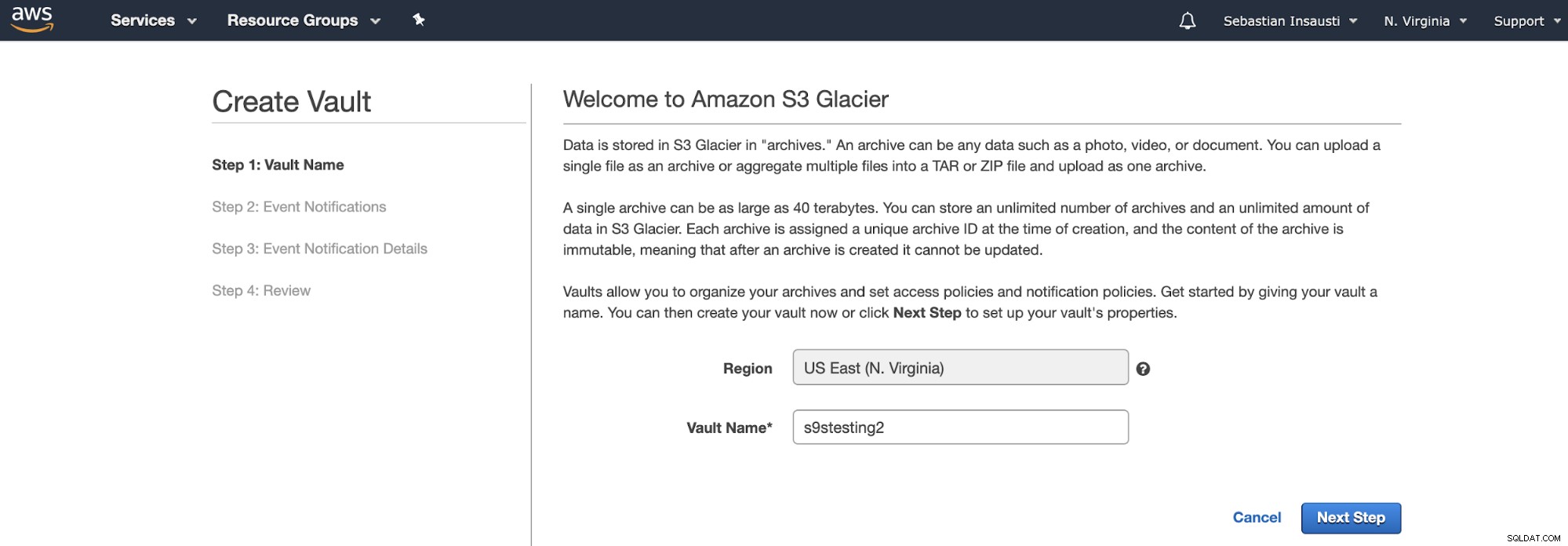
Tại đây, chúng ta cần thêm Tên Vault và Khu vực và trong bước tiếp theo, chúng tôi có thể bật thông báo sự kiện sử dụng Dịch vụ thông báo đơn giản của Amazon (Amazon SNS).
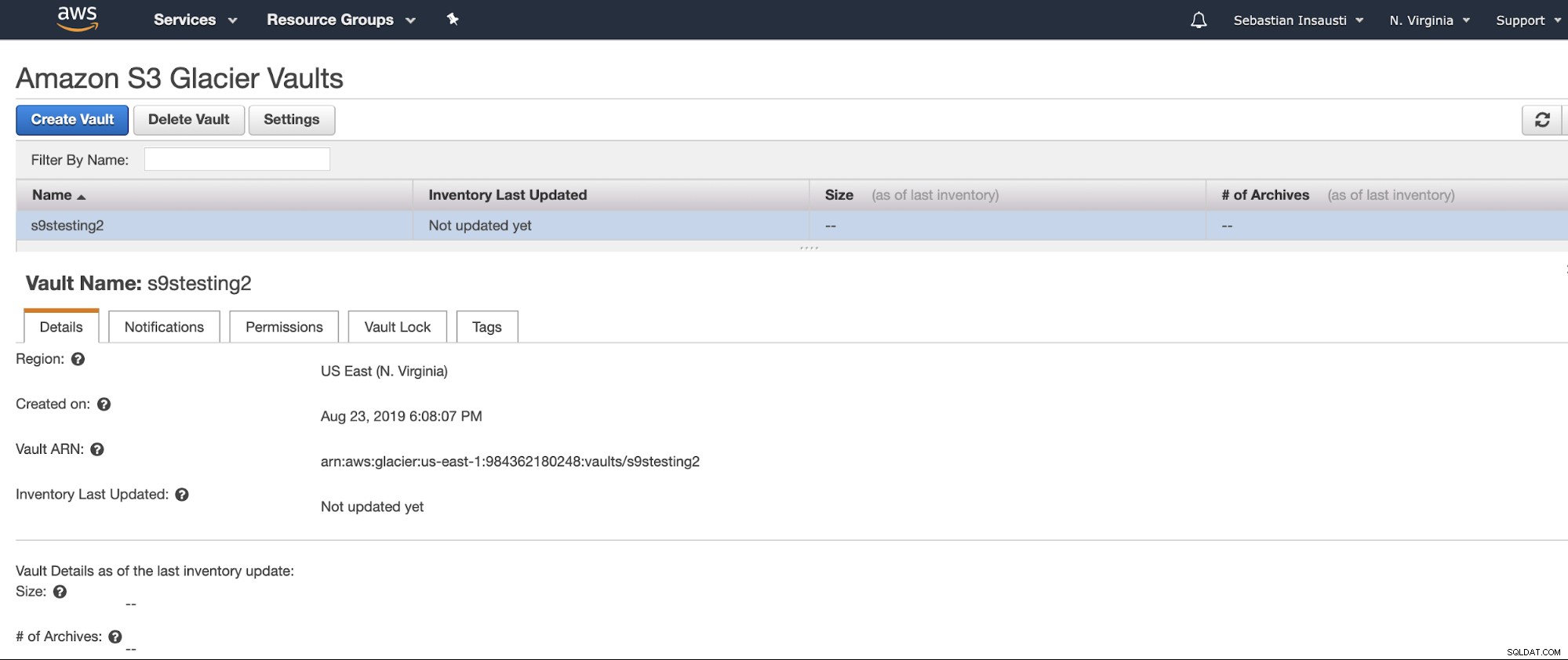
Bây giờ chúng ta đã tạo Vault, chúng ta có thể truy cập nó từ AWS CLI .
[example@sqldat.com ~]# aws glacier describe-vault --account-id - --vault-name s9stesting2
{
"SizeInBytes": 0,
"VaultARN": "arn:aws:glacier:us-east-1:984227183428:vaults/s9stesting2",
"NumberOfArchives": 0,
"CreationDate": "2019-08-23T21:08:07.943Z",
"VaultName": "s9stesting2"
}Nó đang hoạt động. Vì vậy, bây giờ, chúng tôi có thể tải lên bản sao lưu của mình tại đây.
[example@sqldat.com ~]# aws glacier upload-archive --body /root/backups/BACKUP-6/pg_dump_2019-08-23_205919.sql.gz --account-id - --archive-description "Backup upload test" --vault-name s9stesting2
{
"archiveId": "ddgCJi_qCJaIVinEW-xRl4I_0u2a8Ge5d2LHfoFBlO6SLMzG_0Cw6fm-OLJy4ZH_vkSh4NzFG1hRRZYDA-QBCEU4d8UleZNqsspF6MI1XtZFOo_bVcvIorLrXHgd3pQQmPbxI8okyg",
"checksum": "258faaa90b5139cfdd2fb06cb904fe8b0c0f0f80cba9bb6f39f0d7dd2566a9aa",
"location": "/984227183428/vaults/s9stesting2/archives/ddgCJi_qCJaIVinEW-xRl4I_0u2a8Ge5d2LHfoFBlO6SLMzG_0Cw6fm-OLJy4ZH_vkSh4NzFG1hRRZYDA-QBCEU4d8UleZNqsspF6MI1XtZFOo_bVcvIorLrXHgd3pQQmPbxI8okyg"
}Một điều quan trọng là trạng thái Vault được cập nhật khoảng một lần mỗi ngày, vì vậy chúng tôi nên đợi để xem tệp được tải lên.
[example@sqldat.com ~]# aws glacier describe-vault --account-id - --vault-name s9stesting2
{
"SizeInBytes": 33796,
"VaultARN": "arn:aws:glacier:us-east-1:984227183428:vaults/s9stesting2",
"LastInventoryDate": "2019-08-24T06:37:02.598Z",
"NumberOfArchives": 1,
"CreationDate": "2019-08-23T21:08:07.943Z",
"VaultName": "s9stesting2"
}Tại đây, chúng tôi đã tải tệp lên trên S3 Glacier Vault của chúng tôi.
Để biết thêm thông tin về AWS Glacier CLI, bạn có thể xem tài liệu AWS chính thức.
EC2
Tùy chọn lưu trữ sao lưu này đắt hơn và tốn thời gian hơn, nhưng nó hữu ích nếu bạn muốn có toàn quyền kiểm soát môi trường lưu trữ sao lưu và muốn thực hiện các tác vụ tùy chỉnh trên các bản sao lưu (ví dụ:Xác minh sao lưu .)
Amazon EC2 (Elastic Compute Cloud) là một dịch vụ web cung cấp khả năng tính toán có thể thay đổi kích thước trên đám mây. Nó cung cấp cho bạn quyền kiểm soát hoàn toàn các tài nguyên máy tính của bạn và cho phép bạn thiết lập và cấu hình mọi thứ về các phiên bản của bạn từ hệ điều hành cho đến các ứng dụng của bạn. Nó cũng cho phép bạn nhanh chóng mở rộng dung lượng, cả tăng và giảm, khi yêu cầu máy tính của bạn thay đổi.
Amazon EC2 hỗ trợ các hệ điều hành khác nhau như Amazon Linux, Ubuntu, Windows Server, Red Hat Enterprise Linux, SUSE Linux Enterprise Server, Fedora, Debian, CentOS, Gentoo Linux, Oracle Linux và FreeBSD.
Cách sử dụng
Đi tới phần Amazon EC2 và nhấn vào Khởi chạy Phiên bản. Trong bước đầu tiên, bạn phải chọn hệ điều hành phiên bản EC2.
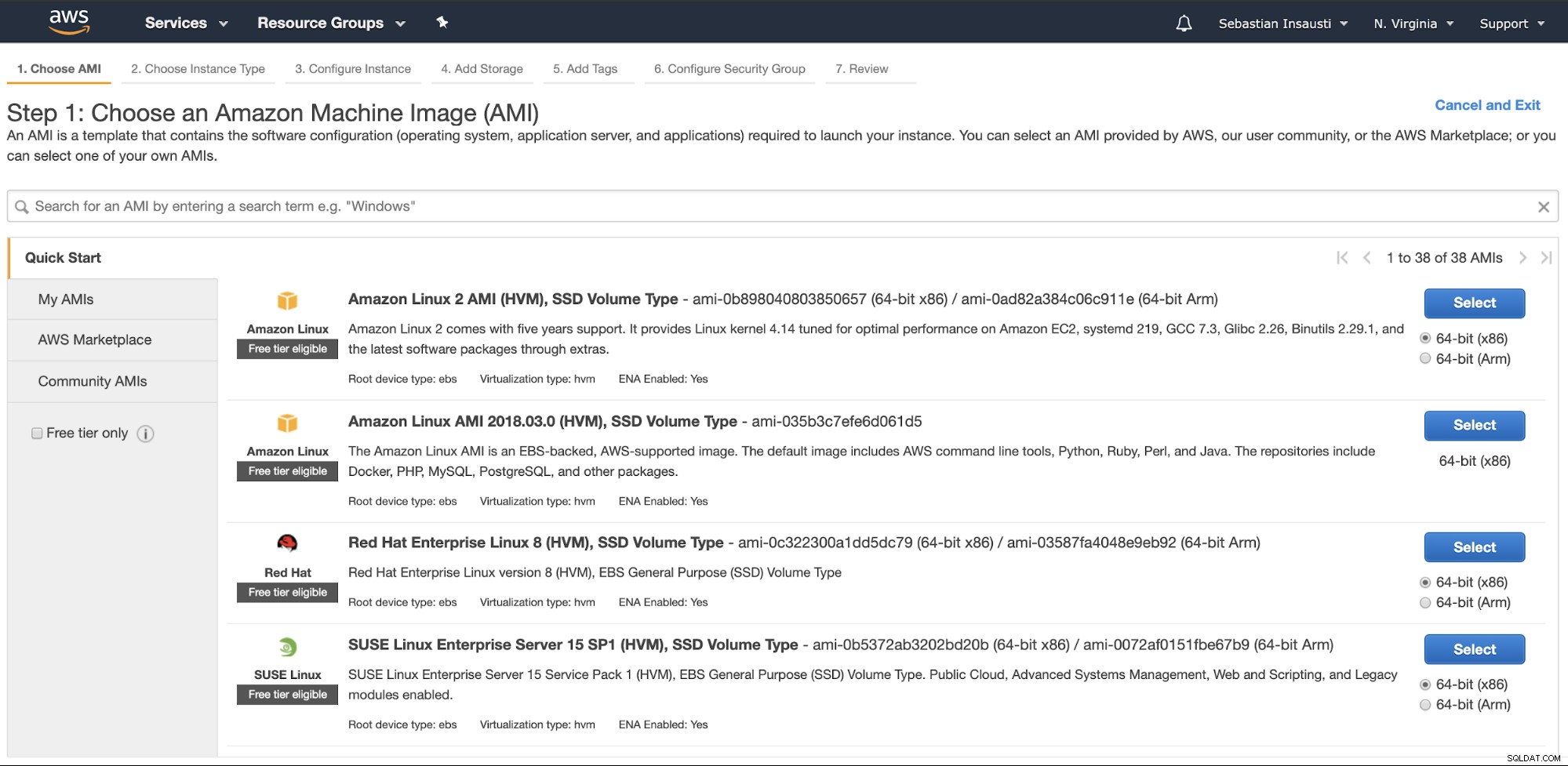
Trong bước tiếp theo, bạn phải chọn tài nguyên cho phiên bản mới.
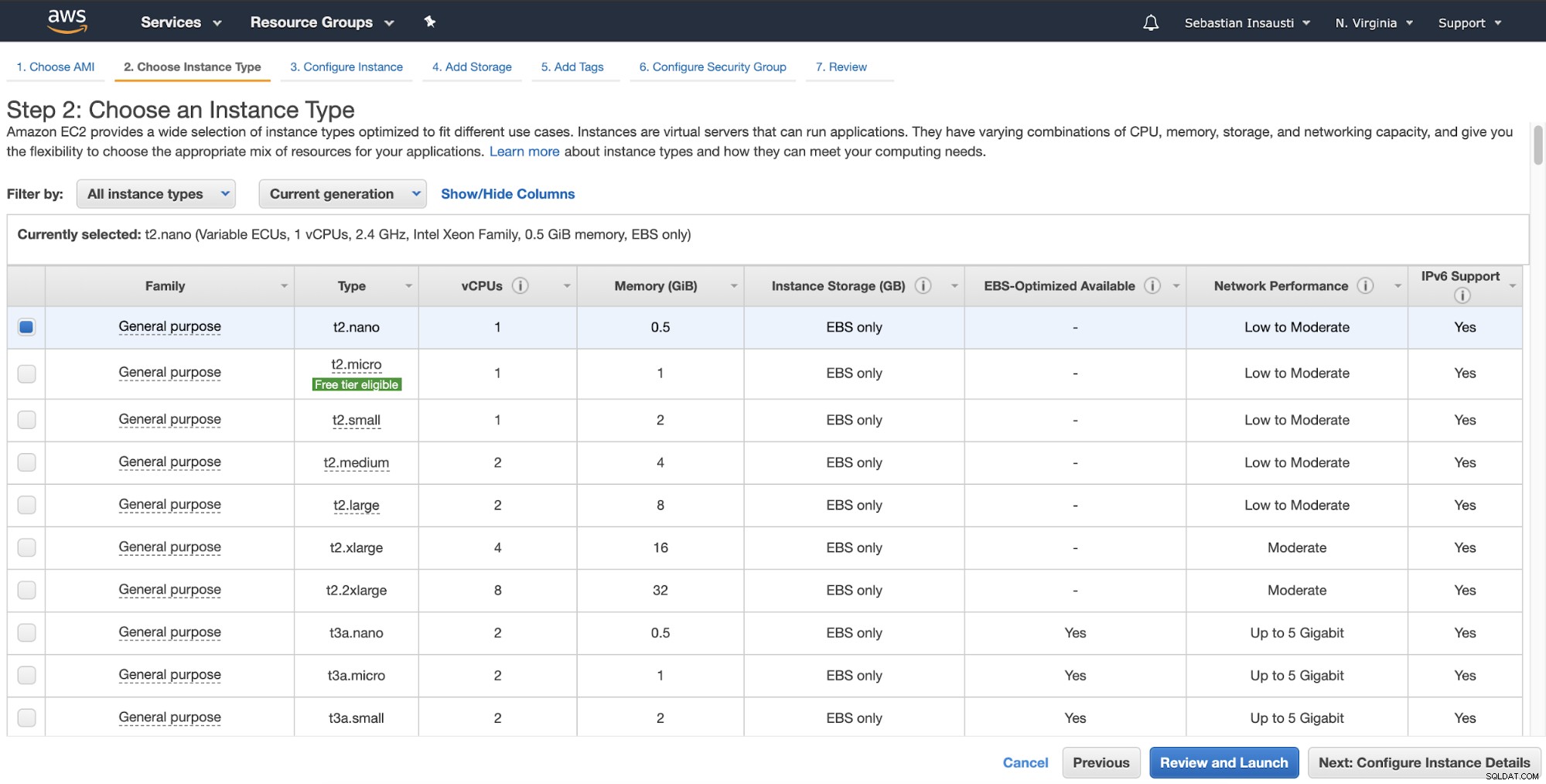
Sau đó, bạn có thể chỉ định cấu hình chi tiết hơn như mạng, mạng con, v.v. .
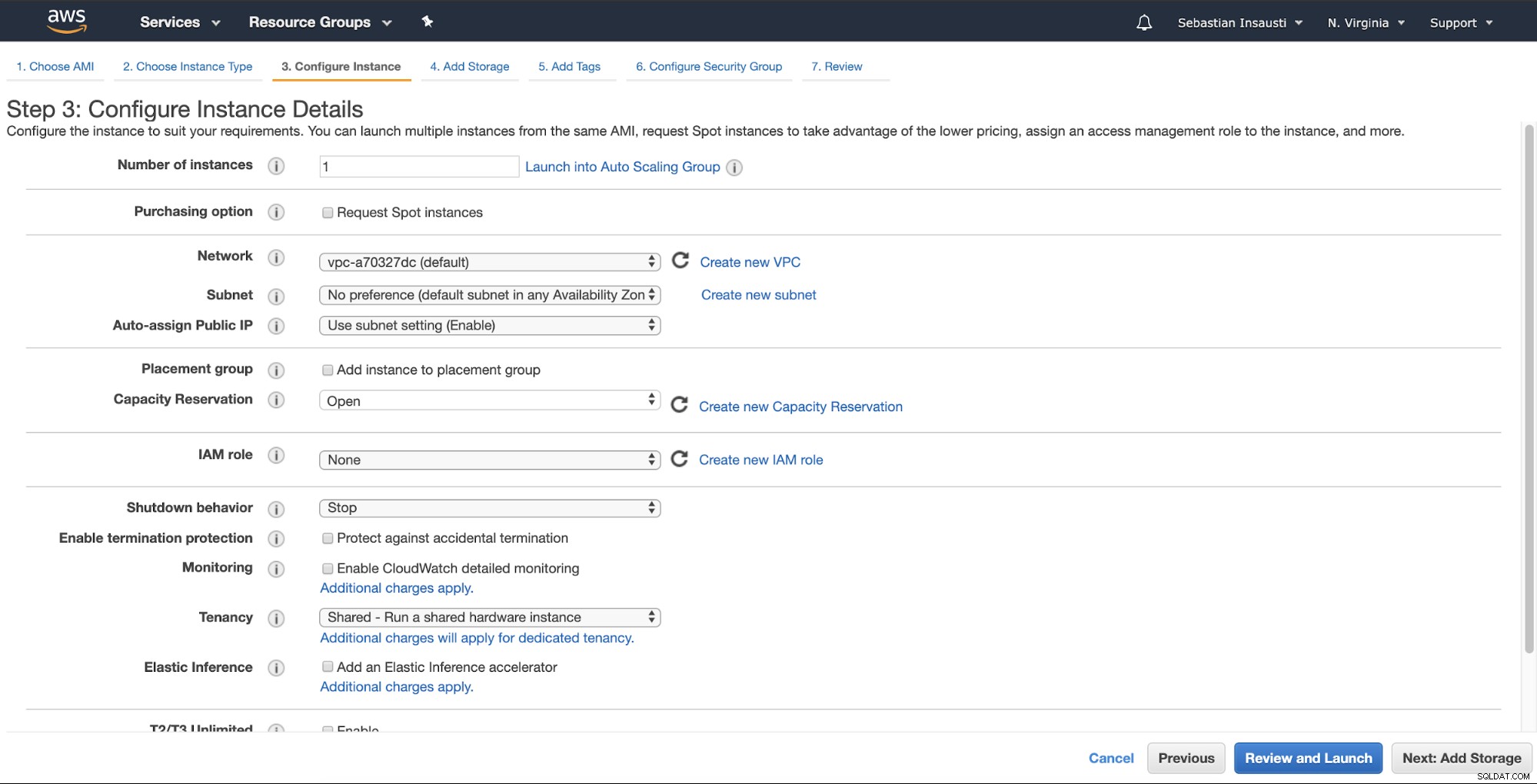
Bây giờ, chúng tôi có thể thêm nhiều dung lượng lưu trữ hơn trên phiên bản mới này và như một máy chủ dự phòng, chúng ta nên làm điều đó.
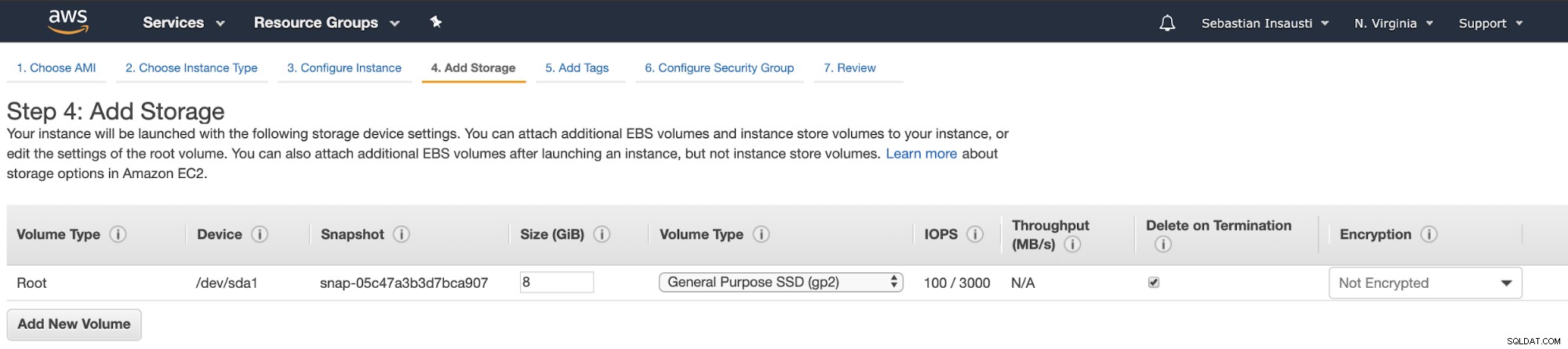
Khi hoàn thành tác vụ tạo, chúng ta có thể chuyển đến phần Phiên bản để xem phiên bản EC2 mới của chúng tôi.
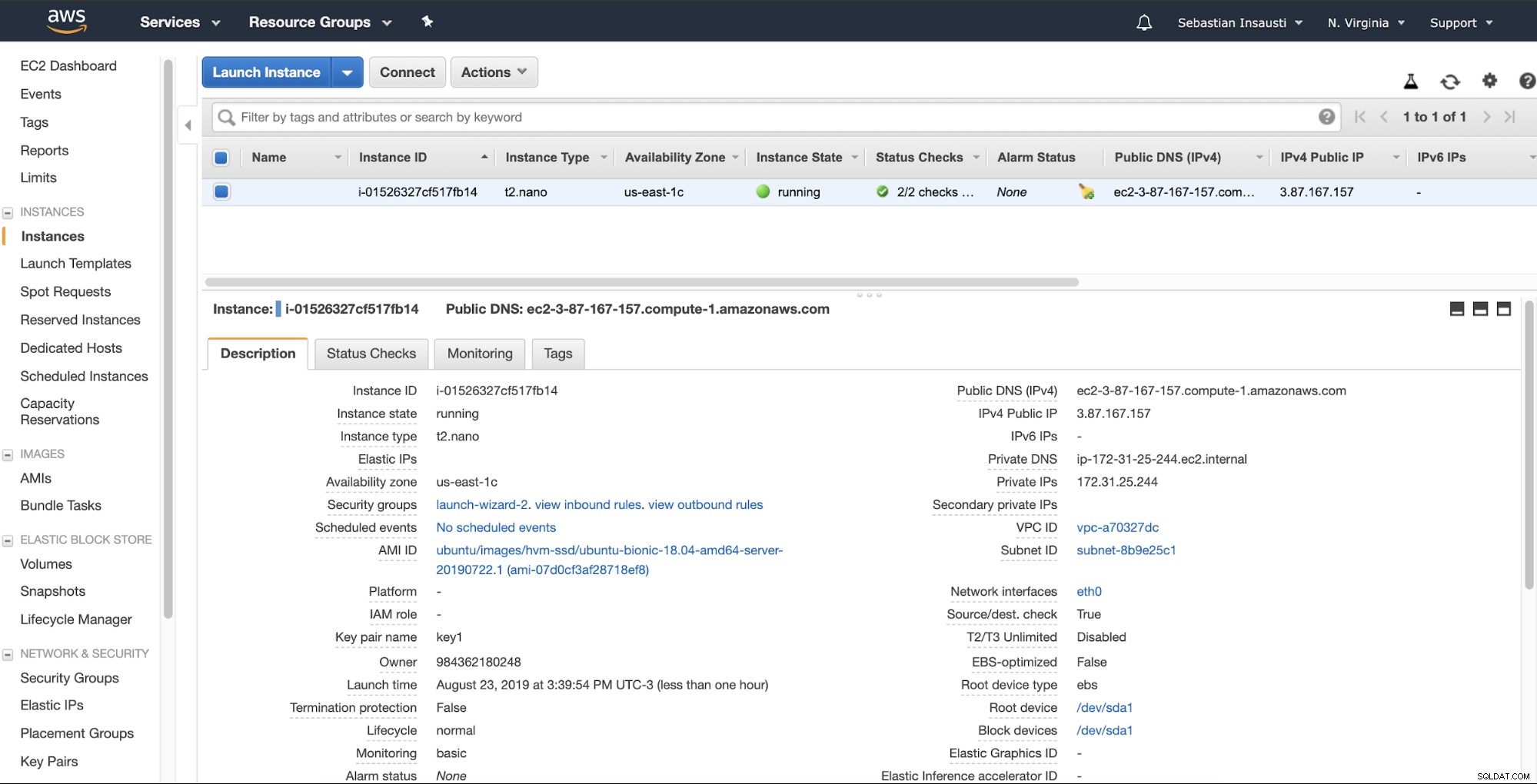
Khi phiên bản đã sẵn sàng (Trạng thái phiên bản đang chạy), bạn có thể lưu trữ tại đây, ví dụ:gửi bản sao lưu qua SSH hoặc FTP bằng DNS công cộng do AWS tạo. Hãy xem một ví dụ với Rsync và một ví dụ khác với lệnh SCP Linux.
[example@sqldat.com ~]# rsync -avzP -e "ssh -i /home/user/key1.pem" /root/backups/BACKUP-11/base.tar.gz example@sqldat.com:/backups/20190823/
sending incremental file list
base.tar.gz
4,091,563 100% 2.18MB/s 0:00:01 (xfr#1, to-chk=0/1)
sent 3,735,675 bytes received 35 bytes 574,724.62 bytes/sec
total size is 4,091,563 speedup is 1.10
[example@sqldat.com ~]#
[example@sqldat.com ~]# scp -i /tmp/key1.pem /root/backups/BACKUP-12/pg_dump_2019-08-25_211903.sql.gz example@sqldat.com:/backups/20190823/
pg_dump_2019-08-25_211903.sql.gz 100% 24KB 76.4KB/s 00:00AWS Backup
AWS Backup là dịch vụ sao lưu tập trung cung cấp cho bạn khả năng quản lý sao lưu, chẳng hạn như lập lịch sao lưu, quản lý lưu giữ và giám sát sao lưu, cũng như các tính năng bổ sung, chẳng hạn như sao lưu vòng đời với chi phí thấp tầng lưu trữ, lưu trữ sao lưu và mã hóa độc lập với dữ liệu nguồn của nó và các chính sách truy cập sao lưu.
Bạn có thể sử dụng AWS Backup để quản lý các bản sao lưu của khối lượng EBS, cơ sở dữ liệu RDS, bảng DynamoDB, hệ thống tệp EFS và khối lượng Storage Gateway.
Cách sử dụng
Đi tới phần Sao lưu AWS trên Bảng điều khiển quản lý AWS.
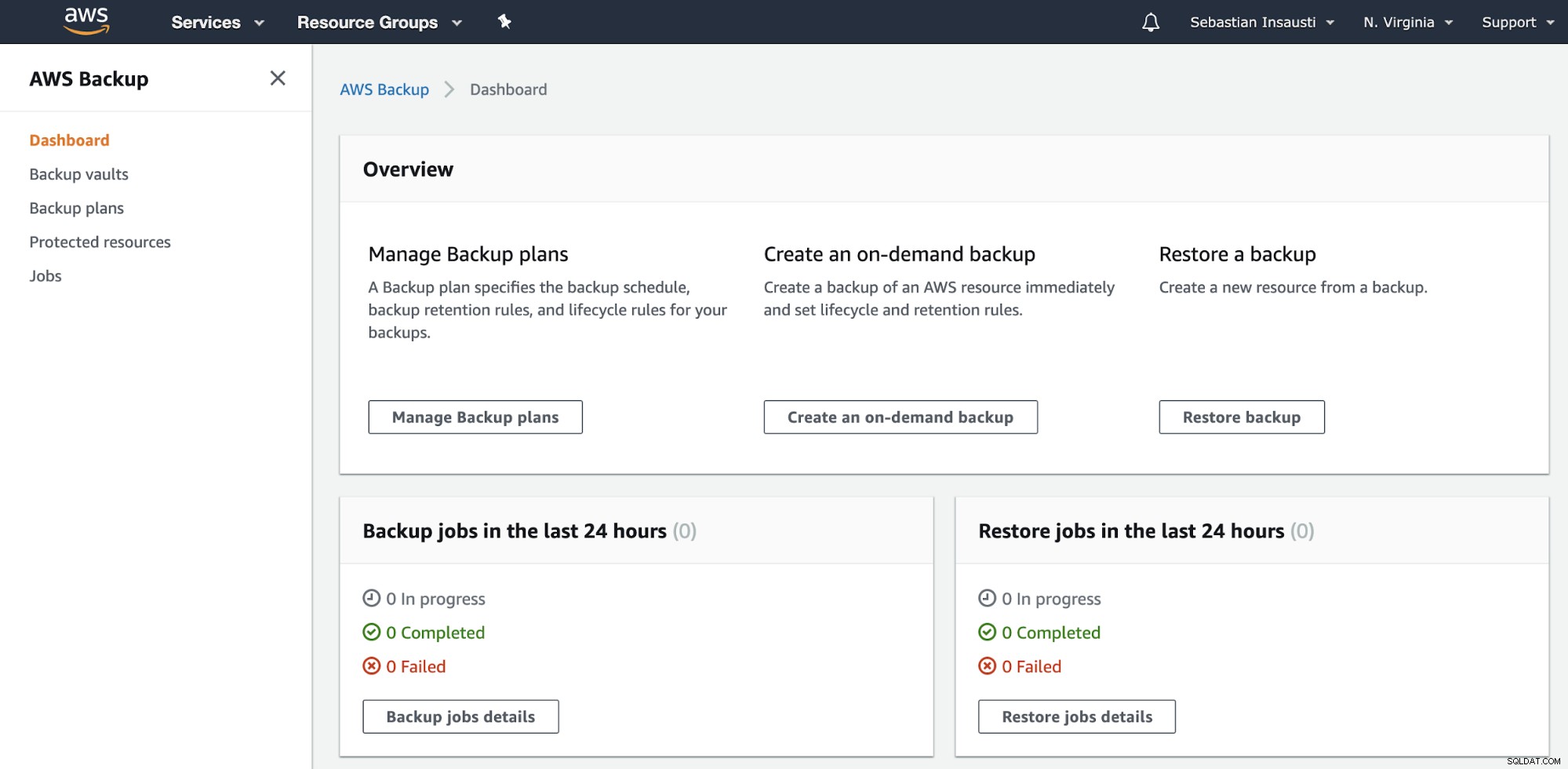
Tại đây bạn có các tùy chọn khác nhau, chẳng hạn như Lập lịch, Tạo hoặc Khôi phục bản sao lưu . Hãy xem cách tạo một bản sao lưu mới.
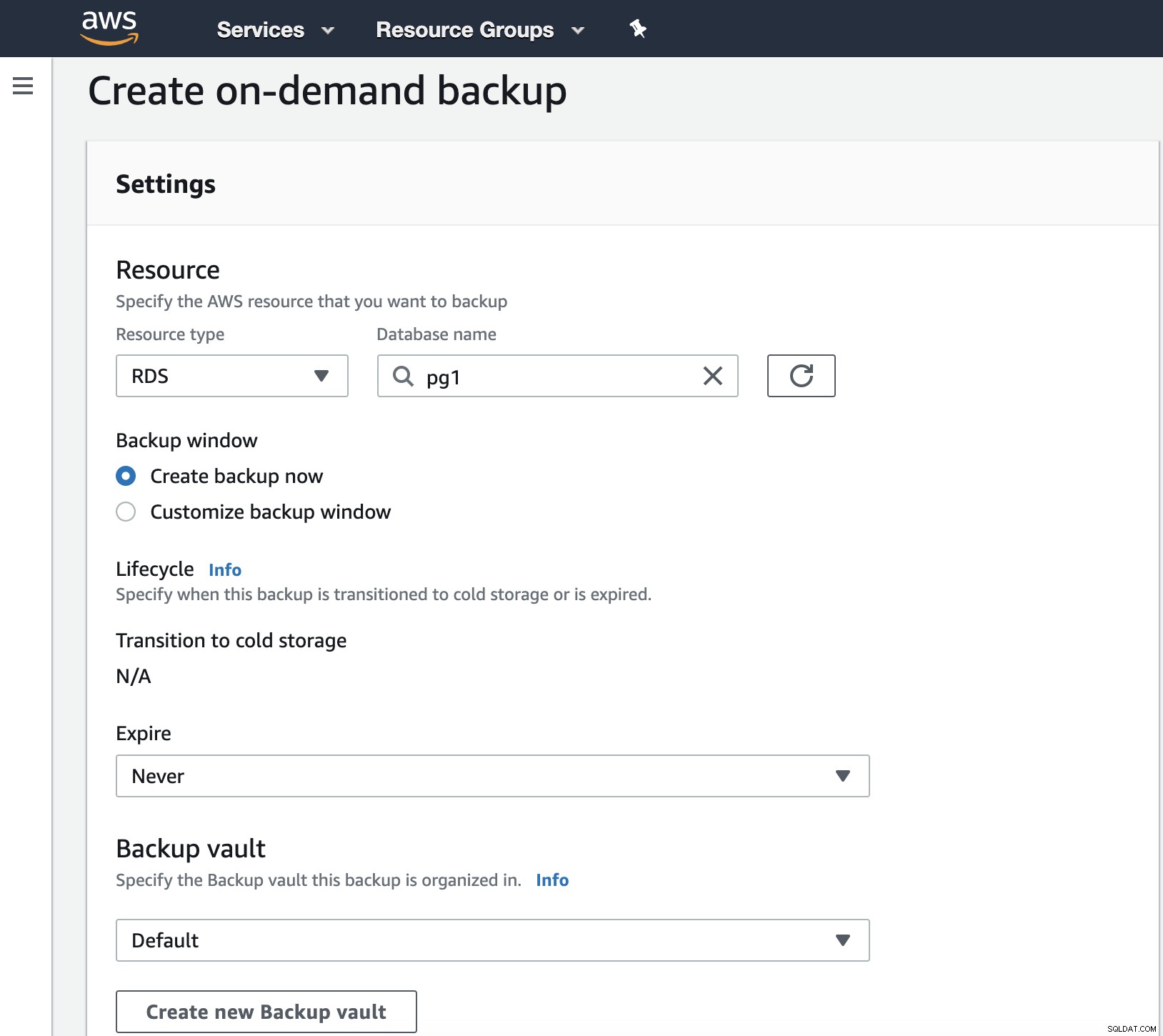
Trong bước này, chúng ta phải chọn Loại tài nguyên có thể là DynamoDB, RDS, EBS, EFS hoặc Cổng lưu trữ và các chi tiết khác như ngày hết hạn, kho dự phòng và Vai trò IAM.
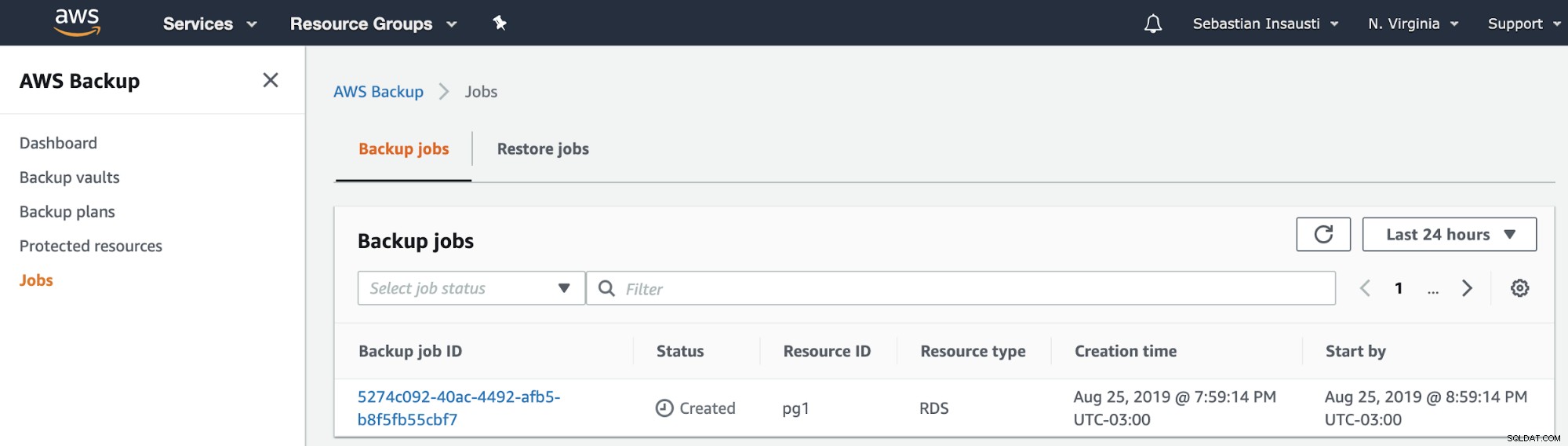
Sau đó, chúng ta có thể thấy công việc mới được tạo trong phần Công việc sao lưu AWS .
Ảnh chụp nhanh
Bây giờ, chúng ta có thể đề cập đến tùy chọn đã biết này trong tất cả các môi trường ảo hóa. Ảnh chụp nhanh là một bản sao lưu được chụp tại một thời điểm cụ thể và AWS cho phép chúng tôi sử dụng nó cho các sản phẩm AWS. Hãy xem một ví dụ về ảnh chụp nhanh RDS.
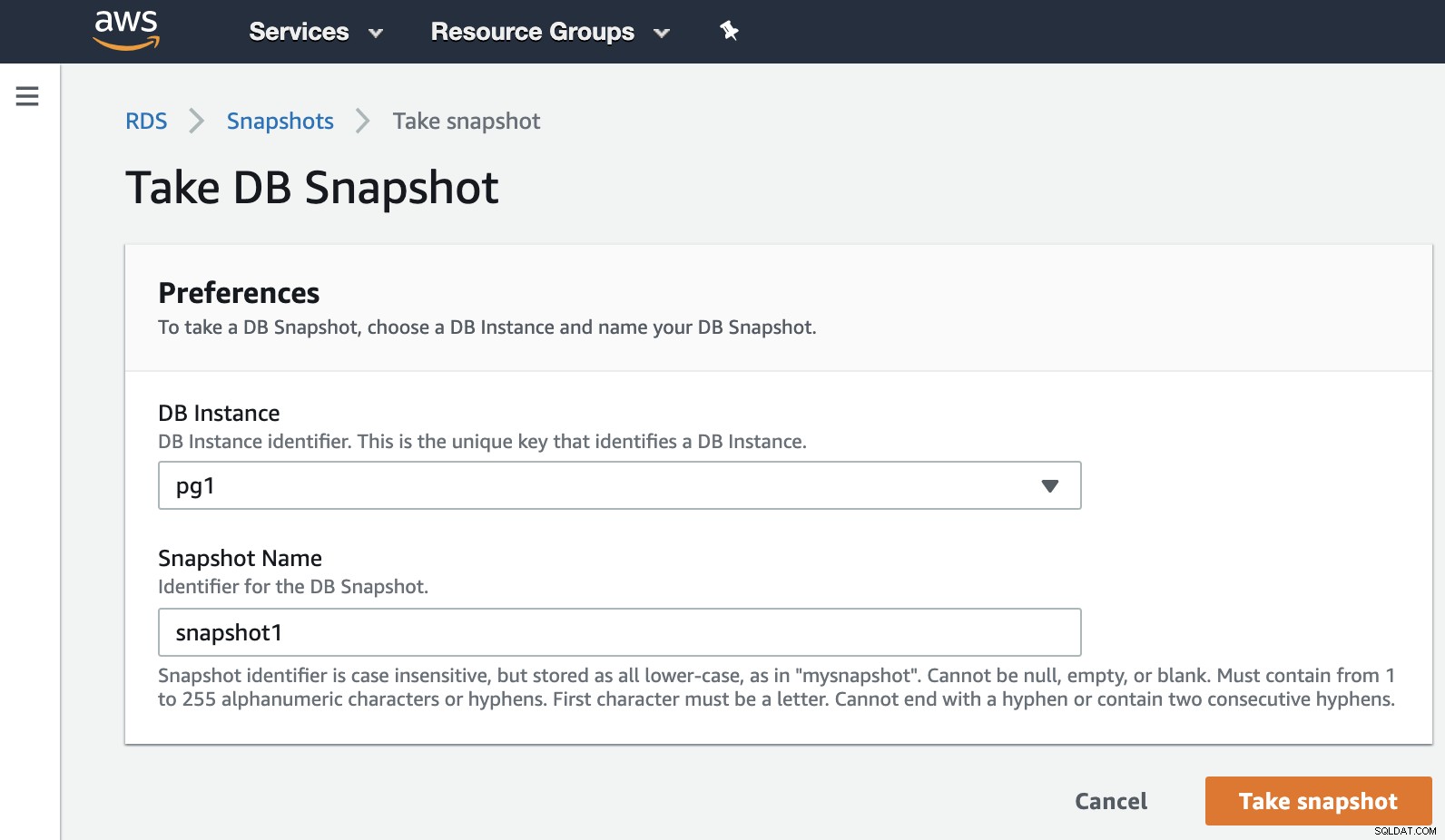
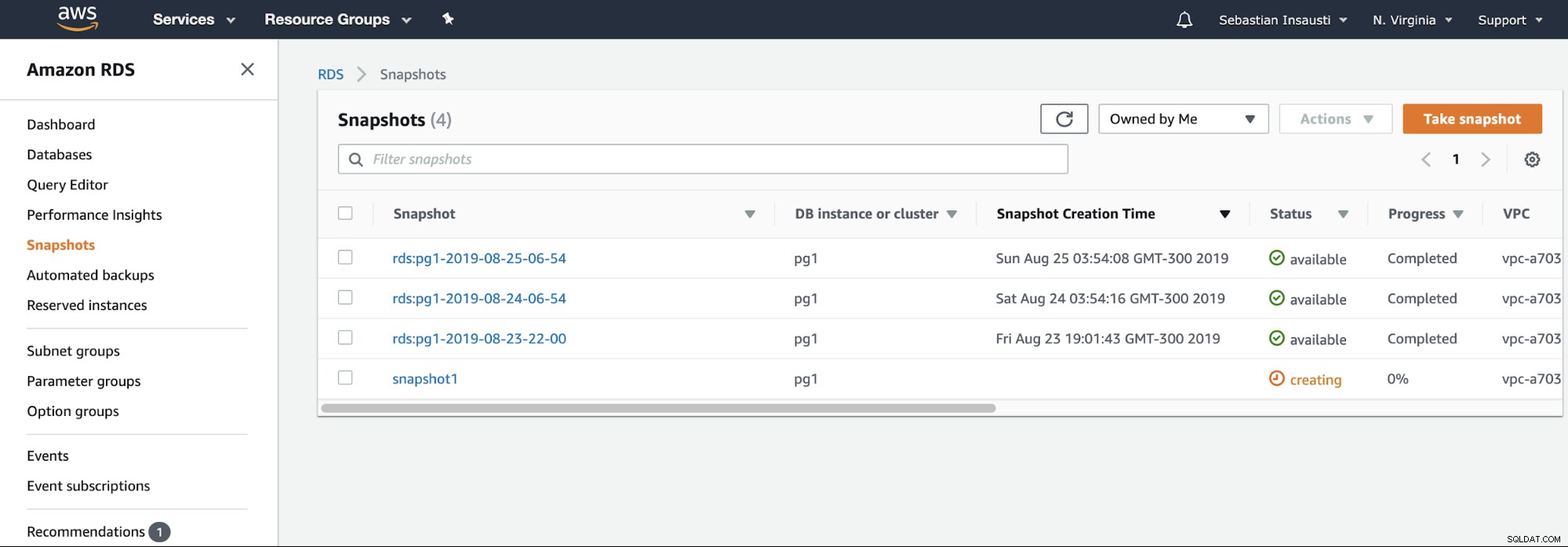
Chúng ta chỉ cần chọn đối tượng và thêm tên ảnh chụp nhanh, thế là nó. Chúng ta có thể xem ảnh này và ảnh chụp nhanh trước đó trong phần Ảnh chụp nhanh RDS.
Quản lý Bản sao lưu của bạn với ClusterControl
ClusterControl là một hệ thống quản lý toàn diện cho cơ sở dữ liệu nguồn mở tự động hóa các chức năng triển khai và quản lý, cũng như theo dõi sức khỏe và hiệu suất. ClusterControl hỗ trợ triển khai, quản lý, giám sát và mở rộng quy mô cho các công nghệ và môi trường cơ sở dữ liệu khác nhau, bao gồm EC2. Vì vậy, chẳng hạn, chúng tôi có thể tạo phiên bản EC2 của mình trên AWS và triển khai / nhập dịch vụ cơ sở dữ liệu của chúng tôi với ClusterControl.

Tạo bản sao lưu
Đối với tác vụ này, hãy chuyển đến ClusterControl -> Chọn Cluster -> Backup -> Create Backup.
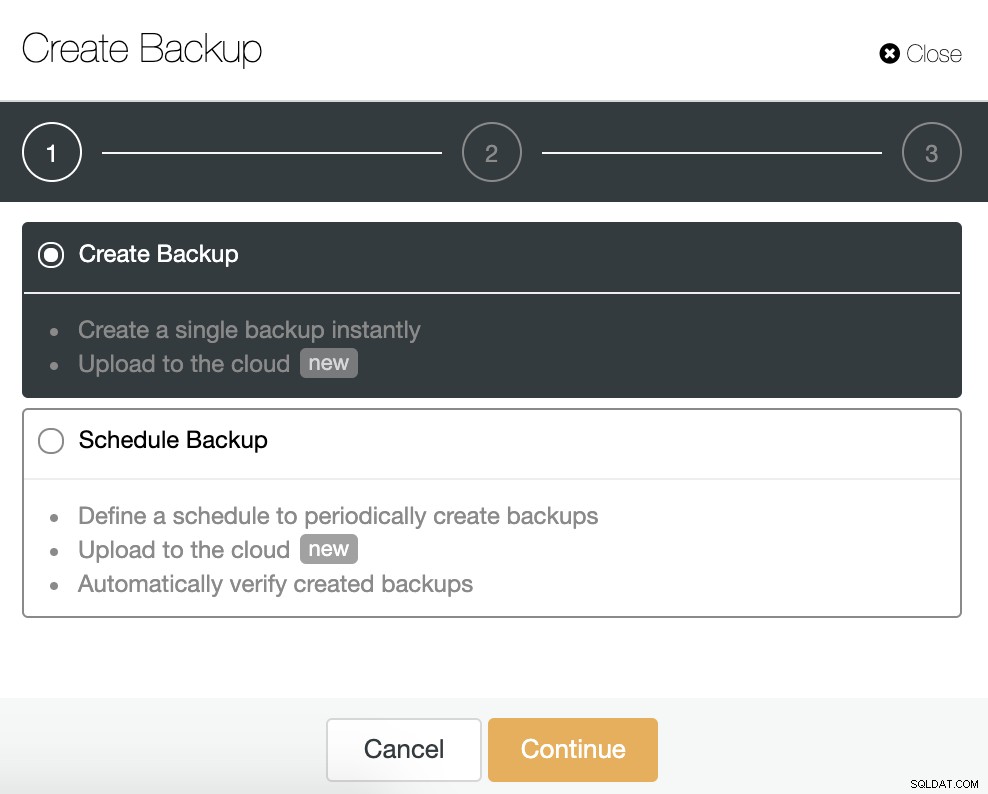
Chúng ta có thể tạo một bản sao lưu mới hoặc định cấu hình một bản sao lưu đã lên lịch. Đối với ví dụ của chúng tôi, chúng tôi sẽ tạo một bản sao lưu duy nhất ngay lập tức.
Chúng ta phải chọn một phương pháp, máy chủ mà từ đó bản sao lưu sẽ được thực hiện và nơi chúng tôi muốn lưu trữ bản sao lưu. Chúng tôi cũng có thể tải bản sao lưu của mình lên đám mây (AWS, Google hoặc Azure) bằng cách bật nút tương ứng.
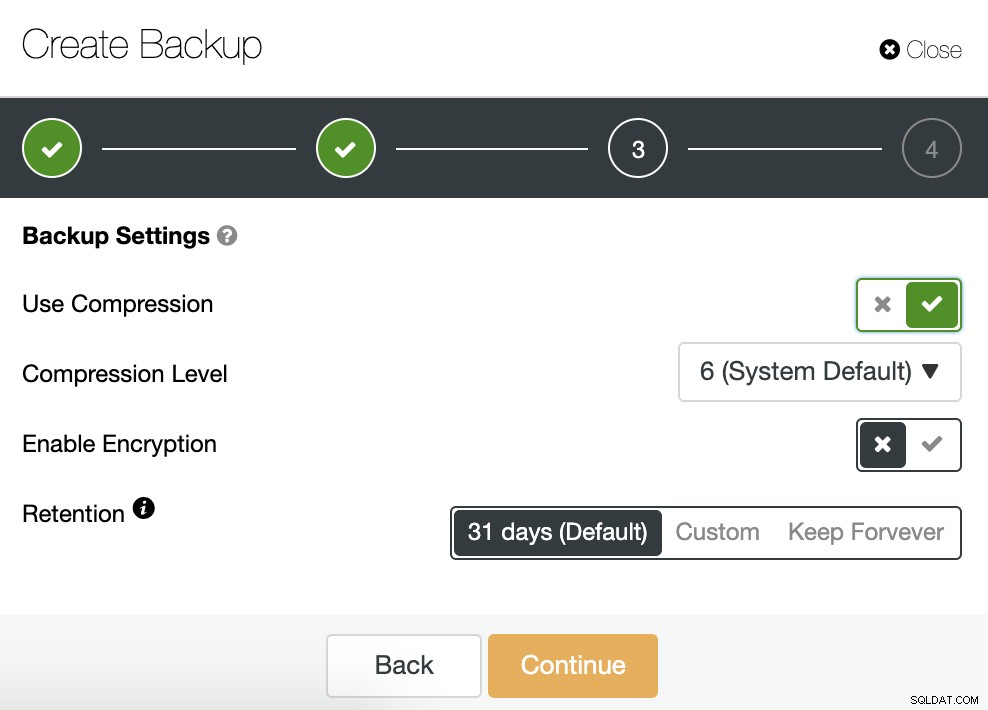
Sau đó, chúng tôi chỉ định việc sử dụng nén, mức độ nén, mã hóa và lưu giữ khoảng thời gian cho bản sao lưu của chúng tôi.
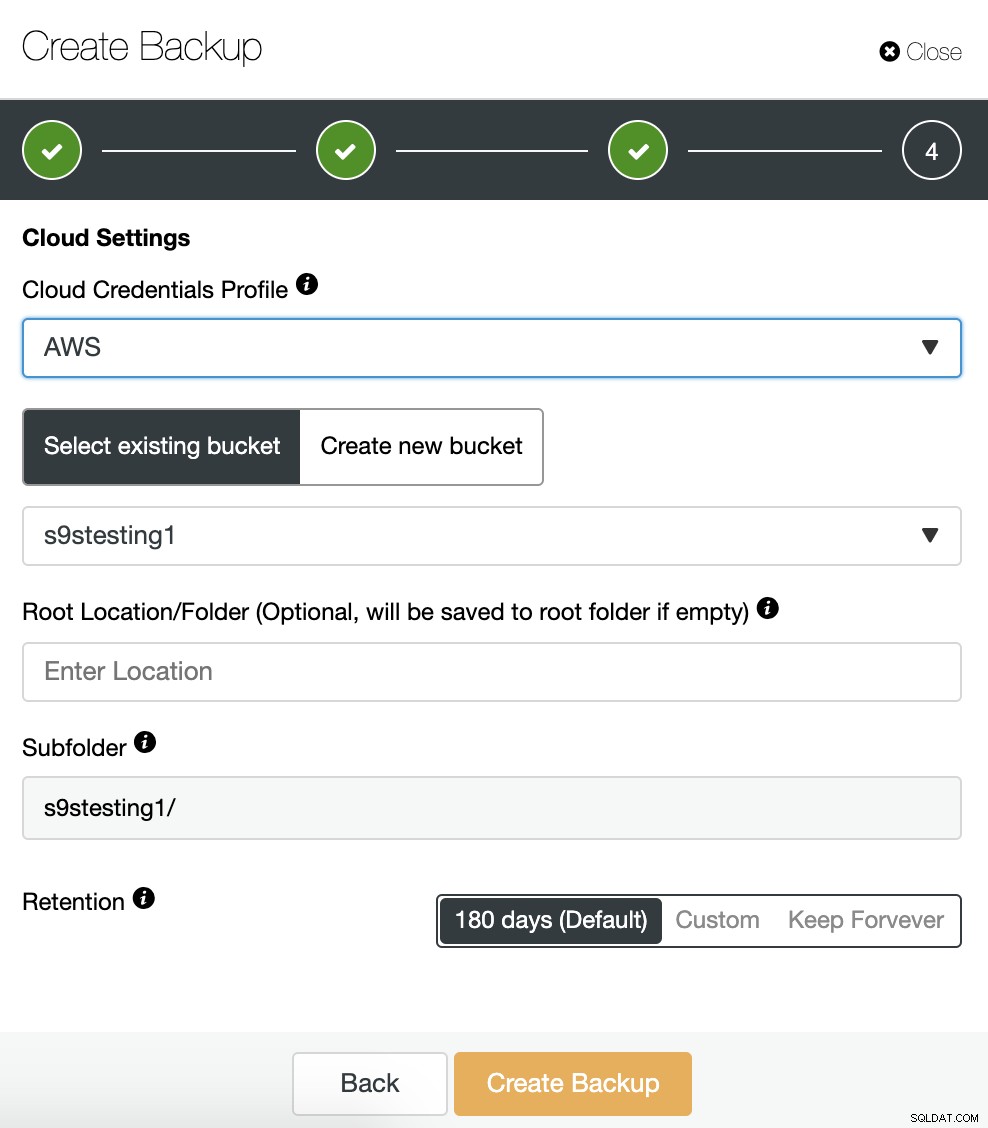
Nếu chúng tôi đã bật tính năng sao lưu tải lên tùy chọn đám mây, chúng tôi sẽ thấy một phần để chỉ định nhà cung cấp đám mây (trong trường hợp này là AWS) và thông tin xác thực (ClusterControl -> Tích hợp -> Nhà cung cấp đám mây). Đối với AWS, nó sử dụng dịch vụ S3, vì vậy chúng tôi phải chọn một Nhóm hoặc thậm chí tạo một nhóm mới để lưu trữ các bản sao lưu của chúng tôi.
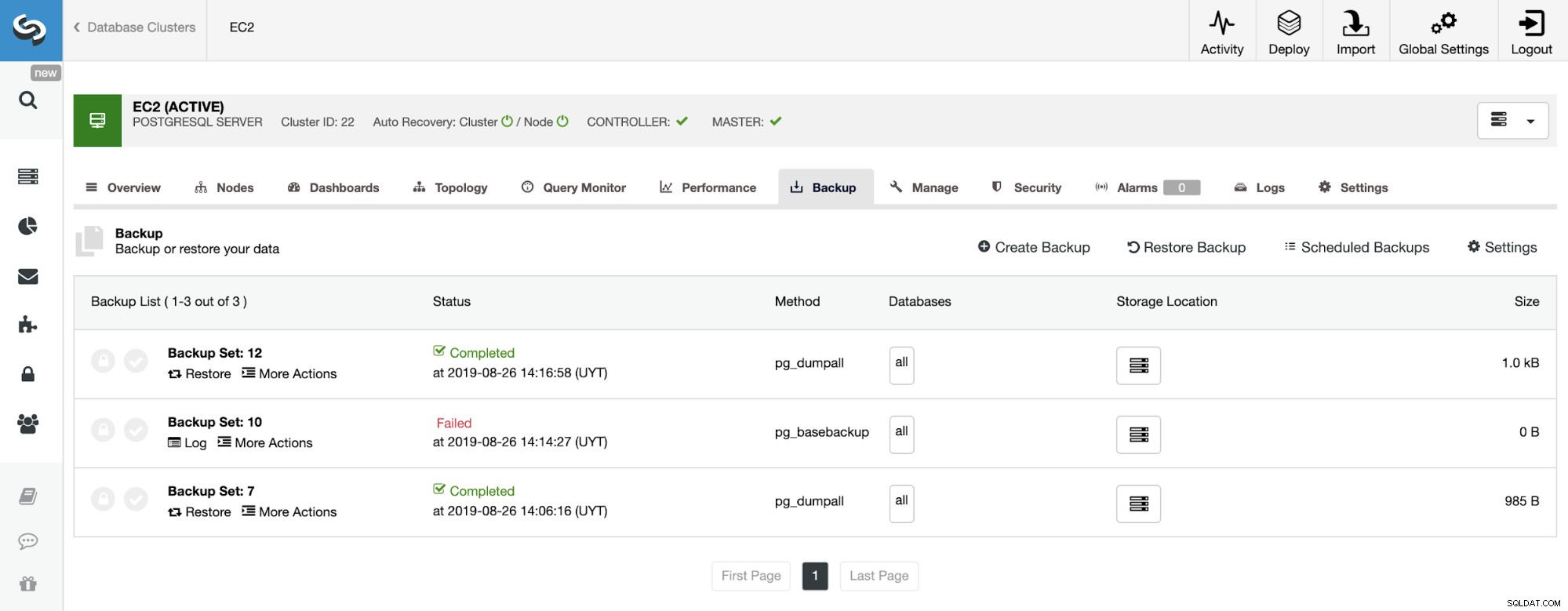
Trên phần sao lưu, chúng ta có thể thấy tiến trình sao lưu và thông tin như phương pháp, kích thước, vị trí, v.v.
Kết luận
Amazon AWS cho phép chúng tôi lưu trữ các bản sao lưu PostgreSQL của mình, cho dù chúng tôi có đang sử dụng nó như một nhà cung cấp đám mây cơ sở dữ liệu hay không. Để có một kế hoạch sao lưu hiệu quả, bạn nên cân nhắc lưu trữ ít nhất một bản sao lưu cơ sở dữ liệu trên đám mây để tránh mất dữ liệu trong trường hợp hỏng phần cứng ở một kho sao lưu khác. Đám mây cho phép bạn lưu trữ bao nhiêu bản sao lưu tùy thích.