Trong bất kỳ công cụ cơ sở dữ liệu quan hệ nào, cần phải tạo ra một kế hoạch tốt nhất có thể tương ứng với việc thực hiện truy vấn với ít thời gian và tài nguyên nhất. Nói chung, tất cả các cơ sở dữ liệu tạo ra các kế hoạch ở định dạng cấu trúc cây, trong đó nút lá của mỗi cây kế hoạch được gọi là nút quét bảng. Nút cụ thể này của kế hoạch tương ứng với thuật toán được sử dụng để tìm nạp dữ liệu từ bảng cơ sở.
Ví dụ:hãy xem xét một ví dụ truy vấn đơn giản là SELECT * FROM TBL1, TBL2 trong đó TBL2.ID> 1000; và giả sử kế hoạch được tạo như sau:
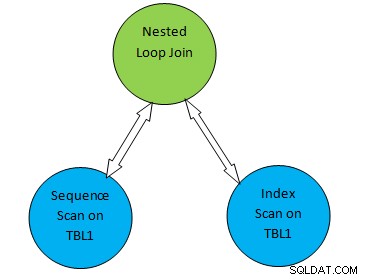
Vì vậy, trong cây kế hoạch ở trên, “Quét tuần tự trên TBL1” và “ Quét chỉ mục trên TBL2 ”tương ứng với phương pháp quét bảng trên bảng TBL1 và TBL2 tương ứng. Vì vậy, theo kế hoạch này, TBL1 sẽ được tìm nạp tuần tự từ các trang tương ứng và TBL2 có thể được truy cập bằng cách sử dụng Quét INDEX.
Chọn phương pháp quét phù hợp như một phần của kế hoạch là rất quan trọng về hiệu suất truy vấn tổng thể.
Trước khi tìm hiểu tất cả các loại phương pháp quét được hỗ trợ bởi PostgreSQL, chúng ta hãy sửa đổi một số điểm chính chính sẽ được sử dụng thường xuyên khi chúng ta xem qua blog.
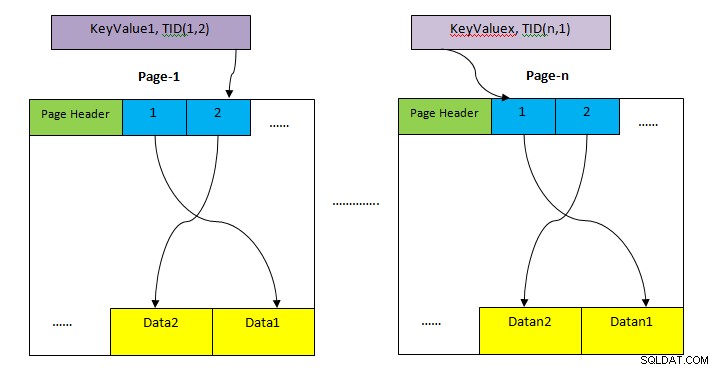
- HEAP: Khu lưu trữ để lưu trữ cả dãy bàn. Điều này được chia thành nhiều trang (như trong hình trên) và kích thước mỗi trang theo mặc định là 8KB. Trong mỗi trang, mỗi con trỏ mục (ví dụ:1, 2,….) Trỏ đến dữ liệu trong trang.
- Bộ nhớ Chỉ mục: Bộ nhớ này chỉ lưu trữ các giá trị chính, tức là giá trị cột được chứa trong chỉ mục. Điều này cũng được chia thành nhiều trang và kích thước mỗi trang theo mặc định là 8KB.
- Số nhận dạng Tuple (TID): TID là số 6 byte bao gồm hai phần. Phần đầu tiên là số trang 4 byte và chỉ mục bộ tuple 2 byte còn lại bên trong trang. Sự kết hợp của hai số này chỉ duy nhất một vị trí lưu trữ cho một bộ giá trị cụ thể.
Hiện tại, PostgreSQL hỗ trợ các phương pháp quét bên dưới mà theo đó, tất cả dữ liệu bắt buộc có thể được đọc từ bảng:
- Quét tuần tự
- Quét chỉ mục
- Chỉ quét chỉ mục
- Quét bitmap
- Quét TID
Mỗi phương pháp quét này đều hữu ích như nhau tùy thuộc vào truy vấn và các tham số khác, ví dụ:số lượng bảng, tính chọn lọc của bảng, chi phí I / O đĩa, chi phí I / O ngẫu nhiên, chi phí I / O trình tự, v.v. Hãy tạo một số bảng thiết lập trước và điền vào một số dữ liệu, sẽ được sử dụng thường xuyên để giải thích rõ hơn các phương pháp quét này .
postgres=# CREATE TABLE demotable (num numeric, id int);
CREATE TABLE
postgres=# CREATE INDEX demoidx ON demotable(num);
CREATE INDEX
postgres=# INSERT INTO demotable SELECT random() * 1000, generate_series(1, 1000000);
INSERT 0 1000000
postgres=# analyze;
ANALYZEVì vậy, trong ví dụ này, một triệu bản ghi được chèn vào và sau đó bảng được phân tích để tất cả thống kê đều được cập nhật.
Quét tuần tự
Như tên cho thấy, Quét tuần tự một bảng được thực hiện bằng cách quét tuần tự tất cả các con trỏ mục của tất cả các trang của các bảng tương ứng. Vì vậy, nếu có 100 trang cho một bảng cụ thể và sau đó có 1000 bản ghi trong mỗi trang, như một phần của quá trình quét tuần tự, nó sẽ tìm nạp 100 * 1000 bản ghi và kiểm tra xem nó có khớp theo mức cách ly và cả theo mệnh đề vị ngữ hay không. Vì vậy, ngay cả khi chỉ có 1 bản ghi được chọn như một phần của quá trình quét toàn bộ bảng, nó sẽ phải quét 100K bản ghi để tìm bản ghi đủ điều kiện theo điều kiện.
Theo bảng và dữ liệu ở trên, truy vấn sau sẽ dẫn đến quá trình quét tuần tự vì phần lớn dữ liệu đang được chọn.
postgres=# explain SELECT * FROM demotable WHERE num < 21000;
QUERY PLAN
--------------------------------------------------------------------
Seq Scan on demotable (cost=0.00..17989.00 rows=1000000 width=15)
Filter: (num < '21000'::numeric)
(2 rows)LƯU Ý
Mặc dù không tính toán và so sánh chi phí kế hoạch, hầu như không thể biết loại quét nào sẽ được sử dụng. Nhưng để quá trình quét tuần tự được sử dụng, ít nhất các tiêu chí dưới đây phải phù hợp:
- Không có chỉ mục nào trên khóa, là một phần của vị ngữ.
- Phần lớn các hàng đang được tìm nạp như một phần của truy vấn SQL.
MẸO
Trong trường hợp chỉ có rất ít% hàng được tìm nạp và vị từ nằm trên một (hoặc nhiều) cột, thì hãy thử đánh giá hiệu suất có hoặc không có chỉ mục.
Quét chỉ mục
Không giống như Quét tuần tự, quét chỉ mục không tìm nạp tất cả các bản ghi một cách tuần tự. Thay vào đó, nó sử dụng cấu trúc dữ liệu khác nhau (tùy thuộc vào loại chỉ mục) tương ứng với chỉ mục liên quan đến truy vấn và định vị mệnh đề dữ liệu được yêu cầu (theo vị từ) với số lần quét rất tối thiểu. Sau đó, mục nhập được tìm thấy bằng cách sử dụng quét chỉ mục trỏ trực tiếp đến dữ liệu trong vùng heap (như thể hiện trong hình trên), sau đó được tìm nạp để kiểm tra khả năng hiển thị theo mức cô lập. Vì vậy, có hai bước để quét chỉ mục:
- Tìm nạp dữ liệu từ cấu trúc dữ liệu liên quan đến chỉ mục. Nó trả về TID của dữ liệu tương ứng trong heap.
- Sau đó, trang heap tương ứng được truy cập trực tiếp để lấy toàn bộ dữ liệu. Bước bổ sung này là bắt buộc vì những lý do sau:
- Truy vấn có thể đã yêu cầu tìm nạp nhiều cột hơn bất cứ thứ gì có sẵn trong chỉ mục tương ứng.
- Thông tin hiển thị không được duy trì cùng với dữ liệu chỉ mục. Vì vậy, để kiểm tra mức độ hiển thị của dữ liệu theo mức cô lập, nó cần phải truy cập vào dữ liệu heap.
Bây giờ chúng ta có thể tự hỏi tại sao không luôn sử dụng Index Scan nếu nó quá hiệu quả. Vì vậy, như chúng ta biết mọi thứ đều đi kèm với một số chi phí. Ở đây chi phí liên quan có liên quan đến loại I / O mà chúng tôi đang thực hiện. Trong trường hợp Quét chỉ mục, I / O ngẫu nhiên có liên quan vì đối với mỗi bản ghi được tìm thấy trong lưu trữ chỉ mục, nó phải tìm nạp dữ liệu tương ứng từ bộ lưu trữ HEAP trong khi trong trường hợp Quét tuần tự, I / O theo trình tự có liên quan, chỉ chiếm khoảng 25%. thời gian vào / ra ngẫu nhiên.
Vì vậy, chỉ nên chọn quét chỉ mục nếu mức tăng tổng thể vượt trội so với chi phí phát sinh do chi phí I / O ngẫu nhiên.
Theo bảng và dữ liệu ở trên, truy vấn sau sẽ dẫn đến việc quét chỉ mục vì chỉ có một bản ghi được chọn. Vì vậy, I / O ngẫu nhiên ít hơn cũng như việc tìm kiếm bản ghi tương ứng cũng nhanh chóng.
postgres=# explain SELECT * FROM demotable WHERE num = 21000;
QUERY PLAN
--------------------------------------------------------------------------
Index Scan using demoidx on demotable (cost=0.42..8.44 rows=1 width=15)
Index Cond: (num = '21000'::numeric)
(2 rows)Chỉ Quét chỉ mục
Index Only Scan tương tự như Index Scan ngoại trừ bước thứ hai, tức là như tên của nó, nó chỉ quét cấu trúc dữ liệu chỉ mục. Có hai điều kiện trước bổ sung để chọn Chỉ quét chỉ mục so với Quét chỉ mục:
- Truy vấn chỉ nên tìm nạp các cột chính là một phần của chỉ mục.
- Tất cả các bộ giá trị (bản ghi) trên trang heap đã chọn sẽ hiển thị. Như đã thảo luận trong phần trước, cấu trúc dữ liệu chỉ mục không duy trì thông tin hiển thị, vì vậy, để chỉ chọn dữ liệu từ chỉ mục, chúng ta nên tránh kiểm tra khả năng hiển thị và điều này có thể xảy ra nếu tất cả dữ liệu của trang đó được coi là hiển thị.
Truy vấn sau sẽ dẫn đến việc quét chỉ chỉ mục. Mặc dù truy vấn này gần như tương tự về cách chọn số lượng bản ghi nhưng vì chỉ có trường khóa (tức là “num”) được chọn, nó sẽ chọn Chỉ quét chỉ mục.
postgres=# explain SELECT num FROM demotable WHERE num = 21000;
QUERY PLAN
-----------------------------------------------------------------------------
Index Only Scan using demoidx on demotable (cost=0.42..8.44 rows=1 Width=11)
Index Cond: (num = '21000'::numeric)
(2 rows)Quét Bitmap
Quét bitmap là sự kết hợp giữa Quét chỉ mục và Quét tuần tự. Nó cố gắng giải quyết nhược điểm của quét Index nhưng vẫn giữ được đầy đủ ưu điểm của nó. Như đã thảo luận ở trên đối với mỗi dữ liệu được tìm thấy trong cấu trúc dữ liệu chỉ mục, nó cần tìm dữ liệu tương ứng trong trang heap. Vì vậy, nó cần tìm nạp trang chỉ mục một lần và sau đó là trang heap, điều này gây ra rất nhiều I / O ngẫu nhiên. Vì vậy, phương pháp quét bitmap tận dụng lợi ích của việc quét chỉ mục mà không có I / O ngẫu nhiên. Điều này hoạt động ở hai cấp độ như sau:
- Quét chỉ mục bitmap:Đầu tiên nó tìm nạp tất cả dữ liệu chỉ mục từ cấu trúc dữ liệu chỉ mục và tạo một bản đồ bit của tất cả TID. Để hiểu đơn giản, bạn có thể coi bitmap này chứa một hàm băm của tất cả các trang (được băm dựa trên số trang) và mỗi mục nhập trang chứa một mảng tất cả các phần bù bên trong trang đó.
- Bitmap Heap Scan:Như tên của nó, nó đọc qua bitmap của các trang và sau đó quét dữ liệu từ heap tương ứng với trang được lưu trữ và bù đắp. Cuối cùng, nó sẽ kiểm tra khả năng hiển thị và vị từ, v.v. và trả về bộ giá trị dựa trên kết quả của tất cả các lần kiểm tra này.
Truy vấn dưới đây sẽ dẫn đến việc quét Bitmap vì nó không chọn rất ít bản ghi (tức là quá nhiều để quét chỉ mục) và đồng thời không chọn một số lượng lớn bản ghi (tức là quá ít cho một tuần tự quét).
postgres=# explain SELECT * FROM demotable WHERE num < 210;
QUERY PLAN
-----------------------------------------------------------------------------
Bitmap Heap Scan on demotable (cost=5883.50..14035.53 rows=213042 width=15)
Recheck Cond: (num < '210'::numeric)
-> Bitmap Index Scan on demoidx (cost=0.00..5830.24 rows=213042 width=0)
Index Cond: (num < '210'::numeric)
(4 rows)Bây giờ hãy xem xét truy vấn dưới đây, truy vấn chọn cùng một số bản ghi nhưng chỉ các trường khóa (tức là chỉ các cột chỉ mục). Vì nó chỉ chọn khóa, nó không cần phải tham khảo các trang heap cho các phần khác của dữ liệu và do đó không có I / O ngẫu nhiên liên quan. Vì vậy, truy vấn này sẽ chọn Chỉ quét chỉ mục thay vì Quét bitmap.
postgres=# explain SELECT num FROM demotable WHERE num < 210;
QUERY PLAN
---------------------------------------------------------------------------------------
Index Only Scan using demoidx on demotable (cost=0.42..7784.87 rows=208254 width=11)
Index Cond: (num < '210'::numeric)
(2 rows)Quét TID
TID, như đã đề cập ở trên, là số 6 byte bao gồm số trang 4 byte và chỉ số bộ 2 byte còn lại bên trong trang. Quét TID là một kiểu quét rất cụ thể trong PostgreSQL và chỉ được chọn nếu có TID trong vị từ truy vấn. Hãy xem xét truy vấn dưới đây thể hiện Quét TID:
postgres=# select ctid from demotable where id=21000;
ctid
----------
(115,42)
(1 row)
postgres=# explain select * from demotable where ctid='(115,42)';
QUERY PLAN
----------------------------------------------------------
Tid Scan on demotable (cost=0.00..4.01 rows=1 width=15)
TID Cond: (ctid = '(115,42)'::tid)
(2 rows)Vì vậy, ở đây trong vị từ, thay vì đưa ra giá trị chính xác của cột như điều kiện, TID được cung cấp. Đây là một cái gì đó tương tự như tìm kiếm dựa trên ROWID trong Oracle.
Tiền thưởng
Tất cả các phương pháp quét đều được sử dụng rộng rãi và nổi tiếng. Ngoài ra, các phương pháp quét này có sẵn trong hầu hết các cơ sở dữ liệu quan hệ. Nhưng có một phương pháp quét khác gần đây đang được thảo luận trong cộng đồng PostgreSQL và gần đây đã được thêm vào trong các cơ sở dữ liệu quan hệ khác. Nó được gọi là “Loose IndexScan” trong MySQL, “Index Skip Scan” trong Oracle và “Jump Scan” trong DB2.
Phương pháp quét này được sử dụng cho một tình huống cụ thể trong đó giá trị khác biệt của cột khóa hàng đầu của chỉ mục B-Tree được chọn. Là một phần của quá trình quét này, nó tránh duyệt qua tất cả giá trị cột khóa bằng nhau thay vì chỉ duyệt qua giá trị duy nhất đầu tiên và sau đó chuyển sang giá trị lớn tiếp theo.
Công việc này vẫn đang được tiến hành trong PostgreSQL với tên dự kiến là “Quét bỏ qua chỉ mục” và chúng tôi có thể mong đợi thấy điều này trong một bản phát hành trong tương lai.