Kiểu dữ liệu chuỗi là một trong những kiểu dữ liệu quan trọng nhất trong bất kỳ ngôn ngữ lập trình nào. Bạn khó có thể viết một chương trình hữu ích mà không có nó. Tuy nhiên, nhiều nhà phát triển không biết một số khía cạnh nhất định của loại hình này. Do đó, hãy xem xét những khía cạnh này.
Biểu diễn chuỗi trong bộ nhớ
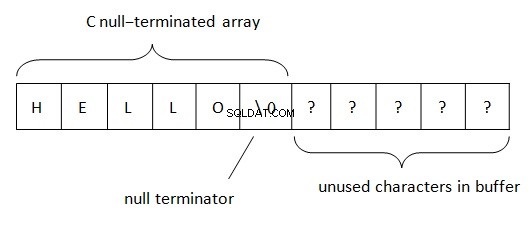
Trong .Net, các chuỗi được đặt theo quy tắc BSTR (Chuỗi cơ bản hoặc chuỗi nhị phân). Phương pháp biểu diễn dữ liệu chuỗi này được sử dụng trong COM (từ ‘basic’ bắt nguồn từ ngôn ngữ lập trình Visual Basic mà nó được sử dụng ban đầu). Như chúng ta đã biết, PWSZ (Pointer to Wide-character String, Zero-end-end) được sử dụng trong C / C ++ để biểu diễn chuỗi. Với vị trí như vậy trong bộ nhớ, một kết thúc bằng null nằm ở cuối một chuỗi. Dấu kết thúc này cho phép xác định kết thúc của chuỗi. Độ dài chuỗi trong PWSZ chỉ bị giới hạn bởi một lượng không gian trống.
Ở BSTR, tình hình hơi khác một chút.
Các khía cạnh cơ bản của biểu diễn chuỗi BSTR trong bộ nhớ như sau:
- Độ dài chuỗi bị giới hạn bởi một số nhất định. Trong PWSZ, độ dài chuỗi bị giới hạn bởi sự sẵn có của bộ nhớ trống.
- Chuỗi BSTR luôn trỏ vào ký tự đầu tiên trong bộ đệm. PWSZ có thể trỏ đến bất kỳ ký tự nào trong bộ đệm.
- Trong BSTR, tương tự như PWSZ, ký tự null luôn nằm ở cuối. Trong BSTR, ký tự null là một ký tự hợp lệ và có thể được tìm thấy ở bất kỳ đâu trong chuỗi.
- Vì dấu chấm dứt rỗng nằm ở cuối nên BSTR tương thích với PWSZ, nhưng không tương thích với ngược lại.
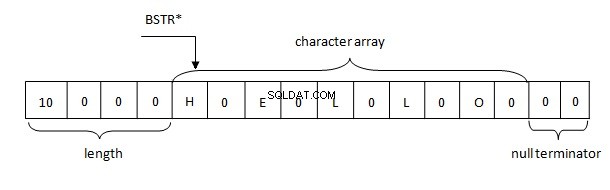
Do đó, các chuỗi trong .NET được biểu diễn trong bộ nhớ theo quy tắc BSTR. Bộ đệm chứa độ dài chuỗi 4 byte theo sau là các ký tự hai byte của chuỗi ở định dạng UTF-16, đến lượt nó, được theo sau bởi hai byte rỗng (\ u0000).
Sử dụng triển khai này có nhiều lợi ích:độ dài chuỗi không phải được tính toán lại vì nó được lưu trữ trong tiêu đề, một chuỗi có thể chứa các ký tự rỗng ở bất kỳ đâu. Và điều quan trọng nhất là địa chỉ của một chuỗi (được ghim) có thể dễ dàng được chuyển qua mã gốc nơi WCHAR * được mong đợi.
Một đối tượng chuỗi chiếm bao nhiêu bộ nhớ?
Tôi đã gặp các bài báo nói rằng kích thước đối tượng chuỗi bằng size =20 + (length / 2) * 4, nhưng công thức này không hoàn toàn chính xác.
Để bắt đầu, chuỗi là một loại liên kết, vì vậy bốn byte đầu tiên chứa SyncBlockIndex và bốn byte tiếp theo chứa con trỏ kiểu.
Kích thước chuỗi =4 + 4 +…
Như tôi đã nêu ở trên, độ dài chuỗi được lưu trữ trong bộ đệm. Đây là trường kiểu int, do đó chúng ta cần thêm 4 byte khác.
Kích thước chuỗi =4 + 4 + 4 +…
Để chuyển một chuỗi sang mã gốc một cách nhanh chóng (mà không cần sao chép), dấu chấm dứt rỗng được đặt ở cuối mỗi chuỗi có 2 byte. Do đó,
Kích thước chuỗi =4 + 4 + 4 + 2 +…
Điều duy nhất còn lại là nhớ lại rằng mỗi ký tự trong một chuỗi nằm trong mã hóa UTF-16 và cũng có 2 byte. Do đó:
Kích thước chuỗi =4 + 4 + 4 + 2 + 2 * chiều dài =14 + 2 * chiều dài
Một điều nữa và chúng tôi đã hoàn thành. Bộ nhớ được cấp phát bởi trình quản lý bộ nhớ trong CLR là bội số của 4 byte (4, 8, 12, 16, 20, 24,…). Vì vậy, nếu độ dài chuỗi có tổng cộng 34 byte, thì 36 byte sẽ được cấp phát. Chúng ta cần làm tròn giá trị của mình đến số lớn hơn gần nhất là bội số của bốn. Đối với điều này, chúng tôi cần:
Kích thước chuỗi =4 * ((14 + 2 * chiều dài + 3) / 4) (phép chia số nguyên)
Vấn đề về phiên bản :cho đến .NET v4, đã có thêm m_arrayLength trường kiểu int trong lớp String chiếm 4 byte. Trường này là độ dài thực của bộ đệm được cấp phát cho một chuỗi, bao gồm cả dấu chấm hết rỗng, tức là độ dài + 1. Trong .NET 4.0, trường này đã bị loại khỏi lớp. Do đó, một đối tượng kiểu chuỗi chiếm ít hơn 4 byte.
Kích thước của một chuỗi trống không có m_arrayLength trường (tức là trong .Net 4.0 trở lên) bằng =4 + 4 + 4 + 2 =14 byte và với trường này (tức là thấp hơn .Net 4.0), kích thước của trường bằng =4 + 4 + 4 + 4 + 2 =18 byte. Nếu chúng ta làm tròn 4 byte, kích thước tương ứng sẽ là 16 và 20 byte.
Các khía cạnh của chuỗi
Vì vậy, chúng tôi đã xem xét biểu diễn của các chuỗi và kích thước của chúng trong bộ nhớ. Bây giờ, hãy nói về những điểm đặc biệt của họ.
Các khía cạnh cơ bản của chuỗi trong .NET như sau:
- Chuỗi là loại tham chiếu.
- Các chuỗi là bất biến. Sau khi được tạo, một chuỗi không thể được sửa đổi (theo cách hợp lý). Mỗi lần gọi phương thức của lớp này trả về một chuỗi mới, trong khi chuỗi trước đó trở thành mồi cho trình thu gom rác.
- Các chuỗi xác định lại phương thức Object.Equals. Do đó, phương thức so sánh các giá trị ký tự trong chuỗi chứ không phải giá trị liên kết.
Hãy xem xét từng điểm một cách chi tiết.
Chuỗi là loại tham chiếu
Chuỗi là kiểu tham chiếu thực. Có nghĩa là, chúng luôn nằm trong đống. Nhiều người trong chúng ta nhầm lẫn chúng với các loại giá trị, vì bạn cư xử theo cùng một cách. Ví dụ:chúng là bất biến và việc so sánh của chúng được thực hiện theo giá trị, không phải bằng tham chiếu, nhưng chúng ta phải lưu ý rằng đó là một loại tham chiếu.
Chuỗi là bất biến
- Các chuỗi là bất biến cho một mục đích. Tính bất biến của chuỗi có một số lợi ích:
- Loại chuỗi an toàn cho chuỗi vì không một chuỗi nào có thể sửa đổi nội dung của chuỗi.
- Việc sử dụng các chuỗi bất biến dẫn đến giảm tải bộ nhớ, vì không cần lưu trữ 2 phiên bản của cùng một chuỗi. Do đó, bộ nhớ được sử dụng ít hơn và so sánh được thực hiện nhanh hơn, vì chỉ các tham chiếu được so sánh. Trong .NET, cơ chế này được gọi là xâu chuỗi (string pool). Chúng ta sẽ nói về vấn đề này một chút sau.
- Khi truyền một tham số không thay đổi cho một phương thức, chúng ta có thể không lo lắng rằng nó sẽ bị sửa đổi (tất nhiên là nếu nó không được truyền dưới dạng tham chiếu hoặc bị loại bỏ).
Cấu trúc dữ liệu có thể được chia thành hai loại:phù du và lâu dài. Cấu trúc dữ liệu phù du chỉ lưu trữ các phiên bản cuối cùng của chúng. Cấu trúc dữ liệu liên tục lưu tất cả các phiên bản trước của chúng trong quá trình sửa đổi. Trên thực tế, cái sau là bất biến, vì hoạt động của chúng không thay đổi cấu trúc trên trang web. Thay vào đó, chúng trả về một cấu trúc mới dựa trên cấu trúc trước đó.
Với thực tế là các chuỗi là bất biến, chúng có thể bền bỉ, nhưng thực tế không phải vậy. Các chuỗi là tạm thời trong .Net.
Để so sánh, hãy lấy các chuỗi Java. Chúng là bất biến, giống như trong .NET, nhưng ngoài ra chúng rất bền. Việc triển khai lớp String trong Java trông như sau:
public final class String
{
private final char value[];
private final int offset;
private final int count;
private int hash;
.....
}
Ngoài 8 byte trong tiêu đề của đối tượng, bao gồm tham chiếu đến loại và tham chiếu đến đối tượng đồng bộ hóa, các chuỗi chứa các trường sau:
- Tham chiếu đến một mảng char;
- Chỉ số của ký tự đầu tiên của chuỗi trong mảng char (phần bù từ đầu)
- Số lượng ký tự trong chuỗi;
- Mã băm được tính sau lần đầu tiên gọi HashCode () phương pháp.
Các chuỗi trong Java chiếm nhiều bộ nhớ hơn trong .NET, vì chúng chứa các trường bổ sung cho phép chúng ổn định. Do tính liên tục, việc thực thi String.substring () phương thức trong Java lấy O (1) , vì nó không yêu cầu sao chép chuỗi như trong .NET, nơi thực thi phương thức này mất O (n) .
Triển khai phương thức String.substring () trong Java:
public String substring(int beginIndex, int endIndex)
{
if (beginIndex < 0) throw new StringIndexOutOfBoundsException(beginIndex); if (endIndex > count)
throw new StringIndexOutOfBoundsException(endIndex);
if (beginIndex > endIndex)
throw new StringIndexOutOfBoundsException(endIndex - beginIndex);
return ((beginIndex == 0) && (endIndex == count)) ? this : new String(offset + beginIndex, endIndex - beginIndex, value);
}
public String(int offset, int count, char value[])
{
this.value = value;
this.offset = offset;
this.count = count;
} Tuy nhiên, nếu một chuỗi nguồn đủ lớn và chuỗi con bị cắt có độ dài vài ký tự, thì toàn bộ mảng ký tự của chuỗi ban đầu sẽ đang chờ xử lý trong bộ nhớ cho đến khi có tham chiếu đến chuỗi con. Hoặc, nếu bạn tuần tự hóa chuỗi con đã nhận bằng phương tiện tiêu chuẩn và chuyển nó qua mạng, toàn bộ mảng ban đầu sẽ được tuần tự hóa và số lượng byte được truyền qua mạng sẽ lớn. Do đó, thay vì mã
s =ss.substring (3)
mã sau có thể được sử dụng:
s =new String (ss.substring (3)),
Mã này sẽ không lưu trữ tham chiếu đến mảng ký tự của chuỗi nguồn. Thay vào đó, nó sẽ chỉ sao chép phần thực sự được sử dụng của mảng. Nhân tiện, nếu chúng ta gọi hàm tạo này trên một chuỗi có độ dài bằng độ dài của mảng ký tự, thì việc sao chép sẽ không diễn ra. Thay vào đó, tham chiếu đến mảng ban đầu sẽ được sử dụng.
Hóa ra, việc triển khai kiểu chuỗi đã được thay đổi trong phiên bản Java mới nhất. Bây giờ, không có trường offset và trường độ dài trong lớp. hash32 mới (với thuật toán băm khác nhau) đã được giới thiệu thay thế. Điều này có nghĩa là các chuỗi không liên tục nữa. Bây giờ, String.substring phương thức sẽ tạo một chuỗi mới mỗi lần.
Chuỗi xác định lại Onbject.Equals
Lớp string định nghĩa lại phương thức Object.Equals. Kết quả là, sự so sánh diễn ra, nhưng không phải theo tham chiếu, mà theo giá trị. Tôi cho rằng các nhà phát triển rất biết ơn những người tạo ra lớp String vì đã xác định lại toán tử ==, vì mã sử dụng ==để so sánh chuỗi trông sâu sắc hơn lệnh gọi phương thức.
if (s1 == s2)
So với
if (s1.Equals(s2))
Nhân tiện, trong Java, toán tử ==so sánh bằng tham chiếu. Nếu bạn cần so sánh các chuỗi theo ký tự, chúng ta cần sử dụng phương thức string.equals ().
Gián đoạn chuỗi
Cuối cùng, chúng ta hãy xem xét việc thực hiện chuỗi. Hãy xem một ví dụ đơn giản - mã đảo ngược một chuỗi.
var s = "Strings are immutuble";
int length = s.Length;
for (int i = 0; i < length / 2; i++)
{
var c = s[i];
s[i] = s[length - i - 1];
s[length - i - 1] = c;
} Rõ ràng, mã này không thể được biên dịch. Trình biên dịch sẽ ném lỗi cho các chuỗi này, vì chúng tôi cố gắng sửa đổi nội dung của chuỗi. Bất kỳ phương thức nào của lớp String đều trả về phiên bản mới của chuỗi, thay vì sửa đổi nội dung của nó.
Chuỗi có thể được sửa đổi, nhưng chúng tôi sẽ cần sử dụng mã không an toàn. Hãy xem xét ví dụ sau:
var s = "Strings are immutable";
int length = s.Length;
unsafe
{
fixed (char* c = s)
{
for (int i = 0; i < length / 2; i++)
{
var temp = c[i];
c[i] = c[length - i - 1];
c[length - i - 1] = temp;
}
}
} Sau khi thực thi mã này, elbatummi era sgnirtS sẽ được ghi vào chuỗi, như mong đợi. Khả năng thay đổi của các chuỗi dẫn đến một trường hợp lạ mắt liên quan đến việc đan xen chuỗi.
Tập chuỗi là một cơ chế trong đó các ký tự tương tự được biểu diễn trong bộ nhớ dưới dạng một đối tượng duy nhất.
Nói tóm lại, điểm của việc đan xen chuỗi là như sau:có một bảng nội bộ được băm duy nhất trong một quy trình (không phải trong miền ứng dụng), trong đó các chuỗi là khóa của nó và các giá trị là tham chiếu đến chúng. Trong quá trình biên dịch JIT, các chuỗi ký tự được đặt vào một bảng tuần tự (mỗi chuỗi trong bảng chỉ có thể được tìm thấy một lần). Trong quá trình thực thi, các tham chiếu đến chuỗi ký tự được gán từ bảng này. Trong quá trình thực thi, chúng ta có thể đặt một chuỗi vào bảng nội bộ với String.Intern phương pháp. Ngoài ra, chúng tôi có thể kiểm tra tính khả dụng của một chuỗi trong bảng nội bộ bằng cách sử dụng String.IsInterned phương pháp.
var s1 = "habrahabr"; var s2 = "habrahabr"; var s3 = "habra" + "habr"; Console.WriteLine(object.ReferenceEquals(s1, s2));//true Console.WriteLine(object.ReferenceEquals(s1, s3));//true
Lưu ý rằng chỉ các ký tự chuỗi được thực hiện theo mặc định. Vì bảng nội bộ được băm được sử dụng để thực hiện interning, việc tìm kiếm đối với bảng này được thực hiện trong quá trình biên dịch JIT. Quá trình này mất một thời gian. Vì vậy, nếu tất cả các chuỗi được thực hiện, nó sẽ giảm tối ưu hóa xuống 0. Trong quá trình biên dịch thành mã IL, trình biên dịch nối tất cả các chuỗi theo nghĩa đen, vì không cần lưu trữ chúng thành từng phần. Do đó, đẳng thức thứ hai trả về true .
Bây giờ, hãy quay lại trường hợp của chúng ta. Hãy xem xét đoạn mã sau:
var s = "Strings are immutable";
int length = s.Length;
unsafe
{
fixed (char* c = s)
{
for (int i = 0; i < length / 2; i++)
{
var temp = c[i];
c[i] = c[length - i - 1];
c[length - i - 1] = temp;
}
}
}
Console.WriteLine("Strings are immutable"); Có vẻ như mọi thứ đều khá rõ ràng và mã sẽ trả về Chuỗi là bất biến . Tuy nhiên, nó không! Mã trả về elbatummi era sgnirtS . Nó xảy ra chính xác vì thực tập. Khi chúng tôi sửa đổi chuỗi, chúng tôi sửa đổi nội dung của nó và vì nó có nghĩa đen, nó được lồng ghép và thể hiện bằng một phiên bản duy nhất của chuỗi.
Chúng tôi có thể từ bỏ việc thực hiện chuỗi nếu chúng tôi áp dụng CompilationRelaxationsAttribute thuộc tính cho hợp ngữ. Thuộc tính này kiểm soát độ chính xác của mã được tạo bởi trình biên dịch JIT của môi trường CLR. Hàm tạo của thuộc tính này chấp nhận CompilationRelaxations liệt kê, hiện chỉ bao gồm CompilationRelaxations.NoStringInterning . Do đó, tổ hợp được đánh dấu là tổ hợp không yêu cầu thực tập.
Nhân tiện, thuộc tính này không được xử lý trong .NET Framework v1.0. Đó là lý do tại sao, không thể vô hiệu hóa chế độ thực tập. Kể từ phiên bản 2, mscorlib lắp ráp được đánh dấu bằng thuộc tính này. Vì vậy, hóa ra các chuỗi trong .NET có thể được sửa đổi bằng mã không an toàn.
Điều gì sẽ xảy ra nếu chúng ta quên mất an toàn?
Khi nó xảy ra, chúng tôi có thể sửa đổi nội dung chuỗi mà không có mã không an toàn. Thay vào đó, chúng ta có thể sử dụng cơ chế phản chiếu. Thủ thuật này đã thành công trong .NET cho đến phiên bản 2.0. Sau đó, các nhà phát triển của lớp String đã tước đi cơ hội này của chúng tôi. Trong .NET 2.0, lớp String có hai phương thức bên trong: SetChar để kiểm tra giới hạn và InternalSetCharNoBoundsCheck điều đó không thực hiện kiểm tra giới hạn. Các phương thức này thiết lập ký tự được chỉ định bởi một chỉ mục nhất định. Việc triển khai các phương pháp trông theo cách sau:
internal unsafe void SetChar(int index, char value)
{
if ((uint)index >= (uint)this.Length)
throw new ArgumentOutOfRangeException("index", Environment.GetResourceString("ArgumentOutOfRange_Index"));
fixed (char* chPtr = &this.m_firstChar)
chPtr[index] = value;
}
internal unsafe void InternalSetCharNoBoundsCheck (int index, char value)
{
fixed (char* chPtr = &this.m_firstChar)
chPtr[index] = value;
} Do đó, chúng tôi có thể sửa đổi nội dung chuỗi mà không có mã không an toàn với sự trợ giúp của mã sau:
var s = "Strings are immutable";
int length = s.Length;
var method = typeof(string).GetMethod("InternalSetCharNoBoundsCheck", BindingFlags.Instance | BindingFlags.NonPublic);
for (int i = 0; i < length / 2; i++)
{
var temp = s[i];
method.Invoke(s, new object[] { i, s[length - i - 1] });
method.Invoke(s, new object[] { length - i - 1, temp });
}
Console.WriteLine("Strings are immutable");
Như mong đợi, mã trả về elbatummi era sgnirtS .
Vấn đề về phiên bản :trong các phiên bản .NET Framework khác nhau, string.Empty có thể được tích hợp hoặc không. Hãy xem xét đoạn mã sau:
string str1 = String.Empty;
StringBuilder sb = new StringBuilder().Append(String.Empty);
string str2 = String.Intern(sb.ToString());
if (object.ReferenceEquals(str1, str2))
Console.WriteLine("Equal");
else
Console.WriteLine("Not Equal"); Trong .NET Framework 1.0, .NET Framework 1.1 và .NET Framework 3.5 với gói dịch vụ 1 (SP1), str1 và str2 không bằng nhau. Hiện tại, string.Empty không được thực tập.
Các khía cạnh của Hiệu suất
Có một tác dụng phụ tiêu cực của việc tập luyện. Vấn đề là tham chiếu đến một đối tượng String interned được lưu trữ bởi CLR có thể được lưu ngay cả sau khi kết thúc công việc của ứng dụng và thậm chí sau khi kết thúc công việc của miền ứng dụng. Do đó, tốt hơn hết bạn nên bỏ qua việc sử dụng các chuỗi ký tự lớn. Nếu vẫn được yêu cầu, quá trình thực tập phải được vô hiệu hóa bằng cách áp dụng CompilationRelaxations thuộc tính cho assembly.