Phân tích cú pháp dữ liệu từ XML bằng cách sử dụng XQuery là một thực hành thường xuyên. Để làm điều này một cách hiệu quả nhất, cần phải có ít nỗ lực.
Giả sử chúng ta cần phân tích cú pháp dữ liệu từ tệp đĩa với cấu trúc sau:
<tables> <table name="Accounting" schema="Production" object="Accounting"> <column name="Date" order="3" visible="1" /> <column name="DateFrom" order="5" visible="1" /> <column name="DateTo" order="6" visible="1" /> <column name="Description" order="4" visible="1" /> <column name="DocumentUID" order="1" visible="0" /> <column name="Number" order="2" visible="1" /> <column name="Warehouse" order="7" visible="1" /> </table> </tables>
Sử dụng BULK INSERT, nếu bạn cần đọc dữ liệu từ một tệp:
SELECT BulkColumn FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x sample xml file
Tệp xml mẫu có ở đây.
Tuy nhiên, hãy nhớ một điều cụ thể… Cố gắng không đọc dữ liệu trực tiếp:
;WITH cte AS
(
SELECT x = CAST(BulkColumn AS XML)
FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x
)
SELECT t.c.value('@name', 'VARCHAR(100)')
FROM cte
CROSS APPLY x.nodes('tables/table') t(c) Gán dữ liệu cho một biến. Bằng cách này, bạn có thể có được một kế hoạch thực thi hiệu quả hơn:
DECLARE @xml XML
SELECT @xml = BulkColumn
FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x
SELECT t.c.value('@name', 'VARCHAR(100)')
FROM @xml.nodes('tables/table') t(c) So sánh kết quả:
Table 'Worktable'. Scan count 0, logical reads 729, physical reads 0, read-ahead reads 0, lob logical reads 62655,... SQL Server Execution Times: CPU time = 1203 ms, elapsed time = 1214 ms. Table 'Worktable'. Scan count 0, logical reads 7, physical reads 0, read-ahead reads 0, lob logical reads 202,.... SQL Server Execution Times: CPU time = 16 ms, elapsed time = 4 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 3 ms.
Như bạn có thể thấy, tùy chọn thứ hai về cơ bản nhanh hơn đáng kể.
Một tính năng quan trọng khác của SQL Server khi làm việc với XQuery là việc đọc một phần tử mẹ có thể dẫn đến hiệu suất kém. Hãy xem xét ví dụ sau:
SET STATISTICS PROFILE OFF
DECLARE @xml XML
SELECT @xml = BulkColumn
FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x
SET STATISTICS PROFILE ON
SELECT
t.c.value('@name', 'SYSNAME')
, t.c.value('@order', 'INT')
, t.c.value('@visible', 'BIT')
, t.c.value('../@name', 'SYSNAME')
, t.c.value('../@schema', 'SYSNAME')
, t.c.value('../@object', 'SYSNAME')
FROM @xml.nodes('tables/table/*') t(c) Hãy xem số hàng thực tế nhận được từ toán tử. Giá trị lớn bất thường:
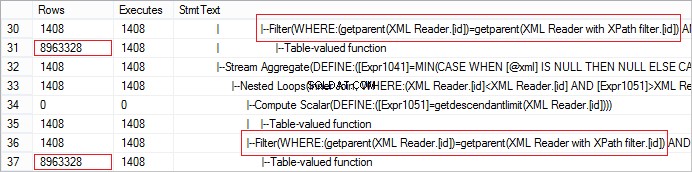
Có thể dễ dàng tối ưu hóa yêu cầu bằng ÁP DỤNG CHÉO:
SELECT
t2.c2.value('@name', 'SYSNAME')
, t2.c2.value('@order', 'INT')
, t2.c2.value('@visible', 'BIT')
, t.c.value('@name', 'SYSNAME')
, t.c.value('@schema', 'SYSNAME')
, t.c.value('@object', 'SYSNAME')
FROM @xml.nodes('tables/table') t(c)
CROSS APPLY t.c.nodes('column') t2(c2) Hãy so sánh thời gian thực hiện:
(1408 row(s) affected) SQL Server Execution Times: CPU time = 10125 ms, elapsed time = 10135 ms. (1408 row(s) affected) SQL Server Execution Times: CPU time = 78 ms, elapsed time = 156 ms.
Như bạn có thể thấy từ ví dụ, yêu cầu với ÁP DỤNG CHÉO sẽ hoạt động ngay lập tức.
Cảm ơn đã quan tâm. Tôi hy vọng bài viết này hữu ích. Vui lòng đặt bất kỳ câu hỏi nào, để lại nhận xét và đề xuất của bạn liên quan đến bài viết này.



