Gần đây, tôi đã tham gia vào việc phát triển chức năng yêu cầu chuyển khối lượng lớn dữ liệu sang đĩa nhanh chóng và thường xuyên. Ngoài ra, dữ liệu này được cho là sẽ được đọc từ đĩa theo thời gian. Vì vậy, tôi đã được định sẵn để tìm ra địa điểm, cách thức và phương tiện để lưu trữ dữ liệu này. Trong bài viết này, tôi sẽ đánh giá ngắn gọn nhiệm vụ cũng như điều tra và so sánh các giải pháp để hoàn thành nhiệm vụ này.
Bối cảnh của nhiệm vụ :Tôi làm việc trong một nhóm phát triển các công cụ để phát triển cơ sở dữ liệu tương đối (SQL Server, MySQL, Oracle). Phạm vi công cụ bao gồm cả hai, các công cụ độc lập và phần bổ trợ cho MS SSMS.
Công việc :Khôi phục các tài liệu đã được mở tại thời điểm IDE đóng vào lần bắt đầu IDE tiếp theo.
Usecase :Để đóng IDE nhanh chóng trước khi rời văn phòng mà không cần nghĩ đến tài liệu nào đã được lưu và tài liệu nào chưa. Vào lần bắt đầu tiếp theo của IDE, chúng ta cần có được môi trường giống như lúc đóng cửa và tiếp tục công việc. Tất cả các kết quả của công việc phải được lưu tại thời điểm đóng cửa một cách mất trật tự, ví dụ:trong sự cố chương trình hoặc hệ điều hành hoặc trong khi tắt nguồn.
Phân tích nhiệm vụ :Tính năng tương tự có trong các trình duyệt web. Tuy nhiên, các trình duyệt chỉ lưu trữ các URL bao gồm khoảng 100 ký hiệu. Trong trường hợp của chúng tôi, chúng tôi cần lưu trữ toàn bộ nội dung tài liệu. Do đó, chúng tôi cần một nơi để lưu và lưu trữ tài liệu của người dùng. Hơn nữa, đôi khi người dùng làm việc với SQL theo một cách khác với các ngôn ngữ khác. Ví dụ, nếu tôi viết một lớp C # dài hơn 1000 hàng, nó sẽ khó được chấp nhận. Trong khi, trong vũ trụ SQL, cùng với các truy vấn 10-20 hàng, tồn tại các kết xuất cơ sở dữ liệu khổng lồ. Những kết xuất như vậy khó có thể chỉnh sửa được, có nghĩa là người dùng muốn giữ an toàn cho các chỉnh sửa của họ.
Yêu cầu đối với bộ nhớ:
- Nó phải là một giải pháp nhúng nhẹ.
- Phải có tốc độ ghi cao.
- Nó phải có một tùy chọn về quyền truy cập đa xử lý. Yêu cầu này không quá quan trọng, vì chúng tôi có thể đảm bảo quyền truy cập với sự trợ giúp của các đối tượng đồng bộ hóa, tuy nhiên, sẽ rất tuyệt nếu có tùy chọn này.
Ứng viên
Ứng cử viên đầu tiên khá vụng về, đó là lưu trữ mọi thứ trong một thư mục, ở đâu đó trong AppData.
Ứng cử viên thứ hai là hiển nhiên - SQLite, một tiêu chuẩn của cơ sở dữ liệu nhúng. Ứng cử viên rất vững chắc và phổ biến.
Ứng cử viên thứ ba là cơ sở dữ liệu LiteDB. Đây là kết quả đầu tiên cho truy vấn "cơ sở dữ liệu được nhúng cho .net" trong Google.
Cái nhìn đầu tiên
Hệ thống tập tin. Tệp là tệp, chúng yêu cầu bảo trì và đặt tên thích hợp. Bên cạnh nội dung tệp, chúng ta sẽ cần lưu trữ một tập hợp nhỏ các thuộc tính (đường dẫn gốc trên đĩa, chuỗi kết nối, phiên bản IDE mà nó đã được mở). Điều đó có nghĩa là chúng ta sẽ phải tạo hai tệp cho một tài liệu hoặc phát minh ra một định dạng phân tách các thuộc tính khỏi nội dung.
SQLite là một cơ sở dữ liệu quan hệ cổ điển. Cơ sở dữ liệu được thể hiện bằng một tệp trên đĩa. Tệp này đang được liên kết với lược đồ cơ sở dữ liệu, sau đó chúng ta phải tương tác với nó với sự trợ giúp của phương tiện SQL. Chúng tôi sẽ có thể tạo 2 bảng, một cho thuộc tính và một cho nội dung, - trong trường hợp chúng tôi cần sử dụng các thuộc tính hoặc nội dung riêng biệt.
LiteDB là một cơ sở dữ liệu không quan hệ. Tương tự như SQLite, cơ sở dữ liệu được biểu diễn bằng một tệp duy nhất. Nó hoàn toàn được viết bằng С #. Nó có cách sử dụng đơn giản hấp dẫn:chúng tôi chỉ cần cung cấp một đối tượng cho thư viện, trong khi tuần tự hóa sẽ được thực hiện bằng chính phương tiện của nó.
Kiểm tra hiệu suất
Trước khi cung cấp mã, tôi muốn giải thích khái niệm chung và cung cấp kết quả so sánh.
Quan niệm chung là so sánh tốc độ ghi số lượng lớn tệp nhỏ vào cơ sở dữ liệu, số lượng tệp trung bình trung bình và số lượng nhỏ tệp lớn. Trường hợp với các tệp trung bình hầu hết gần giống với trường hợp thực, trong khi các trường hợp có tệp nhỏ và lớn là các trường hợp ranh giới, điều này cũng phải được tính đến.
Tôi đang ghi nội dung vào một tệp với sự trợ giúp của FileStream với kích thước bộ đệm tiêu chuẩn.
Có một sắc thái trong SQLite mà tôi muốn đề cập. Chúng tôi không thể đặt tất cả nội dung tài liệu (như tôi đã đề cập ở trên, chúng có thể rất lớn) vào một ô cơ sở dữ liệu. Vấn đề là vì mục đích tối ưu hóa, chúng tôi lưu trữ văn bản tài liệu từng dòng một. Điều này có nghĩa là để đưa văn bản vào một ô duy nhất, chúng ta cần đặt tất cả tài liệu vào một hàng duy nhất, điều này sẽ tăng gấp đôi số lượng bộ nhớ hoạt động được sử dụng. Mặt khác của vấn đề sẽ tự tiết lộ trong quá trình đọc dữ liệu từ cơ sở dữ liệu. Đó là lý do tại sao, có một bảng riêng biệt trong SQLite, nơi dữ liệu được lưu trữ theo từng hàng và dữ liệu được liên kết với sự trợ giúp của khóa ngoại với bảng chỉ chứa các thuộc tính tệp. Bên cạnh đó, tôi đã quản lý để tăng tốc cơ sở dữ liệu bằng cách chèn dữ liệu hàng loạt (vài nghìn hàng cùng một lúc) ở chế độ đồng bộ hóa TẮT mà không cần ghi nhật ký và trong một giao dịch.
LiteDB nhận được một đối tượng có Danh sách trong số các thuộc tính của nó và thư viện tự lưu nó vào đĩa.
Trong quá trình phát triển ứng dụng thử nghiệm, tôi hiểu rằng tôi thích LiteDB hơn. Vấn đề là mã thử nghiệm cho SQLite mất nhiều hơn 120 hàng, trong khi mã giải quyết vấn đề tương tự trong LiteDb, chỉ mất 20 hàng.
Tạo dữ liệu thử nghiệm
FileStrings.cs
nội bộ lớp FileStrings {private static readonly Random random =new Random (); public List Strings {get; đặt; } =new Danh sách (); public int SomeInfo {get; đặt; } public FileStrings () {} public FileStrings (int id, int minLines, decimal lineIncrement) {SomeInfo =id; int lines =minLines + (int) (id * lineIncrement); for (int i =0; i Chuỗi tệp mới (f, MIN_NUM_LINES, (MAX_NUM_LINES - MIN_NUM_LINES) / (thập phân) NUM_FILES)) .ToList ();
SQLite
private static void SaveToDb (List files) {using (var connection =new SQLiteConnection ()) {connect.ConnectionString =@ "Data Source =data \ database.db; FailIfMissing =False;"; kết nối.Open (); var command =connection.CreateCommand (); command.CommandText =@ "TẠO tệp BẢNG (id INTEGER PRIMARY KEY, file_name TEXT); TẠO chuỗi BẢNG (id INTEGER PRIMARY KEY, string TEXT, file_id INTEGER, line_number INTEGER); CREATE INDEX UNIQUE string_file_id_line_number_uindex ON PRAGMA đồng bộ =OFF; PRAGMA journal_mode =OFF "; command.ExecuteNonQuery (); var insertFilecommand =connection.CreateCommand (); insertFilecommand.CommandText ="INSERT INTO files (file_name) VALUES (?); CHỌN last_insert_rowid ();"; insertFilecommand.Parameters.Add (insertFilecommand.CreateParameter ()); insertFilecommand.Prepare (); var insertLineCommand =connection.CreateCommand (); insertLineCommand.CommandText ="CHÈN VÀO chuỗi (string, file_id, line_number) VALUES (?,?,?);"; insertLineCommand.Parameters.Add (insertLineCommand.CreateParameter ()); insertLineCommand.Parameters.Add (insertLineCommand.CreateParameter ()); insertLineCommand.Parameters.Add (insertLineCommand.CreateParameter ()); insertLineCommand.Prepare (); foreach (var item in files) {using (var tr =connect.BeginTransaction ()) {SaveToDb (item, insertFilecommand, insertLineCommand); tr.Commit (); }}}} private static void SaveToDb (FileStrings item, SQLiteCommand insertFileCommand, SQLiteCommand insertLinesCommand) {string fileName =Path.Combine ("data", item.SomeInfo + ".sql"); insertFileCommand.Parameters [0] .Value =fileName; var fileId =insertFileCommand.ExecuteScalar (); int lineIndex =0; foreach (var line in item.Strings) {insertLinesCommand.Parameters [0] .Value =line; insertLinesCommand.Parameters [1] .Value =fileId; insertLinesCommand.Parameters [2] .Value =lineIndex ++; insertLinesCommand.ExecuteNonQuery (); }}
LiteDB
private static void SaveToNoSql (List item) {using (var db =new LiteDatabase ("data \\ litedb.db")) {var data =db.GetCollection ("files"); data.EnsureIndex (f => f.SomeInfo); data.Insert (mục); }}
Bảng sau đây cho thấy kết quả trung bình cho một số lần chạy mã thử nghiệm. Trong quá trình sửa đổi, độ lệch thống kê là khá khó lường.
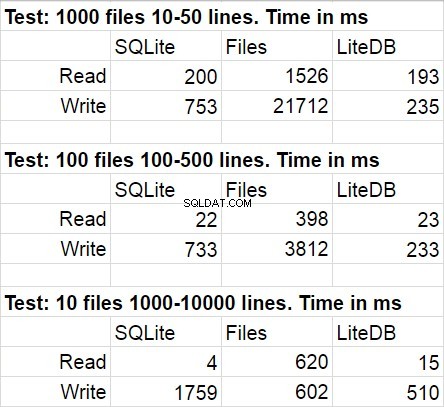
Tôi không ngạc nhiên khi LiteDB giành chiến thắng trong cuộc so sánh này. Tuy nhiên, tôi đã bị sốc trước chiến thắng của LiteDB trên các tệp. Sau khi nghiên cứu ngắn về kho thư viện, tôi đã phát hiện ra tính năng ghi theo trang vào đĩa được thực hiện rất tỉ mỉ, nhưng tôi chắc chắn rằng đây chỉ là một trong nhiều thủ thuật hiệu suất được sử dụng ở đó. Một điều nữa mà tôi muốn chỉ ra là tốc độ truy cập hệ thống tệp giảm nhanh khi số lượng tệp trong thư mục trở nên thực sự lớn.
Chúng tôi đã chọn LiteDB để phát triển tính năng của mình và chúng tôi hầu như không hối hận về sự lựa chọn này. Vấn đề là thư viện được viết bằng ngôn ngữ gốc cho mọi người C #, và nếu có bất kỳ điều gì không rõ ràng, chúng tôi luôn có thể tham khảo mã nguồn.
Nhược điểm
Bên cạnh những ưu điểm đã đề cập ở trên của LiteDB so với các đối thủ của nó, chúng tôi bắt đầu nhận thấy những nhược điểm trong quá trình phát triển. Hầu hết những khuyết điểm này có thể được giải thích bởi 'sức trẻ' của thư viện. Khi bắt đầu sử dụng thư viện vượt ra ngoài ranh giới của kịch bản ‘tiêu chuẩn’ một chút, chúng tôi đã phát hiện ra một số vấn đề (# 419, # 420, # 483, # 496). Tác giả của thư viện trả lời các câu hỏi khá nhanh, và hầu hết các vấn đề đều được giải quyết nhanh chóng. Bây giờ, chỉ còn một nhiệm vụ (đừng nhầm với trạng thái Đã đóng của nó). Đây là một vấn đề của việc tiếp cận cạnh tranh. Có vẻ như tình trạng chủng tộc rất khó chịu đang ẩn náu đâu đó sâu trong thư viện. Chúng tôi đã vượt qua lỗi này một cách khá nguyên bản (tôi định viết một bài riêng về chủ đề này).
Tôi cũng muốn đề cập đến sự vắng mặt của trình biên tập và trình xem gọn gàng. Có LiteDBShell, nhưng chỉ dành cho những người hâm mộ bảng điều khiển thực sự.
Tóm tắt
Chúng tôi đã xây dựng một chức năng lớn và quan trọng trên LiteDB, và bây giờ chúng tôi đang làm việc trên một tính năng lớn khác, nơi chúng tôi cũng sẽ sử dụng thư viện này. Đối với những người đang tìm kiếm một cơ sở dữ liệu trong quá trình, tôi khuyên bạn nên chú ý đến LiteDB và cách nó sẽ tự chứng minh trong bối cảnh nhiệm vụ của bạn, vì như bạn biết, nếu điều gì đó đã giải quyết cho một nhiệm vụ, nó sẽ không nhất thiết chuẩn bị cho một nhiệm vụ khác.