Một vài tuần trước, nhóm SQLskills đã ở Tampa để tham gia Sự kiện hòa nhập điều chỉnh hiệu suất (IE2) và tôi đang đề cập đến các đường cơ sở. Đường cơ sở là một chủ đề gần gũi và thân thiết với trái tim tôi, bởi vì chúng rất có giá trị vì nhiều lý do. Hai trong số những lý do đó, mà tôi luôn đưa ra cho dù là giảng dạy hay làm việc với khách hàng, là sử dụng các đường cơ sở để khắc phục sự cố hiệu suất, sau đó cũng sử dụng theo xu hướng và cung cấp các ước tính lập kế hoạch năng lực. Nhưng chúng cũng rất cần thiết khi bạn thực hiện điều chỉnh hoặc kiểm tra hiệu suất - cho dù bạn có coi các chỉ số hiệu suất hiện tại của mình là đường cơ sở hay không.
Trong mô-đun, tôi đã xem xét các nguồn khác nhau cho dữ liệu như Màn hình hiệu suất, DMV và dữ liệu theo dõi hoặc XE, và một câu hỏi được đưa ra liên quan đến tải dữ liệu. Cụ thể, câu hỏi đặt ra là liệu có tốt hơn không nếu tải dữ liệu vào một bảng không có chỉ mục và sau đó tạo chúng khi hoàn tất, thay vì đặt các chỉ mục trong quá trình tải dữ liệu. Câu trả lời của tôi là "Điển hình là có". Kinh nghiệm cá nhân của tôi là điều này luôn đúng như vậy, nhưng bạn không bao giờ biết được ai đó có thể gặp phải trường hợp báo trước hoặc một lần nào đó mà hiệu suất thay đổi không như mong đợi và như với tất cả các câu hỏi về hiệu suất, bạn sẽ không biết chắc chắn cho đến khi bạn kiểm tra nó. Cho đến khi bạn thiết lập đường cơ sở cho một phương pháp và sau đó xem liệu phương pháp kia có cải thiện dựa trên đường cơ sở đó hay không, bạn chỉ đoán. Tôi nghĩ sẽ rất thú vị khi thử nghiệm kịch bản này, không chỉ để chứng minh những gì tôi mong đợi là đúng, mà còn cho thấy những chỉ số nào tôi sẽ kiểm tra, lý do và cách nắm bắt chúng. của các bạn mới làm quen với phương pháp này, tôi sẽ thực hiện từng bước theo quy trình mà tôi làm theo để giúp bạn bắt đầu. Nhận ra rằng có nhiều cách để tìm ra câu trả lời cho “Phương pháp nào tốt hơn?” Tôi mong rằng bạn sẽ thực hiện quá trình này, chỉnh sửa nó và biến nó thành của bạn theo thời gian.
Bạn đang cố gắng chứng minh điều gì?
Bước đầu tiên là quyết định chính xác những gì bạn đang thử nghiệm. Trong trường hợp của chúng tôi, đó là vấn đề đơn giản:tải dữ liệu vào một bảng trống, sau đó thêm các chỉ mục sẽ nhanh hơn hay nhanh hơn để có các chỉ mục trên bảng trong quá trình tải dữ liệu? Tuy nhiên, chúng ta có thể thêm một số biến thể ở đây nếu chúng ta muốn. Hãy xem xét thời gian cần thiết để tải dữ liệu vào một đống, sau đó tạo các chỉ mục nhóm và không gộp, so với thời gian cần thiết để tải dữ liệu vào một chỉ mục nhóm, rồi tạo các chỉ mục không phân nhóm. Có sự khác biệt về hiệu suất không? Khóa phân cụm có phải là một yếu tố không? Tôi hy vọng rằng việc tải dữ liệu sẽ khiến các chỉ mục không phân tán hiện có bị phân mảnh, vì vậy có lẽ tôi muốn xem tác động của việc xây dựng lại các chỉ mục sau khi tải lên tổng thời lượng. Điều quan trọng là phải mở rộng phạm vi bước này càng nhiều càng tốt và rất cụ thể về những gì bạn muốn đo lường, vì điều này sẽ xác định dữ liệu bạn thu thập. Đối với ví dụ của chúng tôi, bốn bài kiểm tra của chúng tôi sẽ là:
Thử nghiệm 1: Tải dữ liệu vào một đống, tạo chỉ mục theo nhóm, tạo chỉ mục không phân nhóm
Thử nghiệm 2: Tải dữ liệu vào một chỉ mục được phân nhóm, tạo các chỉ mục không được phân nhóm
Thử nghiệm 3: Tạo chỉ mục nhóm và chỉ mục không hợp nhất, tải dữ liệu
Thử nghiệm 4: Tạo chỉ mục nhóm và các chỉ mục không hợp nhất, tải dữ liệu, xây dựng lại các chỉ mục không hợp nhất
Bạn cần biết gì?
Trong kịch bản của chúng tôi, câu hỏi chính của chúng tôi là "phương pháp nào là nhanh nhất"? Do đó, chúng tôi muốn đo thời lượng và để làm như vậy, chúng tôi cần nắm bắt thời gian bắt đầu và thời gian kết thúc. Chúng tôi có thể để nó ở mức đó, nhưng chúng tôi có thể muốn hiểu việc sử dụng tài nguyên trông như thế nào đối với mỗi phương pháp, hoặc có lẽ chúng tôi muốn biết số lần đợi cao nhất, số lượng giao dịch hoặc số lần bế tắc. Dữ liệu thú vị và phù hợp nhất sẽ phụ thuộc vào quá trình bạn đang so sánh. Việc nắm bắt số lượng giao dịch không phải là điều thú vị đối với tải dữ liệu của chúng tôi; nhưng đối với một mã thay đổi, nó có thể được. Bởi vì chúng tôi đang tạo chỉ mục và xây dựng lại chúng, tôi quan tâm đến lượng IO mà mỗi phương pháp tạo ra. Mặc dù thời lượng tổng thể có lẽ là yếu tố quyết định cuối cùng, nhưng việc xem xét IO có thể hữu ích để không chỉ hiểu tùy chọn nào tạo ra nhiều IO nhất mà còn cả việc lưu trữ cơ sở dữ liệu có hoạt động như mong đợi hay không.
Dữ liệu bạn cần ở đâu?
Khi bạn đã xác định được dữ liệu mình cần, hãy quyết định xem dữ liệu đó sẽ được thu thập từ đâu. Chúng tôi quan tâm đến thời lượng, vì vậy chúng tôi muốn ghi lại thời gian mỗi lần kiểm tra tải dữ liệu bắt đầu và thời điểm kết thúc. Chúng tôi cũng quan tâm đến IO và chúng tôi có thể lấy dữ liệu này từ nhiều vị trí - bộ đếm Màn hình hiệu suất và sys.dm_io_virtual_file_stats DMV có lưu ý đến.
Hiểu rằng chúng tôi có thể lấy dữ liệu này theo cách thủ công. Trước khi chạy thử nghiệm, chúng tôi có thể chọn dựa trên sys.dm_io_virtual_file_stats và lưu các giá trị hiện tại vào một tệp. Chúng tôi có thể ghi lại thời gian, và sau đó bắt đầu kiểm tra. Khi quá trình kết thúc, chúng tôi lưu ý thời gian một lần nữa, truy vấn lại sys.dm_io_virtual_file_stats và tính toán sự khác biệt giữa các giá trị để đo IO.
Có rất nhiều sai sót trong phương pháp luận này, cụ thể là nó để lại chỗ sai đáng kể; Điều gì sẽ xảy ra nếu bạn quên ghi lại thời gian bắt đầu hoặc quên ghi lại số liệu thống kê của tệp trước khi bắt đầu? Một giải pháp tốt hơn nhiều là tự động hóa không chỉ việc thực thi tập lệnh mà còn cả việc thu thập dữ liệu. Ví dụ:chúng tôi có thể tạo một bảng chứa thông tin kiểm tra của chúng tôi - mô tả về kiểm tra là gì, thời gian bắt đầu và thời gian hoàn thành. Chúng tôi có thể bao gồm thống kê tệp trong cùng một bảng. Nếu chúng tôi đang thu thập các số liệu khác, chúng tôi có thể thêm chúng vào bảng. Hoặc, có thể dễ dàng hơn để tạo một bảng riêng cho từng bộ dữ liệu mà chúng tôi thu thập. Ví dụ:nếu chúng tôi lưu trữ dữ liệu thống kê tệp trong một bảng khác, chúng tôi cần cung cấp cho mỗi thử nghiệm một id duy nhất để chúng tôi có thể khớp thử nghiệm của mình với dữ liệu thống kê tệp phù hợp. Khi thu thập thống kê tệp, chúng tôi phải nắm bắt các giá trị cho cơ sở dữ liệu của mình trước khi bắt đầu, sau đó sau đó và tính toán sự khác biệt. Sau đó, chúng tôi có thể lưu trữ thông tin đó vào bảng của riêng nó, cùng với ID thử nghiệm duy nhất.
Bài tập mẫu
Đối với thử nghiệm này, tôi đã tạo một bản sao trống của bảng Sales.SalesOrderHeader có tên là Sales.Big_SalesOrderHeader và tôi đã sử dụng một biến thể của tập lệnh mà tôi đã sử dụng trong bài đăng phân vùng của mình để tải dữ liệu vào bảng theo lô khoảng 25.000 hàng. Bạn có thể tải xuống tập lệnh để tải dữ liệu tại đây. Tôi đã chạy nó bốn lần cho mỗi biến thể và tôi cũng thay đổi tổng số hàng được chèn. Đối với bộ kiểm tra đầu tiên, tôi đã chèn 20 triệu hàng và đối với bộ thứ hai, tôi đã chèn 60 triệu hàng. Dữ liệu thời lượng không có gì đáng ngạc nhiên:
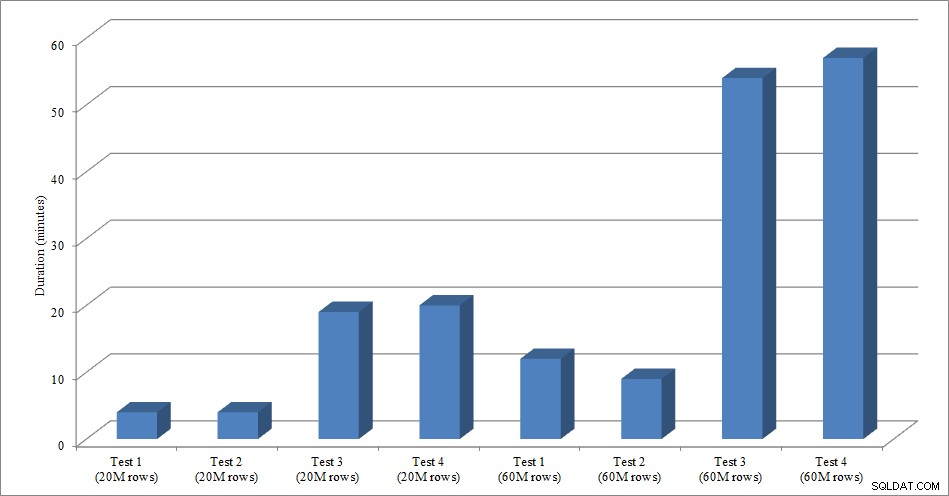
Thời lượng tải dữ liệu
Việc tải dữ liệu, không có chỉ mục không phân biệt, nhanh hơn nhiều so với tải dữ liệu với các chỉ mục không phân biệt đã có sẵn. Điều tôi thấy thú vị là đối với tải 20 triệu hàng, tổng thời lượng là như nhau giữa Thử nghiệm 1 và Thử nghiệm 2, nhưng Thử nghiệm 2 nhanh hơn khi tải 60 triệu hàng. Trong thử nghiệm của chúng tôi, khóa phân cụm của chúng tôi là SalesOrderID, là một danh tính và do đó là một khóa phân cụm tốt cho tải của chúng tôi vì nó tăng dần. Nếu thay vào đó, chúng tôi có khóa phân cụm là GUID, thì thời gian tải có thể cao hơn do các lần chèn và tách trang ngẫu nhiên (một biến thể khác mà chúng tôi có thể kiểm tra).
Dữ liệu IO có bắt chước xu hướng trong dữ liệu thời lượng không? Có, với sự khác biệt có các chỉ mục đã có sẵn hoặc không, thậm chí còn phóng đại hơn:
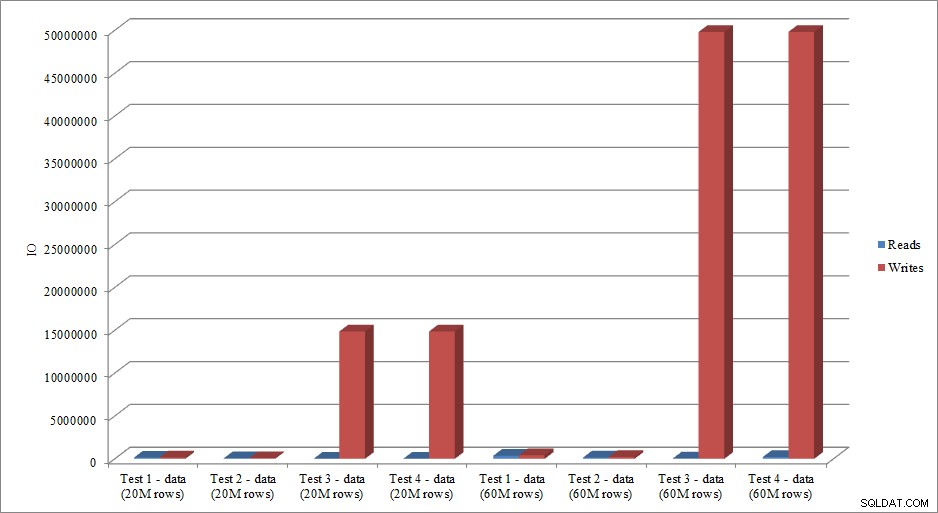
Lượt đọc và ghi khi tải dữ liệu
Phương pháp mà tôi đã trình bày ở đây để kiểm tra hiệu suất hoặc đo lường các thay đổi về hiệu suất dựa trên các sửa đổi đối với mã, thiết kế, v.v., chỉ là một tùy chọn để thu thập thông tin cơ bản. Trong một số trường hợp, điều này có thể là quá mức cần thiết. Nếu bạn có một truy vấn đang cố gắng điều chỉnh, thì việc thiết lập quy trình này để thu thập dữ liệu có thể mất nhiều thời gian hơn so với việc thực hiện các chỉnh sửa đối với truy vấn! Nếu bạn đã thực hiện bất kỳ quá trình điều chỉnh truy vấn nào, bạn có thể có thói quen thu thập dữ liệu THỐNG KÊ IO và THỜI GIAN THỐNG KÊ, cùng với kế hoạch truy vấn, sau đó so sánh kết quả đầu ra khi bạn thực hiện các thay đổi. Tôi đã làm việc này trong nhiều năm, nhưng gần đây tôi đã khám phá ra một cách tốt hơn… SQL Sentry Plan Explorer PRO. Trên thực tế, sau khi hoàn thành tất cả các thử nghiệm tải mà tôi đã mô tả ở trên, tôi đã thực hiện và chạy lại các thử nghiệm của mình thông qua PE và nhận thấy rằng tôi có thể nắm bắt thông tin mình muốn mà không cần phải thiết lập các bảng thu thập dữ liệu của mình.
Trong Plan Explorer PRO, bạn có tùy chọn để lấy kế hoạch thực tế - PE sẽ chạy truy vấn đối với phiên bản và cơ sở dữ liệu đã chọn, đồng thời trả về kế hoạch. Và với nó, bạn nhận được tất cả các dữ liệu tuyệt vời khác mà PE cung cấp (thống kê thời gian, đọc và ghi, IO theo bảng), cũng như thống kê chờ, đó là một lợi ích tuyệt vời. Sử dụng ví dụ của chúng tôi, tôi bắt đầu với thử nghiệm đầu tiên - tạo heap, tải dữ liệu và sau đó thêm chỉ mục nhóm và các chỉ mục không hợp nhất - và sau đó chạy tùy chọn Nhận kế hoạch thực tế. Khi nó hoàn thành, tôi đã sửa đổi thử nghiệm tập lệnh 2 của mình, chạy lại tùy chọn Nhận kế hoạch thực tế. Tôi đã lặp lại điều này cho bài kiểm tra thứ ba và thứ tư, và khi tôi hoàn thành, tôi có điều này:
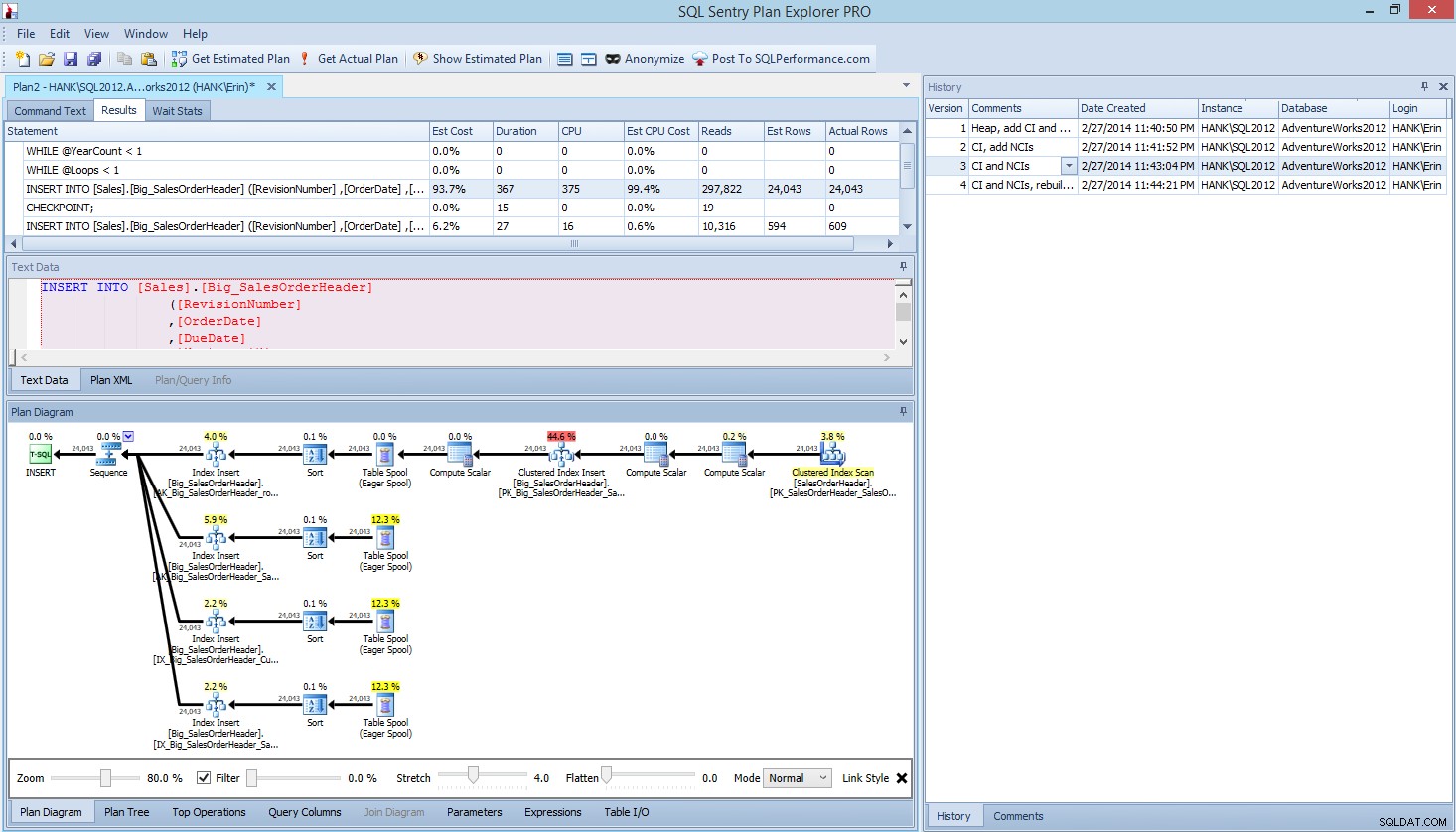
Chế độ xem Plan Explorer PRO sau khi chạy 4 thử nghiệm
Lưu ý ngăn lịch sử ở phía bên phải? Mỗi khi tôi sửa đổi mã của mình và lấy lại kế hoạch thực tế, nó sẽ lưu một tập hợp thông tin mới. Tôi có thể lưu dữ liệu này dưới dạng tệp .pesession để chia sẻ với một thành viên khác trong nhóm của mình hoặc quay lại sau và cuộn qua các bài kiểm tra khác nhau và đi sâu vào các câu lệnh khác nhau trong lô nếu cần, xem xét các chỉ số khác nhau như như thời lượng, CPU và IO. Trong ảnh chụp màn hình ở trên, tôi đã đánh dấu INSERT từ Thử nghiệm 3 và kế hoạch truy vấn hiển thị các bản cập nhật cho cả bốn chỉ mục không phân nhóm.
Tóm tắt
Cũng như rất nhiều tác vụ trong SQL Server, có nhiều cách để thu thập và xem xét dữ liệu khi bạn đang chạy kiểm tra hiệu suất hoặc thực hiện điều chỉnh. Bạn càng phải thực hiện càng ít nỗ lực thủ công càng tốt, vì nó giúp bạn có nhiều thời gian hơn để thực sự thay đổi, hiểu tác động và sau đó chuyển sang nhiệm vụ tiếp theo của bạn. Cho dù bạn tùy chỉnh tập lệnh để thu thập dữ liệu hay để tiện ích của bên thứ ba làm điều đó cho bạn, các bước tôi đã nêu vẫn hợp lệ:
- Xác định những gì bạn muốn cải thiện
- Phạm vi thử nghiệm của bạn
- Xác định dữ liệu nào có thể được sử dụng để đo lường sự cải thiện
- Quyết định cách thu thập dữ liệu
- Thiết lập một phương pháp tự động, bất cứ khi nào có thể, để kiểm tra và nắm bắt
- Kiểm tra, đánh giá và lặp lại nếu cần
Chúc bạn thử nghiệm vui vẻ!