Tuần trước, tôi đã thực hiện một số so sánh nhanh về hiệu suất, tạo ra STRING_AGG() mới chức năng chống lại FOR XML PATH truyền thống cách tiếp cận mà tôi đã sử dụng trong nhiều năm. Tôi đã kiểm tra cả đơn đặt hàng không xác định / tùy ý cũng như đơn hàng rõ ràng và STRING_AGG() đứng đầu trong cả hai trường hợp:
- SQL Server v.Next:Hiệu suất STRING_AGG (), Phần 1
Đối với những thử nghiệm đó, tôi đã bỏ qua một số thứ (không phải tất cả đều cố ý):
- Mikael Eriksson và Grzegorz Łyp đều chỉ ra rằng tôi không sử dụng
FOR XML PATHhiệu quả nhất tuyệt đối xây dựng (và để rõ ràng, tôi không bao giờ có). - Tôi đã không thực hiện bất kỳ thử nghiệm nào trên Linux; chỉ trên Windows. Tôi không hy vọng chúng sẽ khác nhau quá nhiều, nhưng vì Grzegorz đã thấy những khoảng thời gian rất khác nhau, nên điều này đáng để điều tra thêm.
- Tôi cũng chỉ kiểm tra khi đầu ra là một chuỗi hữu hạn, không phải LOB - mà tôi tin rằng đây là trường hợp sử dụng phổ biến nhất (tôi không nghĩ rằng mọi người sẽ thường nối mọi hàng trong bảng thành một chuỗi được phân tách bằng dấu phẩy string, nhưng đây là lý do tại sao tôi đã hỏi trong bài viết trước về (các) trường hợp sử dụng của bạn.
- Đối với các bài kiểm tra thứ tự, tôi đã không tạo một chỉ mục có thể hữu ích (hoặc thử bất kỳ thứ gì trong đó tất cả dữ liệu đến từ một bảng duy nhất).
Trong bài đăng này, tôi sẽ đề cập đến một số mặt hàng trong số này, nhưng không phải tất cả chúng.
ĐỐI VỚI PHƯƠNG TIỆN XML
Tôi đã sử dụng những thứ sau:
... FOR XML PATH, TYPE).value(N'.[1]', ...
Sau nhận xét này từ Mikael, tôi đã cập nhật mã của mình để sử dụng cấu trúc hơi khác này thay thế:
... FOR XML PATH(''), TYPE).value(N'text()[1]', ... Linux so với Windows
Ban đầu, tôi chỉ bận tâm đến việc chạy thử nghiệm trên Windows:
Microsoft SQL Server vNext (CTP1.1) - 14.0.100.187 (X64) Dec 10 2016 02:51:11 Copyright (C) 2016 Microsoft Corporation. All rights reserved. Developer Edition (64-bit) on Windows Server 2016 Datacenter 6.3(Build 14393: ) (Hypervisor)
Nhưng Grzegorz đã nói rõ rằng anh ta (và có lẽ là nhiều người khác) chỉ có quyền truy cập vào phiên bản Linux của CTP 1.1. Vì vậy, tôi đã thêm Linux vào ma trận kiểm tra của mình:
Microsoft SQL Server vNext (CTP1.1) - 14.0.100.187 (X64) Dec 10 2016 02:51:11 Copyright (C) 2016 Microsoft Corporation. All rights reserved. on Linux (Ubuntu 16.04.1 LTS)
Một số quan sát thú vị nhưng hoàn toàn tiếp tuyến:
-
@@VERSIONkhông hiển thị ấn bản trong bản dựng này, nhưngSERVERPROPERTY('Edition')trả vềDeveloper Edition (64-bit). - Dựa trên thời gian xây dựng được mã hóa thành các tệp nhị phân, các phiên bản Windows và Linux dường như hiện được biên dịch cùng một lúc và từ cùng một nguồn. Hoặc đây là một sự trùng hợp điên rồ.
Kiểm tra không theo thứ tự
Tôi đã bắt đầu bằng cách thử nghiệm đầu ra có thứ tự tùy ý (trong đó không có thứ tự được xác định rõ ràng cho các giá trị được nối). Theo dõi Grzegorz, tôi đã sử dụng WideWorldImporters (Chuẩn), nhưng thực hiện kết hợp giữa Sales.Orders và Sales.OrderLines . Yêu cầu hư cấu ở đây là xuất một danh sách tất cả các đơn hàng và cùng với mỗi đơn hàng, một danh sách được phân tách bằng dấu phẩy của mỗi StockItemID .
Kể từ khi StockItemID là một số nguyên, chúng ta có thể sử dụng một varchar đã xác định , có nghĩa là chuỗi có thể dài 8000 ký tự trước khi chúng ta phải lo lắng về việc cần MAX. Vì một int có thể có độ dài tối đa là 11 (thực sự là 10, nếu không có dấu), cộng với dấu phẩy, điều này có nghĩa là một đơn đặt hàng sẽ phải hỗ trợ khoảng 8.000/12 (666) mặt hàng trong trường hợp xấu nhất (ví dụ:tất cả các giá trị StockItemID đều có 11 chữ số). Trong trường hợp của chúng tôi, ID dài nhất là 3 chữ số, vì vậy cho đến khi dữ liệu được thêm vào, chúng tôi thực sự cần 8.000 / 4 (2.000) mặt hàng tồn kho duy nhất trong bất kỳ đơn hàng nào để biện minh cho MAX. Trong trường hợp của chúng tôi, tổng số chỉ có 227 mặt hàng trong kho, vì vậy MAX là không cần thiết, nhưng bạn nên để ý đến điều đó. Nếu một chuỗi lớn như vậy có thể xảy ra trong trường hợp của bạn, bạn sẽ cần sử dụng varchar(max) thay vì mặc định (STRING_AGG() trả về nvarchar(max) , nhưng cắt ngắn còn 8.000 byte trừ khi đầu vào là loại MAX).
Các truy vấn ban đầu (để hiển thị đầu ra mẫu và quan sát thời lượng cho các lần thực thi đơn lẻ):
SET STATISTICS TIME ON;
GO
SELECT o.OrderID, StockItemIDs = STRING_AGG(ol.StockItemID, ',')
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
SELECT o.OrderID,
StockItemIDs = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Sample output:
OrderID StockItemIDs
======= ============
1 67
2 50,10
3 114
4 206,130,50
5 128,121,155
Important SET STATISTICS TIME metrics (SQL Server Execution Times):
Windows:
STRING_AGG: CPU time = 217 ms, elapsed time = 405 ms.
FOR XML PATH: CPU time = 1954 ms, elapsed time = 2097 ms.
Linux:
STRING_AGG: CPU time = 627 ms, elapsed time = 472 ms.
FOR XML PATH: CPU time = 2188 ms, elapsed time = 2223 ms.
*/
Tôi đã bỏ qua hoàn toàn dữ liệu thời gian phân tích cú pháp và biên dịch, vì chúng luôn luôn chính xác bằng 0 hoặc đủ gần để không liên quan. Có sự khác biệt nhỏ về thời gian thực thi cho mỗi lần chạy, nhưng không nhiều - các nhận xét ở trên phản ánh delta điển hình trong thời gian chạy (STRING_AGG dường như tận dụng một chút lợi thế của tính song song ở đó, nhưng chỉ trên Linux, trong khi FOR XML PATH không trên cả hai nền tảng). Cả hai máy đều có một ổ cắm duy nhất, được phân bổ CPU lõi tứ, bộ nhớ 8 GB, cấu hình mới và không có hoạt động nào khác.
Sau đó, tôi muốn thử nghiệm trên quy mô lớn (chỉ đơn giản là một phiên duy nhất thực hiện cùng một truy vấn 500 lần). Tôi không muốn trả lại tất cả kết quả đầu ra, như trong truy vấn ở trên, 500 lần, vì điều đó sẽ áp đảo SSMS - và hy vọng dù sao cũng không đại diện cho các kịch bản truy vấn trong thế giới thực. Vì vậy, tôi đã chỉ định đầu ra cho các biến và chỉ đo thời gian tổng thể cho mỗi đợt:
SELECT sysdatetime();
GO
DECLARE @i int, @x varchar(8000);
SELECT @i = o.OrderID, @x = STRING_AGG(ol.StockItemID, ',')
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int, @x varchar(8000);
SELECT @i = o.OrderID,
@x = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime(); Tôi đã chạy các bài kiểm tra đó ba lần, và sự khác biệt là rất lớn - gần như một mức độ. Đây là thời lượng trung bình qua ba bài kiểm tra:
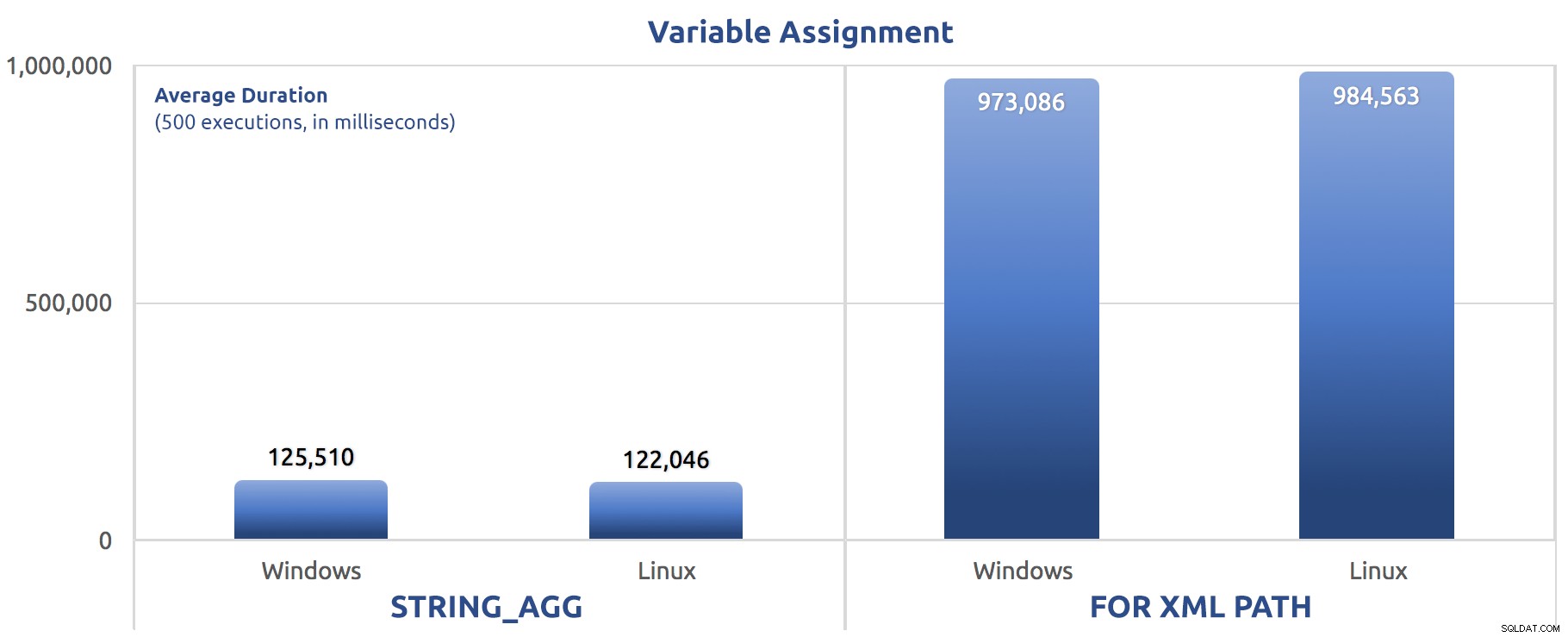 Thời lượng trung bình, tính bằng mili giây, cho 500 lần thực thi phép gán biến
Thời lượng trung bình, tính bằng mili giây, cho 500 lần thực thi phép gán biến
Tôi cũng đã thử nghiệm nhiều thứ khác theo cách này, chủ yếu là để đảm bảo rằng tôi đang bao gồm các loại thử nghiệm mà Grzegorz đang chạy (không có phần LOB).
- Chỉ chọn độ dài của đầu ra
- Nhận độ dài tối đa của đầu ra (của một hàng tùy ý)
- Chọn tất cả kết quả đầu ra vào một bảng mới
Chỉ chọn độ dài của đầu ra
Mã này chỉ chạy qua từng đơn đặt hàng, nối tất cả các giá trị StockItemID và sau đó chỉ trả về độ dài.
SET STATISTICS TIME ON;
GO
SELECT LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
SELECT LEN(STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 142 ms, elapsed time = 351 ms.
FOR XML PATH: CPU time = 1984 ms, elapsed time = 2120 ms.
Linux:
STRING_AGG: CPU time = 310 ms, elapsed time = 191 ms.
FOR XML PATH: CPU time = 2149 ms, elapsed time = 2167 ms.
*/ Đối với phiên bản theo lô, một lần nữa, tôi đã sử dụng phép gán biến thay vì cố gắng trả lại nhiều tập kết quả cho SSMS. Việc gán biến sẽ kết thúc trên một hàng tùy ý, nhưng điều này vẫn yêu cầu quét toàn bộ, vì hàng tùy ý không được chọn trước.
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = LEN(STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime(); Số liệu hiệu suất của 500 lần thực thi:
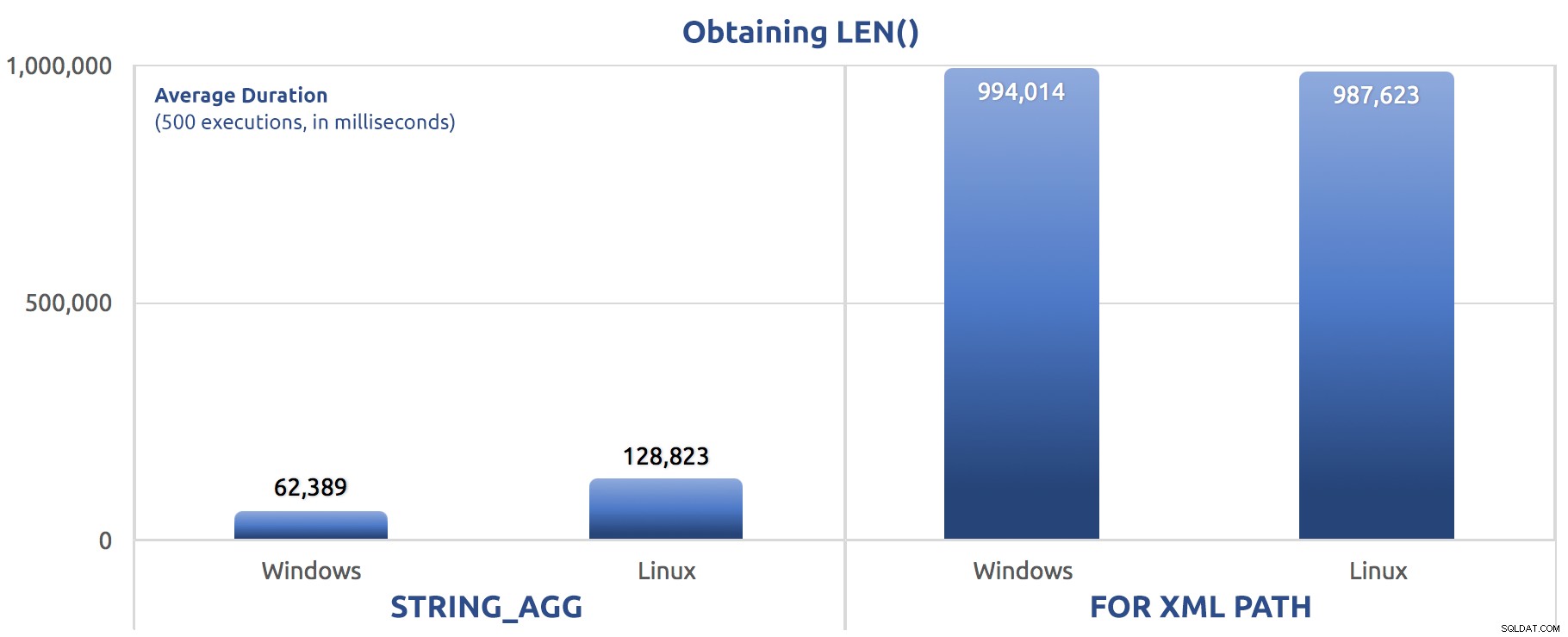 500 lần thực hiện gán LEN () cho một biến
500 lần thực hiện gán LEN () cho một biến
Một lần nữa, chúng ta thấy FOR XML PATH chậm hơn rất nhiều, trên cả Windows và Linux.
Chọn độ dài tối đa của đầu ra
Một thay đổi nhỏ so với thử nghiệm trước đó, thử nghiệm này chỉ truy xuất tối đa độ dài của đầu ra được nối:
SET STATISTICS TIME ON;
GO
SELECT MAX(s) FROM (SELECT s = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID) AS x;
GO
SELECT MAX(s) FROM (SELECT s = LEN(STUFF(
(SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),
1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID) AS x;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 188 ms, elapsed time = 48 ms.
FOR XML PATH: CPU time = 1891 ms, elapsed time = 907 ms.
Linux:
STRING_AGG: CPU time = 270 ms, elapsed time = 83 ms.
FOR XML PATH: CPU time = 2725 ms, elapsed time = 1205 ms.
*/ Và ở quy mô lớn, chúng tôi chỉ cần gán lại đầu ra đó cho một biến:
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = MAX(s) FROM (SELECT s = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID) AS x;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = MAX(s) FROM (SELECT s = LEN(STUFF
(
(SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),
1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID) AS x;
GO 500
SELECT sysdatetime(); Kết quả hiệu suất, cho 500 lần thực thi, được tính trung bình trong ba lần chạy:
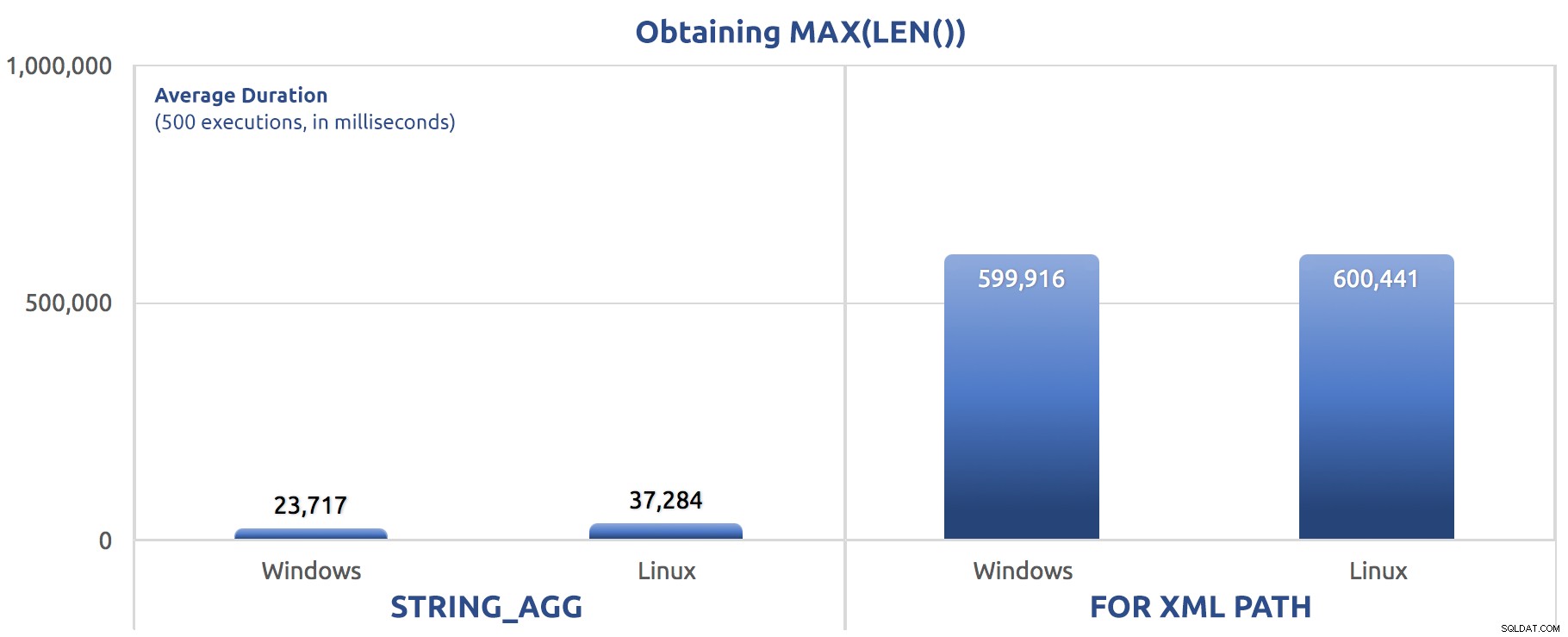 500 lần thực hiện gán MAX (LEN ()) cho một biến
500 lần thực hiện gán MAX (LEN ()) cho một biến
Bạn có thể bắt đầu nhận thấy một mẫu trong các bài kiểm tra này - FOR XML PATH luôn luôn là một con chó, ngay cả với các cải tiến hiệu suất được đề xuất trong bài đăng trước của tôi.
CHỌN VÀO
Tôi muốn xem liệu phương pháp nối có bất kỳ tác động nào đến việc viết dữ liệu trở lại đĩa, như trường hợp trong một số trường hợp khác:
SET NOCOUNT ON;
GO
SET STATISTICS TIME ON;
GO
DROP TABLE IF EXISTS dbo.HoldingTank_AGG;
SELECT o.OrderID, x = STRING_AGG(ol.StockItemID, ',')
INTO dbo.HoldingTank_AGG
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
DROP TABLE IF EXISTS dbo.HoldingTank_XML;
SELECT o.OrderID, x = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
INTO dbo.HoldingTank_XML
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 218 ms, elapsed time = 90 ms.
FOR XML PATH: CPU time = 4202 ms, elapsed time = 1520 ms.
Linux:
STRING_AGG: CPU time = 277 ms, elapsed time = 108 ms.
FOR XML PATH: CPU time = 4308 ms, elapsed time = 1583 ms.
*/
Trong trường hợp này, chúng tôi thấy rằng có lẽ SELECT INTO đã có thể tận dụng một chút tính song song, nhưng chúng tôi vẫn thấy FOR XML PATH vật lộn, với thời gian chạy một thứ tự cường độ dài hơn STRING_AGG .
Phiên bản theo đợt vừa hoán đổi các lệnh SET STATISTICS cho SELECT sysdatetime(); và thêm GO 500 tương tự sau hai đợt chính như với các lần kiểm tra trước. Đây là cách điều đó diễn ra (một lần nữa, hãy cho tôi biết nếu bạn đã nghe điều này trước đây):
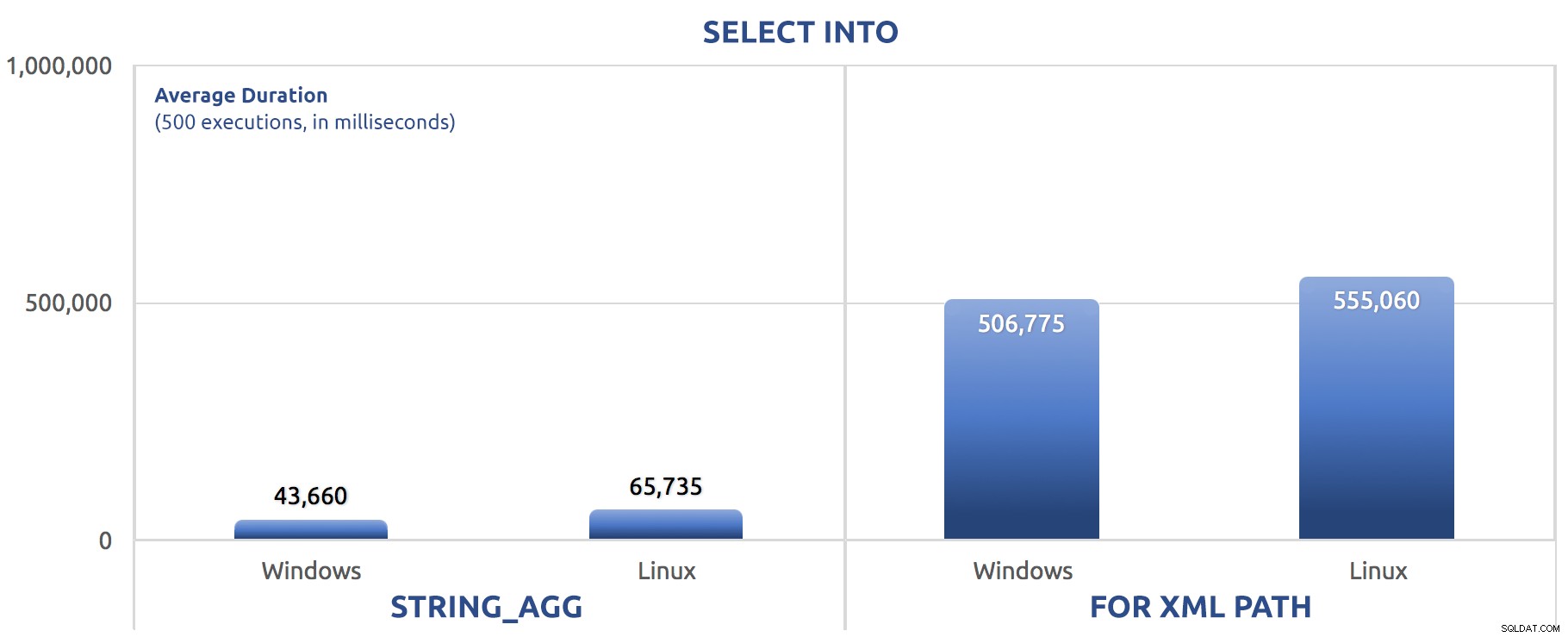 500 lần thực thi CHỌN VÀO
500 lần thực thi CHỌN VÀO
Kiểm tra theo thứ tự
Tôi đã chạy các bài kiểm tra tương tự bằng cách sử dụng cú pháp có thứ tự, ví dụ:
... STRING_AGG(ol.StockItemID, ',')
WITHIN GROUP (ORDER BY ol.StockItemID) ...
... WHERE ol.OrderID = o.OrderID
ORDER BY ol.StockItemID
FOR XML PATH('') ... Điều này có rất ít tác động đến bất cứ điều gì - cùng một bộ bốn giàn thử nghiệm cho thấy các chỉ số và mô hình gần như giống hệt nhau trên toàn diện.
Tôi sẽ tò mò muốn biết liệu điều này có gì khác khi đầu ra được nối ở dạng không phải LOB hoặc nơi nối cần sắp xếp các chuỗi (có hoặc không có chỉ mục hỗ trợ).
Kết luận
Đối với chuỗi không phải LOB , tôi thấy rõ rằng STRING_AGG có lợi thế về hiệu suất rõ ràng so với FOR XML PATH , trên cả Windows và Linux. Lưu ý rằng, để tránh yêu cầu varchar(max) hoặc nvarchar(max) , Tôi đã không sử dụng bất kỳ thứ gì tương tự như các thử nghiệm mà Grzegorz đã chạy, điều này có nghĩa là chỉ cần nối tất cả các giá trị từ một cột, trên toàn bộ bảng, thành một chuỗi duy nhất. Trong bài đăng tiếp theo của tôi, tôi sẽ xem xét trường hợp sử dụng trong đó đầu ra của chuỗi được nối có thể lớn hơn 8.000 byte và do đó, các loại LOB và chuyển đổi sẽ phải được sử dụng.