Mặc dù SQL Server trên Linux đã đánh cắp gần như tất cả các tiêu đề về v.Next, nhưng có một số cải tiến thú vị khác sẽ xuất hiện trong phiên bản tiếp theo của nền tảng cơ sở dữ liệu yêu thích của chúng tôi. Ở mặt trước T-SQL, cuối cùng chúng ta đã có một cách tích hợp để thực hiện nối chuỗi được nhóm theo nhóm:STRING_AGG() .
Giả sử chúng ta có cấu trúc bảng đơn giản sau:
TẠO BẢNG dbo.Objects ([object_id] int, [object_name] nvarchar (261), CONSTRAINT PK_Objects PRIMARY KEY ([object_id])); TẠO BẢNG dbo.Columns ([object_id] int NOT NULL FOREIGN KEY THAM KHẢO dbo.Objects ([object_id]), column_name sysname, CONSTRAINT PK_Columns PRIMARY KEY ([object_id], column_name));
Đối với các bài kiểm tra hiệu suất, chúng tôi sẽ điền thông tin này bằng cách sử dụng sys.all_objects và sys.all_columns . Nhưng để có một minh chứng đơn giản trước tiên, hãy thêm các hàng sau:
CHÈN dbo.Objects ([object_id], [object_name]) VALUES (1, N'E Nhân viên '), (2, N'Orders'); INSERT dbo.Columns ([object_id], column_name) VALUES (1, N'EFasteeID '), (1, N'CurrentStatus'), (2, N'OrderID '), (2, N'OrderDate'), (2 , N'CustomerID ');
Nếu các diễn đàn là bất kỳ dấu hiệu nào, thì yêu cầu rất phổ biến là trả về một hàng cho mỗi đối tượng, cùng với danh sách tên cột được phân tách bằng dấu phẩy. (Ngoại suy điều đó cho bất kỳ loại thực thể nào mà bạn lập mô hình theo cách này - tên sản phẩm liên quan đến đơn đặt hàng, tên bộ phận liên quan đến việc lắp ráp sản phẩm, cấp dưới báo cáo cho người quản lý, v.v.) Vì vậy, ví dụ, với dữ liệu trên, chúng tôi muốn đầu ra như thế này:
Các cột đối tượng-------------------------------------------- Nhân viên EmployeeID, CurrentStatusOrders OrderID, OrderDate, ID khách hàng
Cách chúng tôi thực hiện điều này trong các phiên bản SQL Server hiện tại có lẽ là sử dụng FOR XML PATH , như tôi đã chứng minh là hiệu quả nhất bên ngoài CLR trong bài đăng trước đó. Trong ví dụ này, nó sẽ giống như sau:
SELECT [object] =o. [object_id], [column] =STUFF ((SELECT N ',' + c.column_name FROM dbo.Columns AS c WHERE c. [object_id] =o. [object_id] FOR XML PATH, TYPE) .value (N '. [1]', N'nvarchar (max) '), 1,1, N' ') FROM dbo.Objects AS o;
Có thể dự đoán, chúng tôi nhận được cùng một kết quả được trình bày ở trên. Trong SQL Server v.Next, chúng ta có thể diễn đạt điều này đơn giản hơn:
SELECT [object] =o. [object_name], [column] =STRING_AGG (c.column_name, N ',') FROM dbo.Objects AS oINNER JOIN dbo.Columns AS cON o. [object_id] =c. [ object_id] GROUP BY o. [object_name];
Một lần nữa, điều này tạo ra cùng một đầu ra. Và chúng tôi có thể làm điều này với một hàm gốc, tránh cả FOR XML PATH đắt tiền giàn giáo và STUFF() được sử dụng để loại bỏ dấu phẩy đầu tiên (điều này xảy ra tự động).
Còn về Đơn hàng thì sao?
Một trong những vấn đề với nhiều giải pháp k bùn đối với nối theo nhóm là thứ tự của danh sách được phân tách bằng dấu phẩy nên được coi là tùy ý và không xác định.
Đối với XML PATH giải pháp, tôi đã chứng minh trong một bài đăng khác trước đó rằng thêm một ORDER BY là tầm thường và được đảm bảo. Vì vậy, trong ví dụ này, chúng ta có thể sắp xếp danh sách cột theo tên cột theo thứ tự bảng chữ cái thay vì để nó cho SQL Server để sắp xếp (hoặc không):
SELECT [object] =[object_id], [column] =STUFF ((CHỌN N ',' + c.column_name FROM dbo.Columns AS c WHERE c. [object_id] =o. [object_id] ORDER BY c. column_name - chỉ thay đổi FOR XML PATH, TYPE) .value (N '. [1]', N'nvarchar (max) '), 1,1, N' ') FROM dbo.Objects AS o;
Đầu ra:
Các cột đối tượng------------------------------------------------- Nhân viên Hiện tại, ID Nhân viên, Đơn hàng Khách hàng, Ngày đặt hàng, OrderID
CTP 1.1 thêm WITHIN GROUP thành STRING_AGG() , do đó, bằng cách sử dụng phương pháp mới, chúng ta có thể nói:
SELECT [object] =o. [object_name], [column] =STRING_AGG (c.column_name, N ',') TRONG VÒNG NHÓM (ORDER BY c.column_name) - chỉ changeFROM dbo.Objects AS oINNER JOIN dbo. Các cột NHƯ cON o. [Object_id] =c. [Object_id] GROUP BY o. [Object_name];
Bây giờ chúng tôi nhận được kết quả tương tự. Lưu ý rằng, giống như một ORDER BY thông thường , bạn có thể thêm nhiều cột hoặc biểu thức sắp xếp thứ tự bên trong WITHIN GROUP () .
Được rồi, Hiệu suất đã sẵn sàng!
Sử dụng bộ xử lý lõi tứ 2,6 GHz, 8 GB bộ nhớ và SQL Server CTP1.1 (14.0.100.187), tôi đã tạo cơ sở dữ liệu mới, tạo lại các bảng này và thêm các hàng từ sys.all_objects và sys.all_columns . Tôi đảm bảo chỉ bao gồm các đối tượng có ít nhất một cột:
CHÈN dbo.Objects ([object_id], [object_name]) - 656 hàng CHỌN [object_id], QUOTENAME (s.name) + N '.' + QUOTENAME (o.name) TỪ sys.all_objects AS o INNER JOIN sys.schemas AS s ON o. [Schema_id] =s. [Schema_id] WHERE EXISTS (CHỌN 1 TỪ sys.all_columns WHERE [object_id] =o. [Object_id ]); CHÈN dbo.Columns ([object_id], column_name) - 8.085 hàng CHỌN [object_id], tên TỪ sys.all_columns NHƯ c CÓ TỒN TẠI (CHỌN 1 TỪ dbo.Objects WHERE [object_id] =c. [Object_id]);Trên hệ thống của tôi, điều này mang lại 656 đối tượng và 8.085 cột (hệ thống của bạn có thể mang lại những con số hơi khác một chút).
Các kế hoạch
Đầu tiên, hãy so sánh các kế hoạch và tab Bảng I / O cho hai truy vấn không có thứ tự của chúng tôi, bằng cách sử dụng Plan Explorer. Dưới đây là các chỉ số thời gian chạy tổng thể:
Chỉ số thời gian chạy cho XML PATH (trên) và STRING_AGG () (dưới)
Sơ đồ đồ họa và Bảng I / O từ
FOR XML PATHtruy vấn:
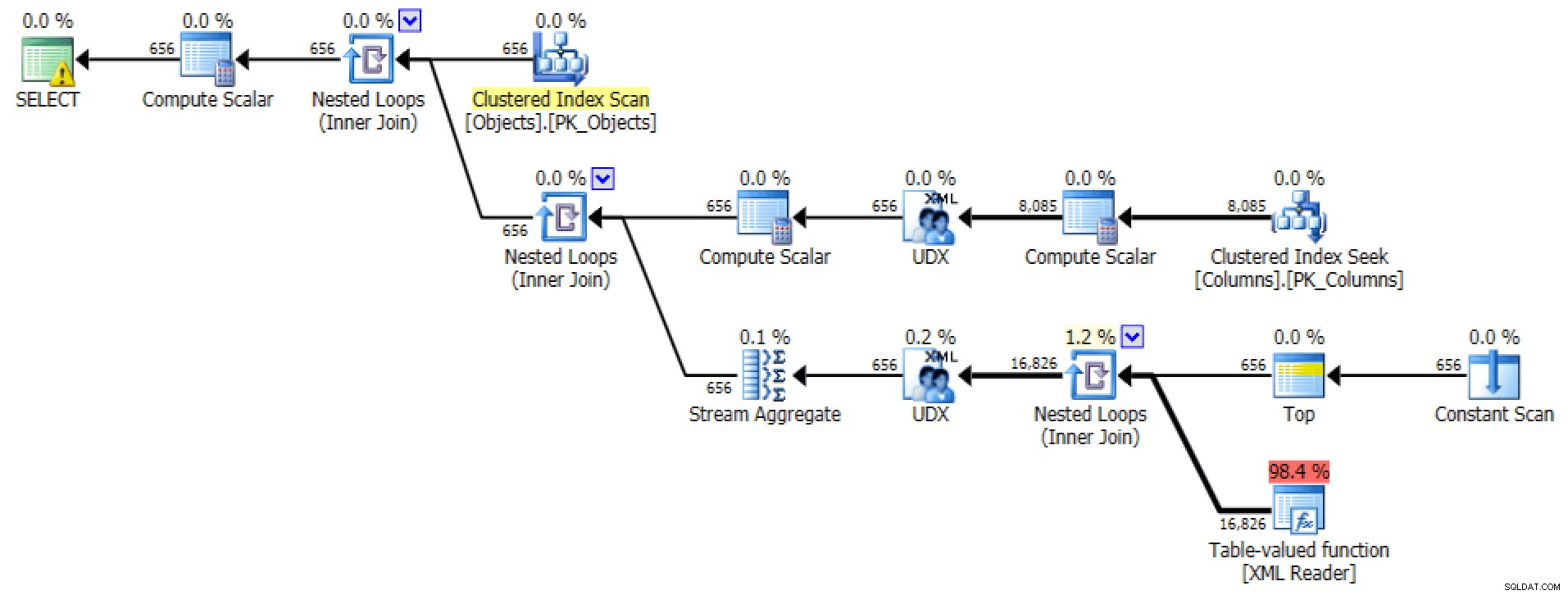
Kế hoạch và Bảng I / O đối với XML PATH, không có đơn đặt hàng
Và từ
STRING_AGGphiên bản:
Kế hoạch và Bảng I / O cho STRING_AGG, không cần đặt hàng
Đối với phần sau, tìm kiếm chỉ mục theo cụm có vẻ hơi rắc rối đối với tôi. Đây có vẻ là một trường hợp tốt để kiểm tra
FORCESCANhiếm khi được sử dụng gợi ý (và không, điều này chắc chắn sẽ không giúp ích được gì choFOR XML PATHtruy vấn):SELECT [object] =o. [object_name], [column] =STRING_AGG (c.column_name, N ',') FROM dbo.Objects AS oINNER JOIN dbo.Columns AS c WITH (FORCESCAN) - thêm gợi ý o . [object_id] =c. [object_id] GROUP BY o. [object_name];Bây giờ kế hoạch và tab Bảng I / O trông rất nhiều tốt hơn, ít nhất là ở cái nhìn đầu tiên:
Kế hoạch và Bảng I / O cho STRING_AGG (), không cần đặt hàng, với FORCESCAN
Các phiên bản có thứ tự của các truy vấn tạo ra các kế hoạch gần giống nhau. Đối với
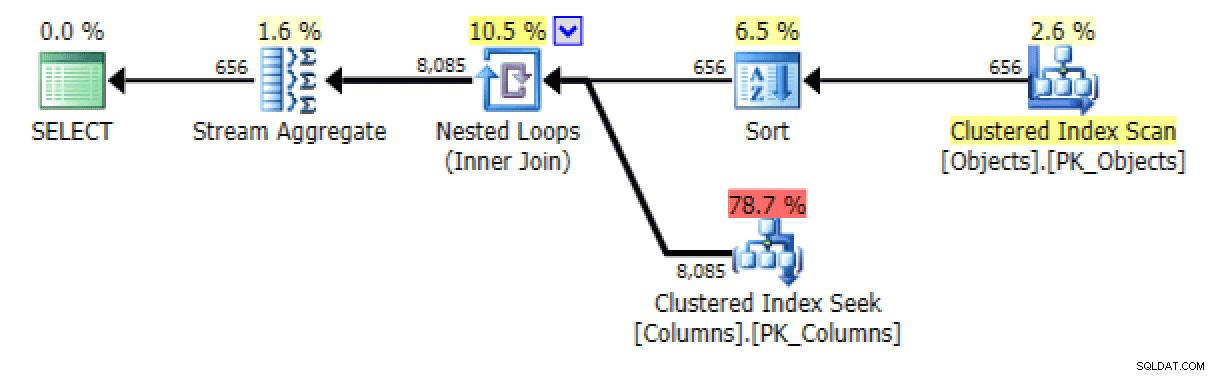
FOR XML PATHphiên bản, một loại được thêm vào:
Đã thêm sắp xếp trong phiên bản FOR XML PATH
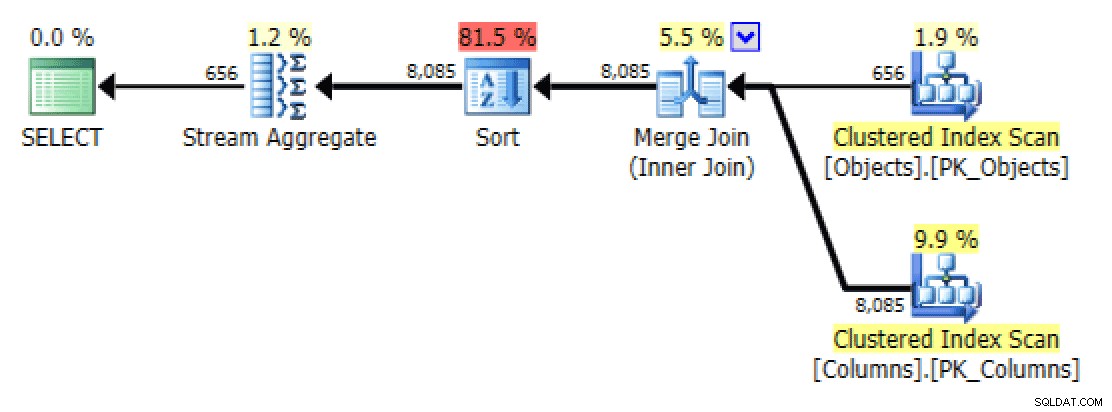
Đối với
STRING_AGG(), quá trình quét được chọn trong trường hợp này, ngay cả khi không cóFORCESCANgợi ý và không cần thao tác sắp xếp bổ sung - vì vậy kế hoạch trông giống vớiFORCESCANphiên bản.Theo quy mô
Việc xem xét kế hoạch và các chỉ số thời gian chạy một lần có thể cho chúng ta một số ý tưởng về việc liệu
STRING_AGG()hoạt động tốt hơnFOR XML PATHhiện có giải pháp, nhưng một thử nghiệm lớn hơn có thể có ý nghĩa hơn. Điều gì sẽ xảy ra khi chúng tôi thực hiện phép nối được nhóm lại 5.000 lần?SELECT SYSDATETIME (); GO DECLARE @x nvarchar (max); SELECT @x =STRING_AGG (c.column_name, N ',') FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c ON o. [object_id ] =c. [object_id] GROUP BY o. [object_name]; GO 5000SELECT [string_agg, không có thứ tự] =SYSDATETIME (); GO DECLARE @x nvarchar (max); SELECT @x =STRING_AGG (c.column_name, N ',' ) TỪ dbo.Objects AS o INNER JOIN dbo.Columns AS c WITH (FORCESCAN) ON o. [Object_id] =c. [Object_id] GROUP BY o. [Object_name]; GO 5000SELECT [string_agg, unsrdered, forcecan] =SYSDATETIME ( ); GODECLARE @x nvarchar (max); SELECT @x =STUFF ((CHỌN N ',' + c.column_name FROM dbo.Columns AS c WHERE c. [Object_id] =o. [Object_id] FOR XML PATH, TYPE) .value (N '. [1]', N'nvarchar (max) '), 1,1, N' ') FROM dbo.Objects AS o; GO 5000SELECT [cho đường dẫn xml, không có thứ tự] =SYSDATETIME (); GODECLARE @x nvarchar (max); SELECT @x =STRING_AGG (c.column_name, N ',') TRONG VÒNG NHÓM (ĐẶT HÀNG THEO c.column_name) TỪ dbo.Objects AS o INNER JOIN dbo.Columns AS c ON o. [Object_id ] =c. [object_id] GROUP BY o. [object_name]; GO 5000SELECT [string_agg, Order] =SYSDATETIME (); GODECLARE @x nvarchar (max); SELECT @x =STUFF ((CHỌN N ',' + c.column_name FROM dbo.Columns AS c WHERE c. [Object_id] =o. [Object_id] ORDER BY c.column_name FOR XML PATH , TYPE) .value (N '. [1]', N'nvarchar (max) '), 1,1, N' ') FROM dbo.Objects AS oORDER BY o. [Object_name]; GO 5000SELECT [cho đường dẫn xml , đã đặt hàng] =SYSDATETIME ();Sau khi chạy tập lệnh này năm lần, tôi tính trung bình số thời lượng và đây là kết quả:
Thời lượng (mili giây) cho các phương pháp nối theo nhóm khác nhau
Chúng ta có thể thấy rằng
FORCESCANcủa chúng tôi gợi ý thực sự đã làm cho mọi thứ trở nên tồi tệ hơn - trong khi chúng tôi chuyển chi phí ra khỏi tìm kiếm chỉ mục theo cụm, loại thực sự còn tồi tệ hơn nhiều, mặc dù chi phí ước tính được coi là tương đối tương đương. Quan trọng hơn, chúng ta có thể thấy rằngSTRING_AGG()không mang lại lợi ích về hiệu suất, cho dù các chuỗi được nối có cần được sắp xếp theo một cách cụ thể hay không. Như vớiSTRING_SPLIT(), mà tôi đã xem xét lại vào tháng 3, tôi khá ấn tượng rằng chức năng này hoạt động tốt trước "v1".Tôi có kế hoạch kiểm tra thêm, có lẽ cho một bài đăng trong tương lai:
- Khi tất cả dữ liệu đến từ một bảng duy nhất, có và không có chỉ mục hỗ trợ sắp xếp
- Các bài kiểm tra hiệu suất tương tự trên Linux
Trong thời gian chờ đợi, nếu bạn có các trường hợp sử dụng cụ thể cho việc nối theo nhóm, vui lòng chia sẻ chúng bên dưới (hoặc gửi e-mail cho tôi theo địa chỉ abertrand@sentryone.com). Tôi luôn cởi mở để đảm bảo rằng các bài kiểm tra của tôi giống trong thế giới thực nhất có thể.



