Puppet là phần mềm mã nguồn mở để quản lý và triển khai cấu hình. Được thành lập vào năm 2005, nó đa nền tảng và thậm chí có ngôn ngữ khai báo riêng để cấu hình.

Các tác vụ liên quan đến quản trị và bảo trì PostgreSQL (hoặc phần mềm thực sự khác) bao gồm các quy trình lặp đi lặp lại hàng ngày và yêu cầu giám sát. Điều này áp dụng ngay cả với những tác vụ được vận hành bởi các tập lệnh hoặc lệnh thông qua một công cụ lập lịch trình. Độ phức tạp của các tác vụ này tăng lên theo cấp số nhân khi được thực thi trên một cơ sở hạ tầng lớn, tuy nhiên, việc sử dụng Puppet cho các loại tác vụ này thường có thể giải quyết các loại vấn đề quy mô lớn này vì Puppet tập trung và tự động hóa việc thực hiện các hoạt động này một cách rất linh hoạt.
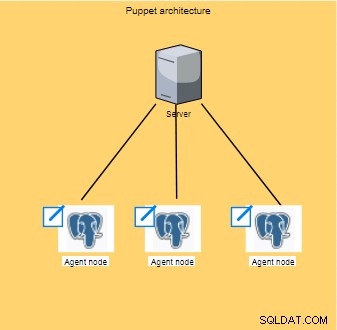
Con rối hoạt động trong kiến trúc ở cấp máy khách / máy chủ nơi cấu hình đang được thực hiện; các hoạt động này sau đó được khuếch tán và thực thi trên tất cả các máy khách (còn được gọi là các nút).
Thông thường chạy 30 phút một lần, nút của tác nhân sẽ thu thập một tập hợp thông tin (loại bộ xử lý, kiến trúc, địa chỉ IP, v.v.), còn được gọi là dữ kiện, sau đó gửi thông tin đến master đang chờ câu trả lời để xem có cấu hình mới nào cần áp dụng không.
Những dữ kiện này sẽ cho phép cái chính tùy chỉnh cùng một cấu hình cho mỗi nút.
Nói một cách đơn giản, Con rối là một trong những công cụ DevOps quan trọng nhất có sẵn ngày hôm nay. Trong blog này, chúng ta sẽ xem xét những điều sau ...
- Trường hợp sử dụng cho Puppet &PostgreSQL
- Cài đặt con rối
- Định cấu hình &lập trình con rối
- Định cấu hình con rối cho PostgreSQL
Quá trình cài đặt và thiết lập Puppet (phiên bản 5.3.10) được mô tả bên dưới được thực hiện trong một bộ máy chủ sử dụng CentOS 7.0 làm hệ điều hành.
Trường hợp sử dụng cho Puppet &PostgreSQL
Giả sử rằng có sự cố trong tường lửa của bạn trên các máy lưu trữ tất cả các máy chủ PostgreSQL của bạn, thì cần phải từ chối tất cả các kết nối gửi đi đến PostgreSQL và thực hiện càng sớm càng tốt.

Con rối là công cụ hoàn hảo cho tình huống này, đặc biệt vì tốc độ và hiệu quả Thiết yếu. Chúng ta sẽ nói về ví dụ này được trình bày trong phần “Định cấu hình con rối cho PostgreSQL” bằng cách quản lý tham số nghe_addresses.
Cài đặt Con rối
Có một loạt các bước phổ biến để thực hiện trên máy chủ chính hoặc máy chủ đại lý:
Bước Một
Cập nhật tệp / etc / hosts với tên máy chủ và địa chỉ IP của chúng
192.168.1.85 agent agent.severalnines.com
192.168.1.87 master master.severalnines.com puppetBước Hai
Thêm kho Con rối trên hệ thống
$ sudo rpm –Uvh https://yum.puppetlabs.com/puppet5/el/7/x86_64/puppet5-release-5.0.0-1-el7.noarch.rpmĐối với các hệ điều hành hoặc phiên bản CentOS khác, bạn có thể tìm thấy kho lưu trữ thích hợp nhất trong Kho lưu trữ Puppet, Inc. Yum.
Bước Ba
Cấu hình máy chủ NTP (Giao thức thời gian mạng)
$ sudo yum -y install chronyBước Bốn
Chrony được sử dụng để đồng bộ hóa đồng hồ hệ thống từ các máy chủ NTP khác nhau và do đó giữ cho thời gian được đồng bộ hóa giữa máy chủ chính và máy chủ đại lý.
Sau khi cài đặt chrony, nó phải được bật và khởi động lại:
$ sudo systemctl enable chronyd.service
$ sudo systemctl restart chronyd.serviceBước Năm
Tắt tham số SELinux
Trên tệp / etc / sysconfig / selinux, tham số SELINUX (Linux được tăng cường bảo mật) phải được tắt để không hạn chế quyền truy cập trên cả hai máy chủ.
SELINUX=disabledBước Sáu
Trước khi cài đặt Con rối (chính hoặc tác nhân), tường lửa trong các máy chủ này phải được xác định tương ứng:
$ sudo firewall-cmd -–add-service=ntp -–permanent
$ sudo firewall-cmd –-reload Cài đặt Puppet Master
Sau khi kho lưu trữ gói rối5-release-5.0.0-1-el7.noarch.rpm được thêm vào hệ thống, quá trình cài đặt trình phục vụ rối có thể được thực hiện:
$ sudo yum install -y puppetserverTham số phân bổ bộ nhớ tối đa là cài đặt quan trọng để cập nhật tệp / etc / sysconfig / puppetserver lên 2GB (hoặc lên 1GB nếu dịch vụ không khởi động):
JAVA_ARGS="-Xms2g –Xmx2g "Trong tệp cấu hình /etc/puppetlabs/puppet/puppet.conf, cần thêm thông số sau:
[master]
dns_alt_names=master.severalnines.com,puppet
[main]
certname = master.severalnines.com
server = master.severalnines.com
environment = production
runinterval = 1hDịch vụ máy chủ con rối sử dụng cổng 8140 để lắng nghe các yêu cầu của nút, do đó cần đảm bảo rằng cổng này sẽ được bật:
$ sudo firewall-cmd --add-port=8140/tcp --permanent
$ sudo firewall-cmd --reloadSau khi tất cả các cài đặt đã được thực hiện trong phần mềm điều khiển rối, đã đến lúc khởi động dịch vụ này:
$ sudo systemctl start puppetserver
$ sudo systemctl enable puppetserver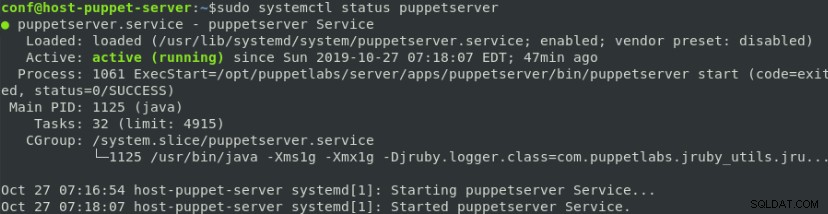
Cài đặt Tác nhân Con rối
Tác nhân con rối trong kho lưu trữ gói rối5-release-5.0.0-1-el7.noarch.rpm cũng được thêm vào hệ thống, việc cài đặt tác nhân con rối có thể được thực hiện ngay lập tức:
$ sudo yum install -y puppet-agentTệp cấu hình tác nhân rối /etc/puppetlabs/puppet/puppet.conf cũng cần được cập nhật bằng cách thêm thông số sau:
[main]
certname = agent.severalnines.com
server = master.severalnines.com
environment = production
runinterval = 1hBước tiếp theo bao gồm đăng ký nút tác nhân trên máy chủ chính bằng cách thực hiện lệnh sau:
$ sudo /opt/puppetlabs/bin/puppet resource service puppet ensure=running enable=true
service { ‘puppet’:
ensure => ‘running’,
enable => ‘true’
}Vào lúc này, trên máy chủ, có một yêu cầu đang chờ xử lý từ đặc vụ bù nhìn về việc ký một chứng chỉ:

Điều đó phải được ký bằng cách thực hiện một trong các lệnh sau:
$ sudo /opt/puppetlabs/bin/puppet cert sign agent.severalnines.comhoặc
$ sudo /opt/puppetlabs/bin/puppet cert sign --allCuối cùng (và khi người điều khiển con rối đã ký chứng chỉ) đã đến lúc áp dụng các cấu hình cho đặc vụ bằng cách truy xuất danh mục từ người điều khiển con rối:
$ sudo /opt/puppetlabs/bin/puppet agent --testTrong lệnh này, tham số --test không có nghĩa là kiểm tra, các cài đặt được truy xuất từ cái chính sẽ được áp dụng cho tác nhân cục bộ. Để kiểm tra / kiểm tra cấu hình từ chính, lệnh sau phải được thực hiện:
$ sudo /opt/puppetlabs/bin/puppet agent --noopCấu hình &Lập trình Con rối
Puppet sử dụng phương pháp lập trình khai báo, mục đích là chỉ định những việc cần làm và không quan trọng bằng cách nào để đạt được điều đó!
Đoạn mã cơ bản nhất trên Puppet là tài nguyên chỉ định thuộc tính hệ thống như lệnh, dịch vụ, tệp, thư mục, người dùng hoặc gói.
Dưới đây trình bày cú pháp của tài nguyên để tạo người dùng:
user { 'admin_postgresql':
ensure => present,
uid => '1000',
gid => '1000',
home => '/home/admin/postresql'
}Các tài nguyên khác nhau có thể được tham gia vào lớp cũ (còn được gọi là tệp kê khai) của tệp có phần mở rộng “pp” (nó là viết tắt của Chương trình con rối), tuy nhiên, một số tệp kê khai và dữ liệu (chẳng hạn như dữ kiện, tệp và mẫu) sẽ tạo một mô-đun. Tất cả các quy tắc và phân cấp logic đó được biểu diễn trong sơ đồ dưới đây:
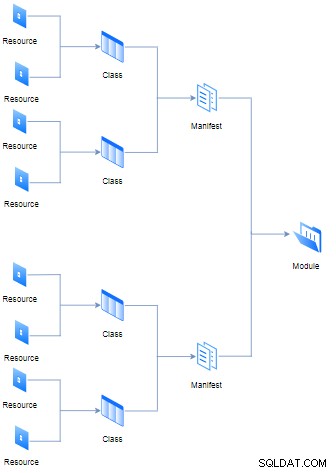
Mục đích của mỗi mô-đun là chứa tất cả các tệp kê khai cần thiết để thực thi đơn nhiệm vụ theo cách mô-đun. Mặt khác, khái niệm lớp không giống với các ngôn ngữ lập trình hướng đối tượng, trong Puppet, nó hoạt động như một tập hợp các tài nguyên.
Tổ chức tệp này có cấu trúc thư mục cụ thể để tuân theo:
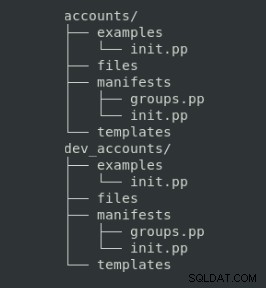
Mục đích của mỗi thư mục như sau:
| Thư mục | Mô tả |
| kê khai | Mã con rối |
| tệp | Các tệp tĩnh sẽ được sao chép vào các nút |
| mẫu | Tệp mẫu sẽ được sao chép vào các nút được quản lý (nó có thể được tùy chỉnh bằng các biến) |
| ví dụ | Tệp kê khai để hiển thị cách sử dụng mô-đun |
class dev_accounts {
$rootgroup = $osfamily ? {
'Debian' => 'sudo',
'RedHat' => 'wheel',
default => warning('This distribution is not supported by the Accounts module'),
}
include accounts::groups
user { 'username':
ensure => present,
home => '/home/admin/postresql',
shell => '/bin/bash',
managehome => true,
gid => 'admin_db',
groups => "$rootgroup",
password => '$1$7URTNNqb$65ca6wPFDvixURc/MMg7O1'
}
}Trong phần tiếp theo, chúng tôi sẽ chỉ cho bạn cách tạo nội dung của thư mục ví dụ cũng như các lệnh để kiểm tra và xuất bản từng mô-đun.
Định cấu hình Con rối cho PostgreSQL
Trước khi trình bày một số ví dụ cấu hình để triển khai và duy trì cơ sở dữ liệu PostgreSQL, bạn cần cài đặt mô-đun bù nhìn PostgreSQL (trên máy chủ lưu trữ) để sử dụng tất cả các chức năng của chúng:
$ sudo /opt/puppetlabs/bin/puppet module install puppetlabs-postgresqlHiện tại, hàng nghìn mô-đun sẵn sàng sử dụng trên Puppet hiện có trên kho lưu trữ mô-đun công khai Puppet Forge.
Bước Một
Định cấu hình và triển khai phiên bản PostgreSQL mới. Đây là tất cả lập trình và cấu hình cần thiết để cài đặt phiên bản PostgreSQL mới trong tất cả các nút.
Bước đầu tiên là tạo một thư mục cấu trúc mô-đun mới như đã chia sẻ trước đây:
$ cd /etc/puppetlabs/code/environments/production/modules
$ mkdir db_postgresql_admin
$ cd db_postgresql_admin; mkdir{examples,files,manifests,templates}Sau đó, trong tệp kê khai tệp kê khai / init.pp, bạn cần bao gồm máy chủ lớp postgresql ::được cung cấp bởi mô-đun đã cài đặt:
class db_postgresql_admin{
include postgresql::server
}Để kiểm tra cú pháp của tệp kê khai, bạn nên thực hiện lệnh sau:
$ sudo /opt/puppetlabs/bin/puppet parser validate init.ppNếu không có gì được trả về, điều đó có nghĩa là cú pháp đúng
Để chỉ cho bạn cách sử dụng mô-đun này trong thư mục mẫu, bạn cần tạo một tệp kê khai mới init.pp với nội dung sau:
include db_postgresql_adminVị trí mẫu trong mô-đun phải được kiểm tra và áp dụng cho danh mục chính:
$ sudo /opt/puppetlabs/bin/puppet apply --modulepath=/etc/puppetlabs/code/environments/production/modules --noop init.ppCuối cùng, cần phải xác định mô-đun nào mà mỗi nút có quyền truy cập trong tệp “/etc/puppetlabs/code/enosystem/production/manifests/site.pp”:
node ’agent.severalnines.com’,’agent2.severalnines.com’{
include db_postgresql_admin
}Hoặc cấu hình mặc định cho tất cả các nút:
node default {
include db_postgresql_admin
}Thông thường cứ sau 30 phút các nút sẽ kiểm tra danh mục chính, tuy nhiên, truy vấn này có thể được buộc ở phía nút bằng lệnh sau:
$ /opt/puppetlabs/bin/puppet agent -tHoặc nếu mục đích là để mô phỏng sự khác biệt giữa cấu hình chính và cài đặt nút hiện tại, nó có thể được sử dụng tham số nopp (không hoạt động):
$ /opt/puppetlabs/bin/puppet agent -t --noopBước Hai
Cập nhật phiên bản PostgreSQL để lắng nghe tất cả các giao diện. Cài đặt trước đó xác định cài đặt phiên bản trong một chế độ rất hạn chế:chỉ cho phép các kết nối trên máy chủ cục bộ có thể được xác nhận bởi máy chủ được liên kết với cổng 5432 (được định nghĩa cho PostgreSQL):
$ sudo netstat -ntlp|grep 5432
tcp 0 0 127.0.0.1:5432 0.0.0.0:* LISTEN 3237/postgres
tcp6 0 0 ::1:5432 :::* LISTEN 3237/postgres Để cho phép nghe tất cả giao diện, bạn cần có nội dung sau trong tệp /etc/puppetlabs/code/enosystem/production/modules/db_postgresql_admin/manifests/init.pp
class db_postgresql_admin{
class{‘postgresql:server’:
listen_addresses=>’*’ #listening all interfaces
}
}Trong ví dụ trên, đã khai báo lớp postgresql ::server và đặt tham số listening_addresses thành “*” có nghĩa là tất cả các giao diện.
Bây giờ cổng 5432 được liên kết với tất cả các giao diện, nó có thể được xác nhận bằng địa chỉ IP / cổng sau:“0.0.0.0:5432”
$ sudo netstat -ntlp|grep 5432
tcp 0 0 0.0.0.0:5432 0.0.0.0:* LISTEN 1232/postgres
tcp6 0 0 :::5432 :::* LISTEN 1232/postgres Để khôi phục cài đặt ban đầu:chỉ cho phép các kết nối cơ sở dữ liệu từ localhost, tham số nghe_addresses phải được đặt thành "localhost" hoặc chỉ định danh sách các máy chủ, nếu muốn:
listen_addresses = 'agent2.severalnines.com,agent3.severalnines.com,localhost'Để truy xuất cấu hình mới từ máy chủ chính, chỉ cần yêu cầu cấu hình đó trên nút:
$ /opt/puppetlabs/bin/puppet agent -tBước Ba
Tạo Cơ sở dữ liệu PostgreSQL. Phiên bản PostgreSQL có thể được tạo bằng cơ sở dữ liệu mới cũng như người dùng mới (có mật khẩu) để sử dụng cơ sở dữ liệu này và quy tắc trên tệp pg_hab.conf để cho phép kết nối cơ sở dữ liệu cho người dùng mới này:
class db_postgresql_admin{
class{‘postgresql:server’:
listen_addresses=>’*’ #listening all interfaces
}
postgresql::server::db{‘nines_blog_db’:
user => ‘severalnines’, password=> postgresql_password(‘severalnines’,’passwd12’)
}
postgresql::server::pg_hba_rule{‘Authentication for severalnines’:
Description =>’Open access to severalnines’,
type => ‘local’,
database => ‘nines_blog_db’,
user => ‘severalnines’,
address => ‘127.0.0.1/32’
auth_method => ‘md5’
}
}Tài nguyên cuối cùng này có tên là "Xác thực cho vàinines" và tệp pg_hba.conf sẽ có thêm một quy tắc bổ sung:
# Rule Name: Authentication for severalnines
# Description: Open access for severalnines
# Order: 150
local nines_blog_db severalnines 127.0.0.1/32 md5Để truy xuất cấu hình mới từ máy chủ chính, tất cả những gì cần thiết là yêu cầu cấu hình đó trên nút:
$ /opt/puppetlabs/bin/puppet agent -tBước Bốn
Tạo Người dùng Chỉ Đọc. Để tạo người dùng mới, với đặc quyền chỉ đọc, các tài nguyên sau cần được thêm vào tệp kê khai trước đó:
postgresql::server::role{‘Creation of a new role nines_reader’:
createdb => false,
createrole => false,
superuser => false, password_hash=> postgresql_password(‘nines_reader’,’passwd13’)
}
postgresql::server::pg_hba_rule{‘Authentication for nines_reader’:
description =>’Open access to nines_reader’,
type => ‘host’,
database => ‘nines_blog_db’,
user => ‘nines_reader’,
address => ‘192.168.1.10/32’,
auth_method => ‘md5’
}Để truy xuất cấu hình mới từ máy chủ chính, tất cả những gì cần thiết là yêu cầu cấu hình đó trên nút:
$ /opt/puppetlabs/bin/puppet agent -tKết luận
Trong bài đăng trên blog này, chúng tôi đã chỉ cho bạn các bước cơ bản để triển khai và bắt đầu định cấu hình cơ sở dữ liệu PostgreSQL của bạn thông qua một cách tự động và tùy chỉnh trên một số nút (thậm chí có thể là máy ảo).
Các loại tự động hóa này có thể giúp bạn trở nên hiệu quả hơn sau đó thực hiện theo cách thủ công và cấu hình PostgreSQL có thể dễ dàng được thực hiện bằng cách sử dụng một số lớp có sẵn trong kho lưu trữ rốiforge