Tính sẵn sàng cao là yêu cầu đối với hầu hết các công ty trên khắp thế giới sử dụng PostgreSQL Người ta biết rằng PostgreSQL sử dụng Streaming Replication làm phương pháp nhân rộng. Theo mặc định, PostgreSQL Streaming Replication là không đồng bộ, vì vậy có thể có một số giao dịch được cam kết trong nút chính chưa được sao chép sang máy chủ dự phòng. Điều này có nghĩa là có khả năng xảy ra một số mất mát dữ liệu tiềm ẩn.
Sự chậm trễ này trong quá trình cam kết được cho là rất nhỏ ... nếu máy chủ dự phòng đủ mạnh để theo kịp tải. Nếu rủi ro mất mát dữ liệu nhỏ này không được chấp nhận trong công ty, bạn cũng có thể sử dụng tính năng sao chép đồng bộ thay vì mặc định.
Trong sao chép đồng bộ, mỗi cam kết của một giao dịch ghi sẽ đợi cho đến khi xác nhận rằng cam kết đã được ghi vào nhật ký ghi trước trên đĩa của cả máy chủ chính và máy chủ dự phòng.
Phương pháp này giảm thiểu khả năng mất dữ liệu. Để xảy ra mất dữ liệu, bạn sẽ cần cả thiết bị chính và dự phòng bị lỗi cùng một lúc.
Nhược điểm của phương pháp này là giống nhau đối với tất cả các phương thức đồng bộ vì với phương pháp này, thời gian phản hồi cho mỗi giao dịch ghi tăng lên. Điều này là do sự cần thiết phải đợi cho đến khi tất cả các xác nhận rằng giao dịch đã được cam kết. May mắn thay, các giao dịch chỉ đọc sẽ không bị ảnh hưởng bởi điều này nhưng; chỉ các giao dịch ghi.
Trong blog này, bạn chỉ cho bạn cách cài đặt Cụm PostgreSQL từ đầu, chuyển đổi bản sao không đồng bộ (mặc định) thành bản sao đồng bộ. Tôi cũng sẽ hướng dẫn bạn cách khôi phục nếu thời gian phản hồi không thể chấp nhận được vì bạn có thể dễ dàng quay lại trạng thái trước đó. Bạn sẽ thấy cách triển khai, cấu hình và giám sát một bản sao đồng bộ PostgreSQL một cách dễ dàng bằng cách sử dụng ClusterControl chỉ bằng một công cụ cho toàn bộ quy trình.
Cài đặt Cụm PostgreSQL
Hãy bắt đầu cài đặt và định cấu hình bản sao PostgreSQL không đồng bộ, đó là chế độ sao chép thông thường được sử dụng trong một cụm PostgreSQL. Chúng tôi sẽ sử dụng PostgreSQL 11 trên CentOS 7.
Cài đặt PostgreSQL
Làm theo hướng dẫn cài đặt chính thức của PostgreSQL, tác vụ này khá đơn giản.
Trước tiên, hãy cài đặt kho lưu trữ:
$ yum install https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpmCài đặt gói máy khách và máy chủ PostgreSQL:
$ yum install postgresql11 postgresql11-serverKhởi tạo cơ sở dữ liệu:
$ /usr/pgsql-11/bin/postgresql-11-setup initdb
$ systemctl enable postgresql-11
$ systemctl start postgresql-11Trên nút chờ, bạn có thể tránh lệnh cuối cùng (khởi động dịch vụ cơ sở dữ liệu) vì bạn sẽ khôi phục một bản sao lưu nhị phân để tạo bản sao truyền trực tuyến.
Bây giờ, hãy xem cấu hình được yêu cầu bởi một bản sao PostgreSQL không đồng bộ.
Định cấu hình sao chép PostgreSQL không đồng bộ
Thiết lập Nút Chính
Trong nút chính của PostgreSQL, bạn phải sử dụng cấu hình cơ bản sau để tạo bản sao Async. Các tệp sẽ được sửa đổi là postgresql.conf và pg_hba.conf. Nói chung, chúng nằm trong thư mục dữ liệu (/ var / lib / pgsql / 11 / data /) nhưng bạn có thể xác nhận nó ở phía cơ sở dữ liệu:
postgres=# SELECT setting FROM pg_settings WHERE name = 'data_directory';
setting
------------------------
/var/lib/pgsql/11/data
(1 row)Postgresql.conf
Thay đổi hoặc thêm các tham số sau trong tệp cấu hình postgresql.conf.
Ở đây bạn cần thêm (các) địa chỉ IP để nghe. Giá trị mặc định là 'localhost' và đối với ví dụ này, chúng tôi sẽ sử dụng '*' cho tất cả các địa chỉ IP trong máy chủ.
listen_addresses = '*' Đặt cổng máy chủ để nghe. Theo mặc định 5432.
port = 5432 Xác định lượng thông tin được ghi vào WAL. Các giá trị có thể là tối thiểu, bản sao hoặc lôgic. Giá trị hot_standby được ánh xạ tới bản sao và nó được sử dụng để giữ tính tương thích với các phiên bản trước.
wal_level = hot_standbyĐặt số lượng quy trình walsender tối đa để quản lý kết nối với máy chủ dự phòng.
max_wal_senders = 16Đặt số lượng tệp WAL tối thiểu được lưu giữ trong thư mục pg_wal.
wal_keep_segments = 32Việc thay đổi các tham số này yêu cầu khởi động lại dịch vụ cơ sở dữ liệu.
$ systemctl restart postgresql-11Pg_hba.conf
Thay đổi hoặc thêm các tham số sau trong tệp cấu hình pg_hba.conf.
# TYPE DATABASE USER ADDRESS METHOD
host replication replication_user IP_STANDBY_NODE/32 md5
host replication replication_user IP_PRIMARY_NODE/32 md5Như bạn thấy, ở đây bạn cần thêm quyền truy cập của người dùng. Cột đầu tiên là kiểu kết nối, có thể là máy chủ hoặc cục bộ. Sau đó, bạn cần chỉ định cơ sở dữ liệu (nhân rộng), người dùng, Địa chỉ IP nguồn và phương thức xác thực. Thay đổi tệp này yêu cầu tải lại dịch vụ cơ sở dữ liệu.
$ systemctl reload postgresql-11Bạn nên thêm cấu hình này vào cả nút chính và nút dự phòng, vì bạn sẽ cần cấu hình này nếu nút dự phòng được thăng cấp thành chính trong trường hợp bị lỗi.
Bây giờ, bạn phải tạo một người dùng sao chép.
Vai trò Sao chép
VAI TRÒ (người dùng) phải có đặc quyền REPLICATION để sử dụng nó trong sao chép trực tuyến.
postgres=# CREATE ROLE replication_user WITH LOGIN PASSWORD 'PASSWORD' REPLICATION;
CREATE ROLESau khi định cấu hình các tệp tương ứng và tạo người dùng, bạn cần tạo một bản sao lưu nhất quán từ nút chính và khôi phục nó trên nút chờ.
Thiết lập Nút chờ
Trên nút chờ, đi tới thư mục / var / lib / pgsql / 11 / và di chuyển hoặc xóa datadir hiện tại:
$ cd /var/lib/pgsql/11/
$ mv data data.bkSau đó, chạy lệnh pg_basebackup để lấy dữ liệu chính hiện tại và chỉ định chủ sở hữu chính xác (postgres):
$ pg_basebackup -h 192.168.100.145 -D /var/lib/pgsql/11/data/ -P -U replication_user --wal-method=stream
$ chown -R postgres.postgres dataBây giờ, bạn phải sử dụng cấu hình cơ bản sau để tạo bản sao Async. Tệp sẽ được sửa đổi là postgresql.conf và bạn cần tạo tệp recovery.conf mới. Cả hai sẽ được đặt trong / var / lib / pgsql / 11 /.
Recovery.conf
Chỉ định rằng máy chủ này sẽ là máy chủ dự phòng. Nếu nó được bật, máy chủ sẽ tiếp tục khôi phục bằng cách tìm nạp các phân đoạn WAL mới khi đến cuối WAL đã lưu trữ.
standby_mode = 'on'Chỉ định một chuỗi kết nối được sử dụng cho máy chủ dự phòng để kết nối với nút chính.
primary_conninfo = 'host=IP_PRIMARY_NODE port=5432 user=replication_user password=PASSWORD'Chỉ định khôi phục vào một dòng thời gian cụ thể. Mặc định là khôi phục cùng dòng thời gian hiện tại khi sao lưu cơ sở được thực hiện. Đặt cài đặt này thành “mới nhất” sẽ khôi phục về dòng thời gian mới nhất được tìm thấy trong kho lưu trữ.
recovery_target_timeline = 'latest'Chỉ định tệp trình kích hoạt có sự hiện diện của nó kết thúc quá trình khôi phục ở chế độ chờ.
trigger_file = '/tmp/failover_5432.trigger'Postgresql.conf
Thay đổi hoặc thêm các tham số sau trong tệp cấu hình postgresql.conf.
Xác định lượng thông tin được ghi vào WAL. Các giá trị có thể là tối thiểu, bản sao hoặc lôgic. Giá trị hot_standby được ánh xạ tới bản sao và nó được sử dụng để giữ tính tương thích với các phiên bản trước. Thay đổi giá trị này yêu cầu khởi động lại dịch vụ.
wal_level = hot_standbyCho phép các truy vấn trong quá trình khôi phục. Thay đổi giá trị này yêu cầu khởi động lại dịch vụ.
hot_standby = onKhởi động Nút chờ
Bây giờ bạn đã có tất cả cấu hình cần thiết, bạn chỉ cần khởi động dịch vụ cơ sở dữ liệu trên nút chờ.
$ systemctl start postgresql-11Và kiểm tra cơ sở dữ liệu đăng nhập / var / lib / pgsql / 11 / data / log /. Bạn nên có một cái gì đó như thế này:
2019-11-18 20:23:57.440 UTC [1131] LOG: entering standby mode
2019-11-18 20:23:57.447 UTC [1131] LOG: redo starts at 0/3000028
2019-11-18 20:23:57.449 UTC [1131] LOG: consistent recovery state reached at 0/30000F8
2019-11-18 20:23:57.449 UTC [1129] LOG: database system is ready to accept read only connections
2019-11-18 20:23:57.457 UTC [1135] LOG: started streaming WAL from primary at 0/4000000 on timeline 1Bạn cũng có thể kiểm tra trạng thái sao chép trong nút chính bằng cách chạy truy vấn sau:
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1467 | replication_user | walreceiver | streaming | async
(1 row)Như bạn có thể thấy, chúng tôi đang sử dụng một bản sao không đồng bộ.
Chuyển đổi bản sao PostgreSQL không đồng bộ thành bản sao đồng bộ
Bây giờ, đã đến lúc chuyển đổi bản sao không đồng bộ này thành bản sao đồng bộ và đối với điều này, bạn sẽ cần phải định cấu hình cả nút chính và nút chờ.
Nút chính
Trong nút chính của PostgreSQL, bạn phải sử dụng cấu hình cơ bản này ngoài cấu hình không đồng bộ trước đó.
Postgresql.conf
Chỉ định danh sách các máy chủ dự phòng có thể hỗ trợ sao chép đồng bộ. Tên máy chủ dự phòng này là cài đặt application_name trong tệp recovery.conf của chế độ chờ.
synchronous_standby_names = 'pgsql_0_node_0'synchronous_standby_names = 'pgsql_0_node_0'Chỉ định liệu cam kết giao dịch có đợi các bản ghi WAL được ghi vào đĩa trước khi lệnh trả về chỉ báo "thành công" cho máy khách hay không. Các giá trị hợp lệ là bật, remote_apply, remote_write, cục bộ và tắt. Giá trị mặc định được bật.
synchronous_commit = onThiết lập Nút chờ
Trong nút chờ PostgreSQL, bạn cần thay đổi tệp recovery.conf bằng cách thêm giá trị 'application_name vào tham số primary_conninfo.
Recovery.conf
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_0_node_0 host=IP_PRIMARY_NODE port=5432 user=replication_user password=PASSWORD'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover_5432.trigger'Khởi động lại dịch vụ cơ sở dữ liệu ở cả nút chính và nút dự phòng:
$ service postgresql-11 restartBây giờ, bạn nên thiết lập và chạy bản sao phát trực tuyến đồng bộ hóa của mình:
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1561 | replication_user | pgsql_0_node_0 | streaming | sync
(1 row)Khôi phục từ Bản sao PostgreSQL Đồng bộ sang Không đồng bộ
Nếu bạn cần quay lại sao chép PostgreSQL không đồng bộ, bạn chỉ cần khôi phục các thay đổi được thực hiện trong tệp postgresql.conf trên nút chính:
Postgresql.conf
#synchronous_standby_names = 'pgsql_0_node_0'
#synchronous_commit = onVà khởi động lại dịch vụ cơ sở dữ liệu.
$ service postgresql-11 restartVì vậy, bây giờ, bạn sẽ có bản sao không đồng bộ một lần nữa.
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1625 | replication_user | pgsql_0_node_0 | streaming | async
(1 row)Cách triển khai Bản sao đồng bộ PostgreSQL bằng ClusterControl
Với ClusterControl, bạn có thể thực hiện tất cả các tác vụ triển khai, cấu hình và giám sát từ cùng một công việc và bạn sẽ có thể quản lý nó từ cùng một giao diện người dùng.
Chúng tôi sẽ giả định rằng bạn đã cài đặt ClusterControl và nó có thể truy cập các nút cơ sở dữ liệu thông qua SSH. Để biết thêm thông tin về cách định cấu hình quyền truy cập ClusterControl, vui lòng tham khảo tài liệu chính thức của chúng tôi.
Đi tới ClusterControl và sử dụng tùy chọn “Triển khai” để tạo một cụm PostgreSQL mới.
Khi chọn PostgreSQL, bạn phải chỉ định Người dùng, Khóa hoặc Mật khẩu và cổng để kết nối bằng SSH với máy chủ của chúng tôi. Bạn cũng cần một tên cho cụm mới của mình và nếu bạn muốn ClusterControl cài đặt phần mềm và cấu hình tương ứng cho bạn.
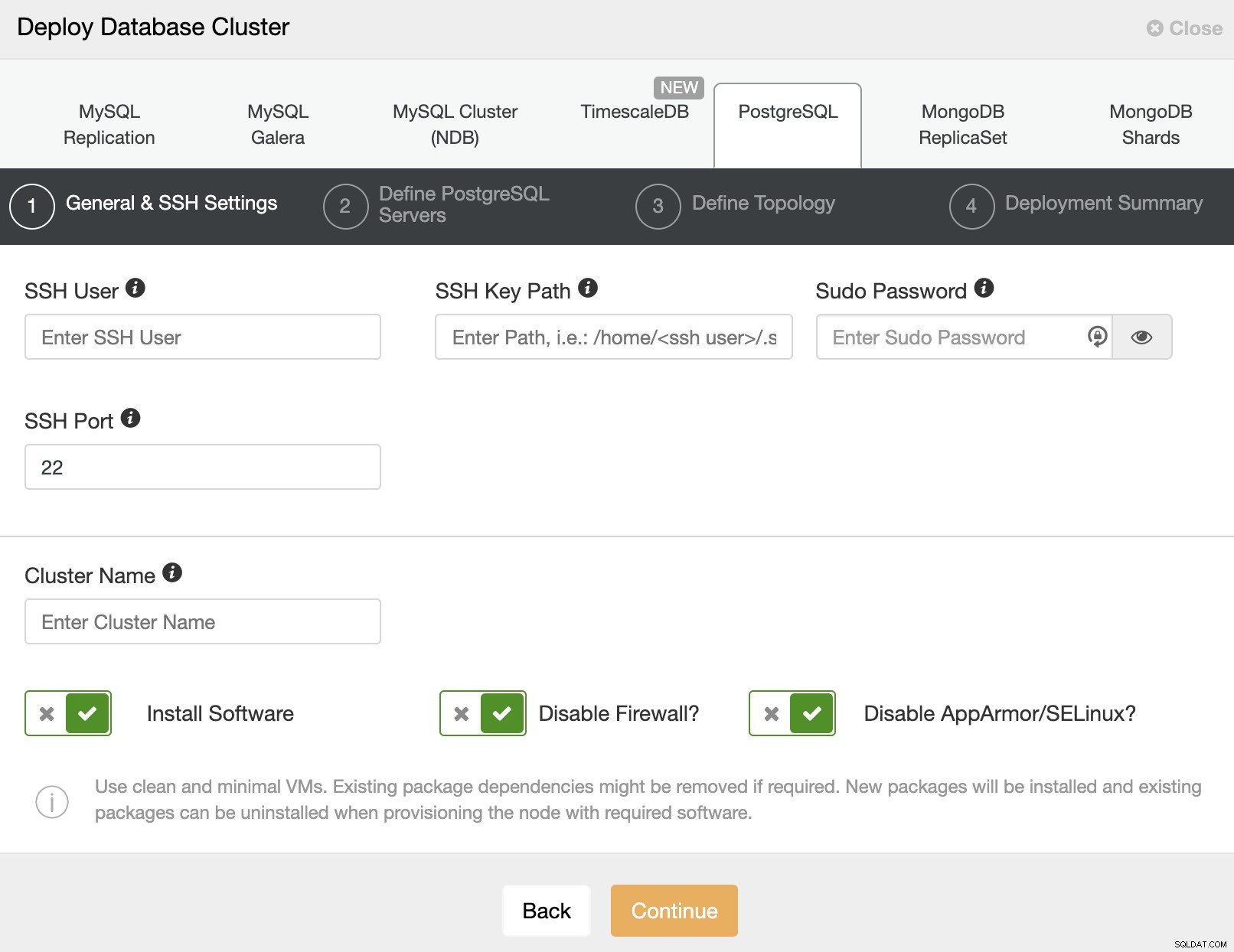
Sau khi thiết lập thông tin truy cập SSH, bạn phải nhập dữ liệu để truy cập cơ sở dữ liệu của bạn. Bạn cũng có thể chỉ định kho lưu trữ nào sẽ sử dụng.
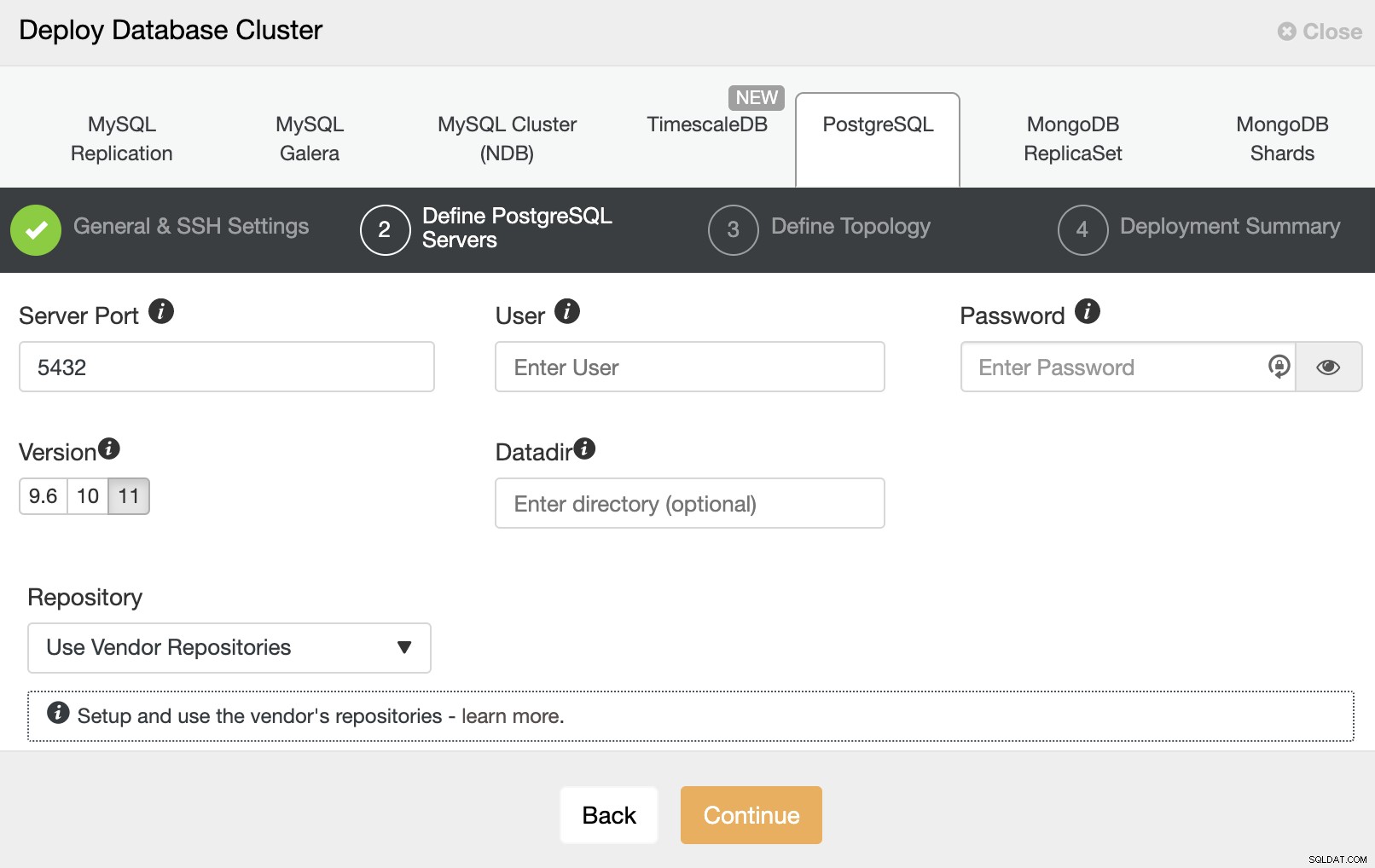
Trong bước tiếp theo, bạn cần thêm máy chủ của mình vào cụm bạn sẽ tạo. Khi thêm máy chủ của mình, bạn có thể nhập IP hoặc tên máy chủ.
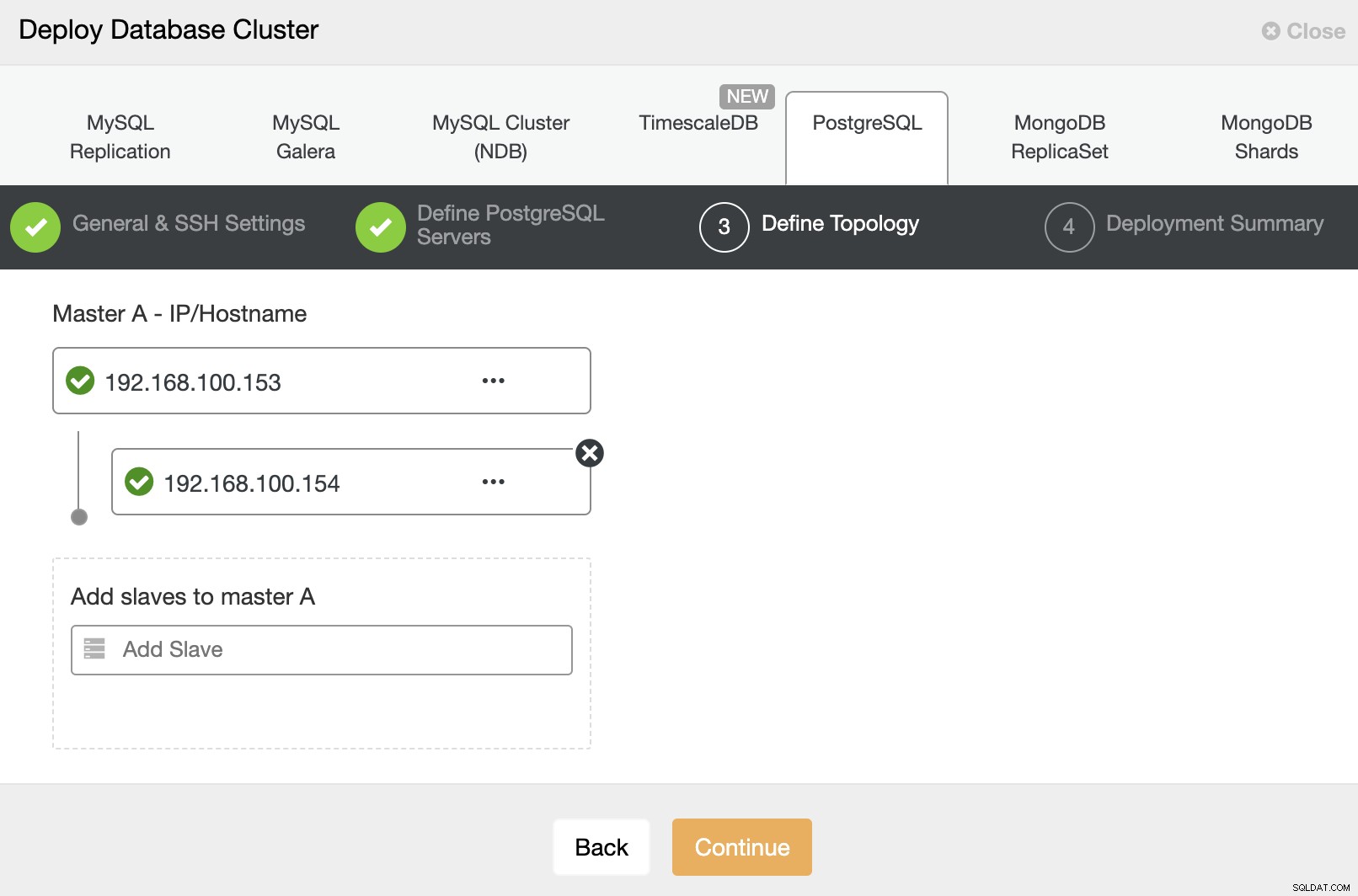
Và cuối cùng, ở bước cuối cùng, bạn có thể chọn phương pháp sao chép, có thể là bản sao không đồng bộ hoặc đồng bộ.
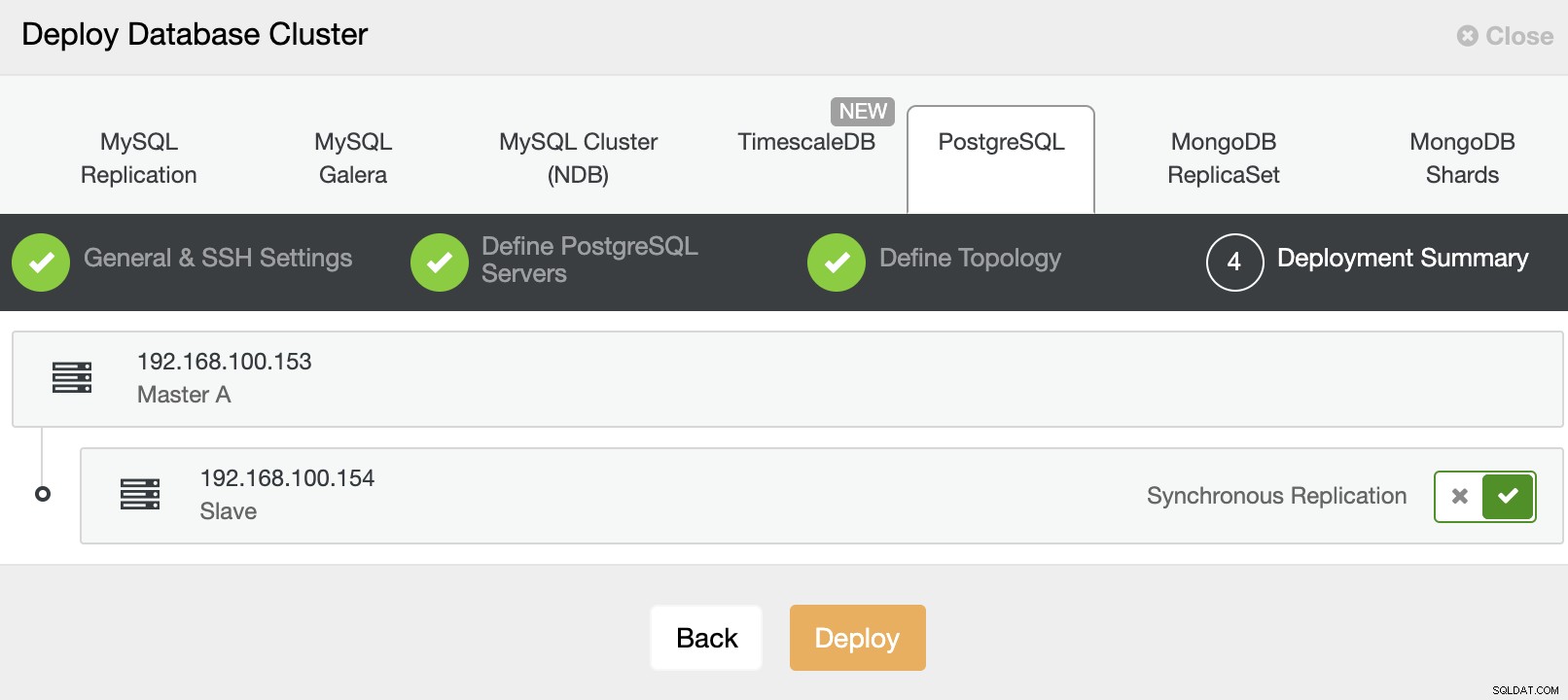
Thế là xong. Bạn có thể theo dõi trạng thái công việc trong phần hoạt động ClusterControl.
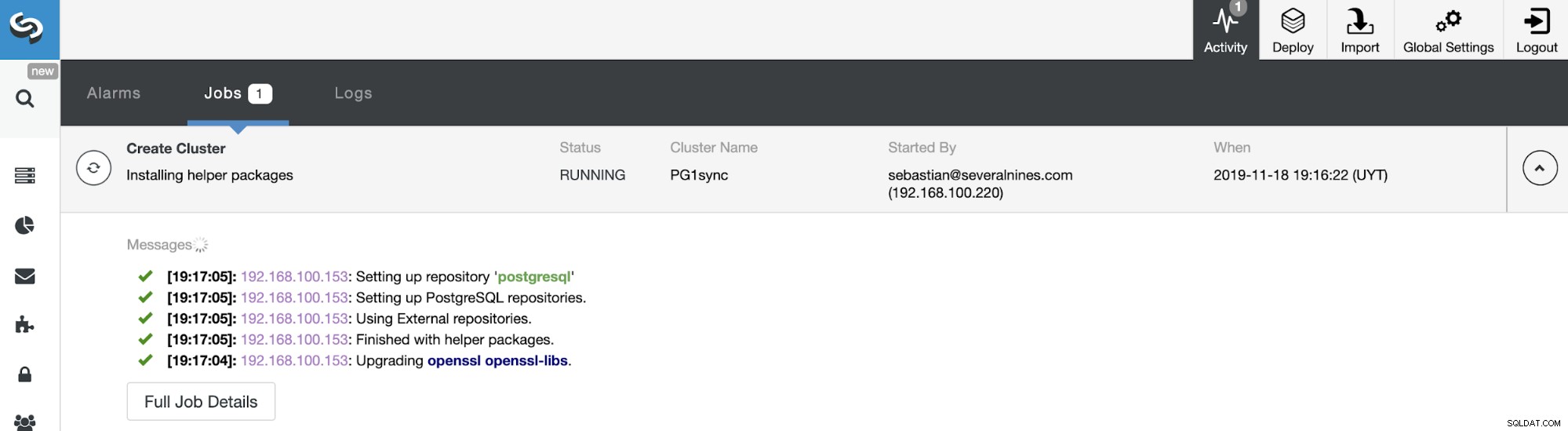
Và khi công việc này kết thúc, bạn sẽ cài đặt cụm đồng bộ PostgreSQL của mình, được cấu hình và giám sát bởi ClusterControl.
Kết luận
Như chúng tôi đã đề cập ở phần đầu của blog này, Tính sẵn sàng cao là yêu cầu đối với tất cả các công ty, vì vậy bạn nên biết các tùy chọn có sẵn để đạt được điều đó cho từng công nghệ đang sử dụng. Đối với PostgreSQL, bạn có thể sử dụng sao chép phát trực tuyến đồng bộ như là cách an toàn nhất để triển khai, nhưng phương pháp này không hoạt động với tất cả các môi trường và khối lượng công việc.
Hãy cẩn thận với độ trễ tạo ra khi chờ xác nhận từng giao dịch có thể là một vấn đề thay vì giải pháp Tính sẵn sàng cao.