Hầu hết khối lượng công việc OLTP liên quan đến việc sử dụng I / O đĩa ngẫu nhiên. Biết rằng đĩa (bao gồm cả SSD) có hiệu suất chậm hơn so với sử dụng RAM, hệ thống cơ sở dữ liệu sử dụng bộ nhớ đệm để tăng hiệu suất. Bộ nhớ đệm là tất cả về việc lưu trữ dữ liệu trong bộ nhớ (RAM) để truy cập nhanh hơn vào thời điểm sau.
PostgreSQL cũng sử dụng bộ nhớ đệm dữ liệu của nó trong một không gian được gọi là shared_buffers. Trong blog này, chúng tôi sẽ khám phá chức năng này để giúp bạn tăng hiệu suất.
Kiến thức cơ bản về bộ nhớ đệm PostgreSQL
Trước khi chúng ta tìm hiểu sâu hơn về khái niệm bộ nhớ đệm, hãy cùng tìm hiểu một số khái niệm cơ bản.
Trong PostgreSQL, dữ liệu được tổ chức dưới dạng các trang có kích thước 8KB và mỗi trang như vậy có thể chứa nhiều bộ dữ liệu (tùy thuộc vào kích thước của bộ dữ liệu). Một biểu diễn đơn giản có thể như sau:
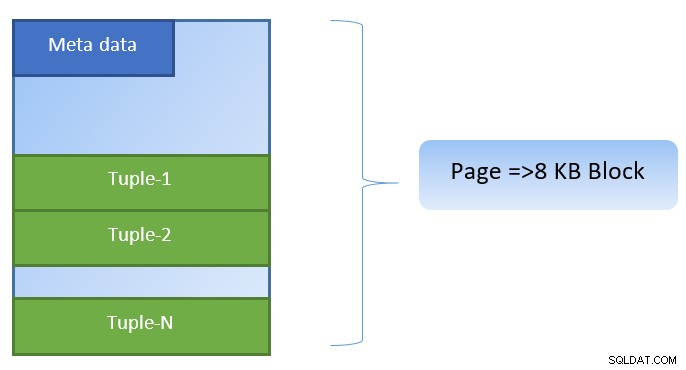
PostgreSQL lưu trữ thông tin sau để tăng tốc truy cập dữ liệu:
- Dữ liệu trong bảng
- Chỉ mục
- Kế hoạch thực thi truy vấn
Trong khi bộ nhớ đệm kế hoạch thực thi truy vấn tập trung vào việc lưu các chu kỳ CPU; Bộ nhớ đệm cho dữ liệu Bảng và dữ liệu Chỉ mục được tập trung để tiết kiệm hoạt động I / O đĩa tốn kém.
PostgreSQL cho phép người dùng xác định dung lượng bộ nhớ họ muốn dự trữ để lưu giữ bộ nhớ đệm như vậy cho dữ liệu. Cài đặt có liên quan là shared_buffers trong tệp cấu hình postgresql.conf. Giá trị hữu hạn của shared_buffers xác định số lượng trang có thể được lưu vào bộ nhớ cache tại bất kỳ thời điểm nào.
Khi một truy vấn được thực thi, PostgreSQL sẽ tìm kiếm trang trên đĩa chứa bộ mã có liên quan và đẩy nó vào bộ đệm shared_buffers để truy cập bên. Lần tới khi cần truy cập cùng một bộ (hoặc bất kỳ bộ nào trong cùng một trang), PostgreSQL có thể lưu IO đĩa bằng cách đọc nó trong bộ nhớ.
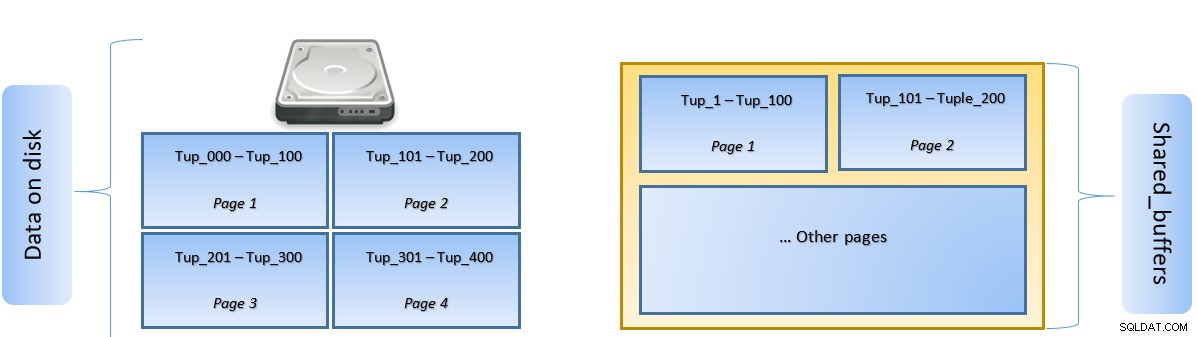
Trong hình trên, Trang-1 và Trang-2 của một số bảng đã được lưu vào bộ nhớ đệm. Trong trường hợp truy vấn của người dùng cần truy cập các bộ giá trị từ Tuple-1 đến Tuple-200, PostgreSQL có thể tìm nạp nó từ chính RAM.
Tuy nhiên, nếu truy vấn cần truy cập Tuples 250 đến 350, nó sẽ cần thực hiện I / O đĩa cho Trang 3 và Trang 4. Bất kỳ truy cập nào khác cho Tuple 201 đến 400 sẽ được tìm nạp từ bộ nhớ cache và I / O đĩa sẽ không cần thiết - do đó làm cho truy vấn nhanh hơn.
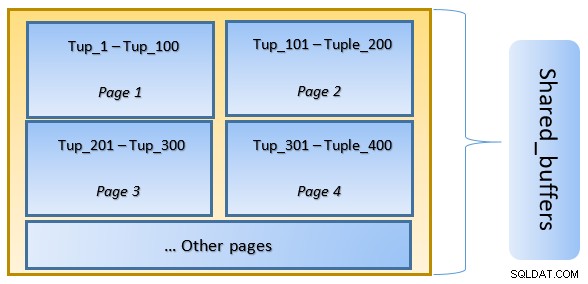
Ở cấp độ cao, PostgreSQL tuân theo thuật toán LRU (ít được sử dụng gần đây nhất) để xác định các trang cần được xóa khỏi bộ nhớ cache. Nói cách khác, một trang chỉ được truy cập một lần có khả năng bị loại bỏ cao hơn (so với một trang được truy cập nhiều lần), trong trường hợp một trang mới cần được PostgreSQL tìm nạp vào bộ nhớ cache.
PostgreSQL Cache đang hoạt động
Hãy thực hiện một ví dụ và xem tác động của bộ nhớ cache đến hiệu suất.
Khởi động PostgreSQL, giữ shared_buffer được đặt thành 128 MB mặc định
$ initdb -D ${HOME}/data
$ echo “shared_buffers=128MB” >> ${HOME}/data/postgresql.conf
$ pg_ctl -D ${HOME}/data startKết nối với máy chủ và tạo bảng giả tblDummy và chỉ mục trên c_id
CREATE Table tblDummy
(
id serial primary key,
p_id int,
c_id int,
entry_time timestamp,
entry_value int,
description varchar(50)
);
CREATE INDEX ON tblDummy(c_id );Điền dữ liệu giả với 200000 bộ giá trị, sao cho có 10000 p_id duy nhất và cứ mỗi p_id thì có 200 c_id
DO $$
DECLARE
random_value integer:= 1;
BEGIN
FOR p_id_ctr IN 1..10000 BY 1 LOOP
FOR c_id_ctr IN 1..200 BY 1 LOOP
random_value = (( random() * 75 ) + 25);
INSERT INTO tblDummy (p_id,c_id,entry_time, entry_value, description )
VALUES (p_id_ctr,c_id_ctr,'now', random_value, CONCAT('Description for :',p_id_ctr, c_id_ctr));
END LOOP ;
END LOOP ;
END $$;Khởi động lại máy chủ để xóa bộ nhớ cache. Bây giờ, hãy thực hiện một truy vấn và kiểm tra thời gian thực hiện tương tự
SELECT pg_stat_reset();
EXPLAIN ANAYZE SELECT count(*) from tbldummy where c_id=1;
QUERY PLAN
--------------------------------------------------------------
Aggregate (cost=17407.33..17407.34 rows=1 width=8) (actual time=160.269..160.269 rows=1 loops=1)
-> Bitmap Heap Scan on tbldummy (cost=189.52..17382.46 rows=9948 width=0) (actual time=10.627..156.275 rows=10000 loops=1)
Recheck Cond: (c_id = 1)
Heap Blocks: exact=10000
-> Bitmap Index Scan on tbldummy_c_id_idx (cost=0.00..187.04 rows=9948 width=0) (actual time=5.091..5.091 rows=10000 loops=1)
Index Cond: (c_id = 1)
Planning Time: 1.325 ms
Execution Time: 160.505 msSau đó, kiểm tra các khối được đọc từ đĩa
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
---------------+---------------
10000 | 0Trong ví dụ trên, có 1000 khối được đọc từ đĩa để tìm các bộ đếm trong đó c_id =1. Phải mất 160 ms kể từ khi có I / O đĩa tham gia để tìm nạp các bản ghi đó từ đĩa.
Việc thực thi sẽ nhanh hơn nếu cùng một truy vấn được thực thi lại, vì tất cả các khối vẫn nằm trong bộ nhớ cache của máy chủ PostgreSQL ở giai đoạn này
SELECT pg_stat_reset();
EXPLAIN ANAYZE SELECT count(*) from tbldummy where c_id=1;
QUERY PLAN
-------------------------------------------------------------------------------------
Aggregate (cost=17407.33..17407.34 rows=1 width=8) (actual time=33.760..33.761 rows=1 loops=1)
-> Bitmap Heap Scan on tbldummy (cost=189.52..17382.46 rows=9948 width=0) (actual time=9.584..30.576 rows=10000 loops=1)
Recheck Cond: (c_id = 1)
Heap Blocks: exact=10000
-> Bitmap Index Scan on tbldummy_c_id_idx (cost=0.00..187.04 rows=9948 width=0) (actual time=4.314..4.314 rows=10000 loops=1)
Index Cond: (c_id = 1)
Planning Time: 0.106 ms
Execution Time: 33.990 msvà khối đọc từ đĩa so với từ bộ nhớ cache
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
---------------+---------------
0 | 10000Ở trên có thể thấy rõ rằng vì tất cả các khối đều được đọc từ bộ nhớ đệm và không cần I / O đĩa. Do đó, điều này cũng cho kết quả nhanh hơn.
Đặt Kích thước của Bộ nhớ đệm PostgreSQL
Kích thước bộ nhớ đệm cần được điều chỉnh trong môi trường sản xuất sao cho phù hợp với dung lượng RAM có sẵn cũng như các truy vấn cần thiết để thực thi.
Ví dụ - shared_buffer 128MB 'có thể không đủ để lưu vào bộ nhớ cache tất cả dữ liệu, nếu truy vấn tìm nạp nhiều bộ dữ liệu hơn:
SELECT pg_stat_reset();
SELECT count(*) from tbldummy where c_id < 150;
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
----------------+---------------
20331 | 288Thay đổi shared_buffer thành 1024MB để tăng heap_blks_hit.
Trên thực tế, khi xem xét các truy vấn (dựa trên c_id), trong trường hợp dữ liệu được sắp xếp lại, tỷ lệ truy cập bộ nhớ cache tốt hơn cũng có thể đạt được với bộ đệm chia sẻ nhỏ hơn.
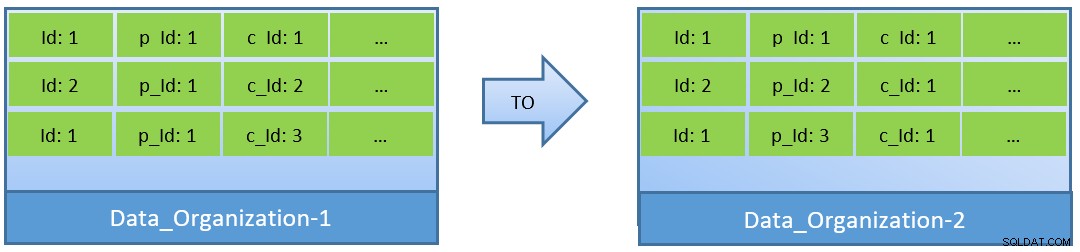
Trong Data_Organization-1, PostgreSQL sẽ cần 1000 lần đọc khối (và mức tiêu thụ bộ nhớ đệm ) để tìm c_id =1. Mặt khác, đối với Data_Organisation-2, đối với cùng một truy vấn, PostgreSQL sẽ chỉ cần 104 khối.
Yêu cầu ít khối hơn cho cùng một truy vấn cuối cùng tiêu thụ ít bộ nhớ cache hơn và cũng giữ cho thời gian thực thi truy vấn được tối ưu hóa.
Kết luận
Trong khi bộ đệm chia sẻ được duy trì ở mức quy trình PostgreSQL, bộ đệm ở mức hạt nhân cũng được xem xét để xác định các kế hoạch thực thi truy vấn được tối ưu hóa. Tôi sẽ đề cập đến chủ đề này trong một loạt blog sau.