Mỗi bản phát hành PostgreSQL đều đi kèm với một số cải tiến về tính năng chính, nhưng điều thú vị không kém là mỗi bản phát hành đều cải thiện các tính năng trước đây của nó.
Vì PostgreSQL 13 dự kiến sẽ sớm được phát hành, đã đến lúc kiểm tra những tính năng và cải tiến mà cộng đồng đang mang lại cho chúng ta. Một trong những cải tiến không gây tiếng ồn như vậy là “Cải tiến sao chép lôgic để phân vùng.”
Hãy hiểu sự cải tiến của tính năng này với một ví dụ đang chạy.
Thuật ngữ
Hai thuật ngữ quan trọng để hiểu tính năng này là:
- Bảng phân vùng
- Bản sao lôgic
Bảng phân vùng
Một cách để chia một bảng lớn thành nhiều phần vật lý để đạt được những lợi ích như:
- Cải thiện hiệu suất truy vấn
- Cập nhật nhanh hơn
- Tải và xóa hàng loạt nhanh hơn
- Sắp xếp dữ liệu hiếm khi được sử dụng trên ổ đĩa chậm
Một số ưu điểm này đạt được bằng cách cắt bớt phân vùng (tức là trình lập kế hoạch truy vấn sử dụng định nghĩa phân vùng để quyết định xem có quét phân vùng hay không) và thực tế là phân vùng khá dễ lắp trong bộ nhớ hữu hạn so với một bảng lớn.
Một bảng được phân vùng dựa trên:
- Danh sách
- Băm
- Phạm vi

Sao chép lôgic
Như tên của nó, đây là một phương pháp sao chép trong đó dữ liệu được sao chép tăng dần dựa trên danh tính của chúng (ví dụ:khóa). Nó không tương tự như WAL hoặc các phương pháp sao chép vật lý nơi dữ liệu được gửi từng byte.
Dựa trên mẫu Nhà xuất bản-Người đăng ký, nguồn dữ liệu cần xác định nhà xuất bản trong khi mục tiêu cần được đăng ký là người đăng ký. Các trường hợp sử dụng thú vị cho điều này là:
- Sao chép có chọn lọc (chỉ một số phần của cơ sở dữ liệu)
- Ghi đồng thời vào hai phiên bản cơ sở dữ liệu nơi dữ liệu đang được sao chép
- Sao chép giữa các hệ điều hành khác nhau (ví dụ:Linux và Windows)
- Bảo mật chi tiết về sao chép dữ liệu
- Kích hoạt thực thi khi dữ liệu đến bên nhận
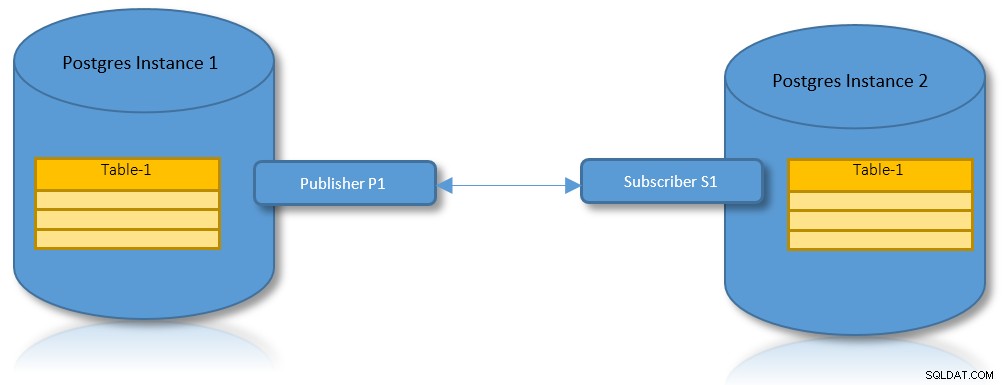
Bản sao lôgic cho các phân vùng
Với những lợi ích của cả sao chép hợp lý và phân vùng, trường hợp sử dụng thực tế là có một kịch bản trong đó một bảng được phân vùng cần được sao chép qua hai phiên bản PostgreSQL.
Sau đây là các bước để thiết lập và làm nổi bật sự cải tiến đang được thực hiện trong PostgreSQL 13 trong bối cảnh này.
Thiết lập
Hãy xem xét thiết lập hai nút để chạy hai phiên bản khác nhau có chứa bảng được phân vùng:
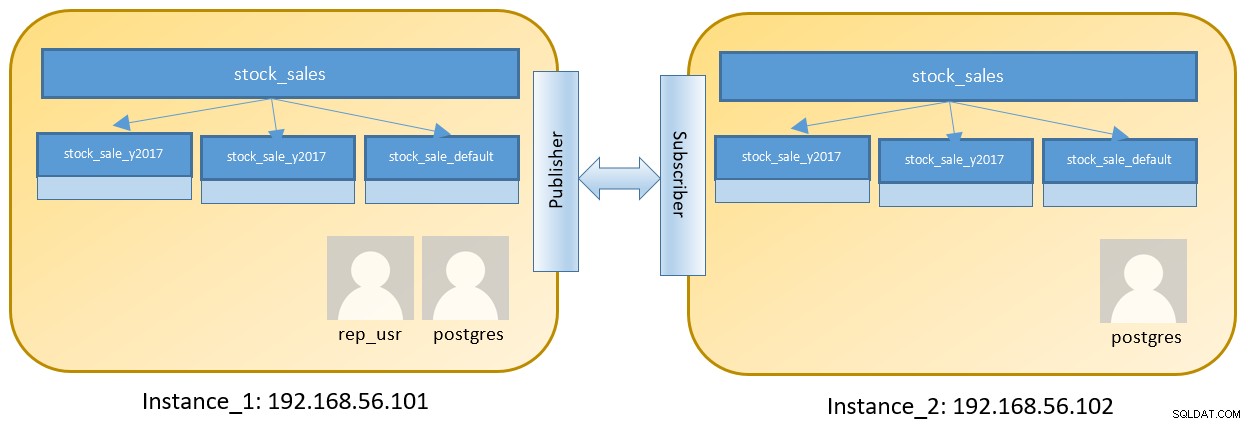
Các bước trên Instance_1 như bên dưới đăng nhập vào 192.168.56.101 với tư cách là người dùng postgres :
$ initdb -D ${HOME}/pgdata-1
$ echo "listen_addresses = '192.168.56.101'" >> ${HOME}/pgdata-1/postgresql.conf
$ echo "wal_level = logical" >> ${HOME}/pgdata-1/postgresql.conf
$ echo "host postgres all 192.168.56.102/32 md5" >> ${HOME}/pgdata-1/pg_hba.conf
$ pg_ctl -D ${HOME}/pgdata-1 -l logfile startCài đặt ‘wal_level’ được đặt riêng thành ‘logic’ để chỉ ra rằng bản sao logic sẽ được sử dụng để sao chép dữ liệu từ trường hợp này. Tệp cấu hình ‘pg_hba.conf’ cũng đã được sửa đổi để cho phép các kết nối từ 192.168.56.102.
# CREATE TABLE stock_sales
( sale_date date not null, unit_sold int, unit_price int )
PARTITION BY RANGE ( sale_date );
# CREATE TABLE stock_sales_y2017 PARTITION OF stock_sales
FOR VALUES FROM ('2017-01-01') TO ('2018-01-01');
# CREATE TABLE stock_sales_y2018 PARTITION OF stock_sales
FOR VALUES FROM ('2018-01-01') TO ('2019-01-01');
# CREATE TABLE stock_sales_default
PARTITION OF stock_sales DEFAULT;Mặc dù vai trò postgres được tạo theo mặc định trên cơ sở dữ liệu Instance_1, người dùng riêng biệt cũng nên được tạo có quyền truy cập hạn chế - chỉ giới hạn phạm vi cho một bảng nhất định.
# CREATE ROLE rep_usr WITH REPLICATION LOGIN PASSWORD 'rep_pwd';
# GRANT CONNECT ON DATABASE postgres TO rep_usr;
# GRANT USAGE ON SCHEMA public TO rep_usr;
# GRANT SELECT ON ALL TABLES IN SCHEMA public to rep_usr;Cần thiết lập gần như tương tự trên Instance_2
$ initdb -D ${HOME}/pgdata-2
$ echo "listen_addresses = '192.168.56.102'" >> ${HOME}/pgdata-2/postgresql.conf
$ pg_ctl -D ${HOME}/pgdata-2 -l logfile startCần lưu ý rằng vì Instance_2 sẽ không phải là nguồn dữ liệu cho bất kỳ nút nào khác, cài đặt wal_level cũng như tệp pg_hba.conf không cần bất kỳ cài đặt bổ sung nào. Không cần phải nói, pg_hba.conf có thể cần cập nhật theo nhu cầu sản xuất.
Logical Replication không hỗ trợ DDL, chúng tôi cũng cần tạo cấu trúc bảng trên Instance_2. Tạo một bảng được phân vùng bằng cách sử dụng tạo phân vùng ở trên để tạo cùng một cấu trúc bảng trên Instance_2.
Thiết lập Bản sao Hợp lý
Thiết lập bản sao lôgic trở nên dễ dàng hơn nhiều với PostgreSQL 13. Cho đến PostgreSQL 12, cấu trúc như sau:
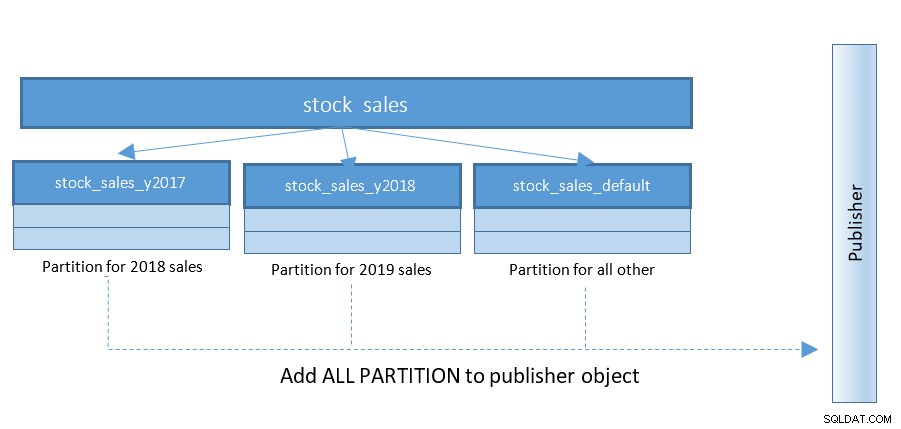
Với PostgreSQL 13, việc xuất bản các phân vùng trở nên dễ dàng hơn nhiều. Tham khảo sơ đồ dưới đây và so sánh với sơ đồ trước:
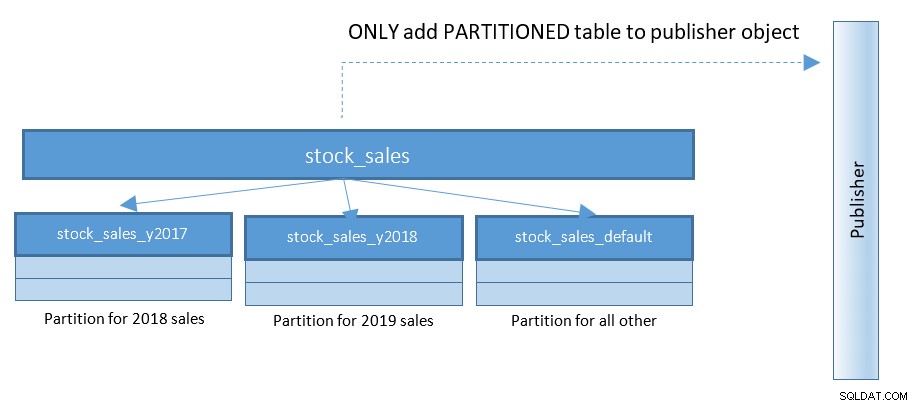
Với thiết lập hoành hành với 100 và 1000 bảng phân vùng - thay đổi nhỏ này đơn giản hóa ở một mức độ lớn.
Trong PostgreSQL 13, các câu lệnh để tạo một ấn phẩm như vậy sẽ là:
CREATE PUBLICATION rep_part_pub FOR TABLE stock_sales
WITH (publish_via_partition_root);Tham số cấu hình Publishing_via_partition_root là tính năng mới trong PostgreSQL 13, cho phép nút người nhận có hệ thống phân cấp lá hơi khác. Chỉ tạo ấn phẩm trên các bảng được phân vùng trong PostgreSQL 12, sẽ trả về các câu lệnh lỗi như sau:
ERROR: "stock_sales" is a partitioned table
DETAIL: Adding partitioned tables to publications is not supported.
HINT: You can add the table partitions individually.Bỏ qua những hạn chế của PostgreSQL 12 và tiếp tục sử dụng tính năng này trên PostgreSQL 13, chúng ta phải thiết lập người đăng ký trên Instance_2 với các câu lệnh sau:
CREATE SUBSCRIPTION rep_part_sub CONNECTION 'host=192.168.56.101 port=5432 user=rep_usr password=rep_pwd dbname=postgres' PUBLICATION rep_part_pub;Kiểm tra xem nó có thực sự hoạt động hay không
Chúng tôi đã hoàn thành khá nhiều việc với toàn bộ thiết lập, nhưng hãy chạy một vài thử nghiệm để xem mọi thứ có hoạt động hay không.
Trên Instance_1, chèn nhiều hàng để đảm bảo rằng chúng sinh ra thành nhiều phân vùng:
# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2017-09-20', 12, 151);# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2018-07-01', 22, 176);
# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2016-02-02', 10, 1721);Kiểm tra dữ liệu trên Instance_2:
# SELECT * from stock_sales;
sale_date | unit_sold | unit_price
------------+-----------+------------
2017-09-20 | 12 | 151
2018-07-01 | 22 | 176
2016-02-02 | 10 | 1721Bây giờ, hãy kiểm tra xem bản sao lôgic có hoạt động hay không ngay cả khi các nút lá không giống nhau ở phía người nhận.
Thêm một phân vùng khác trên Instance_1 và chèn bản ghi:
# CREATE TABLE stock_sales_y2019
PARTITION OF stock_sales
FOR VALUES FROM ('2019-01-01') to ('2020-01-01');
# INSERT INTO stock_sales VALUES(‘2019-06-01’, 73, 174 );Kiểm tra dữ liệu trên Instance_2:
# SELECT * from stock_sales;
sale_date | unit_sold | unit_price
------------+-----------+------------
2017-09-20 | 12 | 151
2018-07-01 | 22 | 176
2016-02-02 | 10 | 1721
2019-06-01 | 73 | 174Các Tính năng Phân vùng Khác trong PostgreSQL 13
Ngoài ra còn có các cải tiến khác trong PostgreSQL 13 liên quan đến phân vùng, cụ thể là:
- Cải tiến trong kết hợp giữa các bảng được phân vùng
- Các bảng được phân vùng hiện hỗ trợ TRƯỚC các trình kích hoạt cấp hàng
Kết luận
Tôi chắc chắn sẽ kiểm tra hai tính năng sắp tới đã nói ở trên trong tập hợp các blog tiếp theo của tôi. Cho đến khi thực phẩm cho suy nghĩ - với sức mạnh tổng hợp của phân vùng và sao chép hợp lý, liệu PostgreSQL có đang tiến gần hơn đến thiết lập tổng thể không?