Phải có nhiều công cụ mạnh để làm tùy chọn sao lưu và khôi phục cho PostgreSQL nói chung; Barman, PgBackRest, BART là một vài cái tên trong bối cảnh này. Điều thu hút sự chú ý của chúng tôi là Barman là một công cụ bắt kịp nhanh với việc triển khai sản xuất và xu hướng thị trường.
Có thể là triển khai dựa trên docker, cần lưu trữ bản sao lưu trong bộ lưu trữ đám mây khác hoặc nhu cầu về kiến trúc khôi phục thảm họa có thể tùy chỉnh cao - Barman là đối thủ rất mạnh trong tất cả các trường hợp như vậy.
Blog này khám phá Barman với một số giả định về việc triển khai, tuy nhiên trong mọi trường hợp, điều này chỉ nên được coi là tập hợp tính năng khả thi. Barman vượt xa những gì chúng ta có thể nắm bắt trong blog này và phải được khám phá thêm nếu xem xét "sao lưu và khôi phục phiên bản PostgreSQL".
Giả định Triển khai DR sẵn sàng
RPO =0 thường phải trả giá - triển khai máy chủ dự phòng đồng bộ thường đáp ứng điều đó, nhưng sau đó nó ảnh hưởng khá thường xuyên đến TPS của máy chủ chính.
Giống như PostgreSQL, Barman cung cấp nhiều tùy chọn triển khai để đáp ứng nhu cầu của bạn khi nói đến RPO so với hiệu suất. Hãy nghĩ về sự đơn giản khi triển khai, RPO =0 hoặc gần như bằng không tác động đến hiệu suất; Barman phù hợp với tất cả.
Chúng tôi đã xem xét việc triển khai sau đây để thiết lập giải pháp khôi phục sau thảm họa cho kiến trúc sao lưu và khôi phục của chúng tôi.
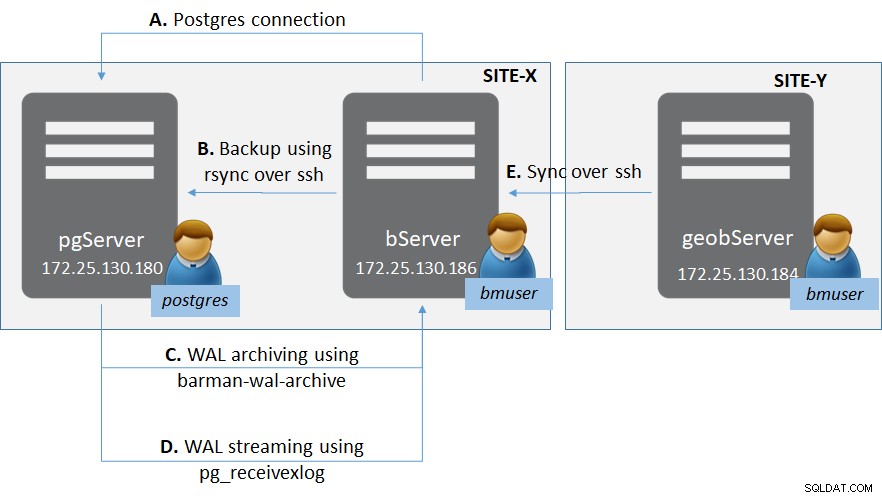 Hình 1:Triển khai PostgreSQL với Barman
Hình 1:Triển khai PostgreSQL với Barman Có hai trang web (nói chung cho các trang web phục hồi sau thảm họa) - Site-X và Site-Y.
Trong Site-X có:
- Một máy chủ ‘pgServer’ lưu trữ phiên bản máy chủ PostgreSQL pgServer và một người dùng hệ điều hành ‘postgres’
- Phiên bản PostgreSQL cũng lưu trữ vai trò siêu người dùng ‘bmuser’
- Một máy chủ ‘bServer’ lưu trữ các tệp nhị phân Barman và một người dùng hệ điều hành ‘bmuser’
Trong Site-Y có:
- Một máy chủ ‘geobServer’ lưu trữ các tệp nhị phân Barman và một người dùng hệ điều hành ‘bmuser’
Có nhiều loại kết nối liên quan đến thiết lập này.
- Giữa ‘bServer’ và ‘pgServer’:
- Kết nối bình diện quản lý từ Barman với Phiên bản PostgreSQL
- rsync kết nối để thực hiện sao lưu cơ sở thực tế từ Barman sang Phiên bản PostgreSQL
- Lưu trữ WAL bằng barman-wal-archive từ Phiên bản PostgreSQL cho Barman
- Truyền trực tuyến WAL bằng pg_receivexlog tại Barman
- Giữa ‘bServer’ và ‘geobserver’:
- Đồng bộ hóa giữa các máy chủ Barman để cung cấp tính năng sao chép địa lý
Khả năng kết nối Đầu tiên
Nhu cầu kết nối chính giữa các máy chủ là thông qua ssh. Để làm cho nó sử dụng các khóa ssh không cần mật khẩu. Hãy thiết lập các khóa ssh và trao đổi chúng.
Trên pgServer:
example@sqldat.com$ ssh-keygen -q -t rsa -N '' -f ~/.ssh/id_rsa <<<y 2>&1 >/dev/null
example@sqldat.com$ ssh-copy-id -i ~/.ssh/id_rsa.pub example@sqldat.com
example@sqldat.com$ ssh example@sqldat.com "chmod 600 ~/.ssh/authorized_keys"Trên bServer:
example@sqldat.com$ ssh-keygen -q -t rsa -N '' -f ~/.ssh/id_rsa <<<y 2>&1 >/dev/null
example@sqldat.com$ ssh-copy-id -i ~/.ssh/id_rsa.pub example@sqldat.com
example@sqldat.com$ ssh example@sqldat.com "chmod 600 ~/.ssh/authorized_keys"Trên geobServer:
example@sqldat.com$ ssh-keygen -q -t rsa -N '' -f ~/.ssh/id_rsa <<<y 2>&1 >/dev/null
example@sqldat.com$ ssh-copy-id -i ~/.ssh/id_rsa.pub example@sqldat.com
example@sqldat.com$ ssh example@sqldat.com "chmod 600 ~/.ssh/authorized_keys"Cấu hình Phiên bản PostgreSQL
Có hai điều chính mà chúng ta cần để tạo lại một thể hiện postgres - Thư mục cơ sở và các bản ghi WAL / Giao dịch được tạo sau đó. Máy chủ Barman theo dõi chúng một cách thông minh. Những gì chúng tôi cần là đảm bảo rằng nguồn cấp dữ liệu thích hợp được tạo ra để Barman thu thập những đồ tạo tác này.
Thêm các dòng sau vào postgresql.conf:
listen_addresses = '172.25.130.180' #as per above deployment assumption
wal_level = replica #or higher
archive_mode = on
archive_command = 'barman-wal-archive -U bmuser bserver pgserver %p'Lệnh lưu trữ đảm bảo rằng khi WAL được lưu trữ bằng phiên bản postgres, tiện ích barman-wal-archive sẽ gửi nó đến Máy chủ Barman. Cần lưu ý rằng gói barman-cli do đó nên được cung cấp trên ‘pgServer’. Có một tùy chọn khác là sử dụng rsync nếu chúng tôi không muốn sử dụng tiện ích barman-wal-archive.
Thêm sau vào pg_hba.conf:
host all all 172.25.130.186/32 md5
host replication all 172.25.130.186/32 md5Về cơ bản, nó cho phép sao chép và kết nối bình thường từ ‘bmserver’ đến phiên bản postgres này.
Bây giờ chỉ cần khởi động lại phiên bản và tạo một vai trò siêu người dùng được gọi là bmuser:
example@sqldat.com$ pg_ctl restart
example@sqldat.com$ createuser -s -P bmuser Nếu được yêu cầu, chúng ta cũng có thể tránh sử dụng bmuser với tư cách là người dùng siêu cấp; sẽ cần các đặc quyền được chỉ định cho người dùng này. Đối với ví dụ trên, chúng tôi cũng sử dụng bmuser làm mật khẩu. Nhưng đó là tất cả, với điều kiện cần phải có cấu hình phiên bản PostgreSQL.
Cấu hình Barman
Barman có ba thành phần cơ bản trong cấu hình của nó:
- Cấu hình chung
- Cấu hình cấp máy chủ
- Người dùng sẽ điều hành barman
Trong trường hợp của chúng tôi, vì Barman được cài đặt bằng rpm, chúng tôi đã lưu trữ các tệp cấu hình chung của mình tại:
/etc/barman.confChúng tôi muốn lưu trữ cấu hình cấp máy chủ trong thư mục chính của bmuser, do đó tệp cấu hình chung của chúng tôi có nội dung sau:
[barman]
barman_user = bmuser
configuration_files_directory = /home/bmuser/barman.d
barman_home = /home/bmuser
barman_lock_directory = /home/bmuser/run
log_file = /home/bmuser/barman.log
log_level = INFOCấu hình Máy chủ Barman Chính
Trong phần triển khai ở trên, chúng tôi quyết định giữ máy chủ Barman chính trong cùng một trung tâm dữ liệu / trang web nơi lưu giữ phiên bản PostgreSQL. Lợi ích của điều tương tự là có ít độ trễ hơn và khôi phục nhanh hơn trong trường hợp cần thiết. Không cần phải nói, nhu cầu về máy tính và / hoặc băng thông mạng ít hơn cũng được yêu cầu trên máy chủ PostgreSQL.
Để Barman quản lý phiên bản PostgreSQL trên pgServer, chúng tôi cần thêm tệp cấu hình (chúng tôi đặt tên là pgserver.conf) với nội dung sau:
[pgserver]
description = "Example pgserver configuration"
ssh_command = ssh example@sqldat.com
conninfo = host=pgserver user=bmuser dbname=postgres
backup_method = rsync
reuse_backup = link
backup_options = concurrent_backup
parallel_jobs = 2
archiver = on
archiver_batch_size = 50
path_prefix = "/usr/pgsql-12/bin"
streaming_conninfo = host=pgserver user=bmuser dbname=postgres
streaming_archiver=on
create_slot = autoVà một tệp .pgpass chứa thông tin đăng nhập cho bmuser trong phiên bản PostgreSQL:
echo 'pgserver:5432:*:bmuser:bmuser' > ~/.pgpass Để hiểu thêm một chút về các mục cấu hình quan trọng:
- ssh_command :Được sử dụng để thiết lập kết nối mà qua đó rsync sẽ được thực hiện
- conninfo :Chuỗi kết nối để cho phép Barman thiết lập kết nối với máy chủ postgres
- reuse_backup :Để cho phép sao lưu gia tăng với ít bộ nhớ hơn
- backup_method :phương pháp sao lưu thư mục cơ sở
- path_prefix :vị trí nơi lưu trữ các tệp nhị phân pg_receivexlog
- streaming_conninfo :Chuỗi kết nối được sử dụng để phát trực tuyến WAL
- create_slot :Để đảm bảo các vị trí được tạo bởi phiên bản postgres
Cấu hình Máy chủ Barman Thụ động
Cấu hình của một trang web sao chép địa lý khá đơn giản. Tất cả những gì nó cần là thông tin kết nối ssh qua đó trang web nút thụ động này sẽ thực hiện việc sao chép.
Điều thú vị là một nút thụ động như vậy có thể hoạt động ở chế độ kết hợp; nói cách khác - chúng có thể hoạt động như các máy chủ Barman đang hoạt động để thực hiện sao lưu cho các trang PostgreSQL và song song hoạt động như một trang sao chép / xếp tầng cho các máy chủ Barman khác.
Vì trong trường hợp của chúng tôi, phiên bản Barman (trên Site-Y) này chỉ cần là một nút thụ động, tất cả những gì chúng tôi cần là tạo tệp /home/bmuser/barman.d/pgserver.conf với cấu hình sau:
[pgserver]
description = "Geo-replication or sync for pgserver"
primary_ssh_command = ssh example@sqldat.comVới giả định rằng các khóa đã được trao đổi và cấu hình toàn cục trên nút này được thực hiện như đã đề cập trước đó - chúng tôi đã hoàn thành khá nhiều việc với cấu hình.
Và đây là lần sao lưu và khôi phục đầu tiên của chúng tôi
Trên máy chủ, đảm bảo rằng quá trình nền để nhận WAL đã được kích hoạt; và sau đó kiểm tra cấu hình của máy chủ:
example@sqldat.com$ barman cron
example@sqldat.com$ barman check pgserverViệc kiểm tra phải đồng ý cho tất cả các bước phụ. Nếu không, hãy tham khảo /home/bmuser/barman.log.
Đưa ra lệnh sao lưu trên Barman để đảm bảo có một DỮ LIỆU cơ sở mà WAL có thể được áp dụng:
example@sqldat.com$ barman backup pgserverTrên ‘geobmserver’, đảm bảo rằng việc sao chép được thực hiện bằng cách thực hiện các lệnh sau:
example@sqldat.com$ barman cron
example@sqldat.com$ barman list-backup pgserverCron phải được chèn vào tệp crontab (nếu không có). Vì đơn giản, tôi không trình bày ở đây. Lệnh cuối cùng sẽ hiển thị rằng thư mục sao lưu cũng đã được tạo trên máy chủ địa lý.
Bây giờ trên phiên bản Postgres, hãy tạo một số dữ liệu giả:
example@sqldat.com$ psql -U postgres -c "CREATE TABLE dummy_data( i INTEGER);"
example@sqldat.com$ psql -U postgres -c "insert into dummy_data values ( generate_series (1, 1000000 ));"Có thể thấy bản sao của WAL từ phiên bản PostgreSQL bằng cách sử dụng lệnh dưới đây:
example@sqldat.com$ psql -U postgres -c "SELECT * from pg_stat_replication ;”Để tạo lại một thể hiện trên Site-Y, trước tiên hãy đảm bảo rằng các bản ghi WAL được chuyển đổi. hoặc ví dụ này, để tạo khôi phục sạch:
example@sqldat.com$ barman switch-xlog --force --archive pgserverTrên Site-X, hãy đưa ra một phiên bản PostgreSQL độc lập để kiểm tra xem sao lưu có tốt không:
example@sqldat.com$ barman cron
barman recover --get-wal pgserver latest /tmp/dataBây giờ, hãy chỉnh sửa các tệp postgresql.conf và postgresql.auto.conf theo nhu cầu. Sau đây giải thích những thay đổi được thực hiện cho ví dụ này:
- postgresql.conf :listening_addresses đã nhận xét để mặc định là localhost
- postgresql.auto.conf :đã xóa sudo bmuser khỏi restore_command
Cung cấp DỮ LIỆU này trong / tmp / data và kiểm tra sự tồn tại của các bản ghi của bạn.
Kết luận
Đây chỉ là phần nổi của một tảng băng trôi. Barman còn sâu hơn thế này vì chức năng mà nó cung cấp - ví dụ:hoạt động như một chế độ chờ đồng bộ, các tập lệnh hook, v.v. Không cần phải nói, tài liệu tổng thể nên được tìm hiểu để định cấu hình nó theo nhu cầu của môi trường sản xuất của bạn.