Chủ đề về bộ nhớ đệm đã xuất hiện trong PostgreSQL cách đây 22 năm và tại thời điểm đó, trọng tâm là độ tin cậy của cơ sở dữ liệu.
Tua nhanh đến năm 2020, các phiến đĩa được ẩn sâu hơn vào các môi trường ảo hóa, bộ siêu giám sát và các thiết bị lưu trữ liên quan. Hơn nữa, các ứng dụng phân tán, được kết nối với nhau hoạt động trên quy mô toàn cầu đang đòi hỏi các kết nối có độ trễ thấp và tất cả các bộ nhớ cache của máy chủ điều chỉnh đột ngột và các truy vấn SQL cạnh tranh với việc đảm bảo kết quả được trả về cho máy khách trong vòng mili giây. Cấp ứng dụng và bộ nhớ đệm trong bộ nhớ được sinh ra và các truy vấn đọc hiện được lưu gần máy chủ ứng dụng. Do đó, các hoạt động I / O được giảm xuống chỉ ghi và độ trễ mạng được cải thiện đáng kể. Với một lần bắt. Việc triển khai chịu trách nhiệm quản lý bộ nhớ cache của riêng chúng, điều này đôi khi dẫn đến giảm hiệu suất.
Việc ghi vào bộ nhớ đệm là một vấn đề phức tạp hơn nhiều, như được giải thích trong wiki PostgreSQL.
Blog này là tổng quan về bộ nhớ đệm truy vấn trong bộ nhớ và bộ cân bằng tải đang được sử dụng với PostgreSQL.
Cân bằng tải PostgreSQL
Ý tưởng về cân bằng tải được nảy sinh cùng lúc với bộ nhớ đệm, vào năm 1999, khi Bruce Momjiam viết:
[...] có khả năng chúng tôi sẽ _very_ phổ biến trong tương lai gần.
Nền tảng để thực hiện cân bằng tải trong PostgreSQL được cung cấp bởi tính năng Hot Standby tích hợp sẵn. Yêu cầu duy nhất là ứng dụng phải xử lý chuyển đổi dự phòng và đây là lúc các giải pháp của bên thứ 3 xuất hiện. Chúng ta sẽ xem xét một số giải pháp đó trong các phần tiếp theo.
Truy vấn cân bằng tải chỉ có thể trả về kết quả nhất quán miễn là độ trễ sao chép đồng bộ được giữ ở mức thấp. Trên thực tế, ngay cả cơ sở hạ tầng mạng hiện đại như AWS cũng có thể có độ trễ hàng chục mili giây:
Chúng tôi thường quan sát thấy thời gian trễ trong 10 giây mili giây. [...] Tuy nhiên, trong các điều kiện điển hình, độ trễ nhân bản dưới một phút là điều phổ biến. [...]
Bản sao giữa các vùng sử dụng sao chép lôgic sẽ bị ảnh hưởng bởi tốc độ thay đổi / áp dụng và sự chậm trễ trong giao tiếp mạng giữa các vùng cụ thể đã chọn. Bản sao xuyên khu vực sử dụng Cơ sở dữ liệu toàn cầu Aurora sẽ có độ trễ điển hình là dưới một giây.
Như đã nêu trước đó, các giải pháp của bên thứ 3 dựa trên các tính năng cốt lõi của PostgreSQL. Ví dụ:cân bằng tải các truy vấn đọc được thực hiện bằng cách sử dụng nhiều standby đồng bộ.
Giải pháp
pgpool-II
pgpool-II là một sản phẩm giàu tính năng cung cấp cả cân bằng tải và bộ nhớ đệm truy vấn trong bộ nhớ. Nó là một thay thế thả vào, không cần thay đổi về phía ứng dụng.
Là một bộ cân bằng tải, pgpool-II kiểm tra từng truy vấn SQL - để được cân bằng tải, các truy vấn SELECT phải đáp ứng một số điều kiện.
Việc thiết lập có thể đơn giản như một nút, được hiển thị bên dưới là một cụm nút kép:
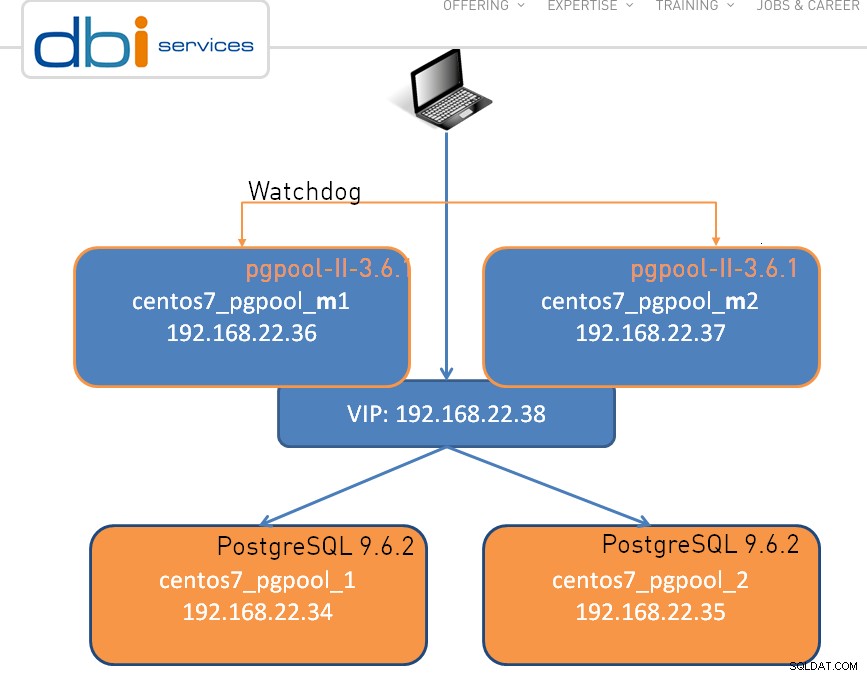
Đối với bất kỳ phần mềm tuyệt vời nào, có một số hạn chế nhất định và pgpool-II cũng không ngoại lệ:
- Nó không xử lý các truy vấn nhiều câu lệnh.
- Truy vấn CHỌN trên các bảng tạm thời yêu cầu nhận xét / * KHÔNG TẢI CÂN BẰNG * / SQL.
Các ứng dụng chạy trong môi trường hiệu suất cao sẽ được hưởng lợi từ cấu hình hỗn hợp trong đó pgBouncer là trình tổng hợp kết nối và pgpool-II xử lý cân bằng tải và bộ nhớ đệm. Kết quả là tăng thông lượng ấn tượng gấp 4 lần và giảm độ trễ 40%:
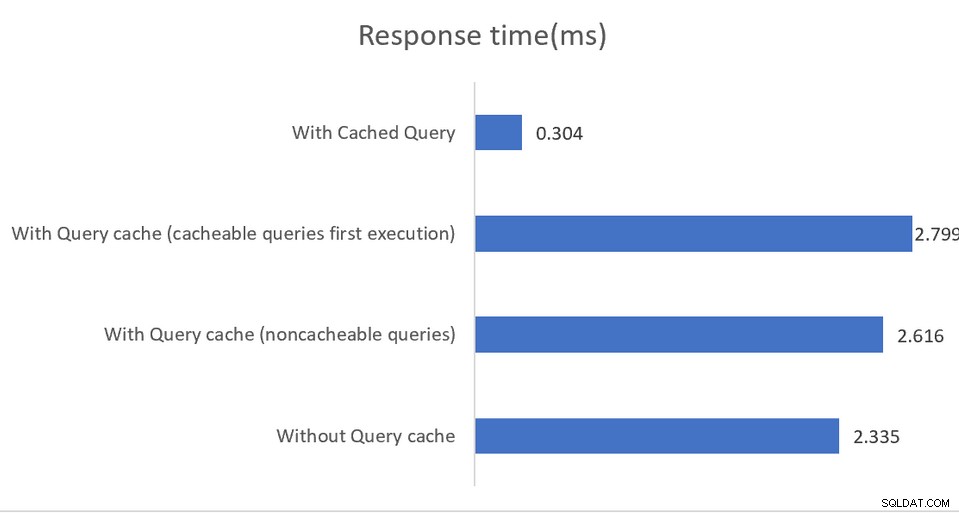
Bộ nhớ đệm trong bộ nhớ hoạt động, một lần nữa, chỉ trên các truy vấn đã đọc, có bộ nhớ đệm dữ liệu được lưu vào bộ nhớ dùng chung hoặc vào cài đặt bộ nhớ đệm bên ngoài. Mặc dù tài liệu này khá tốt trong việc giải thích các tùy chọn cấu hình khác nhau, nhưng nó gián tiếp gợi ý rằng việc triển khai phải giám sát đầu ra SHOW POOL CACHE để cảnh báo về tỷ lệ lần truy cập giảm xuống dưới mốc 70%, tại thời điểm đó, hiệu suất đạt được do bộ nhớ đệm cung cấp sẽ bị mất.
Bucardo
Bucardo là một công cụ sao chép PostgreSQL được viết bằng Perl và PL / Perl.
Tôi đã đề cập đến Bucardo, vì cân bằng tải là một trong những tính năng của nó, theo PostgreSQL wiki, tuy nhiên, một tìm kiếm trên internet không có kết quả phù hợp. Để làm rõ, tôi đi đến tài liệu chính thức đi vào chi tiết về cách phần mềm thực sự hoạt động:

Điều đó làm cho nó khá rõ ràng, Bucardo không phải là một bộ cân bằng tải, giống như đã được chỉ ra bởi những người tại Database Soup.
HAProxy
HAProxy là bộ cân bằng tải mục đích chung hoạt động ở cấp TCP (cho mục đích kết nối cơ sở dữ liệu). Kiểm tra sức khỏe đảm bảo rằng các truy vấn chỉ được gửi đến các nút còn sống.
So với pgpool-II, các ứng dụng sử dụng HAProxy làm bộ cân bằng tải phải được biết về các yêu cầu điều phối điểm cuối tới các nút của trình đọc.
Apache Ignite
Apache Ignite là bộ đệm ẩn cấp hai hiểu ANSI-99 SQL và cung cấp hỗ trợ cho các giao dịch ACID. Apache Ignite không hiểu Giao thức Frontend / Backend PostgreSQL và do đó các ứng dụng phải sử dụng một lớp bền vững như Hibernate ORM. Để thay thế cho việc sửa đổi ứng dụng, Apache Ignite cung cấp `` tích hợp memcached`_ yêu cầu phần mở rộng PostgreSQL memcached. Rất tiếc, tùy chọn thứ hai này không tương thích với các phiên bản gần đây của PostgreSQL, vì phần mở rộng pgmemcache được cập nhật lần cuối vào năm 2017.
Dữ liệu Heimdall
Là một sản phẩm thương mại, Heimdall Data kiểm tra cả hai hộp:cân bằng tải và bộ nhớ đệm. Đây là một sản phẩm trưởng thành, đã được giới thiệu tại các hội nghị PostgreSQL kể từ PGCon 2017:

Bạn có thể tìm thấy thêm chi tiết và bản demo sản phẩm trên blog Azure for PostgreSQL .
Kết luận
Trong máy tính phân tán ngày nay, Bộ nhớ đệm Truy vấn và Cân bằng Tải cũng quan trọng đối với việc điều chỉnh hiệu suất PostgreSQL cũng như GUC nổi tiếng, nhân hệ điều hành, lưu trữ và tối ưu hóa truy vấn. Mặc dù pgpool-II và Heimdall Data là mã nguồn mở và tương ứng là các giải pháp thương mại được ưa chuộng, nhưng có những trường hợp các công cụ được tạo ra có chủ đích có thể được sử dụng làm khối xây dựng để đạt được kết quả tương tự.