Mặc dù có nhiều cách khác nhau để khôi phục cơ sở dữ liệu PostgreSQL của bạn, nhưng một trong những cách tiếp cận thuận tiện nhất để khôi phục dữ liệu của bạn từ một bản sao lưu hợp lý. Các bản sao lưu logic đóng một vai trò quan trọng đối với Lập kế hoạch Thảm họa và Phục hồi (DRP). Sao lưu lôgic là các bản sao lưu được thực hiện, ví dụ như sử dụng pg_dump hoặc pg_dumpall, tạo ra các câu lệnh SQL để lấy tất cả dữ liệu bảng được ghi vào tệp nhị phân.
Bạn cũng nên chạy các bản sao lưu lôgic định kỳ trong trường hợp các bản sao lưu vật lý của bạn bị lỗi hoặc không khả dụng. Đối với PostgreSQL, việc khôi phục có thể gặp vấn đề nếu bạn không chắc chắn về những công cụ nào sẽ sử dụng. Công cụ sao lưu pg_dump thường được ghép nối với công cụ khôi phục pg_restore.
pg_dump và pg_restore hoạt động song song nếu thảm họa xảy ra và bạn cần khôi phục dữ liệu của mình. Mặc dù chúng phục vụ mục đích chính là kết xuất và khôi phục, nhưng nó yêu cầu bạn thực hiện một số tác vụ bổ sung khi bạn cần khôi phục cụm của mình và thực hiện chuyển đổi dự phòng (nếu chính hoặc chủ đang hoạt động của bạn chết do lỗi phần cứng hoặc lỗi hệ thống VM). Cuối cùng, bạn sẽ tìm và sử dụng các công cụ của bên thứ ba có thể xử lý chuyển đổi dự phòng hoặc khôi phục cụm tự động.
Trong blog này, chúng ta sẽ xem xét cách pg_restore hoạt động và so sánh nó với cách ClusterControl xử lý sao lưu và khôi phục dữ liệu của bạn trong trường hợp thảm họa xảy ra.
Cơ chế của pg_restore
pg_restore hữu ích khi thực hiện các tác vụ sau:
- được ghép nối với pg_dump để tạo tệp do SQL tạo chứa dữ liệu, vai trò truy cập, định nghĩa cơ sở dữ liệu và bảng
- khôi phục cơ sở dữ liệu PostgreSQL từ kho lưu trữ do pg_dump tạo ở một trong các định dạng không phải văn bản thuần túy.
- Nó sẽ đưa ra các lệnh cần thiết để xây dựng lại cơ sở dữ liệu về trạng thái tại thời điểm nó được lưu.
- có khả năng chọn lọc hoặc thậm chí sắp xếp lại thứ tự các mục trước khi được khôi phục dựa trên tệp lưu trữ
- Các tệp lưu trữ được thiết kế để có thể di động qua các kiến trúc.
- pg_restore có thể hoạt động ở hai chế độ.
- Nếu tên cơ sở dữ liệu được chỉ định, pg_restore sẽ kết nối với cơ sở dữ liệu đó và khôi phục nội dung lưu trữ trực tiếp vào cơ sở dữ liệu.
- hoặc, một tập lệnh chứa các lệnh SQL cần thiết để xây dựng lại cơ sở dữ liệu được tạo và ghi vào tệp hoặc đầu ra chuẩn. Đầu ra tập lệnh của nó tương đương với định dạng do pg_dump tạo ra
- Do đó, một số tùy chọn kiểm soát đầu ra tương tự như các tùy chọn pg_dump.
Khi bạn đã khôi phục dữ liệu, tốt nhất bạn nên chạy ANALYZE trên mỗi bảng được khôi phục để trình tối ưu hóa có số liệu thống kê hữu ích. Mặc dù nó có được READ LOCK, bạn có thể phải chạy nó trong thời gian lưu lượng truy cập thấp hoặc trong thời gian bảo trì của bạn.
Ưu điểm của pg_restore
pg_dump và pg_restore song song có các khả năng thuận tiện cho DBA sử dụng.
- pg_dump và pg_restore có khả năng chạy song song bằng cách chỉ định tùy chọn -j. Sử dụng -j / - job
cho phép bạn chỉ định số lượng công việc đang chạy song song có thể chạy, đặc biệt là để tải dữ liệu, tạo chỉ mục hoặc tạo ràng buộc bằng nhiều công việc đồng thời. - Sử dụng yên tĩnh, bạn có thể kết xuất hoặc tải một cách chọn lọc cơ sở dữ liệu hoặc bảng cụ thể
- Nó cho phép và cung cấp cho người dùng tính linh hoạt trên cơ sở dữ liệu, lược đồ cụ thể nào hoặc sắp xếp lại thứ tự các thủ tục sẽ được thực thi dựa trên danh sách. Bạn thậm chí có thể tạo và tải chuỗi SQL một cách lỏng lẻo như ngăn chặn acls hoặc đặc quyền phù hợp với nhu cầu của bạn. Có rất nhiều lựa chọn phù hợp với nhu cầu của bạn.
- Nó cung cấp cho bạn khả năng tạo các tệp SQL giống như pg_dump từ một kho lưu trữ. Điều này rất thuận tiện nếu bạn muốn tải vào cơ sở dữ liệu hoặc máy chủ lưu trữ khác để cung cấp một môi trường riêng biệt.
- Nó dễ hiểu dựa trên chuỗi các thủ tục SQL đã tạo.
- Đây là một cách thuận tiện để tải dữ liệu trong môi trường nhân bản. Bạn không cần phải khôi phục lại bản sao của mình vì các câu lệnh là SQL được sao chép xuống các nút chờ và khôi phục.
Hạn chế của pg_restore
Đối với các bản sao lưu logic, những hạn chế rõ ràng của pg_restore cùng với pg_dump là hiệu suất và tốc độ khi sử dụng các công cụ. Nó có thể hữu ích khi bạn muốn cung cấp môi trường cơ sở dữ liệu thử nghiệm hoặc phát triển và tải dữ liệu của mình, nhưng nó không áp dụng được khi tập dữ liệu của bạn lớn. PostgreSQL phải kết xuất dữ liệu của bạn từng cái một hoặc thực thi và áp dụng dữ liệu của bạn một cách tuần tự bởi cơ sở dữ liệu. Mặc dù bạn có thể làm cho điều này linh hoạt một cách lỏng lẻo để tăng tốc độ như chỉ định -j hoặc sử dụng --single-transaction để tránh ảnh hưởng đến cơ sở dữ liệu của mình, việc tải bằng SQL vẫn phải được phân tích cú pháp bởi công cụ.
Ngoài ra, tài liệu PostgreSQL nêu rõ các hạn chế sau, với các bổ sung của chúng tôi khi chúng tôi quan sát thấy các công cụ này (pg_dump và pg_restore):
- Khi khôi phục dữ liệu vào bảng có sẵn và tùy chọn --disable-trigger được sử dụng, pg_restore sẽ phát lệnh để tắt trình kích hoạt trên bảng của người dùng trước khi chèn dữ liệu, sau đó phát lệnh để bật lại chúng sau khi dữ liệu đã được chèn. Nếu quá trình khôi phục bị dừng giữa chừng, danh mục hệ thống có thể ở trạng thái sai.
- pg_restore không thể khôi phục các đối tượng lớn một cách chọn lọc; ví dụ, chỉ những cái cho một bảng cụ thể. Nếu một kho lưu trữ chứa các đối tượng lớn thì tất cả các đối tượng lớn sẽ được khôi phục hoặc không có đối tượng nào trong số chúng nếu chúng bị loại trừ thông qua -L, -t hoặc các tùy chọn khác.
- Cả hai công cụ này đều được mong đợi tạo ra một lượng lớn kích thước (tệp, thư mục hoặc kho lưu trữ tar), đặc biệt là cho một cơ sở dữ liệu khổng lồ.
- Đối với pg_dump, khi kết xuất một bảng hoặc dưới dạng văn bản thuần túy, pg_dump không xử lý các đối tượng lớn. Các đối tượng lớn phải được kết xuất với toàn bộ cơ sở dữ liệu bằng một trong các định dạng lưu trữ không phải văn bản.
- Nếu bạn có các bản lưu trữ tar được tạo bởi các công cụ này, hãy lưu ý rằng các bản lưu trữ tar được giới hạn ở kích thước nhỏ hơn 8 GB. Đây là một hạn chế cố hữu của định dạng tệp tar. Do đó, không thể sử dụng định dạng này nếu biểu diễn dạng văn bản của bảng vượt quá kích thước đó. Tổng kích thước của kho lưu trữ tar và bất kỳ định dạng đầu ra nào khác không bị giới hạn, ngoại trừ có thể do hệ điều hành.
Sử dụng pg_restore
Sử dụng pg_restore khá tiện dụng và dễ sử dụng. Vì nó được ghép nối song song với pg_dump, nên cả hai công cụ này đều hoạt động tốt miễn là đầu ra mục tiêu phù hợp với công cụ kia. Ví dụ:pg_dump sau sẽ không hữu ích cho pg_restore,
[example@sqldat.com ~]# pg_dump --format=p --create -U dbapgadmin -W -d paultest -f plain.sql
Password: Kết quả này sẽ tương thích với psql trông giống như sau:
[example@sqldat.com ~]# less plain.sql
--
-- PostgreSQL database dump
--
-- Dumped from database version 12.2
-- Dumped by pg_dump version 12.2
SET statement_timeout = 0;
SET lock_timeout = 0;
SET idle_in_transaction_session_timeout = 0;
SET client_encoding = 'UTF8';
SET standard_conforming_strings = on;
SELECT pg_catalog.set_config('search_path', '', false);
SET check_function_bodies = false;
SET xmloption = content;
SET client_min_messages = warning;
SET row_security = off;
--
-- Name: paultest; Type: DATABASE; Schema: -; Owner: postgres
--
CREATE DATABASE paultest WITH TEMPLATE = template0 ENCODING = 'UTF8' LC_COLLATE = 'en_US.UTF-8' LC_CTYPE = 'en_US.UTF-8';
ALTER DATABASE paultest OWNER TO postgres;Nhưng điều này sẽ không thành công đối với pg_restore vì không có định dạng rõ ràng để theo dõi:
[example@sqldat.com ~]# pg_restore -U dbapgadmin --format=p -C -W -d postgres plain.sql
pg_restore: error: unrecognized archive format "p"; please specify "c", "d", or "t"
[example@sqldat.com ~]# pg_restore -U dbapgadmin --format=c -C -W -d postgres plain.sql
pg_restore: error: did not find magic string in file headerBây giờ, hãy chuyển sang các thuật ngữ hữu ích hơn cho pg_restore.
pg_restore:Thả và khôi phục
Hãy xem xét một cách sử dụng đơn giản của pg_restore mà bạn đã đánh rơi cơ sở dữ liệu, ví dụ:
postgres=# drop database maxtest;
DROP DATABASE
postgres=# \l+
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
-----------+----------+----------+-------------+-------------+-----------------------+---------+------------+--------------------------------------------
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 83 MB | pg_default |
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 8209 kB | pg_default | default administrative connection database
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +| 8049 kB | pg_default | unmodifiable empty database
| | | | | postgres=CTc/postgres | | |
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | postgres=CTc/postgres+| 8193 kB | pg_default | default template for new databases
| | | | | =c/postgres | | |
(4 rows)Khôi phục bằng pg_restore rất đơn giản,
[example@sqldat.com ~]# sudo -iu postgres pg_restore -C -d postgres /opt/pg-files/dump/f.dump -C / - create ở đây trạng thái tạo cơ sở dữ liệu khi nó gặp trong tiêu đề. -D postgres trỏ đến cơ sở dữ liệu postgres nhưng nó không có nghĩa là nó sẽ tạo các bảng cho cơ sở dữ liệu postgres. Nó yêu cầu rằng cơ sở dữ liệu phải tồn tại. Nếu -C không được chỉ định, (các) bảng và bản ghi sẽ được lưu trữ vào cơ sở dữ liệu đó được tham chiếu với đối số -d.
Khôi phục có chọn lọc theo bảng
Khôi phục bảng với pg_restore rất dễ dàng và đơn giản. Ví dụ, bạn có hai bảng là bảng "b" và "d". Giả sử bạn chạy lệnh pg_dump sau đây,
[example@sqldat.com ~]# pg_dump --format=d --create -U dbapgadmin -W -d paultest -f pgdump_inserts
Password:Trong đó nội dung của thư mục này sẽ giống như sau,
[example@sqldat.com ~]# ls -alth pgdump_inserts/
total 16M
-rw-r--r--. 1 root root 14M May 15 20:27 3696.dat.gz
drwx------. 2 root root 59 May 15 20:27 .
-rw-r--r--. 1 root root 2.5M May 15 20:27 3694.dat.gz
-rw-r--r--. 1 root root 4.0K May 15 20:27 toc.dat
dr-xr-x---. 5 root root 275 May 15 20:27 ..Nếu bạn muốn khôi phục một bảng (cụ thể là "d" trong ví dụ này),
[example@sqldat.com ~]# pg_restore -U postgres -Fd -d paultest -t d pgdump_inserts/Sẽ có,
paultest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | d | table | postgres | 51 MB |
(1 row)pg_restore:Sao chép các Bảng Cơ sở dữ liệu sang Cơ sở dữ liệu Khác
Bạn thậm chí có thể sao chép nội dung của cơ sở dữ liệu hiện có của mình và đưa nó vào cơ sở dữ liệu đích của bạn. Ví dụ:tôi có các cơ sở dữ liệu sau,
paultest=# \l+ (paultest|maxtest)
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
----------+----------+----------+-------------+-------------+-------------------+---------+------------+-------------
maxtest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 84 MB | pg_default |
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 8273 kB | pg_default |
(2 rows)Cơ sở dữ liệu paultest là một cơ sở dữ liệu trống trong khi chúng tôi sẽ sao chép những gì bên trong cơ sở dữ liệu maxtest,
maxtest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | d | table | postgres | 51 MB |
(1 row)
maxtest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | b | table | postgres | 69 MB |
public | d | table | postgres | 51 MB |
(2 rows)Để sao chép nó, chúng ta cần kết xuất dữ liệu từ cơ sở dữ liệu maxtest như sau,
[example@sqldat.com ~]# pg_dump --format=t --create -U dbapgadmin -W -d maxtest -f pgdump_data.tar
Password: Sau đó tải hoặc khôi phục nó như sau,
Bây giờ, chúng tôi đã có dữ liệu trên cơ sở dữ liệu paultest và các bảng đã được lưu trữ tương ứng.
postgres=# \l+ (paultest|maxtest)
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
----------+----------+----------+-------------+-------------+-------------------+--------+------------+-------------
maxtest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 153 MB | pg_default |
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 154 MB | pg_default |
(2 rows)
paultest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | b | table | postgres | 69 MB |
public | d | table | postgres | 51 MB |
(2 rows)Tạo tệp SQL bằng cách sắp xếp lại
Tôi đã thấy rất nhiều cách sử dụng với pg_restore nhưng có vẻ như tính năng này không thường được giới thiệu. Tôi thấy cách tiếp cận này rất thú vị vì nó cho phép bạn đặt hàng dựa trên những gì bạn không muốn đưa vào và sau đó tạo tệp SQL từ thứ tự bạn muốn tiếp tục.
Ví dụ:chúng ta sẽ sử dụng pgdump_data.tar mẫu mà chúng ta đã tạo trước đó và tạo một danh sách. Để thực hiện việc này, hãy chạy lệnh sau:
[example@sqldat.com ~]# pg_restore -l pgdump_data.tar > my.listThao tác này sẽ tạo một tệp như hình dưới đây:
[example@sqldat.com ~]# cat my.list
;
; Archive created at 2020-05-15 20:48:24 UTC
; dbname: maxtest
; TOC Entries: 13
; Compression: 0
; Dump Version: 1.14-0
; Format: TAR
; Integer: 4 bytes
; Offset: 8 bytes
; Dumped from database version: 12.2
; Dumped by pg_dump version: 12.2
;
;
; Selected TOC Entries:
;
204; 1259 24811 TABLE public b postgres
202; 1259 24757 TABLE public d postgres
203; 1259 24760 SEQUENCE public d_id_seq postgres
3698; 0 0 SEQUENCE OWNED BY public d_id_seq postgres
3560; 2604 24762 DEFAULT public d id postgres
3691; 0 24811 TABLE DATA public b postgres
3689; 0 24757 TABLE DATA public d postgres
3699; 0 0 SEQUENCE SET public d_id_seq postgres
3562; 2606 24764 CONSTRAINT public d d_pkey postgresBây giờ, hãy sắp xếp lại thứ tự hoặc chúng ta sẽ nói rằng tôi đã loại bỏ việc tạo SEQUENCE và cả việc tạo ràng buộc. Điều này sẽ giống như sau,
TL;DR
...
;203; 1259 24760 SEQUENCE public d_id_seq postgres
;3698; 0 0 SEQUENCE OWNED BY public d_id_seq postgres
TL;DR
….
;3562; 2606 24764 CONSTRAINT public d d_pkey postgresĐể tạo tệp ở định dạng SQL, chỉ cần thực hiện như sau:
[example@sqldat.com ~]# pg_restore -L my.list --file /tmp/selective_data.out pgdump_data.tar Bây giờ, tệp /tmp/selective_data.out sẽ là tệp do SQL tạo và tệp này có thể đọc được nếu bạn sử dụng psql chứ không phải pg_restore. Điều tuyệt vời về điều này là bạn có thể tạo tệp SQL phù hợp với mẫu của mình, trên đó dữ liệu chỉ có thể được khôi phục từ kho lưu trữ hiện có hoặc bản sao lưu được thực hiện bằng pg_dump với sự trợ giúp của pg_restore.
Khôi phục PostgreSQL bằng ClusterControl
ClusterControl không sử dụng pg_restore hoặc pg_dump như một phần của bộ tính năng của nó. Chúng tôi sử dụng pg_dumpall để tạo các bản sao lưu hợp lý và thật không may, đầu ra không tương thích với pg_restore.
Có một số cách khác để tạo bản sao lưu trong PostgreSQL như được thấy bên dưới.
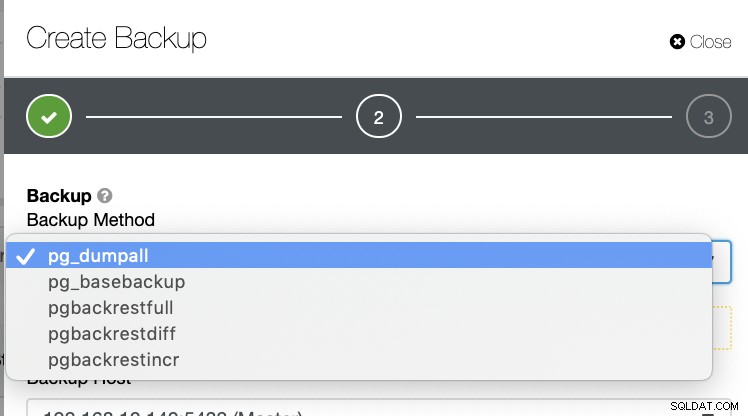
Không có cơ chế nào như vậy mà bạn có thể lưu trữ một cách có chọn lọc một bảng, một cơ sở dữ liệu, hoặc sao chép từ cơ sở dữ liệu này sang cơ sở dữ liệu khác.
ClusterControl hỗ trợ Point-in-Time Recovery (PITR), nhưng điều này không cho phép bạn quản lý việc khôi phục dữ liệu linh hoạt như với pg_restore. Đối với tất cả danh sách các phương pháp sao lưu, chỉ pg_basebackup và pgbackrest là có khả năng PITR.
Cách ClusterControl xử lý khôi phục là nó có khả năng khôi phục một cụm bị lỗi miễn là Tự động khôi phục được bật như hình dưới đây.

Sau khi chủ bị lỗi, máy chủ có thể tự động khôi phục cụm khi ClusterControl thực hiện chuyển đổi dự phòng (được thực hiện tự động). Đối với phần khôi phục dữ liệu, lựa chọn duy nhất của bạn là khôi phục toàn bộ cụm có nghĩa là nó đến từ một bản sao lưu đầy đủ. Không có khả năng khôi phục có chọn lọc trên cơ sở dữ liệu mục tiêu hoặc bảng mà bạn chỉ muốn khôi phục. Nếu bạn muốn làm điều đó, hãy khôi phục bản sao lưu đầy đủ, thật dễ dàng để thực hiện điều này với ClusterControl. Bạn có thể chuyển đến các tab Sao lưu như được hiển thị bên dưới,
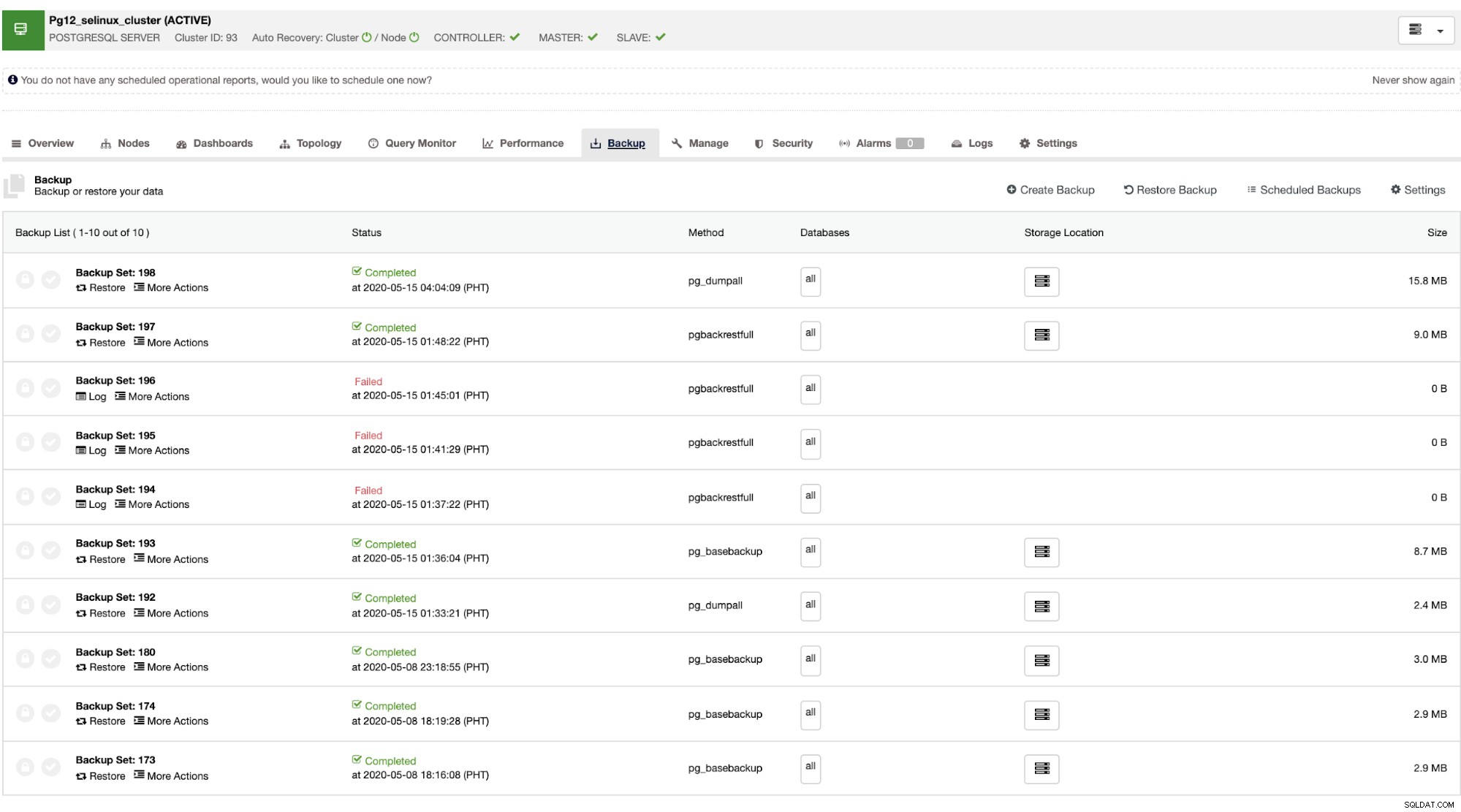
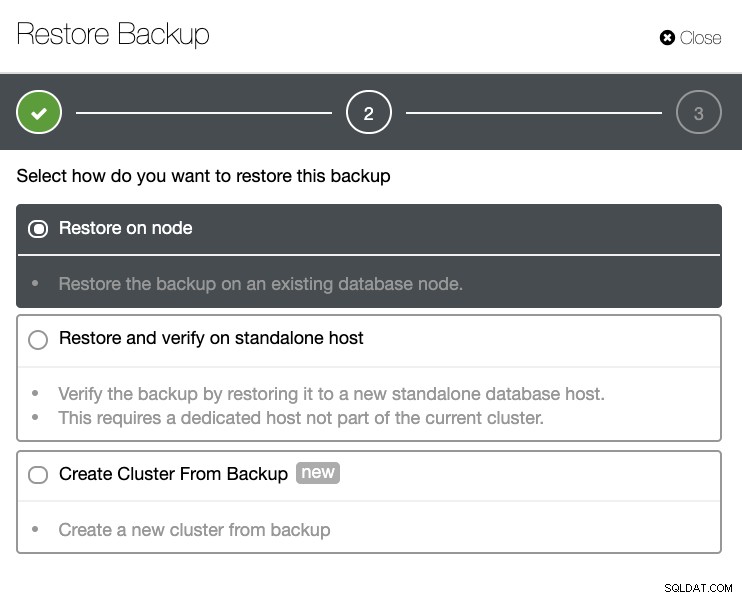
Bạn sẽ có danh sách đầy đủ các bản sao lưu thành công và thất bại. Sau đó, khôi phục nó có thể được thực hiện bằng cách chọn bản sao lưu mục tiêu và nhấp vào nút "Khôi phục". Điều này sẽ cho phép bạn khôi phục trên một nút hiện có được đăng ký trong ClusterControl hoặc xác minh trên một nút độc lập hoặc tạo một cụm từ bản sao lưu.
Kết luận
Sử dụng pg_dump và pg_restore đơn giản hóa phương pháp sao lưu / kết xuất và khôi phục. Tuy nhiên, đối với một môi trường cơ sở dữ liệu quy mô lớn, đây có thể không phải là một thành phần lý tưởng để khôi phục thảm họa. Để có quy trình lựa chọn và khôi phục tối thiểu, việc sử dụng kết hợp pg_dump và pg_restore cung cấp cho bạn sức mạnh để kết xuất và tải dữ liệu theo nhu cầu của bạn.
Đối với môi trường sản xuất (đặc biệt là đối với kiến trúc doanh nghiệp), bạn có thể sử dụng phương pháp ClusterControl để tạo bản sao lưu và khôi phục với tính năng khôi phục tự động.
Kết hợp các phương pháp tiếp cận cũng là một cách tiếp cận tốt. Điều này giúp bạn giảm RTO và RPO, đồng thời tận dụng cách linh hoạt nhất để khôi phục dữ liệu của bạn khi cần.