Được đăng lần đầu tại Serverless vào ngày 2 tháng 7 năm 2019

Để hiển thị một cơ sở dữ liệu đơn giản thông qua API GraphQL yêu cầu rất nhiều mã tùy chỉnh và cơ sở hạ tầng:đúng hay sai?
Đối với những người đã trả lời là “true”, chúng tôi ở đây để cho bạn thấy rằng việc xây dựng các API GraphQL thực sự khá dễ dàng, với một số ví dụ cụ thể để minh họa lý do và cách thức.
(Nếu bạn đã biết việc xây dựng các API GraphQL với Serverless dễ dàng như thế nào, thì cũng có rất nhiều điều cho bạn trong bài viết này.)
GraphQL là một ngôn ngữ truy vấn cho các API web. Có sự khác biệt chính giữa API REST thông thường và các API dựa trên GraphQL:với GraphQL, bạn có thể sử dụng một yêu cầu duy nhất để tìm nạp nhiều thực thể cùng một lúc. Điều này dẫn đến tải trang nhanh hơn và tạo cấu trúc đơn giản hơn cho các ứng dụng giao diện người dùng của bạn, dẫn đến trải nghiệm web tốt hơn cho mọi người. Nếu bạn chưa bao giờ sử dụng GraphQL trước đây, chúng tôi khuyên bạn nên xem hướng dẫn GraphQL này để có phần giới thiệu nhanh.
Khuôn khổ Serverless rất phù hợp cho các API GraphQL:với Serverless, bạn không cần phải lo lắng về việc chạy, quản lý và mở rộng các máy chủ API của riêng mình trên đám mây và bạn sẽ không cần viết bất kỳ tập lệnh tự động hóa cơ sở hạ tầng nào. Tìm hiểu thêm về Serverless tại đây. Ngoài ra, Serverless cung cấp trải nghiệm tuyệt vời dành cho nhà phát triển không phân biệt nhà cung cấp và một cộng đồng mạnh mẽ để giúp bạn xây dựng các ứng dụng GraphQL của mình.
Nhiều ứng dụng trong trải nghiệm hàng ngày của chúng tôi có chứa các tính năng mạng xã hội và loại chức năng đó thực sự có thể được hưởng lợi từ việc triển khai GraphQL thay vì mô hình REST, trong đó khó có thể hiển thị cấu trúc với các thực thể lồng nhau, như người dùng và các bài đăng trên Twitter của họ. Với GraphQL, bạn có thể xây dựng một điểm cuối API thống nhất cho phép bạn truy vấn, viết và chỉnh sửa tất cả các thực thể bạn cần bằng cách sử dụng một yêu cầu API.
Trong bài viết này, chúng ta sẽ xem xét cách tạo một API GraphQL đơn giản với sự trợ giúp của Serverless framework, Node.js và bất kỳ giải pháp cơ sở dữ liệu lưu trữ nào có sẵn thông qua Amazon RDS:MySQL, PostgreSQL và MySQL workalike Amazon Aurora.
Hãy theo dõi kho lưu trữ ví dụ này trên GitHub và chúng ta hãy đi sâu vào!
Xây dựng API GraphQL với phụ trợ DB quan hệ
Trong dự án ví dụ của chúng tôi, chúng tôi quyết định sử dụng cả ba cơ sở dữ liệu (MySQL, PostgreSQL và Aurora) trong cùng một cơ sở mã. Chúng tôi biết, đó là mức quá mức cần thiết ngay cả đối với một ứng dụng sản xuất, nhưng chúng tôi muốn đánh bại bạn bằng cách chúng tôi xây dựng quy mô web. 😉
Nhưng nghiêm túc mà nói, chúng tôi đã tăng quá mức dự án chỉ để đảm bảo rằng bạn sẽ tìm thấy một ví dụ có liên quan áp dụng cho cơ sở dữ liệu yêu thích của mình. Nếu bạn muốn xem các ví dụ về cơ sở dữ liệu khác, vui lòng cho chúng tôi biết trong phần nhận xét.
Xác định lược đồ GraphQL
Hãy bắt đầu bằng cách xác định lược đồ của API GraphQL mà chúng tôi muốn tạo, mà chúng tôi thực hiện trong tệp schema.gql ở gốc của dự án bằng cách sử dụng cú pháp GraphQL. Nếu bạn không quen với cú pháp này, hãy xem các ví dụ trên trang tài liệu GraphQL này.
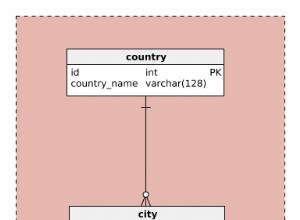
Đối với người mới bắt đầu, chúng tôi thêm hai mục đầu tiên vào giản đồ:thực thể Người dùng và thực thể Bài đăng, xác định chúng như sau để mỗi Người dùng có thể có nhiều thực thể Bài đăng được liên kết với nó:
nhập Người dùng {
UUID:Chuỗi
Tên:Chuỗi
Bài đăng:[Bài đăng]
}
gõ Bài đăng {
UUID:Chuỗi
Văn bản:Chuỗi
}
Bây giờ chúng ta có thể thấy các thực thể Người dùng và Bài đăng trông như thế nào. Sau đó, chúng tôi sẽ đảm bảo rằng các trường này có thể được lưu trữ trực tiếp trong cơ sở dữ liệu của chúng tôi.
Tiếp theo, hãy xác định cách người dùng API sẽ truy vấn các thực thể này. Mặc dù chúng ta có thể sử dụng hai loại GraphQL Người dùng và Người đăng trực tiếp trong các truy vấn GraphQL của mình, nhưng cách tốt nhất là tạo các loại đầu vào để giữ cho giản đồ đơn giản. Vì vậy, chúng tôi tiếp tục và thêm hai trong số các loại đầu vào này, một cho các bài đăng và một cho người dùng:
nhập UserInput {
Tên:Chuỗi
Bài đăng:[PostInput]
}
đầu vào PostInput {
Văn bản:Chuỗi
}
Bây giờ chúng ta hãy xác định các đột biến-các hoạt động sửa đổi dữ liệu được lưu trữ trong cơ sở dữ liệu của chúng tôi thông qua API GraphQL của chúng tôi. Đối với điều này, chúng tôi tạo một loại đột biến. Sự đột biến duy nhất mà chúng tôi sẽ sử dụng lúc này là createUser. Vì chúng tôi đang sử dụng ba cơ sở dữ liệu khác nhau, chúng tôi thêm một đột biến cho mỗi loại cơ sở dữ liệu. Mỗi đột biến chấp nhận UserInput đầu vào và trả về một thực thể Người dùng:
Chúng tôi cũng muốn cung cấp một cách để truy vấn người dùng, vì vậy chúng tôi tạo một loại Truy vấn với một truy vấn cho mỗi loại cơ sở dữ liệu. Mỗi truy vấn chấp nhận một Chuỗi là UUID của người dùng, trả về thực thể Người dùng có chứa tên, UUID và tập hợp của mọi vị trí được liên kết '' t:
Cuối cùng, chúng tôi xác định lược đồ và trỏ đến các loại Truy vấn và Đột biến:
schema { query: Query mutation: Mutation }
Bây giờ chúng tôi có mô tả đầy đủ cho API GraphQL mới của chúng tôi! Bạn có thể xem toàn bộ tệp tại đây.
Xác định trình xử lý cho API GraphQL
Bây giờ chúng tôi đã có mô tả về API GraphQL của mình, chúng tôi có thể viết mã chúng tôi cần cho mỗi truy vấn và đột biến. Chúng tôi bắt đầu bằng cách tạo tệp handler.js trong thư mục gốc của dự án, ngay bên cạnh tệp schema.gql mà chúng tôi đã tạo trước đó.
Công việc đầu tiên của handler.js là đọc lược đồ:
Hằng số typeDefs hiện giữ các định nghĩa cho các thực thể GraphQL của chúng tôi. Tiếp theo, chúng tôi chỉ định nơi mã cho các chức năng của chúng tôi sẽ hoạt động. Để giữ mọi thứ rõ ràng, chúng tôi sẽ tạo một tệp riêng cho từng truy vấn và đột biến:
Hằng số phân giải hiện giữ các định nghĩa cho tất cả các chức năng API của chúng tôi. Bước tiếp theo của chúng tôi là tạo máy chủ GraphQL. Bạn có nhớ thư viện graphql-yoga mà chúng tôi yêu cầu ở trên không? Chúng tôi sẽ sử dụng thư viện đó ở đây để tạo một máy chủ GraphQL đang hoạt động một cách dễ dàng và nhanh chóng:
Cuối cùng, chúng tôi xuất trình xử lý GraphQL cùng với trình xử lý GraphQL Playground (sẽ cho phép chúng tôi dùng thử API GraphQL của mình trong trình duyệt web):
Được rồi, bây giờ chúng ta đã hoàn tất với tệp handler.js. Tiếp theo:viết mã cho tất cả các chức năng truy cập cơ sở dữ liệu.
Viết mã cho các truy vấn và các đột biến
Bây giờ chúng tôi cần mã để truy cập cơ sở dữ liệu và cấp nguồn cho API GraphQL của chúng tôi. Trong thư mục gốc của dự án của chúng tôi, chúng tôi tạo cấu trúc sau cho các hàm trình phân giải MySQL của chúng tôi, với các cơ sở dữ liệu khác để tuân theo:
Truy vấn phổ biến
Trong thư mục Common, chúng tôi điền vào tệp mysql.js những gì chúng tôi cần cho đột biến createUser và truy vấn getUser:một truy vấn init, để tạo bảng cho Người dùng và Bài đăng nếu chúng chưa tồn tại; và truy vấn của người dùng, để trả về dữ liệu của người dùng khi tạo và truy vấn cho người dùng. Chúng tôi sẽ sử dụng điều này trong cả đột biến và truy vấn.
Truy vấn init tạo cả bảng Người dùng và bảng Bài đăng như sau:
Truy vấn getUser trả về người dùng và các bài đăng của họ:
Cả hai chức năng này đều được xuất; sau đó chúng ta có thể truy cập chúng trong tệp handler.js.
Viết đột biến
Đã đến lúc viết mã cho đột biến createUser, cần phải chấp nhận tên của người dùng mới, cũng như danh sách tất cả các bài đăng thuộc về họ. Để thực hiện việc này, chúng tôi tạo tệp giải quyết / Mutation / mysql_createUser.js với một hàm func được xuất duy nhất cho đột biến:
Cơ năng đột biến cần thực hiện những việc sau, theo thứ tự:
-
Kết nối với cơ sở dữ liệu bằng thông tin đăng nhập trong các biến môi trường của ứng dụng.
-
Chèn người dùng vào cơ sở dữ liệu bằng tên người dùng, được cung cấp làm đầu vào cho đột biến.
-
Đồng thời chèn bất kỳ bài đăng nào được liên kết với người dùng, được cung cấp làm đầu vào cho đột biến.
-
Trả lại dữ liệu người dùng đã tạo.
Đây là cách chúng tôi thực hiện điều đó trong mã:
Bạn có thể xem toàn bộ tệp xác định đột biến tại đây.
Viết truy vấn
Truy vấn getUser có cấu trúc tương tự như đột biến mà chúng tôi vừa viết, nhưng điều này thậm chí còn đơn giản hơn. Bây giờ, hàm getUser nằm trong Không gian tên chung, chúng tôi không cần bất kỳ SQL tùy chỉnh nào trong truy vấn nữa. Vì vậy, chúng tôi tạo tệp giải quyết / Query / mysql_getUser.js như sau:
Bạn có thể xem toàn bộ truy vấn trong tệp này.
Tập hợp mọi thứ lại với nhau trong tệp serverless.yml
Hãy lùi lại một bước. Chúng tôi hiện có những thứ sau:
-
Một lược đồ API GraphQL.
-
Tệp handler.js.
-
Một tệp cho các truy vấn cơ sở dữ liệu phổ biến.
-
Một tệp cho mỗi đột biến và truy vấn.
Bước cuối cùng là kết nối tất cả những điều này với nhau thông qua tệp serverless.yml. Chúng tôi tạo một serverless.yml trống ở gốc của dự án và bắt đầu bằng cách xác định nhà cung cấp, khu vực và thời gian chạy. Chúng tôi cũng áp dụng vai trò LambdaRole IAM (mà chúng tôi định nghĩa sau ở đây) cho dự án của chúng tôi:
Sau đó, chúng tôi xác định các biến môi trường cho thông tin đăng nhập cơ sở dữ liệu:
Lưu ý rằng tất cả các biến đều tham chiếu đến phần tùy chỉnh, phần tiếp theo và giữ các giá trị thực tế cho các biến. Lưu ý rằng mật khẩu là một mật khẩu khủng khiếp cho cơ sở dữ liệu của bạn và nên được thay đổi thành một thứ gì đó an toàn hơn (có lẽ là p @ ssw0rd 😃):
Bạn hỏi những tham chiếu đó sau Fn ::GettAtt là gì? Những người đó đề cập đến tài nguyên cơ sở dữ liệu:
Tệp resource / MySqlRDSInstance.yml xác định tất cả các thuộc tính của phiên bản MySQL. Bạn có thể tìm thấy nội dung đầy đủ của nó ở đây.
Cuối cùng, trong tệp serverless.yml, chúng tôi xác định hai hàm, graphql và sân chơi. Hàm graphql sẽ xử lý tất cả các yêu cầu API và điểm cuối của sân chơi sẽ tạo một phiên bản của GraphQL Playground cho chúng tôi, đây là một cách tuyệt vời để thử API GraphQL của chúng tôi trong trình duyệt web:
Bây giờ hỗ trợ MySQL cho ứng dụng của chúng tôi đã hoàn tất!
Bạn có thể tìm thấy toàn bộ nội dung của tệp serverless.yml tại đây.
Thêm hỗ trợ Aurora và PostgreSQL
Chúng tôi đã tạo tất cả cấu trúc cần thiết để hỗ trợ các cơ sở dữ liệu khác trong dự án này. Để thêm hỗ trợ cho Aurora và Postgres, chúng tôi chỉ cần xác định mã cho các đột biến và truy vấn của chúng, chúng tôi thực hiện như sau:
-
Thêm tệp truy vấn chung cho Aurora và cho Postgres.
-
Thêm đột biến createUser cho cả hai cơ sở dữ liệu.
-
Thêm truy vấn getUser cho cả hai cơ sở dữ liệu.
-
Thêm cấu hình trong tệp serverless.yml cho tất cả các biến môi trường và tài nguyên cần thiết cho cả hai cơ sở dữ liệu.
Tại thời điểm này, chúng tôi có mọi thứ cần thiết để triển khai API GraphQL, được cung cấp bởi MySQL, Aurora và PostgreSQL.
Triển khai và thử nghiệm API GraphQL
Việc triển khai API GraphQL của chúng tôi rất đơn giản.
-
Đầu tiên, chúng tôi chạy cài đặt npm để đặt các phụ thuộc của chúng tôi vào đúng vị trí.
-
Sau đó, chúng tôi chạy triển khai npm run, thiết lập tất cả các biến môi trường của chúng tôi và thực hiện triển khai.
-
Bên dưới, lệnh này chạy triển khai không máy chủ bằng cách sử dụng môi trường phù hợp.
Đó là nó! Trong đầu ra của bước triển khai, chúng tôi sẽ thấy điểm cuối URL cho ứng dụng đã triển khai của chúng tôi. Chúng tôi có thể đưa ra các yêu cầu ĐĂNG tới API GraphQL của chúng tôi bằng cách sử dụng URL này và Sân chơi của chúng tôi (mà chúng tôi sẽ phát trong giây lát) có sẵn bằng cách sử dụng GET đối với cùng một URL.
Dùng thử API trong Sân chơi GraphQL
Sân chơi GraphQL, là thứ bạn thấy khi truy cập URL đó trong trình duyệt, là một cách tuyệt vời để thử API của chúng tôi.
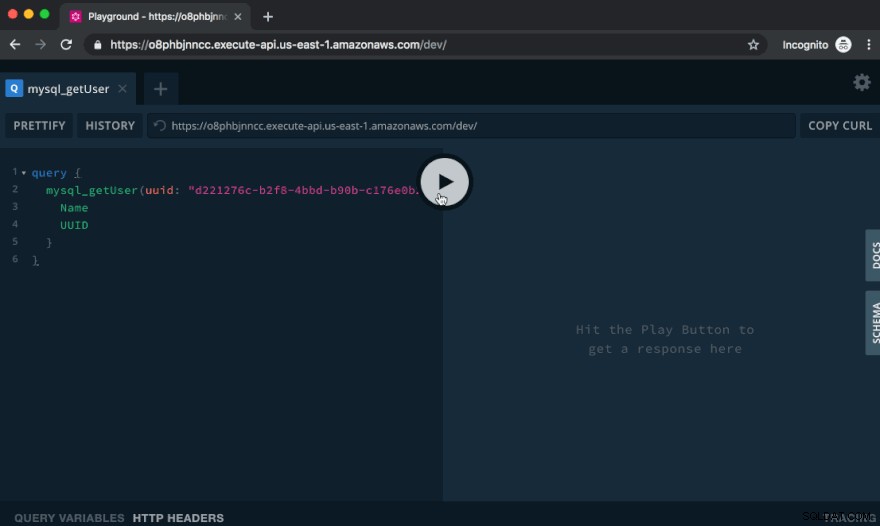
Hãy tạo người dùng bằng cách chạy đột biến sau:
mutation { mysql_createUser( input: { Name: "Cicero" Posts: [ { Text: "Lorem ipsum dolor sit amet, consectetur adipiscing elit." } { Text: "Proin consequat mauris orci, ut consequat purus efficitur vel." } ] } ) { Name UUID } }
Trong đột biến này, chúng tôi gọi là API mysql_createUser, cung cấp văn bản của các bài đăng của người dùng mới và cho biết rằng chúng tôi muốn lấy lại tên của người dùng và UUID làm phản hồi.
Dán văn bản trên vào phía bên trái của Playground và nhấp vào nút Play. Ở bên phải, bạn sẽ thấy đầu ra của truy vấn:
Bây giờ, hãy truy vấn cho người dùng này:
query { mysql_getUser(uuid: "f5593682-6bf1-466a-967d-98c7e9da844b") { Name UUID } }
Điều này trả lại cho chúng tôi tên và UUID của người dùng mà chúng tôi vừa tạo. Gọn gàng!
Chúng ta có thể làm điều tương tự với các phụ trợ khác, PostgreSQL và Aurora. Để làm được điều đó, chúng ta chỉ cần thay thế tên của đột biến bằng postgres_createUser hoặc aurora_createUser và truy vấn bằng postgres_getUser hoặc aurora_getUser. Hãy thử nó cho mình! (Hãy nhớ rằng người dùng không được đồng bộ hóa giữa các cơ sở dữ liệu, vì vậy bạn sẽ chỉ có thể truy vấn những người dùng mà bạn đã tạo trong từng cơ sở dữ liệu cụ thể.)
So sánh triển khai MySQL, PostgreSQL và Aurora
Để bắt đầu, các đột biến và truy vấn trông giống hệt nhau trên Aurora và MySQL, vì Aurora tương thích với MySQL. Và chỉ có sự khác biệt mã tối thiểu giữa hai mã đó và việc triển khai Postgres.
Trên thực tế, đối với các trường hợp sử dụng đơn giản, sự khác biệt lớn nhất giữa ba cơ sở dữ liệu của chúng tôi là Aurora chỉ có sẵn dưới dạng một cụm. Cấu hình Aurora nhỏ nhất hiện có vẫn bao gồm một bản sao chỉ đọc và một bản ghi, vì vậy chúng tôi cần một cấu hình theo nhóm ngay cả khi triển khai Aurora cơ bản này.
Aurora cung cấp hiệu suất nhanh hơn MySQL và PostgreSQL, chủ yếu là do tối ưu hóa SSD mà Amazon thực hiện cho công cụ cơ sở dữ liệu. Khi dự án của bạn phát triển, bạn có thể sẽ thấy rằng Aurora cung cấp khả năng mở rộng cơ sở dữ liệu được cải thiện, bảo trì dễ dàng hơn và độ tin cậy tốt hơn so với cấu hình MySQL và PostgreSQL mặc định. Nhưng bạn cũng có thể thực hiện một số cải tiến này trên MySQL và PostgreSQL nếu bạn điều chỉnh cơ sở dữ liệu của mình và thêm bản sao.
Đối với các dự án và sân chơi thử nghiệm, chúng tôi khuyên bạn nên sử dụng MySQL hoặc PostgreSQL. Chúng có thể chạy trên các phiên bản db.t2.micro RDS, là một phần của cấp AWS miễn phí. Aurora hiện không cung cấp các phiên bản db.t2.micro, vì vậy bạn sẽ phải trả thêm một chút để sử dụng Aurora cho dự án thử nghiệm này.
Một lưu ý quan trọng cuối cùng
Hãy nhớ xóa triển khai Serverless của bạn khi bạn đã dùng thử xong API GraphQL để bạn không phải tiếp tục trả tiền cho các tài nguyên cơ sở dữ liệu mà bạn không còn sử dụng nữa.
Bạn có thể xóa ngăn xếp được tạo trong ví dụ này bằng cách chạy npm run remove trong thư mục gốc của dự án.
Chúc bạn thử nghiệm vui vẻ!
Tóm tắt
Trong bài viết này, chúng tôi đã hướng dẫn bạn cách tạo một API GraphQL đơn giản, sử dụng ba cơ sở dữ liệu khác nhau cùng một lúc; mặc dù đây không phải là điều bạn sẽ làm trong thực tế, nhưng nó cho phép chúng tôi so sánh các triển khai đơn giản của cơ sở dữ liệu Aurora, MySQL và PostgreSQL. Chúng tôi thấy rằng việc triển khai cho cả ba cơ sở dữ liệu gần như giống nhau trong trường hợp đơn giản của chúng tôi, trừ những khác biệt nhỏ về cú pháp và cấu hình triển khai.
Bạn có thể tìm thấy toàn bộ dự án mẫu mà chúng tôi đang sử dụng trong repo GitHub này. Cách dễ nhất để thử nghiệm với dự án là sao chép repo và triển khai nó từ máy của bạn bằng cách sử dụng triển khai npm run.
Để biết thêm các ví dụ về API GraphQL sử dụng Serverless, hãy xem repo serverless-graphql.
Nếu bạn muốn tìm hiểu thêm về cách chạy các API Serverless GraphQL trên quy mô lớn, bạn có thể thưởng thức loạt bài viết của chúng tôi “Chạy điểm cuối GraphQL có thể mở rộng và đáng tin cậy với Serverless”
Có lẽ GraphQL không phải là vấn đề của bạn và bạn muốn triển khai API REST? Chúng tôi đã hỗ trợ bạn:hãy xem bài đăng trên blog này để biết một số ví dụ.
Câu hỏi? Nhận xét về bài đăng này hoặc tạo một cuộc thảo luận trong diễn đàn của chúng tôi.
Được xuất bản lần đầu tại https://www.serverless.com.