Một vài năm trước (tại pgconf.eu 2014 ở Madrid), tôi đã trình bày một bài nói chuyện có tên “Khảo cổ học về hiệu suất” cho thấy hiệu suất đã thay đổi như thế nào trong các bản phát hành PostgreSQL gần đây. Tôi đã nói chuyện đó vì tôi nghĩ tầm nhìn dài hạn là thú vị và có thể cung cấp cho chúng ta những hiểu biết có thể rất có giá trị. Đối với những người thực sự làm việc trên mã PostgreSQL như tôi, đó là một hướng dẫn hữu ích để phát triển trong tương lai và đối với người dùng PostgreSQL, nó có thể giúp đánh giá các bản nâng cấp.
Vì vậy, tôi đã quyết định lặp lại bài tập này và viết một vài bài đăng trên blog phân tích hiệu suất cho một số phiên bản PostgreSQL. Trong buổi nói chuyện năm 2014, tôi bắt đầu với PostgreSQL 7.4, lúc đó đã được 10 năm tuổi (phát hành năm 2003). Lần này tôi sẽ bắt đầu với PostgreSQL 8.3, khoảng 12 tuổi.
Tại sao không bắt đầu lại với PostgreSQL 7.4? Có khoảng ba lý do chính khiến tôi quyết định bắt đầu với PostgreSQL 8.3. Thứ nhất, sự lười biếng nói chung. Phiên bản càng cũ càng khó xây dựng bằng cách sử dụng các phiên bản trình biên dịch hiện tại, v.v. Thứ hai, cần có thời gian để chạy các điểm chuẩn phù hợp, đặc biệt là với lượng dữ liệu lớn hơn, vì vậy việc thêm một phiên bản chính có thể dễ dàng thêm một vài ngày thời gian của máy. Nó chỉ có vẻ không đáng. Và cuối cùng, 8.3 đã giới thiệu một số thay đổi quan trọng - cải tiến autovacuum (được kích hoạt theo mặc định, quy trình công nhân đồng thời,…), tìm kiếm toàn văn bản được tích hợp vào lõi, trải rộng các điểm kiểm tra, v.v. Vì vậy, tôi nghĩ bắt đầu với PostgreSQL 8.3 là rất hợp lý. Được phát hành khoảng 12 năm trước, vì vậy so sánh này thực sự sẽ bao gồm một khoảng thời gian dài hơn.
Tôi đã quyết định chuẩn ba loại khối lượng công việc cơ bản - OLTP, phân tích và tìm kiếm toàn văn. Tôi nghĩ rằng OLTP và phân tích là những lựa chọn khá rõ ràng, vì hầu hết các ứng dụng là một số kết hợp của hai loại cơ bản đó. Tìm kiếm toàn văn cho phép tôi chứng minh những cải tiến trong các loại chỉ mục đặc biệt, cũng được sử dụng để lập chỉ mục các loại dữ liệu phổ biến như JSONB, các loại được PostGIS sử dụng, v.v.
Tại sao lại làm điều này?
Nó có thực sự đáng để nỗ lực không? Rốt cuộc, chúng tôi luôn làm các điểm chuẩn trong suốt quá trình phát triển để cho thấy rằng một bản vá giúp ích và / hoặc nó không gây ra sự thụt lùi, phải không? Rắc rối là đây thường chỉ là những điểm chuẩn "một phần", so sánh hai cam kết cụ thể và thường là với một lựa chọn khá hạn chế về khối lượng công việc mà chúng tôi nghĩ có thể có liên quan. Điều này hoàn toàn hợp lý - đơn giản là bạn không thể chạy hết khối lượng công việc cho mỗi lần cam kết.
Thỉnh thoảng (thường là ngay sau khi phát hành phiên bản chính PostgreSQL mới), mọi người chạy thử nghiệm so sánh phiên bản mới với phiên bản trước đó, điều này thật tuyệt và tôi khuyến khích bạn chạy các điểm chuẩn như vậy (có thể là một số loại điểm chuẩn tiêu chuẩn, hoặc một cái gì đó cụ thể cho ứng dụng của bạn). Nhưng thật khó để kết hợp những kết quả này thành một cái nhìn dài hạn, bởi vì những bài kiểm tra đó sử dụng các cấu hình và phần cứng khác nhau (thường là một kết quả gần đây hơn cho phiên bản mới hơn), v.v. Vì vậy, thật khó để đưa ra đánh giá rõ ràng về những thay đổi nói chung.
Điều tương tự cũng áp dụng cho hiệu suất ứng dụng, tất nhiên, đây là “điểm chuẩn cuối cùng”. Nhưng mọi người có thể không nâng cấp lên mọi phiên bản chính (đôi khi họ có thể bỏ qua một vài phiên bản, ví dụ:từ 9.5 đến 12). Và khi họ nâng cấp, nó thường kết hợp với nâng cấp phần cứng, v.v. Chưa kể đến việc các ứng dụng phát triển theo thời gian (tính năng mới, độ phức tạp bổ sung), lượng dữ liệu và số lượng người dùng đồng thời tăng lên, v.v.
Đó là những gì mà loạt bài blog này cố gắng thể hiện - các xu hướng dài hạn về hiệu suất PostgreSQL đối với một số khối lượng công việc cơ bản, để chúng tôi - những nhà phát triển - có được cảm giác ấm áp và mờ nhạt về công việc tốt trong những năm qua. Và để cho người dùng thấy rằng mặc dù PostgreSQL là một sản phẩm trưởng thành vào thời điểm này, nhưng vẫn có những cải tiến đáng kể trong mỗi phiên bản chính mới.
Mục tiêu của tôi không phải là sử dụng các điểm chuẩn này để so sánh với các sản phẩm cơ sở dữ liệu khác hoặc tạo ra kết quả để đáp ứng bất kỳ xếp hạng chính thức nào (như TPC-H). Mục tiêu của tôi chỉ đơn giản là đào tạo bản thân trở thành một nhà phát triển PostgreSQL, có thể xác định và điều tra một số vấn đề, đồng thời chia sẻ kết quả với những người khác.
So sánh công bằng?
Tôi không nghĩ rằng bất kỳ sự so sánh nào như vậy giữa các phiên bản đã phát hành trong 12 năm là không thể hoàn toàn công bằng, bởi vì bất kỳ phần mềm nào cũng được phát triển trong một bối cảnh cụ thể - phần cứng là một ví dụ điển hình, cho hệ thống cơ sở dữ liệu. Nếu bạn nhìn vào những chiếc máy bạn đã sử dụng cách đây 12 năm, chúng có bao nhiêu lõi, bao nhiêu RAM? Họ đã sử dụng loại bộ nhớ nào?
Một máy chủ tầm trung điển hình vào năm 2008 có thể có 8-12 lõi, RAM 16 GB và RAID với một vài ổ đĩa SAS. Một máy chủ tầm trung điển hình ngày nay có thể có vài chục lõi, hàng trăm GB RAM và bộ nhớ SSD.
Phát triển phần mềm được sắp xếp theo mức độ ưu tiên - luôn có nhiều nhiệm vụ tiềm năng hơn bạn có thời gian, vì vậy bạn cần chọn các nhiệm vụ có tỷ lệ chi phí / lợi ích tốt nhất cho người dùng của mình (đặc biệt là những nhiệm vụ tài trợ cho dự án, trực tiếp hoặc gián tiếp). Và vào năm 2008, một số tối ưu hóa có lẽ vẫn chưa phù hợp - hầu hết các máy không có dung lượng RAM cực lớn nên việc tối ưu hóa cho các bộ đệm chia sẻ lớn là chưa đáng để thực hiện. Và rất nhiều nút thắt cổ chai của CPU đã bị I / O làm lu mờ bởi vì hầu hết các máy đều có bộ phận lưu trữ "rỉ sét".
Lưu ý:Tất nhiên, hồi đó vẫn có những khách hàng sử dụng máy khá lớn. Một số đã sử dụng Postgres cộng đồng với nhiều chỉnh sửa khác nhau, những người khác quyết định chạy với một trong các fork Postgres khác nhau với các khả năng bổ sung (ví dụ:song song lớn, truy vấn phân tán, sử dụng FPGA, v.v.). Và điều này cũng ảnh hưởng đến sự phát triển của cộng đồng.
Khi các máy lớn hơn trở nên phổ biến hơn trong những năm qua, nhiều người có thể mua máy có dung lượng RAM lớn và số lượng lõi cao, làm thay đổi tỷ lệ chi phí / lợi ích. Các nút thắt cổ chai đã được điều tra và giải quyết, cho phép các phiên bản mới hơn hoạt động tốt hơn.
Điều này có nghĩa là điểm chuẩn như thế này luôn hơi không công bằng - nó sẽ ưu tiên phiên bản cũ hơn hoặc mới hơn, tùy thuộc vào thiết lập (phần cứng, cấu hình). Tuy nhiên, tôi đã cố gắng chọn các thông số phần cứng và cấu hình để nó không quá tệ đối với các phiên bản cũ.
Điểm tôi đang cố gắng đưa ra là điều này không có nghĩa là các phiên bản PostgreSQL cũ hơn là vớ vẩn - đây là cách hoạt động của phát triển phần mềm. Bạn giải quyết những nút thắt cổ chai mà người dùng của bạn có thể gặp phải, chứ không phải những nút thắt mà họ có thể gặp phải trong 10 năm nữa.
Phần cứng
Tôi thích làm các điểm chuẩn trên phần cứng vật lý mà tôi có quyền truy cập trực tiếp, vì điều đó cho phép tôi kiểm soát tất cả các chi tiết, tôi có quyền truy cập vào tất cả các chi tiết, v.v. Vì vậy, tôi đã sử dụng chiếc máy mà tôi có trong văn phòng của chúng tôi - không có gì lạ mắt, nhưng hy vọng đủ tốt cho mục đích này.
- 2x E5-2620 v4 (16 lõi, 32 luồng)
- RAM 64 GB
- SSD Intel Optane 900P 280GB NVMe (dữ liệu)
- 3 x 7.2k SATA RAID0 (không gian bảng tạm thời)
- kernel 5.6.15, ext4
- gcc 9.2.0, clang 9.0.1
Tôi cũng đã sử dụng máy thứ hai - nhỏ hơn nhiều - chỉ có 4 lõi và RAM 8GB, nhìn chung cho thấy các cải tiến / thoái triển tương tự, chỉ ít rõ rệt hơn.
pgbench
Là một công cụ đo điểm chuẩn, tôi đã sử dụng pgbench nổi tiếng, sử dụng phiên bản mới nhất (từ PostgreSQL 13) để kiểm tra tất cả các phiên bản. Điều này giúp loại bỏ sai lệch có thể có do tối ưu hóa được thực hiện trong pgbench theo thời gian, giúp kết quả có thể so sánh được.
Điểm chuẩn kiểm tra một số trường hợp khác nhau, thay đổi một số tham số, cụ thể là:
thang đo
- nhỏ - dữ liệu vừa với bộ đệm được chia sẻ, hiển thị các vấn đề về khóa, v.v.
- phương tiện - dữ liệu lớn hơn bộ đệm được chia sẻ nhưng vừa với RAM, thường được ràng buộc bởi CPU (hoặc có thể là I / O cho khối lượng công việc đọc-ghi)
- lớn - dữ liệu lớn hơn RAM, chủ yếu ràng buộc I / O
chế độ
- chỉ đọc - pgbench -S
- đọc-ghi - pgbench -N
số lượng khách hàng
- 1, 4, 8, 16, 32, 64, 128, 256
- số lượng các chủ đề pgbench (-j) được điều chỉnh cho phù hợp
Kết quả
OK, hãy xem kết quả. Trước tiên, tôi sẽ trình bày kết quả từ bộ lưu trữ NVMe, sau đó tôi sẽ hiển thị một số kết quả thú vị khi sử dụng bộ lưu trữ SATA RAID.
NVMe SSD / chỉ đọc
Đối với tập dữ liệu nhỏ (hoàn toàn phù hợp với bộ đệm được chia sẻ), kết quả chỉ đọc trông giống như sau:
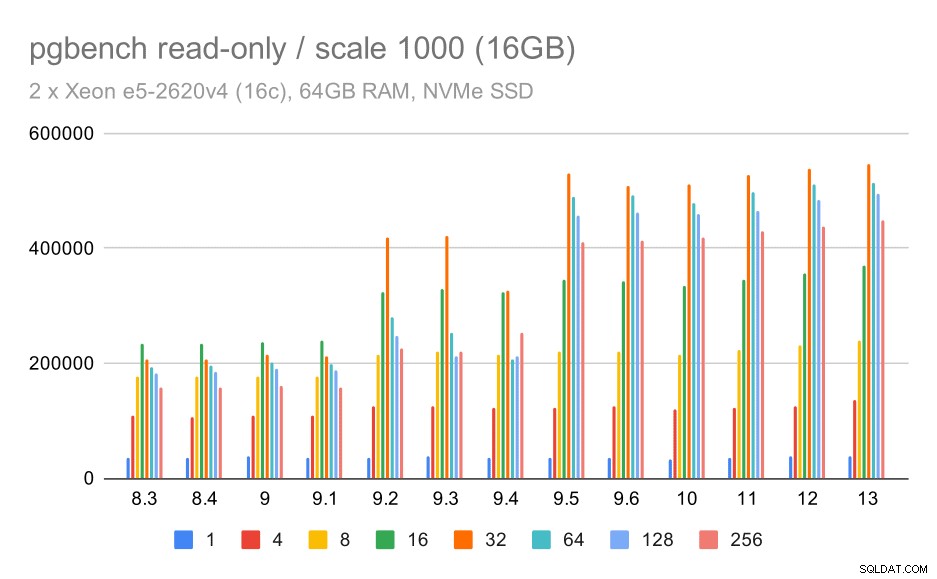
kết quả pgbench / chỉ đọc trên tập dữ liệu nhỏ (tỷ lệ 100, tức là 1,6 GB)
Rõ ràng, đã có sự gia tăng đáng kể về thông lượng trong 9.2, bao gồm một số cải tiến về hiệu suất, chẳng hạn như đường dẫn nhanh để khóa. Thông lượng cho một khách hàng thực sự giảm một chút - từ 47k tps xuống chỉ còn khoảng 42k tps. Nhưng đối với số lượng khách hàng cao hơn, sự cải thiện trong 9.2 là khá rõ ràng.
kết quả pgbench / chỉ đọc trên tập dữ liệu trung bình (quy mô 1000, tức là 16GB)
Đối với tập dữ liệu trung bình (lớn hơn bộ đệm được chia sẻ nhưng vẫn vừa với RAM) dường như cũng có một số cải tiến trong 9.2, mặc dù không rõ ràng như trên, theo sau là cải tiến rõ ràng hơn nhiều ở 9.5 rất có thể nhờ vào cải tiến khả năng mở rộng khóa .
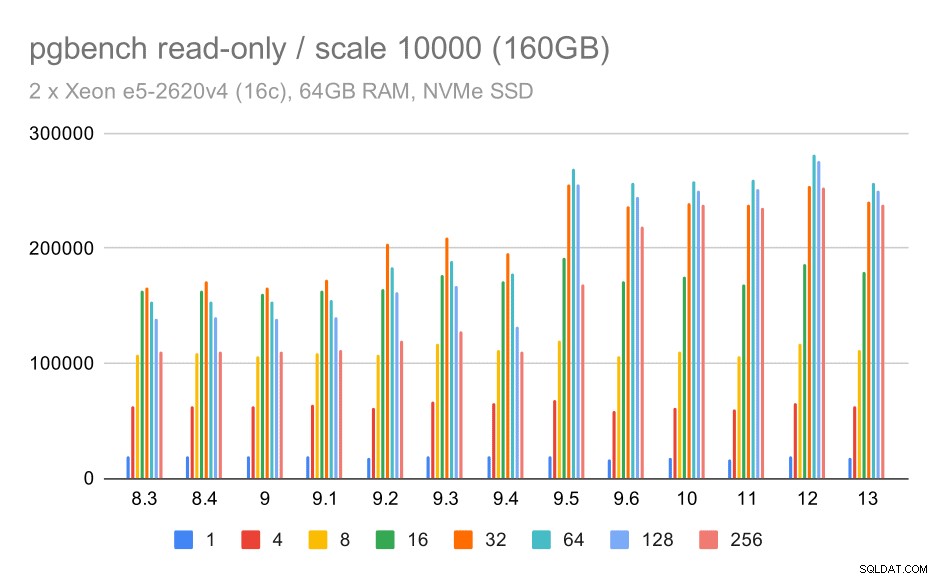
kết quả pgbench / chỉ đọc trên tập dữ liệu lớn (quy mô 10000, tức là 160GB)
Trên tập dữ liệu lớn nhất, chủ yếu là về khả năng sử dụng hiệu quả bộ nhớ, cũng có một số tốc độ tăng - rất có thể là nhờ vào các cải tiến 9.5.
NVMe SSD / đọc-ghi
Kết quả đọc-ghi cũng cho thấy một số cải tiến, mặc dù không rõ rệt. Trên tập dữ liệu nhỏ, kết quả trông như thế này:
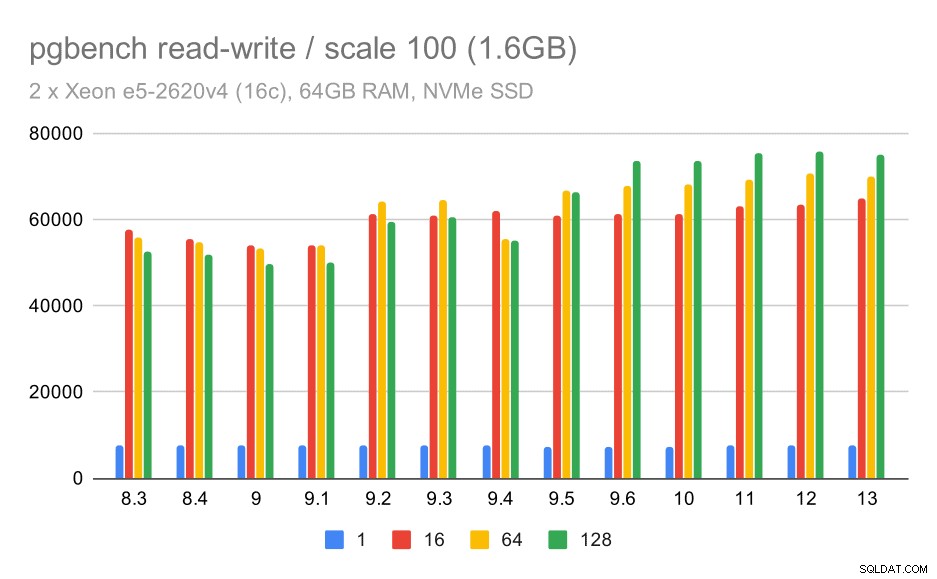
kết quả pgbench / đọc-ghi trên tập dữ liệu nhỏ (tỷ lệ 100, tức là 1,6 GB)
Vì vậy, một sự cải thiện khiêm tốn từ khoảng 52k lên 75k tps với đủ số lượng khách hàng.
Đối với tập dữ liệu trung bình, sự cải thiện rõ ràng hơn nhiều - từ khoảng 27k đến 63k tps, tức là thông lượng tăng hơn gấp đôi.
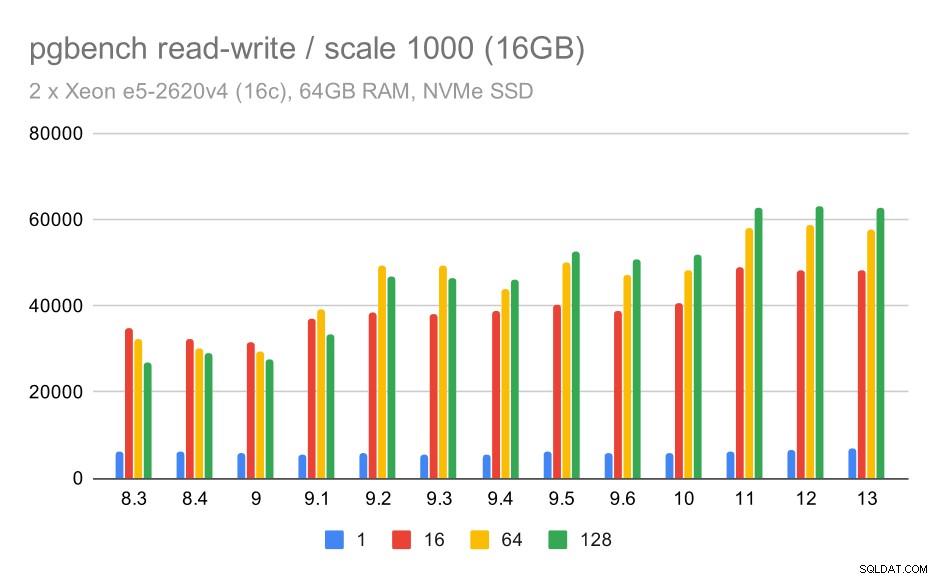
kết quả pgbench / đọc-ghi trên tập dữ liệu trung bình (quy mô 1000, tức là 16GB)
Đối với tập dữ liệu lớn nhất, chúng tôi nhận thấy sự cải thiện tổng thể tương tự, nhưng dường như có một số hồi quy giữa 9,5 và 11.
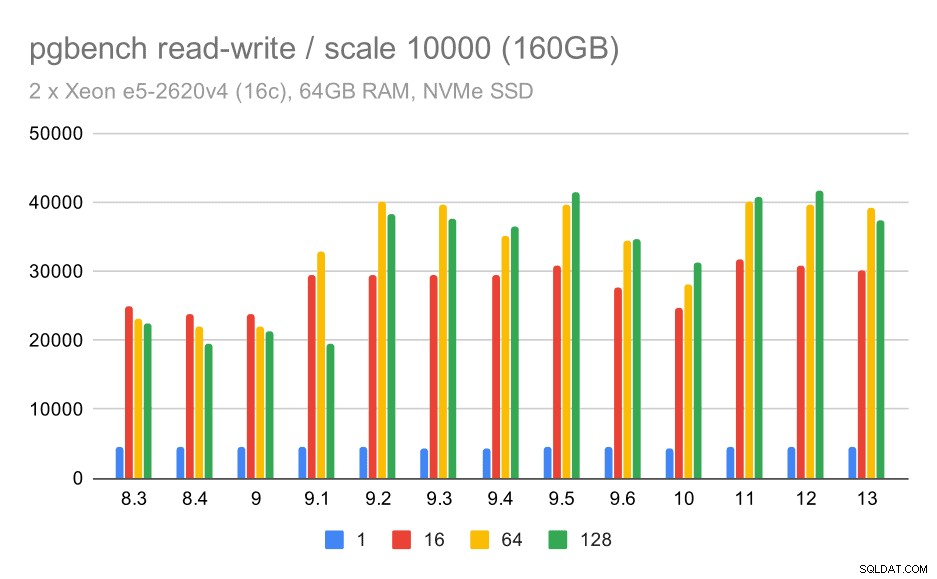
kết quả pgbench / đọc-ghi trên tập dữ liệu lớn (quy mô 10000, tức là 160GB)
SATA RAID / chỉ đọc
Đối với bộ lưu trữ SATA RAID, kết quả chỉ đọc không được tốt cho lắm. Chúng ta có thể bỏ qua các tập dữ liệu vừa và nhỏ mà hệ thống lưu trữ không liên quan. Đối với tập dữ liệu lớn, thông lượng hơi ồn nhưng nó có vẻ thực sự giảm theo thời gian - đặc biệt là kể từ PostgreSQL 9.6. Tôi không biết lý do cho điều này là gì (không có gì trong ghi chú phát hành 9.6 nổi bật như một ứng cử viên rõ ràng), nhưng nó có vẻ giống như một số kiểu hồi quy.
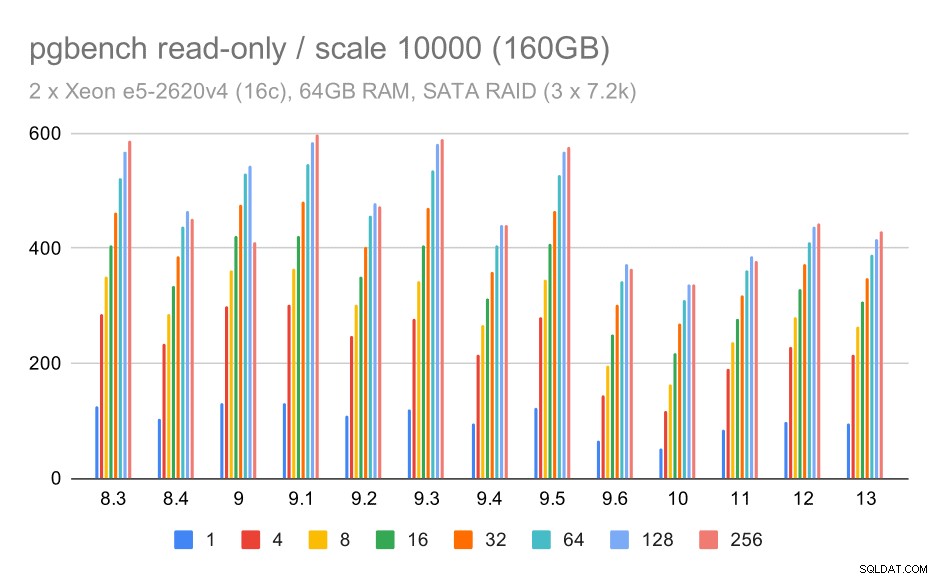
pgbench kết quả trên SATA RAID / chỉ đọc trên tập dữ liệu lớn (quy mô 10000, tức là 160GB)
SATA RAID / đọc-ghi
Tuy nhiên, hành vi đọc-ghi có vẻ đẹp hơn nhiều. Trên tập dữ liệu nhỏ, thông lượng tăng từ khoảng 600 tps lên hơn 6000 tps. Tôi cá rằng điều này là nhờ những cải tiến đối với cam kết nhóm trong 9.1 và 9.2.
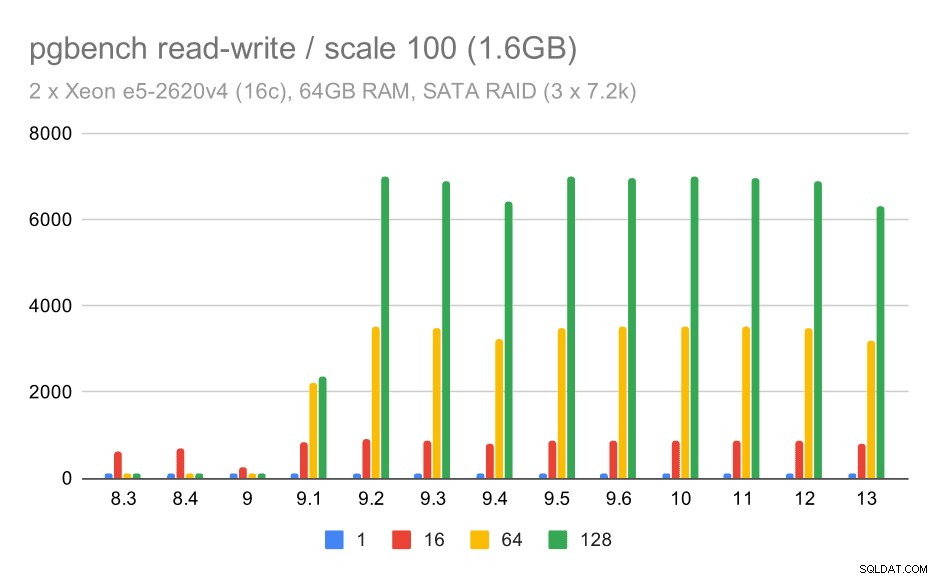
pgbench kết quả trên SATA RAID / đọc-ghi trên tập dữ liệu nhỏ (tỷ lệ 100, tức là 1,6 GB)
Đối với quy mô vừa và lớn, chúng ta có thể thấy sự cải thiện tương tự - nhưng nhỏ hơn - vì bộ lưu trữ cũng cần xử lý các yêu cầu I / O để đọc và ghi các khối dữ liệu. Đối với quy mô trung bình, chúng tôi chỉ cần thực hiện ghi (vì dữ liệu vừa với RAM), đối với quy mô lớn, chúng tôi cũng cần thực hiện đọc - vì vậy thông lượng tối đa thậm chí còn thấp hơn.
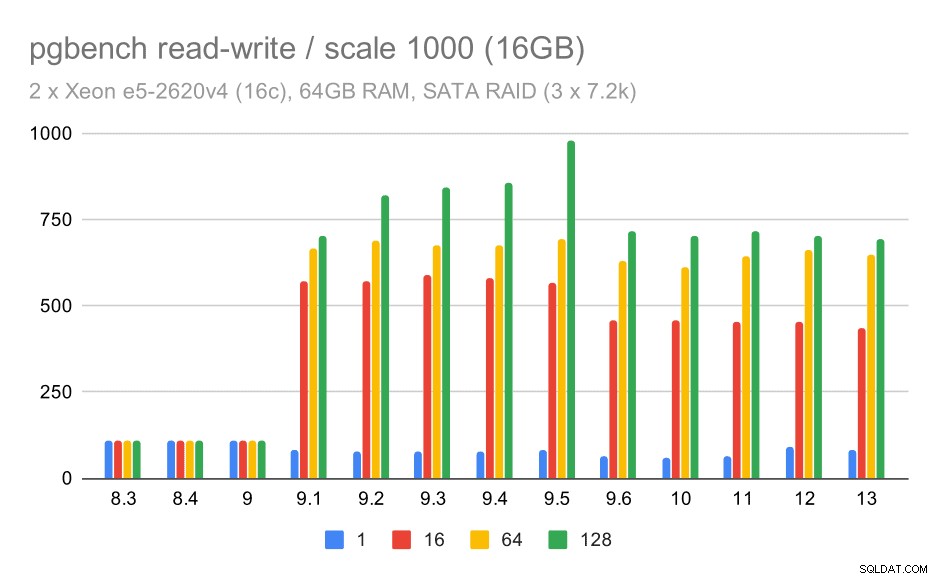
kết quả pgbench trên SATA RAID / đọc-ghi trên tập dữ liệu trung bình (quy mô 1000, tức là 16GB)
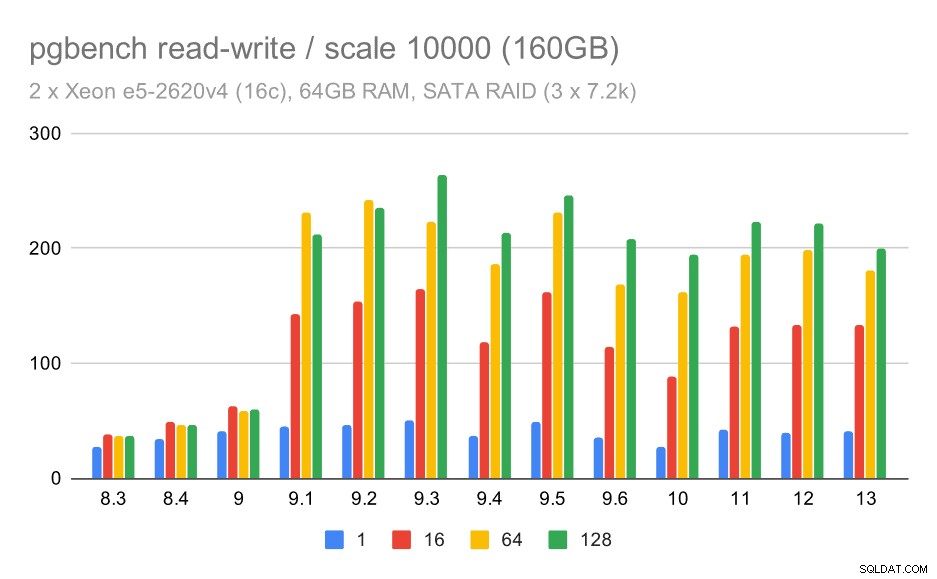
kết quả pgbench trên SATA RAID / đọc-ghi trên tập dữ liệu lớn (quy mô 10000, tức là 160GB)
Tóm tắt và Tương lai
Tóm lại, đối với thiết lập NVMe, các kết luận có vẻ khá tích cực. Đối với khối lượng công việc chỉ đọc, tốc độ tăng vừa phải ở 9,2 và tốc độ đáng kể ở 9,5, nhờ tối ưu hóa khả năng mở rộng, trong khi đối với khối lượng công việc đọc-ghi, hiệu suất được cải thiện khoảng 2 lần theo thời gian, trong nhiều phiên bản / bước.
Tuy nhiên, với thiết lập SATA RAID, các kết luận hơi khác nhau. Trong trường hợp khối lượng công việc chỉ đọc, có rất nhiều biến thể / nhiễu và có thể có hồi quy trong 9.6. Đối với khối lượng công việc đọc-ghi, có một sự tăng tốc lớn trong 9.1 trong đó thông lượng đột ngột tăng từ 100 tps lên khoảng 600 tps.
Còn những cải tiến trong các phiên bản PostgreSQL trong tương lai thì sao? Tôi không có ý tưởng rõ ràng về cải tiến lớn tiếp theo sẽ là gì - Tuy nhiên, tôi chắc chắn rằng các hacker PostgreSQL khác sẽ đưa ra những ý tưởng tuyệt vời giúp mọi thứ hiệu quả hơn hoặc cho phép tận dụng các tài nguyên phần cứng có sẵn. Bản vá để cải thiện khả năng mở rộng với nhiều kết nối hoặc bản vá để thêm hỗ trợ cho bộ đệm WAL không bay hơi là những ví dụ về những cải tiến như vậy. Chúng ta có thể thấy một số cải tiến triệt để đối với lưu trữ PostgreSQL (định dạng trên đĩa hiệu quả hơn, sử dụng I / O trực tiếp, v.v.), lập chỉ mục, v.v.