Trong phần đầu tiên của loạt bài blog này, tôi đã trình bày một số kết quả điểm chuẩn cho thấy hiệu suất của PostgreSQL OLTP đã thay đổi như thế nào kể từ phiên bản 8.3, được phát hành vào năm 2008. Trong phần này, tôi dự định làm điều tương tự nhưng đối với các truy vấn phân tích / BI, xử lý lớn lượng dữ liệu.
Có một số điểm chuẩn ngành để kiểm tra khối lượng công việc này, nhưng có lẽ điểm chuẩn được sử dụng phổ biến nhất là TPC-H, vì vậy đó là những gì tôi sẽ sử dụng cho bài đăng trên blog này. Ngoài ra còn có TPC-DS, một điểm chuẩn TPC khác để thử nghiệm các hệ thống hỗ trợ quyết định, có thể được coi là sự phát triển hoặc thay thế của TPC-H. Tôi đã quyết định gắn bó với TPC-H vì một số lý do.
Thứ nhất, TPC-DS phức tạp hơn nhiều, cả về lược đồ (nhiều bảng hơn) và số lượng truy vấn (22 so với 99). Điều chỉnh điều này đúng cách, đặc biệt là khi xử lý nhiều phiên bản PostgreSQL, sẽ khó hơn nhiều. Thứ hai, một số truy vấn TPC-DS sử dụng các tính năng không được hỗ trợ bởi các phiên bản PostgreSQL cũ hơn (ví dụ:nhóm nhóm), làm cho các truy vấn đó không liên quan đối với một số phiên bản. Và cuối cùng, tôi muốn nói rằng mọi người quen thuộc hơn với TPC-H so với TPC-DS.
Mục tiêu của việc này không phải là để cho phép so sánh với các sản phẩm cơ sở dữ liệu khác, chỉ để cung cấp đặc điểm dài hạn hợp lý về cách hiệu suất PostgreSQL phát triển kể từ PostgreSQL 8.3.
Lưu ý :Để có một phân tích rất thú vị về điểm chuẩn TPC-H, tôi thực sự khuyên bạn nên sử dụng bài báo “TPC-H được phân tích:Thông điệp ẩn và bài học rút ra từ điểm chuẩn có ảnh hưởng” của Boncz, Neumann và Erling.
Phần cứng
Hầu hết các kết quả trong bài đăng trên blog này đến từ “hộp lớn hơn” mà tôi có trong văn phòng của chúng tôi, có các thông số sau:
- 2x E5-2620 v4 (16 lõi, 32 luồng)
- RAM 64 GB
- SSD Intel Optane 900P 280GB NVMe (dữ liệu)
- 3 x 7.2k SATA RAID0 (không gian bảng tạm thời)
- kernel 5.6.15, hệ thống tệp ext4
Tôi chắc chắn rằng bạn có thể mua những chiếc máy mạnh hơn đáng kể, nhưng tôi tin rằng điều này đủ tốt để cung cấp cho chúng tôi dữ liệu liên quan. Có hai biến thể cấu hình - một biến thể bị vô hiệu hóa tính năng song song, một biến thể có tính năng song song được bật. Hầu hết các giá trị tham số đều giống nhau trong cả hai trường hợp, được điều chỉnh theo tài nguyên phần cứng có sẵn (CPU, RAM, bộ nhớ). Bạn có thể tìm thông tin chi tiết hơn về cấu hình ở cuối bài đăng này.
Điểm chuẩn
Tôi muốn nói rõ rằng mục tiêu của tôi không phải là triển khai điểm chuẩn TPC-H hợp lệ có thể vượt qua tất cả các tiêu chí mà TPC yêu cầu. Mục tiêu của tôi là đánh giá hiệu suất của các truy vấn phân tích khác nhau đã thay đổi như thế nào theo thời gian, chứ không phải theo đuổi một số đo lường trừu tượng về hiệu suất trên mỗi đô la hoặc những thứ tương tự.
Vì vậy, tôi đã quyết định chỉ sử dụng một tập hợp con của TPC-H - về cơ bản chỉ cần tải dữ liệu và chạy 22 truy vấn (các thông số giống nhau trên tất cả các phiên bản). Không có dữ liệu nào được làm mới, tập dữ liệu là tĩnh sau khi tải ban đầu. Tôi đã chọn một số hệ số tỷ lệ, 1, 10 và 75, để chúng tôi có kết quả cho các bộ đệm được chia sẻ phù hợp (1), phù hợp với bộ nhớ (10) và nhiều hơn bộ nhớ (75) . Tôi muốn 100 để biến nó thành một "chuỗi tốt", điều này sẽ không phù hợp với bộ nhớ 280GB trong một số trường hợp (nhờ vào chỉ mục, tệp tạm thời, v.v.). Lưu ý rằng hệ số quy mô 75 thậm chí không được TPC-H công nhận là hệ số quy mô hợp lệ.
Nhưng liệu nó có hợp lý khi đánh giá bộ dữ liệu 1GB hoặc 10GB không? Mọi người có xu hướng tập trung vào cơ sở dữ liệu lớn hơn nhiều, vì vậy có vẻ hơi ngu ngốc khi bận tâm đến việc thử nghiệm những cơ sở dữ liệu đó. Nhưng tôi không nghĩ điều đó sẽ hữu ích - phần lớn cơ sở dữ liệu trong tự nhiên là khá nhỏ, theo kinh nghiệm của tôi Và ngay cả khi toàn bộ cơ sở dữ liệu lớn, mọi người thường chỉ làm việc với một tập hợp con nhỏ của nó - dữ liệu gần đây, các đơn đặt hàng chưa được giải quyết, v.v. Vì vậy, tôi tin rằng việc kiểm tra ngay cả với những tập dữ liệu nhỏ đó là rất hợp lý.
Tải dữ liệu
Đầu tiên, hãy xem mất bao lâu để tải dữ liệu vào cơ sở dữ liệu - không và song song. Tôi sẽ chỉ hiển thị kết quả từ tập dữ liệu 75GB, vì hành vi tổng thể gần như giống nhau đối với các trường hợp nhỏ hơn.
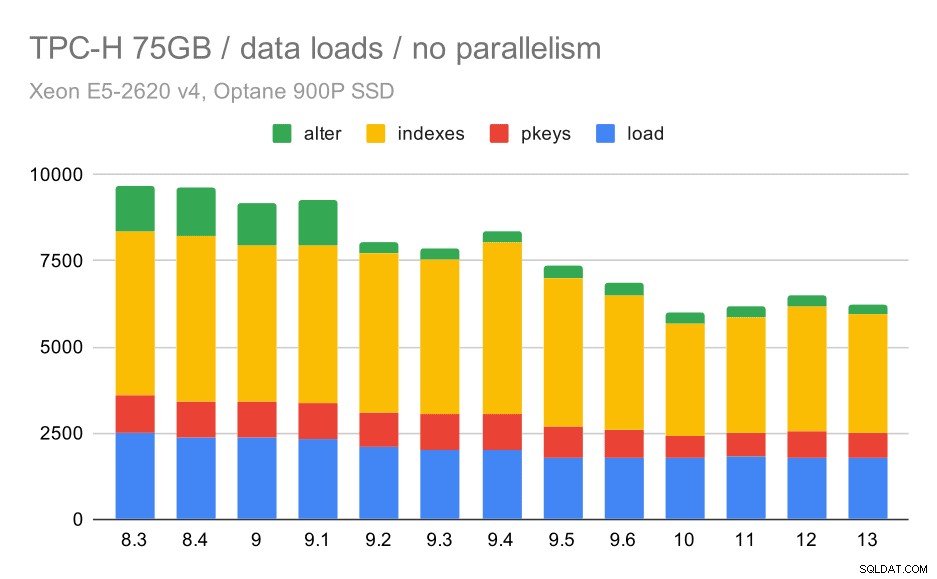
Thời lượng tải dữ liệu TPC-H - quy mô 75GB, không có song song
Bạn có thể thấy rõ xu hướng cải tiến ổn định, giảm khoảng 30% thời lượng chỉ bằng cách nâng cao hiệu quả trong cả bốn bước - SAO CHÉP, tạo khóa chính và chỉ mục, và (đặc biệt) thiết lập khóa ngoài. Cải tiến "thay đổi" trong 9.2 đặc biệt rõ ràng.
| SAO CHÉP | PKEYS | CHỈ SỐ | ALTER | |
| 8.3 | 2531 | 1156 | 1922 | 1615 |
| 8,4 | 2374 | 1171 | 1891 | 1370 |
| 9.0 | 2374 | 1137 | 1797 | 1282 |
| 9.1 | 2376 | 1118 | 1807 | 1268 |
| 9.2 | 2104 | 1120 | 1833 | 1157 |
| 9.3 | 2008 | 1089 | 1836 | 1229 |
| 9.4 | 1990 | 1168 | 1818 | 1197 |
| 9.5 | 1982 | 1000 | 1903 | 1203 |
| 9,6 | 1779 | 872 | 1797 | 1174 |
| 10 | 1773 | 777 | 1469 | 1012 |
| 11 | 1807 | 762 | 1492 | 758 |
| 12 | 1760 | 768 | 1513 | 741 |
| 13 | 1782 | 836 | 1587 | 675 |
Bây giờ, hãy xem việc bật chế độ song song thay đổi hành vi như thế nào. Biểu đồ sau so sánh các kết quả có bật chế độ song song - được đánh dấu bằng “(p)” - với các kết quả đã tắt chế độ song song.
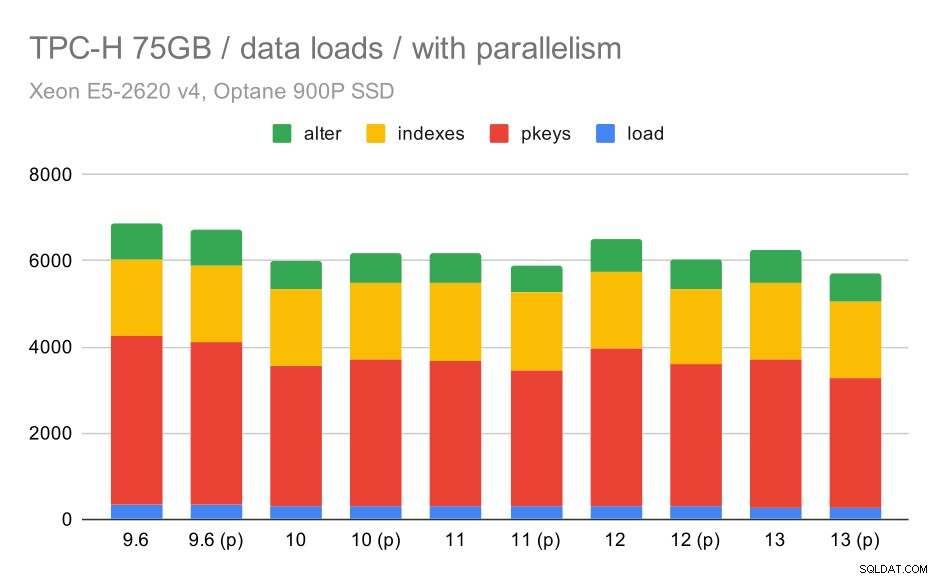
Thời lượng tải dữ liệu TPC-H - quy mô 75GB, bật chế độ song song.
Thật không may, có vẻ như ảnh hưởng của tính song song rất hạn chế trong thử nghiệm này - nó có ích một chút, nhưng sự khác biệt là khá nhỏ. Vì vậy, sự cải thiện tổng thể vẫn còn khoảng 30%.
| SAO CHÉP | PKEYS | CHỈ SỐ | ALTER | |
| 9,6 | 344 | 3902 | 1786 | 831 |
| 9,6 (p) | 346 | 3781 | 1780 | 832 |
| 10 | 318 | 3259 | 1766 | 671 |
| 10 (p) | 315 | 3400 | 1769 | 693 |
| 11 | 319 | 3357 | 1817 | 690 |
| 11 (p) | 320 | 3144 | 1791 | 618 |
| 12 | 314 | 3643 | 1803 | 754 |
| 12 (p) | 313 | 3296 | 1752 | 657 |
| 13 | 276 | 3437 | 1790 | 744 |
| 13 (P) | 274 | 3011 | 1770 | 641 |
Truy vấn
Bây giờ chúng ta có thể xem xét các truy vấn. TPC-H có 22 mẫu truy vấn - Tôi đã tạo một tập hợp các truy vấn thực tế và chạy chúng trên tất cả các phiên bản hai lần - lần đầu tiên sau khi xóa tất cả các bộ nhớ đệm và khởi động lại phiên bản, sau đó với bộ đệm được làm ấm. Tất cả các con số được trình bày trong biểu đồ là tốt nhất trong hai lần chạy này (tất nhiên, trong hầu hết các trường hợp, đó là lần chạy thứ hai).
Không có song song
Không có sự song song, kết quả trên tập dữ liệu nhỏ nhất là khá rõ ràng - mỗi thanh được chia thành nhiều phần với các màu khác nhau cho mỗi trong số 22 truy vấn. Thật khó để nói phần nào ánh xạ đến truy vấn chính xác nào, nhưng nó đủ để xác định các trường hợp khi một truy vấn cải thiện hoặc trở nên tồi tệ hơn nhiều giữa hai lần chạy. Ví dụ:trong biểu đồ đầu tiên, rất rõ ràng Q21 nhanh hơn nhiều trong khoảng từ 8,3 đến 8,4.
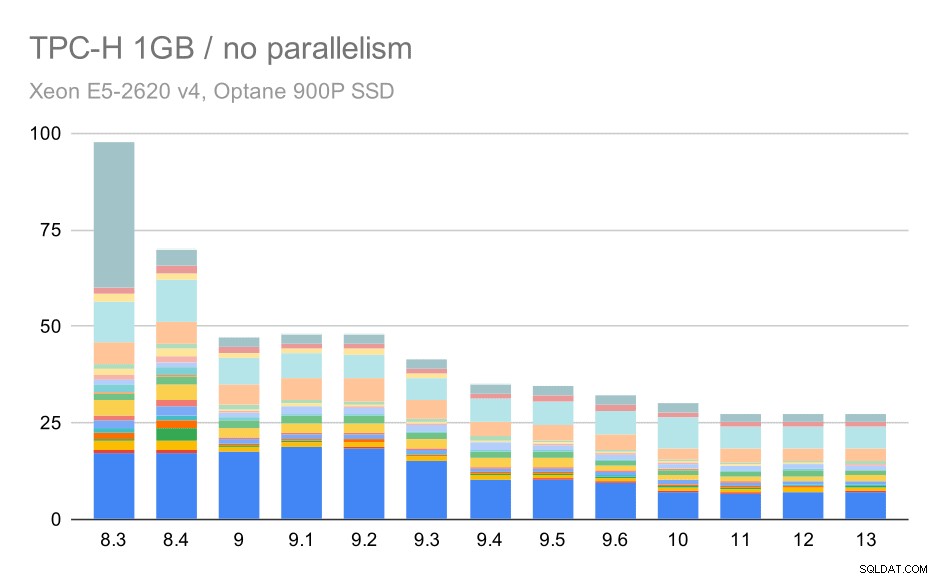
Truy vấn TPC-H trên tập dữ liệu nhỏ (1GB) - tính năng song song bị vô hiệu hóa
Đối với quy mô 10GB, kết quả hơi khó giải thích, vì vào ngày 8.3, một trong các truy vấn (Q21) mất quá nhiều thời gian để thực thi khiến nó làm lùn mọi thứ khác.
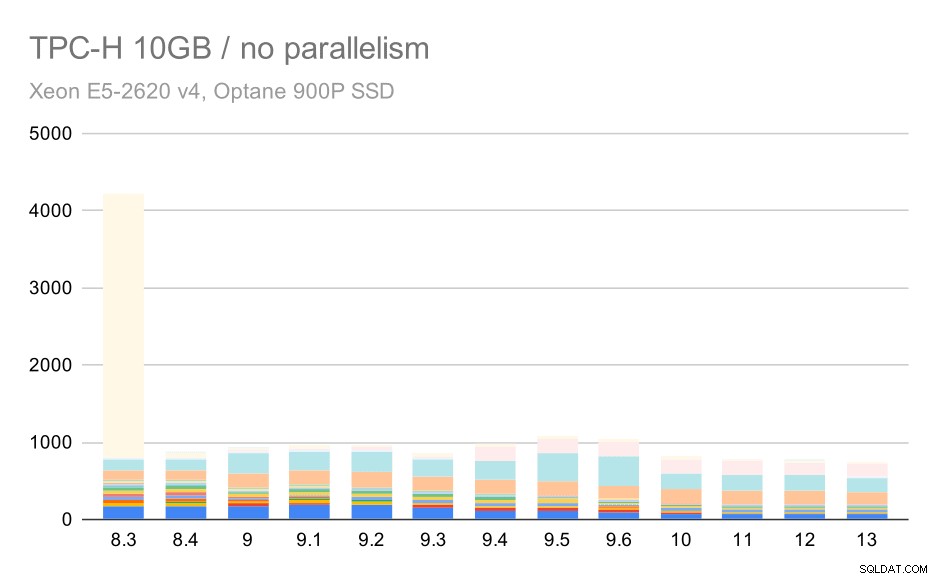
Các truy vấn TPC-H trên tập dữ liệu trung bình (10GB) - tính năng song song bị vô hiệu hóa
Vì vậy, hãy xem biểu đồ sẽ trông như thế nào nếu không có Q21:
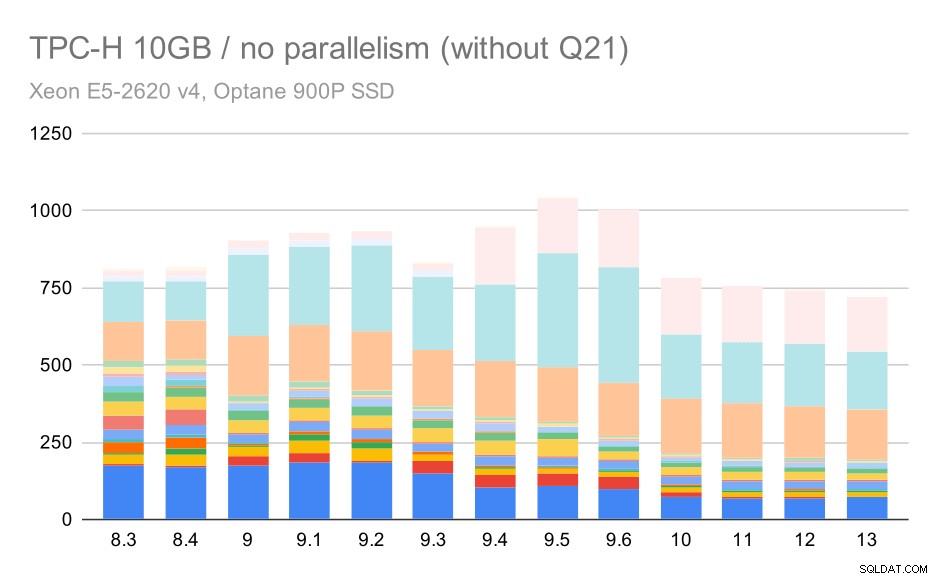
Các truy vấn TPC-H trên tập dữ liệu trung bình (10GB) - tính năng song song bị vô hiệu hóa, không có vấn đề gì quý 2
OK, dễ đọc hơn. Chúng ta có thể thấy rõ rằng hầu hết các truy vấn (lên đến Q17) đều nhanh hơn, nhưng sau đó hai trong số các truy vấn (Q18 và Q20) lại chậm hơn một chút. Chúng ta sẽ thấy một vấn đề tương tự trên tập dữ liệu lớn nhất, vì vậy, sau đó tôi sẽ thảo luận xem điều gì có thể là nguyên nhân gốc rễ.
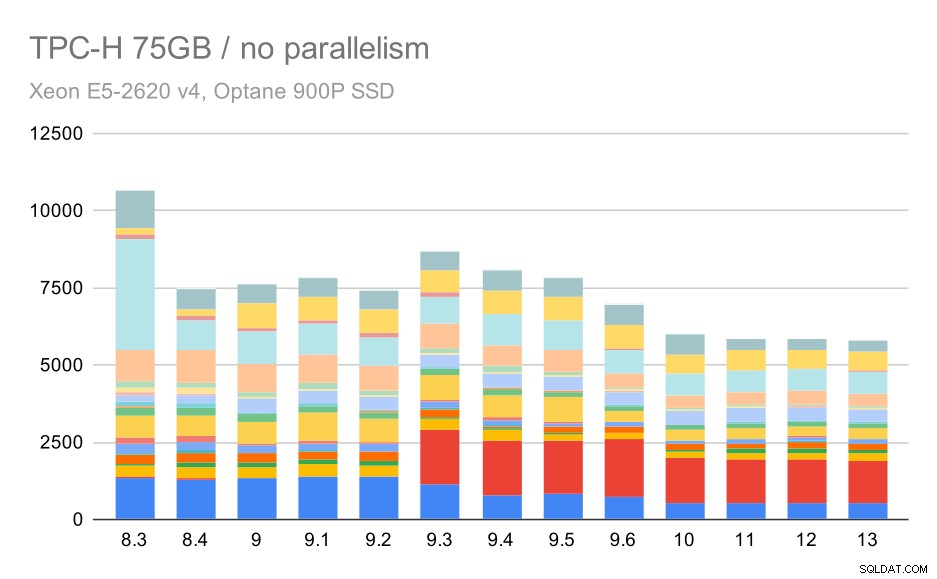
Các truy vấn TPC-H trên tập dữ liệu lớn (75GB) - tính năng song song bị vô hiệu hóa
Một lần nữa, chúng tôi thấy sự gia tăng đột ngột cho một trong các truy vấn trong 9.3 - lần này là quý 2, nếu không có biểu đồ sẽ trông như thế này:
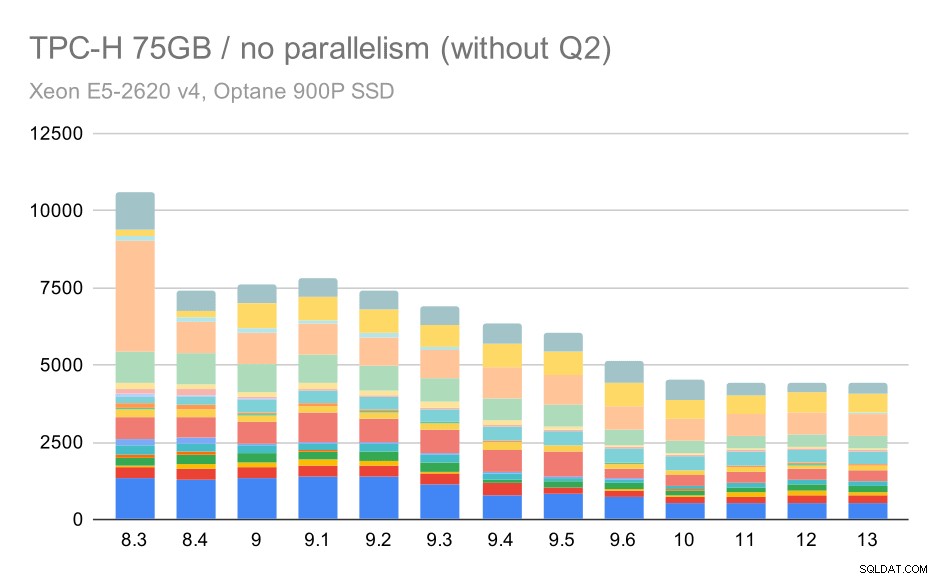
Các truy vấn TPC-H trên tập dữ liệu lớn (75GB) - tính năng song song bị vô hiệu hóa, không có vấn đề gì quý 2
Nói chung, đó là một cải tiến khá tốt, tăng tốc toàn bộ quá trình thực thi từ ~ 2,7 giờ xuống chỉ ~ 1,2 giờ, chỉ đơn thuần bằng cách làm cho trình lập kế hoạch và trình tối ưu hóa thông minh hơn và bằng cách làm cho trình thực thi hiệu quả hơn (hãy nhớ rằng tính song song đã bị vô hiệu hóa trong những lần chạy này) .
Vì vậy, vấn đề có thể là gì với Q2 khiến nó chậm hơn trong 9.3? Câu trả lời đơn giản là mỗi khi bạn làm cho công cụ lập kế hoạch và trình tối ưu hóa thông minh hơn - bằng cách xây dựng các loại đường dẫn / kế hoạch mới hoặc bằng cách làm cho nó phụ thuộc vào một số thống kê, điều đó cũng có nghĩa là bạn có thể mắc phải những sai lầm mới khi thống kê hoặc ước tính sai. Trong quý 2, mệnh đề WHERE tham chiếu đến một truy vấn con tổng hợp - phiên bản đơn giản hóa của truy vấn có thể trông giống như sau:
select 1 from partsupp where ps_supplycost = ( select min(ps_supplycost) from partsupp, supplier, nation, region where p_partkey = ps_partkey and s_suppkey = ps_suppkey and s_nationkey = n_nationkey and n_regionkey = r_regionkey and r_name = 'AMERICA' );
Vấn đề là chúng tôi không biết giá trị trung bình tại thời điểm lập kế hoạch, khiến chúng tôi không thể tính đủ các ước tính tốt cho điều kiện WHERE. Quý 2 thực tế chứa các liên kết bổ sung và việc lập kế hoạch về cơ bản phụ thuộc vào các ước tính tốt về các quan hệ đã tham gia. Trong các phiên bản cũ hơn, trình tối ưu hóa dường như đã làm đúng, nhưng sau đó trong phiên bản 9.3, chúng tôi đã làm cho nó thông minh hơn theo một cách nào đó, nhưng với ước tính kém, nó không đưa ra được quyết định đúng đắn. Nói cách khác, các kế hoạch tốt trong các phiên bản cũ chỉ là may mắn, nhờ vào những hạn chế của trình lập kế hoạch.
Tôi cá rằng các hồi quy của Q18 và Q20 trên tập dữ liệu nhỏ hơn cũng do điều gì đó tương tự gây ra, mặc dù tôi chưa điều tra chi tiết những điều đó.
Tôi tin rằng một số vấn đề trong trình tối ưu hóa đó có thể được khắc phục bằng cách điều chỉnh các thông số chi phí (ví dụ:random_page_cost, v.v.) nhưng tôi chưa thử điều đó vì hạn chế về thời gian. Tuy nhiên, nó cho thấy rằng nâng cấp không tự động cải thiện tất cả các truy vấn - đôi khi nâng cấp có thể kích hoạt hồi quy, do đó, việc kiểm tra ứng dụng của bạn một cách thích hợp là một ý kiến hay.
Song song
Vì vậy, hãy xem mức độ song song của truy vấn thay đổi kết quả như thế nào. Một lần nữa, chúng tôi sẽ chỉ xem xét kết quả từ các bản phát hành kể từ ngày 9.6 gắn nhãn kết quả với “(p)” trong đó truy vấn song song được bật.
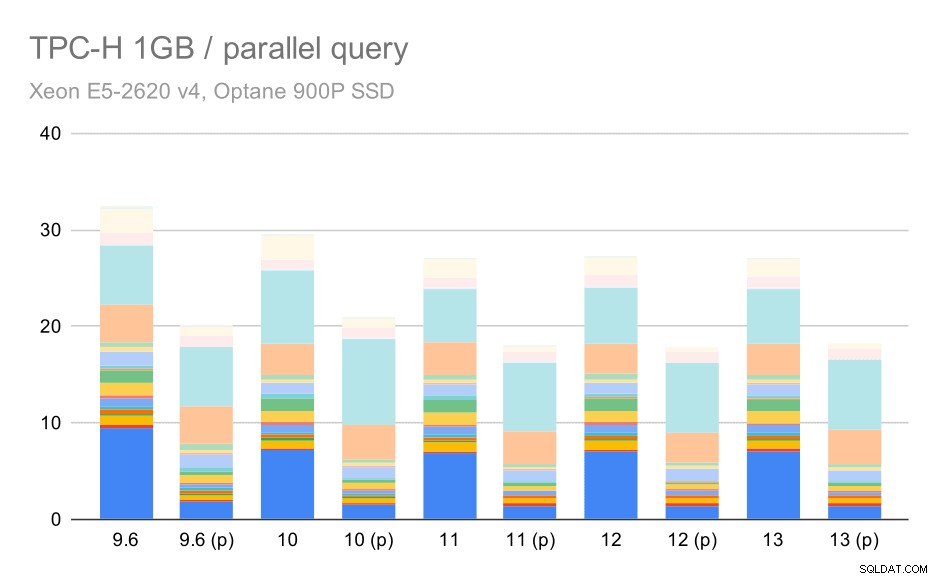
Truy vấn TPC-H trên tập dữ liệu nhỏ (1GB) - bật chế độ song song
Rõ ràng, tính song song giúp ích khá nhiều - nó loại bỏ khoảng 30% ngay cả trên tập dữ liệu nhỏ này. Trên tập dữ liệu phương tiện, không có nhiều sự khác biệt giữa chạy thường xuyên và chạy song song:
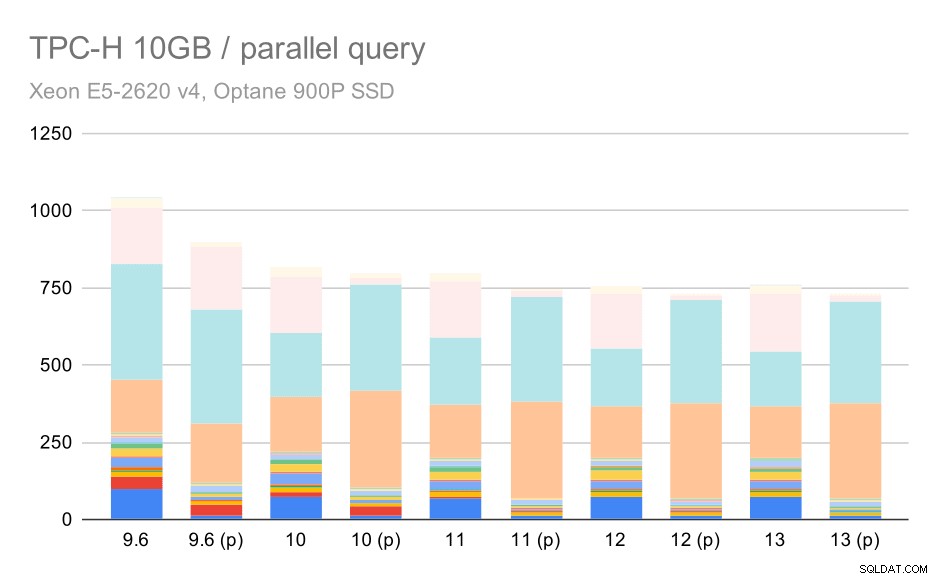
Các truy vấn TPC-H trên tập dữ liệu trung bình (10GB) - bật chế độ song song
Đây là một minh chứng khác về vấn đề đã được thảo luận - cho phép tính song song cho phép xem xét các kế hoạch truy vấn bổ sung và rõ ràng các ước tính hoặc chi phí không phù hợp với thực tế, dẫn đến các lựa chọn kế hoạch kém.
Và cuối cùng là tập dữ liệu lớn, nơi kết quả hoàn chỉnh trông như thế này:
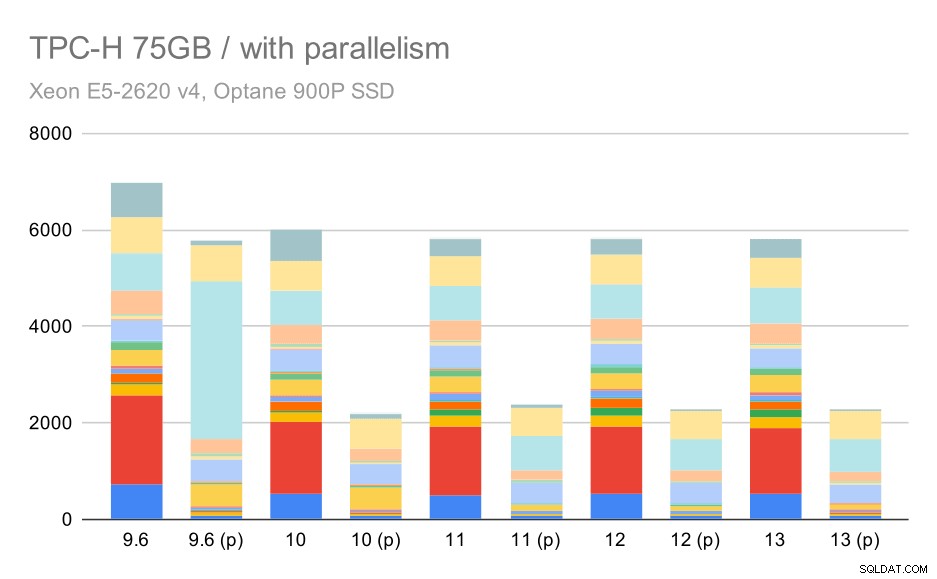
Các truy vấn TPC-H trên tập dữ liệu lớn (75GB) - bật tính năng song song
Ở đây cho phép tính năng song song hoạt động có lợi cho chúng tôi - trình tối ưu hóa quản lý để xây dựng một kế hoạch song song rẻ hơn cho Quý 2, ghi đè lựa chọn kế hoạch kém được giới thiệu trong 9.3. Nhưng chỉ để hoàn thiện, đây là kết quả không có quý 2.
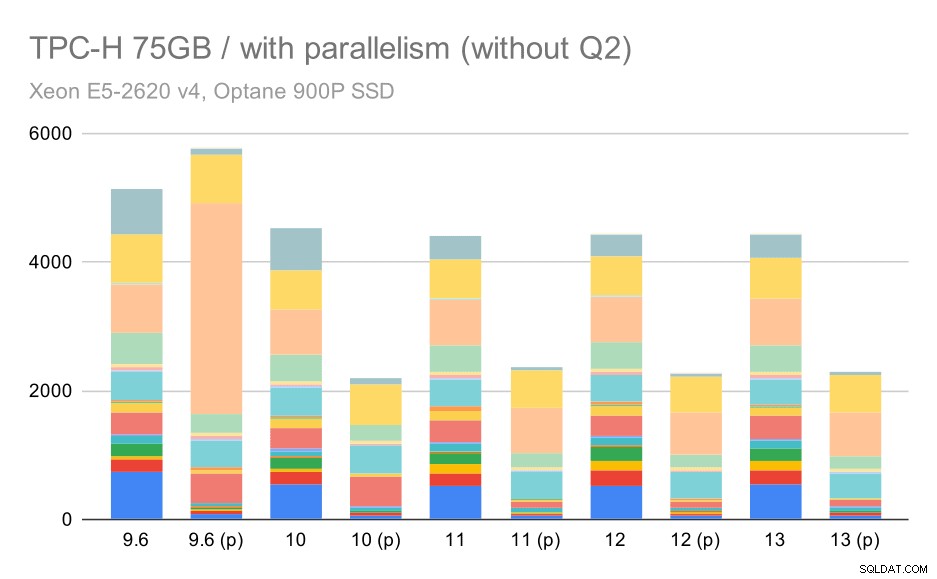
Truy vấn TPC-H trên tập dữ liệu lớn (75GB) - bật chế độ song song, không có vấn đề gì quý 2
Thậm chí ở đây, bạn có thể phát hiện ra một số lựa chọn kế hoạch song song kém - ví dụ như kế hoạch song song cho Q9 kém hơn cho đến 11 khi nó trở nên nhanh hơn - có thể là nhờ có 11 nút hỗ trợ thực thi song song bổ sung. Mặt khác, một số truy vấn song song (Q18, Q20) chậm hơn vào ngày 11, vì vậy, đó không chỉ là cầu vồng và kỳ lân.
Tóm tắt và Tương lai
Tôi nghĩ rằng những kết quả này chứng minh một cách độc đáo việc triển khai tối ưu hóa kể từ PostgreSQL 8.3. Các thử nghiệm với tính năng song song bị vô hiệu hóa minh họa sự cải thiện về hiệu quả (tức là làm được nhiều việc hơn với cùng một lượng tài nguyên) - tải dữ liệu nhanh hơn ~ 30% và truy vấn nhanh hơn ~ 2 lần. Đúng là tôi đã gặp phải một số vấn đề với kế hoạch truy vấn không hiệu quả, nhưng đó là rủi ro cố hữu khi làm cho công cụ lập kế hoạch truy vấn thông minh hơn. Chúng tôi liên tục làm việc để làm cho kết quả đáng tin cậy hơn và tôi chắc chắn rằng tôi có thể giảm thiểu hầu hết các vấn đề này bằng cách điều chỉnh cấu hình một chút.
Kết quả khi bật tính năng song song cho thấy rằng chúng ta có thể sử dụng hiệu quả các tài nguyên bổ sung (đặc biệt là các lõi CPU). Việc tải dữ liệu dường như không được hưởng lợi nhiều từ điều này - ít nhất là không phải trong điểm chuẩn này, nhưng tác động đến việc thực thi truy vấn là đáng kể, dẫn đến tốc độ tăng gấp ~ 2 lần (tất nhiên, mặc dù các truy vấn khác nhau bị ảnh hưởng khác nhau).
Có rất nhiều cơ hội để cải thiện điều này trong các phiên bản PostgreSQL trong tương lai. Ví dụ:có một loạt bản vá thực hiện song song cho COPY, tăng tốc tải dữ liệu. Có nhiều bản vá khác nhau cải thiện việc thực thi các truy vấn phân tích - từ tối ưu hóa cục bộ nhỏ đến các dự án lớn như lưu trữ và thực thi cột, tổng hợp đẩy xuống, v.v. Bạn cũng có thể đạt được nhiều điều bằng cách sử dụng phân vùng khai báo - một tính năng mà tôi hầu như đã bỏ qua khi làm việc này điểm chuẩn, đơn giản vì nó sẽ làm tăng phạm vi quá nhiều. Và tôi chắc chắn rằng có nhiều cơ hội khác mà tôi thậm chí không thể tưởng tượng được, nhưng những người thông minh hơn trong cộng đồng PostgreSQL đã và đang làm việc với chúng.
Phụ lục:Cấu hình PostgreSQL
Tính năng song song bị vô hiệu hóa
shared_buffers = 4GB work_mem = 128MB vacuum_cost_limit = 1000 max_wal_size = 24GB checkpoint_timeout = 30min checkpoint_completion_target = 0.9 # logging log_checkpoints = on log_connections = on log_disconnections = on log_line_prefix = '%t %c:%l %x/%v ' log_lock_waits = on log_temp_files = 1024 # parallel query max_parallel_workers_per_gather = 0 max_parallel_maintenance_workers = 0 # optimizer default_statistics_target = 1000 random_page_cost = 60 effective_cache_size = 32GB
Đã bật chế độ song song
shared_buffers = 4GB work_mem = 128MB vacuum_cost_limit = 1000 max_wal_size = 24GB checkpoint_timeout = 30min checkpoint_completion_target = 0.9 # logging log_checkpoints = on log_connections = on log_disconnections = on log_line_prefix = '%t %c:%l %x/%v ' log_lock_waits = on log_temp_files = 1024 # parallel query max_parallel_workers_per_gather = 16 max_parallel_maintenance_workers = 16 max_worker_processes = 32 max_parallel_workers = 32 # optimizer default_statistics_target = 1000 random_page_cost = 60 effective_cache_size = 32GB