Các tham số giá trị bảng đã có từ SQL Server 2008 và cung cấp một cơ chế hữu ích để gửi nhiều hàng dữ liệu đến SQL Server, được tập hợp lại dưới dạng một lệnh gọi tham số duy nhất. Bất kỳ hàng nào sau đó đều có sẵn trong một biến bảng sau đó có thể được sử dụng trong mã hóa T-SQL tiêu chuẩn, giúp loại bỏ nhu cầu viết logic xử lý chuyên biệt để chia nhỏ dữ liệu một lần nữa. Theo định nghĩa của chúng, các tham số có giá trị bảng được đánh mạnh vào kiểu bảng do người dùng xác định phải tồn tại trong cơ sở dữ liệu nơi lệnh gọi đang được thực hiện. Tuy nhiên, đánh máy mạnh không thực sự hoàn toàn "được đánh máy mạnh" như bạn mong đợi, vì bài viết này sẽ chứng minh và kết quả là hiệu suất có thể bị ảnh hưởng.
Để chứng minh các tác động tiềm năng về hiệu suất của các tham số có giá trị bảng được nhập không chính xác với SQL Server, chúng tôi sẽ tạo một loại bảng mẫu do người dùng xác định với cấu trúc sau:
CREATE TYPE dbo.PharmacyData AS TABLE ( Dosage int, Drug varchar(20), FirstName varchar(50), LastName varchar(50), AddressLine1 varchar(250), PhoneNumber varchar(50), CellNumber varchar(50), EmailAddress varchar(100), FillDate datetime );
Sau đó, chúng ta sẽ cần một ứng dụng .NET sẽ sử dụng loại bảng do người dùng xác định này làm tham số đầu vào để truyền dữ liệu vào SQL Server. Để sử dụng một tham số có giá trị bảng từ ứng dụng của chúng tôi, một đối tượng DataTable thường được điền và sau đó được chuyển làm giá trị cho tham số có kiểu SqlDbType.Structured. DataTable có thể được tạo theo nhiều cách trong mã .NET, nhưng một cách phổ biến để tạo bảng là như sau:
System.Data.DataTable DefaultTable = new System.Data.DataTable("@PharmacyData");
DefaultTable.Columns.Add("Dosage", typeof(int));
DefaultTable.Columns.Add("Drug", typeof(string));
DefaultTable.Columns.Add("FirstName", typeof(string));
DefaultTable.Columns.Add("LastName", typeof(string));
DefaultTable.Columns.Add("AddressLine1", typeof(string));
DefaultTable.Columns.Add("PhoneNumber", typeof(string));
DefaultTable.Columns.Add("CellNumber", typeof(string));
DefaultTable.Columns.Add("EmailAddress", typeof(string));
DefaultTable.Columns.Add("Date", typeof(DateTime)); Bạn cũng có thể tạo DataTable bằng cách sử dụng định nghĩa nội tuyến như sau:
System.Data.DataTable DefaultTable = new System.Data.DataTable("@PharmacyData")
{
Columns =
{
{"Dosage", typeof(int)},
{"Drug", typeof(string)},
{"FirstName", typeof(string)},
{"LastName", typeof(string)},
{"AddressLine1", typeof(string)},
{"PhoneNumber", typeof(string)},
{"CellNumber", typeof(string)},
{"EmailAddress", typeof(string)},
{"Date", typeof(DateTime)},
},
Locale = CultureInfo.InvariantCulture
}; Một trong hai định nghĩa này của đối tượng DataTable trong .NET có thể được sử dụng làm tham số có giá trị bảng cho kiểu dữ liệu do người dùng xác định đã được tạo, nhưng hãy chú ý đến định nghĩa kiểu (chuỗi) cho các cột chuỗi khác nhau; tất cả đều có thể được nhập “đúng cách” nhưng chúng không thực sự được nhập mạnh vào các loại dữ liệu được triển khai trong loại dữ liệu do người dùng xác định. Chúng ta có thể điền dữ liệu ngẫu nhiên vào bảng và chuyển nó tới SQL Server dưới dạng tham số cho một câu lệnh SELECT rất đơn giản sẽ trả về các hàng giống hệt như bảng mà chúng ta đã truyền vào, như sau:
using (SqlCommand cmd = new SqlCommand("SELECT * FROM @tvp;", connection))
{
var pList = new SqlParameter("@tvp", SqlDbType.Structured);
pList.TypeName = "dbo.PharmacyData";
pList.Value = DefaultTable;
cmd.Parameters.Add(pList);
cmd.ExecuteReader().Dispose();
} Sau đó, chúng tôi có thể sử dụng ngắt gỡ lỗi để chúng tôi có thể kiểm tra định nghĩa của DefaultTable trong quá trình thực thi, như hiển thị bên dưới:
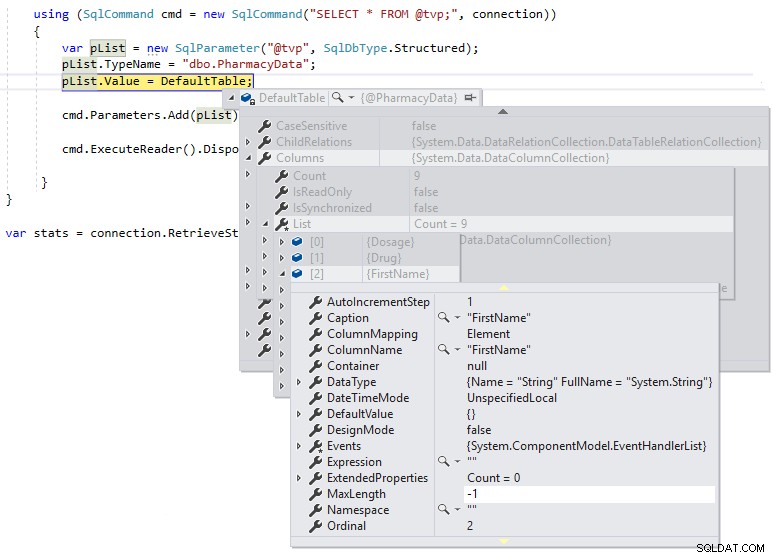
Chúng ta có thể thấy rằng MaxLength cho các cột chuỗi được đặt ở -1, có nghĩa là chúng đang được chuyển qua TDS tới SQL Server dưới dạng LOB (Đối tượng lớn) hoặc về cơ bản là MAX cột được định kiểu dữ liệu và điều này có thể ảnh hưởng đến hiệu suất theo cách tiêu cực. Nếu chúng tôi thay đổi định nghĩa .NET DataTable được nhập mạnh thành định nghĩa giản đồ của loại bảng do người dùng xác định như sau và xem MaxLength của cùng một cột bằng cách sử dụng dấu ngắt gỡ lỗi:
System.Data.DataTable SchemaTable = new System.Data.DataTable("@PharmacyData")
{
Columns =
{
{new DataColumn() { ColumnName = "Dosage", DataType = typeof(int)} },
{new DataColumn() { ColumnName = "Drug", DataType = typeof(string), MaxLength = 20} },
{new DataColumn() { ColumnName = "FirstName", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "LastName", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "AddressLine1", DataType = typeof(string), MaxLength = 250} },
{new DataColumn() { ColumnName = "PhoneNumber", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "CellNumber", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "EmailAddress", DataType = typeof(string), MaxLength = 100} },
{new DataColumn() { ColumnName = "Date", DataType = typeof(DateTime)} },
},
Locale = CultureInfo.InvariantCulture
};
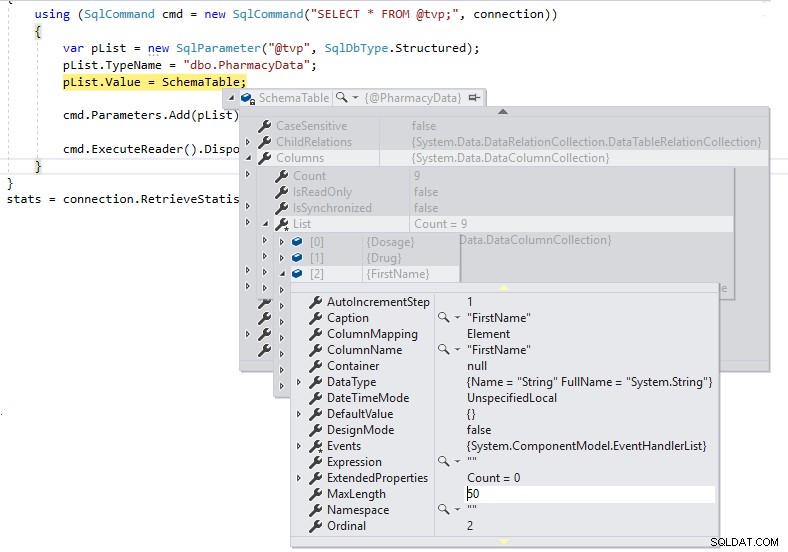
Bây giờ chúng tôi có độ dài chính xác cho các định nghĩa cột và chúng tôi sẽ không chuyển chúng dưới dạng LOB qua TDS tới SQL Server.
Bạn có thể thắc mắc điều này tác động như thế nào đến hiệu suất? Nó ảnh hưởng đến số lượng bộ đệm TDS được gửi qua mạng tới SQL Server và nó cũng ảnh hưởng đến thời gian xử lý tổng thể cho các lệnh.
Việc sử dụng cùng một tập dữ liệu chính xác cho hai bảng dữ liệu và tận dụng phương thức RetrieveSt Statistics trên đối tượng SqlConnection cho phép chúng tôi nhận các chỉ số thống kê ExecutionTime và BuffersSent cho các lệnh gọi đến cùng một lệnh SELECT và chỉ cần sử dụng hai định nghĩa DataTable khác nhau làm tham số và việc gọi phương thức ResetSt Statistics của đối tượng SqlConnection cho phép xóa các số liệu thống kê thực thi giữa các lần kiểm tra.
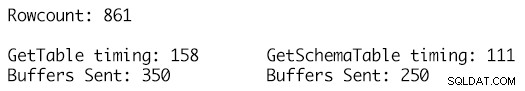
Định nghĩa GetSchemaTable chỉ định MaxLength cho từng cột chuỗi một cách chính xác, trong đó GetTable chỉ thêm các cột của loại chuỗi có giá trị MaxLength được đặt thành -1, dẫn đến 100 bộ đệm TDS bổ sung được gửi cho 861 hàng dữ liệu trong bảng và thời gian chạy là 158 mili giây so với chỉ 250 bộ đệm được gửi cho định nghĩa DataTable được đánh máy mạnh và thời gian chạy là 111 mili giây. Mặc dù điều này có vẻ không nhiều trong kế hoạch tổng thể của mọi thứ, nhưng đây là một cuộc gọi duy nhất, một lần thực hiện duy nhất và tác động tích lũy theo thời gian đối với hàng nghìn hoặc hàng triệu lần thực hiện như vậy là nơi lợi ích bắt đầu cộng lại và có tác động đáng chú ý về hiệu suất khối lượng công việc và thông lượng.
Nơi mà điều này thực sự có thể tạo ra sự khác biệt là trong việc triển khai đám mây, nơi bạn đang trả tiền cho nhiều thứ hơn là chỉ tính toán và tài nguyên lưu trữ. Ngoài việc có chi phí cố định cho tài nguyên phần cứng cho Azure VM, Cơ sở dữ liệu SQL hoặc AWS EC2 hoặc RDS, có một khoản chi phí bổ sung cho lưu lượng mạng đến và đi từ đám mây được tính vào thanh toán cho mỗi tháng. Việc giảm bộ đệm đi qua dây sẽ làm giảm TCO cho giải pháp theo thời gian và các thay đổi mã cần thiết để thực hiện tiết kiệm này tương đối đơn giản.