MariaDB sao chép là một trong những giải pháp tính khả dụng cao phổ biến nhất cho MariaDB và được sử dụng rộng rãi bởi các công ty hàng đầu như Booking.com và Google. Nó rất dễ thiết lập, với một số đánh đổi trong việc bảo trì liên tục như nâng cấp phần mềm, thay đổi lược đồ, thay đổi cấu trúc liên kết, chuyển đổi dự phòng và khôi phục vốn luôn khó khăn. Tuy nhiên, với bộ công cụ phù hợp, bạn sẽ có thể xử lý cấu trúc liên kết một cách dễ dàng. Trong bài đăng trên blog này, chúng ta sẽ xem xét một số mẹo để giám sát sao chép MariaDB một cách hiệu quả bằng cách sử dụng ClusterControl.
Sử dụng Trình xem cấu trúc liên kết
Thiết lập sao chép bao gồm một số vai trò. Một nút trong thiết lập sao chép có thể là:
- Master - Người viết / người đọc chính.
- Bản sao dự phòng - Trình phụ chỉ đọc với tính năng sao chép bán đồng bộ hóa, chỉ dành cho dự phòng chính.
- Bản chính trung gian - Sao chép từ bản chính, trong khi các nô lệ khác sao chép từ nút này.
- Máy chủ binlog - Chỉ thu thập / lưu trữ các binlog mà không cung cấp dữ liệu.
- Slave - Sao chép từ bản chính và thường được đặt là chỉ đọc.
- Máy chủ đa nguồn - Sao chép từ nhiều bản gốc.
Mọi vai trò đều có trách nhiệm và giới hạn riêng của nó và người ta phải hiểu cấu trúc liên kết chính xác khi xử lý các nút cơ sở dữ liệu. Điều này cũng đúng với ứng dụng, trong đó ứng dụng chỉ phải ghi vào nút chính tại bất kỳ thời điểm nào. Do đó, điều quan trọng là phải có một cái nhìn tổng quan về nút nào đang giữ vai trò nào, vì vậy chúng tôi không làm hỏng cơ sở dữ liệu của mình.
Trong ClusterControl, Topology Viewer có thể cung cấp cho bạn cái nhìn tổng quan về cấu trúc liên kết nhân bản và trạng thái của nó, như thể hiện trong ảnh chụp màn hình sau:
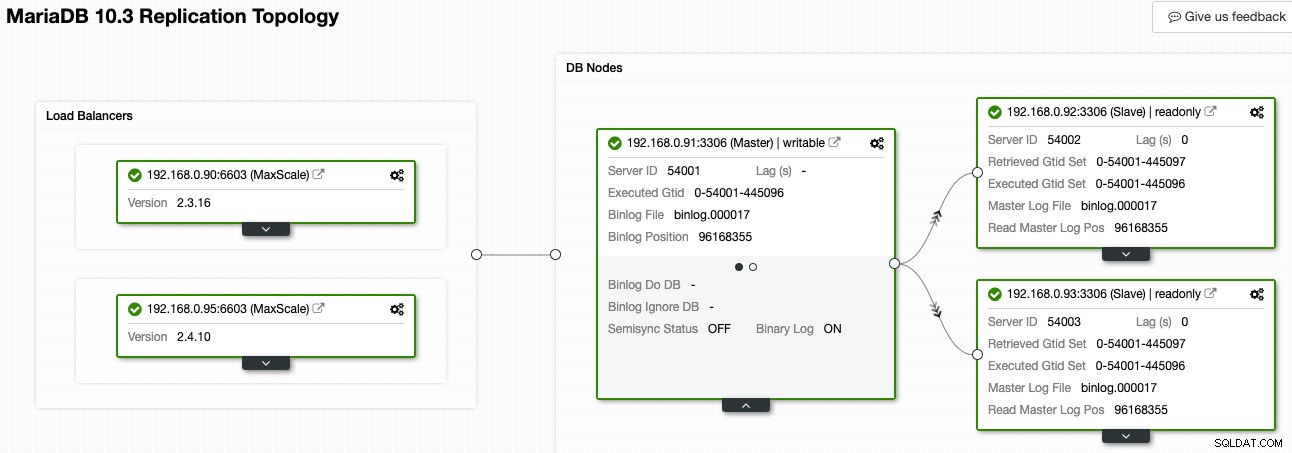
ClusterControl hiểu sao chép MariaDB và có thể trực quan hóa cấu trúc liên kết với luồng dữ liệu sao chép chính xác, như được biểu diễn bằng các mũi tên trỏ đến các nút phụ. Chúng ta có thể dễ dàng phân biệt nút nào là nút chính, nút phụ và bộ cân bằng tải (MaxScale) trong thiết lập sao chép của chúng tôi. Hộp màu xanh lục cho biết tất cả các dịch vụ quan trọng đang chạy như mong đợi với vai trò được chỉ định.
Hãy xem ảnh chụp màn hình sau đây trong đó một số nút của chúng tôi đang gặp sự cố:
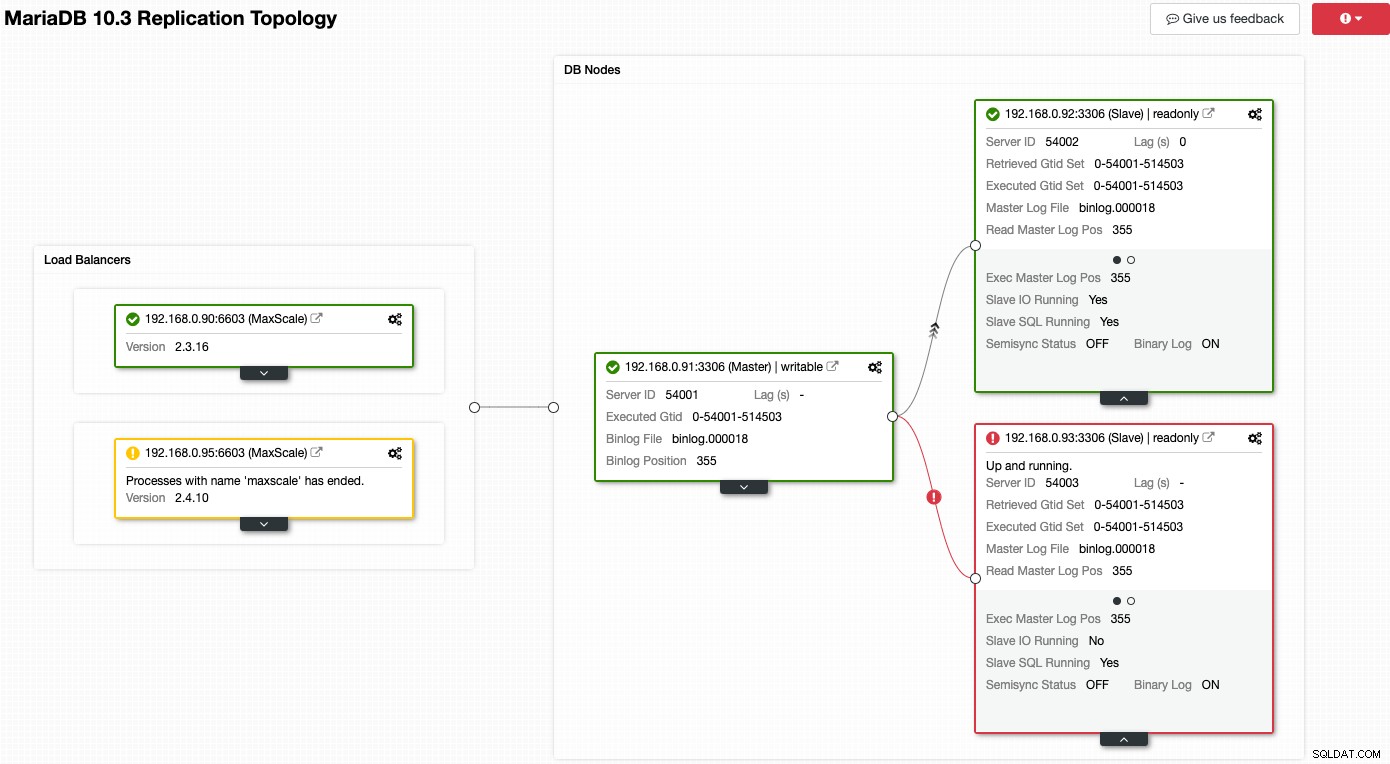
ClusterControl sẽ ngay lập tức cho bạn biết có gì sai với cấu trúc liên kết hiện tại. Một trong các nô lệ (hộp màu đỏ) đang hiển thị "Slave IO Running" là Không, để chỉ ra một số vấn đề kết nối cần sao chép từ chính. Trong khi hộp màu vàng cho thấy dịch vụ MaxScale của chúng tôi không chạy. Chúng tôi cũng có thể nói rằng các phiên bản MaxScale không giống nhau cho cả hai nút. Bạn cũng có thể thực hiện các tác vụ quản lý bằng cách nhấp trực tiếp vào biểu tượng bánh răng (trên cùng bên phải trên mỗi hộp), điều này giúp giảm rủi ro chọn nhầm nút.
Trễ sao chép
Đây là điều quan trọng nhất nếu bạn dựa vào tính nhất quán sao chép dữ liệu. Độ trễ của bản sao xảy ra khi các nô lệ không thể theo kịp các cập nhật xảy ra trên bản chính. Các thay đổi chưa được áp dụng sẽ tích lũy trong nhật ký chuyển tiếp của nô lệ và phiên bản của cơ sở dữ liệu về nô lệ ngày càng trở nên khác biệt so với bản chính.
Trong ClusterControl, bạn có thể tìm thấy biểu đồ độ trễ sao chép trong Tổng quan -> Trễ sao chép trong đó ClusterControl liên tục lấy mẫu giá trị Seconds_Behind_Master từ đầu ra "SHOW SLAVE STATUS":
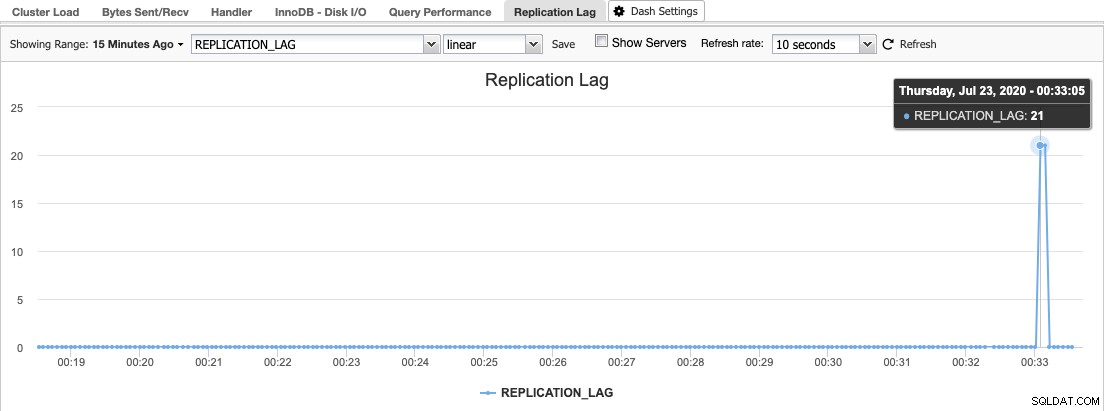
Độ trễ sao chép xảy ra khi Luồng I / O hoặc Luồng SQL không thể đáp ứng các yêu cầu đặt ra. Nếu Luồng I / O gặp sự cố, điều này có nghĩa là kết nối mạng giữa chủ và các nô lệ của nó bị chậm hoặc có vấn đề. Bạn có thể muốn xem xét việc bật slave_compressed_protocol để nén lưu lượng mạng hoặc báo cáo cho quản trị viên mạng của mình.
Nếu đó là chuỗi SQL thì vấn đề có thể là do các truy vấn được tối ưu hóa kém đang khiến nô lệ mất quá nhiều thời gian để áp dụng. Có thể có các giao dịch kéo dài hoặc hoạt động I / O quá nhiều. Không có khóa chính trên các bảng phụ khi sử dụng định dạng sao chép ROW hoặc MIXED cũng là một nguyên nhân phổ biến gây ra độ trễ trên luồng này. Kiểm tra xem phiên bản chính và phụ của bảng có khóa chính hay không.
Một số mẹo và thủ thuật khác được đề cập trong bài đăng blog này, Cách giảm độ trễ của bản sao trong triển khai đa đám mây.
Kích thước nhật ký chuyển tiếp / nhị phân
Điều quan trọng là phải theo dõi kích thước đĩa bản ghi nhị phân và chuyển tiếp vì nó có thể tiêu tốn một lượng lưu trữ đáng kể trên mọi nút trong một cụm sao chép. Thông thường, người ta sẽ đặt biến hệ thống expire_logs_days thành các tệp nhật ký nhị phân tự động hết hạn sau một số ngày nhất định, ví dụ:expire_logs_days =7. Kích thước của nhật ký nhị phân hoàn toàn phụ thuộc vào số lượng sự kiện nhị phân được tạo (ghi đến) và chúng ta ít biết rằng nó sẽ tiêu tốn bao nhiêu dung lượng đĩa trước khi MariaDB hết hạn nhật ký. Hãy nhớ rằng nếu bạn bật log_slave_updates trên các nô lệ, kích thước của các bản ghi sẽ tăng gần gấp đôi do sự tồn tại của cả bản ghi nhị phân và bản ghi chuyển tiếp trên cùng một máy chủ.
Đối với ClusterControl, chúng ta có thể đặt ngưỡng sử dụng dung lượng ổ đĩa trong ClusterControl -> Cài đặt -> Ngưỡng để nhận cảnh báo và thông báo quan trọng như sau:
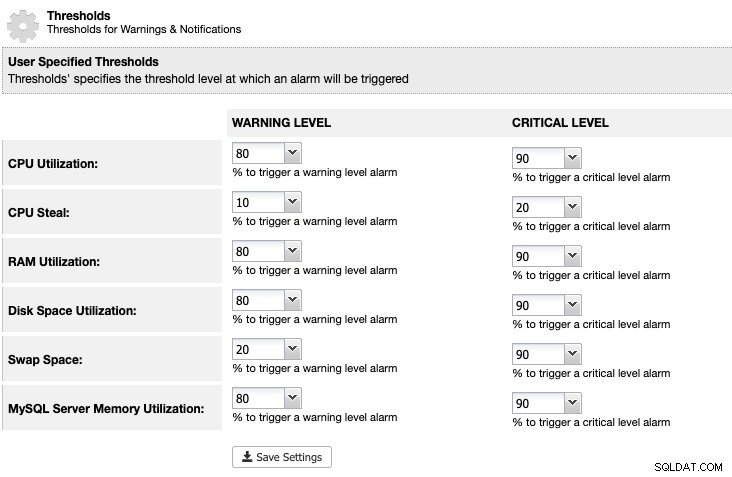
ClusterControl giám sát tất cả dung lượng ổ đĩa liên quan đến dịch vụ MariaDB như vị trí của dữ liệu MariaDB thư mục, thư mục nhật ký nhị phân và cả phân vùng gốc. Nếu bạn đã đạt đến ngưỡng, hãy xem xét xóa các nhật ký nhị phân theo cách thủ công bằng cách sử dụng lệnh PURGE BINARY LOGS, như được giải thích và thảo luận trong bài viết này.
Bật Trang tổng quan giám sát
ClusterControl cung cấp hai tùy chọn giám sát để lấy mẫu các nút cơ sở dữ liệu - không tác nhân hoặc dựa trên tác nhân. Mặc định là không có tác nhân trong đó lấy mẫu xảy ra qua SSH trong cơ chế chỉ kéo. Giám sát dựa trên tác nhân yêu cầu máy chủ Prometheus đang chạy và tất cả các nút được giám sát phải được định cấu hình với ít nhất ba nhà xuất:
- Nhà xuất khẩu chế biến (cổng 9011)
- Trình xuất số liệu hệ thống / nút (cổng 9100)
- Trình xuất MySQL / MariaDB (cổng 9104)
Để bật bảng điều khiển giám sát dựa trên tác nhân, người ta phải đi tới ClusterControl -> Bảng điều khiển -> Bật theo dõi dựa trên tác nhân. Sau khi được kích hoạt, bạn sẽ thấy một tập hợp các trang tổng quan được định cấu hình cho bản sao MariaDB của chúng tôi, giúp chúng ta có cái nhìn sâu sắc hơn về thiết lập bản sao của chúng ta. Ảnh chụp màn hình sau đây cho thấy những gì bạn sẽ thấy đối với nút chính:
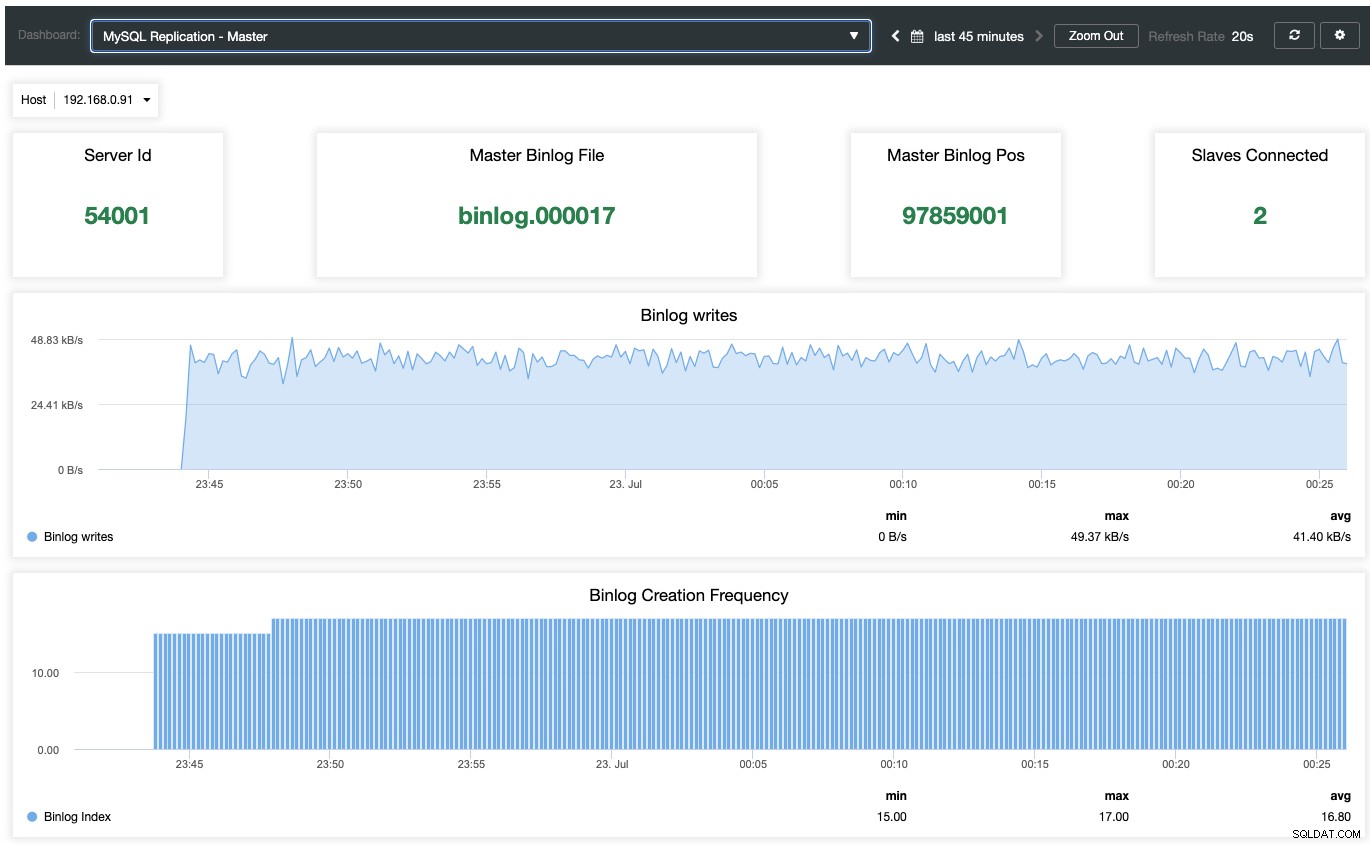
Ngoài bảng điều khiển giám sát tiêu chuẩn MariaDB như chung, bộ nhớ đệm và chỉ số InnoDB, bạn sẽ được trình bày với một bảng điều khiển nhân rộng. Đối với nút chính, chúng ta có thể nhận được nhiều thông tin hữu ích về trạng thái của nút chính, thông lượng ghi và tần suất tạo binlog.
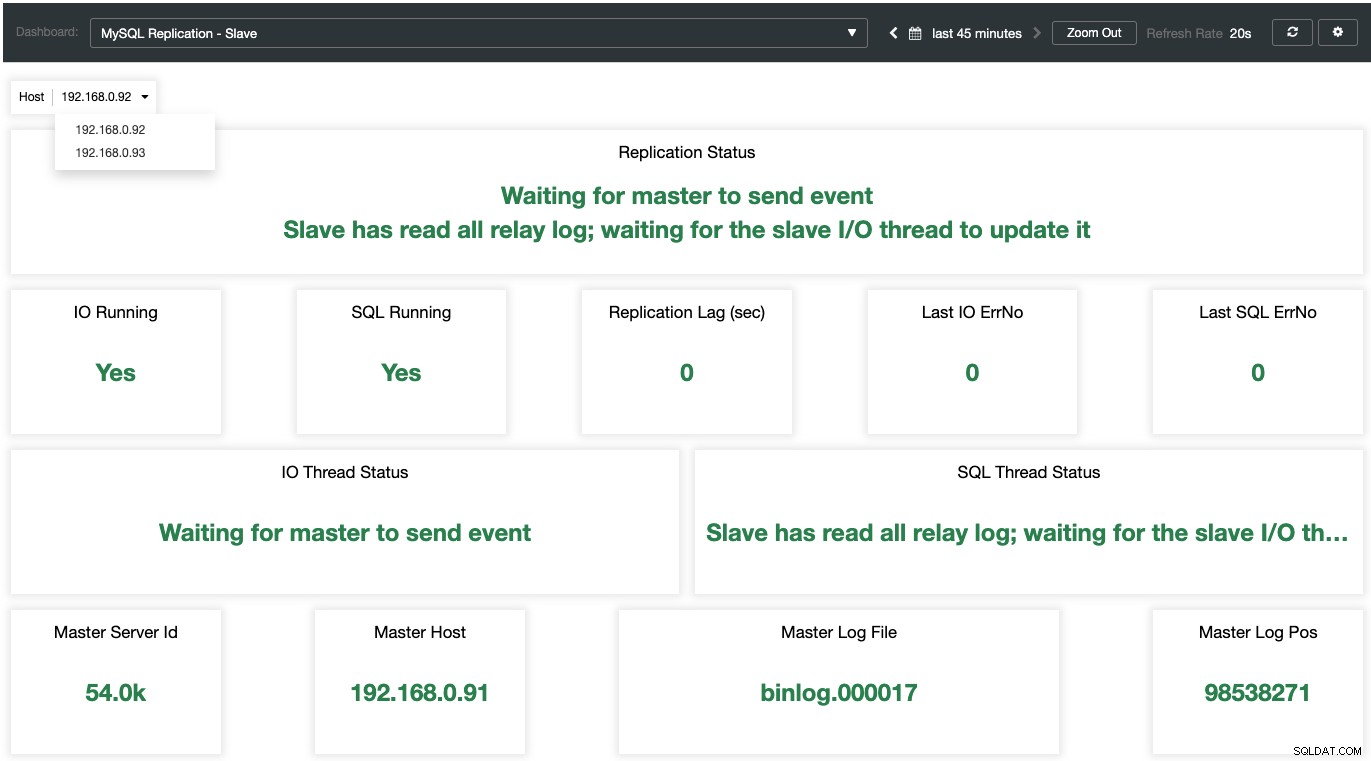
Trong khi đối với nô lệ, tất cả các trạng thái quan trọng được lấy mẫu và tóm tắt như ảnh chụp màn hình sau. nếu mọi thứ đều xanh, bạn đang ở trong tay tốt:
Hiểu Nhật ký Lỗi MariaDB
MariaDB ghi lại các sự kiện quan trọng của nó bên trong nhật ký lỗi, điều này rất hữu ích để hiểu những gì đang xảy ra với máy chủ, đặc biệt là trước, trong và sau khi thay đổi cấu trúc liên kết. ClusterControl cung cấp chế độ xem tập trung các nhật ký lỗi trong ClusterControl -> Nhật ký -> Nhật ký Hệ thống bằng cách kéo chúng từ mọi nút cơ sở dữ liệu. Bạn nhấp vào "Làm mới Nhật ký" để kích hoạt một công việc để lấy các bản ghi mới nhất từ máy chủ.
Các tệp đã thu thập được thể hiện trong cấu trúc cây điều hướng và vùng văn bản có tô sáng cú pháp để dễ đọc hơn:
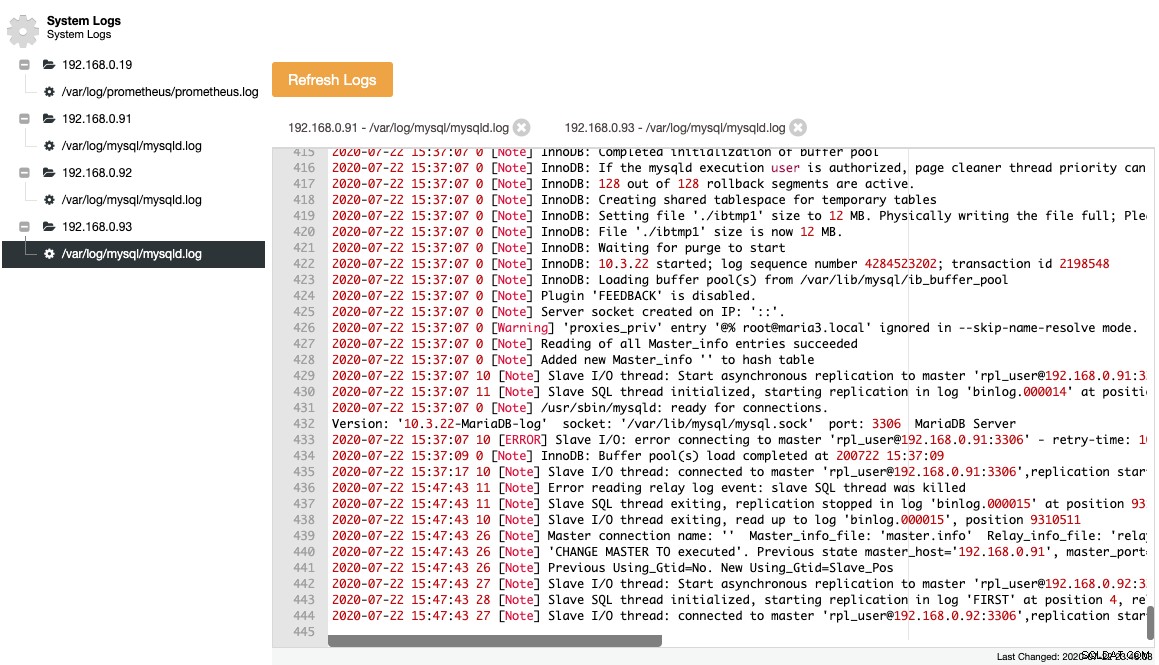
Từ ảnh chụp màn hình ở trên, chúng ta có thể hiểu chuỗi sự kiện và điều gì đã xảy ra với nút này trong sự kiện thay đổi cấu trúc liên kết. Từ 12 dòng cuối cùng của nhật ký lỗi ở trên, máy phụ đã gặp lỗi khi kết nối với cái chính và tệp nhật ký nhị phân cuối cùng và vị trí đã được ghi lại trong nhật ký trước khi nó dừng lại. Sau đó, lệnh CHANGE MASTER mới hơn được thực thi với thông tin GTID, như được hiển thị trong dòng "Trước dùng_Gtid =Không. Mới dùng_Gtid =Slave_Pos" và sau đó bản sao tiếp tục lại như những gì chúng ta muốn.
Cảnh báo và Thông báo của MariaDB
Việc giám sát không hoàn thành nếu không có cảnh báo và thông báo. Tất cả các sự kiện và cảnh báo được tạo bởi ClusterControl có thể được gửi tới email hoặc bất kỳ công cụ nào khác được hỗ trợ của bên thứ ba. Đối với thông báo qua email, người ta có thể định cấu hình xem loại sự kiện sẽ được gửi ngay lập tức, bị bỏ qua hay được tiêu hóa (báo cáo tóm tắt hàng ngày):

Đối với tất cả các sự kiện nghiêm trọng quan trọng, bạn nên đặt mọi thứ thành "Phân phối" để bạn nhận được thông báo sớm nhất có thể. Đặt "Thông báo" thành các sự kiện cảnh báo để bạn biết rõ về trạng thái và trạng thái của cụm.
Bạn có thể tích hợp các công cụ liên lạc và nhắn tin ưa thích của mình với ClusterControl bằng cách sử dụng tính năng Quản lý thông báo trong ClusterControl -> Tích hợp -> Thông báo của bên thứ ba. ClusterControl có thể gửi cảnh báo và sự kiện tới PagerDuty, VictorOps, OpsGenie, Slack, Telegram, ServiceNow hoặc bất kỳ webhook nào do người dùng đăng ký.
Ảnh chụp màn hình sau đây cho thấy tất cả các sự kiện quan trọng sẽ được đẩy sang kênh điện tín đã định cấu hình cho cụm sao MariaDB 10.3 của chúng tôi:

ClusterControl cũng hỗ trợ tích hợp chatbot, nơi bạn có thể tương tác với dịch vụ bộ điều khiển thông qua ứng dụng khách s9s ngay từ công cụ nhắn tin của bạn như được hiển thị trong bài đăng blog này, Tự động hóa cơ sở dữ liệu của bạn với CCBot:ClusterControl Hubot Integration.
Kết luận
ClusterControl cung cấp một bộ hoàn chỉnh các công cụ giám sát chủ động cho các cụm cơ sở dữ liệu của bạn. Sử dụng ClusterControl để giám sát thiết lập sao chép MariaDB của bạn vì hầu hết các tính năng giám sát đều có sẵn miễn phí trong phiên bản cộng đồng. Đừng bỏ lỡ những điều đó!