“Bàn chờ giúp chúng tôi xác định các quầy liên quan đến hiệu suất. Nhưng bản thân việc chờ đợi thông tin không đủ để chẩn đoán chính xác các vấn đề về hiệu suất. Thành phần hàng đợi của phương pháp luận của chúng tôi đến từ bộ đếm Màn hình hiệu suất, bộ đếm này cung cấp cái nhìn về hiệu suất hệ thống từ quan điểm tài nguyên. ”Tom Davidson, Mở Hộp công cụ Điều chỉnh Hiệu suất của Microsoft
Tạp chí SQL Server Pro, tháng 12 năm 2003
Waits và Queues đã được sử dụng như một phương pháp điều chỉnh hiệu suất SQL Server kể từ khi Tom Davidson xuất bản bài viết trên cũng như báo cáo chính thức nổi tiếng về Waits and Queues của SQL Server 2005 vào năm 2006. Khi được áp dụng kết hợp với các chỉ số tài nguyên, các lượt chờ có thể có giá trị đối với đánh giá các đặc điểm hoạt động nhất định của khối lượng công việc và hỗ trợ trong các nỗ lực điều chỉnh chỉ đạo. Dữ liệu chờ được hiển thị bởi nhiều giải pháp giám sát hiệu suất của SQL Server và tôi đã ủng hộ việc điều chỉnh bằng phương pháp này ngay từ đầu. Cách tiếp cận này có ảnh hưởng đến việc thiết kế bảng điều khiển hiệu suất SQL Sentry, bảng điều khiển này trình bày các lần chờ xếp hàng (số liệu tài nguyên chính) để cung cấp một cái nhìn toàn diện về hiệu suất máy chủ.
Tuy nhiên, một số dường như đã bỏ qua quan điểm của Davidson về tầm quan trọng của tài nguyên và hầu như dựa hoàn toàn vào việc chờ đợi để trình bày bức tranh về hiệu suất truy vấn và tình trạng hệ thống. Số liệu thống kê chờ đến trực tiếp từ công cụ SQL Server và dễ sử dụng và phân loại. Truy vấn chờ đợi có nghĩa là các ứng dụng và người dùng đang đợi, và không ai thích đợi! Việc điều chỉnh bằng chờ đợi sẽ dễ dàng hơn để truyền bá phúc âm hóa là giải pháp duy nhất để thực hiện các truy vấn và ứng dụng nhanh hơn so với việc kể toàn bộ câu chuyện, điều này có liên quan nhiều hơn.
Thật không may, cách tiếp cận tập trung vào sự chờ đợi để loại trừ phân tích tài nguyên có thể gây hiểu lầm và trường hợp xấu nhất khiến bạn bị mù. Các thành viên của nhóm SentryOne là Kevin Kline và Steve Wright trước đây đã đề cập đến vấn đề này ở đây và ở đây. Trong bài đăng này, tôi sẽ đi sâu hơn vào một số nghiên cứu gần đây do Query Store thực hiện đã làm sáng tỏ mới về cách thực sự có thể thực sự điều chỉnh độc quyền chờ thiếu.
Các truy vấn hàng đầu không có
Gần đây, một khách hàng của SentryOne đã liên hệ với tôi về những lo ngại về hiệu suất với cơ sở dữ liệu SentryOne của họ. Có một cơ sở dữ liệu SQL Server duy nhất ở trung tâm của mọi môi trường giám sát SentryOne và khách hàng này đã giám sát khoảng 600 máy chủ bằng phần mềm của chúng tôi. Ở quy mô đó, không lạ khi thấy vấn đề hiệu suất truy vấn không thường xuyên và thực hiện một chút điều chỉnh và một số truy vấn được cho là mới trong khối lượng công việc là nguồn gốc của mối quan tâm của họ.
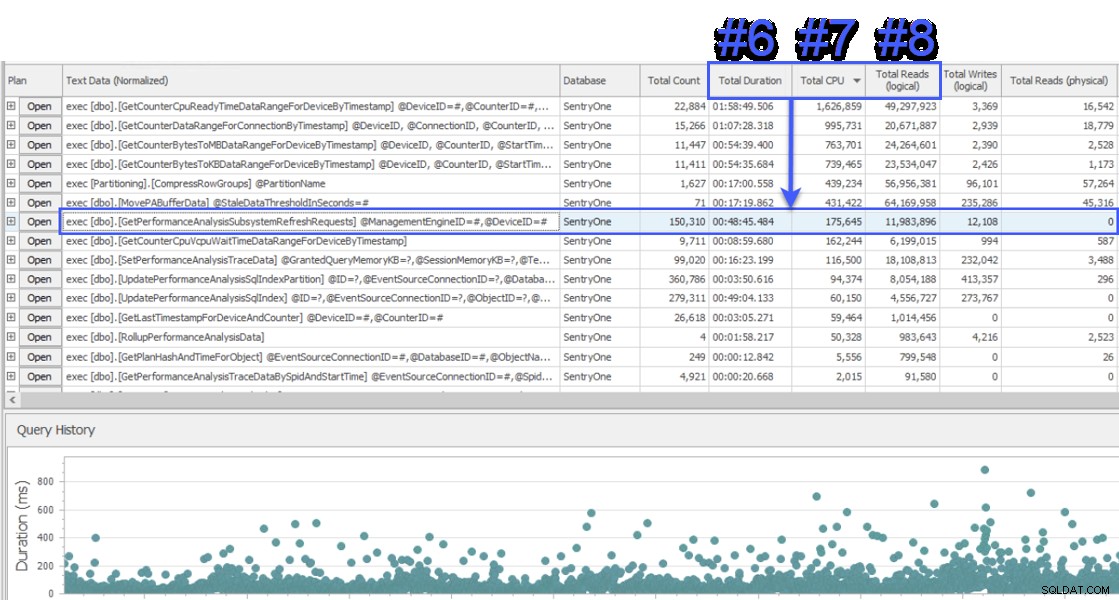
Tôi đã tham gia một phiên chia sẻ màn hình để xem xét và khách hàng lần đầu tiên giới thiệu cho tôi dữ liệu từ một hệ thống khác cũng đang theo dõi cơ sở dữ liệu SentryOne. Hệ thống đã sử dụng phương pháp chờ cấp độ truy vấn và hiển thị hai thủ tục được lưu trữ chịu trách nhiệm cho khoảng một nửa số lần chờ trên máy chủ cơ sở dữ liệu SQL Sentry. Điều này là không bình thường vì hai thủ tục này luôn chạy rất nhanh và chưa bao giờ cho thấy sự cố hiệu suất thực sự trong cơ sở dữ liệu của chúng tôi. Băn khoăn, tôi chuyển sang SQL Sentry để xem nó sẽ hiển thị gì cho chúng ta và rất ngạc nhiên khi thấy rằng trong cùng một khoảng thời gian, thủ tục số 1 trong hệ thống khác là # 6, # 7 và # 8 về tổng thời lượng, CPU và lần lượt đọc logic:
 Chế độ xem “SQL hàng đầu” của SQL Sentry
Chế độ xem “SQL hàng đầu” của SQL Sentry
Từ quan điểm tiêu thụ tài nguyên, điều này có nghĩa là các truy vấn trên nó chiếm 75% tổng thời lượng, 87% tổng CPU và 88% số lần đọc logic. Hơn nữa, thủ tục số 2 trong hệ thống khác thậm chí còn không nằm trong top 30 trong SQL Sentry, bằng bất kỳ biện pháp nào! Hai truy vấn này khác xa so với 2 truy vấn hàng đầu và các truy vấn chiếm hầu hết các truy vấn thực tế mức tiêu thụ trên hệ thống đang được trình bày thiếu nghiêm túc.
Tôi đã luôn cho rằng có mối tương quan chặt chẽ hơn giữa những người phục vụ hàng đầu và những người tiêu dùng tài nguyên hàng đầu nhưng chưa bao giờ thực hiện so sánh cấp độ truy vấn trực tiếp như thế này, vì vậy những kết quả này ít nhất là đáng ngạc nhiên. Sự quan tâm của tôi dấy lên, tôi quyết định điều tra để xác định xem tình huống này là điển hình hay bất thường.
Cửa hàng truy vấn giải cứu năm 2017
Trong SQL Server 2017 trở lên, Cửa hàng truy vấn nắm bắt các lần chờ cấp truy vấn ngoài việc tiêu thụ tài nguyên truy vấn. Erin Stellato đã thực hiện một bài đăng tuyệt vời trên Query Store chờ ở đây. Nó có chi phí thấp hơn và chính xác hơn so với việc truy vấn chờ DMV mỗi giây với hy vọng bắt được các truy vấn trong chuyến bay, cách tiếp cận tiêu chuẩn được sử dụng bởi các công cụ khác bao gồm cả phương pháp đã nói ở trên.
SQL Sentry luôn nắm bắt được các lần đợi nhưng ở cấp phiên bản SQL Server, do những lo ngại này về chi phí và độ chính xác. Các lượt chờ truy vấn chi tiết có sẵn theo yêu cầu thông qua Plan Explorer được tích hợp và chúng tôi đang đánh giá các lượt chờ ở cấp phiên bản bổ sung với dữ liệu cấp truy vấn từ Cửa hàng truy vấn, nếu có.
Đối với nỗ lực này, tôi đã tranh thủ sự giúp đỡ của Hội đồng cố vấn sản phẩm SentryOne, một nhóm khách hàng, đối tác và bạn bè của SentryOne trong ngành tham gia vào kênh Slack riêng. Tôi đã chia sẻ tập lệnh này để kết xuất dữ liệu 8 giờ trước đó từ Cửa hàng truy vấn và nhận lại kết quả cho 11 máy chủ sản xuất trên nhiều ngành dọc bao gồm dịch vụ tài chính, xuất bản trò chơi, theo dõi sức khỏe và bảo hiểm.
Danh mục chờ của Cửa hàng truy vấn được ghi lại ở đây. Tất cả các danh mục đều được đưa vào phân tích ngoại trừ những danh mục này đã bị xóa vì những lý do được trích dẫn:
- Song song - Nó có thể làm tăng quá mức thời gian chờ của truy vấn lên quá thời lượng thực của nó vì nhiều chuỗi có thể loại bỏ thời gian chờ liên quan, gây nhiễu tương quan với thời lượng và các chỉ số khác. Hơn nữa, mặc dù phần tách CXPACKET / CXCONSUMER rất hữu ích, nhưng CXPACKET vẫn chỉ có nghĩa là bạn có song song và không nhất thiết là vấn đề hoặc có thể hành động.
- CPU - Thời gian chờ tín hiệu có thể hữu ích để xác định sự tắc nghẽn của CPU thông qua mối tương quan với thời gian chờ tài nguyên, nhưng Cửa hàng truy vấn hiện chỉ bao gồm SOS_SCHEDULER_YIELD trong danh mục này, không phải là thời gian chờ theo nghĩa truyền thống như được đề cập ở đây. Bản thân nó không cho phép so sánh hoặc tương quan dễ dàng, đặc biệt là khi SQL Server nằm trên một máy ảo sống trên một máy chủ được đăng ký quá mức. Ví dụ:trên một máy chủ, số lần chờ đợi của CPU trong Cửa hàng truy vấn là 227% tổng thời gian CPU trên tất cả các truy vấn mà không có bất kỳ sự song song nào, điều này không thể thực hiện được.
- Người dùng chờ và Không hoạt động - Các danh mục này chỉ bao gồm hẹn giờ và hàng đợi và đã bị loại trừ vì cùng một lý do nên luôn loại trừ những loại này - chúng vô hại và chỉ tạo ra tiếng ồn.
Ngoài ra, gần đây tôi đã nói chuyện với cha đẻ của Cửa hàng truy vấn, Conor Cunningham, về khả năng thay đổi trong tương lai đối với các loại và danh mục chờ trong Cửa hàng truy vấn và ông ấy chỉ ra rằng điều đó chắc chắn có thể xảy ra… vì vậy chúng tôi sẽ cần theo dõi nó.
Kết quả phân tích TL; DR
Sau khi phân tích sâu rộng, tôi đã xác nhận rằng các kết quả quan sát được trên hệ thống khách hàng không phải là bất thường, mà là bình thường. Điều này có nghĩa là nếu bạn phụ thuộc vào một công cụ tập trung vào sự chờ đợi để theo dõi và điều chỉnh khối lượng công việc của mình, thì có khả năng cao là bạn đang tập trung vào các truy vấn sai và thiếu những người chịu trách nhiệm cho hầu hết thời lượng truy vấn và mức tiêu thụ tài nguyên trên hệ thống. Vì mức tiêu thụ CPU và IO chuyển trực tiếp sang phần cứng máy chủ và chi tiêu trên đám mây, điều này rất quan trọng.
Hầu hết các truy vấn đều không đợi
Một phát hiện thú vị và quan trọng mà tôi sẽ đề cập trước tiên là hầu hết các truy vấn hoàn toàn không tạo ra bất kỳ sự chờ đợi nào. Trong tổng số 56.438 truy vấn trên tất cả các máy chủ, chỉ có 9.781 (17%) có thời gian chờ và chỉ 8.092 (14%) có thời gian chờ từ các loại đáng kể. Nếu bạn đang sử dụng chỉ đợi để xác định truy vấn nào cần tối ưu hóa, bạn sẽ bỏ lỡ hầu hết các truy vấn trong khối lượng công việc.
Sự chờ đợi và Tài nguyên có Tương quan
Tôi đã phân tích mức độ liên quan của sự chờ đợi với mức tiêu thụ tài nguyên bằng cách xếp hạng tất cả các truy vấn trên mỗi hệ thống theo lượt chờ và tài nguyên và sử dụng các cấp bậc để tính toán mối tương quan của Spearman. Điều cuối cùng chúng tôi đang cố gắng xác định là liệu những người phục vụ hàng đầu có xu hướng trở thành người tiêu dùng hàng đầu hay không. Hóa ra, họ không.
Bảng 1 hiển thị hệ số tương quan theo tỷ lệ màu cho truy vấn trung bình đợi thời gian đối với các thước đo khác - giá trị 1,00 (xanh lam đậm) thể hiện dữ liệu tương quan hoàn hảo. Như bạn có thể thấy, mối tương quan với lượt chờ và các thước đo khác trên hầu hết các máy chủ là không mạnh và đối với một máy chủ, có mối tương quan nghịch với hầu hết các thước đo.
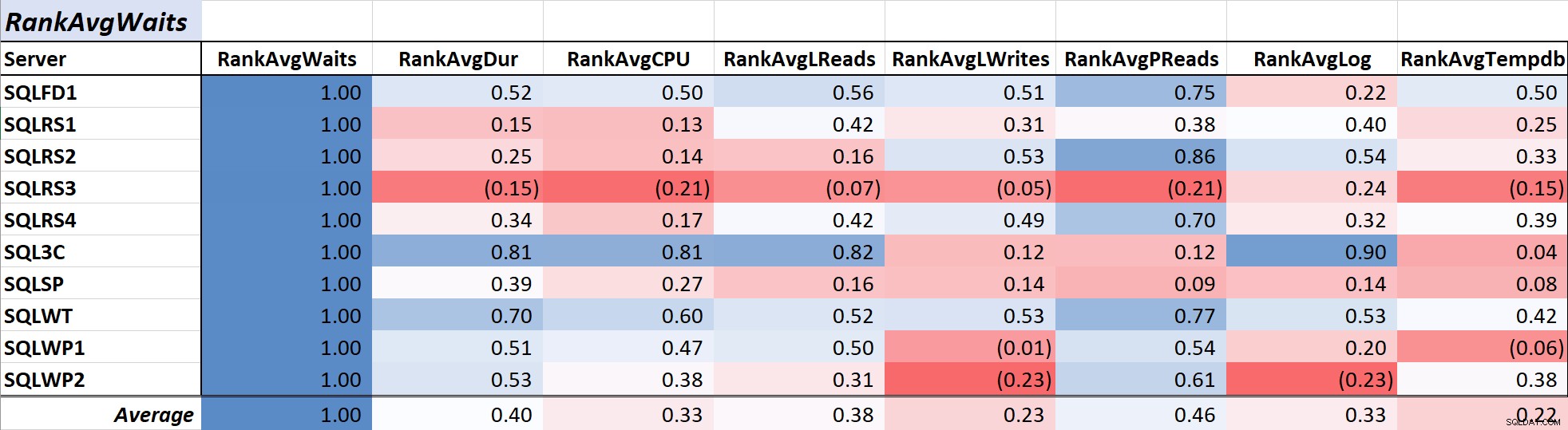 Bảng 1:Tương quan với thời gian chờ truy vấn trung bình (mili giây)
Bảng 1:Tương quan với thời gian chờ truy vấn trung bình (mili giây)
Thời lượng truy vấn thường là mối quan tâm chính đối với DBA và nhà phát triển vì nó chuyển trực tiếp sang trải nghiệm người dùng và Bảng 2 cho thấy mối tương quan giữa thời lượng truy vấn trung bình và các biện pháp khác. Mối tương quan với thời lượng và hai thước đo tài nguyên chính, CPU và đọc logic, khá mạnh ở mức 0,97 và 0,75 tương ứng.
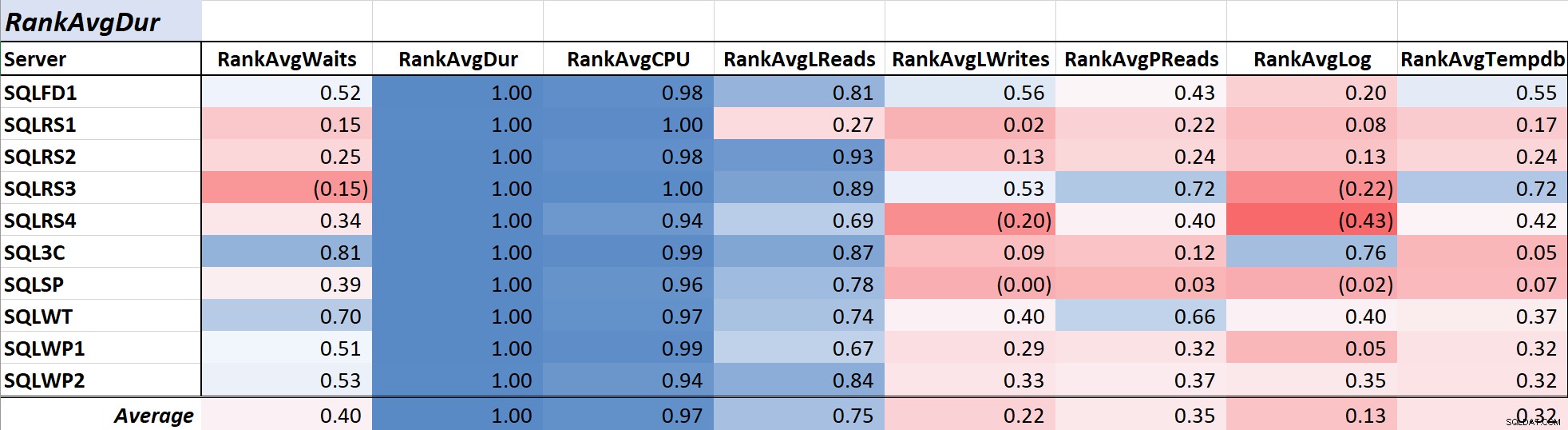 Bảng 2:Tương quan với Thời lượng truy vấn trung bình (mili giây)
Bảng 2:Tương quan với Thời lượng truy vấn trung bình (mili giây)
Vì các lần đọc logic luôn sử dụng CPU và giống như thời lượng, CPU được đo bằng mili giây, mối quan hệ này không có gì đáng ngạc nhiên. Kết quả phù hợp với ý tưởng rằng nếu bạn muốn các ứng dụng cơ sở dữ liệu của mình chạy nhanh nhất có thể, thì việc tập trung vào việc giảm CPU truy vấn và đọc logic sẽ hiệu quả hơn trong việc giảm thời lượng so với việc sử dụng các lượt chờ một mình. May mắn thay, làm như vậy thông qua thiết kế truy vấn tốt hơn, lập chỉ mục, v.v. thường là một đề xuất đơn giản hơn là giảm thời gian chờ truy vấn trực tiếp. Đồng nghiệp Aaron Bertrand trình bày hiệu quả một số lưu ý khi điều chỉnh các lượt chờ ở đây.
% tổng thời gian chờ
Tiếp theo, tôi xem xét liệu các truy vấn có thời gian chờ cao nhất có xu hướng tiêu tốn nhiều tài nguyên nhất hay không. Chúng tôi muốn xác định xem những gì chúng tôi thấy trên hệ thống khách hàng có phải là không điển hình hay không, trong đó 2 truy vấn chờ hàng đầu chiếm một tỷ lệ tương đối nhỏ trong tổng mức tiêu thụ tài nguyên.
Biểu đồ 1 bên dưới hiển thị% tổng số CPU và số lần đọc logic cho mỗi máy chủ được tính bởi các truy vấn đại diện cho 75% tổng thời gian chờ. Chỉ một máy chủ có tài nguyên vượt quá 75% - đọc trên SQLRS3. Đối với phần còn lại, các truy vấn chịu trách nhiệm cho 75% thời gian chờ tiêu thụ ít hơn 75% tài nguyên - thường ít hơn rất nhiều. Điều này phản ánh những gì chúng tôi đã thấy trên hệ thống khách hàng và phù hợp với phân tích tương quan.
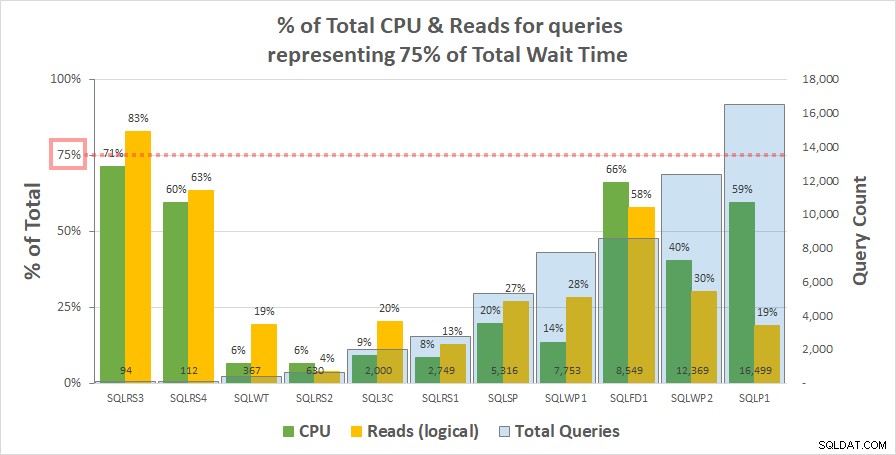 Biểu đồ 1
Biểu đồ 1
Lưu ý rằng dường như có mối quan hệ với tổng số truy vấn trong khối lượng công việc. Điều này được thể hiện bằng chuỗi cột màu xanh lam nhạt trên trục y phụ và biểu đồ được sắp xếp tăng dần theo chuỗi này. Hai máy chủ có số đo tài nguyên cao nhất ở 75% thời gian chờ cũng có ít truy vấn nhất (SQLRS3 và SQLRS4). Khối lượng công việc đặt càng nhỏ thì ảnh hưởng tiềm tàng của một số lượng nhỏ truy vấn càng lớn và chắc chắn, trên cả hai máy chủ, chỉ có hai truy vấn chiếm hầu hết các lượt chờ và tài nguyên. Một cách để xem xét vấn đề này là chờ hầu hết trợ giúp để xác định các truy vấn nặng nhất của bạn khi bạn ít cần nó nhất.
Thời gian chờ và thời lượng truy vấn
Cuối cùng, tôi đã đánh giá% tổng thời gian chờ trên tổng thời lượng truy vấn trên mỗi hệ thống. Bảng 3 có các cột cho:
- Tổng thời lượng truy vấn tính bằng mili giây
- Tổng thời gian chờ mili giây - thô
- Tổng thời gian chờ tính bằng mili giây - không tính Song song, Không hoạt động và Người dùng chờ (Rev1)
- Tổng thời gian chờ mili giây - không tính Song song, Không hoạt động, Người dùng chờ và CPU (Rev2)
- % thời lượng cho 3 cột thời gian chờ, với các thanh dữ liệu
- Tổng số truy vấn duy nhất, với các thanh dữ liệu
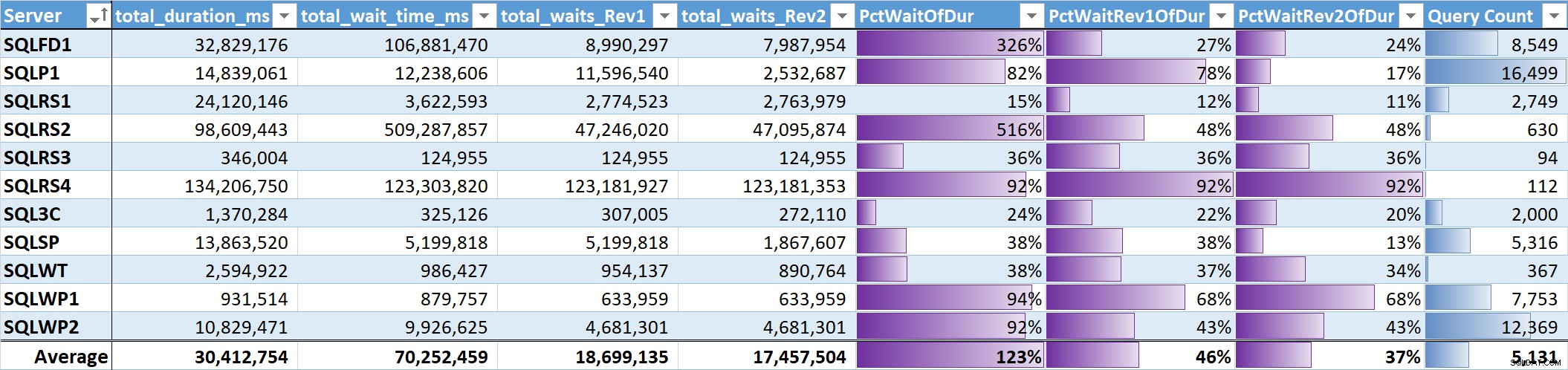 Bảng 3
Bảng 3
Mức trung bình không có trọng số cho số lần chờ đợi có ý nghĩa (Rev2) trên tất cả các hệ thống là 37% tổng thời lượng truy vấn. Trên năm hệ thống, tỷ lệ này thấp hơn 25% và chỉ có hai hệ thống là trên 50%. Trên hệ thống có 92% thời gian chờ (SQLRS4), một hệ thống có ít truy vấn nhất, hai truy vấn chiếm 99% thời gian chờ, 97% thời lượng, 84% CPU và 86% lượt đọc.
Mặc dù thời gian chờ có thể đại diện cho một phần đáng kể thời gian chạy truy vấn trên một số hệ thống nhất định và có vẻ trực quan rằng nếu bạn giảm thời gian chờ thì thời gian truy vấn cũng sẽ giảm xuống, chúng tôi nhận thấy rằng thời gian chờ và thời lượng có tương quan yếu. Điều đó khó có thể đơn giản như vậy, và kinh nghiệm của riêng tôi chứng thực điều này. Cần nghiên cứu thêm ở đây.
Điều chỉnh toàn diện với Plan Explorer và SQL Sentry
Như whitepaper SQLskills tuyệt vời này thường xuyên gợi ý, gốc rễ của các lần chờ đợi cao thường là các truy vấn và chỉ mục chưa được tối ưu hóa. SentryOne Plan Explorer miễn phí được xây dựng nhằm mục đích giảm tiêu thụ tài nguyên thông qua điều chỉnh truy vấn hiệu quả bằng cách sử dụng mô-đun Phân tích Chỉ mục và nhiều tính năng cải tiến khác. SQL Sentry tích hợp Plan Explorer trực tiếp vào các mô-đun SQL Top, Blocking và Deadlocks, vì vậy bạn có thể tự động nắm bắt và điều chỉnh các truy vấn có vấn đề ở một nơi. Bạn có thể dễ dàng chọn phạm vi quan tâm trên các biểu đồ lịch sử đợi, CPU hoặc IO của bảng điều khiển SQL Sentry và chuyển đến chế độ xem SQL Hàng đầu để tìm các truy vấn tiêu tốn tài nguyên hàng đầu trong thời gian đó. Sau đó, chỉ với một cú nhấp chuột, bạn có thể mở một truy vấn trong Plan Explorer và nhận các lần đợi cấp truy vấn chi tiết và tài nguyên theo yêu cầu khi cần thiết. Tôi không nghĩ rằng có một phương pháp nào tốt hơn cho phương pháp điều chỉnh Chờ và Hàng đợi đầy đủ hơn phương pháp này.
 Biểu đồ “Chờ” của Bảng điều khiển SQL Sentry
Biểu đồ “Chờ” của Bảng điều khiển SQL Sentry
 SentryOne Plan Explorer miễn phí hiển thị thời gian chờ, cùng với cấp hoạt động chi phí và tài nguyên
SentryOne Plan Explorer miễn phí hiển thị thời gian chờ, cùng với cấp hoạt động chi phí và tài nguyên
Kết luận
Việc điều chỉnh với các lượt đợi và hàng đợi cũng áp dụng cho hiệu suất SQL Server ngày nay giống như nó đã trở lại vào năm 2006. Tuy nhiên, việc tập trung vào việc chờ đợi để loại trừ tài nguyên là một công việc nguy hiểm, vì rõ ràng từ dữ liệu rằng làm như vậy sẽ dẫn đến việc thường không được tối ưu hóa và các hệ thống không hiệu quả về chi phí. Khi nói đến tài nguyên phần cứng và chi tiêu cho đám mây, cuối cùng bạn đang trả tiền cho tài nguyên máy tính và IO, chứ không phải thời gian chờ đợi, vì vậy cần tối ưu hóa trực tiếp cho tiêu dùng. Theo kinh nghiệm của tôi, khi mức tiêu thụ tài nguyên và sự tranh chấp liên quan được giảm xuống, thời gian chờ đợi sẽ giảm xuống một cách tự nhiên.
Lời cảm ơn
Tôi muốn cảm ơn Fred Frost, Nhà khoa học dữ liệu hàng đầu tại SentryOne, vì những đóng góp quý giá và đánh giá quan trọng của anh ấy về phân tích này.