PostgreSQL là một dự án tuyệt vời và nó phát triển với tốc độ đáng kinh ngạc. Chúng tôi sẽ tập trung vào sự phát triển của khả năng chịu lỗi trong PostgreSQL trong suốt các phiên bản của nó với một loạt bài đăng trên blog. Đây là bài đăng thứ ba của loạt bài này và chúng ta sẽ nói về các vấn đề về dòng thời gian và ảnh hưởng của chúng đối với khả năng chịu lỗi và độ tin cậy của PostgreSQL.
Nếu bạn muốn chứng kiến quá trình phát triển từ đầu, vui lòng kiểm tra hai bài đăng blog đầu tiên của loạt bài:
- Sự phát triển của khả năng chịu lỗi trong PostgreSQL
- Sự phát triển của khả năng chịu lỗi trong PostgreSQL:Giai đoạn tái tạo

Lịch trình
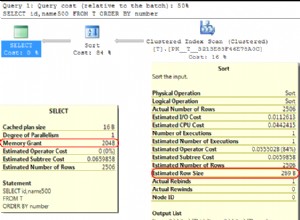
Khả năng khôi phục cơ sở dữ liệu về thời điểm trước đó tạo ra một số phức tạp mà chúng tôi sẽ đề cập đến một số trường hợp bằng cách giải thích chuyển đổi dự phòng (Hình 1), chuyển đổi (Hình 2) và pg_rewind (Hình 3) các trường hợp sau trong chủ đề này.
Ví dụ:trong lịch sử ban đầu của cơ sở dữ liệu, giả sử bạn đã bỏ một bảng quan trọng vào lúc 5:15 chiều tối Thứ Ba, nhưng không nhận ra sai lầm của mình cho đến trưa Thứ Tư. Ở chế độ không mặc định, bạn lấy bản sao lưu của mình ra, khôi phục về thời điểm 5:14 chiều tối Thứ Ba và đang hoạt động. Trong lịch sử của vũ trụ cơ sở dữ liệu này, bạn chưa bao giờ bỏ bảng. Nhưng giả sử sau này bạn nhận ra đây không phải là một ý tưởng tuyệt vời và bạn muốn quay lại vào sáng thứ Tư nào đó trong lịch sử ban đầu. Bạn sẽ không thể thực hiện được nếu, trong khi cơ sở dữ liệu của bạn đang hoạt động, nó đã ghi đè một số tệp phân đoạn WAL dẫn đến thời điểm mà bạn mong muốn có thể quay lại.
Do đó, để tránh điều này, bạn cần phân biệt chuỗi bản ghi WAL được tạo sau khi bạn thực hiện khôi phục tại thời điểm với những bản ghi được tạo trong lịch sử cơ sở dữ liệu ban đầu.
Để đối phó với vấn đề này, PostgreSQL có một khái niệm về các mốc thời gian. Bất cứ khi nào quá trình khôi phục kho lưu trữ hoàn tất, một dòng thời gian mới được tạo để xác định chuỗi bản ghi WAL được tạo sau quá trình khôi phục đó. Số ID dòng thời gian là một phần của tên tệp phân đoạn WAL để dòng thời gian mới không ghi đè dữ liệu WAL được tạo bởi dòng thời gian trước đó. Trên thực tế, có thể lưu trữ nhiều mốc thời gian khác nhau.
Hãy xem xét tình huống mà bạn không chắc chắn về thời điểm nào để khôi phục và do đó, bạn phải thực hiện một số khôi phục trong thời gian ngắn bằng cách thử và sai cho đến khi bạn tìm thấy nơi tốt nhất để tách khỏi lịch sử cũ. Nếu không có các mốc thời gian, quá trình này sẽ sớm tạo ra một mớ hỗn độn không thể quản lý được. Với dòng thời gian, bạn có thể khôi phục về bất kỳ trạng thái nào trước đó, bao gồm các trạng thái trong nhánh dòng thời gian mà bạn đã bỏ qua trước đó.
Mỗi khi dòng thời gian mới được tạo, PostgreSQL sẽ tạo một tệp "lịch sử dòng thời gian" cho biết dòng thời gian đó được phân nhánh từ đâu và khi nào. Các tệp lịch sử này là cần thiết để cho phép hệ thống chọn các tệp phân đoạn WAL phù hợp khi khôi phục từ một kho lưu trữ chứa nhiều mốc thời gian. Do đó, chúng được lưu trữ vào vùng lưu trữ WAL giống như các tệp phân đoạn WAL. Các tệp lịch sử chỉ là các tệp văn bản nhỏ, vì vậy sẽ rẻ và thích hợp để lưu giữ chúng vô thời hạn (không giống như các tệp phân đoạn có dung lượng lớn). Nếu muốn, bạn có thể thêm nhận xét vào tệp lịch sử để ghi lại ghi chú của riêng mình về cách thức và lý do tạo dòng thời gian cụ thể này. Những nhận xét như vậy sẽ đặc biệt có giá trị khi bạn có một tập hợp các mốc thời gian khác nhau do kết quả của quá trình thử nghiệm.
Hành vi mặc định của khôi phục là khôi phục cùng dòng thời gian hiện tại khi sao lưu cơ sở được thực hiện. Nếu bạn muốn khôi phục vào một dòng thời gian con nào đó (nghĩa là bạn muốn quay lại một số trạng thái đã được tạo sau khi cố gắng khôi phục), bạn cần chỉ định ID dòng thời gian đích trong recovery.conf. Bạn không thể khôi phục vào dòng thời gian phân nhánh sớm hơn so với bản sao lưu cơ sở.
Để đơn giản hóa khái niệm dòng thời gian trong PostgreSQL, các vấn đề liên quan đến dòng thời gian trong trường hợp chuyển đổi dự phòng , chuyển đổi và pg_rewind được tóm tắt và giải thích bằng Hình 1, Hình 2 và Hình 3.
Trường hợp chuyển đổi dự phòng:
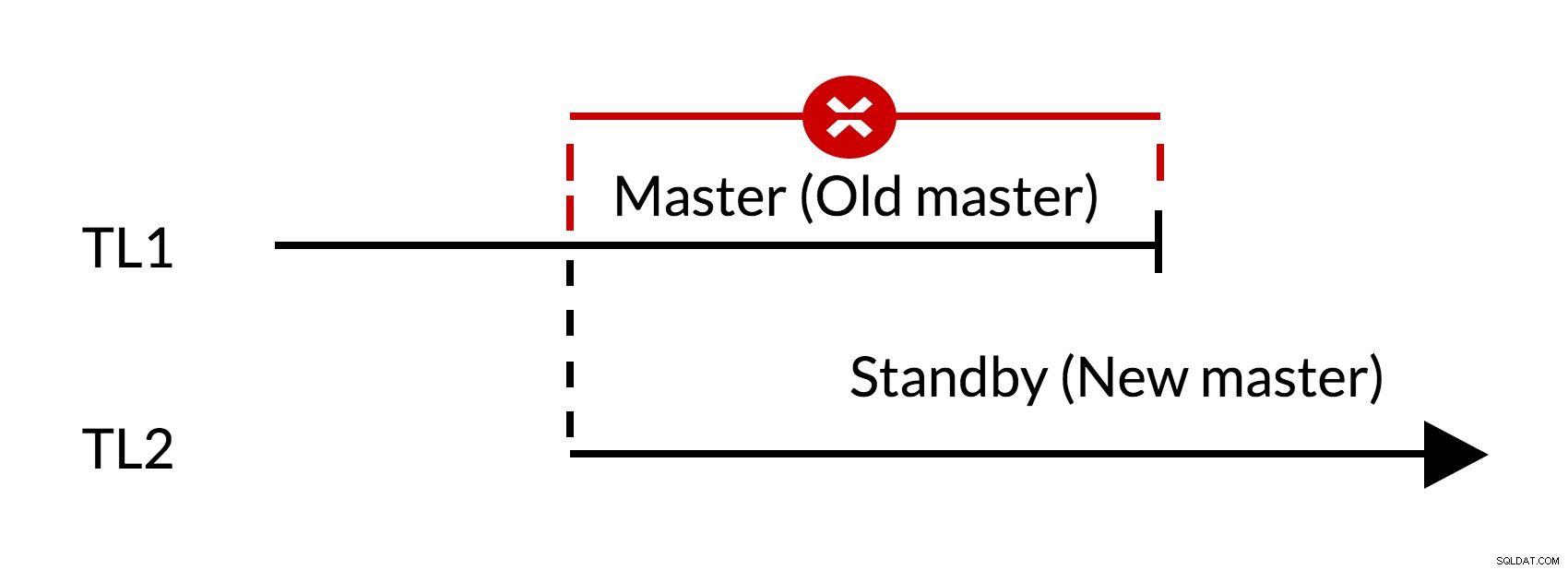
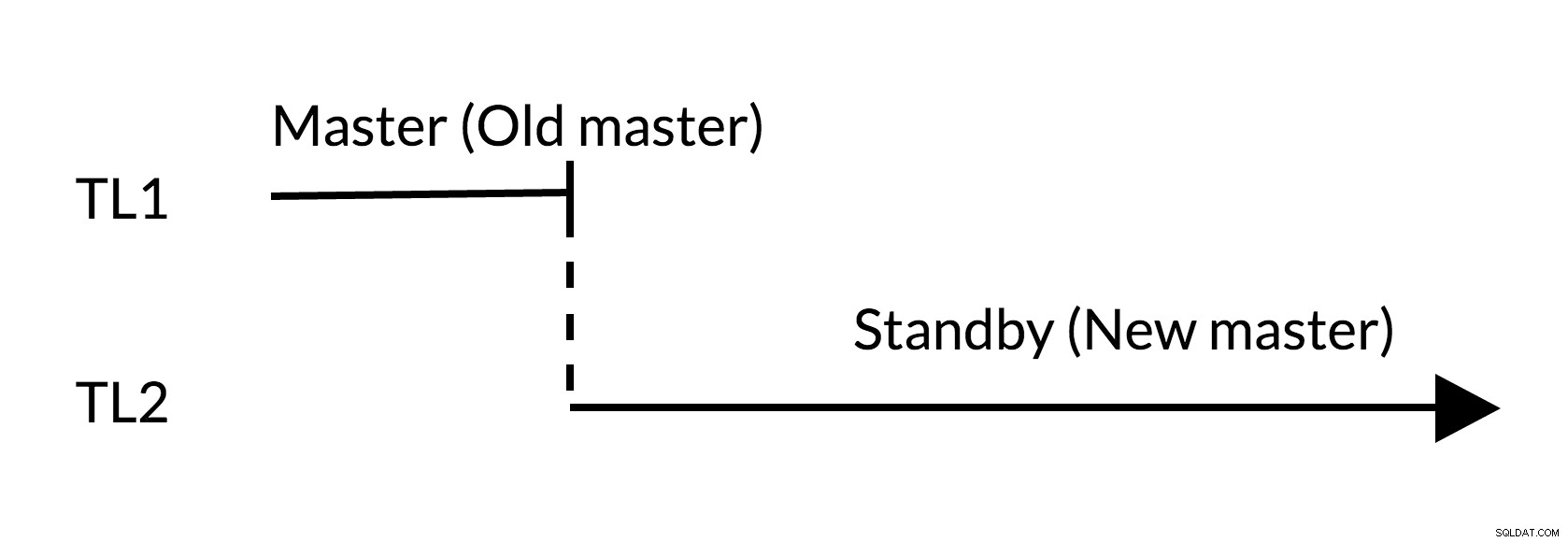
Hình 1 Chuyển đổi dự phòng
- Có những thay đổi nổi bật trong trang cái cũ (TL1)
- Tăng dòng thời gian thể hiện lịch sử thay đổi mới (TL2)
- Không thể phát lại các thay đổi từ dòng thời gian cũ trên các máy chủ đã chuyển sang dòng thời gian mới
- Chủ cũ không thể theo dõi chủ mới
Kịch bản chuyển mạch:
 Hình 2 Switchover
Hình 2 Switchover
- Không có thay đổi nổi bật nào trong trang cái cũ (TL1)
- Tăng dòng thời gian thể hiện lịch sử thay đổi mới (TL2)
- Bản chính cũ có thể trở thành chế độ chờ cho bản chính mới
pg_rewind kịch bản:
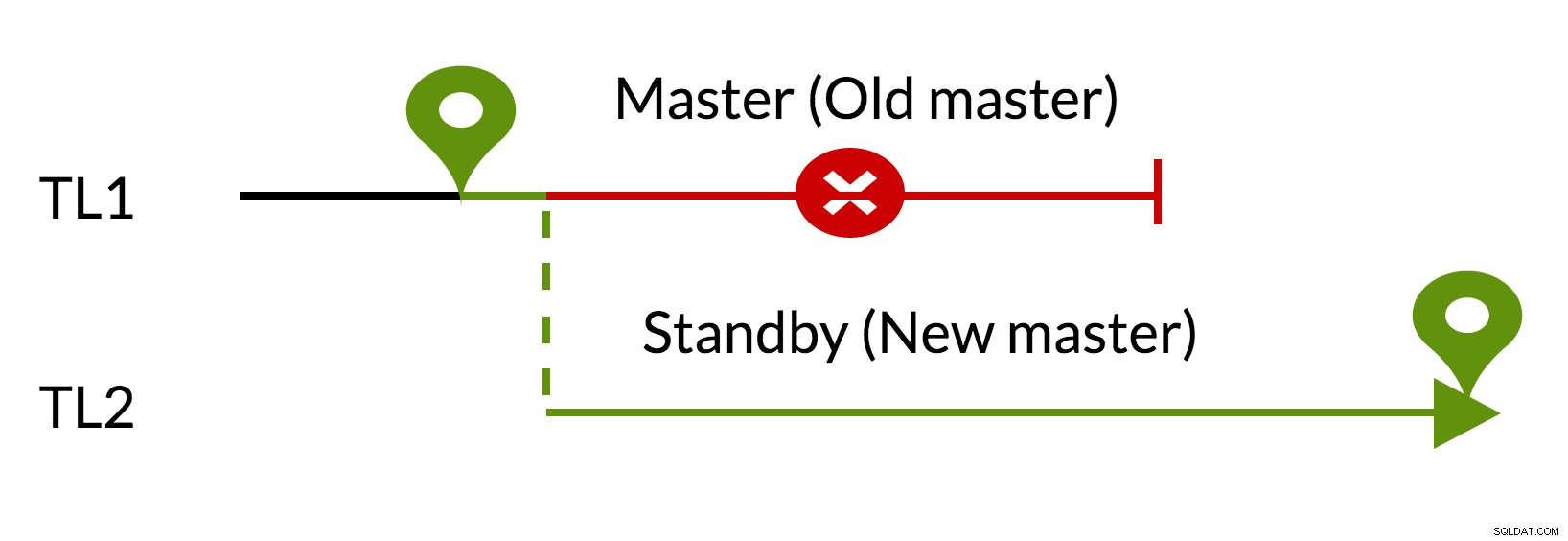
- Các thay đổi nổi bật sẽ bị xóa bằng cách sử dụng dữ liệu từ trang cái mới (TL1)
- Trang cái cũ có thể theo dõi trang cái mới (TL2)
pg_rewind
pg_rewind là một công cụ để đồng bộ hóa một cụm PostgreSQL với một bản sao khác của cùng một cụm, sau khi các mốc thời gian của các cụm đã khác nhau. Một tình huống điển hình là đưa máy chủ chính cũ trở lại trực tuyến sau khi chuyển đổi dự phòng, ở chế độ chờ sau máy chủ mới.
Kết quả tương đương với việc thay thế thư mục dữ liệu đích bằng thư mục nguồn. Tất cả các tệp đều được sao chép, bao gồm cả tệp cấu hình. Ưu điểm của pg_rewind so với việc sử dụng một bản sao lưu cơ sở mới hoặc các công cụ như rsync là pg_rewind không yêu cầu đọc qua tất cả các tệp không thay đổi trong cụm. Điều đó làm cho nó nhanh hơn rất nhiều khi cơ sở dữ liệu lớn và chỉ một phần nhỏ của nó khác nhau giữa các cụm.
Nó hoạt động như thế nào?
Ý tưởng cơ bản là sao chép mọi thứ từ cụm mới sang cụm cũ, ngoại trừ các khối mà chúng ta biết là giống nhau.
- Quét nhật ký WAL của cụm cũ, bắt đầu từ điểm kiểm tra cuối cùng trước điểm mà lịch sử dòng thời gian của cụm mới tách khỏi cụm cũ. Đối với mỗi bản ghi WAL, hãy ghi lại các khối dữ liệu đã được chạm vào. Điều này mang lại danh sách tất cả các khối dữ liệu đã được thay đổi trong cụm cũ, sau khi cụm mới tách rời.
- Sao chép tất cả các khối đã thay đổi đó từ cụm mới sang cụm cũ.
- Sao chép tất cả các tệp khác, chẳng hạn như tệp cấu hình và tắc nghẽn từ nhóm mới sang nhóm cũ, mọi thứ ngoại trừ các tệp quan hệ.
- Áp dụng WAL từ cụm mới, bắt đầu từ điểm kiểm tra được tạo khi chuyển đổi dự phòng. (Nói một cách chính xác, pg_rewind không áp dụng WAL, nó chỉ tạo một tệp nhãn dự phòng cho biết rằng khi PostgreSQL được khởi động, nó sẽ bắt đầu phát lại từ điểm kiểm tra đó và áp dụng tất cả WAL được yêu cầu.)
Lưu ý: wal_log_hints phải được đặt trong postgresql.conf để pg_rewind có thể hoạt động. Tham số này chỉ có thể được đặt khi máy chủ khởi động. Giá trị mặc định là tắt .
Kết luận
Trong bài đăng trên blog này, chúng tôi đã thảo luận về các mốc thời gian trong Postgres và cách chúng tôi xử lý các trường hợp chuyển đổi dự phòng và chuyển đổi. Chúng tôi cũng đã nói về cách pg_rewind hoạt động và lợi ích của nó đối với khả năng chịu lỗi và độ tin cậy của Postgres. Chúng tôi sẽ tiếp tục cam kết đồng bộ trong bài đăng blog tiếp theo.
Tài liệu tham khảo
Tài liệu PostgreSQL
Sách nấu ăn quản trị PostgreSQL 9 - Phiên bản thứ hai
pg_rewind Nordic PGDay trình bày bởi Heikki Linnakangas