Tôi rất vui được tham dự PGDay UK vào tuần trước - một sự kiện rất tốt đẹp, hy vọng tôi sẽ có cơ hội trở lại vào năm sau. Có rất nhiều cuộc nói chuyện thú vị, nhưng cuộc nói chuyện thu hút sự chú ý của tôi đặc biệt là Performace cho các truy vấn có nhóm của Alexey Bashtanov.
Tôi đã từng đưa ra một số cuộc nói chuyện tương tự về hiệu suất trong quá khứ, vì vậy tôi biết khó khăn như thế nào để trình bày kết quả điểm chuẩn một cách dễ hiểu và thú vị, và tôi nghĩ Alexey đã làm một công việc khá tốt. Vì vậy, nếu bạn xử lý việc tổng hợp dữ liệu (tức là BI, phân tích hoặc khối lượng công việc tương tự), tôi khuyên bạn nên xem qua các trang trình bày và nếu bạn có cơ hội tham dự buổi nói chuyện về một số hội nghị khác, tôi thực sự khuyên bạn nên làm như vậy.
Nhưng có một điểm mà tôi không đồng ý với bài nói chuyện. Ở một số nơi, cuộc nói chuyện gợi ý rằng bạn thường nên thích HashAggregate hơn, vì việc sắp xếp diễn ra chậm chạp.
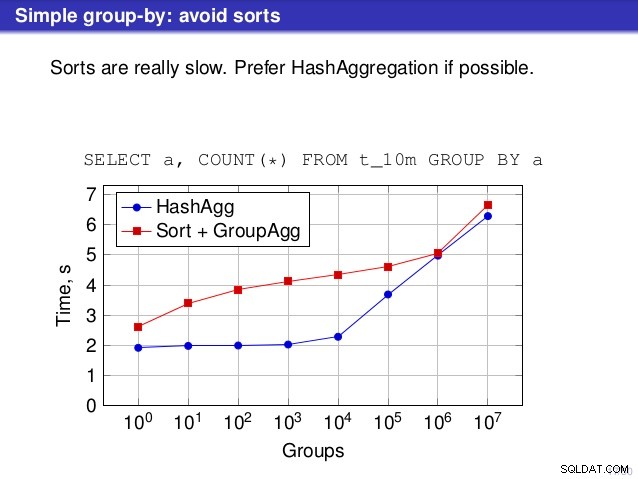
Tôi cho rằng điều này hơi gây hiểu lầm, bởi vì một giải pháp thay thế cho HashAggregate là GroupAggregate, không phải Sort. Vì vậy, đề xuất giả định rằng mỗi GroupAggregate có một Sắp xếp lồng nhau, nhưng điều đó không hoàn toàn đúng. GroupAggregate yêu cầu đầu vào được sắp xếp và Sắp xếp rõ ràng không phải là cách duy nhất để làm điều đó - chúng tôi cũng có các nút IndexScan và IndexOnlyScan, giúp loại bỏ chi phí sắp xếp và giữ các lợi ích khác liên quan đến các đường dẫn được sắp xếp (đặc biệt là IndexOnlyScan).
Hãy để tôi chứng minh cách (IndexOnlyScan + GroupAggregate) hoạt động như thế nào so với cả HashAggregate và (Sort + GroupAggregate) - tập lệnh mà tôi đã sử dụng cho các phép đo có ở đây. Nó xây dựng bốn bảng đơn giản, mỗi bảng có 100 triệu hàng và số lượng nhóm khác nhau trong cột "branch_id" (xác định kích thước của bảng băm). Cái nhỏ nhất có 10k nhóm
-- table with 10k groups create table t_10000 (branch_id bigint, amount numeric); insert into t_10000 select mod(i, 10000), random() from generate_series(1,100000000) s(i);
và ba bảng bổ sung có nhóm 100k, 1M và 5M. Hãy chạy truy vấn đơn giản này để tổng hợp dữ liệu:
SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1
và sau đó thuyết phục cơ sở dữ liệu sử dụng ba kế hoạch khác nhau:
1) HashAggregate
SET enable_sort = off;
SET enable_hashagg = on;
EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1;
QUERY PLAN
----------------------------------------------------------------------------
HashAggregate (cost=2136943.00..2137067.99 rows=9999 width=40)
Group Key: branch_id
-> Seq Scan on t_10000 (cost=0.00..1636943.00 rows=100000000 width=19)
(3 rows) 2) GroupAggregate (có sắp xếp)
SET enable_sort = on;
SET enable_hashagg = off;
EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1;
QUERY PLAN
-------------------------------------------------------------------------------
GroupAggregate (cost=16975438.38..17725563.37 rows=9999 width=40)
Group Key: branch_id
-> Sort (cost=16975438.38..17225438.38 rows=100000000 width=19)
Sort Key: branch_id
-> Seq Scan on t_10000 (cost=0.00..1636943.00 rows=100000000 ...)
(5 rows) 3) GroupAggregate (với IndexOnlyScan)
SET enable_sort = on;
SET enable_hashagg = off;
CREATE INDEX ON t_10000 (branch_id, amount);
EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1;
QUERY PLAN
--------------------------------------------------------------------------
GroupAggregate (cost=0.57..3983129.56 rows=9999 width=40)
Group Key: branch_id
-> Index Only Scan using t_10000_branch_id_amount_idx on t_10000
(cost=0.57..3483004.57 rows=100000000 width=19)
(3 rows) Kết quả
Sau khi đo lường thời gian cho mỗi kế hoạch trên tất cả các bảng, kết quả trông như thế này:
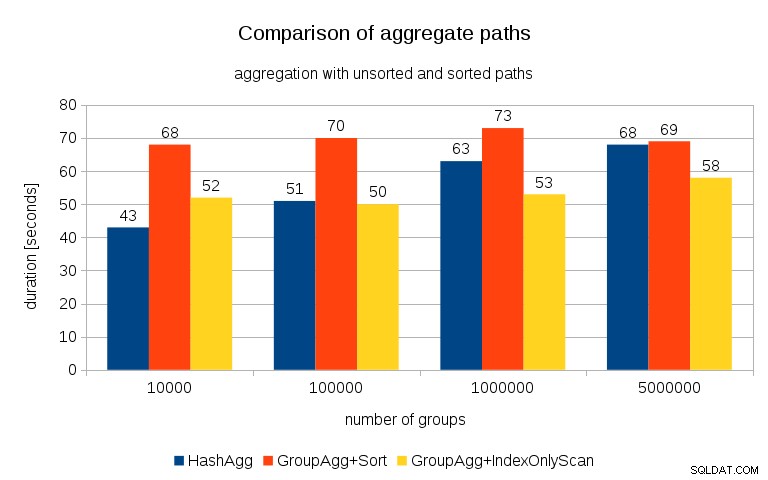
Đối với các bảng băm nhỏ (vừa với bộ đệm L3, trong trường hợp này là 16MB), đường dẫn HashAggregate rõ ràng là nhanh hơn cả hai đường dẫn được sắp xếp. Nhưng chẳng bao lâu nữa GroupAgg + IndexOnlyScan cũng nhanh hơn hoặc thậm chí nhanh hơn - điều này là do hiệu quả của bộ nhớ cache, ưu điểm chính của GroupAggregate. Trong khi HashAggregate cần giữ toàn bộ bảng băm trong bộ nhớ cùng một lúc, GroupAggregate chỉ cần giữ nhóm cuối cùng. Và bạn sử dụng càng ít bộ nhớ thì càng có nhiều khả năng phù hợp với bộ nhớ đệm L3, tức là nhanh hơn một bậc so với RAM thông thường (đối với bộ nhớ đệm L1 / L2, sự khác biệt thậm chí còn lớn hơn).
Vì vậy, mặc dù có một chi phí đáng kể liên quan đến IndexOnlyScan (đối với trường hợp 10k, nó chậm hơn khoảng 20% so với đường dẫn HashAggregate), khi bảng băm phát triển, tỷ lệ truy cập bộ nhớ cache L3 nhanh chóng giảm xuống và sự khác biệt cuối cùng làm cho GroupAggregate nhanh hơn. Và cuối cùng, ngay cả GroupAggregate + Sort cũng ngang bằng với đường dẫn HashAggregate.
Bạn có thể tranh luận rằng dữ liệu của bạn thường có số lượng nhóm khá thấp và do đó bảng băm sẽ luôn phù hợp với bộ đệm L3. Nhưng hãy xem xét rằng bộ đệm L3 được chia sẻ bởi tất cả các tiến trình đang chạy trên CPU và cũng bởi tất cả các phần của kế hoạch truy vấn. Vì vậy, mặc dù chúng tôi hiện có ~ 20MB bộ nhớ đệm L3 trên mỗi ổ cắm, truy vấn của bạn sẽ chỉ nhận được một phần trong số đó và bit đó sẽ được chia sẻ bởi tất cả các nút trong truy vấn (có thể khá phức tạp) của bạn.
Cập nhật 2016/07/26 :Như đã chỉ ra trong nhận xét của Peter Geoghegan, cách dữ liệu được tạo ra có thể dẫn đến mối tương quan - không phải giá trị (hay đúng hơn là băm của giá trị), mà là cấp phát bộ nhớ. Tôi đã lặp lại các truy vấn với dữ liệu ngẫu nhiên thích hợp, tức là đang thực hiện
insert into t_10000 select (10000*random())::bigint, random() from generate_series(1,100000000) s(i);
thay vì
insert into t_10000 select mod(i, 10000), random() from generate_series(1,100000000) s(i);
và kết quả như sau:
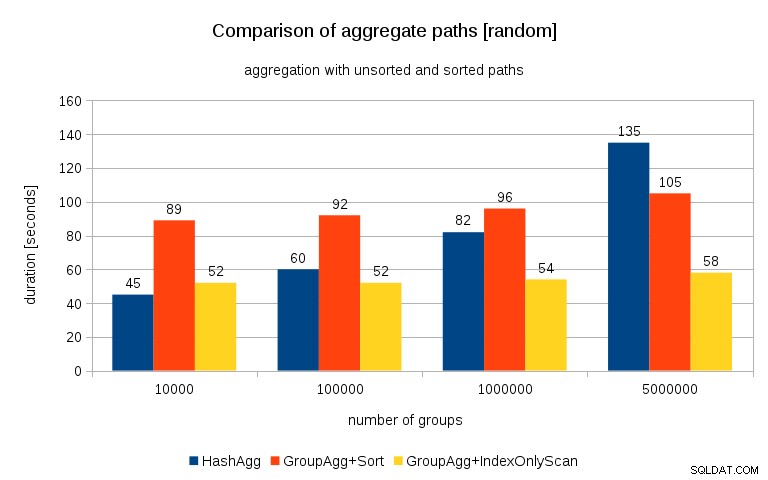
So sánh điều này với biểu đồ trước, tôi nghĩ khá rõ ràng là các kết quả thậm chí còn nghiêng về các đường dẫn được sắp xếp, đặc biệt là đối với tập dữ liệu có 5 triệu nhóm. Tập dữ liệu 5M cũng cho thấy rằng GroupAgg với Sắp xếp rõ ràng có thể nhanh hơn HashAgg.
Tóm tắt
Mặc dù HashAggregate có thể nhanh hơn GroupAggregate với một Sort rõ ràng (tuy nhiên, tôi do dự khi nói rằng nó luôn luôn như vậy), việc sử dụng GroupAggregate với IndexOnlyScan nhanh hơn có thể dễ dàng làm cho nó nhanh hơn nhiều so với HashAggregate.
Tất nhiên, bạn không thể chọn kế hoạch chính xác trực tiếp - người lập kế hoạch nên làm điều đó cho bạn. Nhưng bạn ảnh hưởng đến quá trình lựa chọn bằng cách (a) tạo chỉ mục và (b) thiết lập work_mem . Đó là lý do tại sao đôi khi work_mem thấp hơn (và maintenance_work_mem ) giá trị dẫn đến hiệu suất tốt hơn.
Tuy nhiên, các chỉ mục bổ sung không miễn phí - chúng tốn cả thời gian CPU (khi chèn dữ liệu mới) và dung lượng ổ đĩa. Đối với IndexOnlyScans, các yêu cầu về dung lượng đĩa có thể khá lớn vì chỉ mục cần bao gồm tất cả các cột được tham chiếu bởi truy vấn và IndexScan thông thường sẽ không cung cấp cho bạn hiệu suất tương tự vì nó tạo ra nhiều I / O ngẫu nhiên so với bảng (loại bỏ tất cả lợi nhuận tiềm năng).
Một tính năng thú vị khác là tính ổn định của hiệu suất - hãy chú ý cơ hội định thời gian của HashAggregate tùy thuộc vào số lượng nhóm, trong khi các đường dẫn GroupAggregate hoạt động hầu như giống nhau.



